Semantic Web Services Ontology (SWSO)
- This version:
- http://www.w3.org/submissions/2005/SUBM-SWSF-SWSO-20050909/
- Latest version:
- http://www.w3.org/submissions/SWSF-SWSO/
- Authors:
-
Steve Battle (Hewlett Packard)
Abraham Bernstein (University of Zurich)
Harold Boley (National Research Council of Canada)
Benjamin Grosof (Massachusetts Institute of Technology)
Michael Gruninger (NIST)
Richard Hull (Bell Labs Research, Lucent Technologies)
Michael Kifer (State University of New York at Stony Brook)
David Martin (SRI International)
Sheila McIlraith (University of Toronto)
Deborah McGuinness (Stanford University)
Jianwen Su (University of California, Santa Barbara)
Said Tabet (The RuleML Initiative)
Copyright © 2005 retained by the authors.
All Rights Reserved.
This document is available under the W3C Document License.
See the W3C Intellectual Rights Notices and Disclaimers for additional information.
This document
defines the Semantic Web Services Ontology (SWSO).
The ontology is expressed in two forms: FLOWS, the First-order Logic
Ontology for Web Services; and ROWS, the Rules Ontology for Web Services,
produced by a systematic translation of
FLOWS axioms into the SWSL-Rules language. FLOWS has been specified in
SWSL-FOL, the first-order logic language developed by SWSO's sister SWSL
effort.
Status of this document
This document is part of a member submission, offered by
National Institute of Standards and Technology (NIST),
National Research Council of Canada,
SRI International,
Stanford University,
Toshiba Corporation,
and
University of Southampton
on behalf of themselves and the authors.
This is one of four documents
that make up the submission.
These documents define the Semantic Web Services Framework (SWSF).
This submission has been prepared by the Semantic Web Services
Language Committee of the Semantic Web Services Initiative.
The W3C Team Comment discusses this submission
in the context of W3C activities.
Public comment on this document is invited on the mailing list
public-sws-ig@w3.org
(public archive).
Announcements and current information may also be available on the SWSL Committee Web site.
By publishing this document, W3C acknowledges that
National Institute of Standards and Technology (NIST),
National Research Council of Canada,
SRI International,
Stanford University,
Toshiba Corporation,
and
University of Southampton
have made a formal submission to W3C for discussion. Publication of
this document by W3C indicates no endorsement of its content by W3C,
nor that W3C has, is, or will be allocating any resources to the
issues addressed by it. This document is not the product of a
chartered W3C group, but is published as potential input to the W3C
Process. Publication of acknowledged Member Submissions at the W3C
site is one of the benefits of W3C
Membership. Please consult the requirements associated with Member
Submissions of section
3.3 of the W3C Patent Policy. Please consult the complete list of acknowledged W3C Member
Submissions.
1 Introduction
2
Service Descriptors
3
Process Model
3.1 FLOWS-Core
3.1.1 Service
3.1.2 Atomic Process
3.1.3 composedOf
3.1.4 Message
3.1.5 Channel
3.2 Control Constraints
3.2.1 Split
3.2.2 Sequence
3.2.3 Unordered
3.2.4 Choice
3.2.5 IfThenElse
3.2.6 Iterate
3.2.7 RepeatUntil
3.3 Ordering constraints
3.3.1 OrderedActivity
3.4 Occurrence constraints
3.4.1 OccActivity
3.5 State constraints
3.5.1 TriggeredActivity
3.6 Exceptions
3.6.1 State-based Exception Handling
3.6.2 Message-based Exception Handling
3.6.3 Extended Exception Handling
4
Grounding a Service Description
4.1 Relationship between SWSL and WSDL
4.2 Mapping between SWSL and WSDL
4.2.1 Message Patterns
4.2.2 Message Type Realization
4.2.3 Mapping SWSO Messages to WSDL Messages
4.2.4 Mapping WSDL Messages to SWSO Messages
4.2.5 Declarative Specification of SWSO-to-WSDL Message Mapping
4.2.6 Declarative Specification of WSDL-to-SWSO Message Mapping
5
Rules Ontology for Web Services (ROWS)
6
Background Materials
6.1 Ontology of the Process Specification Language
6.2 Knowledge Preconditions and Knowledge Effects
7 Glossary
8 References
Appendices
A PSL in SWSL-FOL and SWSL-Rules
B Axiomatization of the FLOWS Process Model
C
Axiomatization of the Process Model in SWSL-Rules
D Reference Grammars
This document also refers to Section 2 in the Application Scenarios document.
This document is part of the technical report of the Semantic Web Services
Language (SWSL) Committee of the Semantic Web Services Initiative (SWSI).
The overall structure of the report is described in the document
titled
Semantic Web Services Framework Overview.
This document presents the Semantic Web Services Ontology (SWSO).
This includes a description of the conceptual model underlying
the ontology, and
a description of
a first-order logic (FOL) axiomatization
which defines the model-theoretic semantics of the ontology.
The axiomatization is called "SWSO-FOL" or equivalently,
FLOWS -- the First-order
Logic Ontology for Web Services --
and is expressed using SWSL-FOL.
(The full axiomatization is available in
Appendix B.)
As noted in
Section 5,
These
same axioms can be expressed (or partially expressed in some cases) in
SWSL-Rules. The SWSL-Rules formalization of the axioms, called
SWSO-Rules or ROWS, is
listed in
Appendix C.
The goal of FLOWS is to enable reasoning about the
semantics underlying Web (and other eletronic) services,
and how they interact with each other and with the "real world".
FLOWS does not strive for a complete representation of web
services, but rather for an abstract model that is faithful
to the semantic aspects of service behavior.
(An approach to "grounding" FLOWS specifications into
real Web services, e.g., that use WSDL for messaging,
is discussed in
Section 4).
Following the lead of the situation calculii
[Reiter01],
and in particular the situation calculus semantics
[Narayanan02]
of
OWL-S
[OWL-S 1.1],
the changing portions of the real world are
modeled abstractly using the notion of fluents.
These are first-order logic predicates and terms that can
change value over time.
The FLOWS model provides infrastructure for representing
messages between services;
the focus here is on the semantic content of a message,
rather than, for example, the specifics of how that content is packaged
into an XML-based message payload.
(Again, Grounding will address these issues.)
FLOWS also provides constructs for modeling the internal processing
of Web services.
FLOWS is intended to enable reasoning about essential aspects
of Web service behavior, for a variety of different purposes
and contexts.
Some targeted purposes are to support
(a) descriptions of Web services that enable automated
discovery, composition, and verification, and
(b) creation of declarative descriptions of
a Web service, that can be mapped
(either automatically or through a systematic process)
to executable specifications.
A variety of contexts can be supported, including:
(i)
modelling a service as essentially
a black box, where only the messaging is observable;
(ii) modelling the
internal atomic processes that a service performs, along with
the impact these processes have on the real world
(e.g., inventories, financial accounts, commitments);
(iii)
modelling many properties of a service,
including all message APIs, all or some of the internal processing,
and some or all of the internal process and data flows.
Of course,
the usability of a Web service description may depend on
how much or how little information is included.
It is important to note that the specification of the FLOWS ontology
in first-order logic does not presuppose that the automated reasoning
tasks described above will be realized using a first-order logic theorem
prover. We can certainly use FOL to specify solutions to these tasks,
using notions of entailment and satisfiability. Nevertheless, while
some tasks may naturally be realized through theorem
proving, it has been our experience that most AI automated reasoning
tasks are addressed by special-purpose reasoners, rather than by
general-purpose reasoners such as theorem provers. For example,
we anticipate specialized programs being developed to perform
Web service discovery, Web service composition and Web service
verification. Thus, the role of FLOWS is not necessarily to provide
an executable specification, but rather to provide an ontology --
a definition of concepts -- with a well-defined model theoretical
semantics that will enable specification of these tasks and that
will support the development of specialized reasoners that
may be provably correct with respect to these specifications.
FLOWS captures the
salient, functional elements of various models of Web services found
in the literature and in industrial standards.
In FLOWS, an emphasis is placed on enabling the
formal representation and study
of the following formalisms, among others.
-
Models focused on specifying semantic Web services
[McIlraith01]
including the
OWL-S [OWL-S 1.1]
model of atomic processes, their inputs, outputs, preconditions and effects,
and the
associated notion of impacts "on the world" and testing
conditions "about the world";
and the WSMO [Bruijn05]
ontology for
describing the intended goals of Web services.
-
Various process models for combining atomic services, including
the OWL-S process model and in particular the FOL situation calculus
sematics and Petri Net semantics for OWL-S
[Narayanan02],
automata and process algebra based models
(e.g., pi-calculus [Milner99],
BPEL [BPEL 1.1],
Roman model [Berardi03],
Conversation model [Bultan03],
Guarded finite-state automata [Fu04]).
- The fundamental emphasis of standards such as
WSDL [WSDL 1.1],
BPEL,
WSCL [WSCL 1.0],
WS-Choreography [WS-Choreography],
on the sending of "messages" between "web services";
and more broadly, of
Services Oriented Architectures
[Papazoglou03,
Helland05])
-
Various models of interaction between Web services (e.g.,
WS-Choreography, WSCL, Protocols such as
OWL-P [Singh02]
and the relationship of such "global" protocols
with the "local" behaviors they might imply (e.g., results
from the
conversation model [Bultan03]).
FLOWS represents an attempt to extend on the
work of OWL-S, to incorporate a variety of capabilities
not within the OWL-S goals.
OWL-S was focussed on providing an ontology of Web services that
would facilitate automated discovery, enactment and composition
of Web services. It was not focused on interoperating with or
providing a semantics for (at its outset, nonexistent) industry
process modeling formalisms such as BPEL. As such, OWL-S
concepts such as messages are abstracted away and only reintroduced
in tis grounding to WSDL.
A primary difference between FLOWS and OWL-S is the expressive
power of the underlying language.
FLOWS is based on first-order logic, which means that
it can express considerably more than can be expressed
using OWL-DL (upon which OWL-S is based).
(For example, this immediately includes n-ary
predicates and richly quantified sentences.)
The use of first-order logic enables
a more refined approach than possible in OWL-S
to representing different forms of
data flow that can arise in Web services.
A second difference is that FLOWS strives to explicitly model
more aspects of Web services than OWL-S.
This includes primarily the fact that
FLOWS can readily model
(i) process models using a variety of different paradigms; and
(ii) data flow between services, which is acheived
either through message passing or access to
shared fluents (which might also be thought of as shared data).
Indeed, FLOWS provides the ability to model,
albeit in an abstract, semantically motivated manner,
several key Web services standards, including WSDL,
BPEL, and WS-Choreography.
A key premise of FLOWS is that an appropriate foundation for formally
describing Web services can be built as a family of
PSL extensions.
PSL -- the Process Specification Language --
is a formally axiomatized ontology
[Gruninger03a,
Gruninger03b]
that has been standardized as ISO 18629.
PSL was originally developed to enable sharing of
descriptions of manufacturing processes.
FLOWS refines aspects of PSL with Web service-specific concepts and extensions.
An overview of concepts in the Process Specification Language that are
relevant to FLOWS is given in Section 6 below.
A primary goal of FLOWS is to provide a formal
basis for accurately specifying "application domains" based
broadly on the paradigms of Web services and/or services
oriented architecture (SOA).
While FLOWS captures key fundamental aspects of
the Web services and SOA paradigms, it also strives to remain very
flexible, to allow for the multitude of variations already present
in these domains and likely to arise in coming years. Another
goal of FLOWS is to enable formalization of a diversity of process
modeling formalisms within the ontology. As such, FLOWS, like PSL
is designed to facilitate interoperation between diverse process
modeling formalisms.
In a typical usage of FLOWS, an application domain is created
by combining the FLOWS axioms with additional logical sentences
to form a (first order logic) theory.
Speaking loosely, each sentence in such a theory
can be viewed as a
constraint or restriction on the models (in the sense of
mathematical logic) that satisfy the theory.
In particular, and following the spirit of
Golog [Reiter01]
and similar languages,
even process model constructs such as
while or if-then-else
correspond formally to constraints rather than
procedural elements.
Similarly, the passing of information,
which is often represented using variable assignment
in Web services, is specified in the formal model
in epistemic terms, following the approach taken in
[Scherl03].
Again, the approach taken here is intended to provide maximal
flexibility in terms of formally modeling
the wide range of existing and future web
services and SOA models.
For example, it is possible ot look at data flow
and information sharing at an abstract level based on
what a service "knows", or to specialize
this to models that involve
imperative variable assignment.
Following the high-level structure of OWL-S, FLOWS has three major
components: Service Descriptors,
Process Model,
and
Grounding.
In the formal ontology, these three elements
are associated with services
by representing a formal service as a conceptual
object, and using relations to associate specific
artifacts with the service.
For example,
service-author is a binary relation
that associates an author to a service, and
service-activity is a binary relation
that associates a unique (PSL) "complex activity" to a service;
the complex activity provides a partial or complete specification
of the process model associated with the service.
(See
Section 3)
below for more detail.)
Most domain ontology developers are motivated to provide a logical
description of their Web service with a view to some specific set of
automations tasks, including perhaps Web service discovery, invocation,
composition, verification or monitoring. Each task requires some subset
or view of the entire FLOWS ontology. For example, to perform
automated Web service discovery, we might need axioms from both the Service
Descriptors, and select axioms from the Process Model. For Web
service invocation, we might only need the inputs and outputs of atomic
processes comprising a service in FLOWS-Core, and so on. To cross cut
our three broad subontologies (Service Descriptors, Process Model,
and Grounding) and to create ontologies that are task-specific, it is possible to project
views onto the FLOWS ontology. The concept of
views is not developed in this document, however.
This document is organized as follows.
Service Descriptors are described in
Section 2.
The Process Model portion of the ontology, described in
Section 3, represents the most
substantial advance over OWL-S.
This section is quite extensive, presenting the core
ontology (FLOWS-Core), several formal extensions of it, and
a more informal discussion concerning the relationship of
FLOWS to other service models.
The section also includes an intuitive description of
the conceptual model underlying FLOWS,
and links to a formal axiomatization of FLOWS
(in Appendix B).
(Also relevant is
Appendix A,
which shows how to specify key elements of PSL in
both SWSL-FOL and SWSL-Rules).
Section 4 discusses grounding for FLOWS.
As noted above, (most of) FLOWS can be
systematically translated into the SWSL-Rules language;
this is discussed in
Section 5.
(An axiomatization for
ROWS is presented in
Appendix C).
Section 6 provides a brief review
of PSL and the approach of
[Scherl03] for
incorporating knowledge into the situation calculus,
for readers who have not been exposed to these before.
The document closes with
a Glossary (Section 7),
and References (Section 8).
The description of FLOWS
presented in this document also refers to
Section 2
of the document
Application Scenarios,
that forms part of this W3C submission.
That section provides some extended examples which illustrate
key aspects of the conceptual model underlying FLOWS.
Service descriptors provide basic information about a Web service.
This descriptive information may include non-functional meta-information
and/or provenance information. Service descriptors are often used
to support automated Web service discovery. What follows is an initial
set of domain-independent properties. Our intention is that these be
expanded as needs dictate. Indeed many of the service descriptors
that are most effective for service discovery are domain specific.
The initial list captures basic identifying information including name,
authorship, textual description, version, etc. The set of descriptors
also includes information describing (potentially subjective) notions
of quality of service such as reliability. Note that this is an initial
set of properties derived predominantly from the OWL-S Profile
[OWL-S 1.1]).
The set is expected to be extended with properties that are domain
specific such as those contained in the OWL-S appendices
and those in WSMO's [Bruijn05]
coverage service descriptor (or "non-functional property" as it is called
in their proposed specification). The set may also be expanded with
properties commonly used in other standards such as those found in
Dublin Core. In the following list of properties, those properties
derived from OWL-S are so noted. Some of these properties are similar
or identical to those included in WSMO's list of non-functional properties.
Following the description of each individual property is a listing of the
FLOWS relation that captures the concept within the ontology.
