Mission Possible
Part 1:
- What, exactly, is Linked Data?
- The big picture and today's building blocks
Part 2:
- Viewing Your Data as Triples (slides)
- Working with RDF vocabularies; communicating via triples
Part 3:
- Publishing Triples on the Web (slides)
- The mechanics and politics of actually making the data available
please send comments and questions to sandro@w3.org subject 'tutorial'
Part 1: Fundamentals
- Context and Motivation
- What is a URI?
- What is an RDF Triple?
- Data dormats for RDF Triples
About Us
- @sandhawke
- programmer (C, C++, Java, Perl, Prolog, now mostly Python)
- at W3C since 2000, doing RDF, OWL, RIF, SPARQL, Govt
- W3C: consensus standards, founded by TimBL 1994
- about 60 Working Groups doing HTML(5), CSS, SVG, XML, Accessibility
- @johnlsheridan
- Civil Servant since 2004
- lead on Linked Data for data.gov.uk
- co-chair of W3C e-Government IG
About You (Just Curious)
- Do you work for the government (Federal, State, City, County) or for a supplier?
- Can you read/write HTML?
- Can you read/write some data format:
- Can you program in some language:
- C, C++, Java?
- Perl, Python, Ruby?
- Javascript?
- XSLT?
- Do you know how HTTP works:
- Response Codes (eg 403 Forbidden)?
- Content Types and Content Negotiation?
- RESTful APIs?
- Formal math, logic, logic programming?
- The difference between "domain" and "range"?
- The Unique Names Assumption? Negation-as-Failure?
Context
- Growing demand for open government data
- US, UK, Australia, New Zealand, Netherlands, Denmark, Sweden, ...
- Astrurias and Catalan Regional Governments, London, Vancouver, ...
- Many motivations
- transparency and engagement
- holding government accountable and promoting choice by informing citizens
- efficiency and enhanced public services
- enabling re-use of information within the public sector
- innovation and economic growth
- encouraging and supporting data-based innovation
Download and Programmatic Access
- Downloadable datasets
- Excel, CSV, XML
- global data
- one-off visualisations
- static data
- Programmatic access
- JSON / XML APIs
- local data
- on-demand visualisations
- changing data
About the "Semantic Web"

- The Web should be more than just documents for people to read
- Allow machines to traverse, aggregate, analyze, answer
- TimBL's vision, but it's a big tent
- "Semantics", "Ontologies" (Research Funding)
- Web Architecture, REST
See Kate Ray's Web 3.0 Video (esp. until 3:37 or 6:50)
Linked Data has a narrower goal; uses some of the same technologies.
What Is Linked Data?
Extending spreadsheets and databases to work over the Web.
- Give web identifiers (URIs) to things
- Publish information about them as Web Resources (good website architecture)
- Use Triples (subject, property, value)

Benefits of Linked Data
- Enables web-scale data publishing
- distributed publication with web-based discovery mechanisms
- Everything is a resource
