Copyright © 1998 W3C (MIT, INRIA, Keio ), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply.
This is a W3C Working Draft for review by W3C members and other interested parties. It is a draft document and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to use W3C Working Drafts as reference material or to cite them as other than "work in progress". A list of current W3C technical reports can be found at http://www.w3.org/TR.
This document has been produced as part of the W3C HTTP-ng Activity. This is work in progress and does not imply endorsement by, or the consensus of, either W3C or members of the HTTP-ng Protocol Design Working Group. We expect the document to evolve as we get more data from the HTTP-NG Web Characterization Group describing the current state of the Web.
This document defines a simple model for what an HTTP-ng architecture might look like, along with a set of terms for referring to parts of it. This model and terms are drawn from the HTTP 1.1 work, the ILU work, and the PEP work.
This document is part of a suite of documents describing the HTTP-NG design and prototype implementation:
Please send comments on this specification to <www-http-ng-comments@w3.org>.
Remote or distributed applications typically have a defined interface;
this consists of a set of operations which participants in the application
invoke on other participants. These operations typically are defined in terms
of input parameters and output results; sometimes exceptional results,
or exceptions, are also specified for the operation. In standard Internet
usage, an application such as Telnet or FTP is described in a document which
specifies an abstract model of operation, and enumerates the operations by
describing the form of a message which conveys that operation when marshalled
onto an appropriate transport substrate. Some Internet standards define an
application framework, which is a set of general information that
applies to a family of applications, related by all using that framework.
The RFC 1831 for RPC is such a framework specification. Finally, some
specifications, such as HTTP, define both a framework, and a particular
application (the Web), which uses that framework. It does this by defining
an extensible system of messages in a request/response context, then defines
several specific messages (GET, HEAD,
POST, etc.) and the context of a distributed application that
uses them.
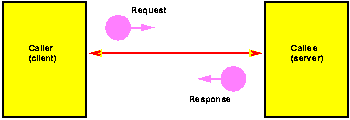
Figure 1a. Elements of a Distributed Application
Though there may be many participants or threads of control in the application, they conventionally engage in two-party interactions. These two parties can be categorized as the caller or client, which is the participant which invokes an operation, and the callee, or server, which is the participant implementing or responding to the operation. When there are many participants in the applications, the role each plays may shift continuously. These participants are said to reside in different compatibility domains; the distributed application serves as a bridge between these domains. There is some essential element which separates the domains; it is typically the fact that the participants are on different computers, but it may also be other factors such as that the two participants are operating under the aegis of different security principals, or are implemented in different programming languages.
Distributed object systems are application frameworks that try to simplify and optimize the definition and use of an application. They typically have an interface definition language (often called IDL), which make it easier to talk about the components of an interface. They often have standards for marshalling the parts of a message into binary forms, or for discovering resources, or for recovering from certain types of errors, or for exporting the interface defined in their IDL to a particular programming language for use in a larger program. This separation of concerns allows each part of the application framework to be small and cohesive, but allows the development of large applications.
Some distributed object systems use the procedure call as a metaphor of operation; these are called RPC systems. Others use a messaging model, and are typically called messaging systems. Most modern distributed object systems have support for both RPC and messaging.
An interface definition consists of a set of inter-related types, exceptions, and methods. Methods are packaged in object types, developed with a partitioning of them according to object-oriented methodologies. A callee is represented by an instance of an object type. Operations are invoked on the callee by calling one of its methods. If the caller of a method and the callee of the method exist in different compatibility domains, they are connected with a connection, which carries messages back and forth between the compatibility domains, and has an associated protocol and transport stack. The message is the basic unit of communication; the connection's protocol specifies the set of messages which can be sent, and their syntax; the connection's transport stack, which typically consists a series of individual transport elements, specifies how the messages are carried between the two domains. Most protocols define two distinguished messages, a request message, which invokes a service in the callee, and a response message, which provides a response about an invocation back to the caller, along with some other control messages used to synchronize state between the two domains. We typically distinguish between transport elements called transport filters, which modify the bits of message passing through them (encryption, compression, etc.) and other elements transport endpoints, which actually convey the message to a different compatibility domain (TCP/IP, UDP/IP, etc.).
