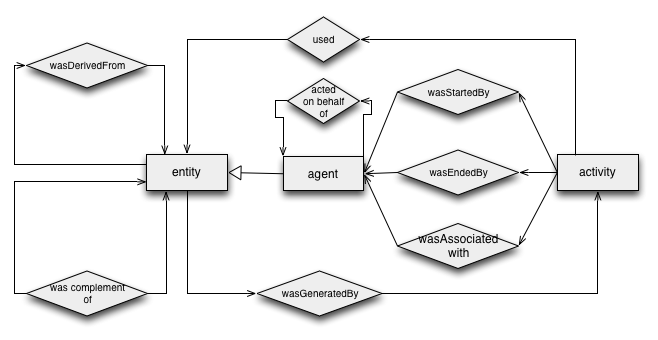
5.3.3.1 Responsibility Record
To promote take-up, PROV-DM offers a mild version of responsibility
in the form of a relation to represent when an agent acted on another
agent's behalf. So in the example of someone running a mail program,
the program is an agent of that activity and the person is also an
agent of the activity, but we would also add that the mail software
agent is running on the person's behalf. In the other example, the
student acted on behalf of his supervisor, who acted on behalf of the
department chair, who acts on behalf of the university, and all those
agents are responsible in some way for the activity to take place but
we don't say explicitly who bears responsibility and to what
degree.
We could also say that an agent can act on behalf of several other
agents (a group of agents). This would also make possible to
indirectly reflect chains of responsibility. This also indirectly
reflects control without requiring that control is explicitly
indicated. In some contexts there will be a need to represent
responsibility explicitly, for example to indicate legal
responsibility, and that could be added as an extension to this core
model. Similarly with control, since in particular contexts there
might be a need to define specific aspects of control that various
agents exert over a given activity.
Given an activity association record wasAssociatedWith(a,ag2,attrs),
a responsibility record, written actedOnBehalfOf(id,ag2,ag1,a,attrs) in PROV-ASN, has the following constituents:
- id: an optional identifier id identifying the responsibility record;
- subordinate: an identifier ag2 for an agent record, which represents an agent associated with an activity, acting on behalf of the responsible agent;
- responsible: an identifier ag1 for an agent record, which represents the agent on behalf of which the subordinate agent ag2 acts;
- activity: an optional identifier a of an activity record for which the responsibility record holds;
- attributes: an optional set of attribute-value pairs attrs that describe the modalities of this relation.
responsibilityRecord ::=
actedOnBehalfOf
(
identifier,
agIdentifier,
agIdentifier,
aIdentifier
optional-attribute-values
)
In the following example, a programmer, a researcher and a funder agents are asserted. The porgrammer and researcher are associated with a workflow activity. The programmer acts on behalf of the researcher (delegation) encoding the commands specified by the researcher; the researcher acts on behalf of the funder, who has an contractual agreement with the researcher.
activity(a,[prov:type="workflow"])
agent(ag1,[prov:type="programmer"])
agent(ag2,[prov:type="researcher"])
agent(ag3,[prov:type="funder"])
wasAssociatedWith(a,ag1,[prov:role="loggedInUser"])
wasAssociatedWith(a,ag2)
actedOnBehalfOf(ag1,ag2,a,[prov:type="delegation"])
actedOnBehalfOf(ag2,ag3,a,[prov:type="contract"])
5.3.3.2 Derivation Record
In PROV-DM, a derivation record is a representation that some entity is transformed from, created from, or affected by another entity in the world.
Examples of derivation include the transformation of a canvas into a painting, the transportation of a person from London to New-York, the transformation of a relational table into a linked data set, and the melting of ice into water.
According to Section Conceptualization, for an entity to be transformed from, created from, or affected by another in some way, there must be some underpinning activities performing the necessary actions resulting in such a derivation.
However, asserters may not assert or have knowledge of these activities and associated details: they may not assert or know their number, they may not assert or know their identity, they may not assert or know the attributes characterizing how the relevant entities are used or generated. To accommodate the varying circumstances of the various asserters, PROV-DM allows more or less precise records of derivation to be asserted. Hence, PROV-DM uses the terms precise and imprecise to characterize the different kinds of derivation record. We note that the derivation itself is exact (i.e., deterministic, non-probabilistic), but it is its description, expressed in a derivation record, that may be imprecise.
The lack of precision may come from two sources:
- the number of activities that underpin a derivation is not asserted or known, or
- any of the other details that are involved in the derivation is not asserted or known; these include activity identities, generation and usage records, and their attributes.
