In this article we look at design and development practices that can cause major problems for translation. Designers must be very
careful about how they split up and reuse text on-screen because the linguistic differences between languages can lead to real headaches for
localizers and may in some cases make a reasonable translation impossible to achieve.
After reviewing the concepts and issues relating to text fragmentation and string reuse, we will look at what works and what
doesn't.
Composite Messages
Composite messages dynamically compose a single message from more than one text string. The usual reason for
creating composite messages is that one or more parts of the composite message will change according to the context.
Composite messages are typically arranged in one of two ways: the first is a sentence-like arrangement; the
second, a topic-comment arrangement.
The parts of a composite message that vary are referred to here as substrings.
Sentence-like arrangements
The example below is of a sentence-like composite message. This arrangement expresses an idea using a flowing, sentence-like syntax.
It is usually the most problematic approach.
{
printer
}
The
stacker
has been disabled.
stapler options
In this example, the designer has created a single string to serve for the common parts of three sentences, ie. The ... has been
disabled.. Three alternating substrings have also been created, and the appropriate one is substituted at runtime to create the appropriate
message for the context.
This is generally a popular idea with designers because reducing the identical parts of a number of messages to a single string
appears to offer a way to reduce the work of the text author, improve message consistency, and optimize memory.
Unfortunately, even if this works in one language, it can be either difficult or impossible to deal with such composite messages in
other languages because of differing rules for sentence structure, agreement and so on.
The problem of agreement is already illustrated in the English example. If the alternative string stapler options is used
at runtime, the word has will be incorrect - it should say have.
The key issue is that, since there is now only a single string containing the word has, it cannot read have when needed.
This often gets even more complicated when we translate into other languages. For example, in French the word for the would be translated le, la, les, or l', depending on what immediately follows. Similarly, the word disabled would need to be désactivé, désactivés, désactivée, désactivées, depending on the gender and number of the subject. Even if stapler options had not
been an option, and the composite messages had all looked fine in English, the French translator would have been faced with an impossible job.
Topic-comment arrangements
Topic-comment arrangements state a topic (the subject) and then state something about it (the comment), usually in a terse way. For
example: Printer: enabled. Note that the colon is very commonly used to separate topic and comment in this arrangement.
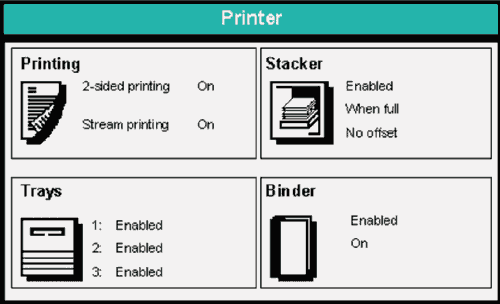
Here is an example that shows some variations on the theme of the topic-comment arrangement.
The topics are unchanging strings such as 2-sided printing, [Tray] 1, and Binder. Each topic
is followed by one of a set of alternative (and pre-defined) comment strings. For example, the topic 2-sided printing is followed by the
comment On. Note how the topic and the comment are in separate display areas here, though that is not always the case.
Most of the messages above are split across two text display areas. The message referring to the binder, however, is split across three display areas - that is, the topic has two comments: the binder is both Enabled and On. This is a perfectly
valid approach and poses no issues for translation.
Here are some other examples of topic-comment composite messages.
The comments here are also translatable text substrings, although in this case all the comments are visible at the same time — that
is, this is an example of a substring-list. In many languages words like lighter and darker will have to agree in gender
with the topic (Image quality).
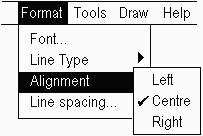
Here we are dealing with a pull-down menu, but the concepts remain the same. The words Left, Centre and Right are translatable text substrings and in many languages must agree with the topic Alignment when translated.
The messages in this set are implemented as variables embedded in parent strings. They nonetheless retain the topic-comment
arrangement. Note that on the last line the topic again has two comments - the test is both completed and passed.
