Figure 1: Example of a hypertree
Current methods of searching the Web are severely limited not only in their abilities to find the information we are looking for, but in the way this information is presented once found.
New, effective tools for querying and restructuring this information are needed. The development of such tools can be eased by relying on powerful declarative query languages, much in the same way as traditional data management applications rely on SQL. In this paper we give a brief overview of two such query languages we designed to support web querying and restructuring, WebSQL [MMM97, AMM97] and WebOQL [Aro97, AM98]. We show that, with the appropriate wrapper, WebOQL can be easily used to query XML documents.
Our first web query language aimed to combine the content-based queries of search engines with structure-based queries similar to what one would find in a database system. The language combines conditions on text patterns appearing within documents with graph patterns describing link structure.
WebSQL proposes to model the web as a relational database composed of two (virtual) relations: Document and Anchor. The Document relation has one tuple for each document in the web and the Anchor relation has one tuple for each anchor in each document in the web. This relational abstraction of the web allows us to use a query language similar to SQL to pose the queries.
If Document and Anchor were actual relations, we could simply use SQL to write queries on them. But since the Document and Anchor relations are completely virtual and there is no way to enumerate them, we cannot operate on them directly. The WebSQL semantics depends instead on materializing portions of them by specifying the documents of interest in the FROM clause of a query. The basic way of materializing a portion of the web is by navigating from known URL's. Path regular expressions are used to describe this navigation. An atom of such a regular expression can be of the form d1 => d2, meaning document d1 points to d2 and d2 is stored on a different server from d1; or d1 -> d2, meaning d1 points to d2 and d2 is stored on the same server as d1.
For example, suppose we want to find a list of triples of the form (d1,d2,label), where d1 is a document stored on our local site, d2 is a document stored somewhere else, and d1 points to d2 by a link labeled label. Assume all our local documents are reachable from www.mysite.start.
SELECT d.url,e.url,a.label
FROM Document d SUCH THAT
"www.mysite.start" ->* d,
Document e SUCH THAT d => e,
Anchor a SUCH THAT a.base = d.url
WHERE a.href = e.url AND a.label = "label";
|
The FROM clause instantiates two Document variables, d and e, and one Anchor variable a. The variable d is bound in turn to each local document reachable from the starting document, and e is bound to each non-local document reachable directly from d. The anchor variable a is instantiated to each link that originates in document d; the extra condition that the target of link a be document e is given in the WHERE clause. Another way of materializing part of the Document and Anchor relations is by content conditions: for example, if we were only interested in documents that contains the string ``database'' we could have added to the FROM clause the condition d MENTIONS "database". The implementation uses search engines to generate candidate documents that satisfy the MENTIONS conditions.
The language described above treats web pages as atomic objects with two properties: they contain or do not contain certain text patterns, and they point to other objects. In this section we describe our second web query language, WebOQL. This language goes beyond WebSQL in two significant ways. First, it provides access to the internal structure of the web objects it manipulates. Second, it provides the ability to create new complex structures as a result of a query. Since the data on the web is commonly semistructured, the language emphasizes the ability to support semistructured features.
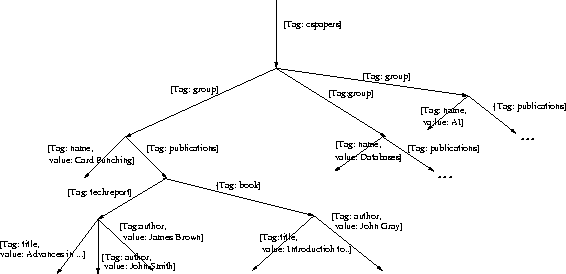
The main data structure provided by WebOQL is the hypertree. Hypertrees are ordered arc-labeled trees with two types of arcs, internal and external. Internal arcs are used to represent structured objects and external arcs are used to represent references (typically hyperlinks) among objects. Arcs are labeled with records. Figure 1 shows a hypertree containing descriptions of publications from several research groups. Such a tree could easily be built, for example, from the XML file shown in Figure 2, using a generic XML wrapper.
Figure 1: Example of a hypertree
<?xml version="1.0"?>
<cspapers>
<group>
<name>Card Punching</name>
<publications>
<techreport>
<title>Advances in Card Punching</title>
<author>John Smith</author>
<author>James Brown</author>
</techreport>
<book>
<title>Introduction to Card Punching</title>
<author>John Gray</author>
</book>
</publications>
</group>
<group>
<name>Databases</name>
<publications>
...
</publications>
</group>
...
</cspapers>
|
Sets of related hypertrees are collected into webs. Both hypertrees and webs can be manipulated using WebOQL and created as the result of a query.
WebOQL is a functional language, but queries are couched in the familiar select-from-where form. For example, suppose that the file ``pubs.xml'' contains the publications database in Figure 1, and that we want to extract from it all the publications authored by ``Smith''.
[Tag:"result" /
select y
from x in browse("file:pubs.xml") via ^*[tag = "publications"],
y in x',
z in y'
where z.tag = "author" and z.value ~ "Smith"
]
|
In this query, x iterates over the ``publications'' subtrees of csPapers and, given a value for x, y iterates over the simple trees of x'. The primed variable x' denotes the result of applying to tree x the Prime operator, which returns the first subtree of its argument. The same applies for the primed variable y'. The tilde represents the string pattern matching predicate: its left argument is a string and its right argument is a grep pattern. Finally, the result of the select-from-where subquery is "hanged" from a new arc labeled with tag "result".
Web Creation The query above maps a hypertree into another hypertree; more generally, a query is a function that maps a web into another. For example, the following query creates a new page for each research group containing only the publications of that group.
select x' as x'.value
from x in browse("file:pubs.xml")'
|
The ``as'' clause specifies that the group name is to be used to create a URL from for each newly created page.
Despite its simple data model, WebSQL is expressive enough to facilitate the development of applications for resource discovery, site maintenance and custom indexing. WebOQL, while retaining all the inter-document exploring capabilities of its precursor, has powerful intra-document data extraction features. This makes it well suited for building applications that retrieve and integrate custom information from existing web sites.
While the two languages we discussed in this paper were designed in the context of the current HTML-dominated web, they continue to be relevant in a web with richer markup languages such as XML. The considerable momentum behind XML and related metadata initiatives can only help the applicability of database concepts to the web by providing the much needed structure in a widely accepted format. While the availability of data in XML format will reduce the need to focus on wrappers converting human readable data to machine readable data, the challenges of semantic integration of data from web sources still remain.