Abstract
This document sets out the use cases and requirements that have motivated the development of the Protocol for Web Description Resources (POWDER).
The use cases address social and commercial needs to provide information about groups of Web resources, such as those available from a Web
site, to aid the annotation and/or personalization of content for end users in varying delivery contexts.
Status of this document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list
of current W3C publications and the latest revision of this technical report can be found in the W3C
technical reports index at http://www.w3.org/TR/.
This is a W3C Working Group Note of the POWDER Use Cases and Requirements, developed by the POWDER Working Group
as part of the Semantic Web Activity.
After reflecting on comments received on the
previous version of this document, the Working Group believes it to be stable and therefore to be suitable as the basis for the group's ongoing work. The differences between this document and the previous version can be found in section 6.
Please send comments about this document to public-powderwg@w3.org (with public archive).
Publication as a Working Group Note does not imply endorsement by the W3C Membership.
This is a draft document and may be updated, replaced or obsoleted by other documents at any time.
It is inappropriate to cite this document as other than work in progress.
This document was produced by a group operating under the 5 February 2004 W3C Patent Policy. W3C maintains a public list of any patent disclosures
made in connection with the deliverables of the group; that page also includes instructions for disclosing a patent.
An individual who has actual knowledge of a patent which the individual believes contains
Essential Claim(s)
must disclose the information in accordance with section 6 of the W3C Patent Policy.
Table of Contents
1 Introduction
The development of the Protocol for Web Description Resources has been motivated by both commercial and social concerns.
On the social side, there is a demand for a system to identify content that meets certain criteria as they apply to specified
audiences. Commercially, there is a demand to be able to personalize content for a particular user or delivery context.
POWDER will address these demands by defining a method through which relatively small amounts of metadata, that can
be produced quickly and easily, can be applied to large amounts of content.
The use cases and requirements for POWDER were originally developed under the Web
Content Label Incubator Activity. They have been revised and updated for this Working Group Note.
2 Use cases
2.1 Profile matching
The generic use case for profile matching is that a user receives content suited to their
delivery context; that is, the combination of user preferences, device capabilities and current
state at the time of content delivery. Description Resources facilitate this decision by
making available rules about groups of Web resources to a Web Server. At request time the Web
Server can determine if there are any rules in the DR which apply to the requested URI,
and respond to the User accordingly.
This extended use case refers to the following terms.
Actors:
User: A human who perceives and interacts with the Web.
Device: Apparatus through which a user can perceive and interact with
the Web
Server: The role adopted by an application when it is supplying
resources or resource manifestations.
Network Operator: A mobile telephony and data infrastructure provider.
Adaptation: a process of selection, generation or modification of Web
content to suit the given delivery context.
Content Types:
Web content: any resource retrievable via a URI over the World Wide Web
intended for direct user consumption (Web pages and audio/visual media types).
2.1.1 Generic Profile Matching Use Case
- Step 1
- User requests Web content via their device.
- Step 2
- A Server resolves the URI and determines that there is metadata associated with the resource that asserts access conditions.
- Step 3
- The Server matches the assertions in the metadata, to the user's delivery context.
Then either
- Step 4a
- The Server interprets that there are no constraints on the user accessing the content,
- Step 5a
- The Server responds to the User with the full Web content.
or
- Step 4b
- The metadata asserts that the requested content is not appropriate to the current delivery context.
- Step 5b
- The Server adapts the content and responds to the User.
This generic example uses the phrase 'delivery context'. This means different things in different circumstances. For
example, in sub use cases 2.1.2 and 2.1.3 it means the characteristics of the device being used to access the content, in
2.1.4 it's the connection bandwidth that is important, whereas in sub uses cases 2.1.5 - 2.1.7 the delivery context is
related to a profile of the end user. It is assumed that the relevant features of the delivery context will be determined using a
technique appropriate to the use case. For example, device characteristics are likely to be retrieved from a repository whilst child
protection software is likely to work with several sources of data in addition to Description Resources. Matching of resources
against end users is likely to involve reference to an Identity Management System which is beyond the scope of POWDER.
2.1.2 Adaptive Search Results
- Anne enters a search string, 'Pianos', into a search engine, search.example.org.
- The search engine notes the characteristics of Anne's device by retrieving a description from a Device Description Repository.
- The search engine obtains a set of URIs that are relevant to the search key.
- The search engine notes the characteristics of the content associated with each URI.
- The search engine compares the device characteristics to the content characteristics.
