Working Group Chairs:
Eric Miller, Online Computer Library Center
Bob Schloss, IBM
Editors:
Ora Lassila, lassila@w3.org,
Nokia Research Center (currently visiting W3C)
Ralph R. Swick, swick@w3.org,
World Wide Web Consortium
Contributors:
Tsuyoshi Sakata (DVL), Murray Maloney (Grif), Bob Schloss (IBM), Naohiko
URAMOTO (IBM), Bill Roberts (KnowledgeCite) Ron Daniel (LANL), Andrew Layman
(Microsoft), Chris McConnell (Microsoft), Jean Paoli (Microsoft), R.V.
Guha (Netscape), Ora Lassila (Nokia), Ralph LeVan (OCLC), Eric Miller (OCLC),
Misha Wolf (Reuters), Lauren Wood (SoftQuad), Tim Bray (Textuality), Paul
Resnick (U. Mich), Tim Berners-Lee (W3C), Dan Connolly (W3C), Jim Miller
(W3C), Ralph Swick (W3C).
Version 1, 02-Oct-1997
This version: http://www.w3.org/TR/WD-rdf-syntax-971002
Latest version: http://www.w3.org/Metadata/RDF/Group/WD-rdf-syntax
Previous version: http://www.w3.org/Member/9708/WD-rdf-syntax-970801
This specification represents a work in progress. It is strongly recommended that only experimental software be implemented to this specification. This working group will not allow early implementation to affect their ability to make changes to this specification in a future revision. This is a draft document and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to use W3C Working Drafts as reference material or to cite them as other than "work in progress". The RDF Model and Syntax Working Group of the W3C will determine when this document should become a public W3C working draft.
Note: As working drafts are subject to frequent change, you are advised to reference the above URL for "Latest version" rather than the URLs for working draft versions themselves. The latest version URL will always point to the most current version of this draft.
RDF – the Resource Description Framework – is a foundation for processing metadata; it provides interoperability between applications that exchange machine-understandable information on the Web. RDF emphasizes facilities to enable automated processing of Web resources. RDF metadata can be used in a variety of application areas; for example: in resource discovery to provide better search engine capabilities; in cataloging for describing the content and content relationships available at a particular Web site, page, or digital library; by intelligent software agents to facilitate knowledge sharing and exchange; in content rating; in describing collections of pages that represent a single logical "document"; for describing intellectual property rights of Web pages, and in many others. RDF with digital signatures will be key to building the "Web of Trust" for electronic commerce, collaboration, and other applications.
Metadata is "data about data" or specifically in the context of RDF "data describing web resources." The distinction between "data" and "metadata" is not an absolute one; it is a distinction created primarily by a particular application. Many times the same resource will be interpreted in both ways simultaneously. RDF encourages this view by using XML as the encoding syntax for the metadata. The resources being described by RDF are, in general, anything that can be named via a URI. The broad goal of RDF is to define a mechanism for describing resources that makes no assumptions about a particular application domain, nor defines the semantics of any application domain. The definition of the mechanism should be domain neutral, yet the mechanism should be suitable for describing information about any domain.
This document introduces a model for representing RDF metadata and one syntax for expressing and transporting this metadata in a manner that maximizes the interoperability of independently developed web servers and clients. The syntax described in this document is best considered as a "serialization syntax" for the underlying RDF representation model. The serialization syntax is XML, XML being the W3C's work-in-progress to define a richer Web syntax for a variety of applications. RDF and XML are complementary; there will be alternate ways to represent the same RDF data model, some more suitable for direct human authoring. Future work may lead to including such alternatives in this document.
At the core of RDF is a model for representing named properties and their values. These properties serve both to represent attributes of resources (and in this sense correspond to usual attribute-value-pairs) and to represent relationships between resources. The RDF data model is a syntax-independent way of representing RDF statements.
RDF statements that are syntactically very different could mean the same thing. This concept of equivalence in meaning is very important when performing queries, aggregation and a number of other tasks at which RDF is aimed. The equivalence is defined in a clean machine understandable way. Two pieces of RDF are equivalent if and only if their corresponding data model representations are the same.
The core data model is precisely defined as:
|
In this data model both the resources being described and the values describing them are nodes in a directed labeled graph (and values may also be resources). The arcs connecting pairs of nodes correspond to the names of the property types. This is represented pictorially as:
[resource R] ---propertyType P---> [value V]
And is read "V is the value of the property P for resource R", or left-to-right; "R has property P with value V".
