Composite Capabilities/Preference Profiles: Requirements and
Architecture
W3C Working Draft 21 July 2000
- This version:
- http://www.w3.org/TR/2000/WD-CCPP-ra-20000721/
- Latest version:
- http://www.w3.org/TR/CCPP-ra/
- Previous version:
- http://www.w3.org/TR/2000/WD-CCPP-ra-20000228/
- Editors:
- Mikael Nilsson, mikael.nilsson@ks.ericsson.se,
Ericsson
- Johan Hjelm, hjelm@w3.org,
W3C/Ericsson
- Hidetaka Ohto, ohto@w3.org,
W3C/Panasonic
Copyright ©
2000 W3C ® (MIT, INRIA, Keio), All
Rights Reserved. W3C liability,
trademark,
document
use and software
licensing rules apply.
This document outlines the requirements for a CC/PP framework, vocabulary,
and trust model, and provides an overview of an architecture that satisfies
these requirements. It represents the current consensus of the working
group.
This document is a working draft made available by the World Wide Web
Consortium (W3C) for discussion only. This indicates no endorsement of its
content. This is work in progress, representing the current consensus of the
working group, and future updates and changes are likely.
The working group is part of the W3C Mobile Access activity.
Continued status of the work is reported on the CC/PP Working Group Home Page (Member-only link).
It incorporates suggestions resulting from reviews and active participation
by members of the IETF CONNEG working group and the WAP Forum UAprof drafting
committee.
Please send comments and feedback to www-mobile@w3.org.
A list of current W3C Recommendations and other technical documents can be
found at http://www.w3.org/TR/.
Table of Contents
- 1. Executive summary
- 2. Use cases
- 3. Design assumptions
- 4. Requirements summary
- 5. Design goals
- 6. Architectural
description
- 7. References
- 8. Acknowledgments
- Appendix 1: Requirements used to derive the
high-level requirements
- Appendix 2: Protocol requirements
1.1 Overview
The goal of the CC/PP framework is to specify how client devices express
their capabilities and preferences (the user agent profile) to the server that
originates content (the origin server). The origin server uses the "user agent
profile" to produce and deliver content appropriate to the client device. In
addition to computer-based client devices, particular attention is being paid
to other kinds of devices such as mobile phones.
1.2 Executive summary of requirements.
The requirements on the framework emphasize three aspects: Flexibility,
extensibility, and distribution. The framework must be flexible, since we can
not today predict all the different types of devices that will be used in the
future, or the ways those devices will be used. It must be extensible for the
same reasons: It should not be hard to add and test new descriptions. And it
must be distributed, since relying on a central registry might make it
inflexible.
1.3 Architecture
The basic problem that the CC/PP framework addresses is to create a
structured and universal format for how a client device tells an origin server
about its user agent profile. This work aims to present a container that can
be used to convey the profile, and is independent on the protocols used to
transport it. It does not present mechanisms or protocols to facilitate the
transmission of the profile.
The framework describes a standardized set of CC/PP attributes - a
vocabulary - that can be used to express a user agent profile in terms of
capabilities, and the users preferences for the use of these capabilities.
This is implemented using the XML [XML] application RDF
[RDF]. This enables the framework to be flexible,
extensible, and decentralized, thus fulfilling the requirements.
RDF is used to express the client device's user agent profile. The client
device may be a workstation, personal computer, mobile terminal, or set-top
box.
When used in a request-response protocol like HTTP, the user agent profile
is sent to the origin server which, subsequently, produces content that
satisfies the constraints and preferences expressed in the user agent profile.
The CC/PP framework may be used to convey to the client device what variations
in the requested content are available from the origin server.
Fundamentally, the CC/PP framework starts with RDF and then overlays a
CC/PP-defined set of semantics that describe profiles.
The CC/PP framework does not specify whether the client device or the
origin server initiates this exchange of profiles. What the CC/PP framework
does specify is the RDF usage and associated semantics that should be applied
to all profiles that are being exchanged.
In this section, we describe use cases for the use of a profile to adapt
information for presentation by a client. The use cases are intended to
describe a number of situations where the CC/PP format can be used; however,
they are not an exhaustive list, nor are the behaviour of any element in the
use cases described below mandatory. Rather, they represent the working groups
best understanding at the time.
2.1 Web CC/PP usecases
2.1.1 Background
Using the World Wide Web with content negotiation as it is designed today
enables the selection of a variant of a document. Using an extended
capabilities description, an optimized presentation can be produced. This can
take place by selecting a style sheet that is transmitted to the client, or by
selecting a style sheet that is used for transformations. It can also take
place through the generation of content, or transformation, e.g. using XSLT [XSLT].
The CC/PP Exchange Protocol [CCPPex] extends this
model by allowing for the transmission and caching of profiles, and the
handling of profile differences.
This use case in itself consists of two different use cases: The origin
server receives the CC/PP profile directly from the client; the origin server
retrieves the CC/PP profile from an intermediate repository.
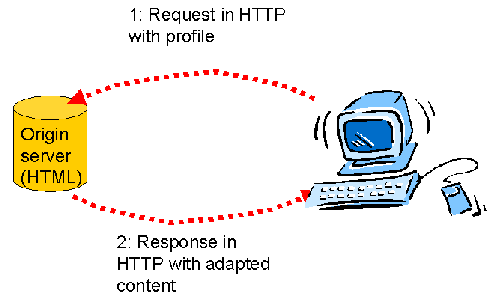
2.1.2 Profile is communicated directly to origin server
This use case describes a case where the profile is used by an origin
server on the web to adapt the information returned in the request.
The CC/PP Exchange Protocol [HTTPex] creates a
modified HTTP GET which carries the profile or the profile difference. The
extended content negotiation with the CC/PP Exchange Protocol uses the CC/PP
format to describe the device. In this context, no vocabulary has been
defined. The existence of the CC/PP Exchange protocol is assumed.
2.1.2.1 Protocol interactions
When the interaction passes directly between a client and a server, the
process is relatively simple: The user agent sends the profile information
with the request, and the server returns adapted information. The interaction
takes place over an extended HTTP method, as described in the CC/PP Exchange
framework.
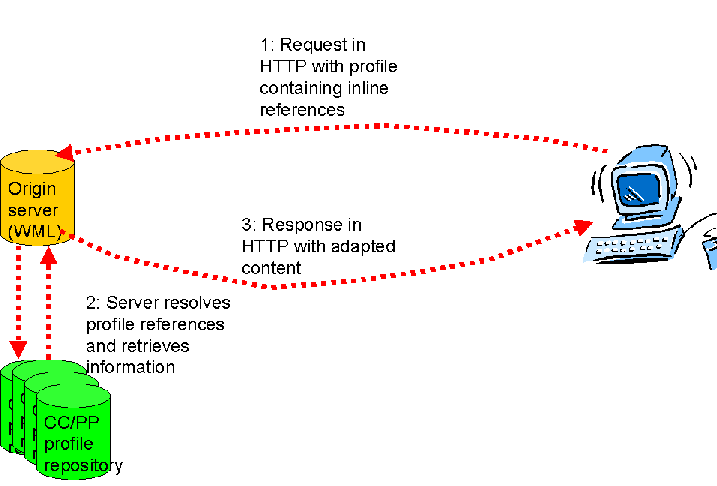
2.1.3 CC/PP profile is retrieved from repository
When the profile is composed by resolving inline references from a
repository for the profile information, the process is slightly more
complicated, but in principle the same.
The interactions take place in more steps, but is basically the same:
1: Request from client with profile information.
2: Server resolves and retrieves profile (from CC/PP repository on the
network), and uses it to adapt the content.
4: Server returns adapted content.
5: Proxy forwards response to client.
