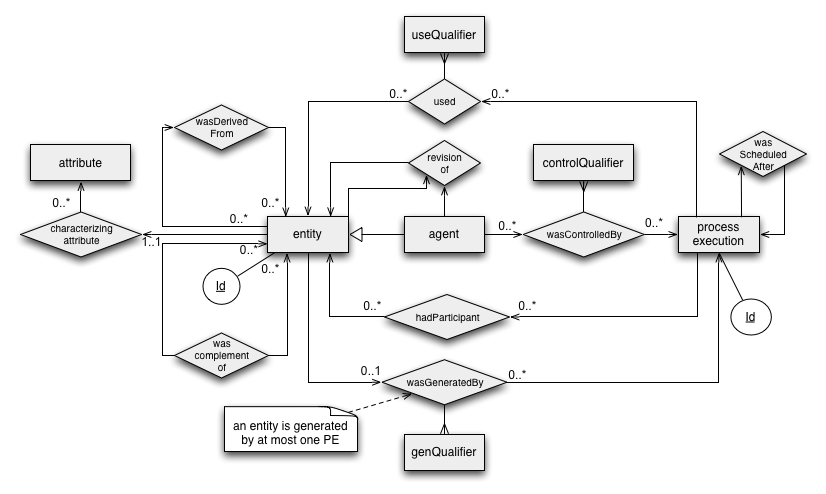
This section contains the normative specification of PROV-DM, the PROV data model.
5.2 Element
This section describes all the PROV-ASN expressions conformant to the elementExpression production of the grammar.
5.2.1 Entity
In PROV-DM, an entity expression is a representation of an identifiable characterized thing.
In PROV-ASN, an entity expression's text matches the entityExpression production of the grammar defined in this specification document.
entityExpression :=
entity
(
identifier
,
[
attribute-values
]
)
attribute-values :=
attribute-value
| attribute-value , attribute-values
attribute-value :=
attribute
=
Literal
An instance of an entity expression, noted entity(id, [ attr1=val1, ...]) in PROV-ASN:
- contains an identifier id identifying a characterized thing;
- contains a set of attribute-value pairs [ attr1=val1, ...], representing this characterized thing's situation in the world.
The assertion of an instance of an entity expression, entity(id, [ attr1=val1, ...]), states, from a given asserter's viewpoint, the existence of an identifiable characterized thing, whose situation in the world is represented by the attribute-value pairs, which remain unchanged during a characterization interval, i.e. a continuous interval between two events in the world.
The following entity assertion,
entity(e0, [ type="File", location="/shared/crime.txt", creator="Alice" ])
states the existence of a thing of type File and location /shared/crime.txt, and creator alice, denoted by identifier e0, during some characterization interval.
Further considerations:
- If an asserter wishes to characterize a thing with the same attribute-value pairs over several intervals, then they are required to assert multiple entity expressions, each with its own identifier (so as to allow potential dependencies between the various entity expressions to be expressed).
- There is no assumption that the set of attributes is complete and that the attributes are independent/orthogonal of each other.
- A characterization interval may collapse into a single instant.
- An entity assertion
is about a characterized thing, whose situation in the world may be variant.
An entity assertion is made at a particular point and is invariant, in the sense that
its attributes are assigned a value as part of that assertion.
- Activities are not represented by entities, but instead by process
executions, as explained below.
The group is still discussing the need for characterizing attributes in entity expressions. At heart: when it comes to exchanging provenance information, why do we *need*
to know exactly what makes one entity a constrained view of another.
This is raised in the following
email.
The characterization interval of an entity expression is currently implicit. Making it explicit would allow us to define wasComplementOf more precisely. It would also allow us to address
ISSUE-108.
Beginning and end of characterization interval could be expressed by attributes (similarly to process executions).
5.2.2 Process Execution
In PROV-DM, a process execution expression is a representation an identifiable activity, which performs a piece of work.
In PROV-ASN, a process execution expression's text matches the processExecutionExpression production of the grammar defined in this specification document.
processExecutionExpression :=
processExecution
(
identifier
[ ,
recipeLink ]
,
[ time ]
,
[ time ]
,
other-attribute-values
)
other-attribute-values := attribute-values
The activity that a process execution expression is a representation of has a duration, delimited by its start and its end events; hence, it occurs over an interval delimited by two events. However, a process execution expression need not mention time information, nor duration, because they may not be known.
Such start and end times constitute attributes of an activity, where the interpretation of attribute in the context of a process execution expression is the same as the interpretation of attribute for entity expression: a process execution expression's attribute remains constant for the duration of the activity it represents. Further characteristics of the activity in the world can be represented by other attribute-value pairs, which must also remain unchanged during the activity duration.
An instance of a process execution expression, written processExecution(id, rl, st, et, [ attr1=val1, ...]) in PROV-ASN:
- contains an identifier id;
- may contain a recipe link rl, which consists of a domain specific description of the activity;
- may contain a start time st;
- may contain an end time et;
- contains a set of attribute-value pairs [ attr1=val1, ...], representing other attributes of this activity that hold for its whole duration.
The following process execution assertion
processExecution(pe1,add-crime-in-london,t+1,t+1+epsilon,[host="server.example.org",type="app:edit"])
identified by identifier id, states the existence of an activity with recipe link add-crime-in-london, start time t+1, and end time t+1+epsilon, running on host server.example.org, and of type edit (declared in some namespace with prefix app). The attribute host is application specific, but must hold for the duration of activity. The attribute type is a reserved attribute of PROV-DM, allowing for subtyping to be expressed.
The mere existence of a process execution assertion entails some event ordering in the world, since the start event precedes the end event. This is expressed by constraint start-precedes-end.
From a process execution expression, one can infer that the
start event precedes the end event of the represented activity.
A process execution expression is not an entity expression.
Indeed, an entity expression represents a thing that exists in full at
any point in its characterization interval, persists during this
interval, and preserves the characteristics that makes it
identifiable. Alternatively, an activity in something that happens,
unfolds or develops through time, but is typically not identifiable by
the characteristics it exhibits at any point during its duration.
5.2.3 Agent
An agent expression is a representation of a characterized thing capable of
activity.
In PROV-ASN, an agent expression's text matches the agentExpression production of the grammar defined in this specification document.
agentExpression :=
agent
(
identifier
)
An agent expression, written agent(e) in PROV-ASN,
refers to an entity expression denoted by identifier e and representing the characterized thing capable of activity.
For a characterized thing, one can assert an agent expression or alternatively, one can infer an agent expression
by involvement in an activity represented by a process execution expression.
With the following assertions,
entity(e1, [employee="1234", name="Alice"]) and agent(e1)
entity(e2) and wasControlledBy(pe,e2,qualifier(role="author"))
the entity expression identified by e1 is accompanied by an explicit assertion of an agent expression, and this assertion holds irrespective of process executions it may be involved in. On the other hand, from the entity expression identified by e2, one can infer an agent expression, as per the following inference.
