Contents
Executive Summary
This page summarizes the discussions and outcomes from the Workshop on Improving Access to Financial Data on the Web. The Workshop brought together people from a wide range of backgrounds, and gave a glimpse of the broad potential for applying Semantic technologies for improved access to financial data. XBRL is leading the way for financial reporting, but we are still at a very early stage when it comes to what could realized for analysing and combining different sources of information.
One of the main outcomes was a realization of the need for encouraging the use of best practices for naming schemes for financial entities. This could potentially be followed up with an Incubator Group. The workshop break-out sessions also called for work on enabling improved search for financial data through richer metadata, and for outreach on success stories for financial transparency, and the development of clear and compelling value proposition for all audiences, as the means to resource further work.
To facilitate a continued conversation in the community, W3C may set up an Interest Group. We would expect such a group to require approximately one full time equivalent of additional staff effort, which could be funded through a fellowship or through additional membership contributions or grants. Organizations that are interested in helping to enable this work should contact Dave Raggett <dsr@w3.org>. Additionally, interested W3C member companies can charter Incubator Groups to explore specific technical work items, this could be an appropriate route for following up on the entity naming issue.
The Semantic Web and XBRL, a brief overview
The Semantic Web makes it straight forword to work with data sources in many formats and data models. The key is to develop filters to map such data into binary relations that are independent of the syntax. By building bridges between communities, and sharing best practices for data models, shared vocabularies can be developed, that facilitate mashing data from different sources, and encourage the development of innovative applications.
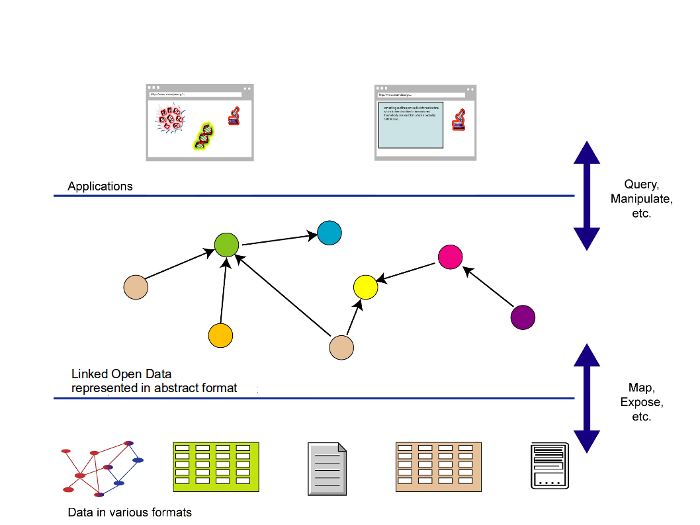
XBRL has largely developed independently of the knowledge representation community centered around the Semantic Web. Bringing the two communities together would be of value to both and could point the way to the future for work on modelling financial and business data as part of a broader ecosystem.
A starting point would be to build upon existing work on the relationship between XBRL and OWL, and defining a standard for financial data that is syntax independent. This would bring opportunities for using richer semantics in XBRL taxonomies, and for introducing more compact and easier to process formats for filing reports. These could be phased in gradually since they would share the same underlying abstract data model. There are also opportunities for further work on versioning and integrity constraints, e.g. taking some of the ideas in XBRL Formula across into OWL.
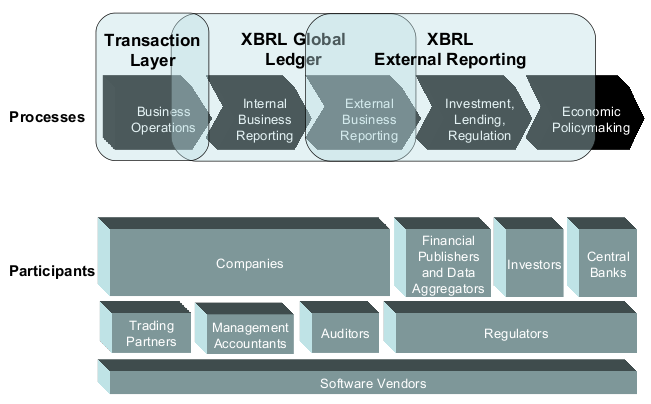
XBRL uses a highly normalized data model. This offers great flexibility, but necessitates lots of queries to create the data structures needed by applications for rendering charts and tables etc. There is an opportunity for defining intermediate data models that will make applications easier to develop and more efficient to run. Such intermediate models could alleviate the complexities involved in combining data from different taxonomies.
Workshop Overview
For more details and links to presentations, please view the Workshop program and minutes.
We expected around 100 participants including about 8 remote, although on the day there were a few no shows. The participants came from US government agencies (SEC, FDIC, FRB, EPA, FSTC), business and academia. There were lots of thank you's e.g. from David Blaszkowsky, Director, Office of Interactive Disclosure, Securities and Exchange Commission who was very encouraging as well as offering to host a follow on meeting if we want to hold one.
The workshop proved a good opportunity for people from different government agencies to exchange ideas, and we found a shared interest in sorting out the naming issue for financial entities, something that is essential for combining data from different sources. I was part of a break out session where people agreed that it would be valuable to work on best practices for harmonizing names across agencies. Each agency has slightly different requirements, and a centralized naming solution is unlikely to be practical. There will be more details in the workshop report.