- The search engine removes the URIs of content that cannot be rendered by, or adapted to, Anne's device.
- The search engine returns a list of the remaining URIs to Anne.
- If Anne selects from one of the returned URIs, the identified content is delivered as is (if appropriate to the known device capabilities) or adapted accordingly.
2.1.3 mobileOK
- Dan wants to be able to access a directory of Web sites that will give an optimal user experience on his mobile phone. He enters
'Sausages' into search.example.com and checks the box that says 'MobileOK results only' [MOK]
- The search engine retrieves a set of URIs from its index and determines those resources with associated metadata describing their
characteristics. Any resources without such metadata are discarded.
- The search engine inspects the metadata and determines which resources are declared to be conformant with mobileOK.
- The search engine returns a list of the URIs of mobileOK conformant resources to Dan.
- If Dan selects from one of the returned URIs, the identified content is delivered as is.
2.1.4 Functional User Experience
- Hwang visits a martial arts Web site through his laptop computer and requests a page of streaming video clips.
- The Server's content management system detects that there is metadata associated with all URIs containing /video/ in their path.
- The Server retrieves and inspects the metadata and discovers that only devices connecting at a minimum bandwidth of 150K will be able to
stream the videos.
- The Server determines that Hwang's laptop is currently connected at a lower bandwidth.
- The Server redirects Hwang to a page of images more appropriate to his bandwidth.
2.1.5 Web Accessibility
- Iris, who has limited dexterity and therefore difficulty using a mouse, wishes to shop for CDs online. A helpful Web
search engine allows her to set a preference for web pages that can easily be used with keyboard-only input. She searches
for her favorite artist through the Search engine's 'search shops' interface.
- The Search engine retrieves a set of URIs from its index, and fetches metadata assertions from a database provided by a trusted third party.
- The Server inspects the metadata and looks for any assertions made about Web accessibility, especially keyboard operability.
- The Server returns the conformant results and Iris goes shopping.
2.1.6 Child Protection A
- Barry, who is 16 years old, has been sent a URI in an SMS message to his mobile phone. He clicks on the link, which unknown to him, is to an
adults-only area of a example.com.
- The Network Operator has a child protection policy which allows parents to decide if they or their family can access certain content.
One technique it uses is to check any metadata references before responding to the User.
- The Network Operator retrieves a metadata description from the Web portal, which declares that anything at the server adult.example.com
contains explicit nudity. The Network Operator determines from Barry's profile that his parents have asked such access to be restricted.
- The Network Operator returns a Child Protection explanation page to Barry.
2.1.7 Child protection B
- Thomas creates a portal offering what he considers to be terrific content for children. He adds a Derscription Resource expressing the view
that all material available on the portal is suitable for children of all ages.
- Independently, a large content classification company, classification.example.org, crawls Thomas's portal and classifiies it as being safe for children.
- Discovering this, Thomas updates his Description Resource with a link to the relevant entry in the online database operated at classification.example.org.
- 5 year old Briana visit's the portal. The parental control software installed by her parents notes the presence of the Description Resource and seeks confirmation
of the claim that the site is child-safe by following the link to the classification.example.org database, which her parents have deemed trustworthy.
- On receiving such confirmation, access is granted and Briana enjoys the content Thomas has created.
2.1.8 Privileged Content
- Ray is a premium customer of exampleISP, an Internet Service Provider. They have a deal which allows him to access premium content on
other Web sites as long as he accesses it using exampleISP. Ray visits such a 3rd party, games.example.org
- The games.example.org Server retrieves metadata which describes the group of resources reachable from their homepage.
- The Server determines from the metadata assertions that all files whose suffix is .jad (to indicate a Java download) are for premium
users.
- The Server determines from Ray's delivery context and exampleISP's identity management system that he is a premium customer
- The Server responds with a page containing all links, available for Ray to download.
Motivates:
3.1.1 Making Assertions;
3.1.2 The Role of a Description Resource;
3.1.3 Grouping;
3.1.4 Composite Assertions;
3.1.8 Reference;
3.1.9 Standard Vocabularies;
3.1.10 Identity;
3.1.11 Unambiguous;
3.2.1 Authentication;
3.2.2 Separation of Description and Resource;
3.3.1 Machine-Readable;
3.3.2 Formal Grammar;
3.3.4 Compact.
2.2 Trustmarks
There are several possible models in which assertions and claims can be made, authenticated and reported to the end user.
Each of the following has several elements in common but differs in details such as whether it is the content provider or
the trust mark operator that makes the original claim, whether the data is stored on the trust mark operator's servers or
alongside the content itself, and whether the trust mark operator provides the description or the authentication
for a description.
