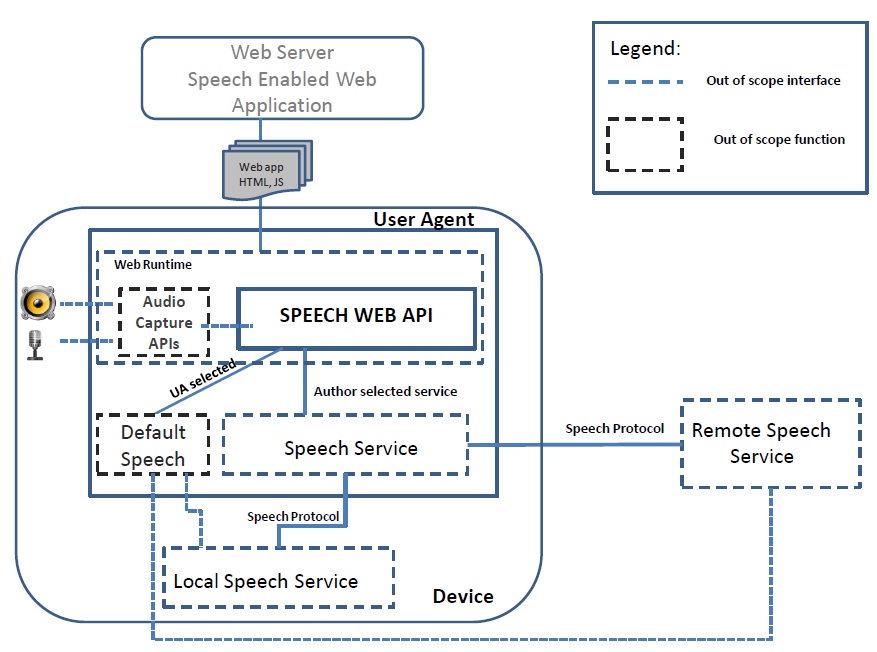
The following sections cover proposed solutions that this Incubator Group recommends. The proposed solutions
represent the consensus of the group, except where clearly indicated that an impasse was reached.
7.1 Speech Web API proposal
This proposed API represents the web API for
doing speech in HTML. This proposal is the HTML bindings and JS functions that sits on top of the protocol proposal
[section 7.2 HTML Speech Protocol Proposal]. This includes:
- A declarative <reco> tag which can optionally bind to recoable elements.
- A JS API that allows programmatic control and parameterization of recognition.
- The ability to do recognition either as one-shot turns or as continuous dictation.
- The ability of the web application author to use the recognition service of their choice.
- A declarative <tts> tag which can be used to output synthesis.
- A JS API that allows programmatic control of the synthesis.
- The ability of the web application author to choose the synthesis service of their choice.
The section on Design Decisions [section 6. Solution Design Agreements and Alternatives] covers the design decisions the group
agreed to that helped direct this API proposal.
The sections on Use Cases [section 4. Use Cases]
and Requirements [section 5. Requirements] cover
the motivation behind this proposal.
This API is designed to be used in conjunction with other APIs and elements on the web platform, including
APIs to capture input and APIs to do bidirectional communications with a server (WebSockets [WEBSOCKETS-API]).
7.1.1 Introduction
Web applications should have the ability to use speech to interact with users. That speech could be for output
through synthesized speech, or could be for input through the user speaking to fill form items, the user
speaking to control page navigation or many other collected use cases. A web application author should be able
to add speech to a web application using methods familiar to web developers and should not require extensive
specialized speech expertise. The web application should build on existing W3C web standards and support
a wide variety of use cases. The web application author should have the flexibility to control the recognition
service the web application uses, but should not have the obligation of needing to support a service.
This proposal defines the basic representations for how to use grammars, parameters, and recognition results
and how to process them. The interfaces and API defined in this proposal can be used with other
interfaces and APIs exposed to the web platform.
Note that privacy and security concerns exist around allowing web applications to do speech recognition.
User agents should make sure that end users are aware that speech recognition is occurring, and that the
end users have given informed consent for this to occur. The exact mechanism of consent is user agent
specific, but the privacy and security concerns have shaped many aspects of the proposal.
7.1.2 Reco Element
The reco element is the way to do speech recognition using markup bindings.
The reco element is legal where ever phrasing content is expected, and can
contain any phrasing content, except with no descendant recoable elements unless
it is the element's reco control, and no descendant reco elements.
The reco represents a speech input in a user interface. The speech input can be associated with a specific form control,
known as the reco element's reco control, either using for attribute, or by putting the form control inside the
reco element itself.
Except where otherwise specified by the following rules, a reco element has no reco control.
Some elements are catagorized as recoable elements. These are elements that can be
associated with a reco element:
The reco element's exact default presentation and behavior, in particular what its activation behavior might be is
unspecified and user agent specific. When the reco element is bound to a recoable element if no grammar attribute
is specified, then by default the default builtin uri is used.
The activation behavior of a reco element for events targeted at interactive content descendants of a reco element, and
any descendants of those interactive content descendants, must be to do nothing. When a reco element with a reco control
is activated and gets a reco result, the default action of the recognition event must be to use the
value of the top n-best interpretation of the current result event. The exact binding depends on the
recoable element in question and is covered in the binding results section.
Not all implementers see value in linking the recognition
behavior to markup, versus an all scripting
API. Some user agents like the possibility of good defaults based on
the associations. Some user agents like the idea of different consent bars based on the user clicking a markup
button, rather then just relying on scripting. User agents are cautioned to remember click-jacking and
should not automatically assume that when a reco element is activated it means the user meant to start
recognition in all situations.