If the expressions
entity(e,av)
and
wasControlledBy(pe,e) hold for some identifiers
pe, e, and attribute-values av, then
the expression agent(e) also holds.
5.2.4 Annotation
An annotation expression is a set of name-value pairs, whose meaning is application specific. It may or may not be a representation of something in the world.
In PROV-ASN, an annotation expression's text matches the annotationExpression production of the grammar defined in this specification document.
annotationExpression :=
annotation
(
identifier
,
name-values
)
name-values :=
name-value
| name-value , name-values
name-value :=
name
=
Literal
A separate PROV-DM expression is used to associate an annotation with an expression (see Section on annotation association). A given annotation may be associated with multiple expressions.
The following annotation expression
annotation(ann1,[color="bue", screenX=20, screenY=30])
consists of a list of application-specific name-value pairs, intended
to help the rendering of the expression it is associated with, by
specifying its color and its position on the screen. In this example,
these name-value pairs do not constitute a representation of something
in the world; they are just used to help render provenance.
Name-value pairs occurring in annotations differ from attribute-value pairs (occurring in entity expressions and process execution expressions). Attribute-value pairs must be a representation of something in the world, which remain constant for the duration of the characterization interval (for entity expression) or the activity duration (for process execution expressions). It is optional for name-value pairs to be representations of something in the world. If they are a representation of something in the world, then it may change value for the corresponding duration. If name-value pairs are a representation of something in the world that does not change, they are not regarded as determining characteristics of a characterized thing or activity, for the purpose of provenance. Indeed, it is not expected that provenance would contain an explanation for these attribute-values.
5.3 Relation
This section describes all the PROV-ASN expressions conformant to the relationExpression production of the grammar.
5.3.1 Generation
In PROV-DM, a generation expression is a representation of a world event, the creation of a new characterized thing by an activity. This characterized thing did not exist before creation.
The representation of this invent encompasses a description of the modalities of generation of this thing by this activity.
In PROV-ASN, a generation expression's text matches the generationExpression production of the grammar defined in this specification document.
generationExpression :=
wasGeneratedBy
(
identifier
,
identifier
,
generationQualifier
[,
time]
)
An instance of a generation expression, written wasGeneratedBy(e,pe,q,t) in PROV-ASN:
- contains an identifier e identifying an entity expression that represents the characterized thing that is created;
- contain an identifier pe identifying a process execution expression that represents the activity that creates the characterized thing;
- contains a generationQualifier q that describes the modalities of generation of this thing by this activity;
- may contain a "generation time" t, the time at which the characterized thing was created.
The following generation assertions
wasGeneratedBy(e1,pe1,qualifier(port="p1", order=1),t1)
wasGeneratedBy(e2,pe1,qualifier(port="p1", order=2),t2)
state the existence of two events in the world (with respective times t1 and t2), at which new characterized things, represented by entity expressions identified by e1 and e2, are created by an activity, itself represented by a process execution expression identified by pe1.
The first one is available as the first value on port p1, whereas the other is the second value on port p1. The semantics of port and order in these expressions are application specific.
A given entity expression can be referred to in a single generation expression in the scope of a given account.
The rationale for this constraint is as follows.
If two process executions sequentially set different values to some attribute by means of two different generate events, then they generate distinct entities. Alternatively, for two process executions to generate an entity simultaneously, they would require some synchronization by which they agree the entity is released for use; the end of this synchronization would constitute the actual generation of the entity, but is performed by a single process execution. This unicity constraint is formalized as follows.
Given an entity expression denoted by e, two process execution expressions denoted by pe1 and pe2, and two qualifiers q1 and q2,
if the expressions wasGeneratedBy(e,pe1,q1) and wasGeneratedBy(e,pe2,q2) exist in the scope of a given account,
then pe1=pe2 and q1=q2.
A generation event
should have some visibility on the attributes of the generated entity, as expressed by the following constraint.
Given an identifier pe for a process execution expression, an identifier e for an entity expression, qualifier q, and optional time t,
if the assertion wasGeneratedBy(e,pe,p)
or wasGeneratedBy(e,pe,q,t) holds, then the values of some of e's
attributes are determined by the activity represented by process execution expression identified by pe and the
entity expressions used by pe.
Only some (possibly none) of the attributes values may be determined
since, in an open world, not all used entity expressions may have been
asserted.
The assertion of a generation event implies ordering of events in the world.
If an assertion wasGeneratedBy(x,pe,q) or wasGeneratedBy(x,pe,q,t), then generation of the thing denoted by x precedes the end
of pe and follows the beginning of pe.
5.3.2 Use
In PROV-DM, a use expression is a representation of a world event: the consumption of a characterized thing by an activity. The representation includes a description of the modalities of use of this thing by this activity.
In PROV-ASN, a use expression's text matches the useExpression production of the grammar defined in this specification document.
useExpression :=
used
(
identifier
,
identifier
,
useQualifier
[,
time]
)
An instance of a use expression, written used(pe,e,q,t) in PROV-ASN:
- refers to a process execution expression identified by pe, which represents the consuming activity;
- refers to an entity expression identified by e, which represents the characterized thing that is consumed;
- contains a useQualifier q, which describes the modalities of use of this thing by this activity;
- may contain a "use time" t, the time at which the characterized thing was used.
The following use assertions
used(pe1,e1,qualifier(parameter="p1"),t1)
used(pe1,e2,qualifier(parameter="p2"),t2)
state that the activity, represented by the process execution expression identified by pe1, consumed two characterized things, represented by entity expressions identified by e1 and e2, at times t1 and t2, respectively; the first one was found as the value of parameter p1, whereas the second was found as value of parameter p2. The semantics of parameter in these expressions is application specific.
A reference to a given entity expression may appear in multiple use expressions that share
a given process execution expression identifier. If one wants to annotate a use edge expression or if one wants to express a pe-linked-derivationExpression referring to this entity and process execution expressions, the qualifier occuring in this use assertion must be unique among the qualifiers qualifiying use expressions for this process execution expression.
Given a process execution expression identified by pe, an entity expression identified by e, a qualifier q, and optional time t, if
assertion used(pe,e,q) or used(pe,e,q,t) holds,
then the existence of an attribute-value pair in the entity expression identified by e is a
pre-condition for the termination of the activity represented by the process execution expression identified by pe.
Given a process execution expression identified by pe, an entity expression identified by e, a qualifier q, and optional time t, if
assertion used(pe,e,q) or used(pe,e,q,t) holds, then
the use of the thing represented by entity expression identified by e precedes the end
time contained in the process execution expression identified by pe and follows its beginning. Furthermore, the generation of the thing denoted by entity expression identified by e always precedes
its use.
