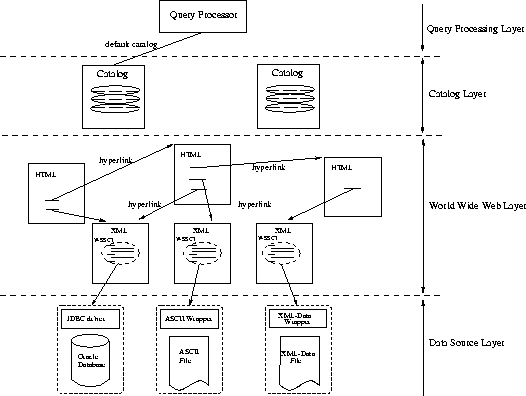
Figure 1: The WebSemantics layers
Recently, many standardized collections of scientific data, in specific disciplines, have become available. For example, many collections of environmental data, located around the world, are now available to scientists [Fra97, Web97]. These sources comply with a standard for interoperability, e.g. the data is in a relational DBMS. The data may also conform to a common semantics, i.e. each item of data is precisely defined. However, the sharing of information between scientists is still a very difficult process. Sharing is hindered by the lack of mechanisms for describing and publishing data sources, for discovering the existence of data relevant to a problem, and accessing discovered relevant data. After a set of potentially relevant sources has been identified, we still have the problem of deciding which sources are best suited for the task at hand. Sources differ with respect to their coverage of a particular domain as well as quality parameters such as data recency, granularity, etc.
In this paper we present an architecture, WebSemantics [MRT98], which permits describing, publishing, discovery and access to sources containing typed data.
WebSemantics extends the Web with a format for publishing data sources and wrappers for these sources in WS-XML documents. A query language facilitates the discovery of relevant published data sources. The language combines features for searching over the metadata (types and domains) with features for searching relevant documents that publish data sources. The document search space is specified by means of text patterns and path regular expressions similar to those used in WebSQL. Thus, we smoothly integrate the functionality already existing on the WWW for searching documents with our extensions for searching over the metadata associated with sources. Once relevant data sources have been found, the same language provides access to the data.
The WS system has a layered architecture of interdependent components (see Figure 1).
Figure 1: The WebSemantics layers
The Data Source Layer has two components, data sources and wrappers. Data providers create and manage collections of autonomous data sources, that can be accessed over the Internet. These data sources can provide query capability ranging from full DBMS functionality to simple scanning of files. WS assumes uniform access to both kinds of sources, independent of the capability of the sources. This may be accomplished using wrapper components.
The second layer is the World Wide Web Layer. The WWW is used as a medium for describing and publishing sources. Thus, in order to publish a data source, a provider needs to create a WS-XML document describing the source.
The third layer is the Catalog Layer. A catalog is a specialized repository storing metadata about a collection of data sources in some application domain. For each source the catalog maintains metadata characterizing the source, such as the set of types exported by the source; the domains for a subset of attributes of some types; a textual description of the data source; the URL of the WS-XML document that published the source, etc. The catalog must be kept consistent with the current contents of the registered sources.
Finally, the WS query processor component, bound to a specific catalog, gives the user integrated access to the collection of sources registered in the catalog and to the data in these sources.
In the rest of the paper we illustrate the functionality of the WS system through a concrete example.
Consider a scientist who measures air quality parameters in Ontario. She measures the concentration of greenhouse gases in the atmosphere and stores the results of her daily measurements in a DB2 database. In order to make this data source available, she publishes the necessary connection information and metadata about the source's contents in an an WS-XML document as follows:
<?xml version="1.0"?>
<title>Environmental Data for Ontario</title>
<ws>
<wssci>
<wrapper>
<type>JDBC </type>
</wrapper>
<source>
<type>DB2</type>
<location>jdbc:db2://server.env.org/ontario</location>
<last_update
</source>
</wssci>
<metadata>
<schema>http://www.env.org/EnvSchema.xml</schema>
<type name="#AirQuality"
last_update="Mon Nov 16 20:36:48 EST 1998" />
<type name="#Rainfall"
last_update="Mon Nov 30 10:23:05 EST 1998" />
...
