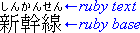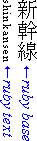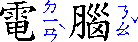“Ruby” are short runs of text alongside the
base text, typically used in East Asian documents to indicate
pronunciation or to provide a short annotation. This module describes the
rendering model and formatting controls related to displaying ruby
annotations in CSS. CSS is
a language for describing the rendering of structured documents (such as
HTML and XML) on screen, on paper, in speech, etc.
Status of this document
This section describes the status of this document at the time of
its publication. Other documents may supersede this document. A list of
current W3C publications and the latest revision of this technical report
can be found in the W3C technical reports
index at http://www.w3.org/TR/.
Publication as a Working Draft does not imply endorsement by the W3C
Membership. This is a draft document and may be updated, replaced or
obsoleted by other documents at any time. It is inappropriate to cite this
document as other than work in progress.
The (archived) public
mailing list www-style@w3.org (see
instructions) is preferred
for discussion of this specification. When sending e-mail, please put the
text “css3-ruby” in the subject, preferably like this:
“[css3-ruby] …summary of comment…”
This module extends the inline box model of CSS Level 2 [CSS21] to support ruby.
None of the properties in this module apply to the
::first-line or ::first-letter pseudo-elements.
1.2. Values
This specification follows the CSS property
definition conventions from [CSS21]. Value types not defined in
this specification are defined in CSS Level 2 Revision 1 [CSS21]. Other CSS
modules may expand the definitions of these value types: for example [CSS3VAL], when
combined with this module, expands the definition of the
<length> value type as used in this specification.
In addition to the property-specific values listed in their definitions,
all properties defined in this specification also accept the inherit
keyword as their property value. For readability it has not been repeated
explicitly.
1.3. Diagram
conventions
Many typographical conventions in East Asian typography depend on
whether the character rendered is wide (CJK) or narrow (non-CJK). There
are a number of illustrations in this document for which the following
legend is used:
Wide-cell glyph (e.g. Han) that is the nth character in the
text run. They are typically sized to 50% when used as annotations.
Narrow-cell glyph (e.g. Roman) which is the nth glyph in
the text run.
The orientation which the above symbols assume in the diagrams
corresponds to the orientation that the glyphs they represent are intended
to assume when rendered by the user agent. Spacing between these
characters in the diagrams is incidental, unless intentionally changed to
make a point.
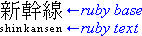
1.4. What is ruby?
Ruby is the commonly-used name for a run of text that
appears alongside another run of text (referred to as the “base”) and
serves as an annotation or a pronunciation guide associated with that run
of text.
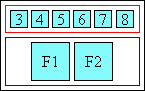
The following figures show two examples of Ruby, a simple case and one
with more complicated structure.
In this first example, a single annotation is used to annotate the base
text.
Example of ruby used in Japanese (simple case)
In Japanese typography, this case is sometimes called taigo ruby or group-ruby (per-word ruby), because the
annotation as a whole is associated with multi-character word (as a
whole).
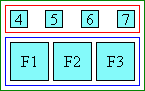
In this second example, two levels of annotations are attached to a
base sequence: the hiragana characters on top refer to the pronunciation
of each of the base kanji characters, while the words “Keio” and
“University” on the bottom are annotations describing the English
translation.
Complex ruby with annotation text over and under the
base characters
Notice that to allow correct association between the hiragana
characters and their corresponding Kanji base characters, the spacing
between these Kanji characters is adjusted. (This happens around the
fourth Kanji character in the figure above.) To avoid variable spacing
between the Kanji characters in the example above the hiragana
annotations can be styled as a collapsed annotation, which will
look more like the group-ruby example earlier. However because the
base-annotation pairings are recorded in the ruby structure, if the text
breaks across lines, the annotation characters will stay correctly paired
with their respective base characters.
Ruby formatting as used in Japanese is
described in JIS X-4051 [JIS4051] (in Japanese) and in
Requirements for Japanese Text Layout [JLREQ] (in English and Japanese)]. In
HTML, ruby structure and markup to represent it is described in the Ruby
Markup Extension specification. This module describes the CSS rendering
model and formatting controls relevant to ruby layout of such markup.