Should we define a taxonomy of use? This is
ISSUE-23.
5.3.3 Derivation
In PROV-DM, a derivation expression is a representation that some characterized thing is transformed from, created from, or affected by another characterized thing in the world.
PROV-DM offers two different forms of derivation expressions. The first one is tightly connected to the notion of activity (represented by a process execution expression), whereas the second one is not. The first kind of assertion is particularly suitable for asserters who have an intimate knowledge of activities, is more prescriptive, but offers a more precise description of derivation, whereas the second does not put such a requirement on the asserter, and allows a less precise description of derivation to be formulated. Both expressions need to be asserted by asserters, since PROV-DM does not provide the means to infer them; however, from these assertions, further derivations can be inferred by transitive closure.
In PROV-ASN, a derivation expression's text matches the derivationExpression production of the grammar defined in this specification document.
derivationExpression :=
pe-linked-derivationExpression
| pe-independent-derivationExpression
| transitiveDerivationExpression
pe-linked-derivationExpression:=
wasDerivedFrom
(
identifier
,
identifier
[,
identifier
,
generationQualifier
,
useQualifier]
)
pe-independent-derivationExpression:=
wasEventuallyDerivedFrom
(
identifier
,
identifier
)
transitiveDerivationExpression:=
dependedOn
(
identifier
,
identifier
)
The three kinds of derivation expressions are successively introduced.
5.3.3.1 Process Execution Linked Derivation Assertion
A process execution linked derivation expression, which, by definition of a derivation expression, is a representation that some characterized thing is transformed from, created from, or affected by another characterized thing, also entails the existence of a process execution expression that represents an activity that transforms, creates or affects this characterized thing.
In its full form, a process-execution linked derivation expression, written wasDerivedFrom(e2,e1,pe,q2,q1) in PROV-ASN:
- refers to an entity expression identified by e2, which is a representation of the generated characterized thing;
- refers to an entity expression identified by e1, which is a representation of the used characterized thing;
- refers to a process execution expression identified by pe, which is a representation of the activity using and generating the above characterized things;
- contains a qualifier q2, which qualifies the generation expression pertaining to e2 and pe;
- contains a qualifier q1, which qualifies in the use expression pertaining to e1 and pe.
For convenience, PROV-DM allows for a compact, process-execution linked derivation assertion, written wasDerivedFrom(e2,e1) in PROV-ASN, which:
- refers to an entity expression identified by e2, which is a representation of the generated characterized thing;
- refers to an entity expression identified by e1, which is a represenation of the used characterized thing.
The following derivation assertions
wasDerivedFrom(e5,e3,pe4,qualifier(channel="out"),qualifier(channel="in"))
wasDerivedFrom(e3,e2)
state the existence of process-linked derivations;
the first expresses that the activity represented by the process execution pe4, by
using the thing represented by e3 obtained on the in channel
derived the
thing represented by entity e5 and generated it on
channel out. The second is similar for e3 and e2, but it leaves the process execution expression and associated qualifiers implicit. The meaning of "channel" is application specific.
If a derivation expression holds for e2 and e1, then it means that the thing represented by the entity expression identified by e1 has an influence on the thing represented by the entity expression identified by e2, which is captured by a dependency between their attribute values; it also implies temporal ordering. These are specified as follows:
Given a process execution expression denoted by pe, entity expressions denoted by e1 and e2, qualifiers q1 and q2, the assertion wasDerivedFrom(e2,e1,pe,q2,q1)
or wasDerivedFrom(e2,e1) holds if and only if
the values of some attributes of the entity expression identified by
e2 are partly or fully determined by the values of some
attributes of the entity expression identified by e1.
Given a process execution expression identified by pe, entity expressions identified by e1 and e2, qualifiers q1 and q2, if the assertion wasDerivedFrom(e2,e1,pe,q2,q1)
or wasDerivedFrom(e2,e1) holds, then
the use
of characterized thing denoted by e1 precedes the generation of
the characterized thing denoted by e2.
The following inference rule states that a generation and use event can be inferred from a process execution linked derivation expression.
If wasDerivedFrom(e2,e1,pe,q2,q1) holds, then
wasGeneratedBy(e2,pe,q2) and used(pe,e1,q1) also
hold.
The compact version has the same meaning as the fully formed
process-execution linked derivation expression, except that a process
execution expression is known to exist, though it does not need to be
asserted. This is formalized by the following inference rule,
referred to as process execution introduction:
If wasDerivedFrom(e2,e1) holds, then there exists a process execution expression identified by pe, and qualifiers q1,q2,
such that:
wasGeneratedBy(e2,pe,q2) and used(pe,e1,q1).
Note that inferring derivation from use and generation does not hold
in general. Indeed, when a generation wasGeneratedBy(e2,pe,q2)
precedes used(pe,e1,q1), for
some e1, e2, q1, q2, and pe, one
cannot infer derivation wasDerivedFrom(e2,e1,pe,q2,q1)
or wasDerivedFrom(e2,e1) since the values of attributes
of e2 cannot possibly be determined by the values of attributes
of e1, given the creation of e2 precedes the use
of e1.
A further inference is permitted from the compact version of derivation expression:
Given a process execution expression identified by pe, entity expressions identified by e1 and e2, and qualifier q2,
if wasDerivedFrom(e2,e1) and wasGeneratedBy(e2,pe,q2) hold, then there exists a qualifier q1,
such that used(pe,e1,q1) also holds.
This inference is justified by the fact that the characterized thing represented by entity expression identified by e2 is generated by at most one activity in a given account (see generation-unicity). Hence, this process execution expression is also the one referred to in the use expression of e1.
We note that the "symmetric" inference, does not hold.
From wasDerivedFrom(e2,e1) and used(pe,e1), one cannot
derive wasGeneratedBy(e2,pe,q2) because identifier e1 may occur in use expressions referring to
many process execution expressions, but they may not be referred to in generation expressions containing identifier e2.
5.3.3.2 Process Execution Independent Derivation Expression
A process execution independent derivation expression is a representation of a derivation, which occurred by any means whether direct or not, and regardless of any activity in the world.
A process-execution independent derivation expression, written wasEventuallyDerivedFrom (e2, e1) in PROV-ASN,
- contains an identifier e2, denoting an entity expression, which represents the generated characterized thing;
- contains an identifier e1, denoting an entity expression, which represents the used characterized thing.
If a derivation expression (wasEventuallyDerivedFrom) holds for e2 and e1, then
this means that the thing represented by entity expression identified by e1 has an influence on the thing represented entity expression identified by e2,
which at the minimum implies temporal ordering, specified as follows:
Given two entity expressions denoted by e1 and e2, if the expression wasEventuallyDerivedFrom(e2,e1)
holds, then the
generation event of the characterized thing represented by the entity expression denoted by e1 precedes the generation event of
the characterized thing represented by the entity expression denoted by e2.