7.1.2.1 Reco Attributes
- form
The form attribute is used to explicitly associate the reco element with its form owner.
The form IDL attribute is part of the element's forms API.
- htmlFor
The htmlFor IDL attribute must reflect the for content attribute.
The for attribute may be specified to indicate a form control with which a speech input is to be associated.
If the attribute is specified, the attribute's value must be the ID of a recoable element in the same Document as the reco element.
If the attribute is specified and there is an element in the Document whose ID is equal to the value of the for attribute, and
the first such element is a recoable element, then that element is the reco element's reco control.
If the for attribute is not specified, but the reco element has a recoable element descendant, then the first such
descendant in tree order is the reco element's reco control.
- control
The control attribute returns the form control that is associated with this element. The control
IDL attribute must return the reco element's reco control, if any, or null if there isn't one.
control . recos returns a NodeList of all the reco elements that the form control is associated with.
Recoable elements have a NodeList object associated with them that represents the list of reco elements,
in tree order, whose reco control is the element in question. The reco IDL attribute of recoable elements, on getting, must return that NodeList object.
- request
The request attribute represents the SpeechReco associated with this reco element. By default the
User Agent sets up the speech service specified by serviceURI and the default speech reco object associated with this reco. The author
may set this attribute to associate a markup reco element with an author created speech reco object. In this way the
author has control over the reco involved. When the reco request object is set then the object's speech parameters take priority
over the corresponding parameters on the reco attributes.
- grammar
The uri of a grammar associated with this reco. If unset, this defaults to the default builtin uri.
Note that to use multiple grammars or different weights the user must use the scripted SpeechReco API.
The other attributes are all defined identically to how they appear in the SpeechInputResult section.
7.1.2.2 Reco Constructors
Two constructors are provided for creating HTMLRecoElement objects (in addition to the factory methods from DOM Core
such as createElement()): Reco() and Reco(for). When invoked as constructors, these must return
a new HTMLRecoElement object (a new reco element). If the for argument is present, the object created must have its for
content attribute set to the provided value. The element's document must be the active document of the browsing context
of the Window object on which the interface object of the invoked constructor is found.
7.1.2.3 Builtin Default Grammars
When the user agent needs to create a default grammar from a recoable element
it builds a uri using the builtin scheme. The format of the uri is of the form:
builtin:<tag-name>?<tag-attributes> where the tag-name is just the name of the
recoable element, and the tag-attributes are the content attributes in the form name=value&name=value.
Since this a uri, both name and value must be properly uri escaped. Note the ? character may be omitted
when there are no tag-attributes.
For example:
- A simple textarea like <textarea /> would produce:
builtin:textarea
- A simple number like <input type="number" max="3" /> would produce:
builtin:input?type=number&max=3
- A zip code like <input type="text" pattern="[0-9]{5}" /> would produce:
builtin:input?type=text&pattern=%5B0-9%5D%7B5%7D
Speech services may define other builtin grammars as well. It is recommended that speech services
allow a builtin:dictation to represents a "say anything" grammar and
builtin:websearch to represent a speech web search and
builtin:default to represent whatever default grammar, if any, the recognition service
defines.
builtin uri for grammars can be used even when the reco element is not bound to any particular element
and may also be used by the SpeechReco object and as a rule reference in an SRGS grammar.
In addition to the content attribute other parameters may be specified. It is recommended that
speech services support a filter parameter that can be set to the value noOffensiveWords to represent
a desire to not recognize offensive words. Speech services may define other extension parameters.
Note the exact grammar that is generated from any builtin uri is specific to the recognition service
and the content attributes are best thought of as hints for the service.
7.1.2.4 Default Binding of Results
When a reco element is bound to a recoable element and does not have an onresult attribute set
then the default binding is used. The default binding can also be used if the SpeechInputResult's
outputElement attribute is set. In both cases the exact binding depends on the recoable
element in question. In general, the binding will use the value associated with the interpretation
of the top n-best element.
When the recoable element is a
button then if
the button is not disabled,
then the result of a speech recognition is to activate the button.
When the recoable element is a
input element
then the exact binding depends on the control type. For basic text fields (input elements with
a type attribute of text, search, tel, url, email, password, and number) the value of the result
should be assigned to the input (inserted at the cursor and replacing any selected text). For
button controls (submit, image, reset, button) the act of recognition just activates the input.
For type checkbox, the input should be set to a checkedness of true. For type radiobutton,
the input should be set to a checkedness of true, and all other inputs in the radio button
group must be set to a checkedness of false. For date and time types (datetime, date,
month, week, time, datetime-local) then the value should be assigned unless the value
represents an non-empty string that is not valid for that type as described
here. For type
of color then the value should be assigned unless the value does not represent a
valid lowercase simple color.
For type of range the assignment is only allowed if it is a valid floating point number,
and before being assigned, it must undergo the value sanitization algorithm as described
here.
When the recoable element is a
keygen element
then the element should regenerate the key.
When the recoable element is a
select element
then the recognition result will be used to select any options that are named the same as the
interpretations value (that is any that are returned by namedItem(value)).
When the recoable element is a
textarea element
then the recognized value is inserted in to the textarea where the text cursor is if it is in the textarea.
If text in the textarea is selected then the new value replaces the highlighted text.
If the text cursor is not in the textarea then the value is appended to the end of the textarea.