- Service Name: This refers to the name of the service and
may be used as a unique identifier. This corresponds directly to the
OWL-S property serviceName. In the future, we may find additional
name-related properties to have value such as alternateName (including
other synonymous names) and presentationName (including a string that
would be presented in user interfaces).
name(service,service_name)
- Service Author: Services could have single or multiple
authors. Authors could be people or organizations. This property
augments the OWL-S contactInformation property.
author(service,service_author)
- Service Contact Information: This property contains a
pointer for people or agents requiring more information about the
service. While it could be anything, it is likely to be an email
address.
contact(service,contact_info)
- Service Contributor: This property describes the entity that is
responsible for making updates to the service. Note that while it is
related to the author, it may not be identical to the author since an
original author may not be the identified contributor or maintainer of
a service. Note also, that while it is related to the
contactInformation property, it is not identical since the author,
contributor, and contact point may all be distinct entities.
contributor(service,service_contributor)
- Service Description: Services may have a textual
description. Typical descriptions would include a summary of what the
service offers and any requirements that the service has. This property
is simply a renaming of the OWL-S textDescription property.
description(service,service_description)
- Service URL: This property is filled with one (or more)
URL's associated with the service.
This property is included in order to
facilitate interoperation where agents need to count on URLs as values.
url(service,service_URL)
- Service Identifier: This property is filled by an
unambiguous reference to the service.
identifier(service,service_identifier)
- Service Version: As with all software programs, there
may be multiple versions of services and this property contains an
identifier for the specific service at a specific time. This is likely
to be a revision number in a source code control system.
version(service,service_version)
- Service Release Date: This property contains a date of
the release of the service. It would be anticipated that it would be
compatible with Dublin Core's date. It may be used, This is a date of
the service so that, for example, to search for services not functions
would be able to find services that are not more than 2 years old.
releaseDate(service,service_release_date)
- Service Language: This property contains an identifier
for the language of the service.
This property is expected to contain an identifier for a
logical programming language and could also contain an ISO language
tag.
language(service,service_language)
- Service Trust: This property contains an entity
describing the trustworthiness of the service.
trust(service,service_trust)
- Service Subject: This property contains an entity
indicating the topic of the service.
subject(service,service_subject)
- Service Reliability: This property contains an entity
used to indicate the dependability of the service. Different
measurements may be useful in determining the fillers such as the
number of failures in a given time period.
reliability(service,service_reliability)
- Service Cost: This property contains an entity used to
indicate a cost of the service. While it could be a monetary unit, it
could also be a complex description of charging plans.
cost(service,service_cost)
The translation of service descriptors into ROWS can be found here.
Link to ROWS Axiomatization
Readers may also be interested in the discussion of inputs,
(conditional) outputs,
preconditions and conditional effects
of the complex activity that describes the
process model of a service. This is discussed
towards the end of
Subsection 3.1.2.
Since PSL is a generic ontology for processes, we
need to specify extensions to provide concepts that are useful in the
context of Web services.
In particular, the FLOWS process model adds two fundamental elements to
PSL, namely (i) the structured notion of atomic process as found
in OWL-S, and (ii) infrastructure for specifying
various forms of data flow.
(The FLOWS process model relies on constructs already available
in PSL for representing basic aspects of process flow,
and also provides some extensions for them.)
Following the modular organization of the PSL ontology,
the FLOWS process model
is layered and partitioned into natural
groupings.
When specifying an application domain, it is thus
easy to incorporate
only the ontological building blocks that are needed.
The FLOWS process model is created as
a family of extensions of PSL-OuterCore,
The fundamental extension of PSL-OuterCore for services is
called "FLOWS-Core".
As will be seen, this extension is quite minimalist, and
provides an abstract
representation only for (web) services,
their impact "on the world", and the
transmission of messages between them.
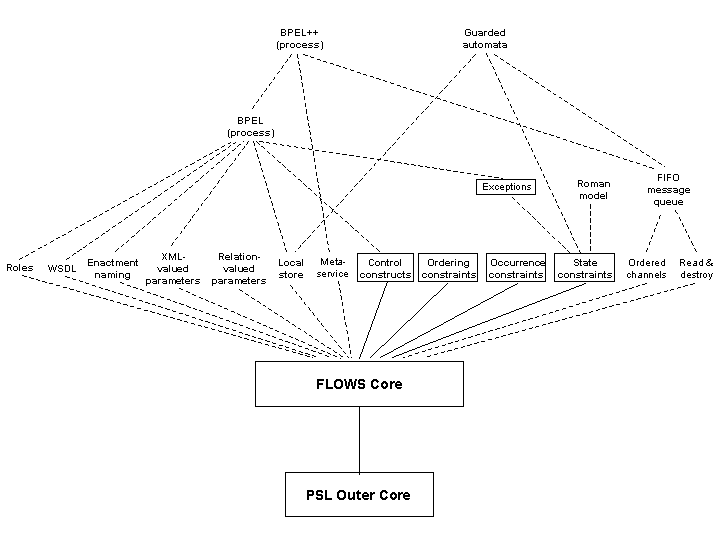
Figure 3.1
shows various families of process modeling constructs,
including PSL-OuterCore, FLOWS-Core,
and several others.
These include models from standards, such as the process model
portion of BPEL
(and a refinement of BPEL that incorporates typical
assumptions made when using BPEL in practice),
and models from the research literature, such
as guarded automata.
A line between a family F of constructs and
a family F' above F indicates that it is
natural to view F'
as a family that includes most or all of the constructs
in F.
The OWL-S process model is not shown explicitly in Figure 3.1, because
it has been integral in the design of the FLOWS-Core and
the Control Constructs extension.
Of course, the
different families of modeling constructs
shown in the figure should not
be viewed as comprehensive.
In some cases, it may be useful to create
PSL extensions of FLOWS-Core, to formally
specify the properties of certain families of constructs
shown in Figure 3.1.
Indeed, as part of the Process Model of the FLOWS ontology presented
below
several extensions are specified;
these are indicated in the figure by the rectangles above
FLOWS-Core.
We note that FLOWS-Core can serve
as a mathematical foundation for representing several other aspects and
models from the Web services and SOA standards and literature,
and it seems likely that additional PSL extensions of
FLOWS-Core will be created in the future.
Following this methodology,
the FLOWS process model ontology is composed of a core set of axioms, referred
to as FLOWS-Core, and a set of extension ontologies.
FLOWS currently consists of six ontology modules that
specify core intuitions about the activities associated with a service together
with classes of composite activities that are used to express different
constraints on the occurrence of services and their subactivities.
- FLOWS-Core introduces the basic notions of services as
activities composed of atomic activities
(Subsection 3.1).
- Control Constraints axiomatize the basic
constructs common to workflow-style process models. In particular, the
Control Constraints in FLOWS include the concepts from the process model of
OWL-S
(Subsection 3.2).
- Ordering Constraint allow the specification of activities
defined by sequencing properties of atomic processes
(Subsection 3.3).
- Occurrence Constraints support the specification of nondeterministic
activities within services
(Subsection 3.4).
- State Constraints
support the specification of activities whose activities are triggered
by states (of an
overall system) that satisfy a given condition
(Subsection 3.5).
- Exception Constraints
provide some basic infrastructure for modeling
exceptions
(Subsection 3.6).
The table below lists the FLOWS ontologies and the concepts defined in those
ontologies.
The FLOWS Process Model Ontology Modules
| Module |
Major Concepts |
| FLOWS-Core |
Service
AtomicProcess
composedOf
message
channel
|
| Control Constraints |
Split
Sequence
Unordered
Choice
IfThenElse
Iterate
RepeatUntil
|
| Ordering Constraints |
OrderedActivity |
| Occurrence Constraints |
OccActivity |
| State Constraints |
TriggeredActivity |
| Exception Constraints |
Exception |
The specification of concepts in FLOWS is presented using
some or all of the following:
- Intended Semantics
Each concept is given an intuitive definition in English.
- Axiomatization
The intended semantics of concepts in FLOWS is formally axiomatized
in SWSL-FOL using the ontology of ISO 18629
( Process Specification Language )
as the foundation.
- Reference Grammar
Process descriptions are often domain-specific. As such, they are not
part of the FLOWS ontology. Nevertheless, FLOWS imposes a syntactic form
on these SWSL-FOL domain-specific axioms. These are specified using
a Reference Grammar.
- Process Description Syntax
A user-friendly syntax for domain-specific process descriptions is provided.
This syntax serves as a macro language that expands into the SWSL-FOL sentences
specified in the Reference Grammar.
- Examples
Where appropriate, we illustrate concepts with a small example. Further
examples may be found in the Applications document.
After the presentation of FLOWS-Core and its formal extensions,
Subsection 3.7
describes
some possible additional extensions of FLOWS-Core, corresponding
to the entries in
Figure 3.1
not enclosed in rectangles.
The FLOWS-Core process model
is intended to provide a formal basis
for specifying essentially any process model
of Web services and service composition
that has arisen or might arise in the future.
As such, the underlying conceptual process model
focuses on the most essential aspects of
Web services and their interaction.
The principles guiding the FLOWS-Core process model can be
summarized as follows:
- In typical usage of the FLOWS-Core (which follows the spirit of
PSL-OuterCore), one creates an
application domain theory for a given application domain, which
incorporates the predicates, terms, and
axioms of FLOWS-Core, along with additional
domain-specific predicates, terms and constraints.
-
Predicates and terms in the underlying first-order logic
language of an application domain theory are
used as an abstraction of the "world".
Following PSL (and the situation calculi),
fluents are predicates and terms whose
values may change as the result of activity occurrences.
We generally use the term relation to
refer to a predicate whose value does not change as the
result of an activiy occurrence.
We informally distinguish between two categories of
relations and fluents:
domain-specific, which focus on the "real world", or
more specifically, on information about the application domain;
and
service-specific, which focus on the infrastructure
used to support the Web services model,
in particular on messages and message transmission.
-
As noted above, a formal service is modeled as
a conceptual object, and for each service
S there is exactly one associated
(PSL-OuterCore) complex activity A.
(These are related by the
predicate
service-activity(?s,?a).)
As in PSL, the complex activity A may have
one or more occurrences, each of which corresponds intuitively
to a possible execution of A (subject
to the constraints in the relevant application domain theory).
The notion of 'occurrence' of activity A
here is essentially the same as the notion of
'enactment' of a workflow specification as found in
the workflow literature.)
Speaking intuitively,
in an application domain theory, the complex acivity
A might be specified
completely, or only partially.
We use the phrase service activity
to refer to a PSL complex activity, such as A,
that is associated
to a formal service in some application domain.
-
We model the atomic actions
involved in service activities as
discrete "occurrences"
of "atomic activities" (in the sense of PSL-OuterCore).
This includes (a) the activities that
are "world-changing", in that they
modify facts "in the world" (e.g., plane reservations,
commitments to ship products, aspects of financial transfer,
modification to inventory databases)
and also (b) activities that support aspects of transferring
messages between Web services,
and (c) activities that create, destroy, or modify channels
(see below).
-
Following the spirit of OWL-S, a
primary focus in FLOWS-Core is on
what are called here (FLOWS)
atomic processes; these are
atomic activities
that have input parameters, output parameters,
pre-conditions and conditional effects.
The pre-conditions of atomic processes
will refer to both fluents and time-invariant
relations.
The conditional effects of atomic processes
can have impact on fluents.
In the interest of flexibility,
FLOWS-Core does not require that every
atomic activity in a service activity be a FLOWS atomic process,
nor does
FLOWS-Core require that every FLOWS atomic process
be a subactivity of a service activity.
-
The flow of information between Web services can occur
in essentially two ways: (a) via message passing and (b)
via shared access to the same "real world" fluent (e.g., an
inventory database, a reservations database).
With regards to message passing, FLOWS-Core
models
messages as (conceptual) objects that are created
and (possibly) destroyed, and that
their life-span has a non-zero duration.
This follows the spirit of standards such as
WSDL and BPEL, the spirit of at least some works
on Services Oriented Architecture
[Helland05],
and indeed the physical reality involved in Web service communication.
Messages have types, which indicate the kind
of information that they can transmit.
-
FLOWS-Core includes the channel construct,
which provides a convenient mechanism for
giving some structure to how
messages are transmitted between services.
Intuitively, a channel holds messages
that have been "sent" and may or may not have been "received".
(The notion of 'channel' is inspired by, but not identical
to, the notion of 'channel' found in many process algebras;
it is also inspired by the notion of channels found in BPEL and elsewhere.)
In a given application domain, channels
may be used to restrict which service activity occurrences can communicate
with which other service activity occurrences, and to
impose further structure on the communication via messages
(e.g., requiring intuitively that messages are stored in FIFO queues).
In an application domain the family of channels might be fixed,
or might be dynamically created, destroyed, and/or modified.
(Some particular approaches to structuring how messages are passed are
provided by the
possible extensions named Ordered Channels,
Read & Destroy, and FIFO Message Queue; other approaches can
also be represented in application domains built on FLOWS-Core.)
-
To represent the acquisition and dissemination of information
inside a Web service we follow the spirit
of the ontology for "knowledge-producing actions"
developed in [Scherl03],
which formed the basis for the situation calculus semantics of
OWL-S inputs and effects
[Narayanan02].
(Some background on the knowledge-producing actions framework
is provided in
Subsection 6.2
below).
Inputs are conceived as knowledge-preconditions, and outputs as
knowledge-effects.
That is, the needed input values must be known
prior to an occurrence (i.e., execution) of an atomic process.
Also, following the occurrence of an atomic process,
values of associated outputs are known
(assuming appropriate conditions in the conditional effect are satisfied).
This treatment of information provides for the use of a notation
Knows(P), where P is a logical formula,
which has the intuitive meaning in our context that
a service activity occurrence
"knows" that P is true (at some point in time).
This approach provides a declarative
basis that enables reasoning about what
information is and is not available to a service activity occurrence
at a given time.
This is essential, since in the real world the mechanisms
available to Web services for gathering information are
typically limited to (a) receiving messages and (b) performing
atomic processes that interact with domain-specific fluents.
Further, in a given application domain it is typical to
restrict a service so that it can gain access to
a specified set of domain-specific relations and fluents.
Using FLOWS-Core
it will thus be possible to precisely specify and
study properties of
Web services related to data flow and data access.
(In the current axiomatization the epistemic fluents
related to Knows intuitively correspond to
knowledge held by the overall system. A planned refinement
is to relativize these fluents, in order to represent
the knowledge of individual service occurrences.)
FLOWS-Core does not
provide any explicit constructs for the structuring of processing
inside a Web service.
(Some minimal constructs are available in PSL OuterCore,
including primarily the
soo_precedes
predicate,
which indicates that one atomic activity occurrence in a complex
activity occurrence precedes in time another
atomic activity occurrence.)
This is intentional, as there are several models for
the internal processing in the standards and literature
(e.g., BPEL, OWL-S Process Model, Roman model, guarded automata model),
and many other alternatives besides (e.g., rooted in
Petri nets, in process algebras, in workflow models, in telecommunications).
We introduce (possible) extensions of FLOWS-Core to
represent some of these service-internal process models
(e.g., Control Constructs,
Roman model, Guarded automata).
When using FLOWS-Core,
it is often useful to model
humans (and organizations and other non-service agents)
as specialized
formal services (or combinations of services, corresponding to
the different roles that they might play).
We are not proposing that all aspects of human behavior can
or should be captured using FLOWS-Core constructs, but
rather that a useful abstraction of human (and organization)
behaviors, in the context of interaction with Web services,
is to focus on the message creation/reading activities that
humans perform, and on the knowledge that they can convey
to other services or obtain from them (via messages).
It is typical to assume that humans
cannot directly perform atomic processes for
testing or directly impacting domain-specific fluents,
but must rather achieve that by invoking standard (web) services.
For an abstract representation
(H, B) of human H
with complex activity B,
in some cases it is natural to view occurrences of
B as relatively short-lived (e.g., corresponding
to one session with an on-line book seller), and
in other cases to view occurrences of B as
long-lived (e.g., the life-long family of interactions
between the human and the on-line bookseller).
In some cases it might be natural to model a human
as embodying several formal services
(H_1, B_1), ..., (H_n, B_n),
corresponding to different roles that the human might play
at different times.
We note that FLOWS-Core
can be used to faithfully represent and study
service process models that do not
include all of the notions just listed.
For example, OWL-S focuses on world-changing atomic processes
and largely ignores the variations that can arise
in connection with message passing.
A given application domain can be represented in FLOWS-Core
in such a way that the message passing is essentially transparent,
so that it provides a faithful simulation of an OWL-S version of the domain.
Alternatively, a domain theory can be specified in FLOWS-Core
which essentially ignores the ability of
atomic processes to modify facts "in the world".
Such theories offer the possibility of
faithfully simulating domains defined in terms
of standards such as WSDL, BPEL, and WS-Choreography, which
focus largely on service I/O signatures,
and the process and data flow involved with message passing.
In the remainder of this subsection we provide more detail
concerning the major concepts of FLOWS-Core.
A service is an object. Associated with a service are a number of service
descriptors, as described in
Section 2.