- discover more about properties, classes, codes within a code list (we'll explain more)
- Everything can be annotated
- make comments about observations, data series, points on a map (we'll explain more)
- Easy to extend
- create new properties as required, no need to plan everything up-front (we'll explain more)
- Easy to merge
- slot together RDF graphs, no need to worry about name clashes (we'll explain more)
Why does Linked Data make sense for government?
- Responsible Publishing of data (we'll explain why)
- Combine different data about the same things, although it is held by different parts and levels of government
- Can make it easier for people to consume your data (we'll explain how)
- Can help solve some snags other approaches miss
RDF Triples
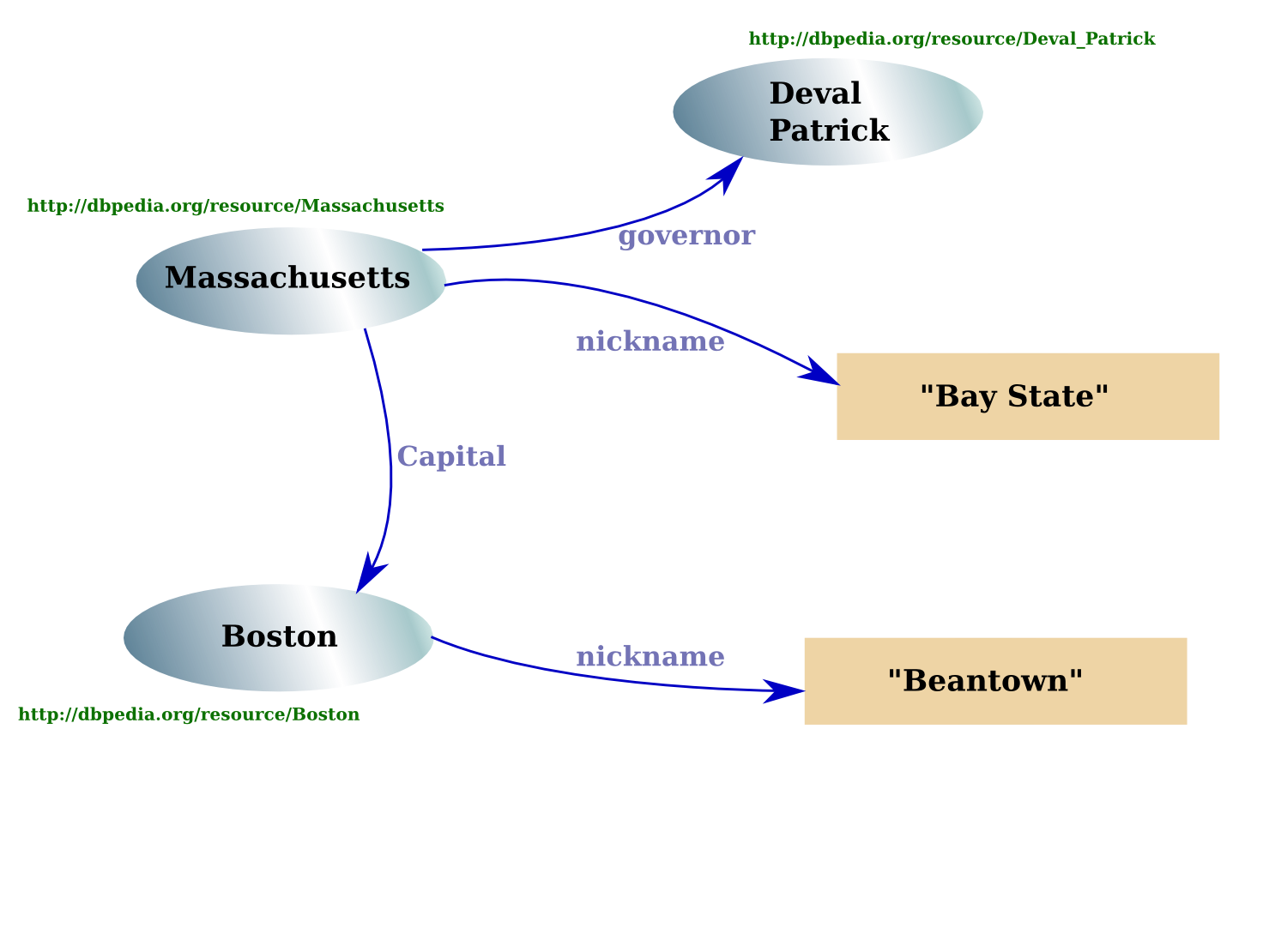
Quick Demo
- ... and try to imagine you're a machine.
So How Do You Add Your Data?
- Think in Subject-Property-Value Triples
- Use URIs
- Publish on the Web
URIs (A Little Web Architecture)
URIs are like URLs, with a few extra tricks.
Long history, "Web Architecture", lots of debate.
Here it is, put simply.
Information Resource
- Anything whose current state can be entirely represented in bytes.
- This is what we see on the Web, including:
- documents (maintained, or frozen)
- video and audio recordings
- photographs, drawings
- databases (product catalog)
Resource
- Anything at all. Anything anyone can conceptualize.
- Includes Information Resource, of course
- Also includes:
- specific people, cities, countries
- my dog, the set of all dogs, the set of all animals
- ... even Unicorns and Dragons

art credit
URLs identify Information Resources
URIs identify Resources
Any resource. Using filenames for things that aren't files.
- They often look just like URLs (many are URLs)
- But they can behave differently
- With some, there is no protocol for GET
- If it's a URL, GET works
- For others, the URI has an associated URL
Hash and Slash
Two kinds of indirection:
- Hash URIs contain a hash ("#") character: http://vocab.deri.ie/dcat#granularity
- chop off the hash and everything after it
- do your GET on what's left
- see what the result says about full, original URI
- Sometimes it turns out to be a "fragment" URL
- Hopefully it's not both (but it happens sometimes)
- Slash URIs don't contain a hash: http://purl.org/dc/elements/1.1/creator
- try to do a GET
- you might just get contents (so it was a URL)
- you might get a "303 See Other" redirecting you elsewhere
- Hopefully the new place says something useful using the original URI.
Hash vs Slash
Hash URIs:
- easier to construct
- more efficient on a small scale
- often used for small, controlled situations
Slash URIs:
- more control over user experience
- better scaling
You'll see both.
When publishing, your software may choose for you.
Review
- Use URIs to identify things
- Think in Triples
- Publish on the web
Publishing Data
- There's lots of choice!