More work is needed on making sure that this binding behavior is well specified and matches
the input validation described in HTML 5. The general desire from the group is for binding to
do a reasonable default behavior, for the additional attributes (type, pattern, max, etc.) to
be available to possibly improve recognition, but for as much as possible those additional
attributes to merely be hints - other then where the HTML 5 specification forbids user agents
to assign certain elements certain values. For example, an input with type of Date can't take arbitrary
non-empty strings, they can only take
non-empty string that are valid date string,
at an recognized string
of "brown" wouldn't work). In addition, some would like the ability to both check selectors as well
as uncheck them, but the exact semantics of how that work (does a default binding toggle the selected item?
check it unless a magic phrase like "uncheck" is recognized before it? something else?) is not well understood,
so no further effort to explain that is made here in this section.
7.1.3 TTS Element
The TTS element is the way to do speech synthesis using markup bindings.
The TTS element is legal where embedded content is expected. If the TTS element has a src attribute,
then its content model is zero or more track elements, then transparent, but with no media element
descendants. If the element does not have a src attribute, then one or more source elements, then
zero or more track elements, then transparent, but with no media element descendants.
IDL
[NamedConstructor=TTS(),
NamedConstructor=TTS(in DOMString src)]
interface HTMLTTSElement : HTMLMediaElement {
attribute DOMString serviceURI;
attribute DOMString text;
attribute DOMString lastMark;
};
A TTS element represents a synthesized audio stream. A TTS element is a media element whose media data is ostensibly synthesized audio data.
When a TTS element is potentially playing, it must have its TTS data played synchronized
with the current playback position, at the element's effective media volume.
When a TTS element is not potentially playing, TTS must not play for the element.
Content may be provided inside the TTS element. User agents should not show this content to the user;
it is intended for older Web browsers which do not support TTS.
In particular, this content is not intended to address accessibility concerns. To make TTS content
accessible to those with physical or cognitive disabilities, authors are expected to provide
alternative media streams and/or to embed accessibility aids (such as transcriptions) into
their media streams.
Implementations should support at least UTF-8 encoded text/plain and application/ssml+xml (both SSML 1.0 and 1.1 should be supported).
User Agents must pass the xml:lang values to synthesizers and synthesizers must use the passed in xml:lang to determine the language
of text/plain.
The existing timeupdate event is dispatched to report progress
through the synthesized speech. If the synthesis is of type application/ssml+xml, timeupdate events should be fired for each mark element that is encountered.
7.1.3.1 Attributes
The src, preload, autoplay, mediagroup, loop, muted, and controls attributes are the attributes common to all media elements.
- serviceURI
The serviceURI attribute specifies the speech service to use in the constructed default request. If the serviceURI
is unset then the User Agent must use the User Agent default service. Note that the serviceURI is a generic URI and can thus point to local services either through use of a URN with meaning to the User Agent or by specifying a URL that the User Agent recognizes as a local service. Additionally, the User Agent default can of course be local or remote and can incorporate end user choices via interfaces provided by the User Agent such as browser configuration parameters.
- text
The text is an optional attribute to specify plain text to be synthesized. The text attribute, on setting must
construct a data: URI that encodes
the text to be played and assign that to the src property of the TTS element. If there are no encoding issues the URI for any given
string would be data:text/plain,string, but if there are problematic characters the UserAgent should use base64 encoding.
- lastMark
The new lastMark attribute must, on getting, return the name of the last SSML mark element that was encountered during playback.
If no mark has been encountered yet, the attribute must return null.
There has been some interest in allowing lastMark to be set to a value as a way to control where playback would start/resume. This feature is simple in principle but may have subtle implementation consequences. It is not a feature that has been seriously studied in other similar languages such as SSML. Thus, the group decided not to consider this feature at this time.
7.1.3.2 Constructors
Two constructors are provided for creating HTMLTTSElement objects (in addition to the factory methods
from DOM Core such as createElement()): TTS() and TTS(src). When invoked as constructors, these must return a
new HTMLTTSElement object (a new tts element). The element must have its preload attribute set to the
literal value "auto". If the src argument is present, the object created must have its src content attribute
set to the provided value, and the user agent must invoke the object's resource selection algorithm before returning.
The element's document must be the active document of the browsing context of the Window object on which the
interface object of the invoked constructor is found.
7.1.4 The Speech Reco Interface
The speech reco interface is the scripted web API for controlling a given recognition.
7.1.4.1 Speech Reco Attributes
- grammars attribute
- The grammars attribute stores the collection of SpeechGrammar objects which represent the grammars
that are active for this recognition.
- maxNBest attribute
- This attribute will set the maximum number of recognition results that should be returned.
The default value is 1.
- lang attribute
- This attribute will set the language of the recognition for the request, using
a valid BCP 47 language tag.
If unset it remains unset for getting in script, but will default to use the
lang of its
recoable element, if tied to an html element, and the lang of the html document root element and
associated hierachy are used when the
SpeechReco is not associated with a recoable element. This default value is
computed and used when the input request opens a connection to the recognition service.
- saveForRereco attribute
- This attribute instructs the speech recognition service if the utterance should be saved for
later use in a rerecognition (true means save). The default value is false.
- endpointDetection attribute
- This attribute instructs the user agent if it should do a low latency endpoint detection
(true means do endpointing). The user agent default should be true.
- finalizeBeforeEnd attribute
- This attribute instructs the recognition service if it should send final results when it gets them, even
if the user is not done talking (true means yes it should send the results early).
The user agent default should be true.
- interimResults attribute
- If interimResults is set to false, that instructs the recognition service that it must not send any interim
results. A value of true represents a hint to the service that the web application would like interim
results. The service may not follow the hint, as the ability to send interim results depends on a combination of the recognition service, the grammars in use,
and the utterance being recognized. The user agent default value should be false.
- confidenceThreshold attribute
- This attribute represents the degree of confidence the recognition system needs in order to
return a recognition match instead of a nomatch. The confidence threshold is a
value between 0.0 (least confidence needed) and 1.0 (most confidence) with 0.5 as the default.