Note that temporal ordering is between generations of e1
and e2, as opposed to process execution linked derivation,
which implies temporal ordering between the use of e1 and
generation of e2 (see derivation-use-generation-ordering). Indeed, in the case of
wasEventuallyDerivedFrom, nothing is known about the use of e1,
since there is no associated process execution.
A process execution linked derivation expression is a richer than a process execution independent derivation expression, since it
contains or implies the existence of a process execution expression. Hence, from
the former, we can infer the latter.
Given two entity expressions denoted by e1 and e2, if the assertion wasDerivedFrom(e2,e1) or wasDerivedFrom(e2,e1,pe,q12,q1)
holds, then the
the expression wasEventuallyDerivedFrom(e2,e1) also holds.
Hence, a process-execution independent derivation expression can be directly asserted or can be inferred (by means of derivation-linked-independent).
Should we link wasEventuallyDerivedFrom to attributes as we did for wasDerivedFrom? If so, this type of inference should be presented upfront, for both.
5.3.3.3 Transitive Derivation Expression
If wasDerivedFrom(e2,e1) holds because attribute a2.1 of e2 is determined by attribute a1.1 of e1,
and if wasDerivedFrom(e3,e2) holds because attribute a3.1of e3 is determined by attribute a2.2 of e1, it is not necessarily the case that an attribute of e3 is determined by an attribute of e1; so, an asserter may not be able to assert wasDerivedFrom(e3,e1), since it would fail to satisfy constraint derivation-attributes. Hence, the constraint on attributes as expressed in derivation-attributes invalidates transitivity in the general case.
However, there is sense that e3 still depends on e1, since e3 could not be generated without e1 existing. Hence, we introduce a weaker notion of derivation expression, which is transitive.
An instance of a transitive derivation expression, written
dependedOn(e2, e1) in PROV-ASN:
- contains an identifier e2, denoting an entity expression, which represents the characterized thing that is the result of the derivation;
- contains an identifier e1, denoting an entity expression, which represents the characterized thing that the derivation relies upon.
The expression dependedOn can only be inferred; in other words, it cannot be asserted. It is
transitive by definition and relies on the previously defined derivation assertions for its
base case.
- If wasDerivedFrom(e2,e1) or wasDerivedFrom(e2,e1,pe,q2,q1) holds, then dependedOn(e2,e1) holds.
- If wasEventuallyDerivedFrom(e2,e1) holds, then dependedOn(e2,e1) holds.
- If dependedOn(e3,e2) and dependedOn(e2,e1) hold, then dependedOn(e3,e1) holds.
Should derivation have a time? Which time? This is
ISSUE-43.
Derivations must take into account characterization intervals, otherwise, transitivity
leads to incorrect conclusion. This is
ISSUE-108.
------------- e1
--------------------------------------- e2
------------- e3
dependedOn(e2,e1) does not make sense, since e1 began to exist after e2.
5.3.4 Control
A control expression is a representation of the involvement of characterized thing (represented as an agent expression or an entity expression) in an activity, which is represented by a process execution expression; a control qualifier qualifies this involvement.
In PROV-ASN, a control expression's text matches the controlExpression production of the grammar defined in this specification document.
controlExpression :=
wasControlledBy
(
identifier,
identifier,
controlQualifier
)
An instance of a control expression, written wasControlledBy(pe,ag,q) in PROV-ASN:
- contains an identifier pe denoting a process execution expression, representing the controlled activity;
- refers to an agent expression or an entity expression identified by ag, representing the controlling characterized thing;
- contains a qualifier q, qualifying the involvement of the thing in the activity.
The following control assertion
wasControlledBy(pe3,a4,qualifier[role="author"])
states that the activity, represented by the process execution expression denoted by pe3 saw the involvement of a characterized thing, represented by entity expression denoted by a4 in the capacity of author. This specification reserves the qualifier name role (see Section Qualifier) to denote the function of a characterized thing with respect to an activity.
5.3.5 Complementarity
A complementarity expression is a relationship between two characterized things stated to have compatible characterization over some continuous interval between two events.
The rationale for introducing this relationship is that in general, at any given time, for a thing in the world, there may be multiple ways of characterizing it, and hence multiple representations can be asserted by different asserters. In the example that follows, suppose thing "Royal Society" is represented by two asserters, each using a different set of attributes. If the asserters agree that both representations refer to "The Royal Society", the question of whether any correspondence can be established between the two representations arises naturally. This is particularly relevant when (a) the sets of attributes used by the two representations overlap partially, or (b) when one set is subsumed by the other. In both these cases, we have a situation where each of the two asserters has a partial view of "The Royal Society", and establishing a correspondence between them on the shared attributes is beneficial, as in case (a) each of the two representation complements the other, and in case (b) one of the two (that with the additional attributes) complements the other.
This intuition is made more precise by considering the entities that form the representations of characterized things at a certain point in time.
An entity expression represents, by means of attribute-value pairs, a thing and its situation in the world, which remain constant over a characterization interval.
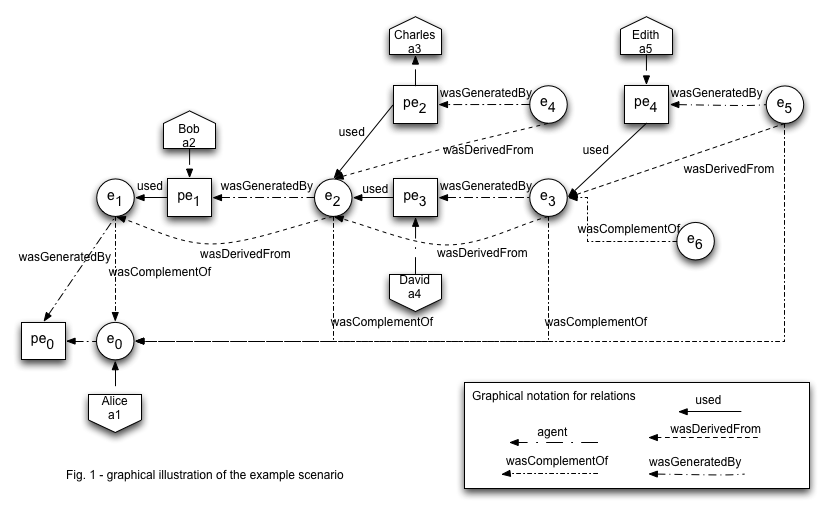
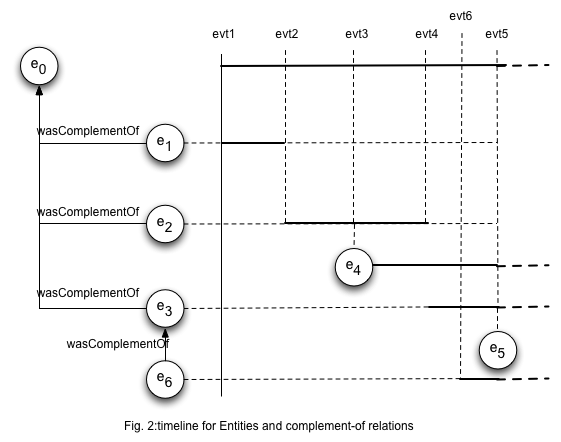
As soon as the thing's situation changes, this marks the end of the characterization interval for the entity expression representing it. The thing's novel situation is represented by an attribute with a new value, or an entirely different set of attribute-value pairs, embodied in another entity expression, with a new characterization interval. Thus, if we overlap the timelines (or, more generally, the sequences of value-changing events) for the two characterized things, we can hope to establish correspondences amongst the entity expressions that represent them at various points along that events line. The figure below illustrates this intuition.