Directory: C:/Workgroup/Scan
File name: MyFile.tif
Image Quality: Text
Original Size: Auto
Resolution: 300 dpi
Communication Test: Completed: Passed
Substring types
There are several types of substring, each of which introduces slightly different requirements for translatability. In this article we
will refer to the following types of substring:
Predefined, translatable text. Pre-defined words or phrases in the message set that will need to be
translated, such as the words printer, stacker or binder in the example above.
Non-translatable, runtime defined text. A non-translatable and non-numeric string that is generated
by the user at runtime or a non-translatable name, as in Error occurred while processing job %s, where %s is the name of the job as
supplied by the user.
Numeric. A numeric string that is generated at runtime by the product or is one of a set of fixed
values such as Pages printed: %d, where %d is the number of pages the machine has counted so far.
Graphic. A graphic selected from a number of alternatives as part of a composite message, for
example, a symbol of a paper tray embedded in text related to paper trays. This is not strictly a substring, but we can regard it as such since it
may be used in a similar way.
Internationalization issues
Inflexible syntax
The following problems are a common feature of sentence-like composite messages. The original text assumes a particular order for the
words in a sentence, and that order may need to be different in another language.
Across separate display areas.
One common problem is caused when composite message components are spread across different display
areas, making it difficult to reorder those components easily.
The following example shows a composite message whose parts are split across different table cells for purposes of layout. (A dotted
line shows the cell boundaries.)
Return web pages updated
In order to achieve a good translation, the translator may want to move the text in one table cell to another. This may change the
originally intended layout of the designer who implemented the table. For example, the word order in German can lead to a translation such as the
following:
veränderte Webseiten abrufen.
If a translator is unable to reorder the message in this way, they may be able to use a topic-comment arrangement to resolve this
issue. Otherwise, the result is likely to be, at best, a very poor translation. For example, the text could be reworded in the target language to
mean:
Time period for returned web pages:
Variables that cannot be reordered.
It must be possible to reorder variables in sentence-like arrangements and reposition them in any way relative to the text.
For example, when programming in PHP it is possible to code the string "There were <number> spelling mistakes in file
<filename>." as follows:
printf( "There were %d spelling mistakes in file %s.", spellerrors, filename)
Unfortunately, if you do so, and if the translator produces the German translation as "Datei
<filename> enthält <number> Rechtschreibfehler." this is likely to introduce a bug into the code. That is because PHP does not
allow you to reorder values of the %d and %s variables.
Instead you should code the text as:
printf( "There were %1\$d spelling mistakes in file %2\$s.", spellerrors, filename)
This will now allow the translator to reorder the variables without potentially introducing a bug.
The translated string, reintegrated into the code, would read:
This issue is by no means specific to PHP. Many programming languages allow you to attach a unique identifier to a variable so that
there is no ambiguity when variables are moved around. You should try to always take advantage of this feature.
Composite messages that are incomplete strings.
A much more serious situation can arise given an example such as the following:
print( "Retrieving last " );
print( desiredEntries );
print( " of " );
print( totalEntries );
print( " total log entries." );
The Japanese translation would put total log entries at the beginning of the sentence and last retrieving at
the end. Much more importantly, it would be necessary to reverse the order of print(desiredEntries) and print(totalEntries). (In the example below I have added translations, to help you see how the text would need to be reordered.)
The problem is that translators are normally prevented, with good reason, from changing anything but the strings in code. Otherwise an
inadvertent edit can introduce a serious bug. Thus, a translator is likely to be presented with the following text for translation:
1: "Retrieving last "
2: " of "
3: " total log entries."
The main issue here is that the translator would have to edit the code to produce the most appropriate translation in
Japanese. This is highly undesirable. In addition, there is also a risk that the translator struggles to identify the beginning and end of such
messages, especially if the strings are not supplied to the translator together and in order.