Note that the notion of a proxy resolving the information and retrieving it
from a repository might assume the use of an XML processor and encoding of the
profile in XML.
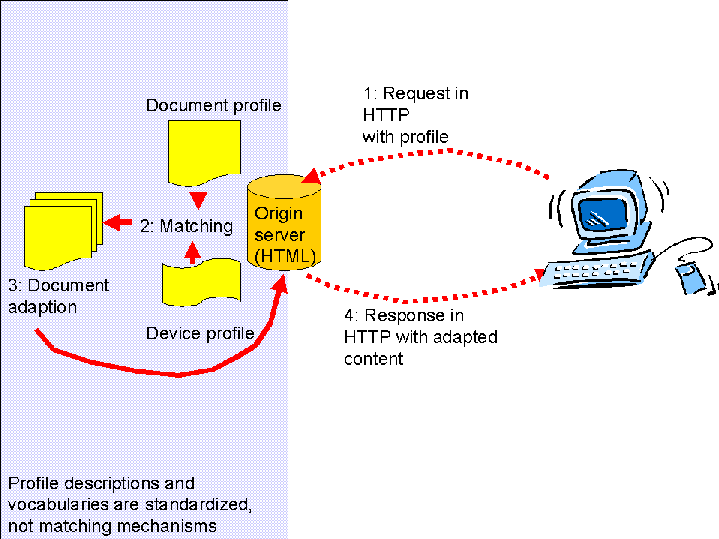
2.1.4 The document profile use case
In case the document contains a profile, the above could still apply.
However, there will be some interactions inside the server, as the client
profile information needs to be matched with the document profile. The
interactions in the server are not defined. This group will not standardize
the matching algorithm. We will standardize the profile system, which is the
interface to it.
- Request (extended method) with profile information.
- Document profile is matched against device profile to derive optimum
representation.
- Document is adapted.
- Response to client with adapted content.
2.1.4 Requirements
No formal requirements document has been formulated in this activity.
However, the use of the CC/PP Exchange Protocol is assumed.
One requirement is that the integrity of the information is guaranteed
during transit.
In the proxy use case, a requirement is the existence of a method to
resolve references in the proxy. This might presume the use of an XML
processor and XML encoding.
The privacy of the user needs to be safeguarded. This is not a technical
requirement, but a societal.
The document profile and the device profile can use a common vocabulary for
common features. They can also use compatible feature constraining forms so
that it is possible to match a document profile against a receiver profile and
determine compatibility. If not, a mapping needs to be provided for the
matching to take place.
2.2. The WAP usecase
This use case describes a mixed architecture with an active proxy in the
network. The use of CC/PP profiles in the WAP architecture is more fully
described in [UAProf].
2.2.1 Background
In the WAP Forum, an architecture optimized for connecting devices working
with very low bandwidths and small message sizes has been developed. In
version 1.2 of this architecture, a format based on RDF is used to communicate
client profile information.
The WAP Forum architecture is based on a proxy server, which acts as a
gateway to the optimized protocol stack for the mobile environment. It is to
this proxy which the mobile device connects. On the wireless side of the
communication, it uses an optimized, stateful protocol (Wireless Session
Protocol, WSP [WSP]; and an optimized transmission
protocol, Wireless Transaction Protocol, WTP [WTP]); on
the fixed side of the connection, it uses HTTP [HTTP/1.1]. The content is marked up in WML, the
Wireless Markup Language of the WAP Forum.
The mobile environment requires small messages and has a much narrower
bandwidth than fixed environments.
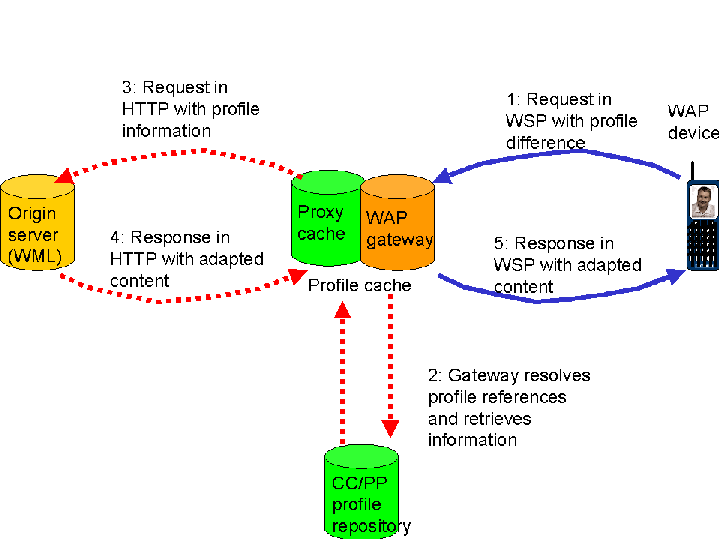
2.2.2 Architecture
When a user agent profile is used with a WAP device, it looks like
this:
- WSP request with profile information or difference relative to a
specified default.
- Gateway caches WSP header, composes the current profile (using the
cached header as defaults, and diffs from the client). UAprof values can
change at setup or resume of session.
- Gateway passes request to server using extended HTTP method.
- Server returns adapted information.
- Response in WSP with adapted content.
The user agent profile is transmitted as a parameter of the WSP session to
the WAP gateway and cached; it is then transferred over HTTP using the CC/PP
Exchange Protocol [CCPPex], which is an application of
the HTTP Extension Framework[HTTPex].
Note that the WAP system uses WML[WML] as its content
format, not HTML. This is an XML application, and the adaption could for
instance be transformation from another XML format into WML.
2.2.2.1 Vocabulary
The WAP UAPROF group has developed a core vocabulary for mobile devices, as
presented in [UAProf].
2.2.3 Requirements
The WAP Forum went through an extensive requirements gathering process
before producing their specifications. The requirements document lists a
number of requirements that has been placed on the solution. These have been
included in our requirements with the prefix UAprof. For more information, see
[UAProf].
Requirements for future versions are:
Addressing XML fragments
Secure transmission
2.3. The MIME multipart usecase
2.3.1 Background
The Conneg working group in the IETF has developed a form of media feature
descriptors, which are registered with IANA. Like the CC/PP format and
vocabulary, this is intended to be independent of protocol. The Conneg working
group also defined a matching semantics, based on constraints.
2.3.2 Architecture
The CONNEG framework defines an IANA registry for feature tags, which are
used to label media feature values associated with the presentation of data
(e.g. display resolution, color capabilities, audio capabilities, etc.). To
describe a profile, CONNEG uses predicate expressions ("feature predicates")
on collections of media feature values ("feature collection") as an acceptable
set of media feature combinations ("feature set"). The same basic framework is
applied to describe receiver and sender capabilities and preferences, and also
document characteristics. Profile matching is performed by finding the feature
set that matches two (or more) profiles. This involves finding the feature
predicate that is equivalent to the logical-AND of the predicates being
matched. (See RFCs [RFC2506] and [RFC2533] for further information.)
2.3.2.1 Mime multipart server-initiated use case
The Conneg system is not dependent on any one protocol, and could
conceivably be used in all the use cases above, given that the information set
to be matched could be expressed in the Conneg format.
Conneg is protocol independent, but can be used for server-initiated
transactions.
Here is what the server-initiated use case would look like:
- Server sends to proxy
- Proxy retrieves profile from client (or checks against a cache)
- Client returns profile
- Proxy formats information and forwards it
2.3.2.2 Information structure(s)
The Conneg system uses a structured text format to describe the device and
its capabilities. This is described in [RFC2533].
2.3.2.3 Vocabulary
The Conneg working group has defined a set of core media features, which
are described in [RFC2543]. A comparison of these and
the UAPROF features is found in [UAProf].
