Antwort
Was ist ein BOM?
A Byte Order Mark, sometimes abbreviated "BOM", is a special Unicode character intended to appear at the very beginning of a text file. Its original purpose was to indicate the endianness
of text that used the UTF-16 or UTF-32 character encodings of Unicode. The Byte Order Mark is U+FEFF ZERO WIDTH NON-BREAKING SPACE: the character name refers to a separate, deprecated, use of the character.
Some systems use the BOM code point at the start of a file to indicate that text files are using the UTF-8 character encoding, even though UTF-8 does not need a marker to indicate endianness.
While often invisible and intended to aid in correctly interpreting text, the presence of the BOM can sometimes cause unexpected display issues or problems with software if not handled correctly.
Die Bezeichnung BYTE ORDER MARK ist ein Alias für die ursprüngliche Bezeichnung ZERO WIDTH NO-BREAK SPACE (ZWNBSP, nullbreites geschütztes Leerzeichen). Mit der Einführung des Zeichens U+2060 WORD JOINER (Wortverbinder) besteht es keine Notwendigkeit mehr, U+FEFF in seiner ZWNSP-Funktion zu verwenden. Ab diesem Zeitpunkt und weil es einen formellen Alias gibt, ist die Bezeichnung ZERO WIDTH NO-BREAK SPACE nicht mehr passend. Hier wird deswegen der Alias verwendet.
Bevor UTF-8 Anfang 1993 eingeführt wurde, war der vorgesehene Weg, Unicode-Text zu übertragen, Zeichen in 16 Bit zu codieren. Die Zeichencodierung wurde UCS-2 genannt und später zu UTF-16 erweitert. Einheiten zu 16 Bit können auf zwei Arten in Bytes repräsentiert werden: das höherwertige Byte zuerst (big-endian) oder das niederwertige Byte zuerst (little-endian). Um anzugeben, welche Reihenfolge der Bytes verwendet wurde, wird das Zeichen U+FEFF (das BOM, byte-order mark) an den Anfang des Datenstroms gesetzt – als Wundermittel, das sinngemäß nicht zum Text gehört, den der Datenstrom repräsentiert.
Die folgende Abbildung zeigt die Bytes für eine Folge von Zwei-Byte-Zeichen. Jede Hexadezimalzahl mit 2 Ziffern steht für ein Byte im Datenstrom. Sie können sehen, das die Reihenfolge der beiden Bytes, die ein Zeichen repräsentieren, bei big-endian gegenüber little-endian umgedreht ist. Das BOM zeigt an, welche Reihenfolge gilt, damit die Anwendung den Inhalt unmittelbar decodieren kann.
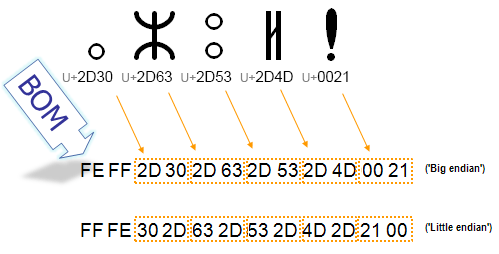
Bei UTF-8 ist im Gegensatz zu den UTF-16-Codierungen kein BOM erforderlich, denn hier gibt es nur eine mögliche Reihenfolge der Bytes für ein bestimmtes Zeichen. Das BOM kann dennoch in UTF-8-codiertem Text auftreten, entweder als Nebenprodukt einer Umwandlung der Zeichencodierung oder weil es durch ein Editorprogramm hinzugefügt wurde, um den Inhalt als UTF-8 zu markieren. In diesem Fall wird das BOM auch oft UTF-8-Signatur genannt.
Was muss man über das BOM wissen?
Meist muss man sich über das BOM in UTF-8 keine Gedanken machen. Einige Texteditoren (wie bspw. Windows Notepad) fügen immer ein BOM ein, wenn eine Datei UTF-8-codiert gespeichert wird, andere bieten mit oder ohne BOM zur Auswahl an.
Gemäß HTML5 wird von Browsern verlangt, dass sie das UTF-8-BOM erkennen und dazu verwenden, die Zeichencodierung der Seite zu ermitteln. Die aktuellen Versionen der gängigen Browser verfahren mit dem BOM bei UTF-8-codierten Seiten wie erwartet.
Das UTF-8-BOM ermöglicht eine verlässliche Erkennung der Zeichencodierung, denn es ist sehr kurz und solide, funktioniert in XML und HTML und funktioniert unabhängig davon, ob die Seite übers Netz übertragen wird oder nicht (im Gegensatz zur Angabe in HTTP). Bedenken Sie aber, dass es immer gut ist, die Zeichencodierung zusätzlich zum BOM per meta-Element anzugeben, damit die Zeichencodierung für alle ersichtlich ist, die sich den Quelltext ansehen.
In einigen Fällen kann das BOM Probleme bereiten, insbesondere weil es unsichtbar ist. Nähere Information dazu finden Sie im Abschnitt weiter unten.
Wenn Sie eine UTF-16-Codierung für Ihre Seite verwenden (wir raten dringend davon ab), gibt es noch weiteres zu beachten.