</metadata>
<desc> This repository contains daily measurements of air quality
parameters in Ontario for the year 1998. </desc>
</ws>
|
This document contains the address of the database server, the name of the database, the type of wrapper needed, and a textual description of the source's contents. The document also states that the types in the data source conform to a schema specified in a separate XML document, which is shared by a community of environmental scientists. This document follows the XML-Data [XD97] conventions for describing strongly typed relational schemas:
<?xml version="1.0"?>
<title>Standard Schema for Environmental Data</title>
<elementType id = "date">
<string/>
<datatype dt = "date.iso8601">
</elementType>
<elementType id = "location">
<string/>
</elementType>
<elementType id = "CO2percentage">
<string/>
<datatype dt = "float">
</elementType>
...
<elementType id = "AirQuality">
<element type = "#date">
<element type = "#location">
<element type = "#CO2percentage">
...
</elementType>
|
The contents of a source can be defined by the domains of selected fields of the types in the relational schema. Domains are described in the following manner:
<metadata>
...
<domain>
<type name="#AirQuality" />
<attribute name="#location" atttype="ENUMERATION"
values="Toronto Hamilton Kingston ..." default="Toronto" />
<attribute name="#date" granularity="1:00:00"/>
...
</domain>
</metadata>
|
Suppose now that a second scientist is interested in air quality data sources for his research. In order to locate data sources of interest, he can execute the following query:
<document text $contains$ "greenhouse gases">
<source ID=$s >
<type ID="AirQuality"></type>
</source>
</document>
|
This query identifies all the data sources described in documents containing the specified phrase. To identify a list of candidate WS-XML documents, a keyword query is submitted to an index server (such as AltaVista). Alternately, one can restrict the search to a specific Web site, as in the following query:
<document ID="http://www.env.org/index.html">
<local*>
<document ID=$d text $contains$ "greenhouse gases" >
<source ID=$s >
<type ID="AirQuality"></type>
</source>
</document>
</>
</document>
|
The above query identifies all the documents on the ``www.env.org'' server which are reachable from the root page. The path regular expression <local*> means ``traverse any number of local links starting from the specified URL''. The set of documents of interest is restricted by the condition text $contains$ "greenhouse gases" which specifies a string containment condition.
Discovered sources may be registered in a WS catalog for that application domain. Catalogs maintain an array of metadata about each source, such as the set of types and domains, time of most recent update, granularity, etc. This information can subsequently be used to select sources based on their content. For example, to select from a given catalog all sources whose granularity corresponds to hourly AirQuality readings for Toronto, and whose data has been updated in the last week, one can issue the following query:
<catalog ID="rmi://alpha.env.org/WSCatalog">
<source ID=$s>
<type ID="AirQuality"
last_update $ge$ "Thu Nov 26 0:00:00 EST 1998" \>
<domain>
<type ID="AirQuality"/>
<attribute name="location" values $contains$ "Toronto" >
<attribute name="date" granularity $eq$ "1:00:00" >
</domain>
</source>
</catalog>
|
The pattern associated with domain restricts the acceptable sources to those who describe the domain for the location attribute of AirQuality to include ``Toronto''.
We have presented an infrastructure which permits publication, discovery and access to data sources. The architecture relies on open standards such as XML and XML-Data for publishing connection parameters and metadata about the contents of data sources. Another key component of the system is a catalog storing additional metadata about the quality of the sources such as domains covered, granularity, recency, frequency of updates, etc. This information can subsequently be used to select sources that contain relevant data and satisfy specific quality requirements.
In future work, we consider harnessing the technology that searches the Web, a la search engines, to gather URLs of all the WS-XML documents that publish sources, and construct indexes over these pages. These indexes may store the keywords from the natural language descriptions of the sources. They may also store the metadata extracted from WS-XML documents. The indexes would then be used to register sources into the catalog. This would be a natural extension of the WS architecture.