Hence, given a precision axis, with values precise and imprecise, and an activity axis, with values one activity and n activities, we can then form a matrix of possible derivations, precise or imprecise, or corresponding to one activity or n activities.
Out of the four possibilities, PROV-DM offers three forms of derivation, while the fourth one is not meaningful. The following table summarises names for the three kinds of derivation, which we then explain.
- The asserter asserts that derivation is due to exactly one activity, and all the details are asserted. We call this a precise-1 derivation record.
- The asserter asserts that derivation is due to exactly one activity, but other details, whether known or unknown, are not asserted. We call this an imprecise-1 derivation record.
- The asserter does not know how many activities are involved in the derivation, and other details, whether known or unknown, are also not asserted. We call this an imprecise-n derivation record.
We note that the fourth theoretical case of a precise derivation, where the number of activities is not known or asserted cannot occur.
The three kinds of derivation records are successively introduced. To minimize the number of relation types in PROV-DM, we introduce a PROV-DM reserved attribute steps, which allows us to distinguish the various derivation types.
A precise-1 derivation record, written wasDerivedFrom(id, e2, e1, a, g2, u1, attrs) in PROV-ASN, contains:
- id: an optional identifier id identifying the derivation record;
- generatedEntity: the identifier e2 of an entity record, which is a representation of the generated entity;
- usedEntity: the identifier e1 of an entity record, which is a representation of the used entity;
- activity: an identifier a of an activity record, which is a representation of the activity using and generating the above entities;
- generation: an identifier g2 of the generation record pertaining to e2 and a;
- usage: an identifier u1 of the usage record pertaining to e1 and a.
- attributes: an optional set of attribute-value pairs attrs that describe the modalities of this derivation, optionally including the attribute-value pair prov:steps="1".
It is optional to include the attribute prov:steps in a precise-1 derivation since the record already refers to the one and only one activity underpinning the derivation.
An imprecise-1 derivation record, written wasDerivedFrom(id, e2,e1, attrs) in PROV-ASN, contains:
- id: an optional identifier id identifying the derivation record;
- generatedEntity: the identifier e2 of an entity record, which is a representation of the generated entity;
- usedEntity: the identifier e1 of an entity record, which is a representation of the used entity.
- attributes: a set of attribute-value pairs attrs that describe the modalities of this derivation; it must include the attribute-value pair prov:steps="1".
An imprecise-1 derivation must include the attribute prov:steps, since it is the only means to distinguish this record from an imprecise-n derivation record.
An imprecise-n derivation record, written wasDerivedFrom(id, e2, e1, attrs) in PROV-ASN, contains:
- id: an optional identifier id identifying the derivation record;
- generatedEntity: the identifier e2 of an entity record, which is a representation of the generated entity;
- usedEntity: the identifier e1 of an entity record, which is a representation of the used entity.
- attributes: an optional set of attribute-value pairs attrs that describe the modalities of this derivation; it optionally includes the attribute-value pair prov:steps="n".
It is optional to include the attribute prov:steps in an imprecise-n derivation record. It defaults to prov:steps="n".
None of the three kinds of derivation is defined to be transitive. Domain-specific specializations of these derivations may be defined in such a way that the transitivity property holds.
In PROV-ASN, a derivation record's text matches the derivationRecord production of the grammar defined in this specification document.
derivationRecord ::=
precise-1-derivationRecord
| imprecise-1-derivationRecord
| imprecise-n-derivationRecord
precise-1-derivationRecord ::=
wasDerivedFrom
(
identifier,
eIdentifier
,
eIdentifier
,
aIdentifier
,
gIdentifier
,
uIdentifier
optional-attribute-values
)
imprecise-1-derivationRecord::=
wasDerivedFrom
(
identifier,
eIdentifier
,
eIdentifier
,
attribute-values
)
imprecise-n-derivationRecord::=
wasDerivedFrom
(
identifier,
eIdentifier
,
eIdentifier
optional-attribute-values
)
The grammar should make it clear that attribute prov:steps="1" is required for imprecise-1-derivationRecord.
PM: suggestion -- remove the distinction between imprecise-1 and imprecise-n in the grammar and instead explain that the qualification (1 vs n) is through attribute prov:steps.
The following assertions state the existence of derivations.
wasDerivedFrom(e5,e3,a4,g2,u2,[])
wasDerivedFrom(e5,e3,a4,g2,u2,[prov:steps="1"])
wasDerivedFrom(e3,e2,[prov:steps="1"])
wasDerivedFrom(e2,e1,[])
wasDerivedFrom(e2,e1,[prov:steps="n"])
The first two are precise-1 derivation records expressing that the activity represented by the activity a4, by
using the entity denoted by e3 according to usage record u2
derived the
entity denoted by e5 and generated it according to generation record
g2.
