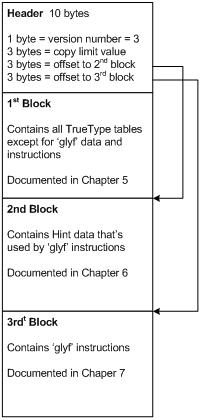
5. Compressed Data Set 1 - Font Tables
The 1st Block of the CTF format contains the ‘glyf’ table outline data and all of the font tables from the TrueType font, except for the ‘loca’ table which is removed. The CTF data compressed in 1st Block retains the entire format of the original TTF file, with the exception that the ‘cvt’, ‘hdmx’, ‘VDMX’, and ‘glyf’ tables contain the compressed data. All other tables from the TTF source file, including the Table Directory, are stored uncompressed in the CTF stream.
To decompress the CTF data in the 1st Block, one needs to parse the TTF file as is defined in the TTF specification, and decompress the data in the ‘cvt’, ‘hdmx’, ‘VDMX’ , and ‘glyf’ tables as described below.
5.1. 'loca' Table
The TrueType ‘loca’ table contains information regarding the specific location of each glyph in the ‘glyf’ table, and implicitly also the length of each glyph in the ‘glyf’ table. In the CTF format we only need to access the glyphs in sequence. The length of each glyph is already implicitly defined by the data for that glyph. The glyphs are stored in sequence in the ‘glyf’ table starting at offset zero. This means there is no need to store the ‘loca’ table in the CTF format. When we translate back to the TTF format, we simply recreate the ‘loca’ table from the available information. The elimination of the ‘loca’ table results in a more compact CTF format.
Note that there is a 'loca' table entry in the CTF file, but its offset and length are both set to zero.
5.2. CVT Table Translation
The table below shows the format of the cvt header in the CTF font.
cvt Header
| Type |
Name |
Description |
| USHORT |
numEntries |
Number of cvt entries. |
In the CTF format, the ‘cvt’ table consists of a USHORT value n, which is the number of cvt entries present, followed immediately by n encoded cvt values, encoded as explained below:
The contents of the ‘cvt’ table in a TrueType font consists of a sequence of signed 16 bit 2’s complement integers. In the CTF format we store the values relative to the previous value modulo 2 raised to 16. The first value is stored relative to zero. Sometimes numerically close values are stored next to each other in the ‘cvt’, and this technique will cause them to be stored as numerically small relative values instead. Then the relative values are stored with the following technique. We encode each value in 1 to 3 bytes, so that most values can be stored as one, or two bytes instead of 2. In this encoded format we treat each byte as an unsigned byte in the range 0..255 inclusive.
If the byte is in the range 248..255 inclusive, we call this byte b1, and then we read another byte b2. The value is in this case defined as equal to 238 * (b1-247) + b2. Thus we are able to encode values in the range 238..2159 inclusive in two bytes.
If the byte is in the range 239..247 inclusive, we call this byte b1, and then we read another byte b2. The value is in this case defined as equal to –(238 * (b1-239) + b2). Thus we are able to encode values in the range -0 to -2159 inclusive in two bytes.
If the byte is equal to 238, we read 2 more bytes and treat the value as a signed 2 byte quantity, based on the last two read bytes. The value is equal to this quantity. Thus we encode large values in 3 bytes. Otherwise if the byte is less than 238 we set the value equal to the byte without reading any more bytes. Thus, we encode 0..237 inclusive in one byte.
This technique results in a more compact CTF format, since the typical statistical distribution of the data values allows us to store a majority of the values as single or double bytes.
In the CVT table processing we define the following constants:
short value;
const unsigned char cvt_pos8 = 255;
const unsigned char cvt_pos1 = 255 - 7; /* == cvt_pos8 - 7 */
const unsigned char cvt_neg8 = 255 - 7 - 1; /* == cvt_pos1 - 1 */
const unsigned char cvt_neg1 = 255 - 7 - 1 - 7; /* == cvt_neg8 - 7 */
const unsigned char cvt_neg0 = 255 - 7 - 1 - 7 - 1; /* == cvt_neg1 - 1 */
const unsigned char cvt_wordCode = 255 - 7 - 1 - 7 - 1 - 1; /* == cvt_neg0 - 1 */
const short cvt_lowestCode = 255 - 7 - 1 - 7 - 1 – 1; /*==cvt_wordCode*/
We encrypt with the following code.
if ( value < 0 )
{
negative = true;
value = (short)-value;
}
index = (shortvalue / cvt_lowestCode);
if ( index <= 8 && valueIn != -32768)
{
/* write -32768 as a word below */
register unsigned char *p = *pRef;
if ( negative )
{
assert( cvt_neg0 + 8 == cvt_neg8 );
code = (unsigned char)(cvt_neg0 + index);
assert( code >=cvt_neg0 && code <= cvt_neg8 );
*p++ = code;
value = (short)(value - index * cvt_lowestCode);
assert( value >=0 && value < cvt_lowestCode );
*p++ = (unsigned char)value;
}
else
{
assert( cvt_pos1 + 7 == cvt_pos8 );
if ( index > 0 )
{
code = (unsigned char)(cvt_pos1 + index - 1);
assert( code >=cvt_pos1 && code <= cvt_pos8 );
*p++ = code;
value = (short)(value - index * cvt_lowestCode);
}
assert( value >=0 && value < cvt_lowestCode );
*p++ = (unsigned char)value;
}
*pRef = p;
}
else
{
*(*pRef)++ = cvt_wordCode; /* Do a word */
WRITEWORD_INC( ( char **)pRef, valueIn );
}
Similarly, we decrypt with the following code.
code = *((*p)++);
if ( code < (unsigned char)cvt_lowestCode )
{
value = code;
}
else
{
if ( code >=cvt_pos1 && code <= cvt_pos8 )
{
index = (short)(code - cvt_pos1 + 1);
assert( index >=1 && index <= 8 );
value = *(*p)++;
assert( value >=0 && value < cvt_lowestCode );
value = (short)(value + index * cvt_lowestCode);
}
else if ( code >=cvt_neg0 && code <= cvt_neg8 )
{
index = (short)(code - cvt_neg0);
assert( index >=0 && index <= 8 );
value = *(*p)++;
assert( value >=0 && value < cvt_lowestCode );
value = (short)(value + index * cvt_lowestCode);
value = (short)-value;
}
else
{
assert( code == cvt_wordCode );
value = READWORD_INC( ( char **)p );
}
}
5.3. Magnitude Dependent Encoding Used in 'hdmx' and 'VDMX' Tables
A magnitude dependent variable size encoding of a value is as follows:
- A value of 0 is encoded as a 0 bit sequence.
- A value of +1 is encoded as the 100 bit sequence.
- A value of -1 is encoded as the 101 bit sequence.
- A value of +2 is encoded as the 1100 bit sequence.
- A value of -2 is encoded as the 1101 bit sequence.
- A value of +3 is encoded as the 11100 bit sequence.
- A value of -3 is encoded as the 11101 bit sequence.
- Etc.
The absolute of the value is equal to the number of 1’s preceding the ‘0’. Then if the value is greater than zero, there is one additional sign bit, where ‘0’ represents ‘+’ and ‘1’ represents ‘-‘. This means that we have a variable bit length encoding of values, where the number of bits used grows with the magnitude of the value. This encoding can advantageously be used for storing very small values.
Note: the bit sequences shown above are stored in LSB to MSB order within each byte, i.e. the first bit of the sequence is stored in the least significant bit of the first encoded byte, the second bit of the sequence is stored in the next-to-least-significant bit of the first encoded byte, and so on – see decoding example below.
5.3.1. Magnitude Dependent Encoding Decoding Example
| Data |
0x90 |
0x48 |
0x84 |
... |
| Bits |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
... |
| LSB first |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
... |
| Value |
0 |
0 |
0 |
0 |
+1 |
+1 |
0 |
+1 |
+1 |
0 |
+1 |
0 |
0 |
0 |
... |
5.4. The 'hdmx' Table Translation
The ‘hdmx’ table in TrueType contains the device advance widths of the glyphs for a range of sizes. TrueType instructions can change the device advance width in a non-linear manner and therefore they are stored in the TrueType file so that the client of the TrueType rasterizer can quickly get access to the widths of characters without actually rendering them. When we translate to CTF format we predict what the device advance width is most likely to be.
The most likely value is the device independent advance width from the hmtx table linearly scaled to the particular device resolutions, and size, and then rounded to the closest integer. This Prediction is always very close to the truth. This enables us to treat the difference between the actual device advance width and the prediction as the Surprise. This method only stores the Surprise value which is typically equal to zero or very small with the “Magnitude dependent variable size encoding” mentioned in section 5.3. When we reconstruct the TTF file from the CTF data we simply make the prediction and then we add the surprise to the prediction to get the actual true value. This technique results in a more compact CTF format.
In the unlikely event that compression code is unable to compress the hdmx data, the original data is stored in uncompressed form and the version is set to (0xFFFF-real_version) otherwise the version is set to the real version.
The tables below show the format of the hdmx table in the TTF and CTF font.
hdmx Header
| Type |
Name |
Description |
| USHORT |
version |
Table version number:
real_version if data compressed in CTF font,
(0xFFFF-real_version) if data not compressed in CTF font. |
| USHORT |
numRecords |
Number of device records. |
| LONG |
sizeDeviceRecord |
Size of a device record, long aligned. |
| DeviceRecord |
records[numRecords] |
Array of device records. |
Device Record
| Type |
Name |
Description |
| BYTE |
pixelSize |
Pixel size for following widths (as ppem). |
| BYTE |
maxWidth |
Maximum width. |
| BYTE |
widths[numGlyphs] |
Array of widths (numGlyphs is from the 'maxp' table). |
Each DeviceRecord is padded with 0's to make it long word aligned. Each Width value is the width of the particular glyph, in pixels, at the pixels per em (ppem) size listed at the start of the DeviceRecord. The widths are encoded using the surprise method described above.
The ppem sizes are measured along the y axis.
In the CTF font, the values in the hdmx table can be compressed using the code:
for ( glyphIndex = 0; glyphIndex < (unsigned short)numEntries; glyphIndex++ )
{
rounded_TT_AW = ((((long)64 * (long)ppem * (long)awArray[ glyphIndex ])+(long)unitsPerEm/2) / (long)unitsPerEm);
rounded_TT_AW += 32;
rounded_TT_AW /= 64;
oldSize += 8;
if ( TTF_To_CTF )
{
long newSize;
short deltaAW = (short)(*GET_hdmxSubRecord_width_Ptr( devSubRecord, glyphIndex ) - rounded_TT_AW);
/* widths is uint8 */
newSize = ctfHeaderSize + (bitOffset+abs(deltaAW)+2+7)/8;
if ( newSize > lengthIn )
{
/* we have a problem, set version to 0xFFFF-real version and just copy data */
AllocateTTFSpace( t, destSfnt, pos, lengthIn, maxOutSize );
/* Update dependencies on destSfnt */
hdmxOut = &(*destSfnt)[pos];
ctf_devMetrics = hdmxOut;
memcpyHuge((char *)hdmxOut,(char *)hdmxIn,lengthIn);
*GET_ctf_hdmx_version_Ptr( ctf_devMetrics ) = (short)(0xFFFF - SWAPENDS_16(*GET_hdmx_version_Ptr( devMetrics )));
*GET_ctf_hdmx_version_Ptr( ctf_devMetrics ) = SWAPENDS_16(*GET_ctf_hdmx_version_Ptr( ctf_devMetrics ));
MTX_mem_free( t->mem,awArray);
return (lengthIn); /*****/
}
else
{
AllocateTTFSpace( t, destSfnt, pos, newSize, maxOutSize );
/* Update dependencies on destSfnt */
hdmxOut = &(*destSfnt)[pos];
ctf_devMetrics = hdmxOut;
WriteHdmxValue( deltaAW, (unsigned char __huge *)hdmxOut + ctfHeaderSize, &bitOffset );
}
}
}
In the CTF font, the values in the hdmx table can be decompressed using the following pseudo-coded algorithm:
version = CTF.hdmx.getNextUInt16()
numRecords = CTF.hdmx.getNextInt16()
recordSize = CTF.hdmx.getNextInt32()
ppemList = []
for recordNumber in 0 to (numRecords - 1)
{
ppem = CTF.hdmx.getNextUInt8()
maxWidth = CTF.hdmx.getNextUInt8()
ppemList.append(ppem)
}
numGlyphs = CTF.maxp.numGlyphs
unitsPerEm = CTF.head.unitsPerEm
widths = {}
for ppem in ppemList
{
widthList = []
for glyphID in 0 to (numGlyphs - 1)
{
predictedAdvanceWidth = ((ppem * CTF.hmtx[glyphID])/unitsPerEm)
surpriseAdvanceWidth = readMagnitudeEncodedValue(CTF.hdmx)
width = (predictedAdvanceWidth + surpriseAdvanceWidth)
widthList.append(width)
}
widths[ppem] = widthList
}
Where “TTF” indicates the decompressed TTF file that is being generated, CTF indicates the compressed 1st Block, HDMX and HMTX indicate TTF tables. Values are rounded up to the nearest integer.
Note that, due to rounding considerations, the actual predictedAdvanceWidth calculation may need to be something more like:
predictedAdvanceWidth = (((((64 * ppem * CTF.hmtx[glyphID]) + (unitsPerEm / 2)) / unitsPerEm) + 32) / 64)
Note also that there is a magnitude encoded value for every glyph in the font, so the glyph IDs are not encoded in the compressed data.
5.5. The 'VDMX' Table Translation
The ‘VDMX’ table contains the maximum font wide maximum and minimum y value for a range of sizes and aspect ratios. Similarly to the ‘hdmx’ table we predict the values and then we only encode the Surprise which is equal to the error prediction with the “Magnitude dependent variable size encoding” mentioned in 5.3. The following technique is used to predict the three values (ppem (size), ymax, ymin).
- The predicted ppem is simply the previous ppem + one.
- The predicted ymax is equal to size * yMaxMultiplier rounded to the closest pixel.
- The predicted ymin is equal to size * yMinMultiplier rounded to the closest pixel.
The yMaxMultiplier and yMinMultiplier are simply computed as the average of the exact multipliers for each instance during the TTF to CTF file translation. These two average values are then stored in the file, so that we can predict the actual ymax and ymin values with the previously mentioned formula.
The tables below show the format of the VDMX table in the TTF and CTF font. The difference in the CTF font being that the Surprise value is stored in the table, instead of the actual value.
In the unlikely event that compression code is unable to compress the VDMX data, the original data is stored in uncompressed form and the version is set to (0xFFFF-real_version) otherwise the version is set to the real version.