2.2.1 Browser Display
Joseph installs a web browser plugin on his personal computer designed to aggregate and interpret safety/reliability
information about Web sites from various sources, such as reputation and accreditation services. The web browser
plugin provides a visual indication of whether the Web site that Joseph is currently visiting is considered trustworthy or not.
The plugin retrieves information about Web sites using several methods. One of these methods involves querying
the Description Resource associated with a Web site.
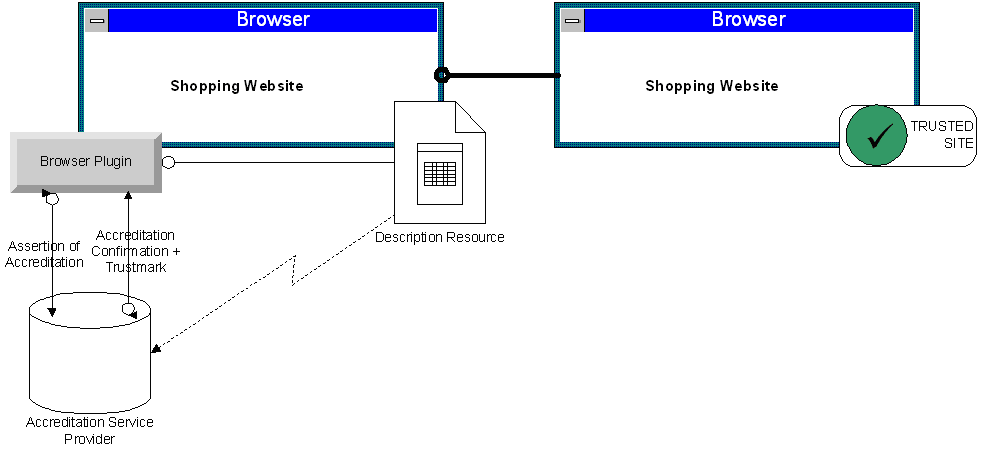
Diagrammatic representation of Use case 2.2.1 (Trust Mark)
Joseph visits a Web site to do some holiday shopping. The browser plugin identifies the site's Description Resource, which
asserts that the Web site has been certified by an accreditation service and provided with a trustmark.
The plugin determines that the accreditation and trustmark are provided by a known entity with a validation
mechanism in place. The plugin queries the accreditation service provider by submitting the assertion of
the Web site's accreditation.
The accreditation service provider validates the assertion of accreditation and provides a graphic file
containing a trustmark. The plugin displays the trustmark to Joseph along with a visual indication that
the Web site has a good reputation.
2.2.2 Compliance Monitoring
This use case refers to the following terms.
- Evaluator
- Evaluates Web content and if it complies with rules, issues a label to the Web site owner.
- Regulator
- A body that oversees quality and accessibility of Web content. Needs to be able to read labels published by Web sites.
- Robot
- An automated system used by the Regulator to read labels on Web sites.
- Authentication Service
- A Web service that attests to the validity and authenticity of labels. Must be able to read the labels used by Evaluators.
- Report generator
- An application that collates and summarizes compliance information provided by the Robot in a form suitable for human users employed by the Regulator.
A government department (regulator) is responsible for overseeing the accessibility of all
Web sites produced by different levels of government: national and local. It has approved a number of
private-sector companies to carry out accessibility evaluation work but there is a need for some mechanism
for the evaluators to label the sites in a reliable and machine-readable way, to allow automated monitoring.
The evaluators provide Web sites with labels. Web site administrators embed links to the labels in their
pages. A robot used by the government department regularly crawls the Web sites and reads the labels, and
checks the data for authenticity and validity using a web service provided by a third-party Authentication
Service. A report generator produces progress reports and violation notices based on the information from
the data.
2.2.3 Direct Data Provision
The Example Trustmark Scheme reviews online traders, providing a trustmark for those that meet a set of published criteria.
The scheme operator wishes to make its trustmark available as machine-readable code as well as a graphic so that content
aggregators, search engines and end-user tools can recognize and process them in some way.
The trustmark operator maintains a database of sites it has approved and makes this available in two ways:
Firstly, the trusted site includes a link to the database. A user agent visiting the site detects and follows the
link to the trustmark scheme's database from which it can extract the description of the particular site in real time.
Secondly, the scheme operator makes the full database available in a single file for download and processing offline.