An implementation of an object type is called a class. An implementation of one or more of the object types defined in an interface, along with whatever additional code is necessary to perform any ancillary tasks such as creating initial instances of a class, or registering instances with a name service, is called a module. A program typically consists of several modules, each of contains one or more classes which implement object types, either by dispatching messages to a module exported from another compatibility domain (classes which do this are called surrogate classes), or by directly performing the functionality of the object type (classes which do this are called true classes). Programs which tend to have many true classes and relatively few surrogate classes are typically called servers, and programs which have few true classes and relatively many surrogate classes are typically called clients; these terms should be used with caution, since they are only appropriate in a specific context. A server is typically made available by a publisher, which is the principal responsible for the services encapsulated in the true instances of object types provided by the module. The principal responsible for accessing the services provided by the publisher is sometimes known as the user.
Interfaces for applications are defined with a type system. This section describes the proposed type system for HTTP-ng. It consists of two kinds of types, primitive types and constructed types. Only two primitive types, or pre-defined types, are included, boolean and pickle. All other types are constructed from parameters and other types using constructors, like sequence types and record types.
All types have an associated universally unique identifier, called the type ID, which can be expressed as a URI. Type IDs from different UUID spaces may be mixed. An implementation of the type system should allow explicit identification of type IDs with types, but should also provide a default type ID for every type in a consistent and predictable fashion. [ We need to define the algorithm here. ]
The rules governing the syntax of identifiers are the same as for Standard C; that is, uppercase and lowercase alphabetic characters and digits from the ASCII character set, along with the underscore character, may be used, and the first character of the identifier must be an alphabetic character. Case is significant.
The single boolean type, the primitive type boolean, has exactly two
values, True and False.
An enumerated type is an abstract type the values of which are explicitly specified. It is specified with one parameter, a set of values, specified as identifiers. Enumerated types are not numeric types, and the values of an enumerated type do not have intrinsic numeric values associated with them; however, some programming languages may use numeric types to represent enumerated types.
The type system includes two different kinds of numeric types, fixed-point and floating-point. All numeric types are constructed; that is, there are no pre-defined "primitive" integer or floating-point types.
A fixed-point type is defined with three parameters: a denominator, a maximum numerator value, and a minimum numerator value. These define a series of rational values which make up the allowable values of that fixed-point type. The numerator and denominator are integer values; the denominator is either a positive integer value greater than zero, or the reciprocal of a positive integer value greater than zero. Each value of a fixed-point type abstractly exists as a rational number with a numerator in the range specified for numerators, and a denominator of the specified denominator value. For example, one could define a fixed-point type which would cover the 16-bit unsigned integer space with a denominator of one (all integer types have denominators of one), a maximum numerator of 65535 and a minimum numerator of zero. One could define a fixed-point type `dollars' for business purposes with a denominator of 100 (two decimal places for `cents'), a maximum numerator of 100000000 (1 million dollars) and a minimum numerator of -100000000 (1 million dollars). There are no limits on the sizes of denominators, maximum numerators, or minimum numerators.
We use this approach, instead of specifying a procrustean flock of predefined integer types as in DCOM or CORBA, to simplify the underlying system in several ways.
Floating-point types are specified with eight parameters:
For instance, the floating point type usually described as IEEE 32-bit floating-point has the parameters significand-size=24, exponent-base=2, maximum-exponent-value=127, minimum-exponent-value=-126, has-Not-A-Number=TRUE, has-Infinity=TRUE, denormalized-values-allowed=TRUE, and has-signed-zero=TRUE; the floating point type usually described as IEEE 64-bit floating-point has the parameters significand-size=53, exponent-base=2, maximum-exponent-value=1023, minimum-exponent-value=-1022, has-Not-A-Number=TRUE, has-Infinity=TRUE, denormalized-values-allowed=TRUE, and has-signed-zero=TRUE. We expect that interface description languages for the HTTP-ng type system will provide shorthand notation for certain floating-point type patterns, such as those corresponding to IEEE single and double precision floating point.
We use this approach because CORBA and similar systems have a problem in that they have no way to represent the variety of floating point numbers available, particularly the different variants of IEEE `extended'. In addition, this system allows representation of older floating-point types still in wide circulation, such as IBM, VAX, and CRAY floating-point, in an simple fashion.