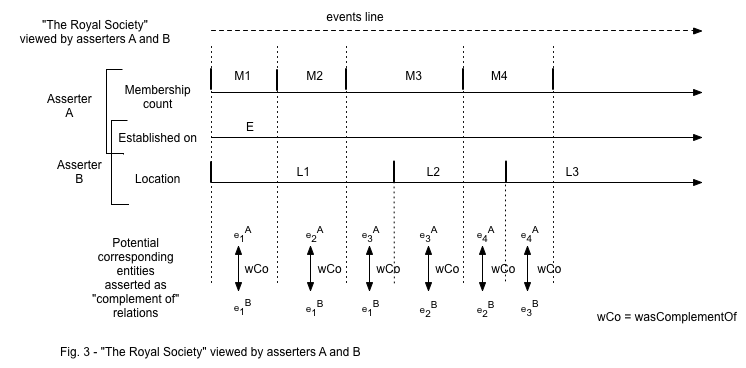
Relation complement-of between two entity expressions is intended to capture these correspondences, as follows. Suppose entity expressions A and B share a set P of attributes, and each of them has other attributes in addition to P. If the values assigned to each attribute in P are compatible between A and B, then we say that A is-complement-of B, and B is-complement-of A, in a symmetrical fashion. In the particular case where the set P of attributes of B is a strict superset of A's attributes, then we say that B is-complement-of A, but in this case the opposite does not hold. In this case, the relation is not symmetric. (as a special case, A and B may not share any attributes at all, and yet the asserters may still stipulate that they are representing the same thing "Royal Society". The symmetric relation may hold trivially in this case).
The term compatible used above means that a mapping can be established amongst the values of attributes in P and found in the two entity expession. This generalizes to the case where attribute sets P1 and P2 of A, and B, respectively, are not identical but they can be mapped to one another. The simplest case is the identity mapping, in which A and B share attribute set P, and furthermore the values assigned to attributes in P match exactly.
It is important to note that the relation holds only for the characterization intervals of the entity expessions involved As soon as one attribute changes value in one of them, new correspondences need to be found amongst the new entities. Thus, the relation has a validity span that can be expressed in terms of the event lines of the thing.
In PROV-ASN, a complementarity expression's text matches the complementarityExpression production of the grammar defined in this specification document.
complementarityExpression :=
wasComplementOf
(
identifier
,
identifier
)
An instance of a complementarity expression is written wasComplementOf(e2,e1), where e1 and e2 are two identifiers denoting entity expressions.
entity(rs,[created="1870"])
entity(rs_l1,[location="loc2"])
entity(rs_l2,[location="The Mall"])
entity(rs_m1,[membership="250", year="1900"])
entity(rs_m2,[membership="300", year="1945"])
entity(rs_m3,[membership="270", year="2010"])
wasComplementOf(rs_m3, rs_l2)
wasComplementOf(rs_m2, rs_l1)
wasComplementOf(rs_m2, rs_l2)
wasComplementOf(rs_m1, rs_l1)
wasComplementOf(rs_m3, rs)
wasComplementOf(rs_m2, rs)
wasComplementOf(rs_m1, rs)
wasComplementOf(rs_l1, rs)
wasComplementOf(rs_l2, rs)
An assertion "wasComplementOf(B,A)" holds over the temporal intersection of A and B,
only if:
- if a mapping can be established from an attribute X of entity expression identified by B to an attribute Y of entity expression identified by A, then the values of A and B must be consistent with that mapping;
- entity expression identified by B has some attribute that entity expression identified by A does not have.
The complementariy relation is not transitive. Let us consider identifiers e1, e2, and e3 identifying three entity expressions such that
wasComplementOf(e3,e2) and wasComplementOf(e2,e1) hold. The expression wasComplementOf(e3,e1) may not hold because the characterization intervals of the denoted entity expressions may not overlap.
We will allow wasComplementOf to be asserted between entities identified by qualified identifiers. This will allow us to express wasComplementOf between entities asserted in separate accounts (potentially, with the same identifiers).
It is suggested that the name 'wasComplementOf' does not capture the meaning of this relation adequately. No concrete suggestion has been made so far.
Furthermore, there is a suggestion that an alternative relation that is transitive may also be useful.
This is raised in the following
email.
A discussion on alternative definition of wasComplementOf has not reached a satisfactory conclusion yet. This is
ISSUE-29
5.3.6 Ordering of Process Executions
Proposal to change the name to "Dependencies amongst Process Executions" to avoid ambiguities
PROV-DM allows two forms of temporal relationships between activities to be expressed.
An information flow ordering expression is a representation that a characterized thing was generated by an activity, before it was used by another activity.
A control ordering expression is a representation that the end of
an activity precedes the start of another activity.
In PROV-ASN, a process execution ordering expression's text matches the peOrderingExpression production of the grammar defined in this specification document.
peOrderingExpression :=
informationFlowOrderingExpression |
controlOrderingExpression
informationFlowOrderingExpression :=
wasInformedBy
(
identifier
,
identifier
)
controlOrderingExpression :=
wasScheduledAfter
(
identifier
,
identifier
)
An instance of an information flow ordering expression, written as
wasInformedBy(pe2,pe1) in PROV-ASN:
- refers to a process execution expression identified by pe2;
- refers to a process execution expression identified by pe1
and states information flow ordering between the activities represented by these expressions, specified as follows.
Given two process execution expressions identified by pe1 and pe2,
the expression wasInformedBy(pe2,pe1)
holds, if and only if
there is an entity expression identified by e and qualifiers q1 and q2,
such that wasGeneratedBy(e,pe1,q1) and used(pe2,e,q2) hold.