Since the actual data comes directly from the trustmark scheme operator, it is not open to corruption by the online trader and can
therefore be considered trustworthy to a large degree. To reduce the risk of spoofing, however, the data is digitally signed.
2.2.4 Description Authentication
Mrs. Bryanton teaches 8 year olds at her local school. An IT enthusiast, she makes her teaching materials available through
her personal Web site. She adds a Description Resource to her material that declares the subject matter and curriculum area.
In order to gain wider trust in her work she submits her site for review by her local education authority. That body
then publishes its own Description Resource that declares Mrs Bryanton's Description Resource to be accurate.
Motivates:
3.1.1 Making Assertions;
3.1.2 The Role of a Description Resource;
3.1.3 Grouping;
3.1.4 Composite Assertions;
3.1.5 Multiple DRs;
3.1.6 Independence;
3.1.7 Attribution;
3.1.8 Reference;
3.1.9 Standard Vocabularies;
3.1.10 Identity;
3.1.11 Unambiguous;
3.2.1 Authentication;
3.2.2 Separation of Description and Resource;
3.2.4 Link to Test Results;
3.2.5 Bulk Data Transfer;
3.3.1 Machine-Readable;
3.3.2 Formal Grammar;
3.3.3 Human Readable;
3.3.4 Compact;
3.3.5 Images.
2.3 Semantic Annotation
The use cases in this section highlight the potential benefit of Description Resources to content aggregators, search engines and related services.
Note, sections 2.3 and 2.4 in the previous version of this document have been rearranged
but the content is the same except for use case 2.3.1 which is new.
2.3.1 Semantic Search
Raman in Bangalore publishes a globally popular sports website that
features Soccer, Gridiron, Gaelic football, and Australian rules
football channels. Raman wants to ensure that when users around the
world search for 'football' that the appropriate channel is included in
the search results, based on their country location. As such he
publishes an accurate description of each channel for search engines to
process.
Gautam in London likes to keep up to date with sport. He enters the
search term 'Football news' into a search engine which, based on his
location, gives priority to those resources in its index that have
metadata explicitly describing the content as being about the game of
soccer. As such Raman's soccer channel is included in the results.
Bill in Silicon Valley also enters the search term 'Football news' into
a search engine which, based on his location, gives priority to those
resources in its index that have metadata explicitly describing the
content as being about the game of Gridiron; and Raman's Gridiron
channel is included in the results.
2.3.2 An Explicit Viewpoint
Fred operates an antiracism education site which aggregates and curates content from around the Web. Fred wants to
label the resources that he aggregates such that educational and other institutions may harvest the resources and associated
commentary and metadata automatically for reuse within their instructional support systems, etc.
One of the ways in which Fred wants to curate resources is to say about them that they are pedagogically useful but
politically noxious. For example, some sites on the Web make claims about Martin Luther King, Jr that are motivated
by a racist ideology and are historically indefensible. Fred's vocabulary allows him to claim that such resources
are pedagogically useful for purposes of analysis, but that they are otherwise suspicious and should only be consumed by
students in an age-appropriate manner or with appropriate supervision, etc. In other words, Fred needs to be able to
make sharply divergent claims about resources: (1) that they are noteworthy, and (2) that they are, from his perspective,
dangerous or noxious or troublesome.
The social book-marking site tags.r.us allows their users to tag any
resource and so provides a service through which people can annotate
both their own and others' resources.
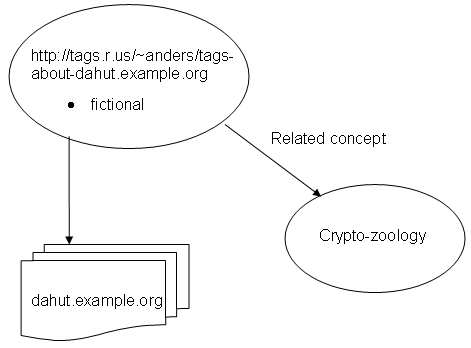
Anders, a zoologist and tags.r.us user, finds a website about the dahut,
an allegedly undescribed animal that lives in the French Alps. Anders
wants to make sure that it is understood by readers that this is a
fictional character, but also that it is interesting to understand the full spectrum of
cryptozoological thinking, and thus tags it "fictional".
The word "fictional" is not very useful without context, so to enable
such user-defined tags to be shared with others, tags.r.us allows users
to assign a link between their own tags and a Description Resource,
that provides the context that it is about an alleged fictional animal.