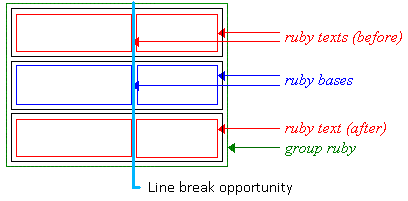
2. Ruby Formatting Model
The CSS ruby model is based on the HTML Ruby Markup Extension
and XHTML Ruby Annotation
Recommendation[RUBY]. In this model, a ruby structure
consists of one or more ruby base elements
representing the base (annotated) text, associated with one or more levels
of ruby annotation elements representing the
annotations. The structure of ruby is similar to that of a table: there
are “rows” (the base text level, each annotation level) and
“columns” (each ruby base and its
corresponding ruby annotations).
Consecutive bases and annotations are grouped together into ruby segments. Within a ruby segment, a ruby annotation may span multiple
ruby bases.
In HTML, a single <ruby> element may
contain multiple ruby segments. (In
the XHTML Ruby model, a single <ruby> element can only
contain one ruby segment.)
2.1. Ruby-specific ‘display’ property values
For document languages (such as XML applications) that do not have
pre-defined ruby elements, authors must map document language elements to
ruby elements; this is done with the ‘display’ property.
Specifies that an element generates a ruby container box.
(Corresponds to HTML/XHTML <ruby> elements.)
‘ruby-base’
Specifies that an element generates a ruby base box. (Corresponds to
HTML/XHTML <rb> elements.)
‘ruby-text’
Specifies that an element generates a ruby annotation box.
(Corresponds to HTML/XHTML <rt> elements.)
‘ruby-base-container’
Specifies that an element generates a ruby base container
box. (Corresponds to XHTML <rbc> elements;
always implied in HTML.)
‘ruby-text-container’
Specifies that an element generates a ruby
annotation container box. (Corresponds to HTML/XHTML
<ruby> elements.)
2.2. Anonymous Ruby Box
Generation
The CSS model does not require that the document language include
elements that correspond to each of these components. Missing parts of the
structure are implied through the anonymous box generation rules similar to
those used to normalize tables. [CSS21]
Any in-flow block-level boxes directly contained by a ruby container, ruby base container, ruby annotation
container, ruby base box, or
ruby annotation box are forced
to be inline-level boxes, and their ‘display’ value computed accordingly. For example,
the ‘display’ property of an in-flow
element with ‘display: block’ parented by an
element with ‘display: ruby-text’ computes to
‘inline-block’. This computation occurs after
any intermediary anonymous-box fixup (such as that required by internal
table elements).
At this point, all ruby layout structures are properly parented, and the
UA can start to associate bases with their annotations.
Note that the UA is not required to create any of these
anonymous boxes in its internal structures, as long as pairing and layout
behaves as if they existed.
2.3. Ruby Pairing and Annotation
Levels
Within a ruby structure, each ruby
base is associated with ruby
annotations and vice versa. A ruby
base can be associated with at most one ruby annotation per annotation
level. If there are multiple annotation levels, it can therefore be
associated with multiple ruby
annotations. A ruby
annotation is associated with one or more ruby bases; annotations can span multiple
bases.
Each ruby annotation
containers in a ruby segment represents one level of annotation: the first
one represents the first level of annotation, the second one represents
the second level of annotation, and so on.
If an implementation supports ruby markup with explicit spanning (e.g.
XHTML Complex Ruby Annotations), it must adjust the pairing rules to
pair spanning annotations to multiple bases appropriately.
A this point, ruby “columns” are defined, each represented by a
single ruby base and associated with
one ruby annotation (possibly an
empty, anonymous one) from each annotation
level.
Using nested ruby containers
thus allows the representation of complex spanning relationships.
This has to be Level 1 because HTML5 allows it, so we have
to handle it. Yay HTML5.
2.4. Autohiding Annotations
If a ruby annotation has the
exact same text content as its base, it is hidden. Hiding a
ruby annotation does not affect
annotation pairing or the block-axis positioning of boxes in other levels. However the hidden
annotation is not visible, and it has no impact on layout other
than to separate adjacent sequences of ruby annotation boxes within its
level, as if they belonged to separate segments and the hidden annotation’s base were not a ruby base but an intervening inline.
