Abstract
There are many situations where it would be useful to be able to
publish
multi-dimensional data, such as statistics, on the web in such a way
that it can be linked to related data sets and concepts. The Data Cube
vocabulary provides a means to do this using the W3C RDF
(Resource Description Framework) standard. The model underpinning the
Data Cube vocabulary is
compatible with the cube model that underlies SDMX (Statistical Data
and Metadata eXchange), an ISO standard for exchanging and sharing
statistical data and metadata among organizations. The Data Cube
vocabulary is a core foundation which supports extension
vocabularies to enable publication of other aspects of
statistical data flows.
Status of This Document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/.
This publication transitions previous work on this subject onto the W3C Recommendation Track.
This document was published by the Government Linked Data (GLD) Working Group as a First Public Working Draft. This document is intended to become a W3C Recommendation. If you wish to make comments regarding this document, please send them to public-gld-comments@w3.org (subscribe, archives). All feedback is welcome.
Publication as a Working Draft does not imply endorsement by the W3C Membership. This is a draft document and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to cite this document as other than work in progress.
This document was produced by a group operating under the 5 February 2004 W3C Patent Policy. W3C maintains a public list of any patent disclosures made in connection with the deliverables of the group; that page also includes instructions for disclosing a patent. An individual who has actual knowledge of a patent which the individual believes contains Essential Claim(s) must disclose the information in accordance with section 6 of the W3C Patent Policy.
1. Introduction
1.1 A Data Cube vocabulary
Statistical data is a foundation for policy
prediction, planning and adjustments and
underpins many of the mash-ups and visualisations
we see on the web. There is strong interest
in being able to publish statistical data in a web-friendly format
to enable it to be linked and combined with related information.
At the heart of a statistical dataset is a set of observed values
organized along a group of dimensions, together with associated metadata.
The Data Cube vocabulary enables such information to be represented
using the the W3C RDF
(Resource Description Framework) standard and published following the
principles of
linked data.
The vocabulary is based upon the approach used by the SDMX ISO standard
for statistical data exchange. This cube model is very
general and so the Data Cube vocabulary can be used for other data sets
such as survey data, spreadsheets and OLAP data cubes [OLAP].
The Data Cube vocabulary is focused purely on the
publication of multi-dimensional data on the web. We envisage a series of modular
vocabularies being developed which extend this core foundation. In
particular, we see the need for an SDMX extension vocabulary to support the
publication of additional context to statistical data (such as the encompassing Data
Flows and associated Provision Agreements). Other extensions are possible to
support metadata for surveys (so called "micro-data", as encompassed by DDI)
or publication of statistical reference metadata.
The Data Cube in turn builds upon the following existing RDF
vocabularies:
1.2 RDF and Linked Data
Linked data is an approach to publishing data on the web, enabling
datasets to be linked together through references to common concepts.
The approach [LOD]
recommends use of HTTP URIs to name the entities and concepts so that consumers of
the data can look-up those URIs to get more information, including links
to other related URIs.
RDF [RDF-PRIMER]
provides a standard for the representation of the
information that describes those entities and concepts, and is returned
by dereferencing the URIs.
There are a number of benefits to being able to publish multi-dimensional data, such as statistics,
using RDF and the linked data approach:
- The individual observations, and groups of observations, become
(web) addressable. This allows publishers and third parties to annotate
and link to this data; for example a report can reference the specific
figures it is based on allowing for fine grained provenance trace-back.
- Data can be flexibly combined across datasets and between
statistical and non-statistical sets (for example find all
Religious schools in census areas with high values for National
Indicators pertaining to religious tolerance). The statistical
data becomes an integral part of the broader web of linked data.
- For publishers who currently only offer static files then
publishing as linked-data offers a flexible, non-proprietary, machine
readable means of publication that supports an out-of-the-box web API
for programmatic access.
- It enables reuse of standardized tools and components.
1.3 SDMX and related standards
The Statistical Data and Metadata Exchange (SDMX) Initiative
was organised in 2001 by seven international organisations (BIS,
ECB, Eurostat, IMF, OECD, World Bank and the UN) to
realise greater efficiencies in statistical practice. These
organisations all
collect significant amounts of data, mostly from the national level,
to support policy. They also disseminate data at the supra-national
and international levels.
There have been a number of important results from this work: two
versions of a set of technical specifications - ISO:TS 17369
(SDMX) - and the release of several recommendations for
structuring and harmonising cross-domain statistics, the SDMX
Content-Oriented Guidelines. All of the products are available at
www.sdmx.org. The standards are now
being widely adopted
around the world for the collection, exchange, processing, and
dissemination of aggregate statistics by official statistical
organisations. The UN Statistical Commission recommended
SDMX as the preferred standard for statistics in 2007.
The SDMX specification defines a core information model
which is reflected in concrete form in two syntaxes - SDMX-ML (an XML
syntax) and SDMX-EDI.
The Data Cube vocabulary builds upon the core of the SDMX information
model.
A key component of the SDMX standards package are
the Content-Oriented Guidelines (COGs), a set of
cross-domain concepts, code lists, and categories that support
interoperability and comparability between datasets by providing a
shared terminology between SDMX implementers. RDF versions of these
terms are available separately for use along with the Data Cube
vocabulary.
1.4 Relationship to SCOVO
The Statistical Core Vocabulary (SCOVO) [SCOVO] is a lightweight
RDF vocabulary for expressing statistical data. Its relative
simplicity allows easy adoption by data producers and consumers, and
it can be combined with other RDF vocabularies for greater effect. The
model is extensible both on the schema and the instance level for more
specialized use cases.
While SCOVO addresses the basic use case of expressing statistical
data in RDF, its minimalist design is limiting, and it does not
support important scenarios that occur in statistical publishing, such
as:
- definition and publication of the structure of a dataset
independent from concrete data,
- data flows which group together datasets that share the same
structure, for example from different national data providers,
- definition of "slices" through a dataset, such as an individual
time series or cross-section, for individual annotation,
- distinctions between dimensions, attributes and measures.
The design of the Data Cube vocabulary is informed by SCOVO,
and every SCOVO dataset can be re-expressed within the vocabulary.
1.5 Audience and scope
This document describes the Data Cube vocabulary
It is aimed at people wishing to publish
statistical or other multi-dimension data in RDF.