When to Use (and Not Use) the BOM
The necessity and recommendation for using a BOM varies significantly depending on the Unicode encoding scheme being used.
UTF-8
For UTF-8, the BOM is the byte sequence EF BB BF. Unlike UTF-16 and UTF-32, UTF-8 does not have byte order (endianness) issues, so a BOM is not needed for this purpose. Its only function in UTF-8 is to act as a "signature" to indicate that the file is UTF-8 encoded. The Unicode Standard permits the BOM in UTF-8 but does not recommend its use.
Recommendation: Generally, it's best to avoid using a BOM with UTF-8 files unless you have a specific reason or compatibility requirement. Always prefer UTF-8 without a BOM if possible.
UTF-16 (UTF-16BE & UTF-16LE)
For UTF-16, the BOM is crucial for indicating endianness if the specific endianness is not already defined by the character set label (e.g., if labeled just as "UTF-16").
FE FF: Indicates Big Endian (UTF-16BE).FF FE: Indicates Little Endian (UTF-16LE).- If a UTF-16 stream is read with the wrong endianness, the BOM character
U+FEFFwill appear asU+FFFE, which is a noncharacter. - If the character set is explicitly stated as "UTF-16BE" or "UTF-16LE", a BOM should not be used as the byte order is already known.
- Recommendation: Use a BOM if your UTF-16 data might be interpreted by systems with different native endianness and the specific endianness (BE or LE) is not declared by a higher-level protocol. If the specific UTF-16 encoding (LE or BE) is known and declared, omit the BOM. (However, for HTML, UTF-8 is strongly preferred over UTF-16).
UTF-32 (UTF-32BE & UTF-32LE)
Similar to UTF-16, the BOM in UTF-32 indicates endianness but UTF-32 is rarely used for transmission or web content.
00 00 FE FF: Indicates Big Endian (UTF-32BE).FF FE 00 00: Indicates Little Endian (UTF-32LE).- Recommendation: Similar to UTF-16, use a BOM if endianness is not otherwise specified. (Again, UTF-8 is preferred for HTML).
Das BOM erkennen
Ob bei einer Webseite am Anfang oder inmitten des Inhalts ein BOM vorkommt, lässt sich mithilfe des W3C-Internationalization-Checkers herausfinden. Ein BOM am Seitenanfang wird unter „Information“ aufgeführt. Ein BOM weiter unter auf der Seite (typischerweise durch aus einer externen Quelle eingefügten Inhalt) wird unter „Detailed Report“ aufgeführt.
Sie können versuchen, das BOM im Dateiinhalt zu erkennen, doch wenn Ihr Editor das BOM richtig behandelt, wird es nicht zu sehen sein. Ein Hex-Editor, der die einzelnen Bytewerte anzeigt, zeigt das BOM als EF BB BF.
Wenn Ihr Editor oder Browser die falsche Zeichencodierung auf eine in UTF-8 mit DOM codierte Datei anwendet, zeigt er zu Beginn die Zeichen an, die den Bytes des BOMs in der eingestellten Zeichencodierung entsprechen. Bei Latin-1 (ISO 8859-1) sind dies die Zeichen .
Möglicherweise zeigt Ihr Editor auch in der Statuszeile oder einem Menü, welche Zeichencodierung verwendet wird und ob ein BOM vorhanden ist oder nicht. Wenn Sie bspw. in Dreamweaver „Speichern unter…“ („Save As…“) verwenden und Ihre Datei ein BOM am Anfang hat, ist das Häkchen bei „Include Unicode Signature (BOM)“ gesetzt. In den Voreinstellungen (siehe Abbildung) können Sie angeben, ob neue Dokumente ein BOM verwenden sollen.
Mögliche Probleme mit dem UTF-8-BOM
Im Folgenden werden einige Situationen beschrieben, in denen das BOM Probleme bereitet.
Im Allgemeinen verschwinden diese Probleme mit der Verwendung neuerer Browserversionen und Editoren. Sie sollten sie aber kennen, wenn Ihre Nutzer noch ältere Versionen verwenden. Hier geht es aber nicht nur um Probleme mit älterer Software.
PHP-Includes
Zum Zeitpunkt des Erscheinens dieses Artikels ist es so, dass wenn man eine externe Datei mit PHP in eine Webseite einbindet und diese mit einem BOM beginnt, dadurch Leerzeilen entstehen können.
Das rührt daher, dass das BOM vor dem Einfügen in die Seite nicht entfernt wird und sich wie ein Zeichen verhält, das eine Textzeile belegt. Siehe dieses Beispiel. In dem Beispiel erscheint eine Leerzeile, die das BOM beinhaltet, über dem ersten eingebundenen Textteil.
Sie sollten sicherstellen, dass eingebundene Dateien kein BOM am Anfang haben.
Sie werden auch feststellen, dass das BOM Probleme bei gewöhnlichen PHP-Seiten bereitet. Wenn man spezielle HTTP-Header sendet, muss der Funktionsaufruf zum Setzen des Headers vor jeglicher Ausgabe stehen. Ein BOM am Dateianfang beginnt die Ausgabe, bevor die header-Funktion aufgerufen wird, und kann zu Fehlermeldungen und anderen Problemen auf der jeweiligen Seite führen.