String types are defined with two parameters: the maximum length
in bytes of the string values, and the language [1] used in the string. If
no language is specified, the language defaults to the Internet default language
"i-default". The maximum length must be less than or equal to
0x7FFFFFFE, or it may also be omitted, in which case a maximum length of
0x7FFFFFFE (2^31-2) is used. The character set (or sets) used in the string
is that identified by the string's language. The codeset used in representations
of the string is not specified at this level. This type system does not have
any representation for individual characters or character codes; integer
types should be used for that purpose.
[ Note that there is no such thing as a "NULL string", as occurs in C or C++. However, a similar type can be constructed with the optional type constructor, using a string type as the base type. ]
Sequence types are variable-length one-dimensional arrays of some other type.
They are defined with two parameters: the base type of the sequence,
and optionally a maximum number of values in the sequence, which must be
a value less than or equal to 0x7FFFFFFE. If no maximum length
is specified, a default maximum length of 0x7FFFFFFE is assumed.
Array types are fixed-length multi-dimensional arrays of some other type.
They are defined with two parameters: the base type of the sequence,
and a sequence of dimensions, each of which is an integer value less than
or equal to 0x7FFFFFFE. Arrays are in row-major order.
A record type is defined with a single parameter, a sequence of fields. Each field is specified with an identifier, unique within the scope of the record type, and a type.
Union types are defined with a single parameter, a set of fields. Each field is specified with an identifier, unique within the scope of the union type, and a type for the field. The same type may be used multiple times for different fields of the union. The value of a union type with N fields consists of a single value of the type of one of the fields, and an unsigned integer value in the range [0..N-1] identifying which field is represented.
A special kind of union type that can hold a value of any other type is known as the pickle type.
Reference types are specifically designed to support recursion through the type system, and must be mapped to a pointer type of some time in those programming languages which distinguish between value types and pointer types. Two kinds of reference types are provided, optional types and aliased types. Each use of a reference type constructor adds another level of indirection.
[ These types effectively cover the practical uses of reference types in the CORBA objects-by-value spec, the Java RMI spec, and the DCE RPC / DCOM system. ]
Optional types are defined with a single parameter, another type, called the base type of the optional type. A value of an optional type may be either NIL or a value of its base type. This type allows the description of data structures like binary trees.
Aliased types are defined with a single parameter, another type, called the base type of the aliased type. Aliased types are distinguished in that multiple references to the same value of an aliased type in a single `scope' will be passed between compatibility domains as a single value. This avoids the problem in some type systems of converting graph data structures to trees when transferring them between compatibility domains. It is important to note that an aliased type is not optional; that is, NIL is not a valid value for an instance of an aliased type unless it is a valid value for the base type of the aliased type.
The scope of an aliased type varies depending on its use. When a value of an aliased type is being sent as an input or output parameter in a method call, the scope of the type is the whole message in which the value is being sent; that is, the invocation or result of the method call. When it is being pickled, the scope of the value type is the pickle.
[If the base of an alias type is an optional type, consider what happens with a particular value where the optional part is NIL; is the alias to the NIL also NIL, or a particular "pointer" to another (actually NIL) pointer?]
In the HTTP-ng type system, operations are modeled as method calls on an instance of an object type which supports that method. There are two kinds of object types, local and remote. Instances of remote object types have a global identity, and are always passed between compatibility domains by reference; the original object value is called the true instance, and references to that true instance are called surrogate instances. Passed instances of any remote object type are always surrogate instances, except in the compatibility domain of the true instance, where it will be the true instance. Instances of local object types have no global identity, and are always passed between compatibility domains by copying the state of the local instance to the new compatibility domain, where a new instance of that object type (or a subtype of the object type) is created from the state. A local instance in one compatibility domain and copy of that local instance in a different compatibility domain have no explicit association after the copy has been made. The behavior of a local object type must be provided locally, but it may be provided statically at link time, or dynamically at runtime via dynamic loading of class code, as is done in Java RMI. The HTTP-ng system does not define any particular system for dynamic loading of behavior.
Both local and remote object types are defined by specifying three parameters: a sequence of supertypes, a sequence of methods, and the state of the object type. Note that the ordering of the elements of each of these parameters is significant. Any of these parameters may be empty.
[ Note that there is no such thing as a "NIL object", as occurs in the CORBA system. However, an equivalent construct may be obtained where necessary by using the optional type constructor, using an object type as the base type. ]
Each object type may have one or more object types as supertypes. An object type with supertypes is said to inherit the methods and state of its supertypes, which means that it provides all of the methods provided by any of its supertypes, and any of their supertypes, and so forth. An object type may occur more than once in the supertype inheritance graph of an object type. Note that the inheritance provided in this model is that of interface inheritance. In particular, it does not guarantee or prohibit polymorphic dispatching of methods.