Mechanics of cross-format translation from other
formats such as SDMX-ML will be covered elsewhere.
1.6 Document conventions
The names of RDF entities -- classes, predicates, individuals -- are
URIs. These are usually expressed using a compact notation where the
name is written prefix:localname, and where the prefix
identifies a namespace URI. The namesapce identified by the prefix is
prepended to the localname to obtain the full URI.
In this document we shall use the conventional prefix names for the
well-known namespaces:
rdf, rdfs -- the core RDF namespacesdc -- Dublin Coreskos -- Simple Knowledge Organization Systemfoaf -- Friend Of A Friendvoid -- Vocabulary of Interlinked Datasetsscovo -- Statistical Core Vocabulary
We also introduce the prefix qb for the Data Cube
namespace http://purl.org/linked-data/cube#.
All RDF examples are written in Turtle syntax [TURTLE-TR].
2. Data cubes
2.1 The cube model - dimensions, attributes, measures
A statistical data set comprises a collection of observations made
at some points across some logical space. The collection can be characterized by
a set of dimensions that define what the observation applies to (e.g. time,
area, gender) along with metadata describing what has been
measured (e.g. economic activity, population), how it was measured and how the
observations are expressed (e.g. units, multipliers, status). We can
think of the statistical data set as a multi-dimensional
space, or hyper-cube, indexed by those dimensions. This space is
commonly referred to
as a cube for short; though the name shouldn't be taken
literally, it is not meant to imply that
there are exactly three dimensions (there can be more or fewer) nor
that
all the dimensions are somehow similar in size.
A cube is organized according to a set of dimensions,
attributes and measures. We collectively call these components.
The dimension components serve to identify
the observations. A set of values for all the dimension
components
is sufficient to identify a single observation. Examples of dimensions
include the
time to which the observation applies, or a geographic region which the observation covers.
The measure components represent the phenomenon being
observed.
The attribute components allow us to qualify and
interpret the observed value(s). They enable specification of the units of
measures, any scaling factors and metadata such as the status
of the observation (e.g. estimated, provisional).
2.2 Slices
It is frequently useful to group subsets of observations within a
dataset. In particular to fix all but one (or a small subset) of the
dimensions and be able to refer to all observations with those
dimension values as a single entity. We call such a selection a slice
through the cube. For example, given a data set on regional performance
indicators then we might group all the observations about a given indicator
and a given region into a slice, each slice would then represent a time series of observed values.
A data publisher may identify slices through the data for various
purposes. They can be a useful grouping to which metadata might be attached, for example to note a
change in measurement process which
affects a particular time or region. Slices also enable the publisher to
identify and label particular subsets of the data which should be presented to the
user - they can enable the consuming application to more easily
construct the appropriate graph or chart for presentation.
In statistical applications it is common to work with
slices in which a single dimension is left unspecified.
In particular,
to refer to such slices in which the single free dimension is time as Time
Series and to refer slices along non-time dimensions as Sections.
Within the Data Cube vocabulary we allow arbitrary dimensionality
slices and do not give different names to particular types of slice but
extension vocabularies, such as SDMX-RDF, can easily add such
concept labels.
3. An example
In order to illustrate the use of the data cube vocabulary we will
use a small demonstration
data set extracted from
StatsWales report
number 003311 which describes life expectancy broken down by region
(unitary authority), age and time. The extract we will use is:
|
2004-2006
|
2005-2007
|
2006-2008
|
|
Male
|
Female
|
Male
|
Female
|
Male
|
Female
|
Newport
|
76.7
|
80.7
|
77.1
|
80.9
|
77.0
|
81.5
|
Cardiff
|
78.7
|
83.3
|
78.6
|
83.7
|
78.7
|
83.4
|
Monmouthshire
|
76.6
|
81.3
|
76.5
|
81.5
|
76.6
|
81.7
|
Merthyr
Tydfil
|
75.5
|
79.1
|
75.5
|
79.4
|
74.9
|
79.6
|
We can see that there are three dimensions - time period (rolling averages over three year timespans),
region and sex. Each observation represents the life expectancy for that population (the measure) and
we will need an attribute to define the units (years) of the measured values.
An example of slicing the data would be to define slices in which the time and sex are
fixed for each slice. Such slices then show the variation in life expectancy across the
different regions, i.e. corresponding to the columns in the above tabular layout.
4. Outline of the vocabulary
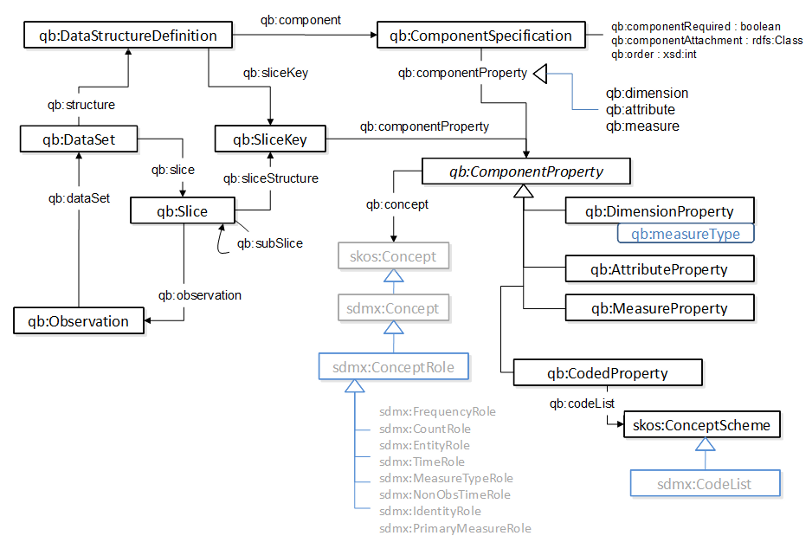
5. Creating data structure definitions
A qb:DataStructureDefinition defines the structure of one or more
datasets. In particular, it defines the dimensions, attributes and measures
used in the dataset along with qualifying information such as ordering of
dimensions and whether attributes are required or optional. For well-formed
data sets much of this information is implicit within the RDF component properties
found on the observations. However, the explicit declaration of the structure has
several benefits:
- it enables verification that the data set matches the expected structure,
in particular helps with detection of incoherent sets obtained by
combining differently structured source data;
- it allows a consumer to easily determine what dimensions are available for query
and their presentational order, which in turn simplifies UI construction;
- it supports transmission of the structure information in associated SDMX data flows.