2.3.3 Requirements
The Conneg group started its work with developing an extensive requirements
document, which is found in [RFC2703]. They are
listed as CONNEG in appendix 2.
2.4. The TV/broadcast usecase
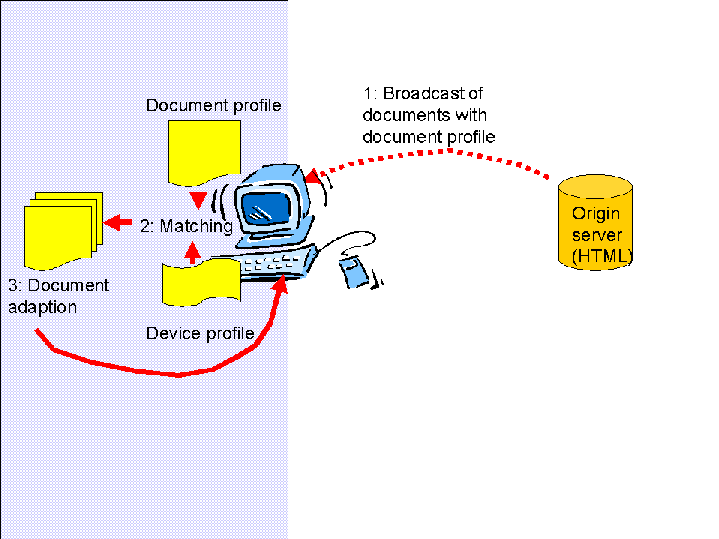
This use case describes a push situation, where a broadcaster sends out an
information set to a device without a backchannel. The server can not get
capabilities for all devices. So it broadcasts a minimum set of elements. Or a
multipart document, which is then adapted to the optimal presentation for the
device.
2.4.1 Background
Television manufacturers desire to turn their appliances into interactive
devices. This effort is based on the use of XHTML as language for the content
representation, which for instance enables the use of content profiles as seen
in 2.2.4.
2.4.2 Architecture
Unlike the use cases above, a television set does not have a local
intelligence of its own, and does not allow for bidirectional communication
with the origin server. This architecture also applies to several different
device classes, such as pagers, e-mail clients and other similar devices.
It is not the case that they are entirely without interaction, however. In
reality, these devices follow a split-client model, where the broadcaster,
cable head-end, or similar entity interacts with the origin server, and sends
a renderable version of the content to the part of the client which resides at
the user site. In this aspect, they resemble the intermediary proxy in
2.5.
There are however also use cases where the entire data set is downloaded
into the client, and the optimal rendering is constructed there, for instance
in a settop box. This resembles 2.1.4, except that the matching of the
document profile with the device capabilities does not take place in the
origin server, but in the client. In these cases, the CC/PP client profile
will need to be matched against a document profile, representing the authors
preferences for the rendering of the document.
2.4.3 Protocol interactions
- Document is pushed to the client including alternate information and
document profile.
- Client matches the rules in the document profile and its own
profile.
- The client adapts content to its optimal presentation using the derived
intersection of the two sets.
2.4.3.1 Information structure(s)
The CC/PP profile and the document profile should ideally be in the same
format, as described in 2.2.4.
2.4.3.2 Vocabulary
The level of detail in a vocabulary that is intended to enable rendering of
information on devices without an intelligence of their own is unclear. See
section 6.3 for a further discussion on the vocabulary developed by the group,
and possible extensions.
2.4.4 Requirements
Since this can be seen as a special case of the application of document
profiles, no separate requirements have been derived.
2.5 Assertion of capabilities by intermediate network elements (proxies
and caches)
This use case describes how an intermediate entity interacts with the
profile and the information received in the response.
2.5.1 Background
When a request for content is made by a user agent to an origin server, a
CC/PP profile describing the capabilities and preferences is transmitted along
with the request. It is quite conceivable that intermediate network elements
such as gateways and transcoding proxies that have additional capabilities
might be able to translate or adapt the content before rendering it to the
device. Such capabilities are not known to the user agents and therefore
cannot be included in the original profile. However, these capabilities would
need to be conveyed to the origin server or proxy serving/ generating the
content. In some instances, the profile information provided by the requesting
client device may need to be overridden or augmented.
For instance, consider a user agent that can render gif images. If there is
a transcoding proxy in the network that has the ability to convert jpeg images
to gif, the proxy can assert this capability to the origin server that may be
able to render content only in jpeg. Similarly, a gateway may wish to add
information to the profile to override the profile information sent by the
requestor, for example, to reflect the policies in place by the network or
gateway operator.
2.5.2 Architecture
CC/PP framework must therefore support the ability for such proxies and
gateways to assert their capabilities using the existing vocabulary or
extensions thereof. This can be done as amendments or overrides to the profile
included in the request. Given the use of XML as our base format, these can be
inline references, to be downloaded from a repository as the profile is
resolved (see use case 2.2.3).
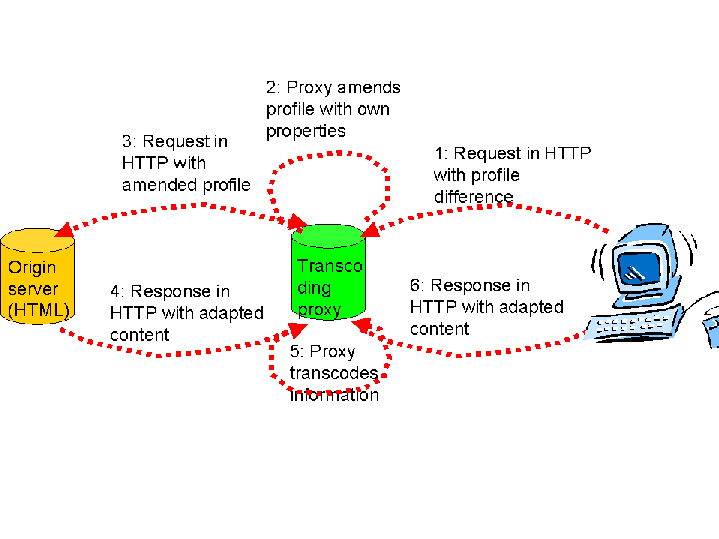
2.5.3 Protocol interactions
1. The CC/PP compliant user agent requests content with the profile.
2. The transcoding proxy appends additional capabilities (profile segment),
or overrides the default values, and forwards the profile to the network.
3. The origin server constructs the profile and generates adapted
content.
4. The transcoding proxy transcodes the content received based on its
abilities, and forwards the resulting customized content to the device for
rendering.
2.5.3.1 Information structure(s)
The CC/PP framework can still be used, given the ability of overrides or
amendments. It is also possible that users wish to select attributes that can
not be overridden.
2.5.3.2 Vocabulary
No specific vocabulary is necessary to express this use case.
2.5.4 Requirements
This use case requires that entries can be added to the CC/PP profile.
An implicit requirement is that this takes place in a secure way,
safeguarding the integrity of the original profile.
The following assumptions have been identified during the process of the
work. These assumptions are basic tenets of the design, as well as assumptions
about other elements in the process, such as network elements and origin
servers. There are implicit requirements inherent in this, which constitute
MUST requirements (e.g. the implication of internationalization on the use of
XML).
The basic assumptions are:
- We use RDF
- We use XML (with all that is inherent in that)
- We use the structures in the CC/PP Note
- HTTP is the assumed protocol but the framework must also be
transportable over other protocols
- Rendering of information is a primary goal but not exclusive
- A wide variety of devices will be supported by customizing an
information set for them (so there is no need to design in all possible
that will occur in the future).
- The transmission of the CC/PP profile and the transmission of the
content are separate.
3.2 Security considerations
Security is here understood to be something else than privacy and trust.