Consider as a simple example the statement:
"Ora Lassila" is the "author" of the web page "http://www.w3.org/People/Lassila"
This statement can be represented as follows
[http://www.w3.org/People/Lassila] ---author---> "Ora Lassila"
where the notation [URI] denotes the instance of the resource identified by URI and "..." denotes a simple Unicode string.
According to the formal definition, the property "author", i.e. the arc labeled "author" plus its source and target nodes is the triple (3-tuple):
{author, [http://www.w3.org/People/Lassila], "Ora Lassila"}
where "author" denotes a node used for labeling this arc. This formulation of the data model lends itself to reification, meaning that the relation expressed by the arc can be converted into a concrete node to which we can refer, as follows:
X ---PropName----> author X ---PropObj-----> [http://www.w3.org/People/Lassila] X ---PropValue---> "Ora Lassila"
which in fact means that a node X and three new triples are added:
{PropName, X, author}
{PropObj, X, [http://www.w3.org/People/Lassila]}
{PropValue, X, "Ora Lassila"}
It is later shown that reification allows us to express modalities (e.g. beliefs about statements) or simply attach any properties to other properties.
A collection of these triples with the same second item is called an assertions. Assertions are particularly useful when describing a number of properties of the same resource. Assertions are diagrammed as follows:
[resource R] ----property P1----> [value Vp1]
|
----property P2----> [value Vp2]
An RDF assertions can be a resource itself and can therefore be described by properties; that is, an assertions can itself be used as the source node of an arc.
Assertions may be associated with the resource they describe in one of four ways:
All resources will not support all association methods; in particular, many kinds of resources will not support embedding and only certain kinds of resources may be embedded.
The set of properties in a given assertions, as well as any characteristics or restrictions of the property values themselves, are defined by one or more schemas. Schemas are identified by URI and RDF relies on the XML namespace mechanism to associate the schema with the properties in the assertions. The schema URI may be treated merely as an identifier or it may refer to a machine-readable description of the schema. By definition, an application that understands a particular schema used by an assertions understands the semantics of each of the contained properties. An application that has no knowledge of the particular schema will minimally be able to parse the assertions into the property and property value components and will be able to transport the assertions intact (e.g. to a cache or to another application).
A human- or machine-readable description of an RDF schema may be accessed through content negotiation by dereferencing the schema URI. If the schema is machine-readable it may be possible for an application to learn some of the semantics of the properties named in the schema on demand. The logic and syntax of RDF schemas are described in a separate document; "RDF Machine Readable Schema Specification" (not yet written).
The triple composed of a resource, a property type, and a value is an RDF statement. Such a statement can itself be the target node of an arc (i.e. the value of some other property) or the source node of an arc (i.e. it can have properties). In these cases, the original property (i.e., the statement) must be reified; that is, converted into nodes and arcs. Reified properties are drawn as a single node with several arcs emanating from it representing the resource, property name, and value:
[property P1] ----PropName---> ["name"]
|
----PropObj----> [resource R]
|
----PropValue--> [value Vp1]
This allows RDF to be used to make statements about other statements; for example, the statement "Ralph believes that the document 'The Origin of Species' was authored by Charles Darwin" is diagrammed as:
[Ralph] --believes--> [statement1] --InstanceOf-> RDF:Property
|
--PropName---> "author"
|
--PropObj----> [http://loc.gov/Books/Species]
|
--PropValue--> "Charles Darwin"
To help in reifying properties, RDF defines the InstanceOf relation (property) to provide primitive typing, as shown in the previous example.
The formal definition of InstanceOf is:
|
The formal definition of reification is:
|
To reify a property, all that is done is to add to the data model an additional node (with a generated label) and the three triples with first items (or arcs with labels) of RDF:PropName, RDF:PropObj, and RDF:PropValue respectively, second item the generated node label, and third item the corresponding property type, resource node, and value node respectively.
Frequently it is necessary to create a collection of nodes; e.g. to state that a property has multiple values. RDF defines three kinds of collections: ordered lists of nodes, called sequences, unordered lists of nodes, called bags, and lists that represent alternatives for the (single) value of a property, called alternatives.
Formally, these three collection types are defined by:
|
To create collections of nodes, create a new node that is an RDF:InstanceOf one of the three node types RDF:Seq, RDF:Bag, or RDF:Alternatives. The remaining arcs from that new node point to each of the members of the collection and are uniquely labeled using the elements from Ord. For the RDF:Alternatives, there must be at least one member whose arc label is RDF:1, and that is the default value for the Alternatives node.