Also associated with every service is an activity
that specifies the process model of the service. We call these activities
service activities.
These service activities are PSL activities. A service
occurrence is an occurrence of the activity that is associated with the
service.
We associate three relations
with services:
service(thing)
service_activity(service,activity)
service_occurrence(service,activity_occurrence)
Link to Axiomatization
Readers may also be interested in the discussion of inputs,
(conditional) outputs,
preconditions and conditional effects
of the complex activity that describes the
process model of a service. This is discussed
towards the end of
the next subsection.
A fundamental building block of the FLOWS process model for Web services
is the concept of an atomic process. An atomic process is a PSL activity
that is generally (but not mandated to be) a subactivity of the activity
associated with a service (i.e., the activity referenced in the relation
service_activity(service,activity) introduced in Section 3.1.1).
An atomic process is directly invocable, has no subprocesses and can
be executed in a single step. Such an activity
can be used on its own to describe a simple Web service,
or it can be composed with other atomic or composite processes (i.e.,
complex activities) in order to
provide a specification of a process workflow. The composition is encoded
as ordering constraints on atomic processes using the FLOWS control constructs
described in Section 2.2.2.
Associated with an atomic process are zero
or more parameters that capture the inputs, outputs, preconditions and
(conditional) effects (IOPEs) of the atomic process. More on IOPEs in
a moment.
Types of Atomic Processes
In FLOWS we use atomic processes to model both the domain-specific activities
associated with a service, such as put_in_cart(book)
or checkout(purchases), but also the atomic processes
associated with producing, reading and destroying the messages that are sent
between Web services. We distinguish these categories of atomic processes
as follows:
- Domain-specific Atomic Process:
Intuitively, this kind of atomic process
is focused on accessing and possibly modifying
domain-specific relations and fluents.
It is not able to
directly manipulate messages or channels,
or in other words, it cannot access or modify
the service-specific relations and fluents concerned
with messages or channels.
In particular, this kind of activity is intended to
model exclusively
(a) the knowledge that a process needs
to execute (i.e., the input parameter values),
(b) the pre-conditions about domain-specific relations and fluents that
must hold for successful execution,
(c) the impact the execution of the activity has
on domain-specific fluents,
and
(d) the knowledge acquired by execution (from the output parameter value
s,
and from whether the execution was successful or not).
Occurrences of activities of this kind
do not include anything concerning
messages -- no producing, reading or destroying of them.
(The occurrences may implicitly rely on previous message
handling activities, e.g., because it uses for its input knowledge
that was acquired by previously reading a message.)
- Produce_Message:
Occurrences of activities of this kind
create a new message object.
If a channel is used for the transmission of
this message, then immediately after the message is produced
it will be present in that channel.
An epistemic pre-condition for producing the message
will be that
appropriate values are "known" by the service occurrence for populating
the parameter values of the message.
(In some domains, another pre-condition on producing a message
will be that there is "room" in some channel or queue
that is used to model the message transmission system.)
- Read_Message:
Occurrences of activities of this kind
are primarily knowledge producing.
Specifically, immediately after a Read_Message
occurrence information about the payload of the
message will be known.
Thus, there is a close correspondence between the treatment
of output values from a
domain-specific atomic process,
and the treatment of
the payload of a message resulting from a Read_Message occurrence.
- Destroy_Message:
Occurrences of activities of this kind
have the effect of destroying a message;
after that time the message cannot be read.
-
Channel Manipulation Atomic Processes are used to
create and destroy channels, and to modify their properties
(what services
can serve as source or target for the channel, and what
message types can be transmitted across them).
These are discussed briefly in
Section 3.1.5 below.
In the FLOWS ontology, the message-specific atomic activities are distinguished
by the following unary relations.
Produce_Message(atomic_process)
Read_Meassage(atomic_process)
Destroy_Message(atomic_process)
where atomic_process is an a FLOWS atomic process.
Atomic Process IOPEs
Associated with each atomic process are (multiple) input, output, precondition
and (conditional) effect parameters (IOPEs). The inputs and outputs are the
inputs and outputs to the program that realizes the atomic process. The
preconditions are any conditions that must be true of the world for the
atomic process to be executed. In most cases, there will be no precondition
parameters since most software (and Web services are generally software)
has no physical preconditions for
execution, at least at the level at which we are modeling it.
Finally, the conditional effects of
the atomic process are the side effects of the execution of the atomic
process. They are conditions in the world that are true following
execution of the process, e.g., that a client's account was
debited, or a book sent to a particular address. These effects, may be
conditional, since they may be predicated on some state of the world
(for example, whether a book is in stock).
In the FLOWS ontology, IOPEs are associated with an atomic process via
the following binary and ternary relation. The inputs and outputs of an
atomic process are represented by functional fluents that take on a
particular value e.g.bookname(book)="Green Eggs and Ham".
We acknowledge that the actual input may be conveyed to the atomic process
(e.g., as a result of a read-message process or via some internal
communication) as rich structured data, but it is ultimately
representable within our ontology as a conjunction of its component
fluent parts. The preconditions and effects of an atomic process are
expressed as
arbitrary first-order logic formulae. Since formulae are not reified
in FLOWS (note that fluents are reified, and further that formulae are
reified in SWSL-Rules), we
must associate a relational fluent with each formula we wish
to represent in our IOPE relations. This fluent is true iff the formula
we associate it with is true. We use this `trick' both for
preconditions, for effects and for the conditions associated with
conditional outputs and conditional effects. In the case where an output
or effect is unconditional, the condition fluent is true.
input(atomic_process, input_fluent)
output(atomic_process, cond_formula_fluent, output_fluent)
precond(atomic_process, precond_formula_fluent)
effect(atomic_process, cond_formula_fluent,effect_formula_fluent)
where
-
atomic_process is an atomic process, and
-
input_fluent and output_fluent are
functional fluents, that serves
as the input (output, respectively) for atomic_process.
This functional fluent is
a term in the language of the domain theory.
(Recall that the relation input (respectively
output) might associate multiple input_fluents or
output_fluents with a single atomic process.)
-
cond_formula_fluent is a relational fluent
that is true if and only if the condition upon which an output
or effect is predicated, is true.
-
precond_formula_fluent is a relational fluent
that is true if and only if the precondition formula is true.
-
effect_formula_fluent is a relational fluent
that is true if and only if the effect formula is true.
These relations have also been systematically translated into ROWS,
the SWSL-Rules ontology, as described in Section 2.5.
Formal models of software often include the inputs and outputs of the
software, but not their side effects. Formal models of processes, such
as those used in manufacturing or robotics, generally model physical
preconditions and effects, but not inputs and outputs. To relate
IOPEs in FLOWS, we intepret the inputs and (conditional) outputs of an atomic
process as knowledge preconditions and knowledge effects
[Scherl03],
respectively, following
[McIlraith01],
[Narayanan02].
Our axiomatization of atomic processes makes explicit that if a fluent
is an input (output, respectively) of an atomic process then it is
a knowledge precondition (effect, respectively) of that process.
Despite PSL's underpinnings in situation calculus, there is no explicit
treatment of epistemic fluents (knowledge fluents). As such, included
in the axiomatization of FLOWS-Core are the axioms for epistemic fluents.
Link to Axiomatization
Domain-Specific Axioms for Atomic Processes
Earlier in this section, we identified 5 classes of atomic processes.
The atomic processes associated with messages and channels are discussed
further in subsection sections relating specifically to messages and channels.
Here we discuss the axiomatization of domain-specific atomic processes.
Domain-specific atomic processes are domain specific and as
such are not part of the FLOWS ontology per se. Nevertheless, FLOWS
imposes a syntactic form on the axioms that comprise a domain-specific
axiomatization of an atomic process. Below we provide a reference
grammar for the axioms associated with inputs, outputs preconditions
and effects. In practice, we do not expect users of FLOWS to write
these axioms, but rather to provide a specification of salient features
of their process IOPEs using a high-level process description syntax that is
then compiled into the syntactically correct FLOWS axioms. The
syntax we propose is below, followed by the reference grammar.
Process Description Syntax
The IOPEs for atomic processes may be specified using the following
presentation syntax. Note that both outputs and effects may be conditional.
The BNF grammar below, captures this. A psuedo_state_formula
is a state formula whose occurrence argument is suppressed. Non-fluent
formulae in psuedo_state_formulas may be differentiated by
prefixing the relation name with an asterisk (*).
< atomicprocess_name > {
Atomic
input < input_fluent_name >
output < output_fluent_name > | < psuedo_state_formula >
< output_fluent_name >
precondition < psuedo_state_formula >
effect < psuedo_state_formula > | < psuedo_state_formula >
; < psuedo_state_formula >
}
Reference Grammar
- Precondition
Axioms (link) A precondition of an atomic process is a formula that states
that the atomic process cannot be executed until this formulae holds.
- Effect
Axioms (link) An effect of an atomic process is a formula that states that
if certain conditions hold, then execution of the atomic process will
result in other conditions holding.
- Input
Axioms (link)
Inputs are treated as knowledge preconditions. As such, an input axiom
of an atomic process is a formula that states that the atomic process
must
know the value of that input. In order for atomic process to execute,
all (knowledge) preconditions must hold.
- Output
Axioms (link) Likewise, outputs are knowledge effects. A knowledge effect of an
atomic process is aformula that states that if certain conditions hold,
then executing the atomic process will result in other knowledge conditions
holding. If the atomic process
knows the output, then the knowledge effect holds.
Walking Through an Example
Process Description Syntax
Here is the presentation syntax for an atomic process called simple_buy_book. It has two inputs, client_id and book_name,
and three outputs:
i) a confirmation of the request, ii) the book price, if the book is in stock,
and iii) an order rejection, if the book is out of stock. This simple
atomic process also has one effect. The atomic process will debit the client's
account (assumed to be on file and accessible through the client_id) by
the price of the book, if the book is in stock. Note that as with the majority
of non-device Web services, there are no (physical) preconditions associated
with the execution of that atomic process. The process must merely know
its inputs in order to execute.
simple_buy_book {
Atomic
input client_id
input book_name
output request_confirm(client_id,book_name)
output (name(book,book_name) and in_stock(book)) price(book)
ouptput (name(book,book_name) and not in_stock(book)) reject(client_id,book_name)
effect (name(book,book_name) and in_stock(book)) debit(client_id,price(book))
}
Domain-Specific Axiomatization
The process description syntax is manually or automatically compiled into the
following input and output relations:
input(simple_buy_book, client_id)
input(simple_buy_book, book_name)
output(simple_buy_book, true, request_confirm(client_id,book_name))
output(simple_buy_book, condition1(book_name), price(book))
output(simple_buy_book, condition2(book_name), reject(client_id,book_name))
effect(simple_buy_book, condition1(book_name),debit(client_id,price(book))
In order to avoid reifying formulae, we associate a unique fluent with
the condition formula of an output or effect, so that we may talk about
it in the relations output and effect.
forall ?occ,?booknm,?book
((condition1(?booknm,?occ) ==> (name(?book,?booknm) and in_stock(?book, ?occ))) and
(name(?book,?booknm) and in_stock(?book,?occ)) ==> condition1(?booknm,?occ))
forall ?occ,?booknm,?book
((condition2(?booknm,?occ) ==> (name(?book,?booknm) and not in_stock(?book,?occ))) and
(name(?book,?booknm) and in_stock(?book,?occ)) ==> condition2(?booknm,?occ))
Following the reference grammar, the IOPEs declared in the presentation
syntax are manually and automatically compiled into IOPE axioms according
to the reference grammar.
Input Axioms, i.e., Knowledge-Precondition Axioms
Each input fluent becomes a knowledge precondition of the occurrence of the
simple_buy_book atomic process. Note that there are no
non-knowledge preconditions to the execution of this atomic process.
forall ?occ,?clientid,?booknm,?book
(occurrence_of(?occ,simple_buy_book(?clientid,?booknm)) and legal(?occ)
==>
(holds(Kref(book_name(?s)),?occ) and holds(Kref(client_id(?s)),?occ))
Effect Axiom
The sole effect of execution of this atomic process is that the client's
account will be debited, if the book is in stock.
forall ?occ,?clientid,?booknm,?book
(occurrence_of(?occ,simple_buy_book(?clientid,?booknm)) and
name(?book,?booknm) and prior(in_stock(?book,?occ)
==>
holds(debit(?clientid,price(?book,?s,?occ)),?occ)
Output Axioms, i.e., Knowledge-Effect Axioms
A confirmation request is an unconditional output of the simple_buy_book atomic process.
forall ?occ,?clientid,?booknm,?book
occurrence_of(?occ,simple_buy_book(?clientid,?booknm))
==>
holds(Kref(request_confirm(?clientid,?booknm)),?occ)
If the book is in stock, then the price of the book will be an output, i.e.,
a knowledge effect of the simple_occ_book atomic process.
forall ?occ,?clientid,?booknm,?book
(occurrence_of(?occ,simple_buy_book(?clientid,?booknm)) and
name(?book,?booknm) and prior(in_stock(?book,?occ))
==>
holds(Kref(price(?book)),?occ)
If the book is not in stock, then an order rejection message is output. It
is a knowledge effect of the simple_occ_book atomic process.
forall ?occ,?clientid,?booknm,?book
(occurrence_of(?occ,simple_buy_book(?clientid,?booknm)) and
name(?book,?booknm) and not prior(in_stock(?book,?occ)))
==>
holds(Kref(reject(?clientid,?booknm)),?occ)
Building on this introduction, the example in
Section 2.1
of the
Application Scenarios document
describes a simple
hypothetical service that involves several domain-specific and
message-handling atomic processes. Application Scenario
Example 2.1(a)
illustrates, at a high level, how the
sequences of atomic process occurrences in an
occurrence (execution) of the overall system
might be constrained by the FLOWS-Core ontology axioms
and an application domain theory.
Service IOPEs
Service IOPEs, or more accurately, the IOPEs of the complex activity
associated with a service, are not formally defined.
Inputs, outputs, preconditions and effects are only
specified for atomic processes. Nevertheless, for a number of automation
tasks, including automated Web service discovery,
enactment and composition, it may be compelling
to consider the inputs, outputs, preconditions and effects of the complex
activity that describes the full process model of the service,
service_activity(service,activity).
In some cases, these properties may be inferred from the IOPEs of the
constituent atomic
processes, producing IOPEs conditional on the control constraints defining the
service. As an alternative to repeated inference, these computed IOPEs
may be added to the representation of the complex activity defining the service.
We provide a means for the axiomatizer to define the IOPEs of a complex
activity, using the relations and process description syntax described above
for atomic processes. Note that these relations are merely descriptive
and though it is desirable, the ontology does not mandate that they
reflect the IOPEs of their constituent atomic processes.
The IOPEs for complex activities are systematically translated into ROWS
using the SWSL-Rules language. They are commonly used for Web service
discovery.
Link to ROWS Axiomatization for IOPEs.
In general, the activity associated with a service can be decomposed
into subactivities associated with other services, and constraints can
be specified on the ordering and conditional execution of these
subactivities. The composedOf relation specifies how one activity is
decomposable into other activities.
Link to Axiomatization
A key aspect of several Web services standards,
including WSDL, BPEL, and WS-Choreography, is the
explicit representation and use of messages.
This fundamental approach to modeling data flow
is largely absent from OWL-S.
To enable the direct study of the semantic
implications of messages,
they are modeled as explicit
objects in the FLOWS-Core ontology.
(Although messages are represented as explicit objects,
it is nevertheless possible with FLOWS
to create an application domain in which
the messaging is transparent.
This might be done by incorporating
specific constraints into the application domain,
or by using a
views mechanism.)
Associated with messages are
message_type and payload (or "body"),
and perhaps other attributes and properties.
Messages are produced by atomic processes occurrences
of kind Produce_Message.
Every message has a message_type,
which is again an object in the FLOWS ontology.
As detailed below, these message types
will be associated with one or more (abstract) functional fluents,
which, intuitively speaking, will provide
information on how the payloads of messages of a given message
type impact the knowledge of the service activity occurrences
reading the message,
and the knowledge pre-conditions of the service attempting
to produce the message.
FLOWS-Core is agnostic about the form
of message type itself. It could be an XML datatype, a database schema,
or an OWL-like class description of a complex object.
Information about messages
can be represented in FLOWS-Core
using a 3-ary relation message_info.
message_info(msg, msg_type, payload)
where
-
msg is a message;
-
msg_type is the message type associated with msg;
-
payload is, intuitively, the value or "body"
associated with the message, generally containing structured data.
