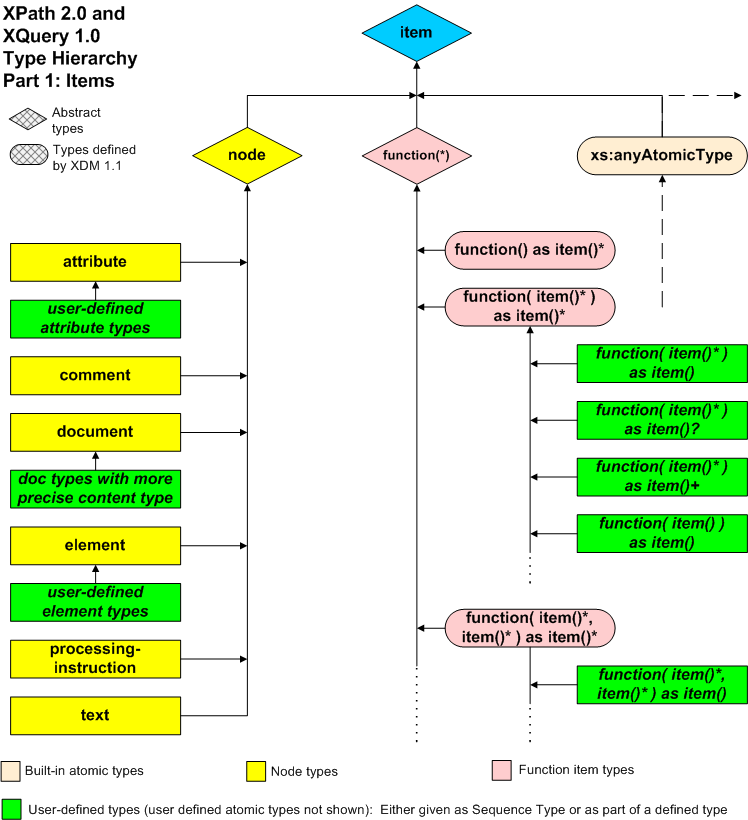
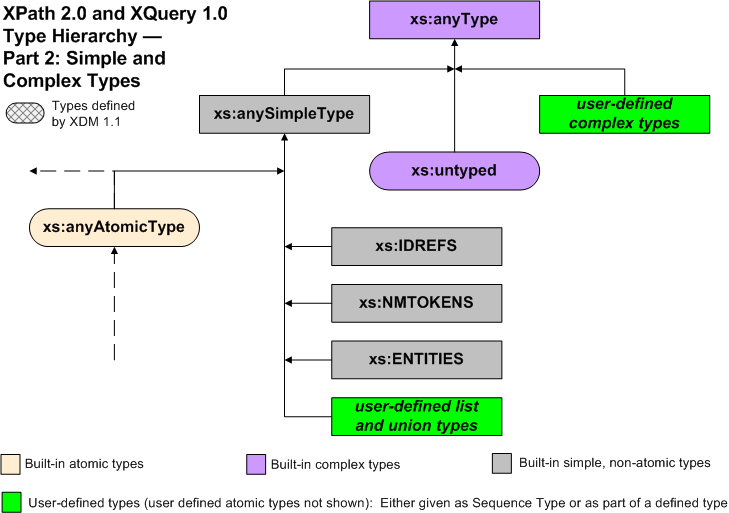
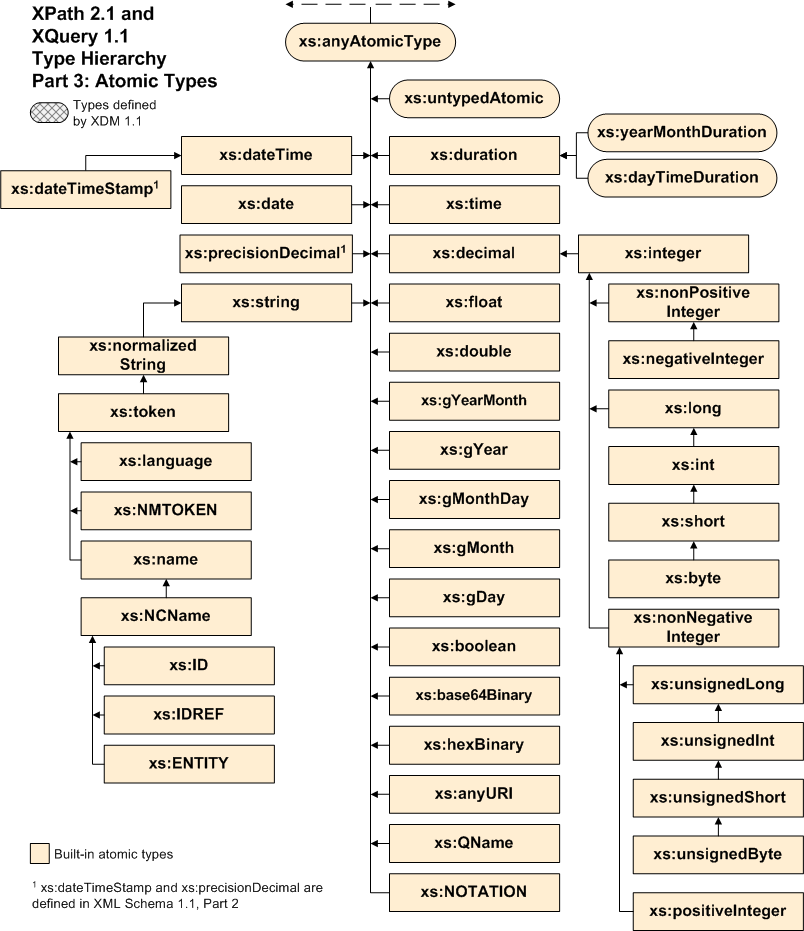
Three functions are provided to represent dates and times as a
string, using the conventions of a selected calendar, language, and
country. The signatures are presented first, followed by the rules
which apply to each of the functions.
9.8.4 The date/time formatting
functions
The fn:format-dateTime,
fn:format-date, and
fn:format-time
functions format $value as a string using the picture
string specified by the $picture argument, the
calendar specified by the $calendar argument, the
language specified by the $language argument, and the
country specified by the $country argument. The result
of the function is the formatted string representation of the
supplied xs:dateTime, xs:date, or
xs:time value.
[Definition] The three functions
fn:format-dateTime,
fn:format-date, and
fn:format-time are
referred to collectively as the date formatting
functions.
If $value is the empty sequence, the function
returns the empty sequence.
Calling the two-argument form of each of the three functions is
equivalent to calling the five-argument form with each of the last
three arguments set to an empty sequence.
For details of the language, calendar,
and country arguments, see 9.8.4.2 The Language, Calendar, and Country
Arguments.
In general, the use of an invalid picture,
language, calendar, or
country argument results in a dynamic error. By
contrast, use of an option in any of these arguments that is valid
but not supported by the implementation is not an error, and in
these cases the implementation is required to output the value in a
fallback representation.
9.8.4.1 The Picture String
The picture consists of a sequence of variable markers and
literal substrings. A substring enclosed in square brackets is