- sensitivity attribute
- This attribute represents the sensitivity to quiet input. The sensitivity is a
value between 0.0 (least sensitive) and 1.0 (most sensitivity) with 0.5 as the default.
- speedVsAccuracy attribute
- This attribute instructs the recognition service on the desired trade off between low latency
and high speed. The speedVsAccuracy is a
value between 0.0 (least accurate) and 1.0 (most accurate) with 0.5 as the default.
- completeTimeout attribute
- This attribute represents the amount of silence, in milliseconds, needed to match a
grammar when a hypothesis is at a complete match of the grammar (that is
the hypothesis matches a grammar, and no larger input can possibly match a grammar).
- incompleteTimeout attribute
- This attribute represents the amount of silence, in milliseconds, needed to match a grammar
when a hypothesis is not at a complete match of the grammar (that is
the hypothesis does not match a grammar, or it does match a grammar but so could a larger input).
- maxSpeechTimeout attribute
- This attribute represents how much speech, in milliseconds, the recognition service should
process before an end of speech or an error occurs.
- inputWaveformURI attribute
- This attribute, if set, instructs the speech recognition service to recognize from this URI instead
of from the input MediaStream attribute.
- parameters attribute
- This attribute holds an array of arbitrary extension parameters. These parameters could set user specific
information (such as profile, gender, or age information) or could be used to set recognition parameters specific
to the recognition service in use.
- serviceURI attribute
- The serviceURI attribute specifies the location of the speech service the web application wishes to connect
to. If this attribute is unset at the time of the open call, then the user agent must use the user agent
default speech service.
- input attribute
- The input attribute is the MediaStream that we are recognizing against. If input is not set, the
speech reco object uses the default UA provided capture (which may be nothing), in which case
the value of input will be null. In cases where the MediaStream is set but the SpeechReco
hasn't yet called start the User Agent should not buffer the audio, the semantics are that the
web application wants to start listening to the Media Stream at the moment it calls Start, and not
earlier than that.
- authorizationState attribute
- The authorizationState variable tracks if the web application is authorized to do speech recognition.
The UA should start in UNKNOWN if the user agent can not determine if the web application
is able to be authorized. The state variable may change values in response to policies of the user agent and possibly
security interactions with the end user. If the web application is authorized then the user agent must set this
variable to AUTHORIZED. If the web application is not authorized then the user agent
must set this variable to NOT_AUTHORIZED. Any time this state variable changes in value
the user agent must raise a authorizationchange event.
- continuous attribute
- When the continuous attribute is set to false the service must only return a single simple
recognition response as a result of starting recognition. This represents a request/response
single turn pattern of interaction. When the continuous attribute is set to true the service
must return a set of recognitions representing more a dictation of multiple recognitions in
response to a single starting of recognition. The user agent default value should be false.
- outputElement attribute
- This attribute, if set, causes default
binding of recognition matches to the recoable element it is set to. This is the same
default binding that occurs when a <reco> element is bound as described at
Default Binding of Results section.
7.1.4.2 Speech Reco Methods
- The setCustomParameter method
- This method appends an arbitrary recognition service parameter to the parameters array. The name of the parameter is given by
the name parameter and the value by the value parameter.
This arbitrary parameter mechanism allows services that want to have extensions or to set user specific information (such
as profile, gender, or age information) to accomplish the task.
- The sendInfo method
- The method allows one to pass arbitrary information to the recognition service, even while recognition is on going.
Each set info call gets transmitted immediately to the recognition service. The type attribute specifies the content-type
of the info message and the value attribute specifies the payload of the info method.
- The open method
- When the open method is called the user agent must connect to the speech service. All of the attributes and parameters
of the SpeechInputResult (I.e., languages, grammars, service uri, etc.) must be set before this method is called, because
they will be fixed with the values they have at the time open is called, at least until open is called again. Note that
the user agent may need to have a permissions dialog at this point to ensure that the end user has given informed consent
for the web application to listen to the user and recognize. Errors may be raised at this point for a variety of
reasons including: not authorized to do recognition, failure to connect to the service, the service can not handle
the languages or grammars needed for this turn, etc. When the service is successfully completed the open with no
errors the user agent must raise an open event.
- The start method
- When the start method is called it represents the moment in time the web application wishes to begin recognition.
When the speech input is streaming live through the input media stream, then this start call represents the moment in
time that the service must begin to listen and try to match the grammars associated with this request. If the
SpeechReco has not yet called open before the start call is made, a call to open is made by the start call
(complete with the open event being raised). Once the system is successfully listening to the recognition the
user agent must raise a start event.
- The stop method
- The stop method represents an instruction to the recognition service to stop listening to more audio, and to try
and return a result using just the audio that it has received to date. A typical use of the stop method might be
for a web application where the end user is doing the end pointing, similar to a walkie-talkie. The end user might
press and hold the space bar to talk to the system and on the space down press the start call would have occurred and
when the space bar is released the stop method is called to ensure that the system is no longer listening to the user.
Once the stop method is called the speech service must not collect additional audio and must not continue to listen to
the user. The speech service must attempt to return a recognition result (or a nomatch) based on the audio that
it has collected to date.
- The abort method
- The abort method is a request to immediately stop listening and stop recognizing and do not return any information
but that the system is done. When the stop method is called the speech service must stop recognizing. The user agent
must raise a end event once the speech service is no longer connected.
- The interpret method
- The interpret method provides a mechanism to request recognition using text, rather than audio.
The text parameter is the string of text to recognize against. When
bypassing audio recognition a number of the normal parameters may be ignored and the sound and audio
events should not be generated. Other normal SpeechReco events should be generated.