The VDMX table consists of a header followed by groupings of VDMX records:
VDMX Header
| Type |
Name |
Description |
| USHORT |
version |
Table version number:
real_version if data compressed in CTF font,
(0xFFFF-real_version) if data not compressed in CTF font. |
| USHORT |
numRecs |
Number of VDMX groups present |
| USHORT |
numRatios |
Number of aspect ratio groupings |
| Ratio |
ratRange[numRatios] |
Ratio ranges (see below for more info) |
| USHORT |
offset[numRatios] |
Offset from start of this table to the VDMX group for this ratio range. |
| Vdmx |
groups |
The actual VDMX groupings (documented below) |
Ratio Record
| Type |
Name |
Description |
| BYTE |
bCharSet |
Character set (see below). |
| BYTE |
xRatio |
Value to use for x-Ratio. |
| BYTE |
yStartRatio |
Starting y-Ratio value. |
| BYTE |
yEndRatio |
Ending y-Ratio value. |
Ratios are set up as follows:
| For a 1:1 aspect ratio |
Ratios.xRatio = 1;
Ratios.yStartRatio = 1;
Ratios.yEndRatio = 1; |
| For 1:1 through 2:1 ratio |
Ratios.xRatio = 2;
Ratios.yStartRatio = 1;
Ratios.yEndRatio = 2; |
| For 1.33:1 ratio |
Ratios.xRatio = 4;
Ratios.yStartRatio = 3;
Ratios.yEndRatio = 3; |
| For all aspect ratios |
Ratio.xRatio = 0;
Ratio.yStartRatio = 0;
Ratio.yEndRatio = 0; |
All values set to zero signals the default grouping to use; if present, this must be the last Ratio group in the table. Ratios of 2:2 are the same as 1:1.
Aspect ratios are matched against the target device by normalizing the entire ratio range record based on the current X resolution and performing a range check of Y resolutions for each record after normalization. Once a match is found, the search stops. If the 0,0,0 group is encountered during the search, it is used (therefore if this group is not at the end of the ratio groupings, no group that follows it will be used). If there is not a match and there is no 0,0,0 record, then there is no VDMX data for that aspect ratio.
Note that range checks are conceptually performed as follows:
(deviceXRatio == Ratio.xRatio) && (deviceYRatio >=Ratio.yStartRatio) && (deviceYRatio <= Ratio.yEndRatio)
Each ratio grouping refers to a specific VDMX record group; there must be at least 1 VDMX group in the table.
The bCharSet value is used to denote cases where the VDMX group was computed based on a subset of the glyphs present in the font file. The semantics of bCharSet is different based on the version of the VDMX table. It is recommended that VDMX version 1 be used. The currently defined values for character set are:
Character Set Values - Version 0
| Value |
Description |
| 0 |
No subset; the VDMX group applies to all glyphs in the font. This is used for symbol or dingbat fonts. |
| 1 |
Windows ANSI subset; the VDMX group was computed using only the glyphs required to complete the Windows ANSI character set. Windows will ignore any VDMX entries that are not for the ANSI subset (i.e. ANSI_CHARSET) |
Character Set Values - Version 1
| Value |
Description |
| 0 |
No subset; the VDMX group applies to all glyphs in the font. If adding new character sets to existing font, add this flag and the groups necessary to support it. This should only be used in conjunction with ANSI_CHARSET. |
| 1 |
No subset; the VDMX group applies to all glyphs in the font. Used when creating a new font for Windows. No need to support SYMBOL_CHARSET. |
VDMX groups immediately follow the table header. Each set of records (there need only be one set) has the following layout:
VDMX Group
| Type |
Name |
Description |
| USHORT |
recs |
Number of height records in this group |
| SHORT |
yMaxMultiplier |
used to predict actual ymax values
[Note: this would be a BYTE:startsz in a TTF font] |
| SHORT |
yMinMultiplier |
used to predict actual ymax values
[Note: this would be BYTE:endsz in a TTF font] |
| vTable |
entry[recs] |
The VDMX records |
vTable Record
| Type |
Name |
Description |
| USHORT |
yPelHeight |
yPelHeight to which values apply. |
| SHORT |
yMax |
Maximum value (in pels) for this yPelHeight. |
| SHORT |
yMin |
Minimum value (in pels) for this yPelHeight. |
This table must appear in sorted order (sorted by yPelHeight), but need not be continuous. It should have an entry for every pel height where the yMax and yMin do not scale linearly, where linearly scaled heights are defined as:
Hinted yMax and yMin are identical to scaled/rounded yMax and yMin.
It is assumed that once yPelHeight reaches 255, all heights will be linear, or at least close enough to linear that it no longer matters. Please note that while the Ratios structure can only support ppem sizes up to 255, the vTable structure can support much larger pel heights (up to 65535). The choice of SHORT and USHORT for vTable is dictated by the requirement that yMax and yMin be signed values (and 127 to -128 is too small a range) and the desire to word-align the vTable elements.
To generate the CTF font, the values in the VDMX table can be compressed using the following code:
p = VDMXIn; p += 2 * sizeof( uint16 );
CheckReadBoundsForTable( t, p, 2); /* numRatios */
numRatios = READWORD_INC( &p );
{
char *offset; /* Harmless pointer related to VDMXIn */
offset = VDMXIn;
offset += sfnt_VDMXFormatSize + (numRatios-1) * sfnt_VDMXRatio_Size;
assert( sfnt_VDMXFormatSize == 10 );
assert( sfnt_VDMXRatio_Size == 4 );
p = offset;
CheckReadBoundsForTable( t, p, 2);
offsetValue = READWORD_INC( &p );
pOut = (char __huge *)VDMXOut + offsetValue;
pIn = (char __huge *)VDMXIn + offsetValue;
p = offset;
}
for ( i = 0; i < numRatios; i++ )
{
CheckReadBoundsForTable( t, p, 2);
offsetValue = READWORD_INC( &p );
if ( TTF_To_CTF )
{
long yMaxRatio, yMinRatio; /* 16.16 fixpoint */
yMaxRatio = yMinRatio = 0;
groups = (VDMXIn + offsetValue);
CheckReadBoundsForTable( t, (char *)GET_VDMXGroup_recs_Ptr( groups ), VDMXGroupSize ); /* groups->recs */
numGroupRecs = SWAPENDS_U16(*GET_VDMXGroup_recs_Ptr( groups ));
/* Check all entries */
CheckReadBoundsForTable( t, (char *)GET_VDMXGroup_entry_yPelHeight_Ptr( groups, 0 ), VDMXTableSize * numGroupRecs);
/* yPelHeight, yMax, yMin */
for ( k = 0; k < numGroupRecs; k++ )
{
ppem = SWAPENDS_U16(*GET_VDMXGroup_entry_yPelHeight_Ptr( groups, k ));
yMax = SWAPENDS_16(*GET_VDMXGroup_entry_yMax_Ptr( groups, k ));
yMin = SWAPENDS_16(*GET_VDMXGroup_entry_yMin_Ptr( groups, k ));
yMaxRatio += (((long)yMax << 16)+(long)ppem/2)/ ppem; /* 16.16 */
yMinRatio += (((long)yMin << 16)-(long)ppem/2)/ ppem;
}
yMaxRatio = (yMaxRatio+(long)numGroupRecs/2)/ numGroupRecs;
yMinRatio = (yMinRatio-(long)numGroupRecs/2)/ numGroupRecs;
yMaxMultiplier = (long)((yMaxRatio + 16) >> 5); /* convert to 21.11 */
yMinMultiplier = (long)((-yMinRatio + 16) >> 5);
WRITEWORD_INC( &pOut, numGroupRecs );
WRITEWORD_INC( &pOut, (short)yMaxMultiplier );
WRITEWORD_INC( &pOut, (short)yMinMultiplier );
base = (unsigned char *)pOut;
}
bitOffset = 0;
Predicted_ppem = 8;
for ( k = 0; k < numGroupRecs; k++ )
{
if ( TTF_To_CTF )
{
long newLength;
/* We have already bounds-checked this data */
ppem = SWAPENDS_U16(*GET_VDMXGroup_entry_yPelHeight_Ptr( groups, k ));
yMax = SWAPENDS_16(*GET_VDMXGroup_entry_yMax_Ptr( groups, k ));
yMin = SWAPENDS_16(*GET_VDMXGroup_entry_yMin_Ptr( groups, k ));
/* Predicted_ppem; */
Predicted_yMax = (short)((ppem * yMaxMultiplier + 1024L + 0) / 2048L);
Predicted_yMin = (short)((ppem * yMinMultiplier + 1024L - 0) / 2048L);
Predicted_yMin = (short)-Predicted_yMin;
ppemError = (short)(ppem - Predicted_ppem);
yMaxError = (short)(yMax - Predicted_yMax);
yMinError = (short)(yMin - Predicted_yMin);
newLength = (long)((char *)base + (bitOffset + abs(ppemError)+abs(yMaxError)+abs(yMinError)+6 + 7)/8 - VDMXOut);
if ( newLength > lengthIn )
{
/* we have a problem, set version to 0xFFFF-real version and just copy data */
memcpyHuge((char *)VDMXOut,(char *)VDMXIn,lengthIn);
version = *((unsigned short*)VDMXOut);
version = (unsigned short)SWAPENDS_U16( version );
version = (unsigned short)(0xFFFF - version);
version = SWAPENDS_U16( version );
*((unsigned short*)VDMXOut) = version;
return (lengthIn); /*****/
}
else
{
/* We know that we already have lengthIn bytes available so we are OK */
WriteHdmxValue( ppemError, base, &bitOffset );
WriteHdmxValue( yMaxError, base, &bitOffset );
WriteHdmxValue( yMinError, base, &bitOffset );
}
}
Predicted_ppem = (short)(ppem + 1);
}
}
In the CTF font, the values in the VDMX table can be decompressed using the following code:
/*
* ================================================================
* Compressed 'VDMX' Table Layout
* ================================================================
*
* version USHORT
* numRecs USHORT
* numRatios USHORT
* ratio[0].bCharSet BYTE
* ratio[0].xRatio BYTE
* ratio[0].yStartRatio BYTE
* ratio[0].yEndRatio BYTE
* ...
* ratio[n-1].bCharSet, where n = numRatios. BYTE
* ratio[n-1].xRatio BYTE
* ratio[n-1].yStartRatio BYTE
* ratio[n-1].yEndRatio BYTE
* offset[0] USHORT
* ...
* offset[n-1] USHORT
* Skip to
* group[0].nRecs USHORT
* yMaxMult SHORT
* yMinMult SHORT
* BitData for group[0] entries:
* group[0].entry[0].ppemError
* group[0].entry[0].yMaxError
* group[0].entry[0].yMinError
* ...
* group[0].entry[group[0].nRecs-1].ppemError
* group[0].entry[group[0].nRecs-1].yMaxError
* group[0].entry[group[0].nRecs-1].yMinError
* Skip to next byte if in the middle of a byte
*
* group[1].nRecs USHORT
* yMaxMult SHORT
* yMinMult SHORT
* BitData for group[1] entries:
* group[1].entry[0].ppemError
* group[1].entry[0].yMaxError
* group[1].entry[0].yMinError
* ...
* group[1].entry[group[1].nRecs-1].ppemError
* group[1].entry[group[1].nRecs-1].yMaxError
* group[1].entry[group[1].nRecs-1].yMinError
* Skip to next byte if in the middle of a byte
* ...
* group[numRecs-1].nRecs USHORT
* yMaxMult SHORT
* yMinMult SHORT
* BitData for group[numRecs-1] entries:
* group[numRecs-1].entry[0].ppemError
* group[numRecs-1].entry[0].yMaxError
* group[numRecs-1].entry[0].yMinError
* ...
* group[numRecs-1].entry[group[numRecs-1].nRecs-1].nRecs-1].ppemError
* group[numRecs-1].entry[group[numRecs-1].nRecs-1].yMaxError
* group[numRecs-1].entry[group[numRecs-1].nRecs-1].yMinError
* Skip to next byte if in the middle of a byte
*
* Note that the bit data is from least to most significant bit in byte.
*
*/
/*
* ================================================================
* External References to Utility Functions
* ================================================================
* The code snippet below contains references to the following functions
* and structures.
*
* uint8 * getOTUShort( uint8 * ptr, USHORT * valP )
*
* reads a BigEndian unsigned short starting at ptr,
* assigns the value to *valP,
* and returns a pointer to the byte after the unsigned short.
*
* uint8 * getOTShort( uint8 * ptr, SHORT * valP )
*
* reads a BigEndian signed short starting at ptr,
* assigns the value to *valP,
* and returns a pointer to the byte after the signed short.
*
* MAG_DEP_ENC_STATE is an 'object' to remember the current byte and
* bit offset while reading a series of "magnitude dependent encoded
* numbers" from a data stream. Note that the "first bit of a byte"
* is the low-order bit. Bits are read from low-order to high-order.
*
* Methods:
*
* void mde_initReadState( MAG_DEP_END_STATE * rs, uint8 * b )
*
* initializes rs to point at the first bit of byte 'b'.
*
* int mde_getNextValue( MAG_DEP_END_STATE * rs )
*
* returns the next values from stream and leaves 'rs' pointing
* at the first bit after the value.
*
* uint8 * mde_getNextByteAddress( MAG_DEP_END_STATE * rs )
*
* If pointing at the first bit of a byte, return the byte address.
* If in the middle of a byte, return the next byte address.
*/
typedef struct {
BYTE bCharSet;
BYTE xRatio;
BYTE yStartRatio;
BYTE yEndRatio;
} OTVDMXRATIO;
typedef struct {
USHORT yPelHeight;
SHORT yMax;
SHORT yMin;
} OTVDMXVTABLE;
typedef struct {
USHORT recs;
BYTE startsz;
BYTE endsz;
OTVDMXVTABLE * entry;
} OTVDMXGROUP;
typedef struct {
USHORT version;
USHORT numRecs;
USHORT numRatios;
OTVDMXRATIO * ratios;
USHORT * offset;
OTVDMXGROUP * groups;
} OTVDMXTABLE;
void
ReadVDMXTable( uint8 * tableStart, OTVDMXTABLE * vdmx )
{
int i;
uint8 * b = tableStart; /* Point to beginning of compressed VDMX table */
/* version, numRecs, numRatios */
b = getOTUShort( b, &(vdmx->version) );
b = getOTUShort( b, &(vdmx->numRecs) );
b = getOTUShort( b, &(vdmx->numRatios) );
/* Allocate space for and read ratios. No error checking for brevity */
vdmx->ratios = ALLOC( vdmx->numRatios*sizeof(OTVDMXRATIO) );
for ( i = 0; i < ( int )vdmx->numRatios; i++ ) {
OTVDMXRATIO * ratio = &vdmx->ratios[i];
ratio->bCharSet = *b;
b++;
ratio->xRatio = *b;
b++;
ratio->yStartRatio = *b;
b++;
ratio->yEndRatio = *b;
b++;
}
/* Allocate space for and read offsets[0..numRatios-1] */
vdmx->offset = ALLOC( vdmx->numRatios * sizeof(USHORT) );
for ( i = 0; i < ( int )vdmx->numRatios; i++ ) {
b = getOTUShort( b, &(vdmx->offset[i]) );
}
/*
* Allocate space for and read the vdmx->numRecs groups
* See the Layout comment above.
* Values group[i]->startsz and group[i]->endsz are accumulated as we go.