It is common, when publishing statistical data, to have a regular series of publications which
all follow the same structure. The notion of a Data Structure Definition (DSD) allows us to define
that structure once and then reuse it for each publication in the series. Consumers can then be
confident that the structure of the data has not changed.
5.1 Dimensions, attributes and measures
The Data Cube vocabulary represents the dimensions, attributes and measures
as RDF properties. Each is an instance of the abstract qb:ComponentProperty
class, which in turn has sub-classes qb:DimensionProperty,
qb:AttributeProperty and qb:MeasureProperty.
A component property encapsulates several pieces of information:
- the concept being represented (e.g. time or geographic area),
- the nature of the component (dimension, attribute or measure) as represented by the type of the component property,
- the type or code list used to represent the value.
The same concept can be manifested in different components. For example, the concept
of currency may be used as a dimension (in a data set dealing with exchange rates) or as
an attribute (when describing the currency in which an observed trade took place). The concept of time
is typically used only as a dimension but may be encoded as a data value (e.g. an xsd:dateTime)
or as a symbolic value (e.g. a URI drawn from the reference time URI set developed by data.gov.uk).
In statistical agencies it is common to have a standard thesaurus of statistical concepts which
underpin the components used in multiple different data sets.
To support this reuse of general statistical concepts the data cube vocabulary provides the qb:concept property which
links a qb:ComponentProperty to the concept it represents. We use the SKOS
vocabulary [SKOS-PRIMER] to represent such concepts. This is very natural for those cases where the
concepts are already maintained as a controlled term list or thesaurus.
When developing a data structure definition for an informal data set there may not be an appropriate
concept already. In those cases, if the concept is likely to be reused in other guises it is recommended to
publish a skos:Concept along with the specific qb:ComponentProperty. However, if
such reuse is not expected then it is not required to do so - the qb:concept
link is optional and a simple instance of the appropriate subclass of qb:ComponentProperty is
sufficient.
The representation of the possible values of the component is described using the rdfs:range
property of the component in the usual RDF manner. Thus, for example, values of a time dimension might
be represented using literals of type xsd:dateTime or as URIs drawn from a time reference service.
In statistical data sets it is common
for values to be encoded using some (possibly hierarchical) code list and it can be useful to be
able to easily identify the overall code list in some more structured form. To cater for this a
component can also be optionally annotated with a qb:codeList denoting a skos:ConceptScheme.
In such a case the rdfs:range of the component might be left as simply skos:Concept but
a useful design pattern is to also define an rdfs:Class
whose members are all the skos:Concepts within a particular scheme. In that way
the rdfs:range can be made more specific which enables generic RDF tools to perform
appropriate range checking.
Note that in the SDMX extension vocabulary there is one further item of information to encode
about components - the role that they play within the structure definition. In particular, is sometimes
convenient for consumers to be able to easily identify which is the time dimension,
which component is the primary measure and so forth. It turns out that such roles are intrinsic to
the concepts and so this information is encoded by providing subclasses of skos:Concept
for each role. The particular choice of roles here is specific to the SDMX standard and so is not
included within the core data cube vocabulary. In cases where such roles are appropriate then we
encourage applications of the data cube vocabulary to also supply the relevant SDMX-derived role
information.
Before illustrating the components needed for our running example, there is one more piece
of machinery to introduce, a reusable set of concepts and components based on SDMX.
5.2 Content oriented guidelines
The SDMX standard includes a set of content oriented guidelines (COG) [COG]
which define a
set of common statistical concepts and associated code lists that are intended to be
reusable across data sets. As part of the data cube work we have created RDF analogues
to the COG. These include:
sdmx-concept: SKOS Concepts for each COG defined concept;sdmx-code: SKOS Concepts and ConceptSchemes for each COG defined code list;sdmx-dimension: component properties corresponding to each COG concept that can be used as a dimension;sdmx-attribute: component properties corresponding to each COG concept that can be used as a attribute;sdmx-measure: component properties corresponding to each COG concept that can be used as a measure.
The data cube vocabulary is standalone and it is not mandatory to use the SDMX COG-derived
terms. However, when the concepts being expressed do match a COG concept it is recommended
that publishers should reuse the corresponding components and/or concept URIs to simplify comparisons
across data sets. Given this background we will reuse the relevant COG components in our worked example.
5.3 Example
Turning to our example data set then we can see there are three dimensions to represent
- time period, region (unitary authority) and sex of the population. There is a single
(primary) measure which corresponds to the topic of the data set (life expectancy) and
encodes a value in years. Hence, we need the following components.
Time. There is a suitable predefined concept in the SMDX-COG for this, REF_PERIOD, so
we could reuse the corresponding component property sdmx-dimension:refPeriod. However,
to represent the time period itself it would be convenient to use the data.gov.uk reference
time service and to declare this within the data structure definition.
eg:refPeriod a rdf:Property, qb:DimensionProperty;
rdfs:label "reference period"@en;
rdfs:subPropertyOf sdmx-dimension:refPeriod;
rdfs:range interval:Interval;
qb:concept sdmx-concept:refPeriod .
Region. Again there is a suitable COG concept and associated component that
we can use for this, and again we can customize the range of the component. In this case
we can use the Ordanance Survey administrative geography ontology [OS-GEO].
eg:refArea a rdf:Property, qb:DimensionProperty;
rdfs:label "reference area"@en;
rdfs:subPropertyOf sdmx-dimension:refArea;
rdfs:range admingeo:UnitaryAuthority;
qb:concept sdmx-concept:refArea .
Sex. In this case we can use the corresponding COG component sdmx-dimension:sex
directly, since the default code list for it includes the terms we need.
Measure. This property will give the value of each observation.
We could use the default smdx-measure:obsValue for this (defining
the topic being observed using metadata). However, it can aid readability and processing
of the RDF data sets to use a specific measure corresponding to the phenomenon being observed.
eg:lifeExpectancy a rdf:Property, qb:MeasureProperty;
rdfs:label "life expectancy"@en;
rdfs:subPropertyOf sdmx-measure:obsValue;
rdfs:range xsd:decimal .
