A global distributed Social Web requires that each person be able to
control their identity, that this identity be linkable across sites -
placing each person in a Web of relationships - and that it be possible to
authenticate globally with such identities.
This specification outlines a simple universal identification mechanism
that is distributed, openly extensible, improves privacy, security and
control over how each person can identify themselves in order to allow fine
grained access control to their information on the Web.
It does this by applying the best practices of Web Architecture whilst
building on well established widely deployed protocols and standards
including HTML, URIs, HTTP, and RDF Semantics.
How to Read this Document
There are a number of concepts that are covered in this document that the
reader may want to be aware of before continuing. General knowledge of RDF
[RDF-PRIMER] is necessary to understand how to implement this specification.
WebID uses a number of specific technologies like Turtle [turtle] and RDFa
[RDFA-CORE].
A general Introduction is provided for all that
would like to understand why this specification is necessary to simplify usage
of the Web.
The terms used throughout this specification are listed in the section
titled Terminology.
This is an internal draft document and may not even end up being
officially published. It may also be updated, replaced or obsoleted by
other documents at any time. It is inappropriate to cite this document
as other than work in progress.
A WebID is an HTTP URI which refers to an Agent (Person, Organization, Group, Device, etc.). A description of the WebID can be found in the Profile Document, a type of web page that any Social Network user is familiar with.
A WebID Profile Document is a Web resource that MUST be available as text/turtle [turtle], but MAY be available in other RDF serialization formats (e.g. [RDFA-CORE]) if requested through content negotiation.
WebIDs can be used to build a Web of trust using vocabularies such as FOAF [FOAF] by allowing people to link together their profiles in a public or protected manner.
Such a web of trust can then be used by a Service to make authorization decisions, by allowing access to resource depending on the properties of an agent, such that he/she is known by some relevant people, works at a given company, is a family member, is part of some group, etc..
1.1 Outline
This specification is divided in the following sections.
This section gives a high level overview of WebID, and presents the organization of the specification and the conventions used throughout the document.
Section 2 provides a short description for the most commonly used terms in this document.
Section 5 deals with the publishing of a WebID Profile.
Section 6 describes how a request for a WebID Profile should be handled.
2. Terminology
This section provides definitions for several important terms used in this document.
Requesting Agent
The Requesting Agent initiates a request to a Service listening on a specific port using a given protocol on a given Server.
Server
A Server is a machine contactable at a domain name or IP address that hosts a number of globally accessible Services.
Service
A Service is an agent listening for requests at a given IP address on a given Server.
WebID
A WebID is a URI with an HTTP or HTTPS scheme which denotes an Agent (Person, Organization, Group, Device, etc.). For WebIDs with fragment identifiers (e.g. #me), the URI without the fragment denotes the Profile Document. For WebIDs without fragment identifiers an HTTP request on the WebID MUST return a 303 with a Location header URI referring to the Profile Document.
WebID Profile or Profile Document
A WebID Profile is an RDF document which uniquely describes the Agent denoted by the WebID in relation to that WebID. The server MUST provide a text/turtle [turtle] representation of the requested profile. This document MAY be available in other RDF serialization formats, such as RDFa [RDFA-CORE], or [RDF-SYNTAX-GRAMMAR] if so requested through content negotiation.
2.1 Namespaces
Examples assume the following namespace prefix bindings unless otherwise stated:
Prefix
IRI
foaf
http://xmlns.com/foaf/0.1/
3. The WebID HTTP URI
When using URIs, it is possible to identify both a thing (which may exist outside of the Web) and a Web document describing the thing. For example, the person Bob is described on his homepage. Alice may not like the look of the homepage, but may want to link to the person Bob. Therefore, two URIs are needed, one for Alice and one for the homepage or a RDF document describing Alice.
The WebID HTTP URI must be one that dereferences to a document the user controls.
For example, if a user Bob controls https://bob.example.org/profile,
then his WebID can be https://bob.example.org/profile#me.
Note
There are two solutions that meet our requirements for identifying real-world objects: 303 redirects and hash URIs. Which one to use depends on the situation, both have advantages and disadvantages, as presented in [COOLURIS]. All examples in this specification will use such hash URIs.
4. Overview
This section is non-normative.