- Don't be overwhelmed, it means there's at least one method that will work well in your situation.
| Publication Method
| Advantages
| Disadvantages
|
| RDF/XML Document
| Oldest, best supported
| Confusingly like normal XML
|
| Turtle (N3) Document
| Simplest
| Not technically a standard yet
|
| HTML Document with RDFa
| Fits inside HTML attributes
| Can get very complicated
|
| JSON
| Normal JSON, but also RDF
| Promising, but still being developed
|
| GRDDL
| Use the XML you have/want
| Needs to download+run XSLT
|
| SPARQL
| Query Protocol
| Query Protocol
|
RDF/XML Example
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:db="http://dbpedia.org/resource/">
<rdf:Description rdf:about="http://dbpedia.org/resource/Massachusetts">
<db:Governor>
<rdf:Description rdf:about="http://dbpedia.org/resource/Deval_Patrick" />
</db:Governor>
<db:Nickname>Bay State</db:Nickname>
<db:Capital>
<rdf:Description rdf:about="http://dbpedia.org/resource/Boston">
<db:Nickname>Beantown</db:Nickname>
</rdf:Description>
</db:Capital>
</rdf:Description>
</rdf:RDF>
validator
Turtle Prefixes
First triple:
<http://dbpedia.org/resource/Massachusetts>
<http://dbpedia.org/resource/Governor>
<http://dbpedia.org/resource/Deval_Patrick> .
Abbreviate it:
@prefix db: <http://dbpedia.org/resource/>
db:Massachusetts db:Governor db:Deval_Patrick.
- Read the same by turtle parsers
Turtle Example
@prefix db: <http://dbpedia.org/resource/>
db:Massachusetts db:Governor db:Deval_Patrick;
db:Nickname "Bay State";
db:Capital db:Boston.
db:Boston db:Nickname "Beantown".
RDFa Example
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML+RDFa 1.0//EN"
"http://www.w3.org/MarkUp/DTD/xhtml-rdfa-1.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:db="http://dbpedia.org/resource/"
version="XHTML+RDFa 1.0">
<head>
<title>About Massachusetts</title>
</head>
<body>
<div about="http://dbpedia.org/resource/Massachusetts">The
Massachusetts governor is
<span rel="db:Governor">
<span about="http://dbpedia.org/resource/Deval_Patrick">Deval
Patrick
</span>,
</span>
the nickname is "<span property="db:Nickname">Bay State</span>",
and the capital
<span rel="db:Capital">
<span about="http://dbpedia.org/resource/Boston">
has the nickname "<span property="db:Nickname">Beantown</span>".
</span>
</span>
</div>
</body>
</html>
distiller community site
One Possible RDF-JSON Example
{ "__iri": "db:Massachusetts",
"db:Nickname": "Bay State",
"db:Governor": { "__iri": "db:Deval_Patrick" },
"db:Capital": { "__iri": "db:Boston",
"db:Nickname": "Beantown"
},
"__prefixes": { "db:": "http://dbpedia.org/resource/" }
}
One Possible GRDDL Example
<MyDataSet xmlns="http://example.org/my-data-xml-namespace">
<State>
<name>Massachusetts</name>
<governor>Deval_Patrick</governor>
<nickname>Bay State</nickname>
<capital>
<name>Boston</name>
<nickname>Beantown</nickname>
</capital>
</State>
</MyDataSet>
All the hard work is done by an XSLT program downloaded via the XML namespace URL. (Not implemented for this demo, sorry.)
spec demo service
SPARQL
- A query language, somewhat like SQL
prefix db: <http://dbpedia.org/resource/>
prefix dbo: <http://dbpedia.org/ontology/>
SELECT ?dnym WHERE { db:Massachusetts dbo:demonym ?dnym }
prefix db: <http://dbpedia.org/resource/>
prefix dbo: <http://dbpedia.org/ontology/>
SELECT ?cap WHERE { db:Massachusetts dbo:capital ?cap }
dbpedia sparql service and
sparql tutorial
Content Negotiation
How do you manage all these options?
- Information Resources can have multiple Representations
- When you GET, you can say which type you want (HTML or XML say)
- HTTP Server returns an appropriate representation
Try:
curl -L --header "Accept: application/rdf+xml" http://vocab.deri.ie/dcat
curl -L --header "Accept: text/turtle" http://vocab.deri.ie/dcat
curl -L --header "Accept: text/html" http://vocab.deri.ie/dcat
Challenges
- You will run into some issues:
- Long term critics of the Semantic Web
- Data consumers who don't want RDF
- Suppliers trying to sell a different technology
- Gov people who think you're trying to spoil years on work on their XML Schemas
- Listen and re-assure - Linked Data can help all these people too!