This is to allow correct inlined display of annotations for Japanese
words that are a mix of kanji and hirangana. For example, the word
振り仮名 should be inlined as
However, when displayed as ruby, the “り” should be hidden
Hiragana ruby for 振り仮名
Future levels of CSS Ruby may add controls for this, but in
this level it is always forced.
The content comparison for this auto-hiding behavior takes place prior
to white space collapsing and ignores elements (considers only the
textContent of the boxes).
Is before or after white space collapsing easier? We should
do whatever is easier, as it really doesn't matter much which way to go.
2.5. White Space
Collapsible white space within a ruby structure is discarded
Where undiscarded white space is collapsible, it will collapse
following the standard white space
processing rules. [CSS3TEXT] For collapsible
white space between ruby segments,
however, the contextual text for determining collapsing behavior is given
by the ruby bases on either side, not
the text on either side of the white space in the source document.
Note that the white space processing rules cause a white space sequence
containing a segment break (such as a line feed) to collapse to
nothing between CJK characters. This means that CJK ruby can safely
use white space for indentation of the ruby markup. For example, the
following markup will display without any spaces:
However, white space that does not contain a segment break does
not collapse completely away, so this markup will display with a space
between the first and second ruby pairs:
Any preserved white space is then wrapped in an anonymous box belonging
to the ruby base container
(if between ruby bases), ruby annotation container
(if between ruby annotations),
or ruby container (if between ruby segments). In the latter case, the
text is considered part of the base level. Such anonynmous boxes do
not take part in pairing. They merely ensure separation between adjacent
bases/annotations.
Specify how these anonymous white space boxes impact layout.
These rules allow ruby to be used with space-separated scripts such as
Latin. For example,
When a ruby structure is laid out, its base level is laid out on the
line, aligned according to its ‘vertical-align’ property exactly as if its
bases were a regular sequence of inline boxes. Each ruby base container is sized
and positioned to contain exactly the full height of its ruby bases.
A ruby container (or fragment thereof) measures as wide as the content
of its widest level. Similarly, ruby base
boxes and ruby annotation
boxes within a ruby “column” have the measure of the widest
content in that “column”. In the case of spanning annotations
(whether actually spanning or pretending to span per ‘ruby-collapse’), the measures of the ruby annotation box and the sum of
its associated ruby base boxes must
match.
How the extra space is distributed when ruby content is narrower than
the measure of its box is specified by the ‘ruby-align’ property.
2.6.1.
Inter-character ruby layout
Inter-character annotations have special layout. When ‘ruby-position’
indicates ‘inter-character’ annotations, the
affected annotation boxes are spliced into and measured as part of
the layout of the base level. The ruby base container must be
sized to include both the base boxes as well as the ‘inter-character’ annotation boxes. The affected
ruby annotation
container is similarly sized so that its content box coincides
with that of the ruby base
container.
For the purpose of laying out other levels of annotations, an ‘inter-character’ annotation effectively becomes part of
its base. Or should it become a quasi-base between two
bases? A spanning ‘inter-character’
annotation is placed after all the bases that it spans.
2.7. Styling Ruby Boxes
In most respects, ruby boxes can be styled similar to inline boxes.
However, the UA is not required to support any of the box properties
(borders, margins, padding), any of the background properties or outline
properties, or any other property that illustrates the bounds of the box
on ruby base container
boxes, ruby annotation
container boxes, or ruby-internal
ruby container boxes. The UA may implement these boxes simply
as abstractions for inheritance and control over the layout of their
contents.
2.8. Ruby box and line
breaking
When there is not enough space for an entire ruby container to fit on the line,
the ruby may be broken wherever all levels simultaneously allow a break.
Ruby most often breaks between base-annotation sets, but if the
line-breaking rules allow it, can also break within a ruby base (and, in parallel, its
associated annotation boxes).
Whenever ruby breaks across lines, ruby annotations must stay with
their respective bases. The line must not break between a
ruby base and its annotations,
even in the case of ‘inter-character’
annotations.
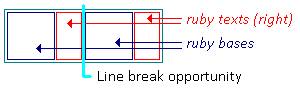
Whether ruby can break between two adjacent ruby bases is controlled by normal
line-breaking rules for the base text, exactly as if the ruby bases were adjacent inline
boxes. (The annotations are ignored when determining soft wrap
opportunities for the base level.)