interpreted as a variable marker; substrings not enclosed in square
brackets are taken as literal substrings. The literal substrings
are optional and if present are rendered unchanged, including any
whitespace. If an opening or closing square bracket is required
within a literal substring, it must be doubled.
The variable markers are replaced in the result by strings
representing aspects of the date and/or time to be formatted. These
are described in detail below.
A variable marker consists of a component specifier followed
optionally by one or two presentation modifiers and/or optionally
by a width modifier. Whitespace within a variable marker is
ignored.
The component specifier indicates the component of the
date or time that is required, and takes the following values:
| Specifier |
Meaning |
Default Presentation Modifier |
| Y |
year (absolute value) |
1 |
| M |
month in year |
1 |
| D |
day in month |
1 |
| d |
day in year |
1 |
| F |
day of week |
n |
| W |
week in year |
1 |
| w |
week in month |
1 |
| H |
hour in day (24 hours) |
1 |
| h |
hour in half-day (12 hours) |
1 |
| P |
am/pm marker |
n |
| m |
minute in hour |
01 |
| s |
second in minute |
01 |
| f |
fractional seconds |
1 |
| Z |
timezone as a time offset from UTC, or if an alphabetic
modifier is present the conventional name of a timezone (such as
PST) |
1 |
| z |
timezone as a time offset using GMT, for example GMT+1 or
GMT-05:00. For this component there is a fixed prefix of
GMT, or a localized variation thereof for the chosen
language, and the presentation modifier controls the representation
of the signed time offset that follows. |
1 |
| C |
calendar: the name or abbreviation of a calendar name |
n |
| E |
era: the name of a baseline for the numbering of years, for
example the reign of a monarch |
n |
An error is reported [err:FOFD1340] if the syntax of the picture is
incorrect.