As a joint W3C/XBRL International event, we were able to swap ideas on the XBRL and the Semantic Web. Dave Raggett gave a short introduction to the Semantic Web using some slides adapted from one of Ivan's tutorials. The idea that the Semantic Web is an abstraction layer over existing data sources went down well, along with being able to express richer semantics than is currently possible in XBRL. Walter Hamsher (SEC) suggested that class-based inheritance of semantics would be of value.
XBRL is just one part of the universe of financial information, and Hatsu Kim (Thomson Reuters) noted that analysts can't rely on annual and quarterly filings alone and need to combine this with information on markets and exchange rates etc. when it comes to valuing companies. Daniel Bennett (eCitizen Foundation) talked to us about LegislativeXML and inserting XBRL into the appropriations supply chain as well as emphasising the power of URLs for combining data. Linda Powell (Federal Reserve) talked about the need for harmonization on metadata standards and referred to work on MDRM. This followed a talk on NIEM, which is a joint DOJ / DHS / S&L program, started in 2005 to promote the standardization of XML information exchanges.
Cate Long (Multiple Markets) gave us a presentation of how credit rating agencies this area works, and the opportunities for using XBRL as part of the rating process. A bipartisan bill H.R. 2392 aims to make XBRL the standard for disclosure to the U.S. government. It has been approved in committee and reported to the full House of Representatives for consideration.
David Watson reported work for the Singapore stock exchange on a web-based tool for financial analysis and benchmarking of companies that submit XBRL corporate financial statement filings to the Accounting Corporate Regulatory Authority of Singapore (ACRA). The goal of Open Analytics is to distill large volumes of standardised financial data into simple, visual business intelligence. This showed the kind of end-user experience that can only be dreamed about elsewhere in the world. Singapore has a tightly controlled reporting model that simplifies comparisons, but nonetheless, it provides a glimpse of the future.
Herm Fischer (Ubimatrix) presented some work on combining data across XBRL filings from Japanese companies. Loading these into memory as XML proved to be very memory intensive, and he suggested the use of relational databases as a more efficient solution. He says he will now take a look at the Semantic Web as a more embracing approach for analysing and combining data.
Brand Niemann (EPA, SAIC) gave a short talk where he highlighted the federal segment architecture methodology. He had a nice slide positioning different approaches to data representation. This provided workshop attendees with some of the reasons on why to pick Semantic Web technologies instead of inventing yet another markup language.
We had a few talks on academic work on XBRL. Edward Curry (DERI) talked about the challenges for combining different sources of financial data. Sean O'Riain (DERI) described the potential benefits for apply the Social Web to financial data (blogs, wikis and tweets) and the connection to linked data. Matheus Silqueira talked to us about multidimensional queries on financial data, and the relationship with OLAP and the LMDQL query language, Christian Leibold presented work in the MUSING project on combining XBRL and Semantic Web data. Finally Roberto García (Universitat de Lleida) talked to us about lessons from the Rhizomik Initiative, and some of the ontological challenges that have emerged for financial data.
Where next?
The big question is how to move forward. Some of the topics raised include:
-
Practices for naming financial data as a basis for cmobining different sources of information. Patrick Slattery provided a summary of the entity naming break out session
-
Best practices for harmonising vocabularies, and the need for a continuing dialog across government agencies.
-
There is a need for further technical work, e.g. on extending OWL to support richer integrity constraints (e.g. to mirror the capabilities of XBRL Formula), and intermediate data models aimed at simplifying the task of Web application developers (reflecting the difficulties of working with fully normalized data).
-
Perhaps W3C could play a role in defining best practices in specific areas and at an international level, depending on obtaining the resources needed to support such work. Tim McNamar (E-Certus) has some suggestions that could be followed up.
Goverment agencies are typically large and relatively slow moving, and progress is dependent on continued involvement. The Web is potentially very disruptive when it comes to realizing goals for transparency, but it will be important to identify pieces where W3C can establish an effective role. This can't proceed very far without finding a way to fund W3C Team work in this area.
-
The work on transparency relating to financial reporting is related to a limited extent to the W3C work on eGovernment, and we need a better way to talk about this. Financial and business information over the Web is sufficiently different in nature to the current focus of the W3C eGov work that simply merging the two areas may be counter productive. W3C has an opportunity to facilitate realization of the potential of financial data on the Web, and it could become a key application area for the Semantic Web, but the challenge will be how to fund a W3C initiative on financial data, and to draw in new members to work on it. The first step is this workshop report. We also plan to conduct an online poll to determine the level of support for a possible Interest Group, including suggestions for how to fund the associated W3C staffing costs.
In conclusion, There is broad interest in realizing the potential for increased financial transparency of government and business organizations. This would be facilitated through bringing together people from a range of communities. A number of topics were identified during the course of the Workshop, including entity naming, harmonization of vocabularies, outreach, and technical work on XBRL and the Semantic Web. A significant challenge will be to obtain the necessary funding for coordinating such work.
Acknowledgements
The Workshop was a joint W3C and XBRL International affair, and our host Richard Campbell provided a truly excellent facility at the FDIC training center. He also arranged to video the proceedings which helped with reviewing the minutes as taken in IRC, but we lacked the funds to arrange for a transcription. Karen Myers did a stirling job taking minutes on IRC. We would also like to express our thanks to Ralph Swick for helping to sort out problems with the teleconference bridge for remote participants.