January 10, 1997
Trust decisions are everywhere. This perception marked the beginning of the Digital Signature Initiative's (DSig) work. Users want to make sure that the code they just downloaded does not mess with their machine - they want to know if they can trust the author of the program. Users want to verify the authenticity of an online price list before placing an order - they want to know if they can trust the contents of the document.
The purpose of DSig is to help users to decide what information they can trust on the Web. One part of DSig allows the author of a (Web) document to make assertions about the document and to cryptographically protect these assertions by digital signatures. The other part of DSig, the Trust Management Architecture (TMA) described in this document, helps the recipient of a document to make a decision about how to treat this document based on the assertions, the trust relationship with sender of the document, and other parameters. Expressing trust is a complicated issue. Users need to
The TMA provides the framework for building systems that satisfy these needs. It is a simple, extensible system that defines standard interfaces for modules that interact with a variety of sources of information for making trust management decisions.
In the DSig TMA policies are represented by policy programs. These policies, which can be written in many different programming languages, work together by sharing a common interface, and it is this interface which is the core of the Trust Management Architecture. Policies are executable programs, so that whenever an application faces a trust decision, it can formulate the trust decision with all relevant parameters as a true/false-question and then call the appropriate policy program with this question. The policy program computes the answer to this trust question and returns this answer together with a justification and some additional information to the calling application. The answer of the trust management system is a recommendation to the calling application, the application need not respect this advice.
The TMA was designed with particular types of applications and particular forms of questions in mind. For DSig the application will usually be a Web browser and typical questions will be: "Is it secure to execute this downloaded piece of code?" or "Is it O.K. to view this text document/ image/ movie with respect to my PICS settings?" Nevertheless the trust architecture can be employed in other environments. There the questions might be "Do we allow this person to log into our system?", "Do we allow this user to access that file?", or "Do we allow this person to rent a car?" The trust management architecture is flexible enough to allow policies appropriate for each of these questions to be implemented smoothly.
In addition to specifying the interfaces of the policy programs, the Trust Management Architecture specifies three architecturally required modules (a URL fetcher, a label fetcher, and an initial policy language) and three modules that are critical to the Digital Signature Initiative (signature validation, certificate validation, and certificate chain reduction). All six of these modules conform to the standard interface specifications.
The DSig project is focused primarily on creating the infrastructure needed to create, validate, and utilize signed documents of various kinds. The Trust Management Architecture work is intended to provide a structure for testing the utility of this infrastructure. It provides a framework for building systems that use the signatures to make trust decisions. In some sense, it is a "test harness" for experiments that use the new infrastructure for real applications.
The design of the architecture was influenced by six primary design goals:
For DSig the trust architecture is typically used to decide whether or not it is OK to execute some piece of code or to view some document that has just been downloaded from the network. The policy program bases its decision on a document description in the form of one or more DSig labels that it downloads from the network or fetches from some other medium like a CD-ROM. In this environment a complex user policy might be consist of the following five steps:
By using specifically designed policy languages it is fairly easy to implement this policy. For example with the Profiles language from our sample implementation this policy can be written in some 40 lines of code excluding signature and hash computation that will be provided by the implementers of the trust management system(e.g. the browser manufacturer).
Besides being able to express complex policies, program based policies have another important advantage: policies become transferable. A policy written in a particular programming language can be shared among all implementations of the TMA that support this programming language. For example, a user of two different Web browsers does not need to click his way through a jungle of dialogs any longer to make both browsers do the same thing, he just needs to define his policy once and then tell both browsers to user it.
Just as important, policies can not only be shared between the multiple trust system implementations one user runs, but also between those of multiple users. For example, if Joe creates a fine policy, he could give it to his friends so that they can use it, too. Organizations, company departments, or ISPs could write policies and distribute them to their customers to take the burden of defining sophisticated policies of their clientele's shoulders. We anticipate that many experienced users will make their policies available via the Web to help less experienced users.
But there is even a third type of transferability that executable policies have: policies need not be enforced at the user's machine. They could also be enforced on a proxy server or at the companies firewall. If a secure policy language is used, policies could be uploaded to e.g. search engines, to allow them to tailor make their results to fit the each user's interests.