An important property of messages, which is captured in the
axiomatization of FLOWS-Core, is that the type and
payload value associated with a message are immutable.
This is suggested by the fact that messages_info
is a relation rather than a fluent -- the tuples in
relation messages_info are not time-varying.
(At first glance, the reader may find this counter-intuitive:
If a message is created and destroyed through time,
then how can information about its payload be
fixed or known "before" and "after" the message's existence?
The answer is that an interpretation of a FLOWS-Core
theory holds information about the full history of the
set of possible occurrences (executions) of the application domain
being modelled.
From that perspective, which is "outside" of the time modeled
in the domain, the relationship between a given message object and
its payload is independent of the creation and destruction
times of the message.)
In FLOWS-Core there are
three relations which relate
atomic process occurrences to the messages they access or
manipulate.
produces(o,msg), reads(o,msg), destroy_message(o,msg)
where
-
o is an AtomicProcess activity occurrence that is
reading/producing/destroying the message (respectively)
-
msg is the message that is produced/read/destroyed
(Additional constraints may apply to these activities
if channels
are in use.
This is considered in the next subsection.)
Since FLOWS-Core does not commit to the form of message types,
but only to the kinds of information that they can convey,
FLOWS-Core includes a 2-ary relation described_by.
described_by(msg_type, io_fluent)
where
-
msg_type is a message type, and
-
io_fluent is a
functional fluent, that serves
as an input for the message producing process
and as an output of the message reading process.
(Similar to atomic processes in general)
this functional fluent is
a term in the language of the domain theory,
which, intuitively speaking, is restricted in the theory
so that it takes appropriate values at those times
when there is an occurrence of a Produce_Message
or Read_Message atomic process.
(The relation
described_by
might associate multiple io_fluents with
a single msg_type, corresponding
to the different component fluent parts that can be encoded
into the payloads of messages having this message type.
Intuitively, the association of multiple io_fluents with
a message type should be interepreted as a conjunction,
e.g., saying that a message will hold both an ISBN and
a book title.)
Analogous to the treatment of the inputs and outputs of
domain-specific atomic processes, the io_fluent(s) associated
with message types are constrained by the
domain theory to correspond to appropriate values at
the times when a message of given type is being
produced or read.
In this way,
the relation described_by aids
in defining the knowledge effects of
a Read_Message activity as well as the knowledge pre-conditions
that are present for a
Produce_Message atomic process.
A Produce_Message atomic process occurrence
has the effect of creating a message
(and possibly its placement on a channel). The
payload (or "body")
of the message, in many cases, is some or all of the output of
some previous atomic process occurrence.
Indeed, a knowledge pre-condition for producing a message
will be knowing the values needed to populate this payload.
This knowledge might be derived from
parts or all of the outputs (knowledge effects) of several
previous domain-specific and/or read-message
atomic process occurrences.
In the case of communication between services, reading a message
containing particular io_fluent(s), establishes that subsequently
this io_fluent is known (to the service occurrence that read the message).
As such the io_fluent(s) can be used to establish the knowledge
preconditions of another atomic process occurrence.
Once again, establishment
of knowledge preconditions and effects
is domain-specific, and thus is not
within the purview of the FLOWS ontology. Rather, we provide a
reference grammar for the Produce_Message
and Read_Message atomic processes, which is consistent
with the reference grammar for Atomic Process.
In many models of Web services found in the standards and
the research literuature, if a message is read
by some service then it is not available to be read by any other
service.
Because of the separation of the Read_Message and Destroy_Message
atomic processes,
FLOWS-Core is more general than those models.
In particular, in some
application domains, many service activity occurrences
can read a message before it is
"destroyed".
As noted previously,
the example of
Section 2.1
(in the
Application Scenarios document)
illustrates the notions of domain-specific and message-handling
atomic processes.
Example 2.1(b) there
illustrates in particular how constraints on the
relationships of domain-specific atomic prcesses can be used to infer,
in the context of an occurrence of the overall system,
that messages with certain characteristics must
have been transmitted.
The example of
Section 2.2
provides additional illustrations of message-handling atomic processes.
Since messages are read, produced and destroyed via atomic processes, the production,
reading and destruction of messages may be explicitly encoded by a domain
axiomatizer, as special atomic processes, following the syntax for atomic
process axioms described in the Reference Grammar above.
Nevertheless, the FLOWS ontology is sufficiently expressive that the
existence of necessary activity occurrences related to messages can
be inferred from the axiomatization. This illustrates
one aspect of the power of the FLOWS
ontology.
Link to Axiomatization
As noted before,
channels are objects in the FLOWS-Core ontology,
used as an abstraction related to message-based
communication between Web services.
Intuitively, a channel holds messages
that have been "sent" and may or may not have been "received".
In FLOWS-Core, there is no requirement that
a message has to be "sent" using a channel.
However, it the message is associated with a channel,
then it must satisfy a variety of axioms.
The notion of 'channel' is inspired by, but not identical
to, the notion of 'channel' found in many process algebras.
It is typical in process algebras that the act of
transmitting a message m via a channel involves two simultaneous
actions, in which one process sends m and another process
that receives m.
In the basic notion of channels provided in FLOWS-Core
there is no requirement for this
form of simultaneity.
In FLOWS-Core,
messages in transit may be associated with at most one channel
(corresponding intuitively to the idea that the message is
being sent across that channel).
As part of an application domain,
a channel might be associated with a single source service and single
target service, or
might have multiple sources and/or targets.
Channels might be pre-defined, i.e.,
included in the definition of an application domain.
Or channels can be created/destroyed "on the fly" by
atomic process occurrences
in an application domain.
For this reason, fluents are used to hold most of the information
about channels.
We now introduce the fluents of FLOWS-Core
that are used to hold information
about channels and their associated messages.
Three of the fluents are
channel_source(c,s), channel_target(o,s'), channel_mtype(o,msg_type)
where
-
c is channel
-
s is a service, where occurrences of this service
may place messages (of appropriate type) onto this channel.
(A service may have write-access to multiple channels, even for
the same types of messages.)
-
s' is a service, where occurrences of this service
may read messages (of appropriate type) that are present in this
channel.
(A service may have read-access to multiple channels, even for
the same types of messages.)
-
msg_type is a message type, which indicates that messages
of this type may be placed on this channel.
(A channel may support multiple message types.)
The fourth fluent for channels in FLOWS-Core is
channel_mobject(c,msg)
where
-
c is channel
-
msg is a message, which is "currently" on channel c,
meaning that msg has been produced by some
atomic process occurrence, the atomic process occurrence
is a sub-occurrence of a service
occurrence that was eligible to place the message on c,
and that msg has not yet been destroyed.
As noted above, FLOWS-Core provides the possibility that
channels can be created and destroyed.
This might be accomplished by
(i) services which correspond
to human administrators,
(ii) specialized, automated services
which have essentially an administrative role,
(iii) ordinary Web services, or
(iv) atomic processes which are not associated with any service.
In any of these cases, the following kinds of
atomic processes are supported.
- Create_Channel
- Add_Channel_Source
- Add_Channel_Target
- Add_Channel_MType
- Delete_Channel_Source
- Delete_Channel_Target
- Delete_Channel_MType
- Destroy_Channel
In most cases these have straight-forward semantics.
In the case of destroying a channel, all messages on
that channel are viewed as simultaneously "destroyed".
An illustration involving the dynamic creation and modification
of channels is provided in
Section 2.2(d)
(in the
Application Scenarios document)
Channels are not required to exist; however, if they do exist, then
they satisfy the following constraints:
- If a message is contained in a channel, then it is produced by an
occurrence of a service that is a source for the channel.
- If a message is contained in a channel, then it is read by an
occurrence of a service that is a target for the channel.
Link to Axiomatization
Most Web services cannot be modeled as simple atomic processes. They
are better modeled as complex activities that are compositions
of other activities (e.g., other complex activities and/or atomic
processes). The Control Constraints extension to FLOWS-Core provides
a set of workflow or programming language style control constructs
(e.g., sequence, if-then-else, iterate, repeat-until, split,
choice, unordered)
that provide a means of specifying the behavior of Web services
as a composition of activities. Control constraints impose
constraints on the evolution of the complex activity they characterize.
As such, specifications may be partial or complete.
Reflecting some of PSL's underpinnings in the situation calculus, and
by extension Golog, these control constructs follow
the style of Web service modeling of atomic and composite processes
presented in
[McIlraith01]
and [OWL-S 1.1].
The subactivity occurrences of a Split activity are partially
ordered, such that every linear extension of the ordering corresponds
to a branch of the activity tree for the Split activity.
Link to Axiomatization
Link to Reference
Grammar
Process descriptions for Split activities specify the subactivity
occurrences whose ordering is constrained by two relations from the PSL
Ontology: soo_precedes (which imposes a linear ordering on subactivity
occurrences) and strong_parallel (which allows all possible linear
orderings on subactivity occurrences).
Process Description Syntax
< activity_name > {
Split
occurrence < subocc_varname > < subactivity_name >
< subocc_varname1 > soo_precedes < subocc_varname2 >
< subocc_varname1 > strong_parallel < subocc_varname2 >
}
Examples
buy_product(?Buyer) {
Split
occurrence ?occ1 transfer(?Fee,?Buyer,?Broker)
occurrence ?occ2 transfer(?Cost,?Buyer,?Seller)
?occ1 strong_parallel ?occ2
}
forall ?y split(buy_product(?y))
forall ?occ,?Buyer
occurrence_of(?occ,buy_product(?Buyer)) ==>
(exists ?occ1,?occ2,?Fee,?Cost,?broker,?Seller
occurrence_of(?occ1,transfer(?Fee,?Buyer,?Broker)) and
occurrence_of(?occ2 transfer(?Cost,?Buyer,?Seller)) and
subactivity_occurrence(?occ1,?occ) and
subactivity_occurrence(?occ2,?occ) and
strong_parallel(?occ1,?occ2))
The subactivity occurrences of a Sequence activity are totally ordered
(that is, the activity tree for the activity contains a unique branch).
Link to Axiomatization
Reference
Syntax
Process descriptions for Sequence activities specify the subactivity
occurrences whose ordering is constrained by one relations from the PSL
Ontology: soo_precedes (which imposes a linear ordering on subactivity
occurrences).
Process Description Syntax
< activity_name > {
Sequence
occurrence < subocc_varname > < subactivity_name >
< subocc_varname1 > soo_precedes < subocc_varname2 >
}
Examples
transfer(?Amount,?Account1,?Account2) {
Sequence
occurrence ?occ1 withdraw(?Amount,?Account1)
occurrence ?occ2 withdraw(?Amount,?Account2)
?occ1 soo_precedes ?occ2
}
forall ?x,?y,?z sequence(transfer(?x,?y,?z))
forall ?occ
occurrence_of(?occ,transfer(?Amount,?Account1,?Account2)) ==>
(exists ?occ1,?occ2
occurrence_of(?occ1,withdraw(?Amount,?Account1)) and
occurrence_of(?occ2,deposit(?Amount,?Account2)) and
subactivity_occurrence(?occ1,?occ) and
subactivity_occurrence(?occ2,?occ) and
soo_precedes(?occ1,?occ2,transfer(?Amount,?Account1,?Account2))
The subactivity occurrences of a Split activity are partially ordered,
such that all subactivities are incomparable and every linear extension
of the ordering corresponds to a branch of the activity tree.
Link to Axiomatization
Reference
Syntax
Process descriptions for Unordered activities specify the subactivity
occurrences of the activity.
Process Description Syntax
< activity_name > {
Unordered
occurrence < subocc_varname > < subactivity_name >
}
Examples
ConferenceTravel {
Unordered
occurrence ?occ1 book_flight
occurrence ?occ2 book_hotel
occurrence ?occ3 register
}
Unordered(ConferenceTravel)
forall ?occ
occurrence_of(?occ,ConferenceTravel) ==>
(exists ?occ1,?occ2,?occ3
bag(?occ) and
occurrence_of(?occ1,book_flight) and
occurrence_of(?occ2,book_hotel) and
occurrence_of(?occ3,register) and
subactivity_occurrence(?occ1,?occ) and
subactivity_occurrence(?occ2,?occ) and
subactivity_occurrence(?occ3,?occ))
A Choice activity is a nondeterministic activity in which only one of
the subactivities occurs.
Link to Axiomatization
Reference
Syntax
Process descriptions for Choice activities specify the subactivity
occurrences of the activity.
Process Description Syntax
< activity_name > {
Choice
occurrence < subocc_varname > < subactivity_name >
}
Examples
travel(?Destination) {
Choice
occurrence ?occ1 book_flight(?Destination)
occurrence ?occ2 book_train(?Destination)
}
forall ?x choice(travel,?x)
forall ?occ,?Destination
occurrence_of(?occ,travel(?Destination)) ==>
((exists ?occ1
occurrence_of(?occ1,(book_flight,?Destination)) and
subactivity_occurrence(?occ1,?occ))
or
(exists ?occ2
occurrence_of(?occ2,(book_train,?Destination)) and
subactivity_occurrence(?occ2,?occ)))
An IfThenElse activity is a nondeterministic activity such that the
subactivity which occurs depends on the state condition that holds
prior to the activity occurrence.
Link to Axiomatization
Reference
Syntax
Process descriptions for IfThenElse activities consist state
constraints on the subactivity occurrences of the activity. Each
constraint specifies a state condition and the subactivity that occurs
when the state condition is satisfied.
Process Description Syntax
< activity_name > {
IfThenElse
if < state_formula > then occurrence < subocc_varname > < subactivity_name >
}
Examples
travel(?Destination, ?Account) {
IfThenElse
if greater(budget_balance(?Account),1000) then occurrence ?occ1 book_deluxe(?Destination)
if greater(1001,budget_balance(?Account)) then occurrence ?occ2 book_economy(?Destination)
}
forall ?x IfThenElse(travel,?x)
forall ?occ,?Destination
(occurrence_of(?occ,travel(?Destination) and
prior(greater(budget_balance(?Account),1000),?occ))
==>
(exists ?occ1
occurrence_of(?occ1,book_deluxe(?Destination)) and
subactivity_occurrence(?occ1,?occ))
forall ?occ,?Destination
(occurrence_of(?occ,travel(?Destination) and
prior(greater(1000,budget_balance(?Account)),?occ))
==>
(exists ?occ2
(occurrence_of(?occ2,book_economy(?Destination)) and
subactivity_occurrence(?occ2,?occ))
An Iterate activity, is composed of a subactivity that occurs an
indeterminate number of times.
Link to Axiomatization
Reference
Syntax
Process descriptions for Iterate activities specify the subactivity
occurrences of the activity.
Process Description Syntax
< activity_name > {
Iterate
occurrence < subocc_varname > < subactivity_name >
}
Examples
In a RepeatUntil activity, there are repeated occurrences of the
subactivity until the state condition holds.
Link to Axiomatization
Link to Reference
Syntax
Process descriptions for RepeatUntil activities specify the subactivity
occurrences of the activity, and the state condition that constrains
the end of the occurrence of the activity.
Process Description Syntax
< activity_name > {
Iterate
while < state_formula > then occurrence < subocc_varname > < subactivity_name >
}
Examples
The intent of this extension is to provide
a family of simple constraints based on
sequencing properties of atomic processes.
This enables succinct specification of
requirements such as that
payment must be received before shipping.
Any branch of the activity tree of an OrderedActivity satisfies the
ordering constraints in the process description.
Note that this is weaker than the Control Constraints, since there may
exist sequences of subactivity occurrences that satisfy the ordering
constraints but which do not correspond to branches of the activity
tree for an OrderedActivity.
Link to Axiomatization
Reference
Syntax
Process descriptions for OrderedActivity specify the subactivity
occurrences and sentences using the basic ordering relation min_precedes
that is axiomatized in the PSL Ontology.
Process Description Syntax
The presentation syntax provides three constructs that facilitate the
specification of ordering constraints:
- The symbol ; is used to specify a linear ordering
constraint over the subactivity occurrences of an activity occurrence;
- The symbol , is used to specify a partial ordering
constraint over the subactivity occurrences of an activity occurrence;
- The symbol ! is used to specify an ordering constraint
in which some possible orderings over subactivity occurrences are not
allowed.
< activity_name > {
OrderedActivity
occurrence < subocc_varname > < subactivity_name >
< subocc_varname1 > ; < subocc_varname2 >
< subocc_varname1 > , < subocc_varname2 >
! < subocc_varname >
}
Examples
- In each path in the activity tree for S that contains an
occurrence of a and an occurrence of b, the subactivity a occurs before
the subactivity b.