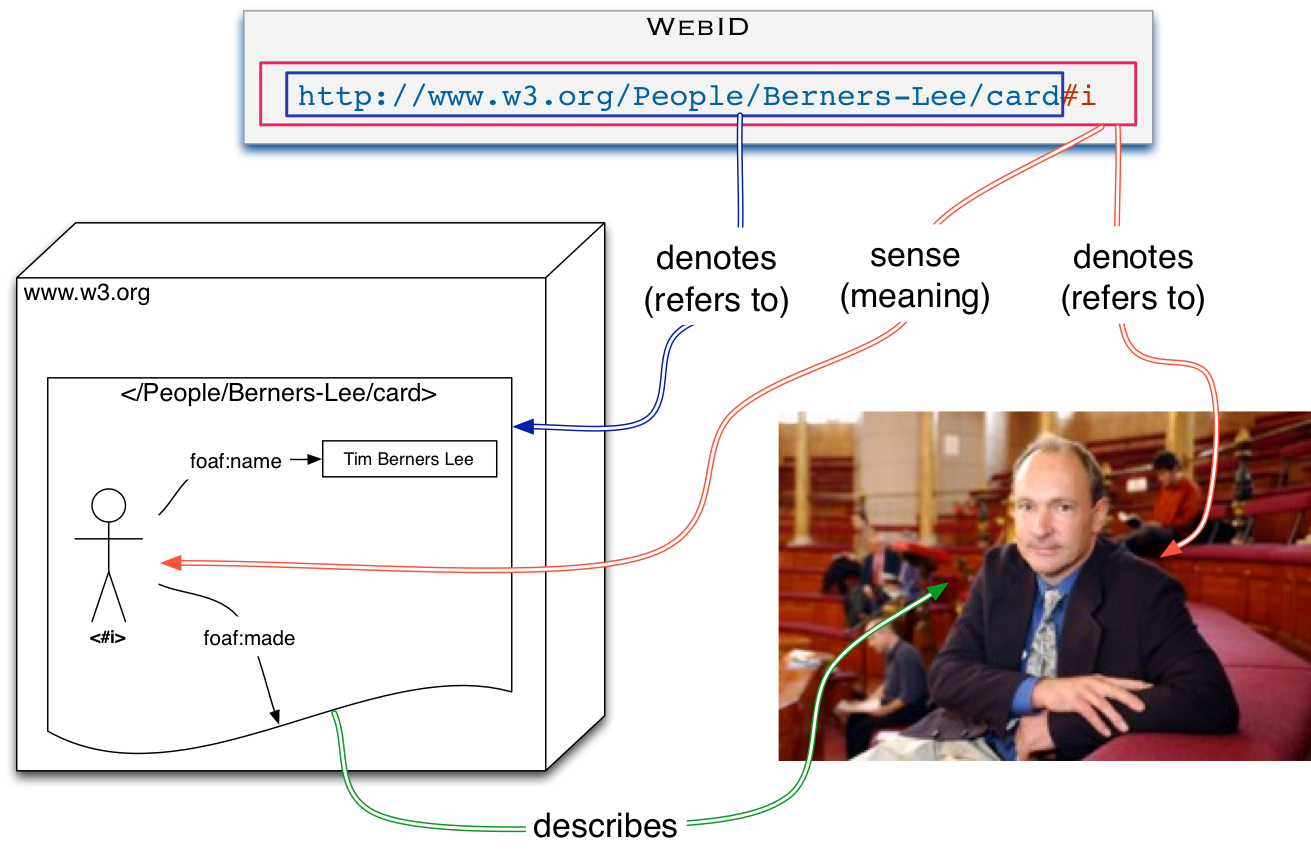
The relation between the WebID URI and the WebID Profile document is illustrated below.
The WebID URI - http://www.w3.org/People/Berners-Lee/card#i" (containing the #i hash tag) - is an identifier that denotes (refers to) a person or more generally an agent. In the above illustration, the referent is Tim Berners Lee, a real physical person who has a history, who invented the World Wide Web, and who directs the World Web Consortium.
The WebID Profile URI - "http://www.w3.org/People/Berners-Lee/card" (without the #i hash tag) - denotes the document describing the person (or more generally any agent) who is the referent of the WebID URI.
The WebID Profile gives the sense of the WebID: its RDF Graph contains a Concise Bounded Description of the WebID such that this subgraph forms a definite description of the referent of the WebID, that is, a description that distinguishes the referent of that WebID from all other things in the world.
The document can, for example, contain relations to another document depicting the WebID referent, or it can relate the WebID to principals used by different authentication protocols.
(More information on WebID and other authentication protocols can be found on the WebID Identity Interoperability page).
5. Publishing the WebID Profile Document
WebID requires that servers MUST at least be able to provide Turtle representation of profile documents, but other serialization formats of the graph are allowed, provided that agents are able to parse that serialization and obtain the graph automatically.
HTTP Content Negotiation can be employed to aid in publication and discovery of multiple distinct serializations of the same graph at the same URL, as explained in [COOLURIS]
It is particularly useful to have one of the representations be in HTML
even if it is not marked up in RDFa as this allows people using a
web browser to understand what the information at that URI represents.
5.1 WebID Profile Vocabulary
WebID RDF graphs are built using vocabularies identified by URIs, that can be placed in subject, predicate or object position of the relations constituting the graph.
The definition of each URI should be found at the namespace of the URI, by dereferencing it.
5.1.1 Personal Information
This section is non-normative.