Security, in this context, is the safeguarding of the transmitted information
in the course of transmission. These problems are usually addressed by the
protocol used to carry the information, not the information structure or
vocabulary itself. Privacy may be handled using the P3P mechanism of the W3C
[P3P]. Integrity of the information is another matter,
and is addressed in the requirements under section 4.1.3 below.
These requirements have been derived from the usecases above. But since
several efforts exist to produce systems for content negotiation, we have also
derived requirements from the work of others, especially the IETF Conneg
working group (CONNEG) and the WAP Forum UAPROF Drafting Committee (UAP).
Requirements have also been derived from the HTML working group in the W3C
(XHTML), and from our own face-to-face meetings (F2F). Requirements have also
been derived from experimental implementations presented to the working group
(CCPP-IMPL).
The requirements are summarized in the order they impact the deliverables
of the working group. However, requirements will typically impact the entire
architecture, not one single deliverable. This listing is therefore for
convenience only.
In addition, we have derived a set of protocol requirements. While the
working group is not chartered to develop a protocol, it is still clear that
its work will impact the design of any protocol used in the content
negotiation process. These requirements have therefore been highlighted in
Appendix 3.
The fulfillment of these requirements are mandatory for the design of
CC/PP. They are MUST requirements.
4.1. Requirements Listing
4.1.1 Requirements on the framework
- FW1: This group shall develop a framework to specify how client devices
express their capabilities and preferences to a server which uses this
information to produce and deliver content appropriate to the client
device.
- FW-2: The framework shall ultimately enable delivery of content in a
format tailored to the specific device characteristics, application
settings, operating environment and user preferences.
- FW-3: The design shall support the ability to reference capability
information stored separately on various systems and databases in the
network. The profile can be dynamically composed from client-provided
default values and referenced values. It shall be possible to override or
append CC/PP attributes to a profile.
4.1.2 Requirements on the vocabulary and schema
- VS-1: The vocabulary shall allow for the expression of relations between
CC/PP attribute values.
- VS-2: There shall be a stable, common, minimum vocabulary for
designating features and feature sets.
- VS-3: There shall be a simple, uniform way to extend vocabularies.
4.1.3 Requirements on the trust model
- TF1: It must be possible to disclose (at a transaction level) only a
subset of the CC/PP.
- TF2: It must be possible for the originator or recipient of a profile or
a profile element to detect cases where the integrity of the profile was
not violated.
- TF3: The CC/PP trust framework MUST provide a mechanism for a server (or
proxy) that processes a CC/PP profile to indicate whether it requires a
profile to be authenticated.
- TF4: The trust mechanisms are not allowed to break other things that are
important (such as added headers by transcoding proxies, cache matches
etc).
Design goals are not as strong as requirements (SHOULD instead of MUST),
and concern the entire architecture rather than a specific part of it.
The goals for the system are as follows:
- DG-1: It is to consume as little network, client and server resources as
possible.
- DG-2: Vocabulary items are to be defined in RDF Schema. Vocabularies and
profiles can be extended using namespaces. The vocabularies created shall
include vocabularies that are semantically compatible with established
practices, so as to enable speedy adoption and ease of use for
developers.
- DG-3: Digital signatures are to be used as part of the trust
framework.
- DG-4: P3P is to be used as management mechanism for the privacy of
profiles.
- DG-5: Proxies and caches are to be allowed to participate in the
negotiation process, as appropriate.
- DG-6: It shall be possible to match two profiles for equality in a
lightweight manner.
- DG-7: The system shall enable the expression of "hints" in the content
for optimized rendering based on a given, or a set of given, CC/PP
profiles.
- DG-8: The system shall enable less abled users to access information in
a manner that they have defined. (WAI coordination is needed for this
goal).
- DG-9: The system shall be usable with existing protocols. It shall be
possible to describe whether it is mandatory or optional to enforce an
attribute.
5.1 Desirable features and future work
Desirable features are not mandated, and optional to the design only if we
feel like it. In terms of RFC 2119 [RFC2119] they are
MAY-requirements.
FW-4: The framework shall allow for the description of preferences for its
use, either through an algorithm within the framework or through a set of
constraint semantics.
To fulfill the requirements in 3, 4 and 5, the CC/PP working group intend
to produce a framework to handle and structure the profile information. The
working group will also produce a basic vocabulary and describe how this can
be extended (or other vocabularies can be created and referenced). In
addition, the trust model for the work will be described in a separate
document, as well as implementation issues.
6.1 Profile framework
The capabilities of the users client agent, and the preferences for the way
the user wants them to be used, are expressed in a profile. The profile is
constructed of a set of components that can be used to convey a group of
attributes that are in some way related. The profile can consist of URI's that
reference information or properties available in other documents or
profiles.
The components that are available in a profile, along with the applicable
attributes are specified as an instance of an RDF schema [RDF-Schema]. The profile may contain URI's that
reference separately provided information or properties. A user agent or
intermediary network entity can change the value of a CC/PP attribute. RDF is
explained in further detail in section 6.2.
6.2 RDF
6.2.1 Basic RDF Model
The foundation of RDF is a model for representing named properties and
property values. The RDF model draws on principles from various data
representation communities. RDF properties may be thought of as attributes of
resources and in this sense correspond to traditional attribute-value pairs.
RDF properties also represent relationships between resources and an RDF model
can therefore resemble an entity-relationship diagram. (More precisely, RDF
Schemas which are themselves instances of RDF data models are ER diagrams.) In
object-oriented design terminology, resources correspond to objects and
properties correspond to instance variables.
The RDF data model is a syntax-neutral way of representing RDF expressions.
The data model representation is used to evaluate equivalence in meaning. Two
RDF expressions are equivalent if and only if their data model representations
are the same. This definition of equivalence permits some syntactic variation
in expression without altering the meaning. (See Section 6.6 for additional
discussion of string comparison issues.)
The basic data model consists of three object types:
- Resources
- All things being described by RDF expressions are called resources. A
resource may be an entire Web page; such as the HTML document
"http://www.w3.org/Overview.html" for example. A resource may be a part
of a Web page; e.g. a specific HTML or XML element within the document
source. A resource may also be a whole collection of pages; e.g. an
entire Web site. A resource may also be an object that is not directly
accessible via the Web; e.g. a printed book. Resources are always named
by URIs plus optional anchor id:s (see [RFC2396]). Anything can have a URI; the
extensibility of URIs allows the introduction of identifiers for any
entity imaginable.
- Properties
- A property is a specific aspect, characteristic, attribute, or
relation used to describe a resource. Each property has a specific
meaning, defines its permitted values, the types of resources it can
describe, and its relationship with other properties. This document does
not address how the characteristics of properties are expressed; for
such information, refer to the RDF Schema specification).
- Statements
- A specific resource together with a named property plus the value of
that property for that resource is an RDF statement. These three
individual parts of a statement are called, respectively, the subject,
the predicate, and the object. The object of a statement (i.e., the
property value) can be another resource or it can be a literal; i.e., a
resource (specified by a URI) or a simple string or other primitive
datatype defined by XML. In RDF terms, a literal may have content that
is XML markup but is not further evaluated by the RDF processor. There
are some syntactic restrictions on how markup in literals may be
expressed; see Section 6.2.1.
6.2.2 Referencing of external resources
RDF properties may be thought of as attributes of resources and in this
sense correspond to traditional attribute-value pairs. RDF properties also
represent relationships between resources. As such, the RDF data model can
therefore resemble an entity-relationship diagram. The RDF data model,
however, provides no mechanisms for declaring these properties, nor does it
provide any mechanisms for defining the relationships between these properties
and other resources. That is the role of RDF Schema.