7.1.4.3 Speech Reco Events
The DOM Level 2 Event Model is used for speech recognition events. The
methods in the EventTarget interface should be used for registering
event listeners. The SpeechReco interface also contains
convenience attributes for registering a single event handler for each
event type.
For all these events, the timeStamp attribute defined in the DOM Level
2 Event interface must be set to the best possible estimate of when
the real-world event which the event object represents occurred.
This timestamp
must be represented in the User Agent's view of time, even for events where
the timestamps in question could be raised on a different machine like
a remote recognition service (I.e., in a speechend event with a remote
speech endpointer).
Unless specified below, the ordering of the different events is
undefined. For example, some implementations may fire audioend before
speechstart or speechend if the audio detector is client-side and the
speech detector is server-side.
- audiostart event
- Fired when the user agent has started to capture audio.
- soundstart event
- Some sound, possibly speech, has been detected. This must be fired
with low latency, e.g. by using a client-side energy detector.
- speechstart event
- The speech that will be used for speech recognition has started.
- speechend event
- The speech that will be used for speech recognition has ended.
speechstart must always have been fire before speechend.
- soundend event
- Some sound is no longer detected. This must be fired with low latency,
e.g. by using a client-side energy detector. soundstart must always
have been fired before soundend.
- audioend event
- Fired when the user agent has finished capturing audio. audiostart
must always have been fired before audioend.
- result event
- Fired when the speech recognizer returns a result. See
here for more information.
- nomatch event
- Fired when the speech recognizer returns a final result with no recognition
hypothesis that meet or exceed the confidence threshold. The result field
in the event may contain speech recognition results that are below the confidence
threshold or may be null.
- resultdeleted event
- Fired when the recognizer needs to delete one of the previously returned
interim results in a continuous recognition. In the protocol, this would be
represented by an empty recognition complete. A simplified example of this might be
the recognizer gives an interim result for "hot" as the zeroth index of the
continuous result and then gives an interim result of "dog" as the first index.
Later the recognize wants to give a final result that is just one word "hotdog".
In order to do that it needs to change the zeroth index to "hotdog" and delete
the first index. When the first element is deleted the response is the
raising of a resultdeleted event. The resultIndex of this event will be the
element that was deleted and the resultHistory will have the updated value.
- error event
- Fired when a speech recognition error occurs. The error attribute must be
set to a SpeechInputError object.
- authorizationchange event
- Fired whenever the state variable tracking if the web application is authorized
to listen to the user and do speech recognition changes its value.
- open event
- Fired whenever the SpeechReco has successfully connected to the speech service
and the various parameters of the request can be satisfied with the service.
- start event
- Fired when the recognition service has begun to listen to the audio with the intention
of recognizing.
- end event
- Fired when the service has disconnected. The event must always be generated
when the session ends no matter the reason for the end.
7.1.4.4 Speech Input Error
The speech input error object has two attributes code and message.
- code
- The code is a numeric error code for whatever has gone wrong. The values are:
- OTHER (numeric code 0)
- This is the catch all error code.
- NO_SPEECH (numeric code 1)
- No speech was detected.
- ABORTED (numeric code 2)
- Speech input was aborted somehow, maybe by some UA-specific behavior such as
UI that lets the user cancel speech input.
- AUDIO_CAPTURE (numeric code 3)
- Audio capture failed.
- NETWORK (numeric code 4)
- Some network communication that was required to complete the
recognition failed.
- NOT_ALLOWED (numeric code 5)
- The user agent is not allowing any speech input to occur for
reasons of security, privacy or user preference.
- SERVICE_NOT_ALLOWED (numeric code 6)
- The user agent is not allowing the web application requested speech service, but would allow some speech service,
to be used either because the user agent doesn't support the selected one or because of reasons of security, privacy
or user preference.
- BAD_GRAMMAR (numeric code 7)
- There was an error in the speech recognition grammar.
- LANGUAGE_NOT_SUPPORTED (numeric code 8)
- The language was not supported.
- message
- The message content is implementation specific. This attribute is
primarily intended for debugging and developers should not use it directly in their application user interface.
7.1.4.5 Speech Input Alternative
The SpeechInputAlternative represents a simple view of the response that gets used in a n-best list.
To see a more full view of how these simple view are derived from the raw emma see the
Mapping EMMA to Speech Input Alternatives section.
- transcript
- The transcript string represents the raw words that the user spoke.
- confidence
- The confidence represents a numeric estimate between 0 and 1 of how confident the recognition
system is that the recognition is correct. A higher number means the system is more confident.
- interpretation
- The interpretation represents the semantic meaning from what the user said. This might
be determined, for instance, through the SISR specification of semantics in a grammar.
7.1.4.6 Speech Input Result
The SpeechInputResult object represents a single one-shot recognition match, either as one small part of a continuous
recognition or as the complete return result of a non-continuous recognition.
- EMMAXML
- The EMMAXML is a Document that contains the complete EMMA [EMMA] document the recognition service returned from the
recognition. The Document has all the normal XML DOM processing to inspect the content.
- EMMAText
- The EMMAText is a text representation of the EMMAXML.
- length
- The long attribute represents how many n-best alternatives are represented in the item array. The user agent
must not return more SpeechInputAlternatives than the value of the maxNBest attribute on the recognition request.
- item
-
- The item getter returns a SpeechInputAlternative from the index into an array of n-best values.
The user agent must ensure that there are not more elements in the array then the maxNBest attribute was set.
The user agent must ensure that the length attribute is set to the number of elements in the array.
The user agent must ensure that the n-best list is sorted in non-increasing confidence order (each element must
be less than or equal to the confidence of the preceding elements).