For example, if two adjacent ruby bases are “蝴” and “蝶”,
the line may break between them, because lines are normally allowed to
break between two Han characters. However, if ‘word-break’ is ‘keep-all’, that line break is forbidden.
<ruby>蝴<rt>hú</rt>蝶<rt>dié</rt>
Inter-base white space is significant for evaluating line break
opportunities between ruby bases. As
with white space between inlines, it collapses when the line breaks there.
Similarly, annotation white space is also trimmed at a line break.
Due to the space, the line may break between “one” and “two“.
If the line breaks there, that space—and the space between “1” and
“2”—disappears, in accordance with standard CSS white space
processing rules. [CSS3TEXT]
2.8.2. Breaking within bases
For longer base texts, it is sometimes appropriate to allow breaking
within a base-annotation pair. For example, if an English sentence is
annotated with its Japanese translation, allowing the text to wrap allows
for reasonable line breaking behavior in the paragraph.
Insert scanned example so people don't think this is just
the ramblings of an insane spec-writer.
Line-breaking within a ruby base is
only allowed if the ‘white-space’ property
of the ruby base and all its parallel
annotations allow it, and there exists a soft wrap
opportunitywithin (i.e. not at the start or end) the content
of each base/annotation box. Since there is no structural correspondance
between fragments of content within ruby
bases and annotations, the UA may break at any set of
opportunities; but it is recommended that the UA attempt to proportionally
balance the amount of content inside each fragment.
There are no line breaking opportunities within ‘inter-character’ annotations.
Ruby alignment takes place within each fragment, after line-breaking.
2.9. Bidi Reordering
Constraints: Text within a ruby base must remain
contiguous, and bases belonging to a single annotation must remain
contiguous. Still figuring out exactly to enforce these limitations in a
sensible manner.
2.10. Ruby box and line
stacking
The ‘line-height’ property controls
spacing between lines in CSS. When inline content on line is shorter than
the ‘line-height’, half-leading is added
on either side of the content, as specificed in CSS2.1§10.8.
[CSS21]
In order to ensure consistent spacing of lines, documents with ruby
typically ensure that the ‘line-height’ is
large enough to accommodate ruby between lines of text. Therefore,
ordinarily, ruby annotation
containers and ruby annotation
boxes do not contribute to the measured height of a line's inline
contents; any alignment (see ‘vertical-align’) and line-height calculations are
performed using only the ruby base
container, exactly as if it were a normal inline.
However, if the ‘line-height’ specified
on the ruby container is less
than the distance between the top of the top ruby annotation container
and the bottom of the bottom ruby annotation
container, then additional leading is added on the appropriate
side of the ruby base
container such that if a block consisted of three lines each
containing ruby identical to this, none of the ruby containers would overlap.
Note that this does not ensure that the ruby annotations remain within the
line box. It merely ensures that if all lines had equal spacing
and equivalent amounts and positioning of ruby annotations, there would be
enough room to avoid overlap.
Authors should ensure appropriate ‘line-height’ and ‘padding’ to accommodate ruby, and be particularly
careful at the beginning or end of a block and when a line contains
inline-level content (such as images, inline blocks, or elements shifted
with ‘vertical-align’) taller than the
paragraph's default font size.
Ruby annotations will often overflow the line; authors
should ensure content over/under a ruby-annotated line is adequately
spaced to leave room for the ruby.
More control over how ruby affects alignment and line layout
will be part of the CSS Line Layout Module Level 3. Note, it is currently
in the process of being rewritten; the current drafts should not be relied
upon.
3. Ruby Properties
The following properties are introduced to control ruby positioning and
alignment.
[ over | under | inter-character ] && [ right | left ]
Initial:
over right
Applies to:
ruby annotation containers
Inherited:
yes
Percentages:
N/A
Media:
visual
Computed value:
specified value
Animatable:
no
Canonical order:
per
grammar
This property controls position of the ruby text with respect to its
base. Values have the following meanings:
Issue-107: Roland Steiner has
requested the addition of an auto value as default. See this
thread and this
one.
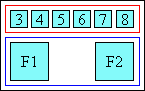
‘over’
The ruby text appears over the base in horizontal text.
Ruby over Japanese base text in horizontal layout
‘right’
The ruby text appears on the right side of the base in vertical text.