The RDF data model provides an abstract, conceptual framework for defining and using metadata. A concrete syntax is also needed for the purposes of authoring and exchanging this metadata. The syntax does not add to the model; APIs may be provided to manipulate RDF without reference to a concrete syntax. RDF uses the Extensible Markup Language (XML) encoding as its syntax. However, RDF will not require (and conforming implementations must not require) an XML Document Type Declaration for the contents of assertions. In this respect RDF requires at most the XML well-formedness constraints. RDF schemas may – but are not required to – be XML DTDs.
The syntax descriptions below use BNF notation to describe the essential RDF serialization syntax elements. As RDF is XML, all syntactic flexibilities of XML are implicitly included; e.g. whitespace rules, quoting, case sensitivity, etc. RDF requires the XML namespace facility, currently under review by the XML Working Group.
RDF serialization syntax takes the form:
[1] RDF ::= '<RDF:serialization>' node* '</RDF:serialization>'
[2] node ::= resource | assertions | aggregate
[3] resource ::= '<RDF:resource' idAttr? '>' property* '</RDF:resource>'
[4] assertions ::= '<RDF:assertions' idRefAttr* '>'
property* '</RDF:assertions>'
[5] aggregate ::= sequence | bag | alternatives
[6] sequence ::= '<RDF:seq' idAttr? '>' aggnode* '</RDF:seq>'
[7] bag ::= '<RDF:bag' idAttr? '>' aggnode* '</RDF:bag>'
[8] alternatives ::= '<RDF:alternatives' idAttr? '>'
aggnode* '</RDF:alternatives>'
[9] aggnode ::= node | '<RDF:li' hrefAttr '/>'
[10] idRefAttr ::= hrefAttr | idAttr
[11] hrefAttr ::= 'href="' resourceURI '"'
[12] idAttr ::= 'id="' IDsymbol '"'
[13] resourceURI ::= (see RFC1738)
[14] IDsymbol ::= (any legal XML name symbol)
The RDF:serialization element is a simple wrapper that marks the boundaries in an XML document.where the content is explicitly intended to be mappable into an RDF data model instance. RDF:assertions and RDF:resource contain the remaining elements that instatiate properties in the model instance. Each XML element E contained by an RDF:assertions or an RDF:resource results in the creation of a property (a triple that is an element of the formal set T), where:
The RDF:resource element creates an in-line resource. Typically such a resource will be a surrogate, or proxy, for some other real resource that does not have a recognizable URI. The idAttr on a resource element permits that resource to be the target of other assertions.
The resourceURI identifies the target resource; the resource to which all the assertions apply. The IDsymbol gives a name for this assertion block so that the block may be referred to elsewhere.
A property takes the form:
[15] property ::= '<' propName idAttr? '>' propValue '</' propName '>'
| '<' propName idRefAttr '/>'
[16] propName ::= name | namePrefix ':' name
[17] propValue ::= node | string
[18] name ::= (any legal XML name symbol)
[19] namePrefix ::= (any legal XML namespace prefix)
[20] string ::= (any XML text)
Within property, the resourceURI identifies the resource that is the value of this property. Strings must be well-formed XML; the usual XML content quoting and escaping mechanisms may be used if the string contains character sequences that violate the well-formedness rules.
It is recommended that property names always be qualified by the namespace prefix to unambiguously connect the property definition with the corresponding RDF schema.
[[This section to be completed]]
Assertions may be signed to facilitate decisions that require trust. Simple signatures include checksums or other assertions about independently verifiable characteristics of a resource. The simplest example of a signature is a statement that the associated assertions apply only to the version of the resource labeled with a given creation date. Stronger signatures will include cryptographic measures to increase the likelihood of detection of falsification of or inadvertent changes to the signed assertions or the resource(s) to which they apply.
With the core defined, we can construct and exchange directed graph models of arbitrary complexity. We could begin by saying very simple things, such as "John Smith is the Author of the document whose URL is http://www.bar.com/some.doc". This assertion can be modeled with the directed graph:
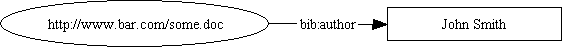
(We use a notation where Nodes are represented as ellipses, arcs as
arrows, and strings are given in rectangles.)