- final
- The final boolean must be set to true if this is the final time the speech service will return this
particular index value. If the value is false, then this represents an interim result that could still
be changed.
7.1.4.7 Speech Input Result List
The SpeechInputResultList object holds a sequence of recognition results representing the complete return result of a continuous recognition. For a non-continuous recognition it will hold only a single value.
- length
- The length attribute indicates how many results are represented in the item array.
- item
-
- The item getter returns a SpeechInputResult from the index into an array of result values.
The user agent must ensure that the length attribute is set to the number of elements in the array.
7.1.4.10 Speech Grammar Interface
The SpeechGrammar object represents a container for a grammar. This structure has the
following attributes:
- src attribute
- The required src attribute is the URI for the grammar. Note some services may support builtin
grammars that can be specified using a builtin URI scheme.
- weight attribute
- The optional weight attribute controls the weight that the speech recognition service should use with
this grammar. By default, a grammar has a weight of 1. Larger weight values positively weight
the grammar while smaller weight values make the grammar weighted less strongly.
7.1.4.11 Speech Grammar List Interface
The SpeechGrammarList object represents a collection of SpeechGrammar objects. This structure has the
following attributes:
- length
- The length attribute represents how many grammars are currently in the array.
- item
-
- The item getter returns a SpeechGrammar from the index into an array of grammars.
The user agent must ensure that the length attribute is set to the number of elements in the array.
The user agent must ensure that the index order from smallest to largest matches the order in which grammars were added to the array.
- The addFromElement method
- This method allows one to create a builtin grammar uri from a recoable element
as outlined in the builtin uri description. This
grammar is then appended to the grammars array parameter. The element in question is provided by the
inputElement attribute. The optional weight attribute sets the corresponding attribute value in the created
SpeechGrammar object.
- The addFromURI method
- This method appends a grammar to the grammars array parameter based on URI. The URI for the grammar is specified by the
src parameter, which represents the URI for the grammar. Note, some services
may support builtin grammars that can be specified by URI. If the
weight parameter is present it represents this grammar's weight
relative to the other grammar. If the weight parameter is not present, the default value of 1.0 is
used.
- The addFromString method
- This method appends a grammar to the grammars array parameter based on text. The content of the grammar
is specified by the
string parameter, which represents the content for the grammar. This content
should be encoded into a data: URI when the SpeechGrammar object is created.
If the
weight parameter is present it represents this grammar's weight
relative to the other grammar. If the weight parameter is not present, the default value of 1.0 is
used.
7.1.4.12 Speech Parameter Interface
The SpeechParameter object represents the container for arbitrary name/value parameters. This extensible
mechanism allows developers to take advantage of extensions that recognition services may allow.
- name attribute
- The required name attribute is the name of the custom parameter.
- value attribute
- The required value attribute is the value of the custom parameter.
7.1.4.13 Speech Parameter List Interface
The SpeechParameterList object represents a collection of SpeechParameter objects. This structure has the
following attributes:
- length
- The length attribute represents how many parameters are currently in the array.
- item
-
- The item getter returns a SpeechParameter from the index into an array of parameters.
The user agent must ensure that the length attribute is set to the number of elements in the array.
7.1.5 Mapping EMMA to Speech Input Alternatives
An EMMA document represents the users input and may contain a number of possible hypothesis of what the user
said. Each individual hypothesis is represented by a emma:interpretation. In the case where there is only one
hypothesis than the emma:interpretation may be a direct child of the emma:emma root element. In cases where there
are one or more hypothesis, the emma:interpretation tags may be included as children of a emma:one-of tag which
is a child of the root emma:emma element.
Each emma:interpretation in turn contains information about the transcript, confidence, and interpretation for
that one hypothesis. The interpretation information
is given in EMMA by the instance data representing the semantics of what the user
meant. In the case that the instance data is in an emma:literal then the interpretation variable of
the Speech Input Alternative must be set to the contents of the emma:literal tag. In the case where the
instance data is given by an XML structure then the interpretation must be set to the XML document created when you
wrap the instance data in a root result element. This Document has all the normal XML DOM processing to inspect
the content.
Each emma:interpretation also contains the transcript of what the user said, represented by the emma:tokens attribute.
The transcript variable of the Speech Input Alternative must be set to the contents of this attribute.
Each emma:interpreation also contains the confidence the recognizer has in this hypothesis, represented by
the emma:confidence attribute. The confidence variable of the Speech Input Alternative must be set to
this value.
Note that while these mapping cover the common usecases, the full EMMA document is available for inspection
when needed through the XML and text properties on the SpeechInputResult object.
7.1.5.1 EMMA Mapping Example
Here is an example that shows how this mapping works.
In the example below the different recognition results are mapped to a result set.
EMMA Document
<emma:emma version="1.0"
xmlns:emma="http://www.w3.org/2003/04/emma"
xmlns="http://www.example.com/example">
<emma:one-of id="r1" emma:medium="acoustic" emma:mode="voice">
<emma:interpretation id="int1" emma:confidence="0.8" emma:tokens="Boston Flight 311">
<emma:literal>BOS</emma:literal>
</emma:interpretation>
<emma:interpretation id="int2" emma:confidence="0.5" emma:tokens="Austin to Denver Flight on 3 11">
<origin>AUS</origin>
<destination>DEN</destination>
<date>03112003</date>
</emma:interpretation>
</emma:one-of>
</emma:emma>
As a result of getting the above EMMA a SpeechInputResultEvent will be generated. The complete
EMMA and n-best list will be accessible from the result property in the form of the SpeechInputResult
object. But the top level mapping is as follows.
