Copyright © 1998 W3C (MIT, INRIA, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply.
This is a W3C Working Draft for review by W3C members and other interested parties. It is a draft document and may be updated, replaced, or obsoleted by other documents at any time. The W3C will not allow early implementation to constrain its ability to make changes to this specification prior to final release. It is inappropriate to use W3C Working Drafts as reference material or to cite them as other than "work in progress". A list of current W3C Working Drafts can be found at http://www.w3.org/TR.
This W3C Working Draft is published by the Internationalization Working Group (members only). In a future version, this work is intended to be submitted to the HTML Working Group (members only) for inclusion in the next version of HTML.
Please send comments and questions regarding this document to i18n-editor@w3.org. Comments in languages other than English, in particular Japanese, are also welcome.
The HyperText Markup Language (HTML) is a simple markup language used to create hypertext documents that are portable from one platform to another. HTML documents are SGML documents with generic semantics that are appropriate for representing information from a wide range of applications. The following specification extends HTML to support ruby text typically used in East Asian documents. Familiarity with both HTML 4.0 [HTML4] and XML-ized HTML [HTML-XML] is assumed.
East Asian typography contains structural elements and types of formatting that are not yet exposed in HTML and thus impossible to achieve on the Web without using special workarounds or graphics. One of such elements is ruby text. The "ruby" is the commonly used name for a run of text that appears in the immediate vicinity of another run of text, referred to as the "base", and serves as an annotation or a pronunciation guide associated with that run of text. Ruby, as used in Japanese, is described in JIS-X-4051 [JIS].
Ruby text's font size is normally half the font size of the base. The name "ruby" in fact originated from the name of the 5.5pt font size in British printing, which is about half the 10pt font size commonly used for normal text.
There are several positions that the ruby text can appear at relative to its base. They can be divided into two main categories: ruby text can appear alongside the base, or it can appear as inline text immediately following the base. When ruby text appears alongside the base, then it almost always appears above the base in horizontal layout (although there are cases of ruby appearing below the base).
![]()
Figure 1.1.1: Top ruby in horizontal Japanese
In vertical ideographic layout, "alongside" ruby appears on the right side of the vertical column of text, and its own layout flow is the same as that of its base, i.e. vertical ideographic.
![]()
Figure 1.1.2: Top ruby applied to vertical ideographic Japanese
When the ruby text appears inline, it may be enclosed within parentheses. Note however that the parentheses are used only for inline ruby. There are no parentheses around ruby text that runs alongside the base.
![]()
Figure 1.1.3: Inline ruby applied to horizontal Japanese
This document introduces a ruby model in HTML using the new ruby element containing the rb, rt and rp elements. Only the structure of the ruby is discussed in this document. For example, the following ruby
![]()
Figure 1.1.4: Top ruby applied to horizontal English
can be represented by the following markup in SGML HTML:
<ruby>WWW<rp>(<rt>World Wide Web<rp>)</ruby>
while the XML-ized HTML [HTML-XML] version of it would be:
<ruby><rb>WWW</rb><rp>(</rp><rt>World Wide Web</rt><rp>)</rp></ruby>
This document only defines ruby markup. Formatting properties for styling ruby will be defined not for HTML/XML, but for CSS/XSL.
This proposal does not include markup to allow to intelligently distribute the base text and the ruby text over two lines when the whole construct would need to be hyphenated. There are very few systems that actually do such processing and the additional markup would be quite complicated. Authors are advised to limit the length of the base text where possible.
This section contains the ruby DTD and the specification of the functionality of the ruby elements. Two DTD versions are given for each tag. The first one is in SGML [HTML4]. The second one is in XML-ized HTML [HTML-XML]. Note that in the SGML DTD, elements and attributes are intended to be case-insensitive, however, in the XML DTD, elements and attributes are case-sensitive. And also, start and end tags are always required in XML.
For convenience, the following parameter entities are used:
<!-- %Inline; covers inline or "text-level" elements --> <!ENTITY % Inline "(#PCDATA | %inline; | %misc; | ruby)*"> <!-- %ruby.content; is %Inline; without ruby --> <!ENTITY % ruby.content "(#PCDATA | %inline; | %misc;)*"> <!ENTITY % attrs "%coreattrs; %i18n; %events; %extra-attrs;">
Further definitions can be found in [HTML-XML].
<!-- SGML DTD: container for ruby elements --> <!ELEMENT ruby - - (rb, rp?, rt, rp?)> <!ATTLIST ruby %attrs; >
Start tag: required, End tag: required
<!-- XML DTD: container for ruby elements --> <!ELEMENT ruby (rb, rp?, rt, rp?)> <!ATTLIST ruby %attrs; >
The ruby element serves as the container for the rb, rp and rt elements only. It provides the structural association between the ruby base and its ruby text.
The ruby element does not accept any attributes other than the standard ones, such as id, class or style.