*/
vdmx->groups = ALLOC( vdmx->numRecs*sizeof(OTVDMXGROUP) );
b = tableStart + vdmx->offset[0];
for ( i = 0; i < ( int )vdmx->numRecs; i++ ) {
OTVDMXGROUP * group = &vdmx->groups[i];
MAG_DEP_ENC_STATE rs;
int j;
int predictedPPEM = 8;
SHORT yMaxMult; /* Fixed point 7.11 */
SHORT yMinMult; /* Fixed point 7.11 */
b = getOTUShort( b, &(group->recs) );
b = getOTShort( b, &yMaxMult );
b = getOTShort( b, &yMinMult );
group->entry = ALLOC( group->recs*sizeof(OTVDMXVTABLE) );
mde_initReadState( &rs, b );
for ( j = 0; j < ( int )group->recs; j++ ) {
OTVDMXVTABLE * entry = &group->entry[j];
int ppemError = mde_getNextValue( &rs );
int yMaxError = mde_getNextValue( &rs );
int yMinError = mde_getNextValue( &rs );
int actualPPEM = ppemError + predictedPPEM;
int predictedYMax = (actualPPEM * yMaxMult + 1024) / 2048;
int predictedYMin = -((actualPPEM * yMinMult + 1024) / 2048);
entry->yPelHeight = ( USHORT )actualPPEM;
entry->yMax = ( SHORT )(predictedYMax + yMaxError);
entry->yMin = ( SHORT )(predictedYMin + yMinError);
if ( 0 == j ) {
group->startsz = actualPPEM; /* Write the first time only */
}
group->endsz = actualPPEM; /* Overwritten each time. */
predictedPPEM = actualPPEM + 1;
}
b = mde_getNextByteAddress( &rs );
}
}
5.6. The 'glyf' Table Translation
The ‘glyf’ table contains all the information about simple and composite glyphs in OpenType TrueType font. Simple glyphs are recorded as a collection of data segments representing number of contours, bounding box, TTF instructions for glyph scaling and arrays of data point coordinates. If composite characters are present they contain the array of simple glyph indexes along with the scaling information and TTF instructions for the composite glyph. These datasets have distinctly different statistical distributions of values and, sometimes, significant levels of redundancy. The use of internal dependencies of glyph data segments and knowledge of TrueType rasterizer behavior allows the application of additional compression algorithms to reduce glyph data set without any affect on the functionality of glyph rendering and the output quality of TrueType rasterizer.
5.7. Glyph Records
Glyph records are located in the ‘glyf’ table of OpenType font. Glyphs are recorded as a set of bounding box values, TrueType instructions, flags and outline data points. The glyph record size can be reduced with no effect on the quality of the glyph rendering. MicroType Express converts simple TTF glyph table records to lossless Compact Table Format (CTF).
5.7.1. Bounding Box
In most cases, the bounding box information can be computed from the data point coordinates and, therefore, bounding box information may be omitted in glyph record. In the event that it is necessary to store the bounding box, numContours will be set to 0x7FFF for a simple glyph or -1 for a composite glyph. In the case of a simple glyph with numContours == 0x7FFF, the next value in the data will be the actual number of contours. (See CTF Glyph data)
5.7.2. Contour End Points
TrueType glyphs store actual numbers of the end point for each contour. CTF stores the end point of the first contour and the number of points in each subsequent contour instead, which is typically less then 255. Translation to the endpoint number is simply the cumulative sum of point count in all preceding contours.
5.8. CTF Glyph Data
The following table contains information that describes the glyph data in CTF format.
| Data Type |
Syntax |
Description and Comments |
| SHORT |
numContours |
Number of contours in the glyph, also used as a flag. |
| |
if (numContours < 0)
{ |
If numContours == -1, the glyph is composite glyph. |
| SHORT |
xMin |
Minimum X value for coordinate data |
| SHORT |
yMin |
Minimum Y value for coordinate data |
| SHORT |
xMax |
Maximum X value for coordinate data |
| SHORT |
yMax |
Maximum Y value for coordinate data |
| |
/* Composite CTF Glyph Table */ |
|
| |
} else { |
|
| |
if (numContours == 0x7FFF) { |
This is a flag, read new value and bounding box information below. |
| SHORT |
numContours |
Number of contours in the glyph, also used as a flag. |
| SHORT |
xMin |
Minimum X value for coordinate data |
| SHORT |
yMin |
Minimum Y value for coordinate data |
| SHORT |
xMax |
Maximum X value for coordinate data |
| SHORT |
yMax |
Maximum Y value for coordinate data |
| |
} else { |
Bounding box information omitted and should be computed from the glyph data coordinates. |
| |
/* Simple CTF Glyph Table */ |
See: Simple CTF Glyph Table |
| 255USHORT (see 6.1.1. 255UShort Data Type) |
pushCount |
Number of data items in the push data stream. See: Compressed Data Set 2 – Glyph Push Data |
| 255USHORT |
codeSize |
Number of data items in the glyph program stream. See: Compressed Data Set 3 –Glyph Instructions |
| |
} |
|
| |
} |
|
5.9. Simple CTF Glyph Table
A simple glyph defines all the contours and points that are used to create the glyph outline. Each point is presented in a {dx, dy, on/off-curve} triplet that is stored with the variable length encoding consuming 2 to 5 bytes per triplet.
We use one bit of the first byte to indicate whether the point is an on- or off-curve point (if the most significant bit is 0, then the point is on-curve). Thus we are left with 128 remaining combinations for the first byte. All 128 remaining combinations have a precisely defined meaning. They specify the following seven properties:
- Total number of bytes used for this triplet (byte count 2-5). This number is used to determine the number of bytes of data to read for the encoding of X and Y coordinates. Be sure to subtract one from this number, since you have already read the flag byte. See Triplet Encoding of X and Y Coordinates.
- Number of additional bits beyond the first byte used for describing the dx value.
- Number of additional bits beyond the first byte used for describing the dy value.
- An additional amount to add to the dx value described by data beyond the first byte.
- An additional amount to add to the dy value described by data beyond the first byte.
- The sign of the dx value. (this has no meaning if the value of dx is zero, which is specified by 0 xbits).
- The sign of the dy value. (this has no meaning if the value of dy is zero, which is specified by 0 ybits).
Each of the 128 combinations identify a unique set of these seven properties which have been assigned after careful consideration has been given to the typical statistical distribution of data found in TrueType files. As a result, the dataset size in CTF format is significantly reduced compared to the native TrueType format. However, the data is left byte aligned so that a Huffman entropy coder can be easily applied on the second stage.
Unlike the native TrueType formats that allows X and Y coordinates values be defined either in relative or absolute values, the CTF format always defines X and Y coordinates as relative values to the previous point. The first point is relative to (0,0).
The information on data formats of (xCoordinate, yCoordinate)[ ] of glyph data can be found in the paragraph 5.11 of this specification. This table describes simple glyph data in CTF format.
| Data Type |
Syntax |
Description and Comments |
| |
/* Data */ |
|
| 255USHORT (see section 6.1.1. 255UShort Data Type) |
contourPoints[numContours] |
End point of first contour, number of points in each subsequent contour, cumulative sum should be calculated to define total number of points. |
| BYTE |
flags[numPoints] |
Array of flags for each coordinate in glyph outline. |
| Variable length bit field |
(xCoordinate, yCoordinate)[numPoints] |
Array of X Y coordinates for glyph outline points. See Triplet Encoding of X and Y Coordinates. |
5.10. Composite CTF Glyph Table
The following table describes composite glyph data in CTF format.
| Data Type |
Syntax |
Description and Comments |
| |
/* Data */ |
|
|
do { |
/* for all glyph components */ |
| USHORT |
flags |
Flags for each component in composite glyph. |
|
. . . . . . . |
See ‘glyf’ table specification for more information. |
|
} while (flags & MORE_COMPONENTS); |
|
|
if (flags & WE_HAVE_INSTR) { |
|
| 255USHORT (see 6.1.1. 255UShort Data Type) |
pushCount |
Number of data items in the push data stream. See: Compressed Data Set 2 – Glyph Push Data |
| 255USHORT |
codeSize |
Number of data items in the glyph program stream. See: Compressed Data Set 3 –Glyph Instructions |
|
} |
|
The information on data formats of flags[ ], (xCoordinate, yCoordinates)[] of glyph data section can be found in the ‘glyf’ table of OpenType font format specification.
Note: if the WE_HAVE_INSTR flag is set, then there is hint data and code for this composite glyph, see Compressed Data Set 2 – Glyph Push Data and Compressed Data Set 3 –Glyph Instructions for more information.
5.11. Triplet Encoding of X and Y Coordinates
The following table presents information on Triplet Encoding (flag[],
(xCoordinate, yCoordinate)[]) of simple glyph outline points.
Please note – “Byte Count” field reflects total size of the triplet, including ‘flags’.
| Index |
Byte Count |
X bits |
Y bits |
Delta X |
Delta Y |
X sign |
Y sign |
| 0 |
2 |
0 |
8 |
N/A |
0 |
N/A |
- |
| 1 |
|
|
|
|
0 |
|
+ |
| 2 |
|
|
|
|
256 |
|
- |
| 3 |
|
|
|
|
256 |
|
+ |
| 4 |
|
|
|
|
512 |
|
- |
| 5 |
|
|
|
|
512 |
|
+ |
| 6 |
|
|
|
|
768 |
|
- |
| 7 |
|
|
|
|
768 |
|
+ |
| 8 |
|
|
|
|
1024 |
|
- |
| 9 |
|
|
|
|
1024 |
|
+ |
| 10 |
2 |
8 |
0 |
0 |
N/A |
- |
N/A |
| 11 |
|
|
|
0 |
|
+ |
|
| 12 |
|
|
|
256 |
|
- |
|
| 13 |
|
|
|
256 |
|
+ |
|
| 14 |
|
|
|
512 |
|
- |
|
| 15 |
|
|
|
512 |
|
+ |
|
| 16 |
|
|
|
768 |
|
- |
|
| 17 |
|
|
|
768 |
|
+ |
|
| 18 |
|
|
|
1024 |
|
- |
|
| 19 |
|
|
|
1024 |
|
+ |
|
| 20 |
2 |
4 |
4 |
1 |
1 |
- |
- |
| 21 |
|
|
|
|
1 |
+ |
- |
| 22 |
|
|
|
|
1 |
- |
+ |
| 23 |
|
|
|
|
1 |
+ |
+ |
| 24 |
|
|
|
|
17 |
- |
- |
| 25 |
|
|
|
|
17 |
+ |
- |
| 26 |
|
|
|
|
17 |
- |
+ |
| 27 |
|
|
|
|
17 |
+ |
+ |
| 28 |
|
|
|
|
33 |
- |
- |
| 29 |
|
|
|
|
33 |
+ |
- |
| 30 |
|
|
|
|
33 |
- |
+ |
| 31 |
|
|
|
|
33 |
+ |
+ |
| 32 |
|
|
|
|
49 |
- |
- |
| 33 |
|
|
|
|
49 |
+ |
- |
| 34 |
|
|
|
|
49 |
- |
+ |
| 35 |
|
|
|
|
49 |
+ |
+ |
| 36 |
2 |
4 |
4 |
17 |
1 |
- |
- |
| 37 |
|
|
|
|
1 |
+ |
- |
| 38 |
|
|
|
|
1 |
- |
+ |
| 39 |
|
|
|
|
1 |
+ |
+ |
| 40 |
|
|
|
|
17 |
- |
- |
| 41 |
|
|
|
|
17 |
+ |
- |
| 42 |
|
|
|
|
17 |
- |
+ |
| 43 |
|
|
|
|
17 |
+ |
+ |
| 44 |
|
|
|
|
33 |
- |
- |
| 45 |
|
|
|
|
33 |
+ |
- |
| 46 |
|
|
|
|
33 |
- |
+ |
| 47 |
|
|
|
|
33 |
+ |
+ |
| 48 |
|
|
|
|
49 |
- |
- |
| 49 |
|
|
|
|
49 |
+ |
- |
| 50 |
|
|
|
|
49 |
- |
+ |
| 51 |
|
|
|
|
49 |
+ |
+ |
| 52 |
2 |
4 |
4 |
33 |
1 |
- |
- |
| 53 |
|
|
|
|
1 |
+ |
- |
| 54 |
|
|
|
|
1 |
- |
+ |
| 55 |
|
|
|
|
1 |
+ |
+ |
| 56 |
|
|
|
|
17 |
- |
- |
| 57 |
|
|
|
|
17 |
+ |
- |
| 58 |
|
|
|
|
17 |
- |
+ |
| 59 |
|
|
|
|
17 |
+ |
+ |
| 60 |
|
|
|
|
33 |
- |
- |
| 61 |
|
|
|
|
33 |
+ |
- |
| 62 |
|
|
|
|
33 |
- |
+ |
| 63 |
|
|
|
|
33 |
+ |
+ |
| 64 |
|
|
|
|
49 |
- |
- |
| 65 |
|
|
|
|
49 |
+ |
- |
| 66 |
|
|
|
|
49 |
- |
+ |
| 67 |
|
|
|
|
49 |
+ |
+ |
| 68 |
2 |
4 |
4 |
49 |
1 |
- |
- |
| 69 |
|
|
|
|
1 |
+ |
- |
| 70 |
|
|
|
|
1 |
- |
+ |
| 71 |
|
|
|
|
1 |
+ |
+ |
| 72 |
|
|
|
|
17 |
- |
- |
| 73 |
|
|
|
|
17 |
+ |
- |
| 74 |
|
|
|
|
17 |
- |
+ |
| 75 |
|
|
|
|
17 |
+ |
+ |
| 76 |
|
|
|
|
33 |
- |
- |
| 77 |
|
|
|
|
33 |
+ |
- |
| 78 |
|
|
|
|
33 |
- |
+ |
| 79 |
|
|
|
|
33 |
+ |
+ |
| 80 |
|
|
|
|
49 |
- |
- |
| 81 |
|
|
|
|
49 |
+ |
- |
| 82 |
|
|
|
|
49 |
- |
+ |
| 83 |
|
|
|
|
49 |
+ |
+ |
| 84 |
3 |
8 |
8 |
1 |
1 |
- |
- |
| 85 |
|
|
|
|
1 |
+ |
- |
| 86 |
|
|
|
|
1 |
- |
+ |
| 87 |
|
|
|
|
1 |
+ |
+ |
| 88 |
|
|
|
|
257 |
- |