Unit measure attribute. The primary measure on its own is a plain decimal value.
To correctly interpret this value we need to define what units it is measured in (years in this case).
This is defined using attributes which qualify the interpretation of the observed value.
Specifically in this example we can use the predefined sdmx-attribute:unitMeasure
which in turn corresponds to the COG concept of UNIT_MEASURE. To express
the value of this attribute we would typically us a common thesaurus of units of measure.
For the sake of this simple example we will use the DBpedia resource http://dbpedia.org/resource/Year
which corresponds to the topic of the Wikipedia page on "Years".
This covers the minimal components needed to define the structure of this data set.
5.4 ComponentSpecifications and DataStructureDefinitions
To combine the components into a specification for the structure of this
dataset we need to declare a qb:DataStuctureDefinition
resource which in turn will reference a set of qb:ComponentSpecification resources.
The qb:DataStuctureDefinition will be reusable across other data sets with the same structure.
In the simplest case the qb:ComponentSpecification simply references the
corresponding qb:ComponentProperty (ususally using one of the sub properties
qb:dimension, qb:measure or qb:attribute).
However, it is also possible to qualify the
component specification in several ways.
- An Attribute may be optional in which case the specification should set
qb:componentRequired "false"^^xsd:boolean.
- The components may be ordered by giving an integer value for
qb:order.
This order carries no semantics but can be useful to aid consuming agents in generating
appropriate user interfaces. It can also be useful in the publication chain to enable
synthesis of appropriate URIs for observations.
- By default the values of all of the components will be attached to each individual observation,
a so called flattened representation.
This allows such observations to stand alone, so that a SPARQL query to retrieve the observation
can immediately locate the attributes which enable the observation to be interpreted. However,
it is also permissible to attach attributes to the
overall data set, to an intervening slice or to a specific Measure (in the case of multiple measures).
This reduces some of the redundancy in the encoding of the instance data. To declare such a
non-flat structure, the
qb:componentAttachment property of the specification should
reference the class corresponding to the attachment level (e.g. qb:DataSet for attributes
that will be attached to the overall data set).
In the case of our running example the dimensions can be usefully ordered. There is only one
attribute, the unit measure, and this is required. In the interests of illustrating the vocabulary
use we will declare that this attribute will be attached at the level of the data set, however
flattened representations are in general easier to query and combine.
So the structure of our example data set (and other similar datasets) can be declared by:
eg:dsd-le a qb:DataStructureDefinition;
# The dimensions
qb:component [qb:dimension eg:refArea; qb:order 1];
qb:component [qb:dimension eg:refPeriod; qb:order 2];
qb:component [qb:dimension sdmx-dimension:sex; qb:order 3];
# The measure(s)
qb:component [qb:measure eg:lifeExpectancy];
# The attributes
qb:component [qb:attribute sdmx-attribute:unitMeasure; qb:componentAttachment qb:DataSet;] .
Note that we have given the data structure definition (DSD) a URI since it will be
reused across different datasets with the same structure. Similarly the component properties
themselves can be reused across different DSDs. However, the component specifications
are only useful within the scope of a particular DSD and so we have chosen the represent
them using blank nodes.
5.5 Handling multiple measures
Our example data set is relatively simple in having a single observable (in this case "life expectancy")
that is being measured. In other data sets there can be multiple measures. These measures
may be of similar nature (e.g. a data set on local government performance might provide
multiple different performance indicators for each region) or quite different (e.g. a data set
on trades might provide quantity, value, weight for each trade).
There are two approaches to representing multiple measures. In the SDMX information model, each
observation can record a single observed value. In a data set with multiple observations then we
add an additional dimension whose value indicates the measure. This is appropriate for applications
where the measures are separate aggregate statistics. In other domains such as a clinical statistics
or sensor networks then the term observation usually denotes an observation event which can include multiple
observed values. Similarly in Business Intelligence applications and OLAP, a single "cell" in the data cube will
typically contain values for multiple measures.
The data cube vocabulary permits either representation approach to be used though they cannot be mixed
within the same data set.
5.5.1 Multi-measure observations
This approach allows multiple observed values to be attached
to an individual observation. Is suited to representation of things like sensor data and OLAP cubes.
To use this representation you simply declare multiple qb:MeasureProperty components
in the data structure definition and attach an instance of each property to the observations within
the data set.
For example, if we have a set of shipment data containing unit count and total weight for each
shipment then we might have a data structure definition such as:
eg:dsd1 a qb:DataStructureDefinition;
rdfs:comment "shipments by time (multiple measures approach)"@en;
qb:component
[ qb:dimension sdmx-dimension:refTime; ],
[ qb:measure eg-measure:quantity; ],
[ qb:measure eg-measure:weight; ] .
This would correspond to individual observations such as:
eg:dataset1 a qb:DataSet;
qb:structure eg:dsd1 .
eg:obs1a a qb:Observation;
qb:dataSet eg:dataset1;
sdmx-dimension:refTime "30-07-2010"^^xsd:date;
eg-measure:weight 1.3 ;
eg-measure:quantity 42 ;
.
Note that one limitation of the multi-measure approach is that it is not possible to attach
an attribute to a single observed value. An attribute attached to the observation instance
will apply to the whole observation (e.g. to indicate who made the observation). Attributes
can also be attached directly to the qb:MeasureProperty itself (e.g. to indicate
the unit of measure for that measure) but that attachment applies to the whole data
set (indeed any data set using that measure property) and cannot vary for different observations.
For applications where this limitation is a problem then use the measure dimension approach.
5.5.2 Measure dimension
This approach restricts observations to having a single measured value but allows
a data set to carry multiple measures by adding an extra dimension, a measure dimension.
The value of the measure dimension denotes which particular measure is being conveyed by the
observation. This is the representation approach used within SDMX and the SMDX-in-RDF
extension vocabulary introduces a subclass of qb:DataStructureDefinition which is restricted
to using the measure dimension representation.
To use this representation you declare an additional dimension within the data structure
definition to play the role of the measure dimension. For use within the Data Cube vocabulary
we provide a single distinguished component for this purpose -- qb:measureType.
