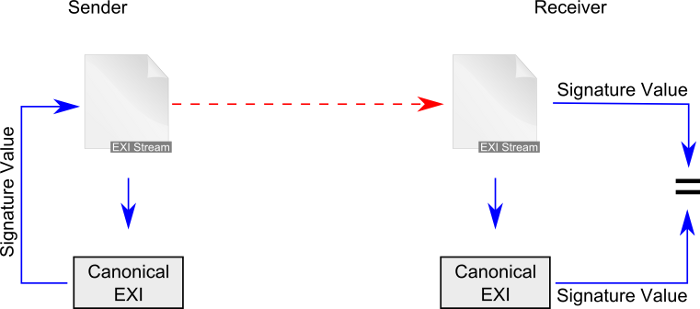
The subsequently described EXI Canonicalization steps and algorithms expect as input
EXI events
(e.g., SE, NS, and AT events). The input MUST be a sequence of EXI events and
produces as output a canonicalized EXI stream. Following the presented algorithms
guarantees that logically-identical documents produce identical serialized EXI Body
stream representations (assuming the same EXI coding options).
2.1 EXI Alignment Options and Streams
EXI provides four alignment options, namely bit-packed,
byte-alignment, pre-compression, and
compression.
The canonicalized EXI form is the resulting EXI stream following the rules
defined in this document. When the alignment option compression is
set for an EXI stream, its canonical form is computed as if the EXI stream was
encoded using the alignment option pre-compression.
EXI processors may make use of padding bits, for example to make the length of
the EXI stream byte-aligned. In a Canonical EXI stream padding bits, if
necessary, MUST always be represented as a sequence of 0 (zero) bits.
Each EXI stream begins with an EXI Header but it MUST NOT be taken into account when building
the canonical EXI form.
2.2 EXI Event Selection
EXI processors represent a given event such as a start element or an attribute
by serializing an event code first, followed by the according event content.
Each event code is represented by a sequence of 1 to 3 parts that uniquely
identifies an event.
In situations where an EXI processor disposes of more than one possible event
(-code) the canonical EXI form prescribes which event and respectively which
event code has to be chosen.
That said, it is not uncommon that an EXI processors has certain flexibility in
choosing the appropriate EXI grammar production, or respectively the appropriate
event. Moreover, the availability of grammar productions is subject to the
convention used by the application. A prominent convention is the [Efficient XML Interchange (EXI) Profile], which is more restrictive in regard to which production
is usable than the [Efficient XML Interchange (EXI) Format 1.0] specification.
After excluding productions that are not usable according to the convention in
use a canonical EXI processor MUST also follow the subsequent order:
Use the event with the most accurate event content first
For Start Element events the order is as follows:
SE( qname )
SE ( uri : * )
SE ( * )
For Attribute events the order is as follows:
AT( qname )
AT ( uri : * )
AT ( * )
IF the accurateness is the same use the event with the least event code
parts
The subsequently following example depicts the available productions for an
example DocContent grammar. From the perspective of the [Efficient XML Interchange (EXI) Format 1.0]
specification it is perfectly fine to match a start element "A" with event code
0 (zero) or 4 (four). A canonical EXI form prescribes event code 0 (zero).
|
|---|
| Syntax | Event Code |
|---|
| DocContent |
| | SE ("A") DocEnd | 0 |
| | SE ("B") DocEnd | 1 |
| | SE ("C") DocEnd | 2 |
| | SE ("D") DocEnd | 3 |
| | SE(*) DocEnd | 4 |
| | DT DocContent | 5.0 |
| | CM DocContent | 5.1.0 |
| | PI DocContent | 5.1.1 |
2.3 EXI Stream Order
In general, a canonical EXI processor SHALL NOT change the order of the EXI input
sequence. The only exceptions to this statement are sequences of attributes
and/or namespace declarations.
The EXI specification defines that namespace (NS) and attribute (AT) events
associated with a given element occur directly after the start element (SE)
event in the following order:
| NS | NS | ... | NS | AT (xsi:type) | AT (xsi:nil) | AT | AT | ... | AT |
In addition, canonical EXI specifies that namespace declarations for a given
element MUST be sorted lexicographically according to the NS prefix. Further,
canonical EXI strictly requires that an xsi:type or an xsi:nil attribute MUST
occur before other AT events even if it does not impact grammar selection.
Moreover, attributes other than xsi:type and xsi:nil for a given element MUST be
sorted lexicographically, first by qname local-name then by qname uri.
Note:
Optimizations such as pruning insignificant xsi:type values
(e.g., xsi:type="xsd:string" for string values) or
insignificant xsi:nil values (e.g.,
xsi:nil="false") is prohibited for a Canonical EXI
processor.