This small graph can be exchanged in the serialization syntax as:
<?namespace href="http://docs.r.us.com/bibliography-info" as="bib"?> <?namespace href="http://www.w3.org/schemas/rdf-schema" as="RDF"?> <RDF:serialization> <RDF:assertions href="http://www.bar.com/some.doc"> <bib:author>John Smith</bib:author> </RDF:assertions> </RDF:serialization>
We could create a more elaborate model in order to say additional things about John Smith, such as his contact information. We might construct the model:
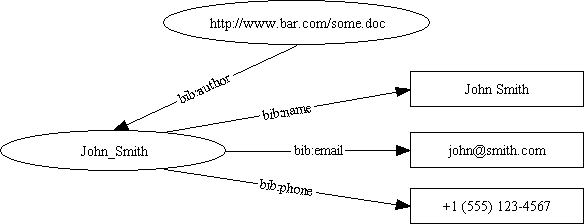
which could be exchanged using the XML serialization representation:
<?namespace href="http://docs.r.us.com/bibliography-info" as="bib"?> <?namespace href="http://www.w3.org/schemas/rdf-schema" as="RDF"?> <RDF:serialization> <RDF:assertions href="http://www.bar.com/some.doc"> <bib:author> <RDF:resource> <bib:name>John Smith</bib:name> <bib:email>john@smith.com</bib:email> <bib:phone>+1 (555) 123-4567</bib:phone> </RDF:resource> </bib:author> </RDF:assertions> </RDF:serialization>
The serialization above is equivalent to this second serialization:
<?namespace href="http://docs.r.us.com/bibliography-info" as="bib"?> <?namespace href="http://www.w3.org/schemas/rdf-schema" as="RDF"?> <RDF:serialization> <RDF:assertions href="http://www.bar.com/some.doc"> <bib:author href="#John_Smith"/> </RDF:assertions> </RDF:serialization> <RDF:resource id="John_Smith"> <bib:name>John Smith</bib:name> <bib:email>john@smith.com</bib:email> <bib:phone>+1 (555) 123-4567</bib:phone> </RDF:resource>
As an example of making a statement about a statement, consider the case of wanting to compute a digital signature on an RDF assertion. (We will assume that the signature is computed over a concrete XML rendition of the assertion rather than over an internal representation. The figure below shows a box containing a small graph. This is a convention to indicate that the XML content whose ID is foo is a concrete representation of the graph it contains.)
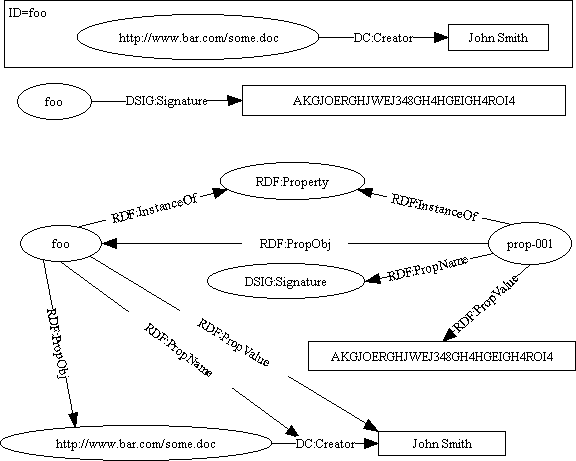
What we want to say in the model is expressed by the pair of graphs at the top of the figure - that we have an XML encoding of some assertion, and that there is some other XML content that is a digital signature over that encoding. If we care to delve into the details, we could build the model at the bottom of the image. Those models could also be expressed as:
<?namespace href="http://purl.org/DublinCore/RDFschema" as="DC"?> <?namespace href="http://www.w3.org/schemas/rdf-schema" as="RDF"?> <?namespace href="http://www.w3.org/schemas/DSig-schema" as="DSIG"?> <RDF:serialization> <RDF:assertions href="http://www.bar.com/some.doc" id="foo"> <DC:Creator>John Smith</DC:Creator> </RDF:assertions><RDF:assertions href="#foo"> <DSIG:Signature>AKGJOERGHJWEJ348GH4HGEIGH4ROI4</DSIG:Signature> </RDF:assertions> </RDF:serialization>
Also note that node labels such as "RDF:Property" are shorthand for a full URI such as "http://www.w3.org/schemas/rdf-schema#Property".