Within the SDMX-in-RDF extension then there is a role used to identify concepts which
act as measure types, enabling other measure dimensions to be declared.
In the special case of using qb:measureType as the measure dimension, the set of allowed
measures is assumed to be those measures declared within the DSD. There is no need to
define a separate code list or enumerated class to duplicate this information.
Thus, qb:measureType is a “magic” dimension property with an implicit code list.
The data structure definition for our above example, using this representation approach, would then be:
eg:dsd2 a qb:DataStructureDefinition;
rdfs:comment "shipments by time (measure dimension approach)"@en;
qb:component
[ qb:dimension sdmx-dimension:refTime; ],
[ qb:measure eg-measure:quantity; ],
[ qb:measure eg-measure:weight; ],
[ qb:dimension qb:measureType; ] .
This would correspond to individual observations such as:
eg:dataset2 a qb:DataSet;
qb:structure eg:dsd2 .
eg:obs2a a qb:Observation;
qb:dataSet eg:dataset2;
sdmx-dimension:refTime "30-07-2010"^^xsd:date;
qb:measureType eg-measure:weight ;
eg-measure:weight 1.3 .
eg:obs2b a qb:Observation;
qb:dataSet eg:dataset2;
sdmx-dimension:refTime "30-07-2010"^^xsd:date;
qb:measureType eg-measure:quantity ;
eg-measure:quantity 42 .
Note the duplication of having the measure property show up both as the property that
carries the measured value, and as the value of the measure dimension. We accept
this duplication as necessary to ensure the uniform cube/dimension mechanism and
a uniform way of declaring and using measure properties on all kinds of datasets.
Those familiar with SDMX should also note that in the RDF representation there is
no need for a separate "primary measure" which subsumes each of the individual
measures, those individual measures are used directly. The SDMX-in-RDF extension
vocabulary addresses the round-tripping of the SDMX primary measure by use of a
separate annotation on sdmx:DataStructureDefinition.
6. Expressing data sets
A DataSet is a collection of statistical data that corresponds to a given data structure definition.
The data in a data set can be roughly described as belonging to one of the following kinds:
- Observations
- This is the actual data, the measured numbers. In a statistical table, the observations
would be the numbers in the table cells.
- Organizational structure
- To locate an observation within the hypercube, one has at least to know the value of each
dimension at which the observation is located, so these values must be specified for each observation.
Datasets can have additional organizational structure in the form of slices
as described earlier in section 2.2.
- Internal metadata
- Having located an observation, we need certain metadata in order to be able to interpret it.
What is the unit of measurement? Is it a normal value or a series break?
Is the value measured or estimated? These metadata are provided as attributes and can
be attached to individual observations, or to higher levels as defined by the ComponentSpecification
described earlier.
- External metadata
- This is metadata that describes the dataset as a whole, such as categorization of the
dataset, its publisher, and a SPARQL endpoint where it can be accessed.
External metadata is described in section 9.
6.1 Data sets and observations
A resource representing the entire data set is created and typed as qb:DataSet and
linked to the corresponding data structure definition via the qb:structure property.
Pitfall: Note the capitalization of qb:DataSet,
which differs from the capitalization in other vocabularies, such as
void:Dataset and dcat:Dataset. This unusual capitalization is chosen for compatibility
with the SDMX standard. The same applies to the related property qb:dataSet.
Each observation is represented as an instance of type qb:Observation.
In the basic case then values for each of the attributes, dimensions and measurements are attached directly to the observation (remember
that these components are all RDF properties). The observation is linked to the containing
data set using the qb:dataSet property. For example:
Thus for our running example we might expect to have:
eg:dataset-le1 a qb:DataSet;
rdfs:label "Life expectancy"@en;
rdfs:comment "Life expectancy within Welsh Unitary authorities - extracted from Stats Wales"@en;
qb:structure eg:dsd-le ;
.
eg:o1 a qb:Observation;
qb:dataSet eg:dataset-le1 ;
eg:refArea admingeo:newport_00pr ;
eg:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
sdmx-dimension:sex sdmx-code:sex-M ;
sdmx-attribute:unitMeasure <http://dbpedia.org/resource/Year> ;
eg:lifeExpectancy 76.7 ;
.
eg:o2 a qb:Observation;
qb:dataSet eg:dataset-le1 ;
eg:refArea admingeo:cardiff_00pt ;
eg:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
sdmx-dimension:sex sdmx-code:sex-M ;
sdmx-attribute:unitMeasure <http://dbpedia.org/resource/Year> ;
eg:lifeExpectancy 78.7 ;
.
eg:o3 a qb:Observation;
qb:dataSet eg:dataset-le1 ;
eg:refArea admingeo:monmouthshire_00pp ;
eg:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
sdmx-dimension:sex sdmx-code:sex-M ;
sdmx-attribute:unitMeasure <http://dbpedia.org/resource/Year> ;
eg:lifeExpectancy 76.6 ;
.
...
This flattened structure makes it easy to query and combine data sets
but there is some redundancy here. For example, the unit of measure for the
life expectancy is uniform across the whole data set and does not change between
observations. To cater for situations like this the Data Cube vocabulary allows components
to be attached at a high level in the nested structure. Indeed if we re-examine our
original Data Structure Declaration we see that we declared the unit of measure to be
attached at the data set level. So the corrected example is:
eg:dataset-le1 a qb:DataSet;
rdfs:label "Life expectancy"@en;
rdfs:comment "Life expectancy within Welsh Unitary authorities - extracted from Stats Wales"@en;
qb:structure eg:dsd-le ;
sdmx-attribute:unitMeasure <http://dbpedia.org/resource/Year> ;
.
eg:o1 a qb:Observation;
qb:dataSet eg:dataset-le1 ;
eg:refArea admingeo:newport_00pr ;
eg:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
sdmx-dimension:sex sdmx-code:sex-M ;
eg:lifeExpectancy 76.7 ;
.
eg:o2 a qb:Observation;
qb:dataSet eg:dataset-le1 ;
eg:refArea admingeo:cardiff_00pt ;
eg:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
sdmx-dimension:sex sdmx-code:sex-M ;
eg:lifeExpectancy 78.7 ;
.
eg:o3 a qb:Observation;
qb:dataSet eg:dataset-le1 ;
eg:refArea admingeo:monmouthshire_00pp ;
eg:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
sdmx-dimension:sex sdmx-code:sex-M ;
eg:lifeExpectancy 76.6 ;
.
