Respuesta
La normalización es algo que se debe tener en cuenta si está en la autoría de páginas HTML con hojas de estilo CSS en UTF-8 (o cualquier otra codificación Unicode), particularmente si se debe tratar con texto de script que emplea acentos u otros diacríticos.
¿Qué son formas de normalización?
En Unicode es posible producir el mismo texto con distintas secuencias de caracteres. Por ejemplo, la palabra en húngaro világ. La cuarta letra podría guardarse en la memoria como un U+00E1 precompuesto LA LETRA A MINÚSCULA LATINA CON ACENTO AGUDO (un solo carácter) o como una secuencia descompuesta de U+0061 LETRA A MINÚSCULA LATINA seguida de U+0301 COMBINACIÓN DE ACENTO AGUDO (dos caracteres).

El Estándar Unicode permite cualquiera de estas alternativas, pero requiere que ambos sean tratados como iguales. Para mejorar la efectividad, una aplicación generalmente normaliza el texto antes de realizar búsquedas o comparaciones. En este caso, la normalización significa convertir el texto para usar todos los caracteres precompuestos o todos los descompuestos.
Existen cuatro formas de normalización especificadas por el Estándar Unicode: NFC, NFD, NFKC y NFKD. La C representa (pre-)compuesto y la D, descompuesto. La K representa la compatibilidad. Para mejorar la interoperabilidad, W3C recomienda el uso de texto NFC normalizado en la Web.
¿Qué es necesario saber acerca de la normalización?
Desafortunadamente, la normalización no siempre se lleva a cabo antes de comparar el contenido. Un caso particularmente importante es el uso de selectores y nombres de clase o identificaciones en HTML y CSS. Si la palabra világ se usa en una forma precompuesta en HTML (p. ej., <span class="világ">), pero en la forma descompuesta en CSS (p. ej., .világ { font-style: italic; }), el selector no va a coincidir con el nombre de clase.
Esto significa que cuando se produce contenido, se debería asegurar que los selectores y los nombres de clase o identificación sean los mismos, carácter por carácter. Es muy probable que esto sea un problema si distintas personas tienen la autoría o dan mantenimiento a la marcación y el CSS.
La mejor forma de asegurar que coincidan es utilizar una forma particular de normalización Unicode para la autoría de todo contenido. Como se indicó antes, W3C recomienda NFC.
La mayoría de los teclados para los idiomas europeos ya producen texto en NFC, pero esto es menos probable si se trata con muchos idiomas no europeos
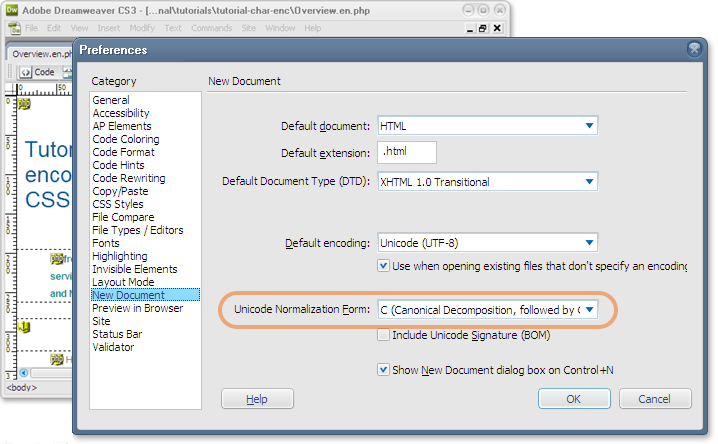
En algunos casos, su editor puede permitirle guardar información en distintas formas de normalización. La imagen a continuación muestra una opción para programar una forma de normalización particular como la predeterminada, cuando se abren nuevos archivos en DreamWeaver (se selecciona NFC). Se muestra una selección similar cuando se guarda un documento.
¿Cómo se puede verificar que las páginas no tengan problemas?
Se puede averiguar cuando una página HTML contiene nombres de clase y valores de identificación que no están normalizados de acuerdo al NFC mediante el Verificador internacional de W3C.
Si tiene problemas, debería encontrar un editor o una herramienta de conversión que le permita especificar la forma de normalización y usarla para volver a guardar su página.