Ruby to the right of Japanese base text in vertical
layout
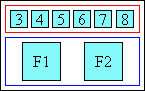
‘under’
The ruby text appears under the base in horizontal text. This is a
relatively rare setting used in ideographic East Asian writing systems,
most easily found in educational text.
Ruby under Japanese base text in horizontal layout
‘left’
The ruby text appears on the left side of the base in vertical text.
Ruby to the left of Japanese base text in vertical
layout
‘inter-character’
The ruby text appears on the right of the base in horizontal text.
This value forces the ‘writing-mode’ of
the ruby annotation to be
vertical.
This value is provided for the special case of traditional Chinese as
used especially in Taiwan: ruby (made of bopomofo glyphs) in that context appears
vertically along the right side of the base glyph, even when the layout
of the base characters is horizontal:
“Bopomofo” ruby in traditional Chinese (ruby text
shown in blue for clarity) in horizontal layout
Note that the user agent is responsible for ensuring the
correct relative alignment and positioning of the glyphs, including
those corresponding to the tone marks, when displaying. Tone marks are
spacing characters that occur (in memory) at the end of the ruby text
for each base character. They are usually displayed in a separate column
to the right of the bopomofo characters, and the height of the tone mark
depends on the number of characters in the syllable. One tone mark,
however, is placed above the bopomofo, not to the right of it.
If multiple ruby annotation
containers have the same ‘ruby-position’, they stack along the block
axis, with lower levels of annotation closer to the base text.
3.2. Collapsed Ruby
Annotations: the ‘ruby-merge’ property
All ruby annotation boxes
within the same ruby segment on the same line are concatenated,
and laid out as if their contents belonged to a single ruby annotation box spanning all
their associated ruby base boxes.
This style renders similar to “group ruby” in [JLREQ], except that ruby annotations are kept
together with their respective ruby
bases when breaking lines.
The following two markups render the same both characters fit on one
line:
However, the second one renders the same as ‘ruby-position: separate’ when the two bases are
split across lines.
‘auto’
The user agent may use any algorithm to determine how each ruby
annotation box is rendered to its corresponding base box, with the
intention that if all annotations fit over their respective bases, the
result is identical to “mono ruby”, but if some annotations are
wider than their bases the space is shared in some way to avoid forcing
space between bases.
One possible algorithm is described as “jukugo ruby” in [JLREQ].
Another, more simplified algorithm of “jukugo ruby” is to render
as ‘separate’ if all ruby annotation boxes
fit within the advances of their corresponding base boxes, and render
as ‘collapse’ otherwise.
3.3. Ruby Text Distribution: the ‘ruby-align’ property
ruby bases, ruby annotations, ruby base containers, ruby annotation
containers
Inherited:
yes
Percentages:
N/A
Media:
visual
Computed value:
specified value (except for initial and inherit)
This property specifies how text is distributed within the various ruby
boxes when their contents do not exactly fill their respective boxes. Note
that space distributed by ‘ruby-align’ is unrelated to, and independent
of, any space distributed due to justification.
Values have the following meanings:
‘start’
The ruby content is aligned with the start edge of its box.
‘start’ ruby distribution
‘center’
The ruby content is centered within its box.
‘center’ ruby distribution
‘space-between’
The ruby content expands as defined for normal text justification (as
defined by ‘text-justify’), except that
if there are no expansion
opportunities the content is centered.
‘space-between’ ruby
distribution
‘space-around’
As for ‘space-between’ except that there
exists an extra expansion
opportunity whose space is distributed half before and half
after the ruby content.
Since a typical implementation will by default define expansion
opportunities between every adjacent pair of CJK characters
and not between adjacent pairs of Latin characters, this should
result in the behavior recommended by [JLREQ]: for wide-cell ruby content
to be distributed...
Wide-cell text in ‘space-around’ ruby distribution is spaced apart
... and narrow-cell glyph ruby to be centered.
Narrow-width ruby text in ‘space-around’ ruby distribution is centered
Add a paragraph explaining how to distribute space in
situations with spanning annotations.
This level of the specification does not define how much the overhang
may be allowed, and under what conditions.