SpeechInputResultEvent top level mappings
{transcript:"Boston Flight 311",
confidence:0.8,
interpretation:"BOS",
...}
The SpeechInputResult object that is generated has two SpeechInputAlternative in the item collection.
The one at the 0th index (the best result) has the same transcript, confidence, and interpretation as the above top level
mappings. The SpeechInputAlternative at the 1st index (the 2nd best result) is associated with the second emma:interpretation
from the EMMA and thus has a transcript of "Austin to Denver Flight on 3 11" with a confidence of 0.5
and the interpretation is the XML Document, complete with all the normal DOM parsing, that is represented
below.
2nd best SpeechInputAlternative Interpretation XML Document
<result>
<origin>AUS</origin>
<destination>DEN</destination>
<date>03112003</date>
</result>
7.1.6 Extension Events
Some speech services may want to raise custom extension interim events either while doing speech recognition
or while synthesizing audio. An example of this kind of event might be viseme events that encode lip and mouth
positions while speech is being synthesized that can help with the creation of avatars and animation. These
extension events must begin with "speech-x", so the hypothetical viseme event might be something like
"speech-x-viseme".
7.1.7 Examples
In the example below the various speech APIs are used to do basic speech web search.
Speech Web Search Markup Only
<!DOCTYPE html>
<html>
<head>
<title>Example Speech Web Search Markup Only</title>
</head>
<body>
<form id="f" action="/search" method="GET">
<label for="q">Search</label>
<reco for="q"/>
<input id="q" name="q" type="text"/>
<input type="submit" value="Example Search"/>
</form>
</body>
</html>
Speech Web Search JS API With Functional Binding
<!DOCTYPE html>
<html>
<head>
<title>Example Speech Web Search JS API and Bindings</title>
</head>
<body>
<script type="text/javascript">
function speechClick() {
var inputField = document.getElementById('q');
var sr = new SpeechReco();
sr.addGrammarFrom(inputField);
sr.outputToElement(inputField);
// Set what ever other parameters you want on the sr
sr.serviceURI = "https://example.org/recoService";
sr.speedVsAccuracy = 0.75;
sr.start();
}
</script>
<form id="f" action="/search" method="GET">
<label for="q">Search</label>
<input id="q" name="q" type="text" />
<button name="mic" onclick="speechClick()">
<img src="http://www.openclipart.org/image/15px/svg_to_png/audio-input-microphone.png" alt="microphone picture" />
</button>
<br />
<input type="submit" value="Example Search" />
</form>
</body>
</html>
Speech Web Search JS API Only
<!DOCTYPE html>
<html>
<head>
<title>Example Speech Web Search</title>
</head>
<body>
<script type="text/javascript">
function speechClick() {
var sr = new SpeechReco();
// Build grammars from scratch
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri("http://example.org/topChoices.srgs", 1.5);
sr.grammars.addFromUri("builtin:input?type=text", 0.5);
sr.grammars.addFromUri("builtin:websearch", 1.1);
// This 3rd grammar is an inline version of the http://www.example.com/places.grxml grammar from Appendix J.2 of the SRGS document (without the comments and xml and doctype)
sr.grammars.addFromUri("data:application/srgs+xml;base64,PGdyYW1tYXIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDEvMDYvZ3JhbW1hciINCiAgICAgICAgIHhtbG5zOnhzaT0iaHR0cDovL3d3dy53My5vcmcvMjAwMS9YTUxTY2" +
"hlbWEtaW5zdGFuY2UiIA0KICAgICAgICAgeHNpOnNjaGVtYUxvY2F0aW9uPSJodHRwOi8vd3d3LnczLm9yZy8yMDAxLzA2L2dyYW1tYXIgDQogICAgICAgICAgICAgICAgICAgICAgICAgICAgIGh0dHA6Ly93d3cudzMub" +
"3JnL1RSL3NwZWVjaC1ncmFtbWFyL2dyYW1tYXIueHNkIg0KICAgICAgICAgeG1sOmxhbmc9ImVuIiB2ZXJzaW9uPSIxLjAiIHJvb3Q9ImNpdHlfc3RhdGUiIG1vZGU9InZvaWNlIj4NCg0KICAgPHJ1bGUgaWQ9ImNpdHki" +
"IHNjb3BlPSJwdWJsaWMiPg0KICAgICA8b25lLW9mPg0KICAgICAgIDxpdGVtPkJvc3RvbjwvaXRlbT4NCiAgICAgICA8aXRlbT5QaGlsYWRlbHBoaWE8L2l0ZW0+DQogICAgICAgPGl0ZW0+RmFyZ288L2l0ZW0+DQogICA" +
"gIDwvb25lLW9mPg0KICAgPC9ydWxlPg0KDQogICA8cnVsZSBpZD0ic3RhdGUiIHNjb3BlPSJwdWJsaWMiPg0KICAgICA8b25lLW9mPg0KICAgICAgIDxpdGVtPkZsb3JpZGE8L2l0ZW0+DQogICAgICAgPGl0ZW0+Tm9ydG" +
"ggRGFrb3RhPC9pdGVtPg0KICAgICAgIDxpdGVtPk5ldyBZb3JrPC9pdGVtPg0KICAgICA8L29uZS1vZj4NCiAgIDwvcnVsZT4NCg0KICAgPHJ1bGUgaWQ9ImNpdHlfc3RhdGUiIHNjb3BlPSJwdWJsaWMiPg0KICAgICA8c" +
"nVsZXJlZiB1cmk9IiNjaXR5Ii8+IDxydWxlcmVmIHVyaT0iI3N0YXRlIi8+DQogICA8L3J1bGU+DQo8L2dyYW1tYXI+", 0.01);
// Say what happens on a match
sr.onresult = function(event) {
var q = document.getElementById('q');
q.value = event.result.item(0).interpretation;
var f = document.getElementById('f');
f.submit();
};
// Also do something on a nomatch
sr.onnomatch() = function(event) {
// even though it is a no match we might have a result
alert("no match: " + event.result.item(0).interpretation);
}
// Set what ever other parameters you want on the sr
sr.serviceURI = "https://example.org/recoService";
sr.speedVsAccuracy = 0.75;
// Start will call open for us, if we wanted to open the sr on page start we could have to do initial permission checking
sr.start();
}
</script>
<form id="f" action="/search" method="GET">
<label for="q">Search</label>
<input id="q" name="q" type="text" />
<button name="mic" onclick="speechClick()">
<img src="http://www.openclipart.org/image/15px/svg_to_png/audio-input-microphone.png" alt="microphone picture" />
</button>
<br />
<input type="submit" value="Example Search" />
</form>
</body>
</html>
Web search by voice, with auto-submit
<script type="text/javascript">
function startSpeech(event) {
var sr = new SpeechReco();
sr.onresult = handleSpeechInput;
sr.start();
}
function handleSpeechInput(event) {
var q = document.getElementById("q");
q.value = event.result.item(0).interpretation;
q.form.submit();
}
</script>
<form action="http://www.example.com/search">
<input type="search" id="q" name="q">
<input type="button" value="Speak" onclick="startSpeech">
</form>
Behavior
- User clicks button.