Activity1 {
OrderedActivity
occurrence ?occ1 a
occurrence ?occ2 b
?occ1 ; ?occ2
}
forall ?occ,?occ1,?occ2
(occurrence_of(?occ,S) and
occurrence_of(?occ1,a) and
occurrence_of(?occ2,b) and
subactivity_occurrence(?occ1,?occ) and
subactivity_occurrence(?occ2,?occ))
==>
min_precedes(?occ1,?occ2,S)
- In each path in the activity tree for S, if there is an
occurrence of a and sometime after the occurrences of b and c are
partially ordered.
Activity2 {
OrderedActivity
occurrence ?occ1 a
occurrence ?occ2 b
occurrence ?occ3 c
?occ1 ; (?occ2 , ?occ3)
}
forall ?occ,?occ1,?occ2
(occurrence_of(?occ,S) and
occurrence_of(?occ1,a) and
occurrence_of(?occ2,b) and
occurrence_of(?occ2,c) and
subactivity_occurrence(?occ1,?occ) and
subactivity_occurrence(?occ2,?occ))
==>
(min_precedes(?occ1,?occ2,S) and
min_precedes(?occ1,?occ3,?S))
- In each path in the activity tree for S, there is an
occurrence of a and sometime after there then: (i) there is an
occurrence of b and a later occurrence of c, and also (ii) there is an
occurrence of d and later an occurrence of e.
Activity3 {
OrderedActivity
occurrence ?occ1 a
occurrence ?occ2 b
occurrence ?occ3 c
occurrence ?occ2.d
occurrence ?occ5 e
?occ1 ; ?occ2
?occ2 ; ?occ3
?occ1 ; ?occ2.
?occ2.; ?occ5
}
forall ?occ,?occ1,?occ2,?occ3,?occ2.?occ5
(occurrence_of(?occ,S) and
occurrence_of(?occ1,a) and
subactivity_occurrence(?occ1,?occ) and
occurrence_of(?occ2,b) and
subactivity_occurrence(?occ2,?occ) and
occurrence_of(?occ3,c) and
subactivity_occurrence(?occ3,?occ) and
occurrence_of(?occ2.d) and
subactivity_occurrence(?occ2.?occ) and
occurrence_of(?occ5,e) and
subactivity_occurrence(?occ5,?occ))
==> (min_precedes(?occ1,?occ2,S) and
min_precedes(?occ2,?occ3,S) and
min_precedes(?occ1,?occ2.S) and
min_precedes(?occ2.?occ5,S))
- In each path in the activity tree for S, there is no
occurrence of b after the occurrence of a.
Activity5 {
OrderedActivity
occurrence ?occ1 a
occurrence ?occ2 b
?occ1 ; ! ?occ2
}
forall ?occ,?occ1,?occ2
(occurrence_of(?occ,S) and
occurrence_of(?occ1,?a) and
subactivity_occurrence(?occ1,?occ) and
occurrence_of(?occ2,b) and
subactivity_occurrence(?occ2,?occ))
==> (not min_precedes(?occ1,?occ2,S))
The intent of this extension is to
make it easy to specify constaints requiring that
there are indeed occurrences of certain activities,
e.g., payments, or the transmission of certain messages.
Any branch of the activity tree of an OccActivity satisfies the
occurrence constraints on subactivities.
Link to Axiomatization
Reference
Syntax
Process descriptions for OccActivity are sentences that specify the
existence or nonexistence of subactivity occurrences within occurrences
of the activity.
Process Description Syntax
The presentation syntax provides three constructs that facilitate the
specification of occurrence constraints:
- The symbol & is used to specify a conjunctive
constraint over the subactivity occurrences of an activity occurrence;
- The symbol + is used to specify a disjunctive
constraint over the subactivity occurrences of an activity occurrence;
- The symbol &tilde is used to specify a constraint
in which some subactivity occurrences are not allowed.
< activity_name > {
OccActivity
occurrence < subocc_varname > < subactivity_name >
< subocc_varname1 > & < subocc_varname2 >
< subocc_varname1 > + < subocc_varname2 >
~ < subocc_varname >
}
Examples
- In each path in the activity tree for S, there is an
occurrence of a and an occurrence of b.
Activity1 {
OccActivity
occurrence ?occ1 a
occurrence ?occ2 b
?occ1 & ?occ2
}
forall ?occ
occurrence_of(?occ,S) ==>
(exists ?occ1,?occ2
occurrence_of(?occ1,a) and
occurrence_of(?occ2,b) and
subactivity_occurrence(?occ1,?occ) and
subactivity_occurrence(?occ2,?occ))
- In each path in the activity tree for S, there is an
occurrence of a and either an occurrence of b or an occurrence of c.
Activity2 {
OccActivity
occurrence ?occ1 a
occurrence ?occ2 b
occurrence ?occ3 c
?occ1 & (?occ2 + ?occ3)
}
forall ?occ
occurrence_of(?occ,S) ==>
(exists ?occ1
occurrence_of(?occ1,a) and
subactivity_occurrence(?occ1,?occ) and
(exists ?occ2
occurrence_of(?occ2,b) and
subactivity_occurrence(?occ2,?occ))
or
(exists ?occ3
occurrence_of(?occ3,c) and
subactivity_occurrence(?occ3,?occ)))
- In each path in the activity tree for S, there is no
occurrence of b.
Activity2.{
OccActivity
occurrence ?occ1 b
~ ?occ1
}
forall ?occ
occurrence_of(?occ,S) ==>
(not (exists ?occ1
occurrence_of(?occ1,b) and
subactivity_occurrence(?occ1,?occ)))
- In each path in the activity tree for S, there is an
occurrence of a, and after there is no occurrence of b.
Activity5 {
OccActivity
occurrence ?occ1 a
occurrence ?occ2 b
?occ1 & ~ ?occ2
}
forall ?occ
occurrence_of(?occ,S) ==>
(exists ?occ1
occurrence_of(?occ1,?a) and
subactivity_occurrence(?occ1,?occ) and
(not (exists ?occ2
(occurrence_of(?occ2,b) and
subactivity_occurrence(?occ2,?occ) and
min_precedes(?occ1,?occ2 S)))
This extension provides an explicit mechanism for
associating triggered activities with states (of an
overall system) that satisfy a given condition.
A particular use of State Constraints is in
exception handling.
A TriggeredActivity is an activity which occurs whenever a state
condition is satisfied.
Link to Axiomatization
Link to Reference
Grammar
Process descriptions for a TriggeredActivity specifies the state
condition that is associated with occurrences of the activity.
Process Description Syntax
< activity_name > {
TriggeredActivity
< state_formula >
}
Examples
Exceptions are
central elements of most process modeling languages.
For example, BPEL [BPEL 1.1],
provides mechanisms based on
faults, fault handlers, and compensation, for specifying
exceptions and their treatments.
FLOWS offers a
variety of approaches to model such exceptions, which are presented in
the following. The approaches presented below are not prescriptive.
The simplest method for
exception handling is to define an exception handler as an activity
whose occurrence is triggered by satisfaction of a state constraint.
An exception handler is defined as an activity that gets triggered when
a specified (exceptional) state occurs. Consequently, the triggered
activity state constraint (see section 2.2.5.1 above) can be used.
Process Description Syntax
< activity_name > {
ExceptionHandlerActivity
< exception_state_formula >
}
Most process modeling
approaches and programming languages (such as Java [Gosling96]) require
exceptions either to be raised or ("thrown") explicitly by
a modeled element (i.e., a process) or by the execution environment. A
raised exception is then sequentially passed to exception handler,
which have registered for it. Essentially, this approach represents the
raising of a "message" which describes the exception and the catching
(or consuming) of this message by some type of handler.
We place the term 'message' in quotes because this can be embodied
in two ways in the conceptual model presented here.
In the first embodiment, these "messages" would be messages between
Web services, i.e., messages in the sense described above.
In the second embodiment, these "messages" would be
internal to a Web service, and would involve the passing
of information from one family of activities in the
service (intuitively, the main body of the service) to
another family of activities in the service
(intuitively, the exception-handling or fault-handling
portion of the service).
In either case, the creation and transmission of an
exception-based "message" can be modeled as a refinement
of the notion of state-based exception handling.
In particular, if the system is in a state in which an exception
condition is satisfied, then an activity that creates or
in some other way embodies a "message" transmission
is triggered.
Exceptions get raised explicitly as messages to the parent activity.
The parent activity can explicitly register an exception handler to
listen for the specific exception message to be raised. If no exception
handler is registered, then the mechanism "executing" the specification
will be informed of the exception and may halt the execution of the
overall process.
Process Description Syntax
If the activity raising the exception is not an AtomicProcess,
then the service description satisfies the following syntax:
< exception_raising_activity_name > {
Unordered | Split | Sequence | Choice | IfThenElse | Iterate | RepeatUntil
...
occurrence ?occ RaiseException(< exception_name > )
...
}
< exception_raising_activity_name > {
Unordered | Split | Sequence | Choice | IfThenElse | Iterate | RepeatUntil
...
occurrence < subocc_varname > < subactivity_name >
...
raises_exception < exception_name >
}
If the activity raising the exception is an AtomicProcess, then
the service description satisfies the following syntax:
< exception_raising_activity_name > {
Atomic
input < input_fluent_name >
output < output_fluent_name > | < psuedo_state_formula >
< output_fluent_name >
precondition < psuedo_state_formula >
effect < psuedo_state_formula > | < psuedo_state_formula >
< psuedo_state_formula >
raises_exception < exception_name >
}
If the activity catching the exception is not an AtomicProcess,
then the service description satisfies the following syntax:
< exception_raising_activity_name > {
Unordered | Split | Sequence | Choice | IfThenElse | Iterate | RepeatUntil
...
occurrence < subocc_varname > < subactivity_name >
...
catches_exception < exception_name >
}
If the activity catching the exception is an AtomicProcess,
then the service description satisfies the following syntax:
< exception_raising_activity_name > {
Atomic
input < input_fluent_name >
output < output_fluent_name > | < psuedo_state_formula > < output_fluent_name >
precondition < psuedo_state_formula >
effect < psuedo_state_formula > | < psuedo_state_formula >
< psuedo_state_formula >
catches_exception < exception_name >
}
Intended Semantics
The intended semantics for the extended exception handling
mechanism are described in great detail in [Klein 00a, Klein 00b].
Summarized it is the following (see also Figure 2.2):
- Any activity can have a number of possible exceptions that might
occur during is execution.
- Any exception can be handled by a number of exception handlers.
- The exception handling either attempts to find or fix the
exception.
- When finding the exception it can either be detected during
execution using some description of the exceptional state or some it
can be anticipated. Anticipation means that the exception handler
detects that an exception will occur if no "evasive action" is taken,
i.e., nothing is changed from the current planned course of activities.
- When fixing an exception, it can either be resolved (i.e, ex
post to its occurrence) or avoided (ex ante to its occurrence).
- Resolution "fixes" (or handles) the exceptional state by
transforming it into a "regular" (or non-exceptional) one.
- Avoidance runs a procedure that ensures that an exceptional
state will not arise (e.g., purchasing health care avoids large
financial loss in the case of a sickness). It is run ex ante to the
(possible) occurrence of the exception.
- Each of the exception handling types (anticipation, detection,
resolution, avoidance) relates the exception to an exception handler of
the respective type.
This setup allows to
develop hierarchy of exception types (similar to Java), where each
exception is associated with a (potentially domain independent)
collection different exception handlers (see [Klein 00a] Figure 7 for an
example).
The various approaches to
exception handling within SWSL are illustrated in the application
scenarios below
Link to Axiomatization
Process Description Syntax
The process description for the exception itself satisfies the
following syntax:
< exception_name > {
is_handled_by < exception_handling_activity_name >
is_found_by < exception_finding_activity_name >
is_fixed_by < exception_fixing_activity_name >
is_detected_by < exception_detection_activity_name >
is_anticipated_by < exception_anticipation_activity_name >
is_avoided_by < exception_avoidance_activity_name >
is_resolved_by < exception_resolution_activity_name >
}
If the activity raising the exception is not an AtomicProcess,
then the service description satisfies the following syntax:
< exception_raising_activity_name > {
Unordered | Split | Sequence | Choice | IfThenElse | Iterate | RepeatUntil
...
occurrence ?occ RaiseException(< exception_name > )
...
}
< exception_raising_activity_name > {
Unordered | Split | Sequence | Choice | IfThenElse | Iterate | RepeatUntil
...
occurrence < subocc_varname > < subactivity_name >
...
raises_exception < exception_name >
}
If the activity raising the exception is an AtomicProcess,
then the service description satisfies the following syntax:
< exception_raising_activity_name > {
Atomic
input < input_fluent_name >
output < output_fluent_name > | < psuedo_state_formula > < output_fluent_name >
precondition < psuedo_state_formula >
effect < psuedo_state_formula > | < psuedo_state_formula >
< psuedo_state_formula >
raises_exception < exception_name >
}
This subsection briefly describes some other possible extensions
to FLOWS-Core.
The intention here is to briefly indicate how FLOWS-Core can indeed
serve as a foundation for the formal study of
several models and approaches to Web services found in
standards and in the literature.
This underscores the fact that FLOWS-Core can serve as a
common foundation for a unified study of two or more
currently disparate Web services models.
This section describes a modeling construct
above FLOWS-Core, that could be used as the basis for
a PSL extension of FLOWS-Core.
In many models and standards for Web services, including BPEL, the Roman
model, the Conversation model, and the Guarded Automata model, it is
typical to consider both Web services and the
Web servers that run them. In essence, a Web server is an
executing process (i.e., an occurrence of some PSL complex activity) that
has the ability to "launch" occurrences of one or more kinds of service
activities (i.e., that includes atomic processes whose occurrences have
the impact of creating service activity occurrences). The extension
Meta-Server is intended to capture salient aspects of such frameworks.
In this possible extension, a (Formal) Server is
itself a Formal Service.
There could be a fluent
server_service(Server:activity, Service:activity),
where server_service(R, S) has the
intuitive meaning that Server R is managing Service S.
A Server R will include at least the
following kind of service-specific atomic process:
- Launch_Service_Occurrence:
An occurrence of this kind of atomic process
has the effect of creating a new occurrence of
some Service associated with
the Server (by the fluent
server_service).
Occurrences of activities of this type
will typically include the creation of
a message,
which is read as the first atomic process
occurrence of the newly launched service occurrence.
A Formal Service may have other kinds of atomic processes.
For example, it is typical that it would have
Read_Message atomic processes.
In typical application, a Server would only
read messages that are intended to launch
new occurrences of a Service that is managed
by the Server.
It is also natural to include Destroy_Message.
Axioms would enforce that a Server R can
launch occurrences of Service S only if
server_service(R, S) holds.
Furthermore, each Service can be associated with at
most one Server in server_service.
An illustration of a Server is provided in
Section 2.2(c)
(in the
Application Scenarios document)
(In [BPEL 1.1]
(and in BPEL 1.0),
messages which are intended to
launch new occurrences of a service activity, have the value of
special-purpose parameter createInstance set to
"yes"; messages intended for existing service activity occurrences
have this parameter set to "no".
In BPEL 1.1, it is required that the first step
of the newly launched service activity occurrence
is the receiving of the launching message.
In the Meta-Service extension here we have the
Server actually read (in essence, receive) the message.
It is possible to build a theory that builds on Meta-Service
to capture the semantics of Service launching as specified in BPEL 1.1.)
Although not explicitly included in the description of the
potential extension Meta-Server presented here,
it is possible in an application domain to include additional
atomic processes with a server, which intuitively have
the impact of terminating services associated with the server,
or monitoring their execution.
A server may also have atomic processes that
embody administrative actions, such as
creating/destroying channels.
We note that in practice, it will be typical to associate
a family of domain-specific fluents with a server, with
a constraint that only services associated by
server_service with that
server are able to access or update those fluents.
3.7.2 Local Store
This possible extension provides constructs for explicitly modeling
that a Web service has a variable-based local store with
imperative commands for assigning and accessing
values associated with the variables.
The use of a local store is found in
[BPEL 1.1],
and in theoretical models such as Guarded Automata.
These constructs are not included in the
FLOWS-Core, to permit the exploration
of other forms of information passing (e.g.,
in the style of functional programming or based
on a style inspired by data flow).
3.7.3 Ordered Channels, Read & Destroy, FIFO queues
This section describes three possible extensions to FLOWS-Core. These
may be particularly useful because they capture an approach for managing
messages common to many Web service implementations.