The DSig trust management architecture can also be employed in other environments. For example, let us return to one of the trust question we already mentioned above: "Do we allow this user to access that file?" The user policy to decide on this question might implement an ACL based on the user id of the requesting user, but it might also have some additional predicates, e.g. to allow the Web administrator to read all files below /html or to log all accesses between 10 p.m. and 7 a.m.
For the "Do we allow this person to rent a car?" example the policy might e.g. check if the customer has a valid driver's license, if he has a membership card, if his credit card is valid, and so on.
The Digital Signature Trust Management Architecture (TMA) is an extensible, self-modifiable, recursive execution environment for evaluating trust management questions. Evaluation is performed within the TMA by one or more policy-controlled modules; each module is a block of executable code that accepts as input a list of statements (which can contain arbitrary information) and generates as output more statements. Figure 1 below shows a typical policy-controlled module with its arguments. (The details of the internal API are discussed more fully below.)
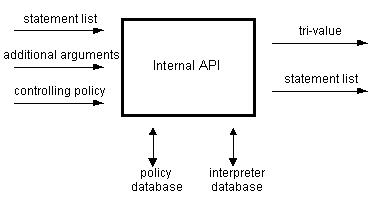
Figure 1: Basic structure of policy-controlled modules
Notice that every module takes a controlling policy as an argument, which controls operation of the module. Every module within the TMA is controlled by some other policy; the idea of "policy execution under policy control" is central to the TMA model. Everything that happens during the execution of an implementation of the TMA is under the control of some policy, and at the root of the control hierarchy is a local policy. Of course, there must be some initial policy information provided by an external source in order to bootstrap the system and root the recursion tree.
An application built on top of the TMA is a collection of policy-controlled modules linked together.
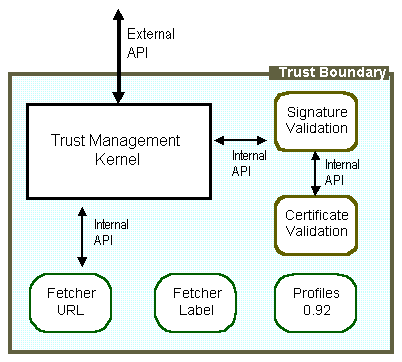
Figure 2: Block diagram of TMA architecture
Within the context of the TMA the terms "policy," "program," and "program element" are interchangeable. All three terms refer to executable blocks of code, and it may be easier to think of policies as small self-contained programs or scripts in a scripting language. (TMA policies are similar to PolicyMaker [BFL] assertions. In both systems policies are code fragments and policy evaluation is accomplished by running the policies in some environment. When policy processing has completed, the final state of the execution environment determines whether the given set of policies has been satisfied.) The policy that controls overall operation of the TMA system, therefore, is a policy controlling the operation of other policies. (This is the "top-level policy" in Figure 2.) The overarching policy states what "sub-policies" should be run when and how those subpolicies interact with each other.
In this section we detail the application programming interfaces (APIs) through which the various elements of the trust management system communicate. There are three classes of APIs:
We address each of these APIs in turn below, after first reviewing some primitive data types shared by the APIs.
The DSig TMA has four primitive underlying data types:
Code databases provide bindings between symbolic names and executable code. They allow code fragments, such as policies or interpreters, to be named.
Tri-values are three-valued logic operands. We designate the three possible values as "true", "false" and "unknown" to distinguish tri-values from traditional Boolean values. Tri-values may be combined in manner similar to Boolean values. They are one of the outputs of policies. Tri-valued logic is detailed in Section 3 below.
Statements express information acquired during the execution of policies. All statements are two-element s-expressions. The first element conveys the context of the statement and the second element provides the content. (For example, a context might be the program that was running when the information was acquired. The content might be an assertion that a particular document has been virus-checked.)
Policy-controlled modules are executable blocks of code that processes input statements and assert additional statements; they are the basic computing units within the TMA. Every module has as one of its inputs a controlling policy, written in a language dictated by the module. (Some modules, such as the label-loaded described below, may accept null policies.) The trust management system itself is an extensible, self-modifiable, recursive execution environment for policy-controlled modules, although it appears to the user to be a monolithic "true/false/unknown" decision box. We may think of a policy-controlled module as a "program element" and of the "TMA" as a network of interconnected program elements.