Personal details are the most common requirement when registering an
account with a website. Some of these pieces of information include an e-mail
address, a name and perhaps an avatar image, expressed using the FOAF [FOAF] vocabulary. This section includes
properties that SHOULD be used when conveying key pieces of personal information
but are NOT REQUIRED to be present in a WebID Profile:
foaf:name
The name of the individual or agent.
foaf:knows
The WebID URI of a known person.
foaf:img
An image representing a person.
5.2 Publishing a WebID Profile using Turtle
This section is non-normative.
A widely used format for writing RDF graphs by hand is the Turtle [turtle] notation.
It is easy to learn, and very handy for communicating over e-mail and on mailing lists.
The syntax is very similar to the SPARQL query language.
Turtle profile documents should be served with the text/turtle content type.
Take for example the WebID https://bob.example.org/profile#me, for which the WebID Profile document contains the following Turtle representation:
5.3 Publishing a WebID Profile using the RDFa HTML notation
This section is non-normative.
RDFa in HTML [RDFA-CORE] is a way to markup HTML with relations that have a well defined semantics and
mapping to an RDF graph. There are many ways of writing out the above graph using RDFa in
HTML. Here is just one example of what a WebID profile could look like.
<divvocab="http://xmlns.com/foaf/0.1/"about="#me"typeof="foaf:Person"><p>My name is <spanproperty="name">Bob</span> and this is how I look like: <imgproperty="img"src="https://bob.example.org/picture.jpg"title="Bob"alt="Bob" /></p><h2>My Good Friends</h2><ul><liproperty="knows"href="https://example.edu/p/Alice#MSc">Alice</li></ul></div>
If a WebID provider would prefer not to mark up his WebID profile in HTML+RDFa, but
just provide a human readable format for users in plain HTML and have the RDF graph appear
in a machine readable format such as Turtle, then he SHOULD provide a link of type alternate
to a machine readable format [RFC5988]. This can be placed in the HTTP header or in the
html as shown here:
A WebID Profile is a public document that may contain public as well personal information about the agent identified by the WebID.
As some agents may not want to reveal a lot of information about themselves, RDF and Linked Data principles allows them to choose how much information they wish to make publicly available.
This can be achieved by separating parts of the profile information into separate documents, each protected by access control policies.
On the other hand, some agents may want to publish more information about themselves, but only to a select group of trusted agents.
In the following example, Bob is limiting access to his list of friends, by placing all foaf:knows relations into a separate document.
A WebID identifies an agent via a description found in the associated WebID Profile document.
An agent that wishes to know what a WebID refers to, must rely on the description found in the WebID Profile.
An attack on the relation between the WebID and the WebID Profile can thus be used
to subvert the meaning of the WebID, and to make agents following links within the WebID Profile come to different conclusions from those intended by profile owners.
The standard way of overcoming such attacks is to rely on the cryptographic security protocols within the HTTPS [HTTP-TLS] stack.
HTTPS servers are identified by a certificate either signed by a well known Certification Authority or whose public key is listed in the DNSSEC as specified by the DANE protocol [RFC6698], or both.
This makes it much more difficult to set up a fake server by DNS Poisoning attacks.
Resources served over HTTPS are furthermore signed and encrypted removing all the simple man-in-the-middle attacks.
Applying the above security measure does not remove the burden from server administrators to take the appropriate security measures, in order to avoid compromising their servers.
Similarly, clients that fetch documents on the web also need to make sure their work environment has not been compromised.
As security is constantly being challenged by new attacks, to which new responses are found, a collection of security considerations will be made available on the WebID Wiki.
6. Processing the WebID Profile
The Requesting Agent needs to fetch the document, if it does not have a valid one in cache.
The Agent requesting the WebID document MUST be able to parse documents in Turtle [turtle], but MAY also be able to parse documents in RDF/XML [RDF-SYNTAX-GRAMMAR] and RDFa [RDFA-CORE].
The result of this processing should be a graph of RDF relations that is queryable, as explained in the next section.
Note
It is recommended that the Requesting Agent sets a qvalue for text/turtle in the HTTP Accept-Header with a higher priority than in the case of application/xhtml+xml or text/html, as sites may produce HTML without RDFa markup but with a link to graph encoded in a pure RDF format such as Turtle.
For an agent that can parse Turtle, rdf/xml and RDFa, the following would be a reasonable Accept header: Accept: text/turtle,application/rdf+xml,application/xhtml+xml;q=0.8,text/html;q=0.7
If the Requesting Agent wishes to have the most up-to-date Profile document for an HTTP URL, it can use the HTTP cache control headers to get the latest versions.
7. Acknowledgments
This section is non-normative.
The following people have been instrumental in providing thoughts, feedback,
reviews, criticism and input in the creation of this specification:
Stéphane Corlosquet, Erich Bremer, Kingsley Idehen, Ted Thibodeau, Alexandre Bertails, Thomas Bergwinkl.