As an example of sequences, we might look at some of the works written by John Smith. Since John is rather prolific, we could use sequences to keep lists of his works sorted by publication date, or according to the alphabetical order of the subject of the article:
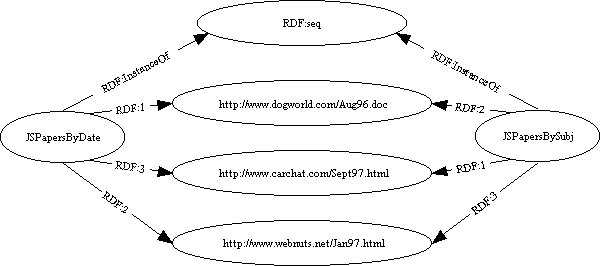
This model could be exchanged as:
<?namespace href="http://www.w3.org/schemas/rdf-schema" as="RDF"?> <RDF:serialization> <RDF:seq id="JSPapersByDate"> <RDF:li href="http://www.dogworld.com/Aug96.doc"/> <RDF:li href="http://www.carchat.com/Sept97.html"/> <RDF:li href="http://www.webnuts.net/Jan97.html"/> </RDF:seq><RDF:seq id="JSPapersBySubj"> <RDF:li href="http://www.carchat.com/Sept97.html"/> <RDF:li href="http://www.dogworld.com/Aug96./doc"/> <RDF:li href="http://www.webnuts.net/Jan97.html"/> </RDF:seq> </RDF:serialization>
The RDF data model intrinsically only supports binary relations. However, in this section we show how we can represent higher arity relations using just binary relations. As an example, consider the subject of one of John Smith's recent articles - library science. We could use the Dewey Decimal Code for library science to categorize that article. While the numeric code is the true Dewey value, few people can understand those codes. Therefore, the description of the Dewey categories has been translated into several different languages. In fact, Dewey Decimal codes are far from the only subject categorization scheme. So, we might want to define a "Subject" node that not only told us the subject of a paper, but also indicated the language and categorization scheme it came from. That might look like:
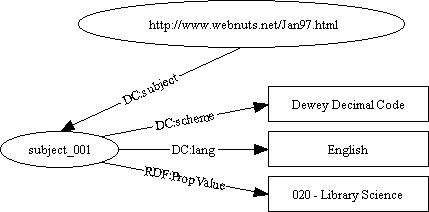
which could be exchanged as:
<?namespace href="http://purl.org/DublinCore/RDFschema" as="DC"?> <?namespace href="http://www.w3.org/schemas/rdf-schema" as="RDF"?> <RDF:serialization> <RDF:assertions href="http://www.webnuts.net/Jan97.html"> <DC:subject> <RDF:resource id="subject_001"> <DC:scheme>Dewey Decimal Code</DC:scheme> <DC:lang>English</DC:lang> <RDF:PropValue>020 - Library Science</RDF:PropValue> </RDF:resource> </DC:subject> </RDF:assertions> </RDF:serialization>
A common use of this higher-arity capability is when dealing with units of measure. A person's weight is not just a number like 94, it also requires us to specify the units on that number. In this case we might be using either pounds or kilograms. We could use a relationship with an additional arc to record the fact that John Smith is a rather strapping gentleman:
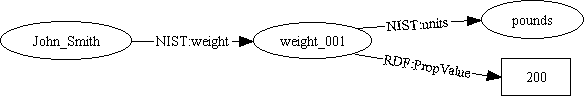
which can be exchanged as:
<?namespace href="http://www.nist.gov/RDFschema" as="NIST"?> <?namespace href="http://www.w3.org/schemas/rdf-schema" as="RDF"?> <RDF:serialization> <RDF:assertions href="John_Smith"> <NIST:weight> <RDF:resource id="weight_001"> <NIST:units href="#pounds"/> <RDF:PropValue>200</RDF:PropValue> </RDF:resource> </NIST:weight> </RDF:assertions> </RDF:serialization>
assuming the node "pounds" was defined elsewhere.
This material is non-normative, but believed necessary for an understanding of the RDF serialization syntax. It will be replaced by references to the appropriate sections of the XML specifications once they have been issued. The material here is our best understanding of the namespace proposal, but almost certainly differs from what the final result will be.
The XML-working group is currently developing a facility that will allow, at least, Generic Identifiers (tag names) to have a prefix which will make them unique and will prevent name clashes when developing documents that mix elements from different schemas. This facility allows a document's prolog to contain a set of Processing Instructions (PIs) of the form:
<?namespace href="some-uri" as="some-abbreviation"?>
for example
<?namespace href="http://www.w3.org/schemas/rdf-schema" as="RDF"?> <?namespace href="http://www.purl.org/DublinCore/schema" as="DC"?>
Elements in the document may then use generic identifiers of the form <RDF:assertions> or <DC:Title>. Those element names would expand to URIs such as http://www.w3.org/schemas/rdf-schema#assertions.
Note also that XML is case-sensitive.
Revision History:
2-October-1997: First public draft
1-October-1997: Edits in preparation for first public distribution
1-August-1997: First draft to Working Group
Last updated: $Date: 2017/10/02 11:00:56 $