An agent can thus use the tag as appropriate, processing the explicit
semantics provided by the DR but perhaps presenting other users with
Anders' original tags.
Diagrammatic representation of Use case 2.4.2 (User Defined Tags)
This use case is very similar to the previous one. The important difference between them being that in 2.3.2
the description is made using only explicit semantics. In this use case, user-defined tags (i.e. free text) are used but these are then associated
with a semantically explicit description. In both cases, the opinions expressed are relatively complex so that the semantics are
critical. Furthermore, these are also scenarios where there is unlikely to be any relationship between the content provider and
the individual describing the content.
2.3.4 Rich Metadata for RSS/ATOM
Dave Cook's Web site offers reviews of children's films and the site is summarized in both RSS and ATOM feeds. Most of
the films reviewed have an MPAA rating of G and/or British Board of Film Classification rating of U. This is declared in
a rating for the channel as a whole. However, Dave includes reviews of some films rated PG-13 or 12 respectively which
is declared at the item level and overrides the channel level metadata.
The actual rating information comes from an online service operated by the relevant film classification board itself
and is identified using a URI and human-readable text. The movie itself is identified by either an ISAN number or
the relevant Internet Movie Database entry ID number. Trust is implicit given the source of
the data, which is indicated by a link to Dave's site's policy.
Separately, Fred combines Dave Cook's and other review feeds to provide alternative reviews of the movies by
transforming the ATOM feeds into RDF and creating an aggregate view using SPARQL queries.
Motivates:
3.1.1 Making Assertions;
3.1.2 The Role of a Description Resource;
3.1.3 Grouping;
3.1.5 Multiple DRs;
3.1.6 Independence;
3.1.7 Attribution;
3.1.8 Reference;
3.1.9 Standard Vocabularies;
3.1.10 Identity;
3.1.11 Unambiguous;
3.2.1 Authentication;
3.2.2 Separation of Description and Resource;
3.2.3 Default Description;
3.2.5 Bulk Data Transfer;
3.3.1 Machine-Readable;
3.3.2 Formal Grammar;
3.3.3 Human Readable;
3.3.4 Compact
3.3.6 User-Generated Tags.
2.4 Scalar Classification
A company named Advance Medical Inc. reviews medical literature on the Web based on a range of quality criteria
such as the qualifications of the author(s), the methodology used and the research evidence presented. The
criteria may be changed according to current scientific and professional developments. The review process
leads to medical literature being classified in two ways:
Quality of Content
Level A: Excellent
Level B: Good
Level C: Acceptable
Peer Review
Level A: Content has been subjected to peer review
Level B: Content has not been subject to peer review
The Quality of Content classification is scalar. i.e. meeting the criteria for Level A implies also meeting Level B
which in turn implies meeting Level C. In contrast, meeting Level A for Peer Review does not imply meeting Level B.
The company produces data that declares the classification levels and provides a summary of each document it has
reviewed. The data is stored in a metadata repository which can be accessed via the Web.
M.D. Smith uses the data in the repository to make decisions about heath care for specific clinical circumstances.
Motivates:
3.1.1 Making Assertions;
3.1.2 The Role of a Description Resource;
3.1.3 Grouping;
3.1.4 Composite Assertions;
3.1.5 Multiple DRs;
3.1.6 Independence;
3.1.7 Attribution;
3.1.9 Standard Vocabularies;
3.1.10 Identity;
3.1.11 Unambiguous;
3.2.1 Authentication;
3.2.2 Separation of Description and Resource;
3.2.4 Link to Test Results;
3.2.5 Bulk Data Transfer;
3.3.1 Machine-Readable;
3.3.2 Formal Grammar;
3.3.3 Human Readable;
3.3.5 Images
2.5 Expressing Editorial Policy
VLCC, (the Very Large Content Company) offers millions of items of content which are delivered through a variety
of branded channels. Its strict editorial policies dictate that before publication, all content is reviewed by a
member of the editorial team who checks for compliance with those policies. This is encoded in a description covering
all its brands that states "VLCC works to ensure that all its content meets W3C Web Accessibility Initiative
level AA and is suitable for all audiences unless otherwise stated. If you find any of our content does not
meet these standards, please contact us."
The editor is responsible for adding two further descriptions:
- Key words (tags). For example: "News, Middle East", "Lifestyle, DIY, Decorating", "Entertainment, Celebrity Gossip."
- An age-rating, taken from a set of pre-defined options. For example, content delivered through VLCC's 'Youth of Today' brand
is usually suitable for all ages, however, occasionally, content aimed at young adults is published that might be inappropriate for
younger children and is described by one of the other available ratings in line with the overall editorial policy.