Each RDF schema is identified by its own static URI. The schema's URI can
be used to construct unique URI references for the resources defined in a
schema. This is achieved by combining the local identifier for a resource with
the URI associated with that schema namespace. The XML representation of RDF
uses the XML namespace mechanism for associating elements and attributes with
URI references for each vocabulary item used.
Please refer to the Namespaces in XML [XML-name]
document for a complete description of how namespaces can be constructed in
XML/RDF.
6.2.3. RDF Schema Constraints
An RDF schema can declare constraints associated with classes and
properties. In particular, the concepts of domain and range are used in RDF
schemas to make statements about the contexts in which certain properties
"make sense". Although the RDF data model does not allow for explicit
properties (such as an rdf:type property) to be ascribed to Literals (atomic
values), we nevertheless consider these entities to be members of classes
(e.g. the string "John Smith" is considered to be a member of the class
rdfs:Literal.) We expect future work in RDF and XML data-typing to provide
clarifications in this area.
An RDF model that violates any of the consistency constraints specified in
this document is said to be an inconsistent model. The following constraints
are specified: rdfs:domain and rdfs:range constraints on property usage, the
rule that rdfs:subPropertyOf and rdfs:subClassOf properties should not form
loops, plus any further consistency constraints defined using the
rdfs:ConstraintResource extensibility mechanism. Different applications may
exhibit different behaviors in the face of an inconsistent model.
Some examples of constraints include:
- That the value of a property should be a resource of a designated class.
This is expressed by the range property. For example, a range constraint
applying to the 'author' property may express that the value of an
'author' property must be a resource of class 'Person'.
- That a property may only be used on resources of a certain class. For
example, that an 'author' property could only originate from a resource
that was an instance of class 'Book'. This is expressed using the domain
property.
RDF schemas can express constraints that relate vocabulary items from
multiple independently developed schemas. Since URI references are used to
identify classes and properties, it is possible to create new properties whose
domain or range is constrained to be a class defined in another namespace.
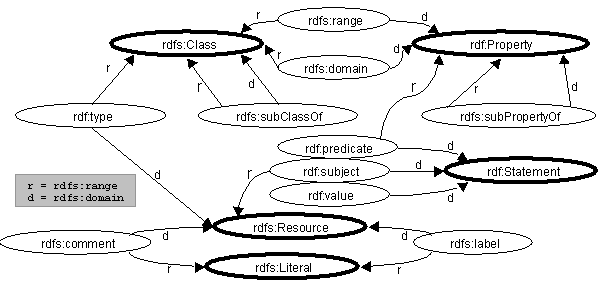
The RDF Schema uses the constraint properties to constrain how its own
properties can be used. These constraints are shown below in figure 7. Nodes
with bold outlines are instances of rdfs:Class.
Please refer to the RDF Schema [RDF-schema] for
a more complete description of RDF Constraints.
6.3 Vocabulary
A CC/PP profile describes client capabilities in terms of a number of
"CC/PP attributes", or "features". Each of these features is identified by a
name in the form of a URI. A collection of such names used to describe a
client is called a "vocabulary".
CC/PP defines a small, core set of features that are applicable to wide
range of user agents, and which provide a broad indication of a clients
capabilities. This is called the "core vocabulary". It is expected that any
CC/PP processor will recognize all names in the core vocabulary, together with
an arbitrary number of additional names drawn from one or more "extension
vocabularies".
When using names from the core vocabulary or an extension vocabulary, it is
important that all system components (clients, servers, proxies, etc.) that
generate or interpret the names all apply a common meaning to the same name.
It is preferable that different components use the same name to refer to the
same feature, even when they are part of different applications, as this
improves the chances of effective interworking across applications that use
capability information.
Within an RDF expression describing a device, a vocabulary name appears as
the label on a graph edge linking a resource to a value for the named
attribute. The attribute value may be a simple string value, or another
resource, with its own attributes representing the component parts of a
composite value.
+-------------+ +------------+
| Resource |---attribute-name--->| Attribute |
| | | value |
+-------------+ +------------+
Simple string values may be used in comparison constraints
[Ref-CCPP-format-document], which may interpret the attribute value as a
textual or numeric value.
6.3.1 Vocabulary extensions
Vocabulary extensions are used to identify more detailed information than
can be described using the core vocabulary. Any application or operational
environment that uses CC/PP may define its own vocabulary extensions, but
wider interoperability is enhanced if vocabulary extensions are defined that
can be used more generally; e.g. a standard extension vocabulary for imaging
devices, or voice messaging devices, or wireless access devices, etc.
Any CC/PP expression can use terms drawn from an arbitrary number of
different vocabularies, so there is no restriction caused by re-using terms
from an existing vocabulary rather then defining new names to identify the
same information.
As indicated above, CC/PP attribute names are in the form of a URI. Any
CC/PP vocabulary is associated with an XML namespace, which combines a base
URI with a local XML element name (or XML attribute name) to yield a URI
corresponding to an element name. Thus, CC/PP vocabulary terms are constructed
from an XML namespace base URI and a local attribute name; e.g. the namespace
URI:
http://w3c.org/ccpp-core-vocabulary/
and the core vocabulary name:
type
are combined to yield the attribute name URI:
http://w3c.org/ccpp-core-vocabulary/type
Anyone can define and publish a CC/PP vocabulary extension (assuming
administrative control or allocation of a URI for an XML namespace). For such
a vocabulary to be useful, it must be interpreted in the same way by
communicating entities. Thus, use of an existing extension vocabulary is
encouraged wherever possible, or publication of a new vocabulary definition
containing detailed descriptions of the various CC/PP attribute names.
Many extension vocabularies will be drawn from existing applications and
protocols; e.g. WAP UAPROF, IETF media feature registrations, etc.
6.4 Document profiles and service profiles
CC/PP expresses the user agent capabilities and how the user wants to use
them.
XHTML document profiles[XHTML-docprof]
express the required functionalities for what the author perceives as optimal
rendering, and how the author wants them to be used.
The same mechanisms can be used to describe the document profile as the
device capabilities profile, i.e. the framework described in section 6.2
combined with an extension vocabulary as described in 6.3.1 expressing the
specific functionalities. This can, for instance, reflect the XHTML modules
used, copyright issues, etc.
6.5 Matching of profiles in different formats
It is quite conceivable that when a device profile is expressed in CC/PP,
it will have to be matched with a document profile expressed in a different
format to achieve the adaption of content described above. This means that
either of the profiles has to be translated to either the format of the other,
or both to a common format.
In the scope of this activity, we will not discuss the translation of CC/PP
profiles to other formats. We will regard the CC/PP format as the common
format, to which other profile formats have been mapped (other groups are of
course welcome to create converse mappings; we are trying to work out how this
would work in the scope of our activity).
The interactions would work as follows:
- Request (extended method) with profile information.
- Profile translation (note: The following refers to functional elements.
The entire process could conceivably take place in the origin server).
- Schema for document profile is retrieved (from a repository or other
entity).
- Server resolves mappings and creates an intermediary CC/PP schema
for the matching.
- Document profile is matched against device profile to derive optimum
representation.
- Document is adapted.
- Response to client with adapted content. Depending on the format of the
document profile, the translation can be done in different ways.
- In the case of a dedicated XML-based format, mapping the XML Schema for
the dedicated format to the schema for RDF will allow the profile to be
expressed as RDF by the translating entity. In the case of a non-XML-based
format, a one-to-one mapping will have to be provided for the
translation.
This group will also describe how to map a different format to the CC/PP
format, using the Conneg vocabulary as an example.