The internal API is the interface between policy-controlled modules within the REFEREE system itself. Here are the required arguments for the internal API:
Table 1: Internal API arguments
| Inputs: | controlling policy statement list additional arguments |
| Outputs: | tri-value statement list |
Policy-controlled modules operate on lists of statements and may optionally require additional parameters or other arguments. The operation of the module itself is controlled by the controlling policy, which is written in some language understood by the module. (For example, the controlling policy input to the Profiles-0.92 module is a script written in the Profiles-0.92 language.) The additional arguments argument is a list (possibly empty) of these extra parameters. Together, the statement list and the list of additional arguments (plus the state captured in the global code databases) provide the context necessary for the module.
The output of a policy-controlled module consists of two values: a tri-value and a statement list. The output tri value is the true/false/unknown result of running the module. The output statement list is a collection of new statements that the module has generated and determined should be added to the statement list being maintained by the calling module. That is, if module A calls module B, the statement list returned by B consists of statements that B would like A to add to A's statement list. Module A is not required to add B's returned statements to its own statement list.
The external API is the interface between applications calling REFEREE and the system itself. The mechanics of the call are obviously implementation-dependent but the information that needs to be conveyed (and the order of those arguments) may be standardized. The requirements of the external API are dictated by the internal API and the information needed to bootstrap the entire trust management system.
Table 2: External API arguments
| Inputs: | action policy-database interpreter-database statement-list additional-arguments |
| Outputs: | tri-value statement-list |
Applications calling the trust manager must provide five arguments: an action, a policy-database, an interpreter-database, an initial statement-list, and an additional-arguments list. The action, statement-list, and additional-arguments together define the context of the question the application is asking the trust manager. For example, an action of "view-url" together with a particular URL may constitute a question of the form, "Does the current policy permit the document with this URL to be viewed?" Any string may be an action; the statement-list is a list of individual statements, and the additional-arguments list may contain any number of arguments of any type (or be empty). Typically the additional-arguments are particular parameters passed to the top-level policy for the action and the statement-list contains more general context information.
The policy-database and interpreter-database provide REFEREE with bootstrap policies and interpreters. Both are instances of the more general code-database data type. Together with the action received from the calling application, these two databases determine both the initial policy that should be executed by the system as well as an environment of known policies and languages. (The action is used in the bootstrap process as the key into the policy-database to retrieve the initial policy and language name for that policy. The language name is then in turn used as the key to the interpreter-database to retrieve an appropriate interpreter for the policy.) We make the distinction between "policies" and "interpreters" so that one interpreter can process any number of policies written in a particular language. Each entry in the policy-database is a triplet (policy-name, policy, language-name); each entry in the interpreter-database maps language-names (strings) to interpreters. The name-value bindings provided by the calling application through these two databases provide only a core set of bindings; additional bindings may be installed dynamically pursuant to policy control.
The fifth argument, the additional-arguments list, is a list of additional arguments that should be passed to the first called policy. This list may be empty. If not empty, the contents of the additional-arguments list is unspecified; we assume that the calling application and the first called policy agree on the type of the arguments contained within it.
The output of a call to REFEREE is a pair consisting of a tri-value and a statement-list. The tri-value records the trust management system's answer to the question posed by the calling application; it is valid for the tri-value to be "unknown." The statement-list returned with the tri-value is a list of statements that is intended to provide context or justification for the tri-value answer. For example, if the tri-value is "false" then the statement-list may provide a list of reasons why REFEREE decided "false." A statement-list must always be returned to the calling application, although it may be empty.
The final component of the Trust Management Architecture specification concerns the common data structures and low-level "system calls" that are available to every policy-controlled module. Portions of these facilities are necessarily implementation-dependent (for example, procedure calling conventions) and thus can be completely detailed only as part of the implementation phase. We describe first the common data structures that need to be supported by the underlying system to support the external and internal APIs and then proceed to outline the required low-level functions.
The external and internal APIs require that all conforming module recognize the following data types:
Tri-values are three-valued logic operands that represent.