The third record is an imprecise-1 derivation, which is similar for e3 and e2, but it leaves the activity record and associated attributes implicit. The fourth and fifth records are imprecise-n derivation records between e2 and e1, but no information is provided as to the number and identity of activities underpinning the derivation.
An precise-1 derivation record is richer than an imprecise-1 derivation record, itself, being more informative that an imprecise-n derivation record. Hence, the following implications hold.
Given two entity records denoted by e1 and e2, if the assertion wasDerivedFrom(e2, e1, a, g2, u1, attrs)
holds for some generation record identified by g2, and usage record identified by u1, then wasDerivedFrom(e2,e1,[prov:steps="1"] ∪ attrs) also holds.
Given two entity records denoted by e1 and e2, if the assertion wasDerivedFrom(e2, e1, [prov:steps="1"] ∪ attrs)
holds, then wasDerivedFrom(e2,e1,attrs) also holds.
If a derivation record holds for e2 and e1, then
this means that the entity represented by entity record identified by e1 has an influence on the entity represented entity record identified by e2,
which at the minimum implies temporal ordering, specified as follows.
First, we consider one-activity derivations.
Given an activity record identified by
a, entity records identified by
e1 and
e2, generation record identified by
g2, and usage record identified by
u1,
if the record
wasDerivedFrom(e2,e1,a,g2,u1,attrs)
or
wasDerivedFrom(e2,e1,[prov:steps="1"] ∪ attrs) holds,
then
the following temporal constraint holds:
the
usage
of entity denoted by
e1 precedes the
generation of
the entity denoted by
e2.
Then, imprecise-n derivations.
Given two entity records denoted by
e1 and
e2,
if the record
wasDerivedFrom(e2,e1,[prov:steps="n"] ∪ attrs)
holds,
then the following temporal constraint holds:
the
generation event of the entity denoted by
e1 precedes the
generation event of
the entity denoted by
e2.
Note that temporal ordering is between generations of e1
and e2, as opposed to precise-1 derivation,
which implies temporal ordering between the usage of e1 and
generation of e2. Indeed, in the case of
imprecise-n derivation, nothing is known about the usage of e1,
since there is no associated activity.
The imprecise-1 derivation has the same meaning as the precise-1
derivation, except that an activity
is known to exist, though it does not need to be
asserted. This is formalized by the following inference rule,
referred to as activity introduction:
If wasDerivedFrom(e2,e1) holds,
then there exist an activity record identified by
a, a usage record identified by
u, and a generation record identified by
g
such that:
activity(a,aAttrs)
wasGeneratedBy(g,e2,a,gAttrs)
used(u,a,e1,uAttrs)
for sets of attribute-value pairs
gAttrs,
uAttrs, and
aAttrs.
Note that inferring derivation from usage and generation does not hold
in general. Indeed, when a generation wasGeneratedBy(g, e2, a, attrs2)
precedes used(u, a, e1, attrs1), for
some e1, e2, attrs1, attrs2, and a, one
cannot infer derivation wasDerivedFrom(e2, e1, a, g, u)
or wasDerivedFrom(e2,e1) since
of e2 cannot possibly be determined by
of e1, given the creation of e2 precedes the use
of e1.
The following property holds for account where
generation-unicity applies. Move it to separate section with all
related material.
A further inference is permitted from the imprecise-1 derivation record:
Given an activity record identified by pe, entity records identified by e1 and e2, and set of attribute-value pairs attrs2,
if wasDerivedFrom(e2,e1, [prov:steps="1"]) and wasGeneratedBy(e2,pe,attrs2) hold, then used(pe,e1,attrs1) also holds
for some set of attribute-value pairs attrs1.
This inference is justified by the fact that the entity represented by entity record identified by e2 is generated by at most one activity in a given account (see generation-unicity). Hence, this activity record is also the one referred to in the usage record of e1.
We note that the converse inference, does not hold.
From wasDerivedFrom(e2,e1) and used(pe,e1), one cannot
derive wasGeneratedBy(e2,pe,attrs2) because identifier e1 may occur in usage records referring to
many activity records, but they may not be referred to in generation records containing identifier e2.
Should derivation have a time? Which time? This is
ISSUE-43.
5.3.3.3 Complementarity Record
While the working group recognizes the importance of the complementarity record concept, its name and its exact semantics are still being discussed.
A complementarity record is a relationship between two entities stated to have compatible characterization over some continuous interval between two events.