The Ordered channels possible extension
would include axioms that would enforce, intuitively speaking,
that all or some of the channels include an ordering for
the message objects that are held in the channel at a given
time.
This ordering might be total or partial.
The Read & destroy possible extension
would include axioms which have the intuitive
meaning that whenever a service occurrence reads a message,
then in the very next step of execution that
occurrence destroys that message.
This will imply that each message is read at most
once (because it is destroyed immediately thereafter).
This restriction corresponds to an assumption made by
many Web services models, including, e.g.,
[BPEL 1.1]
and Guarded Automata.
The FIFO message queue possible extension
is intended to
captures the standard first-in-first-out behavior
for channels.
This extension
would build on top of the
Ordered channels and Read & destroy extensions.
This would include axioms so that the (relevant) channels
have a total ordering on contained message objects,
that whenever a message is placed on the channel it
has the least position in the ordering;
that if a message is read (and destroyed) from the
channel then it must have the greatest position in the channel;
and that the relative ordering of messages on a channel
and that the relative ordering of messages on a channel
never changes during their existence.
3.7.2 Potential Extensions for Relation-valued and XML-valued
Parameters
FLOWS-Core is very general with regards to
the types of values that can be used in parameters,
both as input or output of domain-specific atomic processes,
and as the payload of messages.
In some cases, it may be useful to create theories or
extensions on top of PSL-Core, that can be used for
"encoding" and "decoding" certain kinds of commonly arising payloads.
We briefly consider here one way in which a uniform approach
can be developed for "encoding" and "decoding" paramater values that
are essentially relations, i.e., finite sets of records with
uniform type.
(Other encodings are possible.)
The basic approach to representing this is illustrated
in
Section 2.2(a)
(in the
Application Scenarios document)
by fluents such as Transport_content_lists. In that
example, an occurrence of the Warehouse_order_fulfillment
service can perform an occurrence o of the
activity send_shipment_from_warehouse using a
parameter transport_content_list_idR as the value
of this parameter for o. Under the intended operation, the
actual contents of the shipment can be obtained from fluent
Transport_content_lists.
by selecting on "transport_content_list_id = R"
and then projecting out the
transport_content_list_id field.
This will give a set of records with signature
item_id:int, quantity:int.
A similar encoding schema can be used for relation-valued
parameters with different signatures,
and an analogous encoding can be formulated for
XML-Valued Parameters.
3.7.5 Relationships Relevant to BPEL
We briefly describe here several modeling constructs
that lie above
FLOWS-Core, in order to build up to a
representation of the process model aspects of
services described using
[BPEL 1.1].
We also suggest a refinement of BPEL, called here BPEL++,
which incorporates the use of meta-service,
and specific design choices on how messages
are passed between BPEL services.
-
Roles can provide constructs for
explicit modeling of the notion that "roles" can
be associated with (web) services; these can
provide some structure in specifying the macro-structure
of the intended business logic to be supported
by a family of interoperating services, and
in particular provide guidance on substitutability
of services.
-
A WSDL possible extension might formally specify the
basic building blocks of the WSDL standards
(e.g., [WSDL 1.1]).
-
Enactment Naming
could provide a mechanism for having explicit names
for the enactments (i.e., occurrences)
of service activities; this
might be used, for example, to provide a formal
basis for studying the properties of
"correlation sets" as found in BPEL
[BPEL 1.1].
-
XML-Valued Parameters could provide mechanisms
to represent parameters, of both messages and
input/output arguments for atomic "world-changing"
activities.
All of these possible extensions,
along with possible extensions for
Local store, Control constructs and Exceptions,
can be used in
defining a possible extension BPEL(process),
which can serve as a formal, declarative specification of
essential aspects of some version of BPEL
(e.g., [BPEL 1.1]).
The BPEL(process) possible extension
in turn might be combined with Meta-service and
FIFO Message Queue
to create a possible extension BPEL++(process),
which can incorporate
often made assumptions concerning message passing semantics that
are not explicitly mentioned in the BPEL 1.1 specification.
3.7.6 Potential Extensions for the Roman and Guarded Automata Models
In many approaches to Web services,
including
[BPEL 1.1],
a flowchart-based process model is used to specify the
internal process flow of Web services.
This approach is also found in OWL-S, and
is essentially embodied in the Control Constructs extension
of FLOWS-Core.
In this section we briefly consider an alternative basis for
the internal process model of Web services, based on the
use of automata.
Of course, there are other process modeling paradigms that
may also be considered,
including e.g., Petri nets and models, such as some process algebras,
with unbounded sub-process spawning (see also
the example in
Section 2.3
of the
Application Scenarios document).
We mention two important automata-based approaches from the literature.
-
Roman model.
This model [Berardi03]
provides an abstraction of human-machine Web services.
The focus is primarily on (a) atomic processes that
can be performed by a Web service, and
(b) the use of an automata-based representation of
a Web service process model.
With this model an important theoretical result
concerning automated discovery and composition
of Web services has been obtained,
underscoring the value of using an automata-based framework.
-
Guarded automata model.
An important study here
[Fu04] develops a model
of Guarded finite-state automata suitable for Web services,
and shows how BPEL [BPEL 1.1]
programs can be simulated using them.
Interestingly, the model used can simulate BPEL programs.
Furthermore, verification techniques have been developed
for this model.
Section 2.2(b)
(in the
Application Scenarios document)
gives a brief
illustration of how a guarded automaton can be used to
specify the process model of a service.
The SWSO concepts for service description (as described in Section 3 of this document), and the instantiations
of these concepts that describe a particular service, are
abstract specifications, in the sense that they do not specify
the details of particular message formats, transport protocols, and network
addresses by which a Web service is accessed. The role of
the grounding is to provide these more concrete
details.
The Web Services Description Language (WSDL), developed independently
of SWSL and SWSO, provides a well developed means of specifying these
kinds of details, and is already in widespread use within the
commercial Web services community. Therefore, we can ground a
SWSO service description by defining mappings from certain SWSO
concepts to WSDL constructs that describe the concrete realizations of
these concepts. (For example, SWSO's concept of message can be
mapped onto WSDL's elements that describe messages.) These mappings
are based upon the observation that SWSL's concept of grounding is
generally consistent with WSDL's concept of binding. As a
result, it is a straightforward task to ground a SWSL service
description to a WSDL service description, and thus take advantage of
WSDL features that allow for the lower-level specification of details
related to interoperability between services and service users.
In this release of SWSF, we give a sketch of the essential elements
of grounding to WSDL, rather than a complete specification. Our
approach here is similar to the WSDL grounding specified in [OWL-S 1.1]. We rely upon the
soon-to-be-finalized WSDL 2.0 specification [WSDL 2.0]), which is in last call as of this
writing.
Note that SWSO groundings are deliberately decoupled from SWSO abstract service
descriptions, so as to enable reusability. An abstract service
specification (say, for a bookselling service) can be coupled with one grounding in
one context (say, when deployed by one online bookseller) and coupled with a
different grounding (when deployed by a second online bookseller). The two
booksellers would have completely distinct groundings, which would of course
specify different network addresses for contacting their services,
but could also specify quite different message formats.
The approach described here allows a service developer, who is going
to provide service descriptions for use by potential clients, to take
advantage of the complementary strengths of these two specification
languages. On the one hand (the abstract side of a service
specification), the developer benefits by making use of SWSO's process
model, and the expressiveness of SWSO ontologies, relative to what XML
Schema Definition (XSD) provides. On the other hand (the concrete
side), the developer benefits from the opportunity to reuse the
extensive work done in WSDL (and related languages such as SOAP), and
software support for message exchanges based on WSDL declarations, as
defined to date for various protocols and transport mechanisms.
Whereas a default WSDL specification refers only to XSD primitive data
types, and composite data types defined using XSD, a SWSO/WSDL
specification can refer to SWSO classes and other types defined in
SWSO (in addition to the XSD primitive and defined types). These
types can, if desired, be used directly by WSDL-enabled services, as
supported by WSDL type extension mechanisms. In this case the SWSO
types can either be defined within the WSDL spec, or defined in a
separate document and referred to from within the WSDL spec. However,
it is not necessary to construct WSDL-enabled services that use SWSO
types directly in this manner. When they are not used
directly, translation mechanisms such as those outlined below may be
used to spell out the relationships between the SWSO types and the
corresponding XML Schema types used in the default style of WSDL
definition.
We emphasize that an SWSO/WSDL grounding involves a
complementary use of the two languages, in a way that is in
accord with the intentions of the authors of WSDL. Both languages are
required for the full specification of a grounding. This is because
the two languages do not cover the same conceptual space. The two
languages do overlap, to a degree, in that they both provide
for the specification of "types" associated with message contents.
WSDL, by default, specifies the types of message contents using XML
Schema, and is primarily concerned with defining valid, checkable
syntax for message contents. SWSO, on the other hand, does not
constrain syntax at all, but rather allows for the definition of
abstract types that are associated with logical assertions (IO
fluents) in a knowledge base. WSDL/XSD is unable to express the
semantics associated with SWSO concepts. Similarly, SWSO has no means
to define legal syntax or to declare the binding information that WSDL
captures. Thus, it is natural that a SWSO/WSDL grounding uses SWSO
types as the abstract types of messages declared in WSDL, and then
relies on WSDL binding constructs to specify the syntax and formatting of the
messages.
Web services are inherently message-oriented, and messages are also
the central concern in the grounding of a SWSO service. The essence
of this grounding approach is to establish a mapping between selected
message-oriented constructs in SWSO and their counterparts in WSDL
service descriptions.
To elucidate the requirements for the grounding, and clarify
the scope of the current effort, we consider a hypothetical service
enactment environment, or execution engine, based on SWSO; that is, a
software system that enacts processes described using SWSO's process
model. We assume that this system incorporates a knowledge base that
contains the relevant SWSO service descriptions, and manages the
fluents associated with service execution, as described earlier in
this document. We call a system of this type a Semantic Web Services
Execution Environment (SWSEE).
The primary motivation for this grounding approach is to make it possible for a
SWSEE to handle messages that conform to WSDL service specifications.
We want to allow for scenarios in which a SWSEE plays the role of a
service provider (that is, manages the communications associated with
a service from the provider's point of view), a service user, or
both. When acting as a service provider, a SWSEE will need to accept a
WSDL input message, extract the needed pieces of information from
its content, and assert them into the knowledge base in accordance
with the SWSO declarations of input fluents. This step of handling an
input message, as a service provider, would happen in correspondence
with the execution of a Read_Message atomic process. In addition, a
service-providing SWSEE will need to generate outputs
in correspondence with Produce_Message atomics, by
pulling information from its knowledge base and formatting it into
appropriate WSDL-conformant output messages.
Conversely, when acting as a service user (invoker), a SWSEE
will need to execute a Produce_Message atomic for the purpose of
invoking a remote Web service. In correspondence with this atomic
activity, the SWSEE will need to produce a WSDL-conformant message to
send to the remote service. (This message will be an input from the
WSDL perspective, but an output from the SWSEE perspective in this
situation.) Following that, it may need to receive a return message
from the WSDL service, and will this will be done by a Read_Message
atomic.
In designing these basic grounding mechanisms, we are noncommittal
about the architectural role of a SWSEE. So as to be general and
avoid relying on any particular architectural commitments, our
approach here is minimalist. For example, we do not explain the
mechanisms by which a SWSEE might arrange to make a
run-time selection and binding to a particular WSDL service.
Rather, we are concerned only with essential representational
requirements that will be needed by the builders of enactment
environments: we seek to provide a common denominator of
representation by which the relationships between elements of WSDL and
SWSO service descriptions can be declared.
Thus, the role of the SWSO/WSDL grounding (or at least the most
central role) may be conceived as follows: it provides a SWSEE with
the information it needs at runtime to handle (both send and receive)
messages associated with WSDL service descriptions. To do this, it
must provide the following things:
-
mappings between SWSO and WSDL elements that specify message patterns
-
mappings between SWSO's
(abstract) message types and the concrete message types declared in WSDL
-
specification of a method for translating from an abstract message
type to the corresponding concrete message type (i.e., serializing the
abstract message type into the concrete message type)
-
specification of a method for translating from a concrete message type
to the corresponding abstract message type (i.e., deserializing the
concrete message type into the abstract message type)
In addition to the above, it is also desirable to provide the
following:
-
specification of a default declarative style for providing (3)
-
specification of a default declarative style for providing (4)
We briefly describe each of these aspects of the grounding in turn.
The needed mappings will be provided by introducing several new SWSO
relations here. These relations differ from the process model
relations of Section 3 in that they are
not axiomatized. This is because they provide mappings to external
entities (declared in WSDL) that are outside the scope of SWSO
axiomatization.
In WSDL 2.0 an operation declares a set of messages that are used in
accordance with a message pattern, as in this simple example from the
[WSDL 2.0 Primer]:
<operation name="opCheckAvailability"
pattern="http://www.w3.org/2004/03/wsdl/in-out"
style="http://www.w3.org/2004/08/wsdl/style/uri"
safe = "true">
<input messageLabel="In"
element="ghns:checkAvailability" />
<output messageLabel="Out"
element="ghns:checkAvailabilityResponse" />
<outfault ref="tns:invalidDataFault" messageLabel="Out"/>
</operation>
Here the message pattern is in-out (declared elsewhere). Each
input/output message declaration gives an XML Schema
document type (e.g., ghns:checkAvailability) and a label (e.g., In)
that shows where the message is used in the pattern.
The correspondence to SWSO is this:
-
A WSDL operation corresponds to a SWSO complex activity with one or
more Produce_Message and Read_Message atomics as subprocesses.
(Note: once this correspondence is established, details of network
address and protocol come along "for free", by means of WSDL's binding constructs.)
-
A WSDL message pattern corresponds to the pattern of messages produced
and read by the Produce_Message and Read_Message atomics included
within the control structure of the complex activity.
To indicate this mapping, we introduce a single SWSO relation:
activity_grounding(activity, wsdl_operation)
where activity refers to a complex activity declared in a SWSO service
description, and wsdl_operation is a URL for a WSDL operation declaration.
As discussed in Section 3.1.4, SWSO's
process model is silent as to the concrete form (syntax,
serialization) associated with a message type. The nature of a
message type is characterized abstractly, by associating it with one
or more IO fluents, using the described_by relation. One central job of the
grounding, then, is to specify a concrete syntax for each
SWSO message type. In WSDL these concrete syntaxes are normally given
by "message types" declared using XML Schema declarations. To distinguish
these message types from those of SWSO, we refer to those of WSDL as "concrete
message types".
We note that WSDL allows for the use of type specifications using
other mechanisms than XML Schema. In this document, however, for
simplicity, we assume the use of XML Schema in WSDL service descriptions.
To specify the concrete syntax associated with a SWSO message type, we
introduce the relation
message_type_grounding(msg_type, wsdl_operation, wsdl_message_label)
where msg_type is an identifier for a message type defined using SWSO,
wsdl_operation is a URI for an operation defined in a WSDL
specification, and wsdl_message_label is a label used within that
operation definition. The meaning of an instance of this relation is
simply that a message of the given SWSO message type corresponds to a
WSDL message declared with the given label, within the given WSDL operation.
In addition to showing the correspondence of SWSO message types with
WSDL concrete message types, a grounding should indicate a precise method for
constructing WSDL message content from SWSO message content. For this
purpose we provide the message_serialization_method relation:
message_serialization_method(msg_type, wsdl_operation, wsdl_message_label, method)
The meaning of an instance of this relation is that a message of the
given SWSO message type will be serialized appropriately for the WSDL
message having the given label within the given operation. The
serialization will be performed by the specified method.
In general this allows for an arbitrary method, which could be
external (e.g., it could be a Java method). Therefore, we do not
specify what kind of thing method refers to; this should be
defined by each particular SWSEE implementation.
The specified method retrieves the information
associated with the given message type by querying the knowledge base
(in particular, the IO fluents for that message type), and generates
the appropriate WSDL message containing that information.
msg_type, wsdl_operation, and wsdl_message_label are as described for message_type_grounding.
In Section 4.2.5, we sketch a means by which this translation method can
be specified in a more declarative style.
The grounding must also specify how the various parts of an individual
WSDL message get mapped into the fluents associated with that message
type. This is done using the message_deserialization_method relation:
message_deserialization_method(wsdl_operation, wsdl_msg_label, msg_type, method)
The meaning of an instance of this relation is that a WSDL message,
having the given label within the given operation, will be deserialized
into the given SWSO message type, by the specified method.
As with
message_serialization_method, method
is regarded as external and implementation-defined.