The relationship wasInformedBy is not transitive. Indeed, consider the expressions wasInformedBy(pe2,pe1) and wasInformedBy(pe3,pe2), the expression
wasInformedBy(pe3,pe1), may not necessarily hold, as illustrated by the following event line.
------ pe1
|
e1
|
------- pe2
|
e2
|
----- pe3
The end in process execution expression identified by pe3 precedes the start in process execution expression identified by pe1, while interval for process execution expression pe2 overlaps with each interval for pe1 and pe3, allowing information to flow (e1 and e2, respectively).
An instance of a control ordering expression, written as
wasScheduledAfter(pe2,pe1) in PROV-ASN:
- refers to a process execution expression identified by pe2;
- refers to a process execution expression identified by pe1,
and states control ordering between pe2 and pe1, specified as follows.
Given two process execution expressions identified by pe1 and pe2,
the expression wasScheduledAfter(pe2,pe1)
holds, if and only if
there are two entity expressions identified by e1 and e2,
such that wasControlledBy(pe1,e1,qualifier(role="end")) and wasControlledBy(pe2,e2,qualifier(role="start")) and wasDerivedFrom(e2,e1).
This definition assumes that the activities represented by process execution expressions identified by pe1 and pe2 are controlled by some agents (with identifiers e1 and e2), where the first agent terminates (control qualifier qualifier(role="end")) the first activity, and the second agents initiates (control qualifier qualifier(role="start")) the second activity. The second agent being "derived" from the first enforces temporal ordering.
In the following assertions, we find two process execution expressions, identified by pe1 and pe2, representing two activities, which took place on two separate hosts.
processExecution(pe1,long-workflow,t1,t2,[host="server1.example.org"])
processExecution(pe2,long-workflow,t3,t4,[host="server2.example.org"])
entity(e1,[type="scheduler",state=1])
entity(e2,[type="scheduler",state=2])
wasControlledBy(pe1,e1,qualifier(role="end"))
wasControlledBy(pe2,e2,qualifier(role="start"))
wasDerivedFrom(e2,e1)
wasScheduledAfter(pe2,pe1)
The one identified by pe2 is said to be
scheduled after the one identified by pe1
because the scheduler terminated the activity (represented by process
execution identified by pe1) to relocate it
to the new host.
Suggested definition for process ordering. This is
ISSUE-50.
5.3.7 Revision
A revision expression is a representation of the creation of a characterized thing considered to be a variant of another. Deciding whether something is made available as a revision of something else usually involves an agent who represents someone in the world who takes responsibility for declaring that the former is variant of the latter.
In PROV-ASN, a revision expression's text matches the revisionExpression production of the grammar defined in this specification document.
revisionExpression :=
wasRevisionOf
(
identifier
,
identifier
[,
identifier]
)
An instance of a revision expression, written wasRevisionOf(e2,e1,ag) in PROV-ASN:
- contains an identifier e2 identifying an entity that represents a newer version of a thing;
- contains an identifier e1 identifying an entity that represents an older version of a thing;
- may refer to a responsible agent with identifier ag.
A revision expression can only be asserted, since it needs to include a reference to an agent who represents someone in the real world who bears responsibility for declaring a variant of a thing. However, it needs to satisfy the following constraint, linking the two entity expressions by a derivation, and stating them to be a complement of a third entity expression.
Given two identifiers
old and
new identifying two entities, and an identifier
ag identifying an agent,
if an expression
wasRevisionOf(new,old,ag) is asserted,
then
there exists an entity expression identifier
e and attribute-values
av, such that the following expressions hold:
- wasEventuallyDerivedFrom(new,old);
- entity(e,av);
- wasComplementOf(new,e);
- wasComplementOf(old,e).
wasRevisionOf is a strict sub-relation
of wasEventuallyDerivedDerivedFrom since two entities e2 and e1
may satisfy wasEventuallyDerivedDerivedFrom(e2,e1) without being a variant of
each other.
The following revision assertion
wasRevisionOf(e3,e2,a4)
states that the document represented by entity expression identified by e3 is declared to be revision of document represented by entity expression identified by e2 by agent representy by entity expression denoted by a4.
Revision should be a class not a property. This is
ISSUE-48.
5.3.8 Participation
A participation expression is a representation of the involvement of a characterized thing in an activity. A participation expression can be asserted or inferred.
In PROV-ASN, a participation expression's text matches the participationExpression production of the grammar defined in this specification document.
participationExpression :=
hadParticipant
(
identifier
,
identifier
)
An instance of a participation expression,
written hadParticipant(pe,e) in PROV-ASN:
- contains to identifier pe identifying a process execution expression representing an activity;
- contains an identifier e identifying an entity expression, which is
a representation of a characterized thing involved in this activity.
A thing's participation in an activity can be by direct use or direct control. But also, if a thing and situation are characterized in two complementary manners (and are represented by two entity expressions related by isComplementOf), if one of them participates in an activity, so does the other. The following captures the definition of participation.
Given two identifiers
pe and
e, respectively identifying a process execution expression and an entity expression, the expression
hadParticipant(pe,e) holds
if and only if:
- used(pe,e) holds, or
- wasControlledBy(pe,e) holds, or
- wasComplementOf(e1,e) holds for some entity expression identified by e1, and
hadParticipant(pe,e1) holds some process execution expression identified by pe.
Suggested definition for participation. This is
ISSUE-49.
5.3.9 Annotation Association
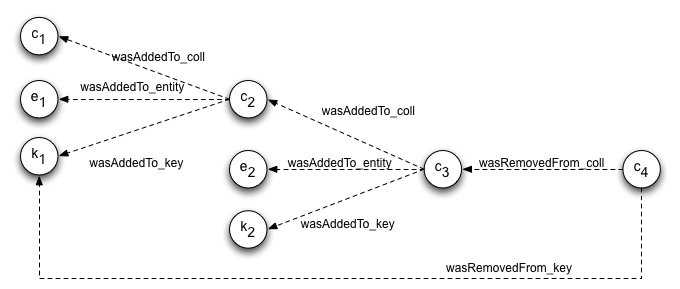
An annotation association expression establishes a link between an identifiable PROV-DM expression and an annotation expression referred to by its identifier. Multiple annotation expressions can be associated with a given PROV-DM expression; symmetrically, multiple PROV-DM expressions can be associated with a given annotation expression. Since annotation expressions have identifiers, they can also be annotated. The annotation mechanism (with annotation expression and the annotation association expression) forms a key aspect of the extensibility mechanism of PROV-DM (see extensibility section).
In PROV-ASN, an annotation expression's text matches the annotationExpression production of the grammar defined in this specification document.
annotationAssociationExpression :=
hasAnnotation
(
identifier
,
identifier
) |
hasAnnotation
(
relationIdentification
,
identifier
)
relationIdentification :=
relation
(
identifier
,
identifier
,
qualifier
[,
qualifier
]
)
Since relations do not have identifiers but can be annotated, a relationIdentification mechanism is provided allowing the constituents of relations to be listed so as to identify relations.