Statements are two-element s-expressions. The first element of a statement is the context of that statement; the second element of a statement is the content. In general, the context of a statement provides information about which policy-controlled modules generated and re-issued the corresponding content.
Statement Lists are a ordered lists of statements. Generally, new statements are appended to the statement list during a policy interpretation.
Policies are three-element strings. The first element of a policy conveys the location of that policy; the second element contains the content of the policy; the third element describes the language in which the policy is written in.
Interpreters are also two-element strings. The first element of an interpreter is the language name which the interpreter executes; the second element contains necessary information in which REFEREE can locate and invoke the interpreter. If the interpreter is written in Java, the second element is the classpath.
Code databases provide bindings between strings (keys) and values (interpreters or policies). A policy entry binds an action string to the policy and the language name. An interpreter entry binds a language name to an executable interpreter. Thus, given only an action string, a module can first extract the controlling policy and language identifier, and the language identifier can then in turn be used to find the corresponding interpreter all from the code database.
Each primitive data type described above has a set of standard methods. This ensures all objects declared in these data types are understood by all modules in REFEREE. Implementers who intend to write their interpreter must provide the standard methods for compatibility reason. Here we assume all interpreters are written in Java. We will describe each data type in Java syntax below.
CodeDatabases is a set of bindings between strings (keys) and arbitrary data values. A REFEREE module can install new policies and interpreter to the CodeDatbase as well as de-install them. CodeDatabase is also searchable; based on an action string, it can find the corresponding policy and interpreter.
Public final class CodeDatabase extends Object
public code_database() throws CodeDatabaseException
Constructs an empty CodeDatabase object.
public void putPolicy(String key, Policy inputPolicy)
Puts a policy in the CodeDatabase with the specified key value.
Public void putInterpreter(String key, Interpreter inputInterpreter)
Puts an interpreter in the CodeDatabase with the specified key value.
Public Policy getPolicy(String key) throws CodeDatabaseException
Gets the policy with the specified key value in the CodeDatabase.
Public Interpreter getInterpreter(String key) throws CodeDatabaseException
Gets the interpreter with the specified key value in the CodeDatabase.
Public Interpreter getInterpreter(Policy userPolicy) throws CodeDatabaseException
Gets the interpreter which matches the userPolicy.
Public boolean removePolicy(String key)
Remove the policy with the specified key from the CodeDatabase.
Public boolean removeInterpreter(String key)
Remove the interpreter with the specified key from the CodeDatabase.
Public CodeDatabase duplicate()
Duplicate a CodeDatabase with the same content.
Policies are programs written in a specific language. A
policy has three attributes; the location of the policy, the
content of the policy, and the language name in which the policy
is written in.
Public final class Policy extends Object
Public Policy(String sourceURI, String content, String languageName)
Constructs a Policy object.
Public String getSourceURI()
Gets the location of the policy.
Public String getContent()
Gets the actual content of the policy.
Public String getLanguageName()
Gets the name of the language the policy is written in.
Public setSourceURI(String sourceURI)
Sets the location of the policy.
Public setContent(String content)
Sets the policy content.
Public setLanguageName(String languageName)
Sets the name of the language the policy is written in.
Interpreters interpret policies written in their
specific language. An interpreter has two attributes; a language
name, and a locator where the interpreter can be found and
invoked. The locator is generally a Java classpath.
Public final class Interpreter extends Object
Public Interpreter(String languageName, String interpreterLocator)
Constructs an Interpreter object.
Public String getLanguageName()
Gets the name of the language the interpreter understands.
Public void setLanguageName(String languageName)
Sets the name of the language the interpreter understands.
Public String getLocator()
Gets the interpreter classpath.
Public void setLocator(String locator)
Sets the interpreter classpath.
Public ReturnedValue invoke(Policy policy, StatementList list, String[] argv)
Invoke the interpreter with the policy, initial statement list, and an array of additional arguments. ReturnValue contains a tri-value and a statement-list.