Motivates:
3.1.1 Making Assertions;
3.1.2 The Role of a Description Resource;
3.1.3 Grouping;
3.1.4 Composite Assertions;
3.1.5 Multiple DRs;
3.1.7 Attribution;
3.1.8 Reference;
3.1.9 Standard Vocabularies;
3.1.10 Identity;
3.1.11 Unambiguous;
3.2.1 Authentication;
3.2.2 Separation of Description and Resource;
3.2.3 Default Description;
3.2.4 Link to Test Results;
3.3.1 Machine-Readable;
3.3.2 Formal Grammar;
3.3.3 Human Readable;
3.3.6 User-Generated Tags.
3 Requirements
The following requirements are derived from the preceding use cases. They have been assigned to thematic groups as an aid to readability.
3.1 Fundamentals
3.1.1 Making Assertions
It must be possible for both resource creators and third parties to make assertions about information resources.
3.1.2 The Role of a Description Resource
A Description Resource, DR, must be able to describe aspects of
a group of information resources using terms chosen from different vocabularies. Such
vocabularies might include, but are not limited to, those that describe a
resource's subject matter, its suitability for children, its conformance
with accessibility guidelines and/or Mobile Web Best Practice, its
scientific accuracy and the editorial policy applied to its creation.
3.1.3 Grouping
It must be possible to define sets of resources and have DRs refer to those sets. For example, DRs can refer to all the
pages of a Web site, defined sections of a Web site, or all resources on multiple Web sites.
3.1.4 Composite Assertions
DRs must support a single composite assertion taking the place of a number of other assertions. For example,
WAI AAA can be defined as WAI AA [WAI] plus a series of detailed descriptors. Other
examples include mobileOK and age-based classifications from a named authority.
3.1.5 Multiple DRs
It must be possible for more than one DR to refer to the same resource or group of resources.
Furthermore, it must be possible for a resource to refer to one or more DRs. It follows that there must be a linking mechanism between content and
descriptions.
3.1.6 Independence
DRs must be able to point to any resource(s) independently of those resources.
3.1.7 Attribution
A DR must include assertions about itself using appropriate vocabularies. As a minimum, a DR must have data describing who
created it. Good practice would be to declare its period of validity, how to provide feedback about it, who last verified it and when etc.
3.1.8 Reference
It must be possible for a DR to refer to other DRs or other sources of data that support the claims and assertions made.
3.1.9 Standard Vocabularies
There must be standard vocabularies for assertions about DRs.
3.1.10 Identity
DRs, their components and individual assertions should have unique and unambiguous identifiers.
3.1.11 Unambiguous
Assertions within DRs should be made using descriptors that themselves have unique identifiers.
3.2 Fitting in with Commercial or Other Large Scale Workflows
3.2.1 Authentication
It must be possible for DRs to be authenticated.
3.2.2 Separation of Description and Resource
It must be possible to create and edit DRs without modifying the resources they describe
3.2.3 Default Description
It must be possible to identify a default DR for a group of resources and provide an override at specific locations within the scope of the DR.
3.2.4 Link to Test Results
It must be possible to link DRs with specific test results that support the claims made.
3.2.5 Bulk Data Transfer
It must be possible for a data provider to make its repository of Description Resources available as a bulk download.
3.3 DRs for Humans and Machines
3.3.1 Machine-Readable
It must be possible to express DRs in a machine-readable way.
The machine-readable form of a DR must be defined by a formal grammar.
3.3.3 Human Readable
DRs must provide support for a human readable summary of the claims it contains.
3.3.4 Compact
It must be possible to express DRs in a compact form.
3.3.5 Images
It must be possible to associate DRs with images.
It must be possible to encode user-generated tags in DRs.
4 Acknowledgements
The editor acknowledges the contributions of members of the POWDER WG
and the WCL-XG in compiling this document. In particular
Dan Appelquist, Dave Rooks, Pantelis Nasikas, Kjetil Kjernsmo, Kai-Dietrich Scheppe, Kendall Clark, Jo Rabin, Kevin Smith,
Alan Chuter and Zeph Harben.
5 References
- [MOK]
- MobileOK is a trustmark that can be applied to online content that meets criteria derived from the Mobile Web Best Practices
- [WAI]
- WAI Conformance is defined in the W3C Web Content Accessibility Guidelines
6 Changes Since Previous Version
The following changes have been made since the previous version of this document was published.