- |
| 89 |
|
|
|
|
257 |
+ |
- |
| 90 |
|
|
|
|
257 |
- |
+ |
| 91 |
|
|
|
|
257 |
+ |
+ |
| 92 |
|
|
|
|
513 |
- |
- |
| 93 |
|
|
|
|
513 |
+ |
- |
| 94 |
|
|
|
|
513 |
- |
+ |
| 95 |
|
|
|
|
513 |
+ |
+ |
| 96 |
3 |
8 |
8 |
257 |
1 |
- |
- |
| 97 |
|
|
|
|
1 |
+ |
- |
| 98 |
|
|
|
|
1 |
- |
+ |
| 99 |
|
|
|
|
1 |
+ |
+ |
| 100 |
|
|
|
|
257 |
- |
- |
| 101 |
|
|
|
|
257 |
+ |
- |
| 102 |
|
|
|
|
257 |
- |
+ |
| 103 |
|
|
|
|
257 |
+ |
+ |
| 104 |
|
|
|
|
513 |
- |
- |
| 105 |
|
|
|
|
513 |
+ |
- |
| 106 |
|
|
|
|
513 |
- |
+ |
| 107 |
|
|
|
|
513 |
+ |
+ |
| 108 |
3 |
8 |
8 |
513 |
1 |
- |
- |
| 109 |
|
|
|
|
1 |
+ |
- |
| 110 |
|
|
|
|
1 |
- |
+ |
| 111 |
|
|
|
|
1 |
+ |
+ |
| 112 |
|
|
|
|
257 |
- |
- |
| 113 |
|
|
|
|
257 |
+ |
- |
| 114 |
|
|
|
|
257 |
- |
+ |
| 115 |
|
|
|
|
257 |
+ |
+ |
| 116 |
|
|
|
|
513 |
- |
- |
| 117 |
|
|
|
|
513 |
+ |
- |
| 118 |
|
|
|
|
513 |
- |
+ |
| 119 |
|
|
|
|
513 |
+ |
+ |
| 120 |
4 |
12 |
12 |
0 |
0 |
- |
- |
| 121 |
|
|
|
|
|
+ |
- |
| 122 |
|
|
|
|
|
- |
+ |
| 123 |
|
|
|
|
|
+ |
+ |
| 124 |
5 |
16 |
16 |
0 |
0 |
- |
- |
| 125 |
|
|
|
|
|
+ |
- |
| 126 |
|
|
|
|
|
- |
+ |
| 127 |
|
|
|
|
|
+ |
+ |
The coordinate values of simple glyph outline points are calculated as follows:
- Xcoord[i] = (SHORT)((Xsign)*(xCoordinate[i] + DeltaX[index]);
- Ycoord[i] = (SHORT)((Ysign)*(xCoordinate[i] + DeltaX[index]);
Here is some pseudo-code illustrating how to read in the data:
for i = 0 to (glyph.numberOfPoints - 1)
{
bitflags = flags[i]
isOnCurvePoint = ((bitflags & 0x80) == 0)
index = (bitflags & 0x7F)
xIsNegative = coordEncoding[index].xIsNegative
yIsNegative = coordEncoding[index].yIsNegative;
# subtract one from byteCount since one byte is for the flags
byteCount = coordEncoding[index].byteCount - 1
data = 0
for j = 0 to (byteCount - 1)
{
data <<= 8
ultmp = glyfData.getNextUInt8()
data |= ultmp
}
ultmp = data >> ((byteCount * 8) - coordEncoding[index].xBits)
ultmp &= ((1L << coordEncoding[index].xBits ) - 1)
dx = ultmp
ultmp = data >> ((byteCount * 8) - coordEncoding[index].xBits
- coordEncoding[index].yBits)
ultmp &= ((1L << coordEncoding[index].yBits ) - 1)
dy = ultmp
dx += coordEncoding[index].deltaX
dy += coordEncoding[index].deltaY
if ( xIsNegative )
dx = -dx
if ( yIsNegative )
dy = -dy
x = (x+dx)
y = (y+dy)
}
Appendix C. LZCOMP Compression/Decompression Sample Code
In the following code we assume that the following symbols are defined:
#define COMPRESS_ON
#define DECOMPRESS_ON
Optional defines are as follows:
#define BIT16 /* for 16-bit applications */
#define __cplusplus /* for C++ applications */
#define _WINDOWS /* for Windows applications */
#define VERBOSE /* for standard printf printout */
/****************************************************************************************/
/* ERRCODES.H */
/****************************************************************************************/
#define NO_ERROR 0
#define ERR_BITIO_end_of_file 3304 /*BITIO::input_bit:UNEXPECTED END OF FILE*/
#define ERR_LZCOMP_Encode_bounds 3353 /*LZCOMP:Encode out of bounds i*/
#define ERR_LZCOMP_Decode_bounds 3354 /*LZCOMP::Decode out of bounds pos*/
/****************************************************************************************/
/* MTXMEM.H */
/****************************************************************************************/
#ifndef MEMORY_HPP
#define MEMORY_HPP
#include <setjmp.h>
#ifdef __cplusplus
extern "C" {
#endif
typedef struct {
/* private */
void *pointermem;
long pointersize;
} mem_struct;
#ifndef MTX_MEMPTR
#define MTX_MEMPTR
#ifdef BIT16 /* for 16-bit applications */
typedef void *(*MTX_MALLOCPTR)(unsigned long);
typedef void *(*MTX_REALLOCPTR)(void *, unsigned long, unsigned long);
typedef void (*MTX_FREEPTR)(void *);
#else /* for 32-bit applications */
typedef void *(*MTX_MALLOCPTR)(size_t);
typedef void *(*MTX_REALLOCPTR)(void *, size_t);
typedef void (*MTX_FREEPTR)(void *);
#endif /* BIT16 */
#endif /* MTX_MEMPTR */
typedef struct {
/* private */
mem_struct *mem_pointers;
long mem_maxPointers;
long mem_numPointers; /* Number of non-zero pointers */
long mem_numNewCalls;
MTX_MALLOCPTR malloc;
MTX_REALLOCPTR realloc;
MTX_FREEPTR free;
/* public */
jmp_buf env;
} MTX_MemHandler;
/* public interface routines */
/* Call mem_CloseMemory on normal exit */
void MTX_mem_CloseMemory( MTX_MemHandler *t ); /* Frees internal memory and for debugging purposes */
/* Call mem_FreeAllMemory insted on an abnormal (exception) exit */
void MTX_mem_FreeAllMemory( MTX_MemHandler *t ); /* Always call if the code throws an exception */
void *MTX_mem_malloc(MTX_MemHandler *t, unsigned long size);
void *MTX_mem_realloc(MTX_MemHandler *t, void *p, unsigned long size);
void MTX_mem_free(MTX_MemHandler *t, void *deadObject);
MTX_MemHandler *MTX_mem_Create(MTX_MALLOCPTR mptr, MTX_REALLOCPTR rptr, MTX_FREEPTR fptr);
void MTX_mem_Destroy(MTX_MemHandler *t);
#ifdef __cplusplus
}
#endif
#endif /* MEMORY_HPP */
/****************************************************************************************/
/* BITIO.H */
/****************************************************************************************/
#include "MTXMEM.H"
#ifdef __cplusplus
extern "C" {
#endif
typedef struct {
/* private */
unsigned char *mem_bytes; /* Memory data buffer */
long mem_index; /* Memory area size */
long mem_size; /* Memory area size */
unsigned short input_bit_count; /* Input bits buffered */
unsigned short input_bit_buffer; /* Input buffer */
long bytes_in; /* Input byte count */
unsigned short output_bit_count; /* Output bits buffered */
unsigned short output_bit_buffer; /* Output buffer */
long bytes_out; /* Output byte count */
char ReadOrWrite;
MTX_MemHandler *mem;
/* public */
/* No public fields! */
} BITIO;
/* public interface routines */
/* Writes out <numberOfBits> to the output memory */
void MTX_BITIO_WriteValue( BITIO *t, unsigned long value, long numberOfBits );
/* Reads out <numberOfBits> from the input memory */
unsigned long MTX_BITIO_ReadValue( BITIO *t, long numberOfBits );
/* Read a bit from input memory */
short MTX_BITIO_input_bit(BITIO *t);
/* Write one bit to output memory */
void MTX_BITIO_output_bit(BITIO *t,unsigned long bit);
/* Flush any remaining bits to output memory before finnishing */
void MTX_BITIO_flush_bits(BITIO *t);
/* Returns the memory buffer pointer */
unsigned char *MTX_BITIO_GetMemoryPointer( BITIO *t );
long MTX_BITIO_GetBytesOut( BITIO *t ); /* Get method for the output byte count */
long MTX_BITIO_GetBytesIn( BITIO *t ); /* Get method for the input byte count */
/* Constructor for the new Memory based incarnation */
BITIO *MTX_BITIO_Create( MTX_MemHandler *mem, void *memPtr, long memSize, const char param ); /* mem Pointer, current size, 'r' or 'w' */
/* Destructor */
void MTX_BITIO_Destroy(BITIO *t);
#ifdef __cplusplus
}
#endif
/****************************************************************************************/
/* BITIO.C */
/****************************************************************************************/
#ifdef _WINDOWS
#include <windows.h>
#endif
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <string.h>
#include <ctype.h>
#include "BITIO.H"
#include "ERRCODES.H"
/* Writes out <numberOfBits> to the output memory */
void MTX_BITIO_WriteValue( BITIO *t, unsigned long value, long numberOfBits )
{
register long i;
for ( i = numberOfBits-1; i >=0; i-- ) {
MTX_BITIO_output_bit( t, (unsigned long)(value & (1L<<i)) );
}
}
/* Reads out <numberOfBits> from the input memory */
unsigned long MTX_BITIO_ReadValue( BITIO *t, long numberOfBits )
{
unsigned long value;
long i;
value = 0;
for ( i = numberOfBits-1; i >=0; i-- ) {
value <<= 1;
if ( MTX_BITIO_input_bit(t) ) value |= 1;
}
return value; /******/
}
/* Read one bit from the input memory */
short MTX_BITIO_input_bit( register BITIO *t )
{
/*assert( t->ReadOrWrite == 'r' ); */
if ( t->input_bit_count-- == 0 ) {
t->input_bit_buffer = t->mem_bytes[ t->mem_index++ ];
if ( t->mem_index > t->mem_size ) {
longjmp( t->mem->env, ERR_BITIO_end_of_file );
}
++(t->bytes_in);
t->input_bit_count = 7;
}
t->input_bit_buffer <<= 1;
return(t->input_bit_buffer & 0x100); /******/
}
/* Write one bit to the output memory */
void MTX_BITIO_output_bit( register BITIO *t, unsigned long bit )
{
/*assert( t->ReadOrWrite == 'w' ); */
t->output_bit_buffer <<= 1;
if ( bit ) t->output_bit_buffer |= 1;
if ( ++(t->output_bit_count) == 8 ) {
if ( t->mem_index >=t->mem_size ) { /* See if we need more memory */
t->mem_size += t->mem_size/2; /* Allocate in exponentially increasing steps */
t->mem_bytes = (unsigned char *)MTX_mem_realloc( t->mem, t->mem_bytes, t->mem_size );
}
t->mem_bytes[t->mem_index++] = (unsigned char)t->output_bit_buffer;
t->output_bit_count = 0;
++(t->bytes_out);
}
}
/* Flush any remaining bits to output memory before finnishing */
void MTX_BITIO_flush_bits( BITIO *t )
{
assert( t->ReadOrWrite == 'w' );
if (t->output_bit_count > 0) {
if ( t->mem_index >=t->mem_size ) {
t->mem_size = t->mem_index + 1;
t->mem_bytes = (unsigned char *)MTX_mem_realloc( t->mem, t->mem_bytes, t->mem_size );
}
t->mem_bytes[t->mem_index++] = (unsigned char)(t->output_bit_buffer << (8 - t->output_bit_count));
t->output_bit_count = 0;
++(t->bytes_out);
}
}
/* Returns the memory buffer pointer */
unsigned char *MTX_BITIO_GetMemoryPointer( BITIO *t )
{
return t->mem_bytes; /******/
}
/* Returns number of bytes written */
long MTX_BITIO_GetBytesOut( BITIO *t )
{
assert( t->ReadOrWrite == 'w' );
return t->bytes_out; /******/
}
/* Returns number of bytes read */
long MTX_BITIO_GetBytesIn( BITIO *t )
{
assert( t->ReadOrWrite == 'r' );
return t->bytes_out; /******/
}
/* Constructor for Memory based incarnation */
BITIO *MTX_BITIO_Create( MTX_MemHandler *mem, void *memPtr, long memSize, const char param )
{
BITIO *t = (BITIO *)MTX_mem_malloc( mem, sizeof( BITIO ) );
t->mem = mem;
t->mem_bytes = (unsigned char *)memPtr;
t->mem_index = 0;
t->mem_size = memSize;
t->ReadOrWrite = param;
t->input_bit_count = 0;
t->input_bit_buffer = 0;
t->bytes_in = 0;
t->output_bit_count = 0;
t->output_bit_buffer = 0;
t->bytes_out = 0;
return t; /******/
}
/* Destructor */
void MTX_BITIO_Destroy(BITIO *t)
{
if ( t->ReadOrWrite == 'w' ) {
MTX_BITIO_flush_bits(t);
assert( t->mem_index == t->bytes_out );
}
MTX_mem_free( t->mem, t );
}
/****************************************************************************************/
/* AHUFF.H */
/****************************************************************************************/
#include "MTXMEM.H"
#ifdef __cplusplus
extern "C" {
#endif
extern long MTX_AHUFF_BitsUsed( register long x );
/* This struct is only for internal use by AHUFF */
typedef struct {
short up;
short left;
short right;
short code; /* < 0 for internal node, == code otherwise */
long weight;
} nodeType;
typedef struct {
/* private */
nodeType *tree;
short *symbolIndex;
long bitCount, bitCount2;
long range;
BITIO *bio;
MTX_MemHandler *mem;
int maxSymbol;
long countA;
long countB;
long sym_count;
/* public */
/* No public fields! */
} AHUFF;
/* Public Interface */
short MTX_AHUFF_ReadSymbol( AHUFF *t );
long MTX_AHUFF_WriteSymbolCost( AHUFF *t, short symbol ); /* returns 16.16 bit cost */
void MTX_AHUFF_WriteSymbol( AHUFF *t, short symbol );
/* Constructor */
AHUFF *MTX_AHUFF_Create( MTX_MemHandler *mem, BITIO *bio, short range ); /* [0 .. range-1] */
/* Destructor */
void MTX_AHUFF_Destroy( AHUFF *t );
#ifdef __cplusplus
}
#endif
/****************************************************************************************/
/* AHUFF.C */
/****************************************************************************************/
#ifdef _WINDOWS
#include <windows.h>
#endif