Every conforming implementation of the Digital Signature Trust Management Architecture is required to provide three standard policy-controlled modules to guarantee a minimal level of functionality and interoperability. The required modules are:
The Profiles-0.92 language for writing policies is described in detail in the specification for REFEREE 1.4d; we do not include that specification here. The PICS label-loader, identified by the name "load-label" in the code database for policies, is a simple module for requesting PICS labels from remote label bureaus. Similarly, the URL fetcher module, identified by the name "load-URL," is a simple module for requesting the contents of a URL over the network. We describe the semantics of the API arguments (both input and output) for the PICS label loader and the URL fetcher below.
The PICS label loader is a primitive policy-controlled module that tries to locate PICS labels for a given URL. Recall that every policy-controlled module takes three input arguments: the controlling policy, the statement list and a list of additional arguments. The PICS label loader has three additional arguments:
Because the operation of the PICS label loader is completely specified by these three arguments (what to find labels for, what kind of labels to look for, and where to look for the labels), no controlling policy is needed. The PICS label loader ignores any input controlling policy, and it is assumed that the controlling policy will in fact be null (empty).
Both the subject URL and the rating service are passed as
quoted URLs to the PICS label loader. The list of places to look
for labels contains one or more of the following elements: (a)
the URL of a label bureau, (b) the reserved keyword EMBEDDED
(for embedded labels), or (c) the reserved keyword ALONG-WITH
(for labels transmitted in the HTTP stream along with the
content). Reserved keywords and any individual label bureau URL
may appear at most once, but multiple label bureaus may be
listed.
A typical call to the PICS label loader from within the
Profiles-0.92 language would look like this:
(invoke"load-label" statement-list("http://www.w3.org/Overview.html" "http://www.gcf.org/v2.5"(EMBEDDED "http://www.label-bureau.org/")))
The URL in question in this example is "http://www.w3.org/Overview.html"
and the label loader is told to first check the document itself
for embedded labels (the EMBEDDED keyword) and then,
if necessary, contact the label bureau at www.label-bureau.org.
Only labels that use the rating service http://www.gcf.org/v2.5
are desired.
When the PICS label loader discovers a label for the given URL
it creates a new statement for the statement-list that consists
of the assertions contained within the label. To continue the
example, assume that when the label loader looks for labels for http://www.w3.org/Overview.html
it finds the following label:
(PICS-1.1 "http://www.gcf.org/v2.5"
labels on "1994.11.05T08:15-0500"
by "John Doe"
until "1995.12.31T23:59-0000"
for "http://w3.org/PICS/Overview.html"
ratings (suds 0.5 density 0 color/hue (1 2:3)))
For each label that is found, the label loader parses the label and creates a new statement containing the contents of the label in a structured format. Basically, keyword-value pairs in the original PICS label are turned into two-element lists (with the key as the first element). For the above example, the content of the new statement generated by the label loader looks like this (line numbers are for identification purposes only):
1.(("load-label" "http://w3.org/Overview.html" EMBEDDED)
2. ((version "PICS-1.1")
3. (service "http://www.gcf.org/v2.5")
4. (by "John Doe")
5. (on "1994.11.05T08:15-0500")
6. (original (PICS-1.1 "http://www.gcf.org/v2.5"
7. labels on "1994.11.05T08:15-0500"
8. by "John Doe"
9. until "1995.12.31T23:59-0000"
10. for "http://w3.org/PICS/Overview.html"
11. ratings (suds 0.5 density 0 color/hue (1 2:3)))")
12. (ratings (color/hue (1 2 : 3))
13. (density 0)
14. (suds 0.5))
15. (until "1995.12.31T23:59-0000")))
Line 1 is the header containing identifying information for
the content of the statement. The header is a list consisting of
the name of the policy ("load-label"), the
URL for which labels were sought, and the source of this
particular label.
Lines 2-15 jointly contain a list of keyword-tagged lists. This list is the content of the discovered label. Each keyword-tagged field (another list) corresponds to some portion of the original label, Most of the keyword-tagged fields are simply keyword-value pairs (lines 2-11,15). Ratings information can be richer, however, and thus its structure is more complex.
The original label itself is included, unparsed, in the original field (lines 6-11). (Some policies, such as signature checks, may require access to the transmitted exact form of the label.)