The interpretation of annotations is application-specific. See Section Annotation for a discussion of the difference between attributes and annotations.
The following expressions
entity(e1,[type="document"])
entity(e2,[type="document"])
processExecution(pe,transform,t1,t2,[])
used(pe,e1,qualifier(file="stdin"))
wasGeneratedBy(e2, pe, qualifier(file="stdout"))
annotation(ann1,[icon="doc.png"])
hasAnnotation(e1,ann1)
hasAnnotation(e2,ann1)
annotation(ann2,[style="dotted"])
hasAnnotation(relation(pe,e1,qualifier(file="stdin")),ann2)
assert the existence of two documents in the world (attribute-value pair: type="document") represented by entity expressions identified by e1 and e2, and annotate these expressions with an annotation indicating that the icon (an application specific way of rendering provenance) is doc.png. It also asserts a process execution, its use of the first entity, and its generation of the second entity. The used relation is annotated with a style (an application specific way of rendering this edge graphically).
5.4 Bundle
In this section, two constructs are introduced to group
PROV-DM expressions. The first
one,
accountExpression is itself an
expression, whereas the second
one
provenanceContainer is not.
5.4.1 Account
In PROV-DM, an account expression is a wrapper of expressions with a dual purpose:
- It is the mechanism by which attribution of provenance can be assserted; it allows asserters to bundle up their assertions, and assert suitable attribution;
- It provides a scoping mechanism for expression identifiers and for some contraints (such as
generation-unicity and derivation-use).
In PROV-ASN, an account expression's text matches the accountExpression production of the grammar defined in this specification document.
accountExpression :=
account
(
identifier
,
asserter
,
{ expression }
)
An instance of an account expression, written account(id, uri, exprs) in PROV-ASN:
- contains an identifier id to identify this account;
- contains an asserter identified by URI denoted by uri;
- contains a set of provenance expressions denoted by exprs.
Currently, the non-terminal asserter is defined as URI. We may want the asserter to be an agent instead, and therefore use PROV-DM to express the provenance of PROV-DM assertions. The editors seek inputs on how to resolve this issue.
The following account expression
account(acc0,
http://example.org/asserter,
entity(e0, [ type="File", location="/shared/crime.txt", creator="Alice" ])
...
wasDerivedFrom(e2,e1)
...
processExecution(pe0,create-file,t)
...
wasGeneratedBy(e0,pe0,qualifier())
...
wasControlledBy(pe4,a5, qualifier(role="communicator")) )
contains the set of provenance expressions of section example-prov-asn-encoding, is asserted by agent http://example.org/asserter, and is identified by identifier acc0.
Account expressions constitue a scope for identifiers. An identifier within the scope of an account is intended to denote a single expression. However, nothing prevents an asserter from asserting an account containing, for example, multiple entity expressions with a same identifier but different attribute-values. In that case, they should be understood as a single entity expression with this identifier and the union of all attributes values, as formalized in identified-entity-in-account.
Given an identifier e, two sets of attribute-values denoted by av1 and av2,
two entity expressions entity(e,av1) and entity(e,av2) occurring in an account are equivalent to the entity expression entity(e,av) where av is the set of attribute-value pairs formed by the union of av1 and av2.
Whilst constraint identified-entity-in-account specifies how to understand multiple entity expressions with a same identifier within a given account, it does not guarantee that the entity expression formed with the union of all attribute-value pairs is consistent. Indeed, a given attribute may be assigned multiple values, resulting in an inconsistent entity expression, as illustrated by the following example.
In the following account expression, we find two entity expressions with a same identifier e.
account(acc1,
http://example.org/id,
entity(e,[type="person",age=20])
entity(e,[type="person",age=30])
...)
Application of identified-entity-in-account results in an entity expression containing the attribute-value pairs age=20 and age=30. This results in an inconsistent characterization of a person. We note that deciding whether a set of attribute-values is consistent or not is application specific.
Account expressions can be nested since an account expression can occur among the expressions being wrapped by another account.
An account is said to be well-formed if
it satisfies the constraints generation-unicity and derivation-use.
The union of two accounts is another account,
containing the unions of their respective expressions, where
expressions with a same identifier should be understood according to constraint identified-entity-in-account. Well-formed
accounts are not
closed under union because the
constraint generation-unicity may no
longer be satisfied in the resulting union.
Indeed, let us consider another account expression
account(acc2,
http://example.org/asserter2,
entity(e0, [ type="File", location="/shared/crime.txt", creator="Alice" ])
...
processExecution(pe1,create-file,t1)
...
wasGeneratedBy(e0,pe1,qualifier(fct="create"))
... )
with identifier acc2, containing assertions by asserter by http://example.org/asserter2 stating that thing represented by entity expression identified by e0 was generated by an activity represented by process execution expression identified by pe1 instead of pe0 in the previous account acc0. If accounts acc0 and acc2 are merged together, the resulting set of expressions violates generation-unicity.
Account expressions constitue a scope for identifiers. Since accounts can be nested, their scope can also be nested; thus, the scope of identifiers should be understood in the context of such nested scopes. When an expression with an identifier occurs directly within an account, then its identifier denotes this expression in the scope of this account, except in sub-accounts where expressions with the same identifier occur.
The following account expression is inspired from section example-prov-asn-encoding. This account, identified by acc3, declares entity expression identified by e0, which is being referred to in the nested account acc4. The scope of identifier e0 is account acc3, including subaccount acc4.
account(acc3,
http://example.org/asserter1,
entity(e0, [ type="File", location="/shared/crime.txt", creator="Alice" ])
processExecution(pe0,create-file,t)
wasGeneratedBy(e0,pe0,qualifier())
account(acc4,
http://example.org/asserter2,
entity(e1, [ type="File", location="/shared/crime.txt", creator="Alice", content="" ])
processExecution(pe0,copy-file,t)
wasGeneratedBy(e1,pe0,qualifier(fct="create"))
isComplement(e1,e0)))
Alternatively, a process execution expression identified by pe0 occurs in each of the two accounts. Therefore, each process execution expression is asserted in a separate scope, and therefore may represent different activities in the world.
The account expression is the hook by which further meta information can be expressed about provenance, such as asserter, time of creation, signatures. How general meta-information is expressed is beyond the scope of this specification, except for asserters.
We are going to introduce a disambiguation mechanism by which we can qualify identifiers by the account in which they occur (or the sequence of nested accounts in which they occur). This mechanism allows two entity expressions, asserted separately in two different accounts but with the same identifier, to be uniquely referred to.