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <string.h>
#include <ctype.h>
#include "BITIO.H"
#include "AHUFF.H"
#include "MTXMEM.H"
/* Returns number of bits used in the positive number x */
long MTX_AHUFF_BitsUsed( register long x )
{
register long n;
assert( x >=0 );
if ( x & 0xffff0000 ) {
/* 17-32 */
if ( x & 0xff000000 ) {
/* 25-32 */
if ( x & 0xf0000000 ) {
/* 29-32 */
if ( x & 0xC0000000 ) {
/* 31-32 */
n = x & 0x80000000 ? 32 : 31;
} else {
/* 29-30 */
n = x & 0x20000000 ? 30 : 29;
}
} else {
/* 25-28 */
if ( x & 0x0C000000 ) {
/* 27-28 */
n = x & 0x08000000 ? 28 : 27;
} else {
/* 25-26 */
n = x & 0x02000000 ? 26 : 25;
}
}
} else {
/* 17-24 */
if ( x & 0x00f00000 ) {
/* 21-24 */
if ( x & 0x00C00000 ) {
/* 23-24 */
n = x & 0x00800000 ? 24 : 23;
} else {
/* 21-22 */
n = x & 0x00200000 ? 22 : 21;
}
} else {
/* 17-20 */
if ( x & 0x000C0000 ) {
/* 19-20 */
n = x & 0x00080000 ? 20 : 19;
} else {
/* 17-18 */
n = x & 0x00020000 ? 18 : 17;
}
}
}
} else {
/* 1-16 */
if ( x & 0xff00 ) {
/* 9-16 */
if ( x & 0xf000 ) {
/* 13-16 */
if ( x & 0xC000 ) {
/* 15-16 */
n = x & 0x8000 ? 16 : 15;
} else {
/* 13-14 */
n = x & 0x2000 ? 14 : 13;
}
} else {
/* 9-12 */
if ( x & 0x0C00 ) {
/* 11-12 */
n = x & 0x0800 ? 12 : 11;
} else {
/* 9-10 */
n = x & 0x0200 ? 10 : 9;
}
}
} else {
/* 1-8 */
if ( x & 0xf0 ) {
/* 5-8 */
if ( x & 0x00C0 ) {
/* 7-8 */
n = x & 0x0080 ? 8 : 7;
} else {
/* 5-6 */
n = x & 0x0020 ? 6 : 5;
}
} else {
/* 1-4 */
if ( x & 0x000C ) {
/* 3-4 */
n = x & 0x0008 ? 4 : 3;
} else {
/* 1-2 */
n = x & 0x0002 ? 2 : 1;
}
}
}
}
return n; /******/
}
#ifdef DEBUG
/* This method does various validity checks on the tree */
/* This is only needed for debugging, but if any changes */
/* are made to the code, then we need to ensure that */
/* this method still accepts the tree. */
static void check_tree( AHUFF *t )
{
long i, j;
short a, b, diff;
register nodeType *tree = t->tree;
const short ROOT = 1;
/* assert children point to parents */
for ( i = ROOT; i < t->range; i++ ) {
if ( tree[i].code < 0 ) {
if ( tree[tree[i].left].up != i ) {
/*cout << i << "," << tree[i].left << "," << tree[tree[i].left].up << endl; */
#ifndef _WINDOWS
printf("%ld , %ld , %ld\n", (long)i, (long)tree[i].left, (long)tree[tree[i].left].up );
#endif
}
assert( tree[tree[i].left].up == i );
assert( tree[tree[i].right].up == i );
}
}
/* assert weigths sum up */
for ( i = ROOT; i < t->range; i++ ) {
if ( tree[i].code < 0 ) {
#ifndef _WINDOWS
if ( tree[i].weight != tree[tree[i].left].weight + tree[tree[i].right].weight ) {
/*cout << i << "," << tree[i].left << "," << tree[i].right << endl; */
printf("%ld , %ld , %ld\n", (long)i, (long)tree[i].left, (long)tree[i].right );
/*cout << tree[i].weight << "," << tree[tree[i].left].weight << "," << tree[tree[i].right].weight << endl; */
printf("%ld , %ld , %ld\n", (long)tree[i].weight, (long)tree[tree[i].left].weight, (long)tree[tree[i].right].weight );
}
#endif
assert( tree[i].weight == tree[tree[i].left].weight + tree[tree[i].right].weight );
}
}
/* assert everything in decreasing order */
j = t->range * 2 - 1;
for ( i = ROOT; i < j; i++ ) {
assert( tree[i].weight >=tree[i+1].weight );
}
/* assert siblings next to each other */
for ( i = ROOT+1; i < j; i++ ) {
if ( tree[i].code < 0 ) {
/* Internal node */
a = tree[i].left;
b = tree[i].right;
diff = (short)(a >=b ? a - b : b - a);
assert( diff == 1 );
}
}
j = t->range * 2;
for ( i = ROOT + 1; i < j; i++ ) {
a = tree[i].up;
assert( tree[a].left == i || tree[a].right == i );
}
}
#endif /* DEBUG */
/* Swaps the nodes a and b */
static void SwapNodes( AHUFF *t, register short a, register short b )
{
short code;
short upa, upb;
nodeType tNode;
register nodeType *tree = t->tree;
const short ROOT = 1;
assert( a != b );
assert( a > ROOT );
assert( b > ROOT );
assert( a < 2*t->range );
assert( b < 2*t->range );
assert( tree[a].code < 0 || t->symbolIndex[ tree[a].code ] == a );
assert( tree[b].code < 0 || t->symbolIndex[ tree[b].code ] == b );
upa = tree[a].up;
upb = tree[b].up;
assert( tree[upa].code < 0 );
assert( tree[upb].code < 0 );
assert( tree[upa].left == a || tree[upa].right == a );
assert( tree[upb].left == b || tree[upb].right == b );
assert( tree[a].weight == tree[b].weight );
#ifdef OLD
deltaW = -tree[a].weight + tree[b].weight;
assert( deltaW == 0 );
tree[upa].weight += deltaW;
tree[upb].weight -= deltaW;
#endif
tNode = tree[a];
tree[a] = tree[b];
tree[b] = tNode;
tree[a].up = upa;
tree[b].up = upb;
code = tree[a].code;
if ( code < 0 ) {
/* Internal nodes have children */
tree[tree[a].left ].up = a;
tree[tree[a].right].up = a;
} else {
assert( code < t->range );
t->symbolIndex[ code ] = a;
}
code = tree[b].code;
if ( code < 0 ) {
/* Internal nodes have children */
tree[tree[b].left ].up = b;
tree[tree[b].right].up = b;
} else {
assert( code < t->range );
t->symbolIndex[ code ] = b;
}
assert( tree[upa].left == a || tree[upa].right == a );
assert( tree[upb].left == b || tree[upb].right == b );
}
/* Updates the weight for index a, and it's parents */
static void UpdateWeight( register AHUFF *t, register short a )
{
register nodeType *tree = t->tree;
const short ROOT = 1;
for (; a != ROOT; a = tree[a].up) {
register long weightA = tree[a].weight;
register short b = (short)(a-1);
/* This if statement prevents sibling rule violations */
assert( tree[b].weight >=weightA );
if ( tree[b].weight == weightA ) {
do {
b--;
} while ( tree[b].weight == weightA );
b++;
assert( b >=ROOT );
if ( b > ROOT ) {
SwapNodes( t, a, b );
a = b;
}
}
tree[a].weight = ++weightA;
#ifdef DEBUG
if ( tree[a].code < 0 ) {
assert( tree[a].weight == tree[tree[a].left].weight + tree[tree[a].right].weight );
}
#endif
}
assert( a == ROOT );
tree[a].weight++;
assert( tree[a].weight == tree[tree[a].left].weight + tree[tree[a].right].weight );
/*check_tree(); slooow */
}
/* Recursively sets the parent weight equal to the sum of the two chilren's weights. */
static long init_weight(AHUFF *t, int a)
{
register nodeType *tree = t->tree;
if ( tree[a].code < 0 ) {
/* Internal node */
tree[a].weight = init_weight(t, tree[a].left) + init_weight(t, tree[a].right);
}
return tree[a].weight; /*****/
}
#ifdef OLD
/* Maps a symbol code into the corresponding index */
static short MapCodeToIndex( AHUFF *t, register short code )
{
register short index = t->symbolIndex[ code ];
assert( t->tree[index].code == code );
return index; /*****/
}
#endif /* OLD */
/* Currently we never rescale the tables */
/* const short MAXWEIGHT = 30000; Max weight count before table reset */
/* Constructor */
AHUFF *MTX_AHUFF_Create( MTX_MemHandler *mem, BITIO *bio, short rangeIn )
{
short i, limit, range;
long j;
const short ROOT = 1;
AHUFF *t = (AHUFF *)MTX_mem_malloc( mem, sizeof( AHUFF ) );
t->mem = mem;
t->bio = bio;
range = rangeIn;
t->range = rangeIn;
t->bitCount = MTX_AHUFF_BitsUsed( rangeIn - 1 );
t->bitCount2 = 0;
if ( rangeIn > 256 && rangeIn < 512 ) {
rangeIn -= 256;
t->bitCount2 = MTX_AHUFF_BitsUsed( rangeIn - 1 );
t->bitCount2++;
}
/*assert( range == range ); */
/* Max possible symbol == range - 1; */
t->maxSymbol = range - 1;
t->sym_count = 0;
t->countA = t->countB = 100;
/*t->symbolIndex = new short[ range ]; */
t->symbolIndex = ( short *)MTX_mem_malloc( mem, sizeof(short) * range );
/*t->tree = new nodeType [ 2*range ]; */
t->tree = (nodeType *)MTX_mem_malloc( mem, sizeof(nodeType) * 2*range );
/* Initialize the Huffman tree */
limit = (short)((short)2 * (short)range);
for ( i = 2; i < limit; i++ ) {
t->tree[i].up = (short)((short)i/(short)2);
t->tree[i].weight = (short)1;
}
for ( i = 1; i < range; i++ ) {
t->tree[i].left = (short)(2*i);
t->tree[i].right = (short)(2*i+1);
}
for ( i = 0; i < range; i++ ) {
t->tree[i].code = -1;
t->tree[range+i].code = i;
t->tree[range+i].left = -1;
t->tree[range+i].right = -1;
t->symbolIndex[i] = (short)(range+i);
}
init_weight( t, ROOT );
#if defined(DEBUG)
check_tree(t);
#endif
if ( t->bitCount2 != 0 ) {
/*assert( range == 256 + (1 << (t->bitCount2-1)) ); */
UpdateWeight(t, t->symbolIndex[256]);
UpdateWeight(t, t->symbolIndex[257]);
/*UpdateWeight(t->symbolIndex[258]); */
assert( 258 < range );
#if defined(DEBUG)
check_tree( t );
#endif
/* DUP2 */
for ( i = 0; i < 12; i++ ) {
UpdateWeight(t, t->symbolIndex[range-3]);
}
/* DUP4 */
for ( i = 0; i < 6; i++ ) {
UpdateWeight(t, t->symbolIndex[range-2]);
}
/* DUP6 range-1 */
} else {
for ( j = 0; j < 2; j++ ) {
for ( i = 0; i < range; i++ ) {
UpdateWeight(t, t->symbolIndex[i]);
}
}
}
t->countA = t->countB = 0;
return t;/*****/
}
/* Deconstructor */
void MTX_AHUFF_Destroy( AHUFF *t )
{
MTX_mem_free( t->mem, t->symbolIndex );
MTX_mem_free( t->mem, t->tree );
MTX_mem_free( t->mem, t );
}
/* Writes the symbol to the file using adaptive Huffman encoding */
/* Jusat like but with writeToFile == false assumed */
long MTX_AHUFF_WriteSymbolCost( AHUFF *t, short symbol )
{
register nodeType *tree = t->tree;
register short a;
register int sp = 0;
const short ROOT = 1;
/* The array maps the symbol code into an index */
a = t->symbolIndex[symbol];
assert( t->tree[a].code == symbol );
do {
sp++;
a = tree[a].up;
} while (a != ROOT);
return (long)sp << 16; /******/
}
/* Writes the symbol to the file using adaptive Huffman encoding */
void MTX_AHUFF_WriteSymbol( AHUFF *t, short symbol )
{
register nodeType *tree = t->tree;
register short a, aa;
register int sp = 0;
char stackArr[50]; /* use this to reverse the bits */
register char *stack = stackArr;
register BITIO *bio = t->bio;
register short up;
const short ROOT = 1;
/* The array maps the symbol code into an index */
a = t->symbolIndex[symbol];
assert( t->tree[a].code == symbol );
aa = a;
do {
up = tree[a].up;
stack[sp++] = (char)(tree[up].right == a);
a = up;
} while (a != ROOT);
assert( sp < 50 );
do {
MTX_BITIO_output_bit( bio, stack[--sp] );
} while (sp);
UpdateWeight( t, aa );
}
/* Reads the symbol from the file */
short MTX_AHUFF_ReadSymbol( AHUFF *t )
{
const short ROOT = 1;
register nodeType *tree = t->tree;
register short a = ROOT, symbol;
register BITIO *bio = t->bio;
do {
a = (short)(MTX_BITIO_input_bit( bio ) ? tree[a].right : tree[a].left);
symbol = tree[a].code;
} while ( symbol < 0 );
UpdateWeight( t, a );
return symbol; /******/
}
/****************************************************************************************/
/* LZCOMP.H */
/****************************************************************************************/
#include "MTXMEM.H"
#ifdef __cplusplus
extern "C" {
#endif
/* This class was added to improve the compression performance */
/* for subsetted large fonts. */
typedef struct {
/* private */
/* State information for SaveBytes */
unsigned char escape, count, state;
MTX_MemHandler *mem;
/* No public fields! */
} RUNLENGTHCOMP;
/* public RUNLENGTHCOMP interface */
#ifdef COMPRESS_ON
/* Invoke this method to run length compress a file in memory */
unsigned char *MTX_RUNLENGTHCOMP_PackData( RUNLENGTHCOMP *t, unsigned char *data, long lengthIn, long *lengthOut );
#endif
#ifdef DECOMPRESS_ON
/* Use this method to decompress the data transparently */
/* as it goes to the output memory. */
void MTX_RUNLENGTHCOMP_SaveBytes( RUNLENGTHCOMP *t, unsigned char value, unsigned char * *dataOut, long *dataOutSize, long *index );
#endif
RUNLENGTHCOMP *MTX_RUNLENGTHCOMP_Create( MTX_MemHandler *mem );
void MTX_RUNLENGTHCOMP_Destroy( RUNLENGTHCOMP *t );
/* This structure is only for private use by LZCOMP */
typedef struct hn {
long index;
struct hn *next;
} hasnNode;
typedef struct {
/* private */
unsigned char *ptr1;
char ptr1_IsSizeLimited;
char filler1, filer2, filler3;
/* New August 1, 1996 */
RUNLENGTHCOMP *rlComp;
short usingRunLength;
long length1, out_len;
long maxIndex;