Object types may be sealed. A sealed object type may not be used as a supertype for another object type.
A method is a way of invoking an operation on an instance of an object type. Each HTTP-ng method has a three required parameters: a synchronization attribute which may either be synchronous or asynchronous; an identifier, unique within the scope of the object type, called the method name; and an invocation, which is specified as a sequence of named and typed input parameters. Synchronous methods may also have additional parameters: a normal result, which is specified as a sequence of named and typed output parameters, and zero or more exceptional results, each specified as a sequence of named and typed output parameters. Exceptional results should only be used to describe results that occur infrequently, as the overhead of handling exceptional results in most programming languages that support them is higher than the overhead of handling a normal result. Input parameters and output parameters are each specified with an identifier, unique within the scope of the method, and a type. [ Note additional restriction on the names of exception parameters. ]
Asynchronous methods transfer the invocation parameters to the compatibility domain of the true instance, and invoke the operation. The caller-side control flow for an asynchronous method returns to the caller of an asynchronous method after the message has been handed to a reliable transport mechanism for transfer to the compatibility domain of the true instance; the remote method itself may not be executed for an arbitrary length of time after that return. Asynchronous methods may be thought of as messages.
Synchronous methods transfer the invocation parameters of the method to the compatibility domain of the true instance, where the method is invoked as a local method on that instance. The result from that invocation, normal or exceptional, is transferred back to the caller's compatibility domain, if different, and returned as the result of the method.
[ Do we need some set of `standard' exceptions? If so, what are they? A small starting list might be:
]
Each object type may have state associated with it. The state of an object type is specified as a sequence of attributes, where each attribute has an identifier unique within the scope of the object type, and an associated type. When an instance of this object type is passed between compatibility domains, the values of these attributes are passed. This is the normal way of passing the state of a local object type. [ TBD - for remote object types, the state may act as the initial values for surrogate instance caching of remote object state, or as a way of passing immutable metadata about the instance with the object reference.]
Attribures may also be marked as public or private. This has no effect on their handling at the lower levels of the system, but may influence the way in which mappings to programming languages deal with them. For example, a programming language object type might provide public accessors for public attributes, but not for private attributes.
All remote object types must inherit directly or indirectly from the object type HTTP-ng.RemoteObjectBase.
INTERFACE HTTP-ng BRAND "http-ng.w3.org";
...
TYPE UUIDString = STRING LANGUAGE "i-default"
TYPEID "w3ngid:www.w3.org/HTTP-ng/UUIDString";
TYPE TypeIDTreeNode = RECORD
type-id : UUIDString,
"supertypes" : InheritanceHierarchy
END TYPEID "w3ngid:www.w3.org/HTTP-ng/TypeIDTreeNode";
TYPE TypeIDTreeNodeRef = ALIASED REFERENCE TypeIDTreeNode
TYPEID "w3ngid:www.w3.org/HTTP-ng/TypeIDTreeNodeRef";
TYPE InheritanceHierarchy = SEQUENCE OF TypeIDTreeNodeRef
TYPEID "w3ngid:www.w3.org/HTTP-ng/InheritanceHierarchy";
TYPE RemoteObjectBase = OBJECT
TYPEID "w3ngid:www.w3.org/HTTP-ng/RemoteObjectBase"
METHODS
GetTypeHierarchy () : InheritanceHierarchy
"Returns the type ID hierarchy for the object"
END;
...
A simple form of garbage collection is defined for HTTP-ng objects. If an object type inherits from HTTP-ng.GCCollectibleObjectBase, a module that implements objects of that type expects clients holding surrogate instances to register with it, passing an instance of a callback object. When a client finishes with the surrogate, the client unregisters itself. Thus the server may maintain a list of clients that hold surrogate instances. If no client is registered for an object, and the object has been dormant (had no methods called on it by a client from a different compatibility domain) for a period of time T1, the module may feel free to garbage collect the true instance. T1 is determined both by human concerns and network performance: T1 is set long enough to allow useful debugging of a client, and longer than the typical transmission delay between all participants in a program.