If the ruby text is not allowed to overhang, then the ruby behaves like
a traditional inline box, i.e. only its own contents are rendered within
its boundaries and adjacent elements do not cross the box boundary:
Simple ruby whose text is not allowed to overhang
adjacent text
However, if ruby annotation
content is allowed to overhang adjacent elements and it happens to be
wider than its base, then the adjacent content is partially rendered
within the area of the ruby container
box, while the ruby
annotation may partially overlap the upper blank parts of the
adjacent content:
Simple ruby whose text is allowed to overhang adjacent
text
The alignment of the contents of the base or the ruby text is not
affected by overhanging behavior. The alignment is achieved the same way
regardless of the overhang behavior setting and it is computed before the
space available for overlap is determined. It is controlled by the ‘ruby-align’ property.
I suspect overhanging interacts with alignment in some
cases; might need to look into this later.
This entire logic applies the same way in vertical ideographic layout,
only the dimension in which it works in such a layout is vertical, instead
of horizontal.
The user agent may use [JIS4051] recommendation of using
one ruby text character length as the maximum overhang length. Detailed
rules for how ruby text can overhang adjacent characters for Japanese are
described by [JLREQ].
4.2. Line-edge Alignment
When a ruby annotation box
that is longer than its ruby base is
at the start or end edge of a line, the user agent may force the
side of the ruby annotation that
touches the edge of the line to align to the corresponding edge of the
base. This type of alignment is described by [JLREQ].
This level of the specification does not provide a mechanism to control
this behavior.
Line-edge alignment
Appendix A: Default Style Sheet
This section is informative.
Supporting Ruby Layout
The following represents a default UA style sheet for rendering HTML and
XHTML ruby markup as ruby layout:
Unfortunately, because Selectors cannot match against text nodes, it's
not possible with CSS to express rules that will automatically and
correctly add parentheses to unparenthesized ruby annotations in HTML.
(This is because HTML ruby allows implying the ruby base from raw text, without a
corresponding element.) However, these rules will handle cases where
either <rb> or <rtc> is used
rigorously.
/* Parens around <rtc> */
rtc::before { content: "("; }
rtc::after { content: ")"; }
/* Parens before first <rt> not inside <rtc> */
rb + rt::before,
rtc + rt::before { content: "("; }
/* Parens after <rt> not inside <rtc> */
rb ~ rt:last-child::after,
rt + rb::before { content: ")"; }
rt + rtc::before { content: ")("; }
Japanese syllabic script, or character of that script. Rounded and
cursive in appearance. Subset of the Japanese writing system, used
together with kanji and katakana. In recent times, mostly used to write
Japanese words when kanji are not available or appropriate, and word
endings and particles. Also see Katakana.
A character that is used to represent an idea, word, or word
component, in contrast to a character from an alphabetic or syllabic
script. The most well-known ideographic script is used (with some
variation) in East Asia (China, Japan, Korea,...).
Japanese term for ideographs; ideographs used in Japanese. Subset of
the Japanese writing system, used together with hiragana and katakana.
Also see Hanja.
Japanese syllabic script, or character of that script. Angular in
appearance. Subset of the Japanese writing system, used together with
kanji and hiragana. In recent times, mainly used to write foreign words.
Also see Hiragana.
6. Conformance
6.1. Document conventions
Conformance requirements are expressed with a combination of descriptive
assertions and RFC 2119 terminology. The key words “MUST”, “MUST
NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”,
“SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in the
normative parts of this document are to be interpreted as described in RFC
2119. However, for readability, these words do not appear in all uppercase
letters in this specification.
All of the text of this specification is normative except sections
explicitly marked as non-normative, examples, and notes. [RFC2119]
Examples in this specification are introduced with the words “for
example” or are set apart from the normative text with
class="example", like this:
This is an example of an informative example.
Informative notes begin with the word “Note” and are set apart from
the normative text with class="note", like this:
Note, this is an informative note.
6.2. Conformance
classes
Conformance to CSS Ruby Module is defined for three conformance classes:
A style sheet is conformant to CSS Ruby Module if all of its statements
that use syntax defined in this module are valid according to the generic
CSS grammar and the individual grammars of each feature defined in this
module.