long num_DistRanges;
long dist_max;
long DUP2, DUP4, DUP6, NUM_SYMS;
long maxCopyDistance;
AHUFF *dist_ecoder;
AHUFF *len_ecoder;
AHUFF *sym_ecoder;
BITIO *bitIn, *bitOut;
#ifdef COMPRESS_ON
hasnNode **hashTable;
hasnNode *freeList;
long nextFreeNodeIndex;
hasnNode *nodeBlock;
#endif /* COMPRESS_ON */
MTX_MemHandler *mem;
/* public */
/* No public fields! */
} LZCOMP;
/* public LZCOMP interface */
#ifdef COMPRESS_ON
/* Call this method to compress a memory area */
unsigned char *MTX_LZCOMP_PackMemory( LZCOMP *t, void *dataIn, long size_in, long *sizeOut);
#endif
#ifdef DECOMPRESS_ON
/* Call this method to un-compress memory */
unsigned char *MTX_LZCOMP_UnPackMemory( LZCOMP *t, void *dataIn, long dataInSize, long *sizeOut, unsigned char version );
#else
#ifdef DEBUG
unsigned char *MTX_LZCOMP_UnPackMemory( LZCOMP *t, void *dataIn, long dataInSize, long *sizeOut, unsigned char version );
#endif
#endif
/* Constructors */
LZCOMP *MTX_LZCOMP_Create1( MTX_MemHandler *mem );
LZCOMP *MTX_LZCOMP_Create2( MTX_MemHandler *mem, long maxCopyDistance );
/* Destructor */
void MTX_LZCOMP_Destroy( LZCOMP *t );
#ifdef __cplusplus
}
#endif
/****************************************************************************************/
/* LZCOMP.C */
/****************************************************************************************/
#ifdef _WINDOWS
#include <windows.h>
#endif
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <string.h>
#include <ctype.h>
#include "BITIO.H"
#include "AHUFF.H"
#include "LZCOMP.H"
#include "ERRCODES.H"
#define sizeof_hasnNodePtr 4
/*const long num_DistRanges = 6; */
/*const long dist_max = ( dist_min + (1L << (dist_width*num_DistRanges)) - 1 ); */
/*const int DUP2 = 256 + (1L << len_width) * num_DistRanges; */
/*const int DUP4 = DUP2 + 1; */
/*const int DUP6 = DUP4 + 1; */
/*const int NUM_SYMS = DUP6 + 1; */
const long max_2Byte_Dist = 512;
/* Sets the maximum number of distance ranges used, based on the <length> parameter */
static void SetDistRange( LZCOMP *t, long length )
{
const long len_min = 2;
const long len_min3 = 3;
const long len_width = 3;
const long bit_Range = 3 - 1; /* == len_width - 1 */
const long dist_min = 1;
const long dist_width = 3;
t->num_DistRanges = 1;
t->dist_max = ( dist_min + (1L << (dist_width*t->num_DistRanges)) - 1 );
while ( t->dist_max < length ) {
t->num_DistRanges++;
t->dist_max = ( dist_min + (1L << (dist_width*t->num_DistRanges)) - 1 );
}
t->DUP2 = 256 + (1L << len_width) * t->num_DistRanges;
t->DUP4 = t->DUP2 + 1;
t->DUP6 = t->DUP4 + 1;
t->NUM_SYMS = t->DUP6 + 1;
}
#ifdef COMPRESS_ON
/* Returns the number of distance ranges necessary to encode the <distance> */
#ifndef SLOWER
#define GetNumberofDistRanges( distance ) ((MTX_AHUFF_BitsUsed( (distance) - dist_min ) + dist_width-1) / dist_width)
#else
static long GetNumberofDistRanges( register long distance )
{
register long distRanges, bitsNeeded;
const long len_min = 2;
const long len_min3 = 3;
const long len_width = 3;
const long bit_Range = 3 - 1; /* == len_width - 1 */
const long dist_min = 1;
const long dist_width = 3;
assert( distance >=dist_min );
bitsNeeded = MTX_AHUFF_BitsUsed( distance - dist_min );
/* 1,2,3.. */
#ifdef OLD
distRanges = bitsNeeded / dist_width;
if ( distRanges * dist_width < bitsNeeded ) distRanges++;
#endif /* OLD */
distRanges = (bitsNeeded + dist_width-1) / dist_width; assert( distRanges * dist_width >=bitsNeeded );
assert( (distRanges-1) * dist_width < bitsNeeded );
return distRanges; /******/
}
#endif /* SLOWER */
#endif /*COMPRESS_ON */
#ifdef COMPRESS_ON
/* Encodes the length <value> and the number of distance ranges used for this distance */
static void EncodeLength( LZCOMP *t, long value, long distance, long numDistRanges )
{
long i, bitsUsed, symbol;
unsigned long mask = 1;
const long len_min = 2;
const long len_min3 = 3;
const long len_width = 3;
const long bit_Range = 3 - 1; /* == len_width - 1 */
const long dist_min = 1;
const long dist_width = 3;
if ( distance >=max_2Byte_Dist ) {
value -= len_min3;
} else {
value -= len_min;
}
assert( value >=0 );
assert( numDistRanges >=1 && numDistRanges <= t->num_DistRanges );
bitsUsed = MTX_AHUFF_BitsUsed( value );
assert( bit_Range == len_width - 1 );
/* for ( i = 0; i < bitsUsed; ) i += bit_Range; */
/* i = (bitsUsed + bit_Range-1)/bit_Range * bit_Range; */
/* for ( i = bit_Range; i < bitsUsed; ) i += bit_Range; */
for ( i = bit_Range; bitsUsed > i; ) i += bit_Range; /* fastest option ! */
assert ( bitsUsed <= i );
mask = 1L << (i-1);
symbol = bitsUsed > bit_Range ? 2 : 0; /* set to 2 so we eliminate the first symbol <= 1 below */
/* repeat bit_Range times, hard-wire so that we do not have to loop */
assert( bit_Range == 2 );
/* 1 */
if ( value & mask ) symbol |= 1; mask >>=1;
/* 2 */
symbol <<= 1;
if ( value & mask ) symbol |= 1; mask >>=1;
MTX_AHUFF_WriteSymbol( t->sym_ecoder, (short)(256 + symbol + (numDistRanges - 1) * (1L << len_width)) );
for ( i = bitsUsed - bit_Range; i >=1; ) {
symbol = i > bit_Range ? 2 : 0; /* set to 2 so we eliminate the first symbol <= 1 below */
/* repeat bit_Range times, hard-wire so that we do not have to loop */
assert( bit_Range == 2 );
/* 1 */
if ( value & mask ) symbol |= 1; mask >>=1;
/* 2 */
symbol <<= 1;
if ( value & mask ) symbol |= 1; mask >>=1;
i -= bit_Range;
MTX_AHUFF_WriteSymbol( t->len_ecoder, (short)symbol );
}
}
/* Same as EncodeLength, except it only computes the cost */
static long EncodeLengthCost( LZCOMP *t, long value, long distance, long numDistRanges )
{
long i, bitsUsed, symbol, count;
unsigned long mask = 1;
const long len_min = 2;
const long len_min3 = 3;
const long len_width = 3;
const long bit_Range = 3 - 1; /* == len_width - 1 */
const long dist_min = 1;
const long dist_width = 3;
if ( distance >=max_2Byte_Dist ) {
value -= len_min3;
} else {
value -= len_min;
}
assert( value >=0 );
assert( numDistRanges >=1 && numDistRanges <= t->num_DistRanges );
bitsUsed = MTX_AHUFF_BitsUsed( value );
assert( bit_Range == len_width - 1 );
/* for ( i = 0; i < bitsUsed; ) i += bit_Range; */
/* i = (bitsUsed + bit_Range-1)/bit_Range * bit_Range; */
/* for ( i = bit_Range; i < bitsUsed; ) i += bit_Range; */
for ( i = bit_Range; bitsUsed > i; ) i += bit_Range; /* fastest option ! */
assert ( bitsUsed <= i );
mask = 1L << (i-1);
symbol = bitsUsed > bit_Range ? 2 : 0; /* set to 2 so we eliminate the first symbol <= 1 below */
/* repeat bit_Range times, hard-wire so that we do not have to loop */
assert( bit_Range == 2 );
/* 1 */
if ( value & mask ) symbol |= 1; mask >>=1;
/* 2 */
symbol <<= 1;
if ( value & mask ) symbol |= 1; mask >>=1;
count = MTX_AHUFF_WriteSymbolCost( t->sym_ecoder, (short)(256 + symbol + (numDistRanges - 1) * (1L << len_width)) );
for ( i = bitsUsed - bit_Range; i >=1; ) {
symbol = i > bit_Range ? 2 : 0; /* set to 2 so we eliminate the first symbol <= 1 below */
/* repeat bit_Range times, hard-wire so that we do not have to loop */
assert( bit_Range == 2 );
/* 1 */
if ( value & mask ) symbol |= 1; mask >>=1;
/* 2 */
symbol <<= 1;
if ( value & mask ) symbol |= 1; mask >>=1;
i -= bit_Range;
count += MTX_AHUFF_WriteSymbolCost( t->len_ecoder, (short)symbol );
}
return count; /*****/
}
#endif /* COMPRESS_ON */
#ifdef DECOMPRESS_ON
/* Decodes the length, and also returns the number of distance ranges used for the distance */
static long DecodeLength( LZCOMP *t, int symbol, long *numDistRanges )
{
unsigned long mask;
long done, bits, firstTime = symbol >=0, value = 0;
const long len_min = 2;
const long len_min3 = 3;
const long len_width = 3;
const long bit_Range = 3 - 1; /* == len_width - 1 */
const long dist_min = 1;
const long dist_width = 3;
mask = 1L << bit_Range;
do {
if ( firstTime ) {
bits = symbol - 256;
firstTime = false;
assert( bits >=0 );
/*assert( bits < 8 ); */
*numDistRanges = (bits / (1L << len_width) ) + 1;
assert( *numDistRanges >=1 && *numDistRanges <= t->num_DistRanges );
bits = bits % (1L << len_width);
} else {
bits = MTX_AHUFF_ReadSymbol(t->len_ecoder);
}
done = (bits & mask) == 0;
bits &= ~mask;
value <<= bit_Range;
value |= bits;
} while ( !done );
value += len_min;
return value; /******/
}
#endif /* DECOMPRESS_ON */
#ifdef COMPRESS_ON
/* Encodes the distance */
static void EncodeDistance2( LZCOMP *t, long value, long distRanges )
{
register long i;
const long len_min = 2;
const long len_min3 = 3;
const long len_width = 3;
const long bit_Range = 3 - 1; /* == len_width - 1 */
const long dist_min = 1;
const long dist_width = 3;
const long mask = (1L << dist_width) - 1;
value -= dist_min;
assert( value >=0 );
assert( distRanges >=1 && distRanges <= t->num_DistRanges );
for ( i = (distRanges-1)*dist_width; i >=0; i -= dist_width ) {
MTX_AHUFF_WriteSymbol( t->dist_ecoder, (short)((value >> i) & mask) );
}
}
/* Same as EncodeDistance2, except it only computes the cost */
static long EncodeDistance2Cost( LZCOMP *t, long value, long distRanges )
{
register long i, count = 0;
const long len_min = 2;
const long len_min3 = 3;
const long len_width = 3;
const long bit_Range = 3 - 1; /* == len_width - 1 */
const long dist_min = 1;
const long dist_width = 3;
const long mask = (1L << dist_width) - 1;
value -= dist_min;
assert( value >=0 );
assert( distRanges >=1 && distRanges <= t->num_DistRanges );
for ( i = (distRanges-1)*dist_width; i >=0; i -= dist_width ) {
count += MTX_AHUFF_WriteSymbolCost( t->dist_ecoder, (short)((value >> i) & mask) );
}
return count;
}
#endif /*COMPRESS_ON */
#ifdef COMPRESS_ON
/* Frees all nodes from the hash */
static void FreeAllHashNodes(LZCOMP *t)
{
register hasnNode *nextNodeBlock;
const short hNodeAllocSize = 4095;
while ( t->nodeBlock != NULL ) {
nextNodeBlock = t->nodeBlock[hNodeAllocSize].next;
MTX_mem_free( t->mem, t->nodeBlock );
t->nodeBlock = nextNodeBlock;
}
}
/* Returns a new hash node */
static hasnNode *GetNewHashNode(LZCOMP *t)
{
register hasnNode *hNode;
const short hNodeAllocSize = 4095;
/* Try recycling first */
if ( t->freeList != NULL ) {
hNode = t->freeList;
t->freeList = hNode->next;
} else {
if ( t->nextFreeNodeIndex >=hNodeAllocSize ) {
register hasnNode *oldNodeBlock;
oldNodeBlock = t->nodeBlock;
t->nodeBlock = (hasnNode *)MTX_mem_malloc( t->mem, sizeof(hasnNode) * (hNodeAllocSize+1) );
assert( t->nodeBlock != NULL );
t->nodeBlock[hNodeAllocSize].next = oldNodeBlock;
t->nextFreeNodeIndex = 0;
}
hNode = &t->nodeBlock[t->nextFreeNodeIndex++];
}
return hNode; /******/
}
/* Updates our model, for the byte pointed to by <index> */
static void UpdateModel( LZCOMP *t, long index )
{
hasnNode *hNode;
unsigned char c = t->ptr1[ index ];
long pos;
unsigned short prev_c;
if ( index > 0 ) {
hNode = GetNewHashNode( t );
prev_c = t->ptr1[ index -1 ];
pos = (prev_c << 8) | c;
hNode->index = index-1;
hNode->next = t->hashTable[ pos ];
t->hashTable[ pos ] = hNode;
}
}
#else
static void UpdateModel( LZCOMP *t, long index )
{
;
}
#endif /* COMPRESS_ON */
#ifdef DECOMPRESS_ON
/* Decodes the distance */
static long DecodeDistance2( LZCOMP *t, long distRanges )
{
long i, bits, value = 0;
const long len_min = 2;
const long len_min3 = 3;
const long len_width = 3;
const long bit_Range = 3 - 1; /* == len_width - 1 */
const long dist_min = 1;
const long dist_width = 3;
/* for ( i = 0; i < distRanges; i++ ) */
for ( i = distRanges; i > 0; i-- ) {
bits = MTX_AHUFF_ReadSymbol(t->dist_ecoder);
value <<= dist_width;
value |= bits;
}
value += dist_min;
return value; /******/
}
#endif /* DECOMPRESS_ON */
/*
* Initializes our hashTable and also pre-loads some data so that
* there is a chance that bytes in the beginning of the file
* might use copy items.
* if compress is true then it initializes for compression, otherwise
* it initializes only for decompression.