[CC/PP] Composite Capability/Preference
Profiles (CC/PP): A user side framework for content negotiation
[CCPPex] CC/PP exchange protocol based on
HTTP Extension Framework
[FAX-conneg] Content
Negotiation for Facsimile Using Internet Mail
[HTTPex] HTTP
Extension Framework
[HTTP/1.1] HTTP/1.1,
Rev6
[Dsig] XML-Signature
Syntax and Processing
[P3P] Platform for
Privacy Preferences P3P Project
[P3P-Syntax] Platform for Privacy Preferences (P3P1.0)
Syntax Specification
[RDF] Resource Description Framework,
(RDF) Model and Syntax Specification
[RDF-Schema] Resource Description Framework
(RDF) Schema Specification
[RFC2543] RFC 2543 : Media Features for
Display, Print, and Fax
[RFC2506] RFC 2506 : Media Feature Tag
Registration Procedure
[RFC2533] RFC 2533 : A Syntax for
Describing Media Feature Sets
[RFC2703] RFC 2703 : Protocol-independent
content negotiation framework
[RFC2738] RFC 2738 : Corrections to 'A
syntax for describing media feature sets'
[RFC2246] RFC2246 : The TLS Protocol
Version 1.0
[RFC2119] RFC 2119 : Key words for use in
RFCs to Indicate Requirement Levels
[RFC2045] RFC 2045 : Multipurpose Internet
Mail Extensions(MIME) Part One: Format of Internet Message Bodies
[RFC2396] RFC 2396 : Uniform Resource
Identifiers (URI): Generic Syntax
[UAProf] User
Agent Profiling Specification 10-Nov-1999
[WSP] WAP
Wireless Session Protocol Specification
[WTP] WAP
Wireless Transaction Protocol Specification
[WML] WAP
Wireless Markup Language Specification
[WTLS] WAP
Wireless Transport Layer Security Specification
[WBXML] WAP
Binary XML Content Format Specification
[XHTML-docprof] XHTML Document Profile
Requirements - Document profiles - a basis for interoperability
guarantees
[XML] Extensible Markup Language
(XML) 1.0
[XML-name] Namespaces in XML
[XSLT] XSL
Transformations
This document has been edited by the editors, but the real credit goes to
the CC/PP working group, especially those members who provided input to this
document, listed below:
Anne Owen, Nortel
Barry Briggs, Interleaf
Chris Woodrow, Information Architects
Franklin Reynolds, Nokia
Graham Klyne, Content Technologies Ltd.
Hidetaka Ohto, W3C/Panasonic
Johan Hjelm, W3C/Ericsson. Working Group Chair.
Kynn Bartlett, HTML Writers Guild
Lalitha Suryanarayana, SBC Technology Resources
Mikael Nilsson, Ericsson. Editor.
Noboru IWAYAMA, Fujitsu
Sandeep Singhal, IBM. Chair WAP Forum UAProf DC.
Ted Hardie, Equinix
Ted Wugofski, Gateway2000
Ulrich Kauschke, T-Mobil
Appendix 1: Listing of detailed design
assumptions, design goals, and requirements
This is a listing of design assumptions, design goals, and requirements
used in our work to derive the requirements in section 4 of the document.
1. Listing of design assumptions
- CCPP3: P3P is fundamentally limited because it is server-based. This
limits the namespaces to those the server proposes.
- CCPP-IMPL 1: Follow RDF
- CCPP-IMPL 2: Valid XML (or only well formed?)
- UAPR 6-12: The UAPROF framework shall support internationalization as
required.
- XHTML-docprof 3.2.16 The design shall support referencing resources
indirectly. This is also intended in our work; it is also inherent in
RDF.
- UAPR 6-8: The UAPROF framework shall support an indirect addressing
scheme based on RFC 1630 for referencing profile information.
- F2F-3: Web-based (URL-based) mechanism for the framework
- F2F-9: Overrides of defaults
- CCPP1: Base: The CC/PP framework, as described in the Note.
- F2F-1: XML-based, RDF-based.
- XHTML-docprof 3.2.3 The design shall support machine readable profiles.
Suggestion: We make it stronger: The design shall support machine
understandable profiles. This is a likely requirement for the future.
- XHTML-docprof 3.2.7 The design shall support a human readable
description of the profile. Well, if RDF can be said to be human
readable.
- XHTML-docprof 3.2.9 The design shall use XML or RDF. Well, we do.
- XHTML-docprof 3.2.6 The design shall support multiple XML name spaces.
We do this using RDF, as in the original CC/PP Note[CC/PP].
- F2F-2: Multiple namespaces must be supported, logical operators would be
a single set only by revving the protocol.
- F2FA-1: An assumption during the work has been that the base is the
CC/PP framework, as described in the CC/PP Note [CC/PP]. This implies the use of RDF and XML.
- F2FA-2: Receiver-initiated transfer and sender-initiated transfers are
two protocol families. We need to be able to handle both. It must be
possible to send profile differences over the same protocol that conveys
the profile. We assume HTTP but we must make sure not to be bound to
it.
- F2FA-3: P3P is fundamentally limited because it is server-based. This
limits the namespaces to those the server proposes.
- F2FA-4: We are not specifying any specific behaviors internal to
clients, intermediary network elements, or proxies.
- UAPA 4-1: Implicit in the requirements and the architecture is an
assumption of the existence of a WAP gateway function in the network.
- UAPA 4-2: Synergy of goals and requirements with the CC/PP
proposal.
- UAPA 4-3: any statement on the security aspects of UAPROF information as
it is cached in the gateway? (note: UAPA 4-1 and 4-3 are more or less WAP
specific)
- CONNEG 5.1: The data is transmitted in one transaction (e.g. a mail or
an HTTP transaction). Metadata and the content negotiation framework may
be applicable to streaming media, even though it may be too much for the
framework.
- CONNEG 5.7: Performance may sometimes impact content negotiation.
- CONNEG 6.4: In cases where secure services are used, it should be
possible to continue to use them.
2 Listing of requirements and design assumptions with bearing on security
concerns
- CONNEG 6.5.1 User agent identification: Disclosure of capability
information may allow a potential attacker to deduce what message handling
agent is used, and hence may lead to the exploitation of known security
weaknesses in that agent. Implicit requirement: this should be
avoided.
- CONNEG 6.5.2 Macro viruses: Macro viruses are a widespread problem among
applications such as word processors and spreadsheets. Knowing which
applications a recipient employs (e.g. by file format) may assist in a
malicious attack. However, such viruses can be spread easily without such
knowledge by sending multiple messages, where each message infects a
specific application version. Implicit requirement: The trust model must
take this into account.
- CONNEG 6.5.3 Personal vulnerability: One application of content
negotiation is to enable the delivery of message content that meets
specific requirements of less able people. Disclosure of this information
may make such people potential targets for attacks that play on their
personal vulnerabilities. Implicit requirement: Their privacy must be
safeguarded.
- CONNEG 6.6 Problems of negotiating security: If feature negotiation is
used to decide upon security-related features to be used, some special
problems may be created if the negotiation procedure can be subverted to
prevent the selection of effective security procedures. Implicit
requirement: This needs to be addressed. (The security considerations
section of GSS-API negotiation discusses the use of integrity protecting
mechanisms with security negotiation).
- CONNEG 6: The following security threats have been identified: Privacy
violations and denial of service attacks. Negotiation with a mailing list
server has also been identified as not consistent with good practice. Out
of scope? Or do W3C recommendations carry the equivalent of a "security
considerations" section required for IETF specifications?
- CONNEG 4.2.4 A request for capability information, if sent other than in
response to delivery of a message, should clearly identify the requester,
the party whose capabilities are being requested, and the time of the
request. It should include sufficient information to allow the request to
be authenticated. (Or is this a protocol requirement?)
- OHTO-6.1: The protocol SHOULD support the method of authenticating the
originator(s) of CC/PP description(s).
