Unicode normalization is something you need to be aware of if you are authoring HTML pages with CSS style sheets in UTF-8 (or any other Unicode encoding), particularly if you are dealing with text in a script that uses accents or other diacritics.
This page addresses the question: What is Unicode Normalization, and why do I need to know about it when creating HTML and CSS content?
What is Unicode normalization?
In Unicode-encoded content it is possible to produce the same text with different sequences of characters. For example, take the Hungarian word világ. The fourth letter could be stored in memory as a precomposed (single) code point U+00E1 LATIN SMALL LETTER A WITH ACUTE or as a decomposed sequence of U+0061 LATIN SMALL LETTER A followed by U+0301 COMBINING ACUTE ACCENT (two code points).
The Unicode Standard allows either of these alternatives, but requires that both be treated as identical by applications (ie. they are 'canonically equivalent'). To improve effectiveness, an application will usually normalize text before performing searches or comparisons. Normalization, in this particular case, means converting the text to use all precomposed or all decomposed characters.
Four normalization forms are specified by the Unicode Standard: NFC, NFD, NFKC and NFKD. The C stands for (pre-)composed, and the D for decomposed. The K stands for compatibility.
NFD uses Unicode rules to maximally decompose a code point into component parts. For example, the Vietnamese letter ề [U+1EC1 LATIN SMALL LETTER E WITH CIRCUMFLEX AND GRAVE] becomes the sequence ề [U+0065 LATIN SMALL LETTER E + U+0302 COMBINING CIRCUMFLEX ACCENT + U+0300 COMBINING GRAVE ACCENT].
NFC runs that process in reverse, and will also completely compose partially decomposed sequences. However, this composition process is only applied to a subset of the Unicode repertoire. For example, the sequence g̀ [U+0067 LATIN SMALL LETTER G + U+0300 COMBINING GRAVE ACCENT] has no precomposed form, and is unaffected by normalization.
NFKC and NFKD were introduced to handle characters that were included in Unicode in order to provide compatibility with other character sets. This applies to code points that represent such things as glyph variants, shaped forms, alternative compositions, and so on. NFKD and NFKC normalization replaces these code points with canonical characters or character sequences, and you cannot convert back to the original code points. In principle, such compatibility variants should not be used.
What do I need to know about normalization?
Choosing a normalization form
Natural language content aimed at human consumption does not need to all be in one normalized form – there may sometimes be good reasons to mix normalized forms. Applications that try to match one piece of text with another should, however, compare normalized versions of both.
Unfortunately, normalization doesn't always take place before content is compared, and a particularly important case is when CSS selectors are compared with HTML class names or ids, as style is applied to a page. If the word világ (meaning 'word' in Hungarian) is used in precomposed form in the HTML (eg. <span class="világ">), but in decomposed form in the CSS (eg. .világ { font-style: italic; }), then the selector won't match the class name.
The following example shows this. The CSS selector is decomposed, whereas one class name in the HTML is decomposed and the other precomposed. As you should be able to see, only the decomposed class name is matched to the style. But notice also that it is not possible to distinguish the two forms in the source text.
This means that when creating content you should ensure that selectors and class or id names are character-for-character the same. This is particularly likely to be a issue if the markup and the CSS are being authored or maintained by different people.
The best way to ensure that these match is to use one particular Unicode normalization form for all syntactic constructs, and as the default for all authored content. It doesn't really matter whether you use the NFC or NFD normalization form, it's more important that you are consistent. NFC is, however, a good recommendation because this is what many (but not all) keyboards tend to produce. (Most keyboards for European languages output text in NFC already, but this is less likely to be the case if dealing with many non-European languages.)
We don't recommend using any of the K forms in this way.
Converting the normalization form of a page
You should also try to avoid automatically converting content from one normalization form to another, as it may obliterate some important code point distinctions, such as in the carefully crafted examples of világ above, or in filenames or URLs, or text included in the page from elsewhere, etc.
It may also introduce a security risk, especially in code syntax. For example, the following code points are canonically equivalent: ≯ [U+003E GREATER-THAN SIGN + U+0338 COMBINING LONG SOLIDUS OVERLAY] and ≯ [U+226F NOT GREATER-THAN]. Therefore source code in XML such as <character≯</character> can be corrupted by normalising to NFC.
Sometimes people choose to use compatibility characters in their content, most likely without realising what they are. Examples might include ¼ [U+00BC VULGAR FRACTION ONE QUARTER], ² [U+00B2 SUPERSCRIPT TWO] (eg. for m²), and № [U+2116 NUMERO SIGN]. Blind normalization of that content would change those characters to the ASCII code points 1⁄4, 2, and No, respectively. In some cases this may affect the look of the text; in others it may affect the readability.
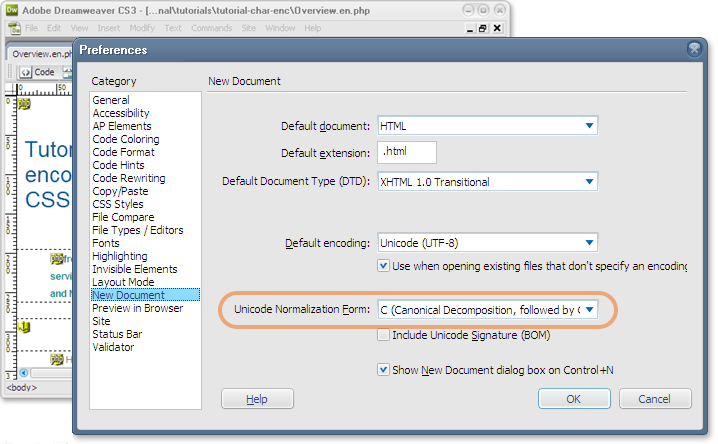
Normalization settings in your editor
In some cases your editor may allow you to save data in a choice of normalization forms. The picture below shows an option for setting a particular normalization form as the default when opening new files in Dreamweaver (NFC is selected). You are shown a similar choice when saving a document.
If you have set up your editing environment like this, you may find yourself in a situation where you want to deviate from the default normalisation form, for instance to create the examples above. However, as soon as you save the file, it will obliterate those carefully implemented variant forms. A way around this is to use character escapes. If you write the word világ in your source code as világ it will not be normalized during the save.
How can I check pages for problems?
You can find out whether an HTML page contains class names and id values that are not normalized according to NFC by using the W3C Internationalization Checker. (Look for the row Markup / Non-NFC class or id names.)