*/
static void InitializeModel( LZCOMP *t, int compress )
{
long i, j, k;
const long preLoadSize = 2*32*96 + 4*256;
#ifdef COMPRESS_ON
if ( compress ) {
unsigned long hashSize;
/*t->hashTable = new hasnNode * [ 0x10000 ]; assert( t->hashTable != NULL );
t->hashTable = (hasnNode **)MTX_mem_malloc( t->mem, sizeof(hasnNode *) * 0x10000 ); */
hashSize = (unsigned long)sizeof_hasnNodePtr * 0x10000;
t->hashTable = (hasnNode **)MTX_mem_malloc( t->mem, hashSize );
for ( i = 0; i < 0x10000; i++ ) {
t->hashTable[i] = NULL;
}
}
#endif
i = 0;
assert( preLoadSize > 0 );
if ( compress ) {
for ( k = 0; k < 32; k++ ) {
for ( j = 0; j < 96; j++ ) {
t->ptr1[i] = (unsigned char)k; UpdateModel(t,i++);
t->ptr1[i] = (unsigned char)j; UpdateModel(t,i++);
}
}
j = 0;
while ( i < preLoadSize && j < 256 ) {
t->ptr1[i] = (unsigned char)j; UpdateModel(t,i++);
t->ptr1[i] = (unsigned char)j; UpdateModel(t,i++);
t->ptr1[i] = (unsigned char)j; UpdateModel(t,i++);
t->ptr1[i] = (unsigned char)j; UpdateModel(t,i++);
j++;
}
} else {
for ( k = 0; k < 32; k++ ) {
for ( j = 0; j < 96; j++ ) {
t->ptr1[i++] = (unsigned char)k;
t->ptr1[i++] = (unsigned char)j;
}
}
j = 0;
while ( i < preLoadSize && j < 256 ) {
t->ptr1[i++] = (unsigned char)j;
t->ptr1[i++] = (unsigned char)j;
t->ptr1[i++] = (unsigned char)j;
t->ptr1[i++] = (unsigned char)j;
j++;
}
}
assert( j == 256 );
assert( i == preLoadSize );
}
#ifdef COMPRESS_ON
/* Finds the best copy item match */
static long Findmatch( register LZCOMP *t, long index, long *bestDist, long *gainOut, long *costPerByte )
{
long length, bestLength = 0, bestGain = 0;
long maxLen, i, distance, bestCopyCost = 0, bestDistance = 0;
long copyCost, literalCost, distRanges, gain;
register hasnNode *hNode, *prevNode = NULL;
long hNodeCount = 0;
long maxIndexMinusIndex = t->maxIndex - index;
unsigned char *ptr2 = &t->ptr1[index];
#define MAX_COST_CACHE_LENGTH 32
long literalCostCache[MAX_COST_CACHE_LENGTH+1], maxComputedLength = 0;
unsigned short pos;
const long len_min = 2;
const long len_min3 = 3;
const long len_width = 3;
const long bit_Range = 3 - 1; /* == len_width - 1 */
const long dist_min = 1;
const long dist_width = 3;
assert( index >=0 );
literalCostCache[0] = 0;
if ( 1 < maxIndexMinusIndex ) {
pos = ptr2[0];
pos <<= 8;
assert( &ptr2[1] < &t->ptr1[t->maxIndex] );
pos |= ptr2[1];
/* *costPerByte = 0xff0000; */
for ( hNode = t->hashTable[ pos ]; hNode != NULL; prevNode = hNode, hNode = hNode->next ) {
i = hNode->index;
distance = index - i; /* to head */
/* hNodeCount added March 14, 1996 */
if ( ++hNodeCount > 256 || distance > t->maxCopyDistance ) { /* Added Feb 26, 1996 */
if ( t->hashTable[ pos ] == hNode ) {
assert( prevNode == NULL );
t->hashTable[ pos ] = NULL;
} else {
assert( prevNode != NULL );
assert( prevNode->next == hNode );
prevNode->next = NULL;
}
while ( hNode != NULL ) {
hasnNode *oldHead = t->freeList;
t->freeList = hNode;
hNode = hNode->next;
t->freeList->next = oldHead;
}
break; /******/
}
maxLen = index - i;
if ( maxIndexMinusIndex < maxLen ) maxLen = maxIndexMinusIndex;
if ( maxLen < len_min ) continue; /******/
assert( t->ptr1[i+0] == ptr2[0] );
assert( t->ptr1[i+1] == ptr2[1] );
/* We already have two matching bytes, so start at two instead of zero !! */
/* for ( length = 0; i < index && length+index < t->maxIndex; i++ ) */
i += 2;
assert( &ptr2[maxLen-1] < &t->ptr1[t->maxIndex] );
for ( length = 2; length < maxLen && t->ptr1[i] == ptr2[length]; i++ ) {
length++;
}
assert( length >=2 || index + length >=t->maxIndex );
if ( length < len_min ) continue; /******/
distance = distance - length + 1; /* tail */
assert( distance > 0 );
if ( distance > t->dist_max ) continue; /******/
if ( length == 2 && distance >=max_2Byte_Dist ) continue; /******/
if ( length <= bestLength && distance > bestDistance ) {
if ( length <= bestLength-2 ) continue; /***** SPEED optimization *****/
if ( distance > (bestDistance << dist_width) ) {
if ( length < bestLength ) continue; /***** SPEED optimization *****/
if ( distance > (bestDistance << (dist_width+1)) ) continue; /***** SPEED optimization *****/
}
}
if ( length > maxComputedLength ) {
long limit = length;
if ( limit > MAX_COST_CACHE_LENGTH ) limit = MAX_COST_CACHE_LENGTH;
for ( i = maxComputedLength; i < limit; i++ ) {
literalCostCache[i+1] = literalCostCache[i] + MTX_AHUFF_WriteSymbolCost( t->sym_ecoder, ptr2[i] );
}
maxComputedLength = limit;
if ( length > MAX_COST_CACHE_LENGTH ) {
assert( maxComputedLength == MAX_COST_CACHE_LENGTH );
literalCost = literalCostCache[MAX_COST_CACHE_LENGTH];
/* just approximate */
literalCost += literalCost/MAX_COST_CACHE_LENGTH * (length-MAX_COST_CACHE_LENGTH);
} else {
literalCost = literalCostCache[length];
}
} else {
literalCost = literalCostCache[length];
}
if ( literalCost > bestGain ) {
distRanges = GetNumberofDistRanges( distance );
copyCost = EncodeLengthCost( t, length, distance, distRanges );
if ( literalCost - copyCost - (distRanges << 16) > bestGain ) {
/* The if statement above conservatively assumes only one bit per range for distBitCount */
copyCost += EncodeDistance2Cost( t, distance, distRanges );
gain = literalCost - copyCost;
if ( gain > bestGain ) {
bestGain = gain;
assert( hNode->index < index );
bestLength = length;
bestDistance = distance;
bestCopyCost = copyCost;
}
}
}
}
}
*costPerByte = bestLength ? bestCopyCost / bestLength : 0; /* To avoid divide by zero */
*bestDist = bestDistance;
*gainOut = bestGain;
return bestLength; /******/
}
#endif /*COMPRESS_ON */
#ifdef COMPRESS_ON
/* Makes a decision on whether to use a copy item, and then if it decides */
/* to use a copy item it decides on an optimal length & distance for the copy. */
static long MakeCopyDecision( LZCOMP *t, long index, long *bestDist )
{
long dist1, dist2, dist3;
long len1, len2, len3;
long gain1, gain2, gain3;
long costPerByte1, costPerByte2, costPerByte3;
long lenBitCount, distBitCount;
long here, symbolCost, dup2Cost;
const long len_min = 2;
const long len_min3 = 3;
const long len_width = 3;
const long bit_Range = 3 - 1; /* == len_width - 1 */
const long dist_min = 1;
const long dist_width = 3;
here = index;
len1 = Findmatch( t, index, &dist1, &gain1, &costPerByte1 );
UpdateModel(t, index++ );
if ( gain1 > 0 ) {
len2 = Findmatch( t, index, &dist2, &gain2, &costPerByte2 );
symbolCost = MTX_AHUFF_WriteSymbolCost( t->sym_ecoder, t->ptr1[here]);
if ( gain2 >=gain1 && costPerByte1 > (costPerByte2 * len2 + symbolCost ) / (len2+1) ) {
len1 = 0;
} else if ( len1 > 3 ) {
/* Explore cutting back on len1 by one unit */
len2 = Findmatch( t, here + len1, &dist2, &gain2, &costPerByte2 );
if ( len2 >=2 ) {
len3 = Findmatch( t, here + len1-1, &dist3, &gain3, &costPerByte3 );
if ( len3 > len2 && costPerByte3 < costPerByte2 ) {
long cost1A, cost1B, distRanges;
distRanges = GetNumberofDistRanges( dist1 + 1 );
lenBitCount = EncodeLengthCost( t, len1-1, dist1+1, distRanges );
distBitCount = EncodeDistance2Cost( t, dist1+1, distRanges );
cost1B = lenBitCount + distBitCount;
cost1B += costPerByte3 * len3;
cost1A = costPerByte1 * len1;
cost1A += costPerByte2 * len2;
if ( (cost1A / (len1+len2)) > (cost1B/ (len1-1+len3)) ) {
len1--;
dist1++;
}
}
}
}
if ( len1 == 2 ) {
if ( here >=2 && t->ptr1[here] == t->ptr1[here-2] ) {
dup2Cost = MTX_AHUFF_WriteSymbolCost( t->sym_ecoder, (short)t->DUP2 );
if ( costPerByte1 * 2 > dup2Cost + MTX_AHUFF_WriteSymbolCost( t->sym_ecoder, t->ptr1[here+1] ) ) {
len1 = 0;
}
} else if ( here >=1 && here+1 < t->maxIndex && t->ptr1[here+1] == t->ptr1[here-1] ) {
dup2Cost = MTX_AHUFF_WriteSymbolCost( t->sym_ecoder, (short)t->DUP2 );
if ( costPerByte1 * 2 > symbolCost + dup2Cost ) {
len1 = 0;
}
}
}
}
*bestDist = dist1;
return len1; /******/
}
#endif /* COMPRESS_ON */
#ifdef COMPRESS_ON
/* This method does the compression work */
static void Encode( LZCOMP *t )
{
register long i, j, limit;
long here, len, dist;
long distRanges;
const long len_min = 2;
const long len_min3 = 3;
const long len_width = 3;
const long bit_Range = 3 - 1; /* == len_width - 1 */
const long dist_min = 1;
const long dist_width = 3;
const long preLoadSize = 2*32*96 + 4*256;
assert( (t->length1 & 0xff000000) == 0 );
t->maxIndex = t->length1+preLoadSize;
InitializeModel( t, true );
MTX_BITIO_WriteValue( t->bitOut, t->length1, 24 );
limit = t->length1+preLoadSize;
for ( i = preLoadSize; i < limit; ) {
here = i;
len = MakeCopyDecision( t, i++, &dist );
if ( len > 0 ) {
assert( dist > 0 );
distRanges = GetNumberofDistRanges( dist );
EncodeLength( t, len, dist, distRanges );
EncodeDistance2( t, dist, distRanges );
/*for ( j = 0; j < len; j++ ) { */
/* assert( t->ptr1[here+j] == t->ptr1[here-dist-len+1 + j] ); */
/*} */
for ( j = 1; j < len; j++ ) {
UpdateModel(t, i++ );
}
} else {
unsigned char c = t->ptr1[here];
if ( here >=2 && c == t->ptr1[here-2] ) {
MTX_AHUFF_WriteSymbol( t->sym_ecoder, (short)t->DUP2 );
} else {
if ( here >=4 && c == t->ptr1[here-4] ) {
MTX_AHUFF_WriteSymbol( t->sym_ecoder, (short)t->DUP4 );
} else {
if ( here >=6 && c == t->ptr1[here-6] ) {
MTX_AHUFF_WriteSymbol( t->sym_ecoder, (short)t->DUP6 );
} else {
MTX_AHUFF_WriteSymbol( t->sym_ecoder, t->ptr1[here] ); /* 0-bit + byte */
}
}
}
}
}
if ( i != t->maxIndex ) longjmp( t->mem->env, ERR_LZCOMP_Encode_bounds );
}
#endif /* COMPRESS_ON */
#ifdef DECOMPRESS_ON
/* This method does the de-compression work */
/* There is potential to save some memory in the future by uniting */
/* dataOut and ptr1 only when the run length encoding is not used. */
static unsigned char *Decode( register LZCOMP *t, long *size )
{
register int symbol;
long j, length, distance, start, pos = 0;
long numDistRanges;
register unsigned char *ptr1;
register unsigned char value;
register usingRunLength = t->usingRunLength;
long dataOutSize, index = 0;
unsigned char *dataOut;
const long preLoadSize = 2*32*96 + 4*256;
dataOut = (unsigned char *)MTX_mem_malloc( t->mem, dataOutSize = t->out_len );
InitializeModel( t, false );
if ( !t->ptr1_IsSizeLimited ) {
ptr1 = (unsigned char __huge *)t->ptr1 + preLoadSize;
for ( pos = 0; pos < t->out_len;) {
symbol = MTX_AHUFF_ReadSymbol(t->sym_ecoder);
if ( symbol < 256 ) {
/* Literal item */
value = (unsigned char)symbol;
} else if ( symbol == t->DUP2 ) {
/* One byte copy item */
value = ptr1[ pos - 2 ];
} else if ( symbol == t->DUP4 ) {
/* One byte copy item */
value = ptr1[ pos - 4 ];
} else if ( symbol == t->DUP6 ) {
/* One byte copy item */
value = ptr1[ pos - 6 ];
} else {
/* Copy item */
length = DecodeLength( t, symbol, &numDistRanges );
distance = DecodeDistance2( t, numDistRanges );
if ( distance >=max_2Byte_Dist ) length++;
start = pos - distance - length + 1;
for ( j = 0; j < length; j++ ) {
value = ptr1[ start + j ];
ptr1[ pos++ ] = value;
if ( usingRunLength ) {
MTX_RUNLENGTHCOMP_SaveBytes( t->rlComp, value, &dataOut, &dataOutSize, &index );
} else {
assert( index <= dataOutSize );
if ( index >=dataOutSize ) {
dataOutSize += dataOutSize>>1; /* Allocate in exponentially increasing steps */
dataOut = (unsigned char *)MTX_mem_realloc( t->mem, dataOut, dataOutSize );
}
dataOut[ index++ ] = value;
/*fputc( value, fpOut ); */
}
}
continue; /****** Do not fall through *****/
}
ptr1[ pos++ ] = value;
if ( usingRunLength ) {
MTX_RUNLENGTHCOMP_SaveBytes( t->rlComp, value, &dataOut, &dataOutSize, &index );
} else {
assert( index <= dataOutSize );
if ( index >=dataOutSize ) {
dataOutSize += dataOutSize>>1; /* Allocate in exponentially increasing steps */
dataOut = (unsigned char *)MTX_mem_realloc( t->mem, dataOut, dataOutSize );
}
dataOut[ index++ ] = value;
/*fputc( value, fpOut ); */
}
}
} else {
long src, dst = preLoadSize; /* source and destination indeces */
ptr1 = t->ptr1;
assert( t->maxCopyDistance > preLoadSize );
for ( pos = 0; pos < t->out_len;) {
symbol = MTX_AHUFF_ReadSymbol(t->sym_ecoder);
if ( symbol < 256 ) {
/* Literal item */
value = (unsigned char)symbol;
} else if ( symbol == t->DUP2 ) {
/* One byte copy item */
src = dst - 2;
if ( src < 0 ) src = src + t->maxCopyDistance;
value = ptr1[ src ];
} else if ( symbol == t->DUP4 ) {
/* One byte copy item */
src = dst - 4;
if ( src < 0 ) src = src + t->maxCopyDistance;
value = ptr1[ src ];
} else if ( symbol == t->DUP6 ) {
/* One byte copy item */
src = dst - 6;
if ( src < 0 ) src = src + t->maxCopyDistance;