The specified method takes an arbitrary message of the kind specified
by the given message label (within the given WSDL operation), extracts
the information content from that message, and
asserts the appropriate IO fluents into the knowledge base.
msg_type, wsdl_operation, and
wsdl_message_label are as described above for
message_type_grounding.
In Section 4.2.6, we sketch a means by which this translation method can
be specified in a more declarative style.
Here, we sketch a general declarative means for specifying the
serialization of a message of a given SWSO message type into a
concrete message type specified in WSDL, which could be used as an
alternative to declaring a message serialization method. The idea
here is to use a knowledge base query to extract information from the
IO fluents within the SWSEE's knowledge base, and use a message
generation script to generate a message containing that information.
The information is passed from the query to the message generation
script by means of variable bindings. This approach is supported by
the message_serialization relation:
message_serialization(msg_type, wsdl_operation, wsdl_msg_label, kb_query, msg_generation_script)
msg_type refers to a SWSO message type.
The second and third arguments are references to a WSDL message element, as used in
message_serialization_method and
message_deserialization_method, above.
kb_query is a query expression, containing variables,
that extracts the needed information from IO fluents in the knowledge
base and binds the variables to that information. We do not specify a
particular query language in this document. A SWSL-based
query language, yet to be developed, is a possibility.
msg_generation_script is a script in a language such as
XSLT [XSLT] that is suitable for
generating an XML document. Variables mentioned in the script would
correspond to variables mentioned in the KB query, and would be bound
to the query's return values before the script is executed.
The meaning of an instance of this relation is that a message of the
given SWSO message type will be serialized appropriately into the WSDL
message having the given label within the given operation. The
serialization will result by running the message generation script
with variables bound as described above.
Here, we sketch a general declarative means for specifying the
deserialization of a message of a given concrete message type (as specified
in WSDL). This approach may be regarded as the inverse functionality
of that specified using message_serialization. The idea
here is to use a document query language to extract information from
the concrete message content, and use an update script to insert that
information into a SWSEE's knowledge base. The information is passed
from the document query to the update script by means of variable
bindings. This approach is
supported by the message_deserialization relation:
message_deserialization(wsdl_operation, wsdl_msg_label, msg_type, msg_query, kb_update_script)
The first two arguments, as above, refer to a WSDL message declaration
(within an operation declaration), and the third refers to a SWSO
message type.
msg_query is a document query expression, containing variables,
that extracts the needed information from in the knowledge
base and binds the variables to that information. We do not specify a
particular document query language in this document, but XQuery
[XQuery 1.0] would be a natural candidate.
kb_update_script is a script in a knowledge base update language. Variables
bound in the update script would correspond to variables mentioned
in the message query, and would be bound to the query's return values
before the script is executed.
The preceding material of this section describes FLOWS, the
First-Order Logic Ontology for Web Services, which is expressed in
SWSL-FOL. To enable implementations in reasoning and execution
environments based on logic-programming,
we provide, in
Appendix C,
the Rules Ontology
for Web Services (ROWS). ROWS is a (partial) translation of FLOWS
into SWSL-Rules. The intent of each ROWS axiom is identical to what
is explained above for the corresponding axioms of FLOWS. However,
because SWSL-Rules is inherently less expressive than SWSL-FOL, some
axioms in ROWS are weakened with respect to the corresponding axiom in
SWSL-FOL. The strategies by which the axioms have been translated
into SWSL-Rules are summarized in Section 5 below.
ROWS also defines several top-level classes, which correspond to similar
classes in FLOWS. These classes
are Service,
Process,
AtomicProcess,
Message,
and Channel.
Services and service descriptors.
The Service class is defined by its descriptors and the process
associated with the service.
Service descriptors are defined
in Section 2 and processes
in Section 3.1.
prefix xsd = "http://www.w3.org/2001/XMLSchema".
Service[
name *=> xsd#string,
author *=> xsd#string,
contactInformation *=> xsd#string,
contributor *=> xsd#string,
description *=> xsd#string,
url *=> xsd#string,
identifier *=> xsd#string,
version *=> xsd#string,
releaseDate *=> xsd#date,
language *=> xsd#string,
subject *=> xsd#string,
trust *=> xsd#string,
reliability *=> xsd#string,
cost *=> xsd#string
].
Some of the above string-datatypes may be replaced with more
appropriate data types later. For instance, the type of
the cost descriptor may be replaced with a
type that supports currencies and even compelex arrangements such as payment
plans.
Processes and IOPEs.
In addition to the descriptors, the Service class has the
process attribute, which specifies the process associated with
the service. It is defined as follows:
Service[
process *=> Process
].
where the Process class has the following attributes:
Process[
precondition *=> Formula,
effect *=> Formula,
input *=> ProcessInput,
output *=> ProcessOutput
].
Here Formula is a built-in class that consists of all
reifications of formulas in SWSL-Rules and ProcessInput and
ProcessOutput are classes that determine the structure of
inputs and outputs of processes. They will be defined in a
future release.
In addition, the AtomicProcess class
of Section 3.1 is defined as a subclass of
Process:
AtomicProcess :: Process.
Messages and channels.
The Message and the Channel classes
are declared as follows:
Message[
type *=> MessageType,
body *=> MessageBody,
producer *=> AtomicProcess
].
Channel[
contents *=> Message,
source *=> Service,
target *=> Service
].
where the classes MessageType and MessageBody,
which are used to specify the ranges of the attributes type and
body in class Message, will be
defined in a future release.
6.1 Ontology of the
Process Specification Language
The semantics of concepts in FLOWS is formally axiomatized using
ontology of ISO 18629 ( Process
Specification Language )
[Gruninger03a],
[Gruninger03b].
The complete set of axioms for the PSL Ontology can be found at PSL Ontology .
FLOWS adopts the basic ontological commitments of ISO 18629-11 (
PSL-Core ):
- There are four kinds of entities required for reasoning about
processes -- activities, activity occurrences, timepoints, and objects.
- Activities may have multiple occurrences, or there may exist
activities that do not occur at all.
- Timepoints are linearly ordered, forwards into the future, and
backwards into the past.
- Activity occurrences and objects are associated with unique
timepoints that mark the begin and end of the occurrence or object.
Some key predicates in PSL-Core include
activity(?a) which holds
when the value of ?a is an activity in
a given interpretation, and
occurrence_of(?occ, ?a) which
holds when the value associated with ?occ
is an occurrence (intuitively, an execution) of the
activity associated with ?a.
PSL-Core also provides terms and predicates for describing
chronological time and relating the activity occurrences to time
(e.g., term beginof(?occ) corresponds to the
time point at which ?occ begins, and
predicate before(?t1,?t2) holds if
the value of ?t1 is chronologically before
the value of ?t2).
The axiomatization of FLOWS also requires the extensions in ISO
18629-12 ( PSL
Outer-Core ):
- Subactivity
Theory
The PSL Ontology uses the subactivity relation to
capture the basic intuitions for the composition of activities. This
relation is a discrete partial ordering, in which primitive activities
are the minimal elements.
The primary predicate that is axiomatized in this extension is
subactivity(?a1,?a2),
which holds when activity ?a1
is component activity of
activity ?a2.
- Occurrence
Trees Theory
The occurrence trees that are axiomatized in this core theory
are partially ordered sets of activity occurrences, such that for a
given set of activities, all discrete sequences of their occurrences
are branches of the tree. An occurrence tree contains all occurrences
of all activities; it is not simply the set of occurrences of a
particular (possibly complex) activity.
- Discrete
State Theory
This core theory introduces the notion of state (fluents).
Fluents are changed only by the occurrence of activities, and fluents
do not change during the occurrence of primitive activities. In
addition, activities have preconditions (fluents that must hold before
an occurrence) and effects (fluents that always hold after an
occurrence).
- Atomic
Activities Theory
This core theory axiomatizes intuitions about the concurrent
aggregation of primitive activities. This concurrent aggregation is
represented by the occurrence of concurrent activities, rather than
concurrent activity occurrences.
In particular, occurrences of atomic activities
are non-decomposable (e.g., in the sense of database concurrency)
-- the occurrence is not interleaved with
other activity occurrences, and all aspects of the occurrence
are completed.
- Complex
Activity Theory
This core theory characterizes the relationship between the
occurrence of a complex activity and occurrences of its subactivities.
Occurrences of complex activities correspond to sets of occurrences of
subactivities; in particular, these sets are subtrees of the occurrence
tree. An activity tree consists of all possible sequences of atomic
subactivity occurrences beginning from a root subactivity occurrence.
In a sense, activity trees are a microcosm of the occurrence tree, in
which we consider all of the ways in which the world unfolds in the
context of an occurrence of the complex activity.
Different subactivities may occur on different branches of the
activity tree, so that different occurrences of an activity may have
different subactivity occurrences or different orderings on the same
subactivity occurrences. In this sense, branches of the activity tree
characterize the nondeterminism that arises from different ordering
constraints or iteration.
An activity will in general have multiple activity trees within
an occurrence tree, and not all activity trees for an activity need be
isomorphic. Different activity trees for the same activity can have
different subactivity occurrences. Following this intuition, this core
theory does not constrain which subactivities occur.
- Complex
Activity Occurrence Theory
Within the Complex Activity Theory, complex activity occurrences
correspond to activity trees, and consequently occurrences of complex
activities are not elements of the legal occurrence tree. The axioms of
the Activity Occurrences core theory ensure that complex activity
occurrences correspond to branches of activity trees. Each complex
activity occurrence has a unique atomic root occurrence and each finite
complex activity occurrence has a unique atomic leaf occurrence. A
subactivity occurrence corresponds to a sub-branch of the branch
corresponding to the complex activity occurrence.
The primary relation is subactivity_occurrence(?occ1,?occ2),
which holds in an interpretation
when the occurrence ?occ1
(which can be viewed as a set of one or more atomic occurrences
in one branch of the execution tree)
is a subset of the occurrence ?occ2.
In order to characterize the inputs and outputs of Web services as
knowledge preconditions and knowledge effects, FLOWS augments PSL
with a treatment of knowledge. To do so, it appeals to the work of
Scherl and Levesque who provided a means of encoding the knowledge
of an agent in the situation calculus by adapting Moore's
possible-world semantics for knowledge and action
[Scherl03]. Scherl and Levesque
achieve this by adding a K fluent to the situation calculus.
Intuitively,
K(s',s) holds iff when the agent is in situation s, she
considers it possible to be in s'. Thus, a
first-order formula f is known in a situation s if
f holds in every situation that is K-accessible from s.
For notational convenience, the following abbreviations are adopted.
Knows(f,s) is defined to be forall s' K(s',s) ==> f[s'],
and
Knowswhether(f,s) is equivalent to Knows(f,s)
or Knows(not f,s).
To define
properties of the knowledge of agents they define restrictions such as
reflexivity over the K fluent. The FLOWS axiomatization
of these epistemic concepts can be found
here.
Note: We assume f is a situation-suppressed
formula (i.e. a situation formula whose situation terms are suppressed).
f[s] denotes the formula that restores situation arguments in f
by s.
- Activity
-
Activity.
In the formal PSL ontology, the notion of activity is a basic construct,
which corresponds intuitively to a kind of (manufacturing
or processing) activity.
In PSL, an activity may have associated
occurrences, which
correspond intuitively to individual instances or
executions of the activity.
(We note that in PSL an activity is not a class or type with
occurrences as members; rather, an activity is an object,
and occurrences are related to this object by the
binary predicate
occurrence_of.)
The occurrences of an activity may impact
fluents (which provide an abstract
representation of the "real world").
In FLOWS, with each service there is an associated
activity (called the "service activity" of that service).
The service activity may specify aspects of the internal
process flow of the service, and also aspects of the
messaging interface of that service to other services.
- Channel
-
Channel.
In FLOWS, a channel is a formal conceptual object,
which corresponds intuitively to a repository and
conduit for messages.
The FLOWS notion of channel is quite primitive,
and under various restrictions can be used to model
the form of channel or message-passing as
found in web services standards,
including WSDL, BPEL, WS-Choreography, WSMO,
and also as found in several research investigations,
including process algrebras.
- FLOWS
-
First-order
Logic Ontology for Web Services.
FLOWS, also known as SWSO-FOL,
is the first-order logic version of the Semantic Web Services Ontology.
FLOWS is an extension of the PSL-OuterCore ontology, to
incorporate the fundamental aspects of
(web and other electronic) services, including service descriptors,
the service activity, and the service grounding.
- Fluent
-
Fluent.
In FLOWS, following PSL and the situation calculii, a
fluent is a first-order logic term or predicate whose
value may vary over time.
In a first-order model of a FLOWS theory, this
being a model of PSL-OuterCore,
time is represented as a discrete linear sequence
of timees, and
fluents has a value for each time in this sequence.
- Grounding
-
Grounding.
The SWSO concepts for describing service activities,
and the instantiations
of these concepts that describe a particular service activity, are
abstract specifications, in the sense that they do not specify
the details of particular message formats, transport protocols,
and network
addresses by which a Web service is accessed. The role of
the grounding is to provide these more concrete
details.
A substantial portion of the grounding can be acheived by
mapping SWSO concepts into corresponding WSDL constructs.
(Additional grounding, e.g., of some process-related aspects
of SWSO, might be acheived using other standards, such
as BPEL.)
- Message
-
Message.
In FLOWS, a message is a formal conceptual object,
which corresponds intuitively to a single message that
is created by a service occurrence, and read by zero
or more service occurrences.
The FLOWS notion of message is quite primitive, and
under various restrictions can be used to model
the form of messages as found in web services standards,
including WSDL (1.0 and 2.0), BPEL, WS-Choreography, WSMO,
and also as found in several research investigations.
A message has a payload, which corresponds
intuitively to the body or contents of the message.
In FLOWS emphasis is placed on the knowledge that
is gained by a service occurrence when reading a message
with a given payload
(and the knowledge needed to create that message.
- Occurrence
-
Occurence (of a service).
In FLOWS, a service S has an associated FLOWS activity
A (which
generalizes the notion of PSL activity).
An occurrence of S is formally
a PSL occurrence of the activity A.
Intuitively, this occurrence corresponds to
an instance or execution (from start to finish) of the activity
A, i.e., of the process associated with
service S.
As in PSL, an occurrence has a starting time
time and an ending time.
- PSL
-
Process Specification Language.
The Process Specification Language (PSL) is a
formally axiomatized ontology
[Gruninger03a,
Gruninger03b]
that has been
standardized as ISO 18629.
PSL provides a layered, extensible ontology
for specifying properties of processes.
The most basic PSL constructs are embodied in
PSL-Core; and PSL-OuterCore incorporates
several extensions of PSL-Core that includes
several useful constructs.
(An overview of concepts in PSL
that are
relevant to FLOWS is given in
Section 6 of the
Semantic Web Services Ontology document.)
- QName
-
Qualified name.
A pair (URI, local-name). The URI represents a
namespace and local-name represents a name used in an XML
document, such as a tag name or an attribute name.
In XML, QNames are syntactically
represented as prefix:local-name, where prefix is
a macro that expands into a concrete URI.
See Namespaces
in XML for more details.
- ROWS
-
Rules Ontology for Web Services.
ROWS, also known as SWSO-Rules,
is the rules-based version of the Semantic Web Services Ontology.
ROWS is created by a relatively straight-forward,
almost faithful,
transformation of FLOWS, the First-order Logic Ontology for
Web Services.
As with FLOWS, ROWS incorporates
fundamental aspects of
(web and other electronic) services, including service descriptors,
the service activity, and the service grounding.
ROWS enables a rules-based specification of a family of
services, including both the underlying ontology and
the domain-specific aspects.
- Service
-
(Formal) Service.
In FLOWS, a service is a conceptual object, that
corresponds intuitively to a web service (or other electronically
accessible service). Through binary predicates a service
is associated with various service descriptors (a.k.a.
non-functional properties) such as Service Name, Service Author,
Service URL, etc.; an activity (in the sense of
PSL) which specifies intuitively the process model associated with the
service; and a grounding.
- Service contract
- Describes an agreement between the service requester and service
provider,
detailing requirements on a service occurrence or family of
service occurrences.
- Service descriptor
-
Service Descriptor.
This is one of several non-functional properties
associated with services.
The Service Descriptors include
Service Name, Service Author, Service Contract Information,
Service Contributor, Service Description, Service URL,
Service Identifier, Service Version, Service Release Date,
Service Language, Service Trust, Service Subject,
Service Reliability, and Service Cost.
- Service offer description
-
Describes an abstract service (i.e. not a concrete instance of the service)
provided by a service provider agent.