2.4 EXI Datatypes
This section describes the built-in EXI datatype representations used for
representing content items in canonical EXI streams.
A value content item that can be represented by the associated EXI datatype MUST
be represented with the associated datatype representation. When the strict option
is false, attributes and character events that cannot be represented by the
associated EXI datatype representations (e.g., schema-invalid values) MUST use
the additional untyped AT and CH terminal symbols.
Note:
A Canonical EXI processor MUST NOT account for XML schema validity (just like
an EXI processor). The verification solely bases on EXI grammars and EXI
datatypes.
When the
Preserve.lexicalValues option is true, individual items are
represented as String. Each value MUST be represented as a String with the
associated restricted character set, if such a set is defined for the associated
datatype representation (see Restricted
Character Sets for Built-in EXI Datatype Representations). String
content items associated with a restricted character MUST also follow the rules
described in 2.4.6 Restricted Character Sets.
When the
Preserve.lexicalValues option is false, a value content item MUST
be represented with the associated datatype representation. The following
sub-sections describe the Canonical EXI behavior for datatypes that otherwise
may not lead to a uniquely defined representation.
Canonical EXI processors SHOULD support string-based EXI input stream values that
according to Canonical EXI must be represented with an EXI datatype other than
String (e.g., the value "0.1230" typed as String that according to Canonical EXI
Float would be mantissa 123 and exponent -3). However, due to increased code
footprint and processing complexity, Canonical EXI processors MUST support only
EXI input streams that use the according datatype representation already. Be
aware of this restriction when passing EXI streams to a recipient that is
required to create the canonical EXI form.
2.4.1 Unsigned Integer
The EXI specification defines that the Unsigned
Integer datatype representation supports unsigned integer
numbers of arbitrary magnitude. EXI processors SHOULD support arbitrarily
large Unsigned Integer values. EXI processors MUST support Unsigned Integer
values less than 2147483648.
Canonical EXI processors MUST use the Unsigned Integer datatype
representation even if a value goes beyond the value 2147483647.
2.4.2 Enumeration
The EXI
Enumeration assigns to each item an unsigned integer value
that corresponds to its ordinal position in the enumeration in schema-order
starting with position zero. When there is more than one item that
represents the same value in the enumeration, the value MUST be represented
by using the first ordinal position that represents the value.
2.4.3 Float
The EXI
Float datatype uses two consecutive EXI Integers.
The first Integer represents the mantissa of the floating point number and
the second Integer represents the base-10 exponent of the floating point
number.
The canonical EXI Float MUST respect the following constraints.
A mantissa value of -0 MUST be changed to 0. If the mantissa is 0,
then the exponent MUST be 0. If the mantissa is not 0, mantissas
MUST have no trailing zeros.
An exponent value of -0 MUST be changed to 0.
Given an EXI Float value that consists of one integer representing its
mantissa and the other integer representing its exponent, Canonical EXI
processors MUST find an equivalent canonical EXI Float that satisfies the
above constraints, where the rules of determining equivalence is described
below.
Two floats A and B each denoted as (mantissa, exponent) pair of (mA, eA) and
(mB, eB) where eA >= eB are equivalent under the following circumstances.
Both mantissa and exponent are the same between the two floats.
Otherwise, if two exponents are different (i.e. eA > eB), substitute
A with A2 where A2 has exponent eB and mantissa mA *
10(eA-eB). If A2 and B are equivalent per the rule 1
above, A and B are equivalent.
The appendix section A.2 EXI Floats depicts one example
algorithm for finding the canonical EXI Float that is equivalent to a given
EXI Float value.
2.4.5 Strings and String Table
A String value MUST be represented as string value hit if possible. Unless
the convention used by the application dictates differently (e.g., EXI
Profile parameter localValuePartitions set to "0"). EXI processors MUST
first try to represent the string value as local hit and only when this is
not successful as global value hit.
Note:
A String value miss MAY also need to follow the rules described in
2.4.6 Restricted Character Sets according to the given restricted character
set, if available.
Note that a Canonical EXI processor MUST also respect the XML schema
whiteSpace facet, if available.
2.4.6 Restricted Character Sets
Restricted
Character Sets in EXI enable to restrict the characters of
the string datatype. The canonical representation dictates that characters
from the restricted character set MUST use the according n-bit
Unsigned Integer. Hence, only characters that are not in the set SHALL be
represented by the n-bit Unsigned Integer N followed by the
Unicode code point of the character represented as an Unsigned Integer.
2.4.7 Datatype Representation Map
The EXI option datatypeRepresentationMap may specify an alternate set of
datatype representations for typed values in the EXI body stream. This
specification does not define any canonicalization rules for alternate
representations. Other specifications and/or groups making use of this
feature MAY describe a canonical form.