value = ptr1[ src ];
} else {
/* Copy item */
length = DecodeLength( t, symbol, &numDistRanges );
distance = DecodeDistance2( t, numDistRanges );
if ( distance >=max_2Byte_Dist ) length++;
start = dst - distance - length + 1;
assert( distance + length - 1 <= t->maxCopyDistance );
for ( j = 0; j < length; j++ ) {
src = start + j;
if ( src < 0 ) src = src + t->maxCopyDistance;
value = ptr1[ src ];
ptr1[ dst ] = value;
dst = (dst + 1) % t->maxCopyDistance;
pos++;
if ( usingRunLength ) {
MTX_RUNLENGTHCOMP_SaveBytes( t->rlComp, value, &dataOut, &dataOutSize, &index );
} else {
assert( index <= dataOutSize );
if ( index >=dataOutSize ) {
dataOutSize += dataOutSize>>1; /* Allocate in exponentially increasing steps */
dataOut = (unsigned char *)MTX_mem_realloc( t->mem, dataOut, dataOutSize );
}
dataOut[ index++ ] = value;
/*fputc( value, fpOut ); */
}
}
continue; /****** Do not fall through *****/
}
ptr1[ dst ] = value;
dst = (dst + 1) % t->maxCopyDistance;
pos++;
if ( usingRunLength ) {
MTX_RUNLENGTHCOMP_SaveBytes( t->rlComp, value, &dataOut, &dataOutSize, &index );
} else {
assert( index <= dataOutSize );
if ( index >=dataOutSize ) {
dataOutSize += dataOutSize>>1; /* Allocate in exponentially increasing steps */
dataOut = (unsigned char *)MTX_mem_realloc( t->mem, dataOut, dataOutSize );
}
dataOut[ index++ ] = value;
/*fputc( value, fpOut ); */
}
}
}
assert( pos == t->out_len );
assert( t->usingRunLength || index == t->out_len );
if ( pos != t->out_len ) longjmp( t->mem->env, ERR_LZCOMP_Decode_bounds );
*size = index;
assert( dataOutSize >=*size );
if ( t->usingRunLength ) {
dataOut = (unsigned char *)MTX_mem_realloc( t->mem, dataOut, *size ); /* Free up some memory if possible */
}
return dataOut; /******/
}
#endif /*DECOMPRESS_ON */
#ifdef COMPRESS_ON
void * memcpyHuge( void * object2, void * object1, unsigned long size )
{
unsigned long i;
void * object2Ptr;
object2Ptr = object2;
for (i=0; i<size; i++)
*(((char __huge *)object2)++) = *(((char __huge *)object1)++);
return object2Ptr;
}
/* Call this method to compress a memory area */
unsigned char *MTX_LZCOMP_PackMemory( register LZCOMP *t, void *dataIn, long size_in, long *sizeOut )
{
long lengthOut;
unsigned char *bin;
long binSize;
const long len_min = 2;
const long len_min3 = 3;
const long len_width = 3;
const long bit_Range = 3 - 1; /* == len_width - 1 */
const long dist_min = 1;
const long dist_width = 3;
const long preLoadSize = 2*32*96 + 4*256;
t->length1 = size_in;
/* DeAllocate Memory */
if ( t->ptr1 != NULL ) {
MTX_mem_free( t->mem, t->ptr1 );
}
t->ptr1 = NULL;
/* Allocate Memory */
t->ptr1 = (unsigned char *)MTX_mem_malloc( t->mem, sizeof(unsigned char) * (t->length1 + preLoadSize) );
memcpyHuge( (unsigned char __huge *)t->ptr1+preLoadSize, dataIn, t->length1 );
t->usingRunLength = false;
{
long i, packedLength = 0;
unsigned char *out, *d;
t->rlComp = MTX_RUNLENGTHCOMP_Create( t->mem );
out = MTX_RUNLENGTHCOMP_PackData( t->rlComp, (unsigned char __huge *)t->ptr1+preLoadSize, t->length1, &packedLength );
/* Only use run-length encoding if there is a clear benefit */
if ( packedLength < t->length1 * 3 / 4 ) {
t->usingRunLength = true;
t->length1 = packedLength;
MTX_mem_free( t->mem, t->ptr1 );
t->ptr1 = (unsigned char *)MTX_mem_malloc( t->mem, sizeof(unsigned char) * (t->length1 + preLoadSize) );
d = (unsigned char __huge *)t->ptr1+preLoadSize;
for ( i = 0; i < t->length1; i++ ) {
*d++ = out[i];
}
}
MTX_mem_free( t->mem, out );
MTX_RUNLENGTHCOMP_Destroy( t->rlComp ); t->rlComp = NULL;
}
binSize = 1024;
bin = (unsigned char *)MTX_mem_malloc( t->mem, binSize );
t->bitOut = MTX_BITIO_Create( t->mem, bin, binSize, 'w'); assert( t->bitOut != NULL );
MTX_BITIO_output_bit(t->bitOut, t->usingRunLength);
t->dist_ecoder = MTX_AHUFF_Create( t->mem, t->bitOut, (short)(1L << dist_width) );
assert( t->dist_ecoder != NULL );
t->len_ecoder = MTX_AHUFF_Create( t->mem, t->bitOut, (short)(1L << len_width) );
assert( t->len_ecoder != NULL );
SetDistRange( t, t->length1 ); /* sets t->NUM_SYMS */
t->sym_ecoder = MTX_AHUFF_Create( t->mem, t->bitOut, (short)t->NUM_SYMS); assert( t->sym_ecoder != NULL );
Encode(t); /* Do the work ! */
MTX_AHUFF_Destroy( t->dist_ecoder ); t->dist_ecoder = NULL;
MTX_AHUFF_Destroy( t->len_ecoder ); t->len_ecoder = NULL;
MTX_AHUFF_Destroy( t->sym_ecoder ); t->sym_ecoder = NULL;
MTX_BITIO_flush_bits( t->bitOut );
lengthOut = MTX_BITIO_GetBytesOut( t->bitOut );
bin = MTX_BITIO_GetMemoryPointer( t->bitOut );
MTX_BITIO_Destroy( t->bitOut );
t->bitOut = NULL;
*sizeOut = lengthOut;
return bin; /******/
}
#endif /* COMPRESS_ON */
#ifdef DECOMPRESS_ON
/* Call this method to un-compress memory */
unsigned char *MTX_LZCOMP_UnPackMemory( register LZCOMP *t, void *dataIn, long dataInSize, long *sizeOut, unsigned char version )
{
long maxOutSize;
unsigned char *dataOut;
const long len_width = 3;
const long dist_width = 3;
const long preLoadSize = 2*32*96 + 4*256;
assert( dataIn != NULL );
/* DeAllocate Memory */
if ( t->ptr1 != NULL ) {
MTX_mem_free( t->mem, t->ptr1 );
}
t->ptr1 = NULL;
t->rlComp = MTX_RUNLENGTHCOMP_Create( t->mem );
t->bitIn = MTX_BITIO_Create( t->mem, dataIn, dataInSize, 'r' ); assert( t->bitIn != NULL );
if ( version == 1 ) { /* 5-Aug-96 awr */
t->usingRunLength = false;
} else {
t->usingRunLength = MTX_BITIO_input_bit( t->bitIn );
}
t->dist_ecoder = MTX_AHUFF_Create( t->mem, t->bitIn, (short)(1L << dist_width) );
assert( t->dist_ecoder != NULL );
t->len_ecoder = MTX_AHUFF_Create( t->mem, t->bitIn, (short)(1L << len_width) );
assert( t->len_ecoder != NULL );
t->out_len = MTX_BITIO_ReadValue( t->bitIn, 24 );
SetDistRange( t, t->out_len ); /* Sets t->NUM_SYMS */
/* Allocate Memory, but never more than t->maxCopyDistance bytes */
maxOutSize = t->out_len + preLoadSize;
t->ptr1 = (unsigned char *)MTX_mem_malloc( t->mem, sizeof(unsigned char) *
(t->maxCopyDistance < maxOutSize ? t->ptr1_IsSizeLimited = true, t->maxCopyDistance : maxOutSize) );
t->sym_ecoder = MTX_AHUFF_Create( t->mem, t->bitIn, (short)t->NUM_SYMS );
assert( t->sym_ecoder != NULL );
dataOut = Decode( t, sizeOut); /* Do the work ! */
MTX_AHUFF_Destroy( t->dist_ecoder ); t->dist_ecoder = NULL;
MTX_AHUFF_Destroy( t->len_ecoder ); t->len_ecoder = NULL;
MTX_AHUFF_Destroy( t->sym_ecoder ); t->sym_ecoder = NULL;
MTX_BITIO_Destroy( t->bitIn ); t->bitIn = NULL;
MTX_RUNLENGTHCOMP_Destroy( t->rlComp ); t->rlComp = NULL;
assert( t->usingRunLength || *sizeOut < maxOutSize );
#ifdef VERBOSE
/*cout << "Wrote " << *sizeOut << " Bytes to file <" << outName << ">" << endl; */
printf("Wrote %ld Bytes to file <%s>\n", (long)*sizeOut, outName );
#endif
return dataOut; /******/
}
#endif /* DECOMPRESS_ON */
/* Constructor */
LZCOMP *MTX_LZCOMP_Create1( MTX_MemHandler *mem )
{
const short hNodeAllocSize = 4095;
LZCOMP *t = (LZCOMP *)MTX_mem_malloc( mem, sizeof( LZCOMP ) );
t->mem = mem;
t->ptr1 = NULL;
t->maxCopyDistance = 0x7fffffff;
t->ptr1_IsSizeLimited = false;
#ifdef COMPRESS_ON
t->freeList = NULL;
t->hashTable = NULL;
t->nodeBlock = NULL;
t->nextFreeNodeIndex = hNodeAllocSize;
#endif
return t; /*****/
}
LZCOMP *MTX_LZCOMP_Create2( MTX_MemHandler *mem, long maxCopyDistance )
{
const long preLoadSize = 2*32*96 + 4*256;
const short hNodeAllocSize = 4095;
LZCOMP *t = (LZCOMP *)MTX_mem_malloc( mem, sizeof( LZCOMP ) );
t->mem = mem;
t->ptr1 = NULL;
t->maxCopyDistance = maxCopyDistance;
if ( t->maxCopyDistance < (preLoadSize+64) ) t->maxCopyDistance = preLoadSize+64;
t->ptr1_IsSizeLimited = false;
#ifdef COMPRESS_ON
t->freeList = NULL;
t->hashTable = NULL;
t->nodeBlock = NULL;
t->nextFreeNodeIndex = hNodeAllocSize;
#endif
return t; /*****/
}
/* Deconstructor */
void MTX_LZCOMP_Destroy( LZCOMP *t )
{
MTX_mem_free( t->mem, t->ptr1 );
#ifdef COMPRESS_ON
FreeAllHashNodes(t);
MTX_mem_free( t->mem, t->hashTable );
#endif
MTX_mem_free( t->mem, t );
}
/*---- Begin RUNLENGTHCOMP --- */
#ifdef COMPRESS_ON
/* Invoke this method to run length compress a file in memory */
unsigned char *MTX_RUNLENGTHCOMP_PackData( RUNLENGTHCOMP *t, unsigned char *data, long lengthIn, long *lengthOut )
{
unsigned long counters[256], minCount;
register long i, runLength;
unsigned char escape, theByte;
unsigned char *out, *outBase;
/* Reset the counters */
for ( i = 0; i < 256; i++ ) {
counters[i] = 0;
}
/* Set the counters */
for ( i = 0; i < lengthIn; i++ ) {
counters[data[i]]++;
}
/* Find the least frequently used byte */
escape = 0; /* Initialize */
minCount = counters[0];
for ( i = 1; i < 256; i++ ) {
if ( counters[i] < minCount ) {
escape = (unsigned char)i;
minCount = counters[i];
}
}
/* Use the least frequently used byte as the escape byte to */
/* ensure that we do the least amount of "damage". */
/* We can at most grow the file by the first escape byte + minCount, since all bytes */
/* equal to the escape byte are represented as two bytes */
outBase = out = (unsigned char *)MTX_mem_malloc( t->mem, sizeof(unsigned char) * (lengthIn + minCount + 1) );
/* write: escape byte */
*out++ = escape;
for ( i = 0; i < lengthIn; ) {
long j;
theByte = data[i];
for ( runLength = 1, j = i + 1; j < lengthIn; j++) {
if ( theByte == data[j] ) {
runLength++;
if ( runLength >=255 ) break;/******/
} else {
break; /******/
}
}
if ( runLength > 3 ) {
assert( runLength <= 255 );
/* write: escape, runLength, theByte */
/* We have a run of bytes which are equal to theByte. */
/* This is were we WIN. */
*out++ = escape;
*out++ = (unsigned char)runLength;
*out++ = theByte;
} else {
runLength = 1;
if ( theByte != escape ) {
/* write: theByte */
/* Just write out the byte */
*out++ = theByte;
} else {
/* write: escape, 0 */
/* This signifies that we a have single byte which is equal to the escape byte! */
/* This is the only case were we loose, and expand intead of compress. */
*out++ = escape;
*out++ = 0;
}
}
i += runLength;
}
*lengthOut = (long)(out - outBase);
assert( *lengthOut <= (long)(lengthIn + minCount + 1) );
return outBase; /******/
}
#endif /* COMPRESS_ON */
const unsigned char initialState = 100;
const unsigned char normalState = 0;
const unsigned char seenEscapeState = 1;
const unsigned char needByteState = 2;
#ifdef DECOMPRESS_ON
/* Use this method to decompress the data transparantly */
/* as it goes to the memory. */
void MTX_RUNLENGTHCOMP_SaveBytes( register RUNLENGTHCOMP *t, unsigned char value, unsigned char * *dataOutRef, long *dataOutSizeRef, long *indexRef )
{
register unsigned char *dataOut = *dataOutRef;
register long dataOutSize = *dataOutSizeRef;
register long index = *indexRef;
if ( t->state == normalState ) {
if ( value == t->escape ) {
t->state = seenEscapeState;
} else {
assert( index <= dataOutSize );
if ( index >=dataOutSize ) {
dataOutSize += dataOutSize>>1; /* Allocate in exponentially increasing steps */
dataOut = (unsigned char *)MTX_mem_realloc( t->mem, dataOut, dataOutSize );
}
dataOut[ index++ ] = value;
}
} else if ( t->state == seenEscapeState ) {
if ( (t->count = value) == 0 ) {
assert( index <= dataOutSize );
if ( index >=dataOutSize ) {
dataOutSize += dataOutSize>>1; /* Allocate in exponentially increasing steps */
dataOut = (unsigned char *)MTX_mem_realloc( t->mem, dataOut, dataOutSize );
}
dataOut[ index++ ] = t->escape;
t->state = normalState;
} else {
t->state = needByteState;
}
} else if ( t->state == needByteState ) {
register int i;
if ( index + (long)t->count > dataOutSize ) {
dataOutSize = index + (long)t->count + (dataOutSize>>1); /* Allocate in exponentially increasing steps */
dataOut = (unsigned char *)MTX_mem_realloc( t->mem, dataOut, dataOutSize );
}
/* for ( i = 0; i < t->count; i++ ) */
for ( i = t->count; i > 0; i-- ) {
dataOut[ index++ ] = value;
}
assert( index <= dataOutSize );
t->state = normalState;
} else {
assert( t->state == initialState );
t->escape = value;
t->state = normalState;
}
*dataOutRef = dataOut;
*dataOutSizeRef = dataOutSize;
*indexRef = index;
}
#endif /* DECOMPRESS_ON */
/* Constructor */
RUNLENGTHCOMP *MTX_RUNLENGTHCOMP_Create( MTX_MemHandler *mem )
{
RUNLENGTHCOMP *t = (RUNLENGTHCOMP *)MTX_mem_malloc( mem, sizeof( RUNLENGTHCOMP ) );
t->mem = mem;
t->state = initialState; /* Initialize */
return t; /*****/
}
/* Deconstructor */
void MTX_RUNLENGTHCOMP_Destroy( RUNLENGTHCOMP *t )
{
MTX_mem_free( t->mem, t );
}
/*---- End RUNLENGTHCOMP --- */