An error is reported [err:FOFD1350] if a component specifier within
the picture refers to components that are not available in the
given type of $value, for example if the picture
supplied to the format-time refers to the year, month,
or day component.
It is not an error to include a timezone component when the
supplied value has no timezone. In these circumstances the timezone
component will be ignored.
The first presentation modifier indicates the style in
which the value of a component is to be represented. Its value may
be either:
-
any format token permitted as a primary format token in the
second argument of the format-integer function,
indicating that the value of the component is to be output
numerically using the specified number format (for example,
1, 01, i, I,
w, W, or Ww) or
-
the format token n, N, or
Nn, indicating that the value of the component is to
be output by name, in lower-case, upper-case, or title-case
respectively. Components that can be output by name include (but
are not limited to) months, days of the week, timezones, and eras.
If the processor cannot output these components by name for the
chosen calendar and language then it must use an
implementation-defined fallback representation.
If a comma is to be used as a grouping separator within the
format token, then there must be a width specifier. More
specifically: if a variable marker contains one or more commas,
then the last comma is treated as introducing the width modifier,
and all others are treated as grouping separators. So
[Y9,999,*] will output the year as
2,008.
If the implementation does not support the use of the requested
format token, it must use the default presentation
modifier for that component.
If the first presentation modifier is present, then it may
optionally be followed by a second presentation modifier as
follows:
| Modifier |
Meaning |
| t |
traditional numbering. This has the same meaning
as in the second argument of fn:format-integer. |
| o |
ordinal form of a number, for example
8th or 8º. This has the same meaning as
in the second argument of fn:format-integer. The
actual representation of the ordinal form of a number may depend
not only on the language, but also on the grammatical context (for
example, in some languages it must agree in gender). |
Note:
Although the formatting rules are expressed in terms of the
rules for format tokens in fn:format-integer, the
formats actually used may be specialized to the numbering of date
components where appropriate. For example, in Italian, it is
conventional to use an ordinal number (primo) for the
first day of the month, and cardinal numbers (due, tre,
quattro ...) for the remaining days. A processor may
therefore use this convention to number days of the month, ignoring
the presence or absence of the ordinal presentation modifier.
Whether or not a presentation modifier is included, a width
modifier may be supplied. This indicates the number of characters
or digits to be included in the representation of the value.
The width modifier, if present, is introduced by a comma or
semicolon. It takes the form:
"," min-width ("-"
max-width)?
where min-width is either an unsigned integer
indicating the minimum number of characters to be output, or
* indicating that there is no explicit minimum, and
max-width is either an unsigned integer indicating the
maximum number of characters to be output, or *
indicating that there is no explicit maximum; if
max-width is omitted then * is assumed.
Both integers, if present, must be greater than
zero.
A format token containing more than one digit, such as
001 or 9999, sets the minimum and maximum
width to the number of digits appearing in the format token; if a
width modifier is also present, then the width modifier takes
precedence.
Note:
A format token consisting of a single digit, such as
1, does not constrain the number of digits in the
output. In the case of fractional seconds in particular,
[f001] requests three decimal digits,
[f01] requests two digits, but [f1] will
produce an implementation-defined number of digits. If exactly one
digit is required, this can be achieved using the component
specifier [f1,1-1].
If the minimum and maximum width are unspecified, then the
output uses as many characters as are required to represent the
value of the component without truncation and without padding: this
is referred to below as the full representation of the
value. For a timezone offset (component specifier z),
the full representation consists of a sign for the offset, the
number of hours of the offset, and if the offset is not an integral
number of hours, a colon (:) followed by the two
digits of the minutes of the offset..
If the full representation of the value exceeds the specified
maximum width, then the processor should attempt
to use an alternative shorter representation that fits within the
maximum width. Where the presentation modifier is N,
n, or Nn, this is done by abbreviating
the name, using either conventional abbreviations if available, or
crude right-truncation if not. For example, setting
max-width to 4 indicates that four-letter
abbreviations should be used, though it would be
acceptable to use a three-letter abbreviation if this is in
conventional use. (For example, "Tuesday" might be abbreviated to
"Tues", and "Friday" to "Fri".) In the case of the year component,
setting max-width requests omission of high-order
digits from the year, for example, if max-width is set
to 2 then the year 2003 will be output as
03. In the case of the fractional seconds component,
the value is rounded to the specified size as if by applying the
function round-half-to-even(fractional-seconds,
max-width). If no mechanism is available for fitting the
value within the specified maximum width (for example, when roman
numerals are used), then the value should be
output in its full representation.