...
In a data set containing just observations with no intervening structure then each observation
must have a complete set of dimension values, along with all the measure values. If the
set is structured by using slices then further abbreviation is possible, as discussed
in the next section.
7. Slices
Slices allow us to group subsets of observations together. This not intended
to represent arbitrary selections from the observations but uniform slices
through the cube in which one or more of the dimension values are fixed.
Slices may be used for a number of reasons:
- to guide consuming applications in how to present the data (e.g. to organize
data as a set of time series);
- to provide an identity (URI) for the slice to enable to be annotated or externally referenced;
- to reduce the verbosity of the data set by only stating each fixed dimensional value once.
To illustrate the use of slices let us group the sample data set into geographic series.
That will enable us to refer to e.g. "male life expectancy observations for 2004-6"
and guide applications to present a comparative chart across regions.
We first define the structure of the slices we want by associating a "slice key" which the
data structure definition. This is done by creating a qb:SliceKey which
lists the component properties (which must be dimensions) which will be fixed in the
slice. The key is attached to the DSD using qb:sliceKey. For example:
eg:sliceByRegion a qb:SliceKey;
rdfs:label "slice by region"@en;
rdfs:comment "Slice by grouping regions together, fixing sex and time values"@en;
qb:componentProperty eg:refPeriod, sdmx-dimension:sex .
eg:dsd-le-slice1 a qb:DataStructureDefinition;
qb:component
[qb:dimension eg:refArea; qb:order 1];
[qb:dimension eg:refPeriod; qb:order 2];
[qb:dimension sdmx-dimension:sex; qb:order 3];
[qb:measure eg:lifeExpectancy];
[qb:attribute sdmx-attribute:unitMeasure; qb:componentAttachment qb:DataSet;] ;
qb:sliceKey eg:sliceByRegion .
In the instance data then slices are represented by instances of qb:Slice which
link to the observations in the slice via qb:observation and to the key by means
of qb:sliceStructure. Data sets indicate
the slices they contain by means of qb:slice. Thus in our example we would have:
eg:dataset-le2 a qb:DataSet;
rdfs:label "Life expectancy"@en;
rdfs:comment "Life expectancy within Welsh Unitary authorities - extracted from Stats Wales"@en;
qb:structure eg:dsd-le-slice2 ;
sdmx-attribute:unitMeasure <http://dbpedia.org/resource/Year> ;
qb:slice eg:slice2;
.
eg:slice2 a qb:Slice;
qb:sliceStructure eg:sliceByRegion ;
eg:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
sdmx-dimension:sex sdmx-code:sex-M ;
qb:observation eg:o1b, eg:o2b; eg:o3b, ... .
eg:o1b a qb:Observation;
qb:dataSet eg:dataset-le2 ;
eg:refArea admingeo:newport_00pr ;
eg:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
sdmx-dimension:sex sdmx-code:sex-M ;
eg:lifeExpectancy 76.7 ;
.
eg:o2b a qb:Observation;
qb:dataSet eg:dataset-le2 ;
eg:refArea admingeo:cardiff_00pt ;
eg:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
sdmx-dimension:sex sdmx-code:sex-M ;
eg:lifeExpectancy 78.7 ;
.
eg:o3b a qb:Observation;
qb:dataSet eg:dataset-le2 ;
eg:refArea admingeo:monmouthshire_00pp ;
eg:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
sdmx-dimension:sex sdmx-code:sex-M ;
eg:lifeExpectancy 76.6 ;
.
...
Note that here we are still repeating the dimension values on the individual observations.
This flattened representation means that a consuming application can still query
for observed values uniformly without having to first parse the data structure
definition and search for slice definitions. If it is desired, this redundancy can be reduced
by declaring different attachment levels for the dimensions. For example:
eg:dsd-le-slice3 a qb:DataStructureDefinition;
qb:component
[qb:dimension eg:refArea; qb:order 1];
[qb:dimension eg:refPeriod; qb:order 2; qb:componentAttachment qb:Slice];
[qb:dimension sdmx-dimension:sex; qb:order 3; qb:componentAttachment qb:Slice];
[qb:measure eg:lifeExpectancy];
[qb:attribute sdmx-attribute:unitMeasure; qb:componentAttachment qb:DataSet;] ;
qb:sliceKey eg:sliceByRegion .
eg:dataset-le3 a qb:DataSet;
rdfs:label "Life expectancy"@en;
rdfs:comment "Life expectancy within Welsh Unitary authorities - extracted from Stats Wales"@en;
qb:structure eg:dsd-le-slice3 ;
sdmx-attribute:unitMeasure <http://dbpedia.org/resource/Year> ;
qb:slice eg:slice3 ;
.
eg:slice3 a qb:Slice;
qb:sliceStructure eg:sliceByRegion ;
eg:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
sdmx-dimension:sex sdmx-code:sex-M ;
qb:observation eg:o1c, eg:o2c; eg:o3c, ... .
eg:o1c a qb:Observation;
qb:dataSet eg:dataset-le3 ;
eg:refArea admingeo:newport_00pr ;
eg:lifeExpectancy 76.7 ;
.
eg:o2c a qb:Observation;
qb:dataSet eg:dataset-le3 ;
eg:refArea admingeo:cardiff_00pt ;
eg:lifeExpectancy 78.7 ;
.
eg:o3c a qb:Observation;
qb:dataSet eg:dataset-le3 ;
eg:refArea admingeo:monmouthshire_00pp ;
eg:lifeExpectancy 76.6 ;
.
...
The Data Cube vocabulary allows slices to be nested. We can declare
multiple slice keys in a DSD and it is possible for one slice key to
be a narrower version of another, represented using qb:subSlice. In that case, when providing non-flattened
data with dimensions attached to the slice level, then
it is permissible to nest the qb:Slice instances and so
further reduce the duplication stating of dimension values. However,
in general flat representations are recommended to simplify data consumption.
Some tool chains may support (dynamic or static) generation flattened representations from
abbreviated data sets.