To deal with possible failure of a client process, we introduce another time-out parameter. If an instance with registered clients has been dormant for a period of time T2, the server uses the callback instance associated with each client to see if the client still exists. If the client cannot be contacted for the callback, the server may remove it from the list of registered clients for that instance.
Object types which participate in distributed garbage collection must inherit from HTTP-ng.GCCollectibleObjectBase.
INTERFACE HTTP-ng BRAND "http-ng.w3.org";
...
TYPE Seconds = FIXED-POINT DENOMINATOR=1
MIN-NUMERATOR=0 MAX-NUMERATOR=0xFFFFFFFF
TYPEID "w3ngid:www.w3.org/HTTP-ng/Seconds";
TYPE GCCallBackObject = OBJECT SUPERTYPES RemoteObjectBase END
TYPEID "w3ngid:www.w3.org/HTTP-ng/GCCallBackObject"
METHODS
StillInterested (obj : GCCollectibleObjectBase) : BOOLEAN
"Should return TRUE if the callback object is still interested in
using the remote object 'obj', FALSE otherwise. An error return
is counted as a FALSE return."
END;
TYPE GCCollectibleObjectBase = OBJECT SUPERTYPES RemoteObjectBase END
TYPEID "w3ngid:www.w3.org/HTTP-ng/GCCollectibleObjectBase"
METHODS
RegisterGCInterest (user : GCCallBackObject)
"Indicates that the caller, indicated by the 'user' parameter, is
interested in using the object, and should be considered a reference
for the purposes of distributed garbage collection. This may be
called multiple times with the same 'user' parameter, but only one
reference per distinct 'user' parameter will be registered.",
UnregisterGCInterest (user : GCCallBackObject)
"Indicates that the caller, indicated by the 'user' parameter, is
no longer interested in using the object, and should no longer be
considered a reference for the purposes of distributed garbage
collection. It is not an error to call this for objects which have
not previously registered interest.",
GetTimeoutParameters(OUT t1 : Seconds, OUT t2 : Seconds)
"Returns the T1 and T2 garbage collection parameters used by the
server.",
Ping()
"Can be used by surrogate users of the instance to refresh the T1
timeout of the instance, and prevent server-side outcalls to the
callback object."
END;
...
Our current thinking is that a typical HTTP-ng application would be layered as described in Section 1. The lowest layer, the transport layer, would typically (but not necessarily always) consist of of a MUX transport filter over a TCP/IP transport endpoint. The MUX layer would be used to provide multiple connections over a single TCP/IP connection, bi-directional use of the TCP/IP connection for callbacks, and message-marking for the higher layers. We call the MUX connection a session to distinguish it from TCP/IP connections. Similarly, we call the MUX port (the thing to which MUX connections are made, like a TCP/IP port), a channel, to similarly distinguish it. The set of MUX channels which can be connected to over a TCP/IP connection to a particular IP host machine is called a MUX endpoint. Typically, this endpoint identifies a particular address space or process on an IP host. Note that a single MUX endpoint (and all the MUX channels at that endpoint) may be available via a number of different TCP ports. This means that the TCP port used in the transport stack does not explicitly identify a set of MUX channels; rather, the set of MUX channels are identified by the MUX endpoint.
The next layer, the RPC layer, would typically consist an object-oriented RPC protocol, maximizing use of protocol features found to be successful in existing Internet protocols. The RPC layer is a simple messaging layer - it should not provide any application-specific services like security or caching, or any other application layer functionality. This belongs in the upper layers. It would provide an extensible and regular mechanism for forming and handling messages described by application-level interfaces without knowledge of semantic information that is application-specific. It would provide a distributed garbage-collection facility which could be used for automatic management of application objects. This layer would also have associated machinery which would allow automated uses of interface descriptions written in an interface description language, such as stub-code and implementation-skeleton generation. This layer may use a number of different, but equivalent, protocols; we expect the major one will be an efficient binary wire protocol.
The third and highest layer is the application layer. This layer would vary from application to application. For example, The Classic Web Application (TCWA) would have a different layer here than the WebDAV application, though they may share some common part. The HTTP-ng architecture would allow multiple applications to co-exist at this level, and would provide a mechanism to add new applications easily without disturbing existing applications.
