Details
This section provides more detailed information on a variety of topics related to declaring language in HTML.
What if element content and attribute values are in different languages?
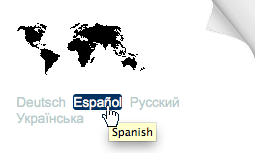
Occasionally the language of the text in an
attribute and the element content are in different languages. For example, at the top right corner of this article there are links to translated versions of this page. The
link text shows the language of the target page using the language of the target page, but an associated title attribute contains a hint in the
language of the current page:
If your code looks as follows, the language
attributes would actually indicate that not only the content but also the title attribute text is in Spanish.
This is obviously incorrect.
<a lang="es" title="Spanish"
href="qa-html-language-declarations.es">Español</a>
Instead, move the attribute containing text in a different language to another element, as shown in this example, where the a element inherits the default en setting of the html element.
<a title="Spanish" href="qa-html-language-declarations.es"><span lang="es">Español</span></a>
What if there's no element to hang your attribute on?
If you want to specify the language of some content but there is no markup around it, use an element such as span, bdi or div around the content.
Here is an example:
<p>You'd say that in Chinese as <span lang="zh-Hans">中国科学院文献情报中心</span>.</p>
Choosing language values
To be sure that all user agents recognize which language you mean, you need to follow a standard approach when providing language attribute values. You also need to consider how to refer in a standard way to dialectal differences between languages, such as the difference between US English and British English, which diverge significantly in terms of spelling and pronunciation.
The rules for creating language attribute values are described by an IETF specification called BCP 47. In addition to specifying how to use simple language tags, such as en for English or fr for French, BCP 47 describes
how to compose language tags that allow you specify regional dialects, scripts and other variants related to that language.
BCP 47 incorporates, but goes beyond, the ISO sets of language and country codes. To find relevant codes you should consult the IANA Language Subtag Registry.
For a gentle but fairly thorough introduction to the syntax of BCP 47 tags, read Language tags in HTML and XML. For help in choosing the right language tag out of the many possible tags and combinations, see Choosing a language tag.
Choosing the right attribute
If your document is HTML (ie. served as text/html), use the lang attribute to set the language of the
document or a range of text. For example, the following sets the default language to French:
<html lang="fr">
When serving XHTML 1.x or polyglot pages as text/html, use both the lang attribute and the xml:lang attribute together every time you want to set the language. The xml:lang attribute is the standard way to identify language information in XML. Ensure that the values for both attributes are identical.
<html lang="fr" xml:lang="fr" xmlns="http://www.w3.org/1999/xhtml">
The xml:lang attribute is not actually useful for handling the file as HTML, but takes over from the lang attribute any time you process or serve the document as XML. The lang attribute is allowed by the syntax of XHTML, and may also be recognized by browsers. When using other XML parsers, however (such as the lang() function in XSLT) you can't rely on the lang attribute being recognized.
If you are serving your page as XML (ie. using a MIME type such as application/xhtml+xml), you do
not need the lang attribute. The xml:lang attribute alone will suffice.
<html xml:lang="fr" xmlns="http://www.w3.org/1999/xhtml">