Verarbeitung durch Programmcode
Besonderes Augenmerk auf das BOM muss man bei Scripten oder Programmcode legen, die automatisch Dateien verarbeiten, die mit einem BOM beginnen. Bei einer Mustersuche am Anfang einer mit BOM beginnenden Datei bspw. benötigt man zusätzlichen Code, der auf das Vorhandensein eines BOMs prüft und es gegebenenfalls ignoriert.
Die UTF-8-Codierung ohne BOM hat die Eigenschaft, dass ein Dokument, das ausschließlich ASCII-Zeichen enthält, Byte für Byte genauso codiert ist wie dasselbe Dokument in der US-ASCII-Codierung. Solch ein Dokument kann sowohl als UTF-8-codiertes als auch als US-ASCII-codiertes verarbeitet und verstanden werden. Mit BOM kommen zusätzliche Nicht-ASCII-Bytes hinzu, so dass dies nicht mehr gilt. Wenn Sie Prozesse oder Scripte haben, die davon ausgehen, dass der Inhalt nur aus ASCII-Zeichen besteht, müssen Sie das BOM vermeiden.
Vorrang vor HTTP
Die HTML5-Spezifikation wurde kürzlich geändert und besagt nun, dass das BOM die Zeichencodierungsangabe im HTTP-Header überschreiben sollte, wenn die Zeichencodierung eines HTML-Dokuments ermittelt wird. Das kann sehr hilfreich sein, wenn der Seitenautor keinen Einfluss auf die Servereinstellungen zur Zeichencodierung hat oder sich deren Bedeutung nicht bewusst ist und der Server für die Seiten eine andere Codierung als UTF-8 angibt. Wenn das BOM höhere Priorität als der HTTP-Header hat, sollten die Seiten korrekt als UTF-8 erkannt werden.
Zum Zeitpunkt des Erscheinens dieses Artikels tun das nicht alle Browser, wenngleich geplant ist, dass alle gängigen Browser dieses Verhalten demnächst übernehmen. Sie sollten jedoch nicht davon ausgehen, dass bereits alle Leser Ihrer Seiten schon davon profitieren.
Frühere Versionen des Internet Explorers gaben dem BOM Vorrang gegenüber HTTP, doch IE10 und IE11 gaben HTTP höhere Priorität.
In Browsern, in denen der HTTP-Header noch das BOM überschreibt und der Server angibt, dass die Seiten in einer Nicht-Unicode-Codierung vorliegen, erscheinen vermutlich unerwartete Zeichen am Seitenanfang (wie  auf einer in HTTP als ISO 8859-1 deklarierten Seite) und bei der Anzeige von Nicht-ASCII-Zeichen auf der Seite treten Probleme auf.
Weiteres
Wenn Sie im Backend Ihrer Website Anwendungsprogramme oder Scripte verwenden, sollten Sie prüfen, ob diese imstande sind, das BOM zu erkennen und damit umzugehen.
Wir empfehlen ausdrücklich, dass Sie die Zeichencodierung einer UTF-8-codierten Datei nicht zu einer Nicht-Unicode-Codierung ändern. Doch wenn Sie das aus speziellen Gründen tun sollten, müssen Sie dafür sorgen, dass das BOM entfernt wird. Wenn Sie das nicht tun, wird ein Browser entweder die Datei weiterhin als UTF-8 behandeln, oder es erscheinen ungewöhnliche Zeichen am Seitenanfang.
Das BOM entfernen
Wenn Sie das BOM entfernen müssen, überprüfen Sie, ob Ihr Editor ermöglicht einzustellen, ob beim Speichern ein BOM hinzugefügt wird bzw. erhalten bleibt. Solch ein Editor erlaubt es Ihnen, auf einfache Weise das BOM zu entfernen: die Datei einlesen und wieder speichern. Editoren wie bspw. Notepad++ unter Windows und BBEdit auf dem Mac erlauben in der Dialogbox „Speichern unter…“ die Zeichencodierung zu wählen. Dort gibt es die Optionen UTF-8 mit oder ohne BOM. Wählen Sie die Optionen ohne BOM und speichern Sie die Datei.
Ein Script bietet u.a. den Vorteil, dass es das BOM schnell entfernen kann – auch in mehreren Dateien. Solch ein Script könnte automatisch als Teil des Arbeitsprozesses laufen.
Anmerkung: Überprüfen Sie, welchen Einfluss die Entfernung des BOM hat. Es könnte sein, dass irgendein Teil in ihrem Arbeitsprozess das BOM benötigt um zu erkennen, dass eine Datei UTF-8-codiert ist. Beachten Sie auch, dass Seiten mit einem hohen Anteil an lateinischen Buchstaben auf den ersten Blick korrekt aussehen, aber vereinzelte Nicht-ASCII-Zeichen (außerhalb des Bereichs U+0000 bis U+007F) nicht korrekt codiert sein könnten.