8. Concept schemes and code lists
The values for dimensions within a data set must be unambiguously
defined. They may be typed values (e.g. xsd:dateTime for time instances)
or codes drawn from some code list. Similarly, many attributes
used in data sets represent coded values from some controlled term list rather
than free text descriptions. In the Data Cube vocabulary such codes are
represented by URI references in the usual RDF fashion.
Sometimes
appropriate URI sets already exist for the relevant dimensions (e.g. the representations
of area and time periods in our running example). In other cases the data set being
converted may use controlled terms from some scheme which does not yet have
associated URIs. In those cases we recommend use of SKOS, representing
the individual code values using skos:Concept and the overall
set of admissible values using skos:ConceptScheme.
We illustrate this with an example drawn from the translation of the SDMX COG
code list for gender, as used already in our worked example. The relevant subset of this code list is:
sdmx-code:sex a skos:ConceptScheme;
skos:prefLabel "Code list for Sex (SEX) - codelist scheme"@en;
rdfs:label "Code list for Sex (SEX) - codelist scheme"@en;
skos:notation "CL_SEX";
skos:note "This code list provides the gender."@en;
skos:definition <http://sdmx.org/wp-content/uploads/2009/01/02_sdmx_cog_annex_2_cl_2009.pdf> ;
rdfs:seeAlso sdmx-code:Sex ;
sdmx-code:sex skos:hasTopConcept sdmx-code:sex-F ;
sdmx-code:sex skos:hasTopConcept sdmx-code:sex-M .
sdmx-code:Sex a rdfs:Class, owl:Class;
rdfs:subClassOf skos:Concept ;
rdfs:label "Code list for Sex (SEX) - codelist class"@en;
rdfs:comment "This code list provides the gender."@en;
rdfs:seeAlso sdmx-code:sex .
sdmx-code:sex-F a skos:Concept, sdmx-code:Sex;
skos:topConceptOf sdmx-code:sex;
skos:prefLabel "Female"@en ;
skos:notation "F" ;
skos:inScheme sdmx-code:sex .
sdmx-code:sex-M a skos:Concept, sdmx-code:Sex;
skos:topConceptOf sdmx-code:sex;
skos:prefLabel "Male"@en ;
skos:notation "M" ;
skos:inScheme sdmx-code:sex .
skos:prefLabel is used to give a name to the code,
skos:note gives a description and skos:notation can be used
to record a short form code which might appear in other serializations.
The SKOS specification [SKOS] recommends the generation of a custom datatype for
each use of skos:notation but here the notation is not intended for use
within RDF encodings, it merely documents the notation used in other representations
(which do not use such a datatype).
It is convenient and good practice when developing a code list to also
create an Class to denote all the codes within the code
list, irrespective of hierarchical structure. This allows the range of an
qb:ComponentProperty to be defined by using rdfs:range
which then permits standard RDF closed-world checkers to validate use of the
code list without requiring custom SDMX-RDF-aware tooling. We do that in the
above example by using the common convention that the class name is the
same as that of the concept scheme but with leading upper case.
This code list can then be associated with a coded property, such as a dimension:
eg:sex a sdmx:DimensionProperty, sdmx:CodedProperty;
qb:codeList sdmx-code:sex ;
rdfs:range sdmx-code:Sex .
Explicitly declaring the code list using qb:codeList
is not mandatory but can be helpful in those cases where a concept scheme has been defined.
In some cases code lists have a hierarchical structure. In particular, this is
used in SDMX when the data cube includes aggregations of data values
(e.g. aggregating a measure across geographic regions).
Hierarchical code lists lists should be represented using the
skos:narrower relationship to link from the skos:hasTopConcept
codes down through the tree or lattice of child codes.
In some publishing tool chains the corresponding transitive closure
skos:narrowerTransitive will be automatically inferred.
The use of skos:narrower makes it possible to declare new
concept schemes which extend an existing scheme by adding additional aggregation layers on top.
All items are linked to the scheme via skos:inScheme.
A. Namespaces used in this document
| prefix |
namespace URI |
vocabulary |
| rdf |
http://www.w3.org/1999/02/22-rdf-syntax-ns# |
RDF core |
| rdfs |
http://www.w3.org/2000/01/rdf-schema# |
RDF Schema |
| skos |
http://www.w3.org/2004/02/skos/core# |
Simple Knowledge Organization System |
| foaf |
http://xmlns.com/foaf/0.1/ |
Friend Of A Friend |
| void |
http://rdfs.org/ns/void# |
Vocabulary of Interlinked Datasets |
| scovo |
http://purl.org/NET/scovo# |
Statistical Core Vocabulary |
| dc |
http://purl.org/dc/elements/1.1/ |
Dublin Core |
| qb |
http://purl.org/linked-data/cube# |
The Data Cube vocabulary |
B. Vocabulary reference
B.1 DataSets
-
Class:
qb:DataSet
Sub class of:
qb:Attachable
Equivalent to:
scovo:Dataset
- Represents a collection of observations, possibly organized into various slices, conforming to some common dimensional structure.