The rationale for introducing this relationship is that in general, at any given time, for an entity in the world, there may be multiple ways of characterizing it, and hence multiple representations can be asserted by different asserters. In the example that follows, suppose thing "Royal Society" is represented by two asserters, each using a different set of attributes. If the asserters agree that both representations refer to "The Royal Society", the question of whether any correspondence can be established between the two representations arises naturally. This is particularly relevant when (a) the sets of attributes used by the two representations overlap partially, or (b) when one set is subsumed by the other. In both these cases, we have a situation where each of the two asserters has a partial view of "The Royal Society", and establishing a correspondence between them on the shared attributes is beneficial, as in case (a) each of the two representation complements the other, and in case (b) one of the two (that with the additional attributes) complements the other.
This intuition is made more precise by considering the entities that form the representations of entities at a certain point in time.
An entity record represents, by means of attribute-value pairs, a thing and its situation in the world, which remain constant over a characterization interval.
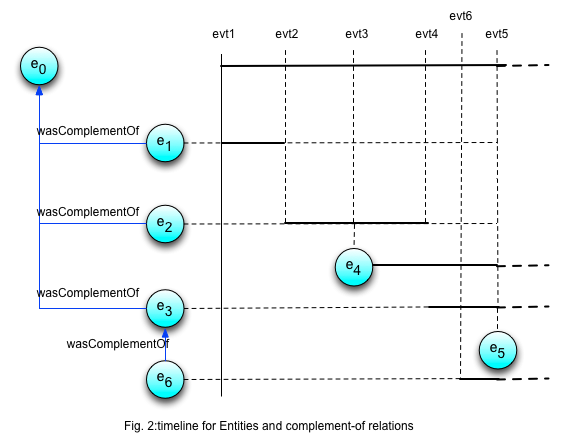
As soon as the thing's situation changes, this marks the end of the characterization interval for the entity record representing it. The thing's novel situation is represented by an attribute with a new value, or an entirely different set of attribute-value pairs, embodied in another entity record, with a new characterization interval. Thus, if we overlap the timelines (or, more generally, the sequences of value-changing events) for the two entities, we can hope to establish correspondences amongst the entity records that represent them at various points along that events line. The figure below illustrates this intuition.
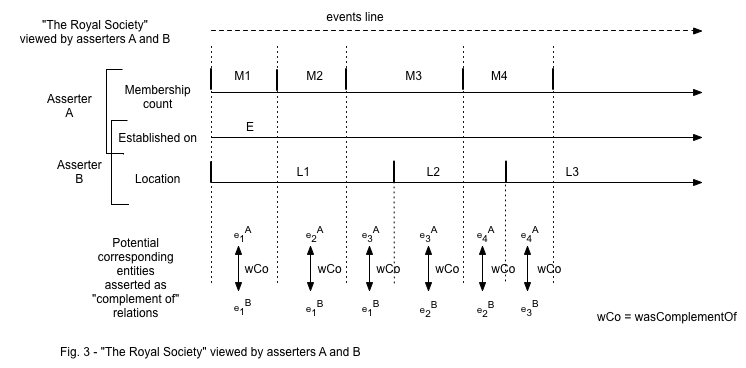
Relation complement-of between two entity records is intended to capture these correspondences, as follows. Suppose entity records A and B share a set P of attributes, and each of them has other attributes in addition to P. If the values assigned to each attribute in P are compatible between A and B, then we say that A is-complement-of B, and B is-complement-of A, in a symmetrical fashion. In the particular case where the set P of attributes of B is a strict superset of A's attributes, then we say that B is-complement-of A, but in this case the opposite does not hold. In this case, the relation is not symmetric. (as a special case, A and B may not share any attributes at all, and yet the asserters may still stipulate that they are representing the same thing "Royal Society". The symmetric relation may hold trivially in this case).
The term compatible used above means that a mapping can be established amongst the values of attributes in P and found in the two entity expession. This generalizes to the case where attribute sets P1 and P2 of A, and B, respectively, are not identical but they can be mapped to one another. The simplest case is the identity mapping, in which A and B share attribute set P, and furthermore the values assigned to attributes in P match exactly.
It is important to note that the relation holds only for the characterization intervals of the entity expessions involved As soon as one attribute changes value in one of them, new correspondences need to be found amongst the new entities. Thus, the relation has a validity span that can be expressed in terms of the event lines of the entity.
A complementarity record is written wasComplementOf(e2,e1), where e1 and e2 are two identifiers denoting entity records.