Note that similar problems also arise in code that looks like the following example. Even though this is in a single print statement,
it doesn't improve matters.
print( "Retrieving last " + requiredEntries + " of " + totalEntries + " total log entries." );
A better approach would be to use a print function that allows you to specify the variables as a part of the string to print. For
example:
print( "Retrieving last $requiredEntries of $totalEntries total log entries." );
Agreement and word/concept mappings
Gender agreement.
Predefined, translatable text substrings in a sentence-like arrangement can create insurmountable difficulties for the translator
because of the linguistic properties of many languages.
The following example shows a sentence-like parent string into which the appropriate predefined substring will be inserted at
run-time.
The %s has been disabled.
The %s will be replaced at run-time with one of:
printer
stacker
stapler options
The problem here is already visible even in English, since the word has should be have alongside the
substring stapler options. In French, the substrings above are, respectively, feminine singular, masculine singular and feminine plural,
and would require three very different translations of the parent string:
L'imprimante a été désactivée.
Le module de reception a été désactivé.
Les options d'agrafage ont été désactivées.
The word the may also be la in French if the next word is feminine and begins with a
consonant, and the word disabled would need to be translated désactivés for a masculine plural
noun. Such agreement is extremely common in languages other than English or Japanese and can often be more complicated than in French.
The key issue here is that, since we only have one string to translate, it is impossible to apply the various appropriate translations
in French to the parent string.
Such an implementation probably arose from the designer's or developer's attempts to improve the situation, but unfortunately a lack
of knowledge about what would happen in translation has created a major problem for the foreign versions of the product.
A better approach here would be either to use separate strings, or to use a topic-comment arrangement, such as Disabled
function: printer, etc. Note that in the latter case the word disabled refers to function, and is therefore
unchanging.
Word and concept mappings.
Word and concept mappings can also cause problems. Take, for example, the sequence:
Turn on the %s.
The %s will be replaced at run-time with one of:
printer
stacker
stapler options
In some languages, the appropriate translation for Turn on may vary according to what is being turned on. For example,
Spanish may translate this idea with distinct terms such as conectar, encender or activar. There would also be four
possible translations for the word the. Since there is only one instance of the initial string, it is again impossible to provide a
quality translation.
You should always try to ensure that the invariant part is expressed as a topic.
Gender agreement and runtime-defined substrings.
Here we refer specifically to text supplied at runtime — such as a file name, job name, person's name and so on — or to
non-translatable names. These are not predefined translatable substrings.
Normally, even in sentence-like arrangements, these types of substring do not cause internationalization problems. For example, the
translated sentences below do not need to agree with the text substring since the subject of the sentence (ie. in this case file or section) is already defined or clearly inferred to be something different from the substring itself.
The file <file_name> has been scanned.
The section <section_title> gives further information.
In linguistic terms, this works because the text of the variable is provided in apposition to the subject.
Putting in words like section and file is recommended, rather than inferring them. This helps the translator understand the meaning of
the message.
There is, however, an exception to this rule. If the text variable refers to a person rather than an object, many languages
will still require changes to other parts of the sentence according to the gender of the person. For example:
The patient <person's_name> is ready.
Spanish translations for this could be:
El enfermo Richard está listo.
or
La enferma Julia está lista.
In other words, embedded runtime-defined substrings only work in sentence-like arrangements if they don't represent a proper noun. It
is better to use topic-comment arrangements for these types of message.
Number agreement.
Numeric substrings do not work well in sentence-like arrangements.
In many languages the word that is qualified by a number changes according to how many we are talking about. Take for example the
message %d pages were printed.
In English, pages were should become page was if only one page was printed. Sometimes authors try to get
around this by saying %d page(s) printed.
Unfortunately, things are not so simple in other languages. For example, Arabic has different verb and noun endings for one page, two
pages and more than two pages, that is, they have two different types of plural.
Russian is even more complicated. The accompanying table shows the endings for the word page in Russian
when associated with different numbers.