Rating values themselves (lines 12-14) are either single
floating-point numbers or multi-values consisting of two
floating-point numbers separated by a colon (indicating a range
of values). Note that, unlike in PICS labels, each
dimension-value pair is enclosed in parentheses; this makes it
easier to write match statements in the
Profiles-0.92 language.
All poptions (parenthesized options) present are sorted and listed in PICS canonical order (alphabetized by shortest name in US-ASCII character collating sequence). The shortest name of an option is always used.
Recall from PICS
label syntax that a label-list consists of (possibly) several
labels. load-label returns one statement for each
label. The order of the returned statements is not guaranteed by
"load-label," they may appear in any
order. Each option is guaranteed to appear at most once. load-label
merges the service-specific options and the label-specific
options according to the scope rules described in PICS
label syntax.
Finally, here is a formal grammar for the statement content returned by the PICS label loader:
returned-content-list :: '(' *content ')'
content :: '(' header version service *poption ratings ')'
header :: '(' '"label-loader"' quotedURL label-source ')'
label-source :: bureau | 'EMBEDDED' | 'ALONG-WITH'
bureau :: quotedURL
version :: '(' 'version' '"PICS-1.1"' ')'
service :: '(' 'service' quotedURL ')'
poption :: '(' option ')'
option :: 'by' quotedname | 'gen' boolean |
'for' quotedURL | 'on' quoted-ISO-date |
'signature-rsa-md5' base64-string |
'exp' quoted-ISO-date | 'at' quoted-ISO-date |
'md5' base64-string | 'comment' quotedname |
'full' quotedURL | 'original' quotedname |
'extension' '(' mand/opt quotedURL data* ')'
ratings :: '(' 'ratings' *rating ')'
rating :: '(' transmit-name number ')' |
'(' transmit-name '(' *multi-value ')' ')'
transmit-name :: 1*urlchar
alphanumpm :: 'A' | ... | 'Z' | 'a' | ... | 'z' | '0' | ... | '9' | '+' | '-'
urlchar :: alphanumpm | '.' | '$' | ',' | ';' | ':' | '&' | '=' | '?' | '!' |
'*' | '~' | '@' | '#' | '_' | '%' hex hex
The symbols quotedURL, quotedname, quoted-ISO-date, base64-string, mand/opt, data, hex, multi-value and number are defined as in the PICS label syntax. Our definition of the symbol transmit-name differs from the definition in that document because in our definition parentheses are not allowed in transmit-names (except via the percent-hex-hex mechanism).
The URL fetcher, like the PICS label loader, is a policy-controlled module. Its purpose is simply to retrieve the data addressed by a particular URL. The URL fetcher takes one additional argument: the quoted URL whose contents are desired. As the operation of the PICS label loader is completely specified by the URL to load, the controlling policy input is ignored by the URL loader (and, in fact, may be null).
A typical call to the URL loader from within the
Profiles-0.92 language would look like this (assuming that
the policy is bound to the name load-URL in the
execution environment):
(invoke "load-url" statement-list
("http://www.w3.org/Overview.html"))
The URL loader returns a tri-value of true so
long as some response was obtained from the remote server
(otherwise it returns false). The statement-list
returned by the URL loader consists of a single statement of the
form:
(("load-url")
("http://www.w3.org/Overview.html" <url-data>))
where <url-data> is the data returned as a
result of fetching the given URL. Note: it is an
open issue whether the <url-data> that is
returned should be the unparsed string obtained from the remote
server or a parsed, structured representation. For example, for HTTP
data the headers exchanged as part of the HTTP
protocol are probably desired as well as the content of the
document pointed at by the URL.
In addition to the three architecturally-required components implementations need to provide certain additional modules to make effective use of digital signature information. These three modules are:
The interfaces to these three components are not yet specified as the architecture of the digital signature block itself is currently in flux; once that architecture is fixed the specific APIs to these modules may be easily specified. We expect in a typical scenario for individual digital signature blocks to be processed in turn by each of the three modules, resulting in one or more statements containing derived Ellison 6-tuples of the form:
(<context> (dsig (issuer <the-issuer>)
(subject <the-subject>)
(delegation <the-delegation>)
(authorization <the-authorization>)
(validity <the-validity>)
(algorithm-information <the-alg-info>)))