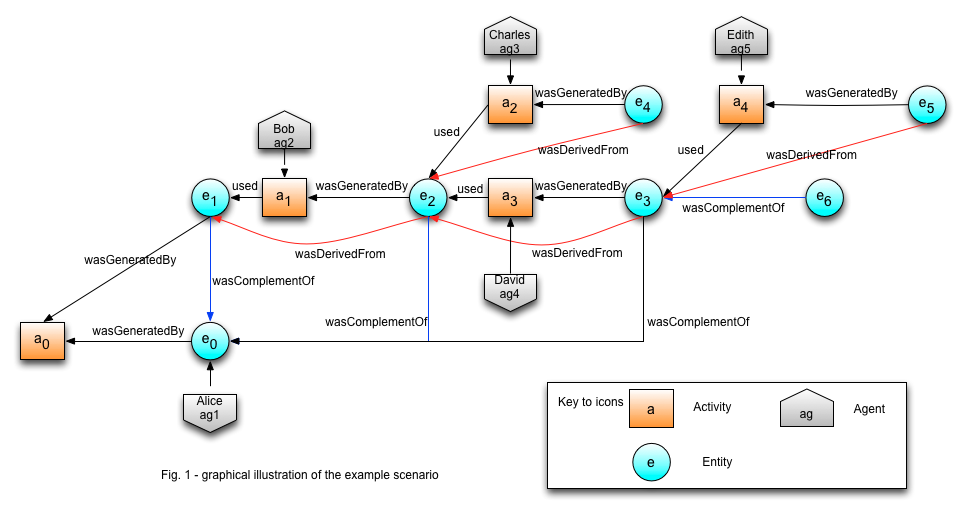
The following example illustrates the entity "Royal Society"and its perspectives at various points in time.
entity(rs,[ex:created=1870])
entity(rs_l1,[prov:location="loc2"])
entity(rs_l2,[prov:location="The Mall"])
entity(rs_m1,[ex:membership=250, ex:year=1900])
entity(rs_m2,[ex:membership=300, ex:year=1945])
entity(rs_m3,[ex:membership=270, ex:year=2010])
wasComplementOf(rs_m3, rs_l2)
wasComplementOf(rs_m2, rs_l1)
wasComplementOf(rs_m2, rs_l2)
wasComplementOf(rs_m1, rs_l1)
wasComplementOf(rs_m3, rs)
wasComplementOf(rs_m2, rs)
wasComplementOf(rs_m1, rs)
wasComplementOf(rs_l1, rs)
wasComplementOf(rs_l2, rs)
An assertion "wasComplementOf(B,A)" holds over the temporal intersection of A and B,
only if:
- if a mapping can be established from an attribute X of entity record identified by B to an attribute Y of entity record identified by A, then the values of A and B must be consistent with that mapping;
- entity record identified by B has some attribute that entity record identified by A does not have.
The complementarity relation is not transitive. Let us consider identifiers e1, e2, and e3 identifying three entity records such that
wasComplementOf(e3,e2) and wasComplementOf(e2,e1) hold. The record wasComplementOf(e3,e1) may not hold because the characterization intervals of the denoted entity records may not overlap.
In PROV-ASN, a complementarity record's text matches the complementarityRecord production of the grammar defined in this specification document.
complementarityRecord ::=
wasComplementOf
(
eIdentifier
,
eIdentifier
optional-attribute-values
)
|
wasComplementOf
(
eIdentifier
,
accIdentifier
,
eIdentifier
,
accIdentifier
optional-attribute-values
)
An entity record identifier can optionally be accompanied by an account identifier. When this is the case, it becomes possible to link two entity record identifiers that are appear in different accounts. (In particular, the entity record identifiers in two different account are allowed to be the same.). When account identifiers are not available, then the linking of entity records through complementarity can only take place within the scope of a single account.
In the following example, the same description of the Royal Society is structured according to two different accounts. In the second account, we find a complementarity record linking rs_m1 in account ex:acc2 to
rs in account ex:acc1.
account(ex:acc1,
http://example.org/asserter1,
...
entity(rs,[ex:created=1870])
...
)
account(ex:acc2,
http://example.org/asserter2,
...
entity(rs_m1,[ex:membership=250, ex:year=1900])
...
wasComplementOf(rs_m1, ex:acc2, rs, ex:acc1)
)
It is suggested that the name 'wasComplementOf' does not capture the meaning of this relation adequately. No concrete suggestion has been made so far.
Furthermore, there is a suggestion that an alternative relation that is transitive may also be useful.
This is raised in the following
email.
A discussion on alternative definition of wasComplementOf has not reached a satisfactory conclusion yet. This is
ISSUE-29