If the full representation of the value is shorter than the
specified minimum width, then the processor should
pad the value to the specified width.
-
For decimal representations of numbers, this
should be done by prepending zero digits from the
appropriate set of digit characters, or appending zero digits in
the case of the fractional seconds component.
-
For timezone offsets this should be done by first appending a
colon (:) followed by two zero digits from the
appropriate set of digit characters if the full representation does
not already include a minutes component and if the specified
minimum width permits adding three characters, and then if
necessary prepending zero digits from the appropriate set of digit
characters to the hour component.
-
In other cases, it should be done by appending
spaces.
9.8.4.2
The Language, Calendar, and Country Arguments
The set of languages, calendars, and countries that are
supported in the ·date formatting functions· is ·implementation-defined·. When any of these arguments is omitted or is
an empty sequence, an ·implementation-defined· default value is used.
If the fallback representation uses a different calendar from
that requested, the output string must identify
the calendar actually used, for example by prefixing the string
with [Calendar: X] (where X is the calendar actually
used), localized as appropriate to the requested language. If the
fallback representation uses a different language from that
requested, the output string must identify the
language actually used, for example by prefixing the string with
[Language: Y] (where Y is the language actually used)
localized in an implementation-dependent way. If a particular
component of the value cannot be output in the requested format, it
should be output in the default format for that
component.
The language argument specifies the language to be
used for the result string of the function. The value of the
argument must be either the empty sequence or a
value that would be valid for the xml:lang attribute
(see [XML]). Note that this permits the identification of
sublanguages based on country codes (from [ISO
3166-1]) as well as identification of dialects and of regions
within a country.
If the language argument is omitted or is set to an
empty sequence, or if it is set to an invalid value or a value that
the implementation does not recognize, then the processor uses an
·implementation-defined· language.
The language is used to select the appropriate
language-dependent forms of:
names (for example, of months)
numbers expressed as words or as ordinals (twenty, 20th,
twentieth)
hour convention (0-23 vs 1-24, 0-11 vs 1-12)
first day of week, first week of year
Where appropriate this choice may also take into account the
value of the country argument, though this
should not be used to override the language or any
sublanguage that is specified as part of the language
argument.
The choice of the names and abbreviations used in any given
language is ·implementation-defined·. For example, one implementation might
abbreviate July as Jul while another uses
Jly. In German, one implementation might represent
Saturday as Samstag while another uses
Sonnabend. Implementations may
provide mechanisms allowing users to control such choices.
Where ordinal numbers are used, the selection of the correct
representation of the ordinal (for example, the linguistic gender)
may depend on the component being formatted and on
its textual context in the picture string.
The calendar attribute specifies that the
dateTime, date, or time
supplied in the $value argument must
be converted to a value in the specified calendar and then
converted to a string using the conventions of that calendar.
A calendar value must be a valid lexical QName.
If the QName does not have a prefix, then it identifies a calendar
with the designator specified below. If the QName has a prefix,
then the QName is expanded into an expanded-QName using the
in-scope namespaces from the static context; the expanded-QName
identifies the calendar; the behavior in this case is ·implementation-defined·.
If the calendar attribute is omitted an ·implementation-defined· value is used.
Note:
The calendars listed below were known to be in use during the
last hundred years. Many other calendars have been used in the
past.
This specification does not define any of these calendars, nor
the way that they map to the value space of the
xs:date data type in [XML
Schema Part 2: Datatypes Second Edition]. There may be
ambiguities when dates are recorded using different calendars. For
example, the start of a new day is not simultaneous in different
calendars, and may also vary geographically (for example, based on
the time of sunrise or sunset). Translation of dates is therefore
more reliable when the time of day is also known, and when the
geographic location is known. When translating dates between one
calendar and another, the processor may take account of the values
of the country and/or language arguments,
with the country argument taking precedence.
Information about some of these calendars, and algorithms for
converting between them, may be found in [Calendrical Calculations].