Figure 2a illustrates the general arrangement of layers an HTTP-ng-enabled program. Each application would contain application-specific code to use the classes of interfaces it imports, and to provide the functionality of classes it exports. Any number of different applications can be supported on a common base. Note that multiple protocols (message formats) can co-exist simultaneously; note that several different transport chains can share a single TCP/IP port or connection by using the MUX protocol; note that additional processing of messages, such as compression, can be performed by using an appropriate transport chain in the transport layer.
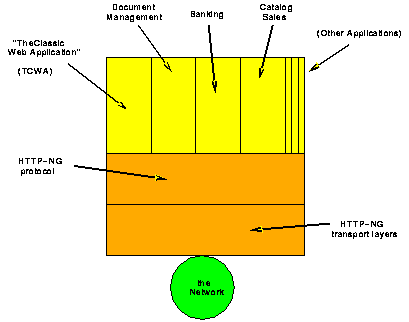
Figure 2a. Layers of a Sample Program
In an application like the Web, there would be at least two participants, typically one or more web browsers, and one or more web servers. A web browser would connect to a web server as shown in figure 2b:
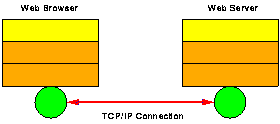
Figure 2b. The Web Application Participants
At this gross level, the two participants seem similar, but if examined more closely, we can see differences corresponding to the essential client-like behavior of the browser and server-like behavior of the, er, server. For instance, the browser tends to have more surrogate classes for the object types defined in the Web interface, and the browser tends to have more true classes. The server may also have more different kinds of protocols and transport elements, in order to cope with a wider variety of possible clients. Figure 2c illustrates a possible architecture of a web server, while Figure 2d shows a possible, somewhat stripped-down, architecture of a web browser.
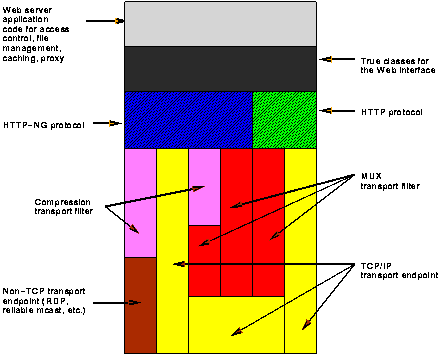
Figure 2c. A Web Server
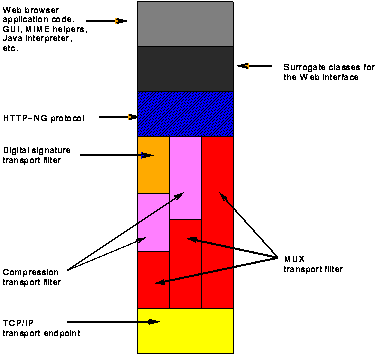
Figure 2d. A Web Browser
Note that the capabilities of the example server and browser architectures are different. The server speaks both HTTP and HTTP-ng; the browser speaks only HTTP-ng. The server can support HTTP-ng messages over a plain TCP/IP transport, while the browser expects every server to have the MUX protocol. The browser is capable of handling digitally signed documents, while this server is unable to hand them out. Both client and server can use compression on their message streams. Of course, many other possible combinations of transport filters and protocols are possible on both sides. A proxy server, for instance, would have all the client side functionality, as well as the server side functionality.
[1] RFC 2277, IETF Policy on Character Sets and Languages; H. Alvestrand, January 1998.
We are using the ILU system from Xerox PARC in some of the HTTP-ng prototyping. Generally the ILU type system is a superset of the HTTP-ng type system. The following mapping should be used in expressing the NG type system in terms of ILU's Interface Specification Language:
BOOLEAN
FIXED-POINT (C only)
SHORT
REAL
REAL
LONG REAL
ENUMERATION constructor --
note that ISL allows specification of integer values for enumeration values,
which should not be used
ILUSTRING constructor -- note that
the ILUSTRING constructor allows the explicit specification
of a charset, which should not be used
SEQUENCE constructor -- note
that the maximum length must be specified, as the ISL default maximum length
is different from the HTTP-ng default maximum length
ARRAY constructor
RECORD constructor
UNION constructor -- note
that the ISL constructor is considerably more complex; do not use that extra
complexity
PICKLE
OPTIONAL constructor
OBJECT constructor -- use
ASYNCHRONOUS qualifier on methods to get asynchronous methods,
the default is synchronous; define exceptions separately in ISL and use them
in method definitions; local objects and object type state are not yet supported
in ISL