5.4.2 Provenance Container
A provenance container is a house-keeping construct of PROV-DM, also capable of bundling PROV-DM expressions. A provenance container is not an expression, but can be exploited to return assertions in response to a request for the provenance of something ([PROV-PAQ]).
In PROV-ASN, a provenance container's text matches the provenanceContainer production of the grammar defined in this specification document.
provenanceContainer :=
provenanceContainer
(
{ namespaceDeclaration }
,
{ identifier }
,
{ expression }
)
An instance of a provenance container, written provenanceContainer(decls, ids, exprs) in PROV-ASN:
- contains a set of namespace declarations decls, declaring namespaces and associated prefixes, which can be used in attributes (conformant to production attribute) and in names (conformant to production name) in exprs;
- contains a set of identifiers ids naming all accounts occurring (at any nesting level) in exprs;
- contains one or more expressions exprs.
All the expressions in exprs are implictly wrapped in a default account, scoping all the identifiers they declare directly, and constituting a toplevel account, in the hierarchy of accounts. Consequently, every provenance expression is always expressed in the context of an account, either explicitly in an asserted account, or implicitly in a container's default account.
The following container
container([x http://example.org/], [acc1,acc2]
account(acc1,http://example.org/asserter1,...)
account(acc2,http://example.org/asserter1,...))
illustrates how two accounts with identifiers acc1 and acc2 can be returned in a PROV-ASN serialization of the provenance of something.
Asserter needs to be defined. This is
ISSUE-51.
Scope and Identifiers. This is
ISSUE-81.
5.5 Other Expressions
This section specifies the productions of sub-expressions of PROV-DM expressions.
5.5.1 Qualifier
A qualifier is an ordered list of name-value pairs, used to qualify use expressions, generation expressions and control expressions.
In PROV-ASN, a qualifier's text matches the qualifier production of the grammar defined in this specification document.
useQualifier :=
qualifier
generationQualifier :=
qualifier
controlQualifier :=
qualifier
qualifier :=
qualifier
(
name-values )
name-values :=
name-value
| name-value , name-values
name-value :=
name
=
Literal
Use, generation, and control expressions must contain a qualifier. A qualifier's sequence of name-value pairs may be empty.
aren't these two sentences contradictory>
The interpretation of a qualifier is specific to the process execution expression it occurs in, which means that a same qualifier may appear in two different process execution expressions with different interpretations.
From this specification's viewpoint, a qualifier's interpretation is out of
scope.
By definition, a use (resp. generation, control) expression does not contain an identifier.
If one wants to annotate a use (resp. generation, control) expression, this expression must be identifiable from its constituents, i.e. its source's identifier, its destination's identifier, and its qualifier.
To be able to annotate use (resp. generation, control) expressions that refer to a given process execution identifier,
any qualifier occuring in use expressions (resp. generation, control) with this identifier and a given entity expression identifier must be unique.
It may seem strange that we do not require use expressions to have an identifier. Mandating the presence of identifiers in use expressions would facilitate their annotation. However, this would make it difficult for use expressions to be encoded as properties in OWL2.
Qualifiers are used in determining the exact source and destination of a pe-linked-derivationExpression. Hence,
if one wants to express a pe-linked-derivationExpression referring to an entity expression and a process execution expression, then:
- the useQualifier must be unique among the qualifiers occuring in use expressions for this process execution expression;
- the generationQualifier must be unique among the qualifiers occuring in generation expressions for this process execution expression.
The PROV data model introduces the qualifier role in the PROV-DM namespace to denote the function of a characterized thing with respect to an activity, in the context of a use/generation/control relation. The value associated with a role attribute must be conformant with Literal.
The following control expression qualifies the role of the agent identified by a5 in this control relation.
wasControlledBy(pe4,a5, qualifier(role="communicator"))
5.5.2 Attribute
An attribute is a finite sequence of characters. (Exact production TBD).
attribute :=
a qualified name
If a namespace prefix occurs in the qualified name, it refers to a namespace declared in the provenance container.
5.5.3 Name
A name is a finite sequence of characters. (Exact production TBD).
name :=
a qualified name
If a namespace prefix occurs in the qualified name, it refers to a namespace declared in the provenance container.
Proposed to adopt the abbreviatedIRI definition of OWL2 [
OWL2-SYNTAX]
(see section
IRIs).
5.5.4 Identifier
An identifier is a finite sequence of characters.
Do we require identifiers to be URIs? All the examples in this document so far use simple labels as identifiers? Would this be acceptable? Maybe understood as default namespace and local name?
identifier :=
?????
We are going to introduce a notion of qualified identifier, which allows us to refer to an identifier in the scope of a given account. Given that accounts may be nested, a qualifier identifier will be prefixed by a sequence of account identifiers, and then followed by an identifier, local to the innermost account.
5.5.5 Literal
Literals represent data values such as particular string or integers.
5.5.6 Time
Time instants are defined according to xsd:dateTime [XMLSCHEMA-2].
It is optional to assert time in use, generation, and process execution expressions.
5.5.6.1 Temporal Events
Four kinds of discrete events underpin the PROV-DM data model. They are:
- Generation of a characterized thing by an activity: identifies the final instant of a characterized thing's creation timespan, after which it becomes available for use.
- Use of a characterized thing by an activity: identifies the first instant of a characterized thing's consumption timespan.
- Start of an activity: identifies the instant an activity, represented by a process execution, starts;
- End of an activity: identifies the instant an activity, represented by a process execution, ends.
5.5.6.2 Event Ordering
Follows is a partial order between events, indicating that an event occurs after another. For convenience, precedes is defined as the symmetric of follows.
This specification introduces inference rules allowing such event ordering to be inferred from provenance constructs.
5.5.7 Asserter
An asserter is a creator of PROV-DM expressions. An asserter is denoted by an IRI.
asserter := an IRI
Currently, the non-terminal asserter is defined as URI. We may want the asserter to be an agent instead, and therefore use PROV-DM to express the provenance of PROV-DM. We seek inputs on how to resolve this issue.
5.5.8 Namespace Declaration
A namespace declaration declares a namespace and a prefix to denote it.
namespaceDeclaration := ... TBD
5.5.9 Recipe Link
A recipe link is an association between a process execution expression and a process specification that underpins the represented activity.
recipeLink := an IRI
It is optional to assert recipe links in process executions.
Process specifications, as referred to by recipe links, are out of scope of this specification.
5.5.10 Location
Location is an identifiable geographic place (ISO 19112). As such, there are numerous ways in which location can be expressed, such as by a coordinate, address, landmark, row, column, and so forth. This document does not specify how to concretely express locations, but instead provide a mechanism to introduce locations in assertions.
Location is an optional attribute of entity expressions and process execution expressions. The value associated with a attribute location must be a Literal, expected to denote a location.