A renderer is conformant to CSS Ruby Module if, in addition to
interpreting the style sheet as defined by the appropriate specifications,
it supports all the features defined by CSS Ruby Module by parsing them
correctly and rendering the document accordingly. However, the inability
of a UA to correctly render a document due to limitations of the device
does not make the UA non-conformant. (For example, a UA is not required to
render color on a monochrome monitor.)
An authoring tool is conformant to CSS Ruby Module if it writes style
sheets that are syntactically correct according to the generic CSS grammar
and the individual grammars of each feature in this module, and meet all
other conformance requirements of style sheets as described in this
module.
6.3. Partial implementations
So that authors can exploit the forward-compatible parsing rules to
assign fallback values, CSS renderers must treat as
invalid (and ignore as
appropriate) any at-rules, properties, property values, keywords, and
other syntactic constructs for which they have no usable level of support.
In particular, user agents must not selectively ignore
unsupported component values and honor supported values in a single
multi-value property declaration: if any value is considered invalid (as
unsupported values must be), CSS requires that the entire declaration be
ignored.
6.4. Experimental
implementations
To avoid clashes with future CSS features, the CSS2.1 specification
reserves a prefixed
syntax for proprietary and experimental extensions to CSS.
Prior to a specification reaching the Candidate Recommendation stage in
the W3C process, all implementations of a CSS feature are considered
experimental. The CSS Working Group recommends that implementations use a
vendor-prefixed syntax for such features, including those in W3C Working
Drafts. This avoids incompatibilities with future changes in the draft.
6.5. Non-experimental
implementations
Once a specification reaches the Candidate Recommendation stage,
non-experimental implementations are possible, and implementors should
release an unprefixed implementation of any CR-level feature they can
demonstrate to be correctly implemented according to spec.
To establish and maintain the interoperability of CSS across
implementations, the CSS Working Group requests that non-experimental CSS
renderers submit an implementation report (and, if necessary, the
testcases used for that implementation report) to the W3C before releasing
an unprefixed implementation of any CSS features. Testcases submitted to
W3C are subject to review and correction by the CSS Working Group.
This specification would not have been possible without the help from:
Stephen Deach, Martin Dürst, Hideki Hiura(樋浦
秀樹), Masayasu Ishikawa(石川 雅康),
Chris Pratley, Takao Suzuki(鈴木 孝雄), Frank
Yung-Fong Tang, Chris Thrasher, Masafumi Yabe家辺
勝文), Steve Zilles.
Changes
The following major changes have been made since the previous Working
Draft:
Remove ‘ruby-span’ and mentions of
rbspan.
Explicit spanning is not used in HTML ruby in favor of implicit
spanning. This can't handle some pathological double-sided spanning
cases, but there seems to be no requirement for these at the moment. (For
implementations that support full complex XHTML Ruby, they can imply
spanning from the markup the same magic way that we handle cell spanning
from tables. It doesn't seem necessary to include controls this in Level
1.)
Defer ‘ruby-overhang’ and ‘ruby-align: line-end’ to Level 2.
It's somewhat complicated, advanced feature. Proposal is to make this
behavior UA-defined and provide some examples of acceptable options.
Close issue requesting ‘display: rp’: use
‘display: none’.
The Internationalization WG added an issue requesting a display value
for <rp> elements. They're supposed to be hidden when <ruby> is
displayed as ruby. But this is easily accomplished already with ‘display: none’.
Change ‘ruby-position’ values to match ‘text-emphasis-position’.
Other than ‘inter-character’, which we
need to keep, it makes more sense to align ruby positions with ‘text-emphasis-position’, which can correctly
handle various combinations of horizontal/vertical preferences.
Replace ‘auto’, ‘distribute-letter’, and ‘distribute-space’ from ‘ruby-align’ with ‘space-between’ and ‘space-around’.
The ‘auto’ value relied on inspecting
content to determine behavior; this can be avoided by just using ‘space-around’ with standard justification rules (which
allow spacing between CJK but not between Latin). Replaced ‘distribute-letter’ and ‘distribute-space’ with ‘space-between’ and ‘space-around’ for consistency with distribution
keywords in [CSS3-FLEXBOX] and [CSS3-ALIGN]
and to avoid any links to the definition of ‘text-justify: distribute’.
Added ‘ruby-merge’ property to control jukugo
rendering.
This is a stylistic effect, not a structural one; the previous model
assumed that it was structural and suggested handling it by changing
markup. :(