B.2 Observations
-
Class:
qb:Observation
Sub class of:
qb:Attachable
Equivalent to:
scovo:Item
- A single observation in the cube, may have one or more associated measured values
-
Property:
qb:dataSet
(
qb:Observation
->
qb:DataSet
)
- indicates the data set of which this observation is a part
-
Property:
qb:observation
(
qb:Slice
->
qb:Observation
)
- indicates a observation contained within this slice of the data set
B.3 Slices
-
Class:
qb:Slice
Sub class of:
qb:Attachable
- Denotes a subset of a DataSet defined by fixing a subset of the dimensional values, component properties on the Slice
-
Property:
qb:slice
(
qb:DataSet
->
qb:Slice
)
- Indicates a subset of a DataSet defined by fixing a subset of the dimensional values
-
Property:
qb:subSlice
(
qb:Slice
->
qb:Slice
)
- Indicates a narrower slice which has additional fixed dimensional values, for example a time-series slice might a subSlice of a slice which spans both time and geographic area
B.4 Dimensions, Attributes, Measures
-
Class:
qb:Attachable
- Abstract superclass for everything that can have attributes and dimensions
-
Class:
qb:ComponentProperty
Sub class of:
rdf:Property
- Abstract super-property of all properties representing dimensions, attributes or measures
-
Class:
qb:DimensionProperty
Sub class of:
qb:ComponentProperty
qb:CodedProperty
- The class of components which represent the dimensions of the cube
-
Class:
qb:AttributeProperty
Sub class of:
qb:ComponentProperty
- The class of components which represent attributes of observations in the cube, e.g. unit of measurement
-
Class:
qb:MeasureProperty
Sub class of:
qb:ComponentProperty
- The class of components which represent the measured value of the phenomenon being observed
-
Class:
qb:CodedProperty
Sub class of:
qb:ComponentProperty
- Superclass of all coded ComponentProperties
B.5 Reusable general purpose component properties
-
Property:
qb:measureType
(
->
qb:MeasureProperty
)
- Generic measure dimension, the value of this dimension indicates which measure (from the set of measures in the DSD) is being given by the obsValue (or other primary measure)
B.6 Data Structure Definitions
-
Class:
qb:DataStructureDefinition
Sub class of:
qb:ComponentSet
- Defines the structure of a DataSet or slice
-
Property:
qb:structure
(
qb:DataSet
->
qb:DataStructureDefinition
)
- indicates the structure to which this data set conforms
-
Property:
qb:component
(
qb:DataStructureDefinition
->
qb:ComponentSpecification
)
- indicates a component specification which is included in the structure of the dataset
B.7 Component specifications - for qualifying component use in a DSD
-
Class:
qb:ComponentSpecification
Sub class of:
qb:ComponentSet
- Used to define properties of a component (attribute, dimension etc) which are specific to its usage in a DSD.
-
Class:
qb:ComponentSet
- Abstract class of things which reference one or more ComponentProperties
-
Property:
qb:componentProperty
(
qb:ComponentSet
->
qb:ComponentProperty
)
- indicates a ComponentProperty (i.e. attribute/dimension) expected on a DataSet, or a dimension fixed in a SliceKey
-
Property:
qb:order
(
qb:ComponentSpecification
->
xsd:int
)
- indicates a priority order for the components of sets with this structure, used to guide presentations - lower order numbers come before higher numbers, un-numbered components come last
-
Property:
qb:componentRequired
(
qb:ComponentSpecification
->
xsd:boolean
)
- Indicates whether a component property is required (true) or optional (false) in the context of a DSD or MSD
-
Property:
qb:componentAttachment
(
qb:ComponentSpecification
->
rdfs:Class
)
- Indicates the level at which the component property should be attached, this might an qb:DataSet, qb:Slice or qb:Observation, or a qb:MeasureProperty.
-
Property:
qb:dimension
(
->
qb:DimensionProperty
; sub property of:
qb:componentProperty
)
- An alternative to qb:componentProperty which makes explicit that the component is a dimension
-
Property:
qb:measure
(
->
qb:MeasureProperty
; sub property of:
qb:componentProperty
)
- An alternative to qb:componentProperty which makes explicit that the component is a measure
-
Property:
qb:attribute
(
->
qb:AttributeProperty
; sub property of:
qb:componentProperty
)
- An alternative to qb:componentProperty which makes explicit that the component is a attribute
-
Property:
qb:measureDimension
(
->
qb:DimensionProperty
; sub property of:
qb:componentProperty
)
- An alternative to qb:componentProperty which makes explicit that the component is a measure dimension
B.8 Slice definitions
-
Class:
qb:SliceKey
Sub class of:
qb:ComponentSet
- Denotes a subset of the component properties of a DataSet which are fixed in the corresponding slices
-
Property:
qb:sliceStructure
(
qb:Slice
->
qb:SliceKey
)
- indicates the sub-key corresponding to this slice
-
Property:
qb:sliceKey
(
qb:DataSet
->
qb:SliceKey
)
- indicates a slice key which is used for slices in this dataset
B.9 Concepts
-
Property:
qb:concept
(
qb:ComponentProperty
->
skos:Concept
)
- gives the concept which is being measured or indicated by a ComponentProperty
-
Property:
qb:codeList
(
qb:CodedProperty
->
skos:ConceptScheme
)
- gives the code list associated with a CodedProperty
C. Acknowledgements
This work is based on a collaboration that was initiated in a
workshop on Publishing statistical datasets in SDMX and the semantic
web, hosted by ONS in Sunningdale, United Kingdom in February 2010 and
continued at the ODaF 2010 workshop in Tilburg. The authors would like
to thank all the participants at those workshops for their input into
this work but especially Arofan Gregory for his patient
explanations of SDMX and insight in the need and requirements
for a core Data Cube representation.
The authors would also like to thank John Sheridan for his comments,
suggestions and support for this work.
D. Open issues
Based on early use experiences with the vocabulary the working group is considering
some clarifications and modifications to the specification. Each of
the candidate areas under consideration are listed as issues
below. Note that there is, as yet, no commitment that all (or indeed any) of these areas
will be addressed by the working group.
Specify additional well-formedness criteria to which
cube-publishers should adhere to facilitate tool interoperability.
Issue-30:
Declaring relations between cubes
Consider extending the vocabulary to support declaring
relations between data cubes (or between measures within a cube).
Issue-31:
Supporting aggregation for other than SKOS hierarchies
The Data Cube vocabulary allows hierarchical code lists to be
used as dimensions values by means of SKOS. Consider whether to
extend this to support use of other hierarchical relations
(e.g. geo-spatial containment) without requiring mapping to SKOS.
Issue-32:
Relationship to ISO 19156 - Observations & Measurements
One use case for the Data Cube vocabulary is for the publication
of observational, sensor network and forecast data
sets. Existing standards for such publication include OGC
Observations & Measurements (ISO 19156). There are multiple ways
that Data Cube can be mapped to the logical model of O&M.
Consider making an explicit statement of the ways in which Data
Cube can be related to O&M as guidance for users seeking to
work with both specifications.
Experience with Data Cube has shown that publishers often wish
to publish slices comprising arbitrary collections of
observations.
Consider supporting this usage, either through a clarification
of qb:Slice or through an additional collection mechanism.
Issue-34:
Clarify or drop qb:subslice
Use of qb:subslice in abbreviated datasets can result
in ambiguity. Consider
clarifying or deprecating qb:subslice.
Bring all references into W3C style
E. References
E.1 Normative references
No normative references.