| Designator |
Calendar |
| AD |
Anno Domini (Christian Era) |
| AH |
Anno Hegirae (Muhammedan Era) |
| AME |
Mauludi Era (solar years since Mohammed's birth) |
| AM |
Anno Mundi (Jewish Calendar) |
| AP |
Anno Persici |
| AS |
Aji Saka Era (Java) |
| BE |
Buddhist Era |
| CB |
Cooch Behar Era |
| CE |
Common Era |
| CL |
Chinese Lunar Era |
| CS |
Chula Sakarat Era |
| EE |
Ethiopian Era |
| FE |
Fasli Era |
| ISO |
ISO 8601 calendar |
| JE |
Japanese Calendar |
| KE |
Khalsa Era (Sikh calendar) |
| KY |
Kali Yuga |
| ME |
Malabar Era |
| MS |
Monarchic Solar Era |
| NS |
Nepal Samwat Era |
| OS |
Old Style (Julian Calendar) |
| RS |
Rattanakosin (Bangkok) Era |
| SE |
Saka Era |
| SH |
Mohammedan Solar Era (Iran) |
| SS |
Saka Samvat |
| TE |
Tripurabda Era |
| VE |
Vikrama Era |
| VS |
Vikrama Samvat Era |
At least one of the above calendars must be
supported. It is ·implementation-defined· which calendars are supported.
The ISO 8601 calendar ([ISO 8601]), which
is included in the above list and designated ISO, is
very similar to the Gregorian calendar designated AD,
but it differs in several ways. The ISO calendar is intended to
ensure that date and time formats can be read easily by other
software, as well as being legible for human users. The ISO
calendar prescribes the use of particular numbering conventions as
defined in ISO 8601, rather than allowing these to be localized on
a per-language basis. In particular it provides a numeric 'week
date' format which identifies dates by year, week of the year, and
day in the week; in the ISO calendar the days of the week are
numbered from 1 (Monday) to 7 (Sunday), and week 1 in any calendar
year is the week (from Monday to Sunday) that includes the first
Thursday of that year. The numeric values of the components year,
month, day, hour, minute, and second are the same in the ISO
calendar as the values used in the lexical representation of the
date and time as defined in [XML Schema Part
2: Datatypes Second Edition]. The era ("E" component) with this
calendar is either a minus sign (for negative years) or a
zero-length string (for positive years). For dates before 1
January, AD 1, year numbers in the ISO and AD calendars are off by
one from each other: ISO year 0000 is 1 BC, -0001 is 2 BC, etc.
Note:
The value space of the date and time data types, as defined in
XML Schema, is based on absolute points in time. The lexical space
of these data types defines a representation of these absolute
points in time using the proleptic Gregorian calendar, that is, the
modern Western calendar extrapolated into the past and the future;
but the value space is calendar-neutral. The ·date
formatting functions· produce a
representation of this absolute point in time, but denoted in a
possibly different calendar. So, for example, the date whose
lexical representation in XML Schema is 1502-01-11
(the day on which Pope Gregory XIII was born) might be formatted
using the Old Style (Julian) calendar as 1 January
1502. This reflects the fact that there was at that time a
ten-day difference between the two calendars. It would be
incorrect, and would produce incorrect results, to represent this
date in an element or attribute of type xs:date as
1502-01-01, even though this might reflect the way the
date was recorded in contemporary documents.
When referring to years occurring in antiquity, modern
historians generally use a numbering system in which there is no
year zero (the year before 1 CE is thus 1 BCE). This is the
convention that should be used when the requested
calendar is OS (Julian) or AD (Gregorian). When the requested
calendar is ISO, however, the conventions of ISO 8601
should be followed: here the year before +0001 is
numbered zero. In [XML Schema Part 2:
Datatypes Second Edition] (version 1.0), the value space for
xs:date and xs:dateTime does not include
a year zero: however, a future edition is expected to endorse the
ISO 8601 convention. This means that the date on which Julius
Caesar was assassinated has the ISO 8601 lexical representation
-0043-03-13, but will be formatted as 15 March 44 BCE in the Julian
calendar or 13 March 44 BCE in the Gregorian calendar (dependant on
the chosen localization of the names of months and eras).
The intended use of the country argument is to
identify the place where an event represented by the
dateTime, date, or time
supplied in the $value argument took place or will
take place. If the value is supplied, and is not the empty
sequence, then it should be a country code defined
in [ISO 3166-1]. Implementations
may also allow the use of codes representing
subdivisions of a country from ISO 3166-2, or codes representing
formerly used names of countries from ISO 3166-3. This argument is
not intended to identify the location of the user for whom the date
or time is being formatted; that should be done by means of the
language attribute. This information
may be used to provide additional information when
converting dates between calendars or when deciding how individual
components of the date and time are to be formatted. For example,
different countries using the Old Style (Julian) calendar started
the new year on different days, and some countries used variants of
the calendar that were out of synchronization as a result of
differences in calculating leap years. The geographical area
identified by a country code is defined by the boundaries as they
existed at the time of the date to be formatted, or the present-day
boundaries for dates in the future.