- OHTO-6.2: The protocol SHOULD support the method of assuring the
integrity of CC/PP description.
3. Requirements used in the derivation of high-level requirements
3.1 Requirements used for the framework requirements
- FW-1
- UAPG 5-1: The User Agent Profile (UAPROF) framework shall ultimately
enable delivery of content in a format tailored to the specific device
characteristics, application settings, operating environment and user
preferences, while enhancing the speed of content negotiation between
the client and origin server.
- UAPG 5-2: For this purpose, the UAPROF data model shall adequately
represent the capabilities of the WAP client device, operating
environment, user agent settings as well as the user's
preferences.
- FW-2
- XHTML-docprof 3.2.1 The design shall support lightweight testing of
two profiles for equality. Do we have a way that is generic to RDF of
doing this? Or is that something we need to introduce?
- CONNEG 4.2.3b Should this be a goal: should it be clear from an
isolated CCPP profile what entity to which is is applicable?
- XHTML-docprof 3.2.2 The design shall support lightweight testing of
a clients capabilities and preferences against a documents profile.
Yes, that is our intention. And the easiest way of doing this is using
the same mechanisms.
- CCPP-IMPL4: Extensibility for matching rules by creating a specific
set of operand tags
- FW-3
- XHTML-docprof 3.2.14 The design shall support in-place linked
assertions. This is something we need to look into; if it assumes that
a subgraph can be expressed in terms of the node that points to it, we
can do it.
- UAPR 6-5: The UAPROF framework shall support the ability to
reference capability information stored separately on various systems
and databases on the Internet and wireless network.
- UAPR 6-5-1: The UAPROF shall be extensible to dynamically compose
capability information located at several sites in the network.
- CONNEG 4.2.1 A CCPP profile should allow a sender to determine an
acceptable form of data to send to a client.
- UAPG 5-3: The framework for UAPROF shall provide the ability to
transmit the information across the wireless network (from the device
to the WAP gateway) in a flexible, yet efficient and optimum manner
that minimizes round-trip-delays and network resources consumption in
terms of bandwidth and number of messages exchanged.
- UAPG 5-3-1: The UAPROF information shall be optimized with the above
objectives in mind.
- UAPG 5-4: The UAPROF may be changed during the life span of a user's
interaction with the wireless network and the Internet
- UAPR 6-5-2: UAPROF shall support unification of information provided
by the device with information located at other sites in the
network.
- FW-4
- CONNEG 4.2.7 Profiles should provide a way to describe both
capabilities and preferences for specific features
- CONNEG 4.1.4 Permit an indication of quality or preference. (see
CONNEG 4.2.7 above)
3.2 Requirements used to derive the vocabulary and schema
requirements
- VS-1
- XHTML-docprof 3.2.4 The design shall specify document syntax by
reference to external definitions. The intention of this requirement
is to say that schemas should be used for definitions (it says in the
comments), which is something we always intended, too.
- XHTML-docprof 3.2.8 The design shall support reference to
specifications and documentation defining a document type for the
profiled documents. It seems more like 3.2.4 than 3.2.7, as the HTML
WG says. Could it not be covered by those? If so, it is a basic
assumption of our architecture.
- UAPR 6-14: The UAPROF data model shall adequately represent the
characteristics specific to a bearer service (such as required for
ETSI/MExE).
- VS-2
- CONNEG 4.1.5 Capture dependencies between feature values. This is
about constraints: do we want a common way to do this. I think it's
useful.
- CCPP-IMPL6: Expression of hints as well as absolutes
- F2F-7: Constraints
- F2F-8: Requirements, hints, or both
- VS-3
- CONNEG 4.1.1 A common vocabulary for designating features and
feature sets. This would be a naming framework for client
features.
- UAPG 5-5: (Design goal or desirable feature?) UAPROF shall include
vocabularies that are semantically compatible with established
practices, so as to enable speedy adoption and ease of use for
developers.
- CONNEG 4.1.2 A stable reference for commonly used features. This
would be the "core nouns" we discussed.
- UAPR 6-4: An initial set of capabilities that comprise the UAPROF
shall be defined. Additionally, the UAPROF data model shall be
extensible to allow for rapid and easy adoption of new features and
capabilities of the device.
- VS-4
- XHTML-docprof 3.2.10 The design shall support a uniform way in which
to extend profiles.
- CONNEG 4.1.3 An extensible framework, to allow rapid and easy
adoption of new features. This would be mechanisms for extension.
- CCPP-IMPL5: Extend feature tags by using namespaces
3.3 Requirements used in deriving requirements for the trust model
- TF-1
- CONNEG 4.2.9 CCPP should indicate mechanisms to be used to protect
the privacy of users' profiles.
- TF-2
- CONNEG 4.2.10 CCPP should indicate mechanisms to be used to protect
the accuracy/integrity of users' profiles.
- UAPA 4-3: any statement on the security aspects of UAPROF
information as it is cached in the gateway?
- CCPP-IMPL3: Trust relationship w/repositories, origin servers, over
the wire. Encryption?
- F2F-9: Use IOTP (DSIG) for signing documents
- TF-3
- F2F2-1: The client must be able to determine whether the profile was
authenticated by the server (viz, the server needs to be indicate that
it authenticated the profile).
- F2F2-2: The client must be able to determine that it needs to
provide authentication information (viz, the server must be able to
indicate that it requires authentication information with the
profile)
- F2F2-3: If the client includes authentication information in the
profile, then the server SHOULD authenticate it and MUST indicate
whether it did.
- F2F2-4: Maybe the server should similarly indicate whether it used
the profile supplied, and if not, why not (thus potentially providing
an indication of authenticated-profile-required)? A server-signed
response might even usefully include a digest of the profile
used?
3.4 Requirements used in deriving the design goals
- VS-1: Vocabulary items shall be defined in an RDF schema (with the
implications of XML and RDF implicit in that). They can be externally
referenced.
- TF3: The digital signature shall be considered a part of the CC/PP.
- FW-2: The design shall support lightweight testing of two profiles for
equality.
- CONNEG 4.1.9 Be capable of addressing the role of content negotiation in
fulfilling the communication needs of less able computer users. WAI
coordination should take care of this.
- CONNEG 5.3: It is clearly helpful to use existing protocols such as LDAP
to exchange content negotiation metadata. (See CONNEG 4.2.5 in appendix
2)
- F2FG-3: It shall be possible to extend feature tags by using
namespaces.
- F2FG-4-1: It shall be possible to express "hints" in the content of to
present it to the user, based on the CC/PP profile.
- F2FG-4-2: It shall be possible to describe whether it is mandatory or
optional to enforce an attribute.
- UAPG 5-1: The content negotiation between the client and origin server
shall take place with a minimum consumption of network resources and
computational capacity.
- UAPG 5-3-1: The UAPROF information shall be optimized with the above
objectives in mind.
- UAPG 5-3-2: OTA transmission mechanism shall be optimized as mentioned
above.
- CONNEG 4.1.5 Capture dependencies between feature values.
- CONNEG 5.2: To allow proxies and caches to participate in the
negotiation process, as appropriate.
- UAPG 5-5: UAPROF shall include vocabularies that are semantically
compatible with established practices, so as to enable speedy adoption and
ease of use for developers.
(Note: The CONNEG goals are in an unordered list in the original
document)
This section describes the requirements the CC/PP working group have been
able to identify that applies to the protocol used to transport the
information and/or perform the negotiation between the client and origin
server. Since the CC/PP framework itself is intended to be independent from
protocols, the protocol which conveys CC/PP information could be based on or
extend a protocol of any kind such as HTTP, SMTP, LDAP etc.