In this simplest example, ruby "aaa" is associated with base "AA":
<ruby>AA<rt>aaa</ruby>
Figure 2.1.1: SGML usage of the ruby element
In XML-ized HTML, the above example would be:
<ruby><rb>AA</rb><rt>aaa</rt></ruby>
Figure 2.1.2: XML usage of the ruby element
<!-- SGML DTD: container for ruby base --> <!ELEMENT rb O O %ruby.content; > <!ATTLIST rb %attrs; >
Start tag: optional, End tag: optional
In SGML, neither the opening nor the closing tags are required, which means that any text in the ruby element that is not enclosed within an rt or an rp element belongs to the rb element. The rb element is automatically closed by an rt or an rp element.
<!-- XML DTD: container for ruby base --> <!ELEMENT rb %ruby.content; > <!ATTLIST rb %attrs; >
The rb element is the container for the text of the ruby base. Any content, other than another ruby element, is valid inside of rb.
<!-- SGML DTD: container for ruby text --> <!ELEMENT rt - O %ruby.content; > <!ATTLIST rt %attrs; >
Start tag: required, End tag: optional
In SGML, only the opening tag is required. The rt element is automatically closed by an opening rp tag or a closing ruby tag.
<!-- XML DTD: container for ruby text --> <!ELEMENT rt %ruby.content; > <!ATTLIST rt %attrs; >
The rt element is the container for the ruby text. The rt element does not allow other nested ruby elements inside of it.
<!-- SGML DTD: container for parenthesis characters --> <!-- ELEMENT rp - O %ruby.content; --> <!ELEMENT rp - O (#PCDATA)> <!ATTLIST rp %attrs; >
Start tag: required, End tag: optional
In SGML, the rp element is automatically closed by an opening rt tag or a closing ruby tag.
<!-- XML DTD: container for parenthesis characters --> <!-- ELEMENT rp %ruby.content; --> <!ELEMENT rp (#PCDATA)> <!ATTLIST rp %attrs; >
This element is intended to contain parenthesis characters. Parentheses are necessary for the ruby to be rendered correctly when it is inline. When rendering a non-inline (i.e. an alongside) ruby, the UA must ignore the contents of the rp elements completely, as if there were a "display: none" setting in the rp CSS definition [CSS2]. The existence of the rp element however is necessary for UA's that are unable to render ruby. That way, any ruby will degrade to no worse than a properly formed inline ruby in non-supporting UA's.
Consider the following markup, specifying a top (default) ruby:
<ruby><rb>A</rb><rp>(</rp><rt>aaa</rt><rp>)</rp></ruby>
Figure 2.4.1: Ruby markup using rp elements
A user agent that supports top ruby would render it as:
aaa A
Figure 2.4.2: Top ruby rendered by a supporting UA (note the parentheses are not visible)
However, a UA that is unable to render top ruby or does not support ruby HTML, would still correctly show:
A(aaa)
Figure 2.4.3: Top ruby rendered by a non-supporting UA (note the parentheses are visible)
In a UA that supports ruby, the ruby structure consists of three boxes. The outermost container is the ruby element itself. It is a container for two non-overlapping boxes: the ruby text box and the ruby base box.
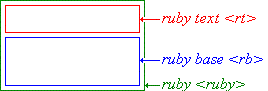
Figure 3.1.1: Ruby box model
The width of the ruby element is by default determined by its widest child element, whose width in turn is determined by its content. Both of ruby's children assume the width of the widest one of them. In this respect, the ruby element is much like a two-cell table element, with the following exceptions:
If the ruby text is not allowed to overhang anything, then the ruby behaves like a traditional box, i.e. only its contents are rendered within its boundaries and adjacent elements do not cross the box boundary:
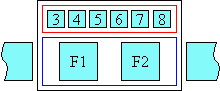
Figure 3.1.2: Ruby whose text is not allowed to overhang adjacent text
However, if ruby text is allowed to overhang adjacent elements and it happens to be wider than its base, then the adjacent content is partially rendered within the area of the rb box, while the rt may be partially overlapping with the upper blank parts of the adjacent content:
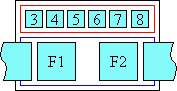
Figure 3.1.3: Ruby whose text is allowed to overhang adjacent text
Ruby text from one base can never overhang another ruby base.
The alignment of the contents of the base or the ruby text is not affected by the overhanging behavior. The alignment is achieved the same way regardless of the overhang behavior setting and it is computed before the space available for overlap is determined.
The exact circumstances in which the ruby text will overhang other elements, and to what degree it will do so, will be controlled by ruby CSS properties.
This entire logic applies the same way in vertical ideographic layout, only the dimension in which it works in such a layout is vertical, instead of horizontal.
The model presented in this specification is largely inspired by the work done by Martin Dürst [DUR97].
This specification would also not have been possible without the help from:
Laurie Anna Edlund, Arye Gittelman, Koji Ishii, Eric LeVine, Chris Lilley, Chris Pratley, Rahul Sonnad, Michel Suignard, Takao Suzuki, Chris Thrasher.