- Service requirement description
-
Describes an abstract service required by a service requester agent,
in the context of service discovery, service brokering, or negotiation.
- sQName
-
Serialized QName.
A serialized QName is a shorthand representation of a URI. It is
a macro that expands into a full-blown URI.
sQNames are not QNames: the former are URIs, while the latter are
pairs (URI, local-name).
Serialized QNames were originally introduced in RDF as a notation for
shortening URI representation. Unfortunately,
RDF introduced confusion by adopting the term QName for something that is
different from QNames used in XML. To add to the confusion, RDF uses
the syntax for sQNames that is identical to XML's syntax for QNames.
SWSL distinguishes between QNames and sQNames, and uses the
syntax prefix#local-name for the latter.
Such an sQName expands into a full URI by concatenating the value
of prefix with local-name.
- URI
-
Universal Resource Identifier.
A symbol used to locate resources on the Web. URIs are defined by IETF. See
Uniform Resource Identifiers
(URI): Generic Syntax for more details.
Within the IETF standards the notion of URI is an extension
and refinement of the notions of Uniform Resource Locator (URL)
and Relative Uniform Resource Locators.
- [Berardi03]
- Automatic composition of e-services that export their
behavior.
D. Berardi, D. Calvanese, G. De Giacomo, M. Lenzerini, and M. Mecella.
In Proc. 1st Int. Conf. on Service Oriented Computing (ICSOC),
volume 2910 of LNCS, pages 43--58, 2003.
- [Bernstein2000]
- How can cooperative work tools support dynamic group
processes? Bridging the specificity frontier. A. Bernstein. In
Proc. Computer Supported Cooperative Work (CSCW'2000), 2000.
- [Bernstein2002]
- Towards High-Precision Service Retrieval. A.
Bernstein, and M. Klein. In
Proc. of the first International Semantic Web Conference (ISWC'2002),
2002.
- [Bernstein2003]
- Beyond Monotonic Inheritance: Towards Semantic Web
Process Ontologies. A. Bernstein and B.N. Grosof (NB: authorship
sequence is alphabetic). Working Paper, Aug. 2003. Available at: http://ebusiness.mit.edu/bgrosof/#beyond-mon-inh-basic.
- [Bonner93]
- Database Programming in Transaction Logic. A.J.
Bonner, M. Kifer, M. Consens. Proceedings of the 4-th Intl.~Workshop on
Database Programming Languages,
C. Beeri, A. Ohori and D.E. Shasha
(eds.), 1993. In Springer-Verlag Workshops in Computing Series, Feb.
1994: 309-337.
- [Bonner98]
- A Logic for Programming Database Transactions.
A.J. Bonner, M. Kifer. Logics for Databases and Information Systems, J.
Chomicki and G. Saake (eds.). Kluwer Academic Publishers, 1998: 117-166.
- [Bruijn05]
- Web Service Modeling Ontology (WSMO).
J. de Bruijn, C. Bussler, J. Domingue,
D. Fensel, M. Hepp, M. Kifer, B. Kaenig-Ries, J. Kopecky,
R. Lara, E. Oren, A. Polleres, J. Scicluna, M. Stollberg.
DERI Technical Report.
- [BPML 1.0]
- A. Arkin.
Business Process Modeling Language.
BPMI.org, 2002
- [BPEL 1.1]
-
Business Process Execution Language for Web Services, Version 1.1
. S. Thatte, editor.
OASIS Standards Specification, May 5, 2003.
- [Bultan03]
- Conversation specification: A new approach to design and
analysis of e-service composition.
T. Bultan, X. Fu, R. Hull, and J. Su. In Proc. Int. World Wide
Web Conf. (WWW), May 2003.
- [Chang73]
- Symbolic Logic and Mechanical Theorem Proving.
C.L. Chang and R.C.T. Lee. Academic Press, 1973.
- [Chen93]
- HiLog: A Foundation for Higher-Order Logic Programming.
W. Chen, M. Kifer, D.S. Warren. Journal of Logic Programming, 15:3,
February 1993, 187-230.
- [Chimenti89]
- Towards an Open Architecture for LDL. D. Chimeti,
R. Gamboa, R. Krishnamurthy, VLDB Conference, 1989: 195-203.
- [deGiacomo00]
- ConGolog, A Concurrent Programming Language Based on the
Situation
Calculus.
G. de Giacomo, Y. Lesperance, and H. Levesque.
Artificial Intelligence, 121(1--2):109--169, 2000.
- [Fu04]
- WSAT: A Tool for Formal Analysis of Web Services.
X. Fu, T. Bultan, and J. Su. 16th International Conference on
Computer Aided Verification (CAV), July 2004.
- [Frohn94]
- Access to Objects by Path Expressions and Rules.
J. Frohn, G. Lausen, H. Uphoff. Intl. Conference on Very Large
Databases, 1994, pp. 273-284.
- [Gosling96]
- The Java language specification.Gosling, James,
Bill Joy, and Guy L. Steele. 1996. Reading, Mass.: Addison-Wesley.
- [Grosof99a]
- A Courteous Compiler From Generalized Courteous Logic
Programs To Ordinary Logic Programs. B.N. Grosof. IBM Report
included as part of documentation in the IBM CommonRules 1.0 software
toolkit and documentation, released on http://alphaworks.ibm.com. July
1999. Also available at:
http://ebusiness.mit.edu/bgrosof/#gclp-rr-99k.
- [Grosof99b]
-
A Declarative Approach to Business Rules in Contracts.
B.N. Grosof, J.K. Labrou, and H.Y. Chan.
Proceedings of the 1st ACM Conference on Electronic Commerce (EC-99).
Also available at:
http://ebusiness.mit.edu/bgrosof/#econtracts+rules-ec99.
- [Grosof99c]
-
DIPLOMAT: Compiling Prioritized Default Rules Into Ordinary
Logic Programs (Extended Abstract of Intelligent Systems Demonstration).
B.N. Grosof. IBM Research Report RC 21473, May 1999.
Extended version of 2-page refereed conference paper
appearing in Proceedings of the National Conference on
Artificial Intelligence (AAAI-99), 1999. Also available at:
http://ebusiness.mit.edu/bgrosof/#cr-ec-demo-rr-99b.
- [Grosof2003a]
- Description Logic Programs: Combining Logic Programs with
Description Logic. B.N. Grosof, I. Horrocks, R. Volz, and S.
Decker. Proceedings of the 12th International Conference on the World
Wide Web (WWW-2003). Also available at: http://ebusiness.mit.edu/bgrosof/#dlp-www2003.
- [Grosof2004a]
- Representing E-Commerce Rules Via Situated Courteous
Logic Programs in RuleML. B.N. Grosof. Electronic Commerce
Research and Applications, 3:1, 2004, 2-20. Preprint version is also
available at: http://ebusiness.mit.edu/bgrosof/#.
- [Grosof2004b]
- SweetRules: Tools for Semantic Web Rules and Ontologies,
including Translation, Inferencing, Analysis, and Authoring.
B.N. Grosof, M. Dean, S. Ganjugunte, S. Tabet, C. Neogy, and D. Kolas.
http://sweetrules.projects.semwebcentral.org. Software toolkit and
documentation. Version 2.0, Dec. 2004.
- [Grosof2004c]
- Hypermonotonic Reasoning: Unifying Nonmonotonic Logic
Programs with First Order Logic. B.N. Grosof.
http://ebusiness.mit.edu/bgrosof/#HypermonFromPPSWR04InvitedTalk.
Slides from Invited Talk at Workshop on Principles and Practice of
Semantic Web Reasoning (PPWSR04), Sep. 2004; revised Oct. 2004. Paper
in preparation.
- [Grosof2004d]
- SweetPH: Using the Process Handbook for Semantic Web
Services. B.N. Grosof and A. Bernstein.
http://ebusiness.mit.edu/bgrosof/#SweetPHSWSLF2F1204Talk. Slides
from Presentation at SWSL Meeting, Dec. 9-10, 2004. Note: Updates
the design in the 2003 Working Paper "Beyond Monotonic Inheritance:
Towards Semantic Web Process Ontologies" and describes implementation.
- [Grosof2004e]
-
SweetDeal: Representing Agent Contracts with Exceptions using
Semantic Web Rules, Ontologies, and Process Descriptions.
B.N. Grosof and T.C. Poon.
International Journal of Electronic Commerce (IJEC), 8(4):61-98, Summer 2004
Also available at:
http://ebusiness.mit.edu/bgrosof/#sweetdeal-exceptions-ijec.
- [Grosof2004f]
-
Semantic Web Rules with Ontologies, and their E-Business Applications.
B.N. Grosof and M. Dean.
Slides of Conference Tutorial (3.5-hour) at the 3rd International Semantic
Web Conference (ISWC-2004).
Available at:
http://ebusiness.mit.edu/bgrosof/#ISWC2004RulesTutorial.
- [Gruninger03a]
-
A Guide to the Ontology of the Process Specification Language.
M. Gruninger.
Handbook on Ontologies in Information Systems.
R. Studer and S. Staab (eds.). Springer Verlag, 2003.
-
[Gruninger03b]
-
Process Specification Language: Principles and Applications.
M. Gruninger and C. Menzel.
AI Magazine, 24:63-74, 2003.
- [Gruninger03c]
-
Applications of PSL to Semantic Web Services.
M. Gruninger.
Workshop on Semantic Web and Databases. Very Large Databases Conference, Berlin.
- [Hayes04]
- RDF Model Theory.
Hayes, P. W3C, February 2004.
- [Helland05]
- Data on the Outside Versus Data on the Inside.
P. Helland. Proc.
2005 Conf. on Innovative Database Research (CIDR), January,
2005.
- [Hull03]
- E-Services: A Look Behind the Curtain.
R. Hull, M. Benedikt, V. Christophides, J. Su. Proc. of the ACM
Symp. on Principles of Database Systems (PODS), San Diego, June,
2003.
- [Kifer95]
- Logical Foundations of Object-Oriented and Frame-Based
Languages, M. Kifer, G. Lausen, J. Wu. Journal of ACM, 1995, 42,
741-843.
- [Kifer04]
- A Logical Framework for Web Service Discovery, M.
Kifer, R. Lara, A. Polleres, C. Zhao. Semantic Web Services Workshop,
November 2004, Hiroshima, Japan.
- [Klein00a]
- Towards a Systematic Repository of Knowledge About
Managing Collaborative Design Conflicts. Klein, Mark.
2000. Proceedings of the Conference on Artificial Intelligence in
Design. Boston, MA, USA.
- [Klein00b]
- A Knowledge-Based Approach to Handling Exceptions in
Workflow Systems. Klein, Mark, and C. Dellarocas. 2000.
Computer Supported Cooperative Work: The Journal of Collaborative
Computing 9:399-412.
- [Lloyd87]
- Foundations of logic programming (second, extended edition).
J. W. Lloyd. Springer series in symbolic computation. Springer-Verlag,
New York, 1987.
- [Lindenstrauss97]
- Automatic Termination Analysis of Logic Programs.
N. Lindenstrauss and Y. Sagiv. International Conference on Logic
Programming (ICLP), 1997.
- [Maier81]
- Incorporating Computed Relations in Relational Databases.
D. Maier, D.S. Warren. SIGMOD Conference, 1981: 176-187.
- [Malone99]
- Tools for inventing organizations: Toward a handbook of
organizational processes. T. W. Malone, K. Crowston, J. Lee, B.
Pentland, C. Dellarocas, G. Wyner, J. Quimby, C. Osborne, A. Bernstein,
G. Herman, M. Klein, E. O'Donnell. Management Science, 45(3),
pages 425--443, 1999.
- [McIlraith01]
- Semantic Web Services.
IEEE Intelligent Systems, Special Issue on the
Semantic Web, S. McIlraith, T.Son and H. Zeng.
16(2):46--53, March/April, 2001.
- [Milner99]
- Communicating and Mobile Systems: The π-Calculus.
R. Milner. Cambridge University Press, 1999.
- [Narayanan02]
- Simulation, Verification and Automated Composition of Web
Services. S. Narayanan and S. McIlraith.
In Proceedings of the Eleventh International World Wide Web
Conference (WWW-11), May, 2002.
- [Ontobroker]
-
Ontobroker 3.8. Ontoprise, GmbH.
- [OWL Reference]
- OWL
Web Ontology Language 1.0 Reference. Mike Dean, Dan
Connolly, Frank van Harmelen, James Hendler, Ian Horrocks, Deborah L.
McGuinness, Peter F. Patel-Schneider, and Lynn Andrea Stein. W3C
Working Draft 12 November 2002. Latest version is available at http://www.w3.org/TR/owl-ref/.
- [OWL-S 1.1]
- OWL-S:
Semantic Markup for Web Services. David Martin, editor. Technical Overview
(associated with OWL-S Release 1.1).
- [Papazoglou03]
- Service-Oriented Computing: Concepts,
Characteristics and Directions.
M.P. Papazoglou.
Keynote for the 4th International Conference on Web Information
Systems Engineering (WISE 2003), December 10-12, 2003.
- [Perlis85]
- Languages with Self-Reference I: Foundations. D.
Perlis. Artificial Intelligence, 25, 1985, 301-322.
- [Preist04]
- A Conceptual Architecture for Semantic Web Services, C. Preist, 1993.
In Proceedings of Third International Semantic Web Conference, Nov. 2004:
395-409.
- [Reiter01]
- Knowledge in Action: Logical Foundations for Specifying and
Implementing Dynamical Systems.
Raymond Reiter. MIT Press. 2001
- [Scherl03]
- Knowledge, Action, and the Frame Problem.
R. B. Scherl and H. J. Levesque. Artificial Intelligence,
Vol. 144, 2003, pp. 1-39.
- [Singh04]
- Protocols for Processes: Programming in the Large for Open
Systems.
M. P. Singh, A. K. Chopra, N. V. Desai, and A. U. Mallya. Proc. of
the 19th Annual ACM Conf. on Object-Oriented Programming, Systems,
Languages, and Applications (OOPSLA), Vancouver, October 2004.
- [SWSL Requirements]
- Semantic Web Services Language Requirements.
B. Grosof, M. Gruninger, et al, editors.
White paper of the Semantic Web Services Language Committee.
- [UDDI v3.02]
-
Universal Description, Discovery and Integration (UDDI)
protocol. S. Thatte, editor.
OASIS Standards Specification, February 2005.
- [VanGelder91]
- The Well-Founded Semantics for General Logic Programs.
A. Van Gelder, K.A. Ross, J.S. Schlipf. Journal of ACM, 38:3, 1991,
620-650.
- [WSCL 1.0]
- Web Services
Conversation Language (WSCL) 1.0. A. Banerji et al. W3C Note, March 14, 2002.
- [WSDL 1.1]
-
Web Services Description
Language (WSDL) 1.1. E. Christensen, F. Curbera,
G. Meredith, and S. Weerawarana. W3C Note, March 15, 2001.
- [WSDL 2.0]
-
Web Services Description
Language (WSDL) 2.0 --
Part 1: Core Language. R. Chinnici, M. Gudgin, J.-J. Moreau, J. Schlimmer, and S. Weerawarana.
W3C Working Draft,
August 3, 2004.
- [WSDL 2.0 Primer]
-
Web Services Description
Language (WSDL) Version 2.0 --
Part 0: Primer. D. Booth, C. Liu, editors.
W3C Working Draft,
21 December 2004.
- [WS-Choreography]
- Web Services
Choreography Description Language Version 1.0. N. Kavantzas, D. Burdett, et. al., editors. W3C
Working Draft, December 17,
2004.
- [XSLT]
- XSL Transformations (XSLT) Version
1.0. J. Clark, editor. W3C
Recommendation, 16 November 1999.
- [XQuery 1.0]
- XQuery 1.0: An XML Query
Language. S. Boag, D. Chamberlin, et al, editors.
W3C Working Draft 04 April 2005.
- [Yang02]
- Well-Founded Optimism: Inheritance in Frame-Based
Knowledge Bases. G. Yang, M. Kifer. Intl. Conference on
Ontologies, DataBases, and Applications of Semantics for Large Scale
Information Systems (ODBASE), October 2002.
- [Yang03]
- Reasoning about Anonymous Resources and Meta Statements
on the Semantic Web. G. Yang, M. Kifer. Journal on Data
Semantics, Lecture Notes in Computer Science 2800, Springer Verlag,
September 2003, 69-98.
- [Yang04]
- FLORA-2 User's
Manual. G. Yang, M. Kifer, C. Zhao, V. Chowdhary. 2004.