The CC/PP information can be transported in in other messaging formats, for
instance included in an email, sent on a backchannel, or out of band (either
the head or the body) for describing the required capabilities of the
recipient. How to convey content negotiation information in the extended MIME
headers is being worked on the Internet FAX Working Group in the IETF [FAX-conneg].
The use case that is most likely (given that 80% of all Internet traffic is
HTTP), is the use case where a web user agent sends a request with CC/PP
information, and an origin server or intermediaries creates or selects
tailored content, and includes the tailored content in the response. The use
of HTTP has been a design assumption in the work.
Given this, the protocol requirements are as follows.
- P-1: The design shall support inclusion of profile information in a
request to a server (in request-response protocols); and in the message
(in message-sending protocols).
- XHTML-docprof 3.2.13 The design shall support including document
profile information in a request to a server. This is protocol work
and outside our scope; however, the CC/PP Exchange Protocol
demonstrates how this could be done using the HTTP Extension
Framework.
- CONNEG 4.2.2 If capabilities are being sent at times other than the
time of message transmission, then they should include sufficient
information to allow them to be verified and authenticated.
- CONNEG 4.2.5 A CCPP profile may be transferred by a number of
different mechanisms appropriate to the circumstances of its use (or
does this belong under framework?).
- UAPR 6-2: The format and communication mechanism of the UAPROF
information shall support and be compatible with existing and emerging
Internet standards for the desktop environment.
- CONNEG 4.2.6 The negotiation mechanism should include a standardized
method for associating features with resource variants. Out of scope?
This reflects in part my (here: GK) view that the same profile
framework can describe document and client profiles. This conneg usage
requirement about having a means to identify the features of a
particular type of data resource.
- OHTO-8.1:The protocol MUST convey CC/PP descriptions originating
from multiple sources.
- CC/PP descriptions which describes device capabilities would
originate from multiple sources such as hardware vendors, software
vendors etc.
- CC/PP descriptions which represent capabilities for one device
would be provided by multiple sources such as hardware vendors and
software vendors. Therefore the protocol SHOULD support the
ability to reference capability information stored separately on
various systems and databases in the network.
- OHTO-8.2: The protocol SHOULD support partial distribution of
profile information be able to indicate what information is missing so
that the client can decide what to do.
- UAPG 5-3: The framework for UAPROF shall provide the ability to
transmit the information across the wireless network (from the device
to the WAP gateway) in a flexible, yet efficient and optimum manner
that minimizes round-trip-delays and network resources consumption in
terms of bandwidth and number of messages exchanged.
- P-2: Matching of profiles and/or content negotiation shall have as
little impact as possible in terms of network resources, especially
protocol round trips.
- CONNEG 4.2.8 Negotiation should have the minimum possible impact on
network resource consumption, particularly in terms of bandwidth and
number of protocol round trips required. Out of scope?
- F2F-6: Minimum number of roundtrips for profile matching (none is
best)
- OTHO-5.1: The protocol SHOULD support the way of minimizing the
amount of CC/PP information conveyed with a request.
- OHTO-5.2: CC/PP descriptions would be verbose. Therefore conveying
CC/PP descriptions with a request would be a moderately expensive way
in some networks such as wireless networks.
- OHTO-5.3: There are several optimization possibilities(those might
not be mutual exclusive) such as :
- compress CC/PP description(s) when it is conveyed.
- send reference(s)(URI) which represents CC/PP descriptions
instead of sending CC/PP descriptions themselves.
- send only the changes when propagating changes to the current
CC/PP description(s) to an origin server, a gateway or a
proxy.
- P-3: The protocol must work in the presence of gateways or proxies,
including enabling intermediate network elements to interact with the
profile and content.
- F2F-5: Must work in the presence of gateways and proxies. Web is
receiver initiated.
- CONNEG 4.2.12 Intelligent gateways, proxies, or caches should be
allowed to participate in the negotiation.
- CONNEG 4.2.13 CCPP data should be regarded as cacheable. It may be
desirable to indicate cache control directives to forestall the
introduction of ad-hoc cache-busting techniques
- CONNEG 5.2: To allow proxies and caches to participate in the
negotiation process, as appropriate.
- OHTO-4.1: The protocol SHOULD allow intermediaries to participate in
the content negotiation.
- OHTO-4.2: It is quite conceivable that intermediate network elements
such as gateways or proxies take participate in the content
negotiation(content generation, content transformation and content
variant selection). For example, a transcoding proxy transcodes a
content received based on its abilities, and forwards the resulting
customized content to the device for rendering. Such kind of gateways,
proxies, or caches should be allowed to participate in the content
negotiation.
- OHTO-4.3: The protocol SHOULD support asserting capabilities by
intermediate network elements. When a request for a content is made by
a user agent to an origin server, a CC/PP profile describing the
capabilities and preferences is transmitted along with the request. It
is quite conceivable that intermediaries such as gateways and
transcoding proxies that have additional capabilities might be able to
translate or adapt the content before rendering it to the device. Such
capabilities are not known to the user agents and therefore cannot be
included in the original profile. However, these capabilities would
need to be conveyed to the origin server or proxy serving/ generating
the content. Therefore the protocol MUST support the ability for such
proxies and gateways to assert their capabilities.
- OHTO-4.4: The protocol SHOULD support overriding capabilities by
intermediate network elements.
- OHTO-4.5: In some instances, the profile information provided by the
requesting client device may need to be overridden.
- OHTO-4.6: The protocol SHOULD maintain the original CC/PP profiles
intact up to the point where content selection/generation is performed
(by origin or proxy). Any overrides are described by a combining form,
somewhat like the 'default' combining form, that forces values in the
original profile to be disregarded. This approach maintains end-to-end
security for the client's profile.
- P-4: The profile shall work independently of the protocol type. However,
any protocols which enable extended content negotiation using CC/PP shall
support the ability dynamically modify and update any changes to the
profile information during the scope of a session or transaction.
- CCPP2: Receiver-initiated transfer and sender-initiated transfers
are two protocol families. We need to be able to handle both. Send
diffs over protocol. We assume HTTP but we must make sure not to be
bound to it. It's pretty obvious what we have to steal.
- CONNEG 4.1.7 Efficient negotiation should be possible in both
receiver initiated ('pull') and sender initiated ('push') message
transfers. I.e. allow for fax/email/etc as well as web access.
- CONNEG 4.1.8 The structure of the negotiation procedure framework
should stand independently of any particular message transfer
protocol. (See CONNEG 4.2.5 above).
- UAPR 6-7: The UAPROF framework shall support the ability to
dynamically modify and update any changes to the UAPROF capabilities/
preferences during the scope of a single request or during the
life-span a WSP session.
- UAPR 6-13: It shall be possible for a WAP client to embed in the
request, UAPROF information (granularity = attribute) which can be
used instead of the cached information available at the WAP gateway
(i.e. overwrite the existing information temporarily). This
information embedded in the request shall not be cached at the
gateway.
- UAPG 5-3-2: OTA transmission mechanism shall be optimized as
mentioned above.
- F2F-4: Sender-initiated and receiver-initiated protocols
- CONNEG 4.2.3a A capability assertion should clearly identify the
party to whom the capabilities apply, the party to whom they are being
sent, and some indication of their date/time or range of validity. To
be secure, capability assertions should be protected against
interception and substitution of valid data by invalid data.
Assuming a protocol based on HTTP 1.1, the following applies:
- The protocol SHOULD be HTTP/1.1 compatible.
- For the purpose of taking advantage of the technologies such as cache
controls, and making use of the existing web server infrastructures, the
protocol should be HTTP/1.1 compatible.
- The protocol SHOULD support caching mechanisms for both of CC/PP
descriptions and tailored contents.
- Caching is very important for performance improvement. HTTP/1.1 cache
control mechanisms would be used for the purpose of it.