Number of pages
Russian word for 'page'
1
страница
2-4
страницы
5-10
страниц
11-20 (irregular)
страниц
21
страница
22-24
страницы
25-30
страниц
> 30
Repeat pattern of endings for 1 to 10.
As a result, it is extremely difficult to deal with such a message expressed in a sentence-like arrangement. It is therefore better to
always express messages containing numbers like this as a topic-comment arrangement. In a topic-comment arrangement, the word pages remains invariant. The Russian equivalent, meaning Pages printed: %d, is shown below.
Отпечатано страниц: %d
Indistinguishable substrings
If a translator is to switch the order of substrings in a message, it must be clear what the intended new order is.
Take the following example:
%s near '%s' at line %d
A Japanese translation of this would be
%d 行の%s近くに%s
What is not clear from looking at this example is that the translator intended to reverse the two variables called %s. This, of
course, is not clear to the software, either.
It therefore makes sense to use a unique identifier for each variable in a string. We have already seen that, in PHP, for example, you
could obtain this by coding the English as:
%1\$s near '%2\$s' at line %3\$d
In Japanese this would give:
%3\$d 行の%2\$s近くに%1\$s
The need for context
The translator must be provided with a means to associate a comment with its topic in order to achieve a translation.
For many languages it is usually not possible to translate the comment part of a topic-comment message unless you know what the topic
is. The word enabled in French is translated in one of four different ways, according to whether the topic is masculine, feminine,
singular or plural:
Topic
Part of speech
Translation of 'enabled'
stacker
masculine, singular
activé
printer
feminine, singular
activée
bar codes
masculine, plural
activés
stapler options
feminine, plural
activées
In other languages there are many other possibilities, since there are more than two genders and there may be case endings.
If the translator were presented with the word enabled on its own for translation, he or she would have no idea how it
should be translated. For example, presenting text to the translator in the following order would prove very difficult to handle.
enabled
disabled
enabled
enabled
disabled
stacker
printer
enabled
bar codes
stacker
disabled
etc.
The only way to address this is to attempt a translation, look at the result in completed interface, and then retranslate as
necessary. This is a time consuming process. It would be much better to ensure that the translator can see straight away how these things
correspond.
There are a number of ways of achieving this:
The text could be ordered so that it is intuitive what goes where.
stacker
enabled
disabled
stacker
enabled
disabled
printer
enabled
disabled
etc.
The correspondences could be indicated by message ids.
Designers could use some kind of annotation to provide this information.
Differences may also be semantic in nature. For example, if the word on was used here rather than enabled,
the appropriate translation in Spanish may be encendida for the printer but activadas for the stapler options. conectado is another translation of the word on. Each of these three words also has four agreement forms. This gives 12 possible translations.
Recommendations
Use a topic-comment approach whenever possible. Topic-comment composite messages work well whether the parts
are in a single or multiple displayers, and with any type of substring.
Avoid sentence-like arrangements when they contain substrings that are predefined translatable text or numeric
text.
Use sentence-like arrangements with care if you have non-numeric and non-translatable text substrings (ie.
text created at runtime). Do not use if the substring represents a proper noun. In addition, implement sentence-like messages such that the text and
substrings can be easily repositioned in any order during translation. When writing program code this usually means using format strings for output
in such a way that each variable is uniquely identified.
Where the parts of a composite message appear in separate locations, provide the translator with contextual
information to show how the various parts of a composite message relate to each other - especially which substrings relate to which other
composite message parts. Preferably composite message parts should be grouped together for delivery to the translator.
Provide information to the translator, where needed, to clarify what a substring represents (eg. something
like "%s near '%s' at line %d" can pose a challenge for a translator). For this purpose, consider using the ITS Localization Note data category.
When requested by the localization group, provide information about the size of each substring to help test
whether the translation fits in a fixed-size space. For this purpose, consider using the ITS Storage Size attribute.
In another article we also discuss a number of important things to bear in mind in terms of re-use of text strings.