- Audio is captured and the speech recognizer runs.
- If some speech was recognized, the first hypothesis is put in the text field and the form is submitted.
- Search results are loaded.
Web search by voice, with "Did you say..."
This example uses the second best result. The search results page will display a link with the text "Did you say $second_best?".
<script type="text/javascript">
function startSpeech(event) {
var sr = new SpeechReco();
sr.onresult = handleSpeechInput;
sr.start();
}
function handleSpeechInput(event) {
var q = document.getElementById("q");
q.value = event.result.item(0).interpretation;
if (event.result.length > 1) {
var second = event.result[1].interpretation;
document.getElementById("second_best").value = second;
}
q.form.submit();
}
</script>
<form action="http://www.example.com/search">
<input type="search" id="q" name="q">
<input type="button" value="Speak" onclick="startSpeech">
<input type="hidden" name="second_best" id="second_best">
</form>
Speech translator
<script type="text/javascript" src="http://www.example.com/jsapi"></script>
<script type="text/javascript">
library.load("language", "1"); // Load the translator JS library.
// These will most likely be set in a UI.
var fromLang = "en";
var toLang = "es";
function startSpeech(event) {
var sr = new SpeechReco();
sr.onresult = handleSpeechInput;
sr.start();
}
function handleSpeechInput(event) {
var text = event.result.item(0).interpretation;
var callback = function(translationResult) {
if (translationResult.translation)
speak(translationResult.translation, toLang);
};
library.language.translate(text, fromLang, toLang, callback);
}
function speak(output, lang) {
var tts = new TTS();
// NOTE: these attributes don't seem to be in the proposal
tts.text = output;
tts.lang = lang;
tts.play();
}
</script>
<form>
<input type="button" value="Speak" onclick="startSpeech">
</form>
Behavior
- User clicks button and speaks in English.
- System recognizes the text in English.
- A web service translates the text from English to Spanish.
- System synthesizes and speaks the translated text in Spanish.
Speech shell
HTML:
<script type="text/javascript">
function startSpeech(event) {
var sr = new SpeechReco();
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri("commands.grxml");
sr.onresult = handleSpeechInput;
sr.start();
}
function handleSpeechInput(event) {
var command = event.result.item(0).interpretation;
if (command.action == "call_contact") {
var number = getContactNumber(command.contact);
callNumber(number);
} else if (command.action == "call_number") {
callNumber(command.number);
} else if (command.action == "calculate") {
say(evaluate(command.expression));
} else if {command.action == "search") {
search(command.query);
}
}
function callNumber(number) {
window.location = "tel:" + number;
}
function search(query) {
// Start web search for query.
}
function getContactNumber(contact) {
// Get the phone number of the contact.
}
function say(text) {
// Speak text.
}
</script>
<form>
<input type="button" value="Speak" onclick="startSpeech">
</form>
English SRGS XML Grammar (commands.grxml):
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE grammar PUBLIC "-//W3C//DTD GRAMMAR 1.0//EN"
"http://www.w3.org/TR/speech-grammar/grammar.dtd">
<grammar xmlns="http://www.w3.org/2001/06/grammar" xml:lang="en"
version="1.0" mode="voice" root="command"
tag-format="semantics/1.0">
<rule id="command" scope="public">
<example> call Bob </example>
<example> calculate 4 plus 3 </example>
<example> search for pictures of the Golden Gate bridge </example>
<one-of>
<item>
call <ruleref uri="contacts.grxml">
<tag>out.action="call_contact"; out.contact=rules.latest()</tag>
</item>
<item>
call <ruleref uri="phonenumber.grxml">
<tag>out.action="call_number"; out.number=rules.latest()</tag>
</item>
<item>
calculate <ruleref uri="#expression">
<tag>out.action="calculate"; out.expression=rules.latest()</tag>
</item>
<item>
search for <ruleref uri="http://grammar.example.com/search-ngram-model.xml">
<tag>out.action="search"; out.query=rules.latest()</tag>
</item>
</one-of>
</rule>
</grammar>
Turn-by-turn navigation
HTML:
<script type="text/javascript">
var directions;
function startSpeech(event) {
var sr = new SpeechReco();
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri("grammar-nav-en.grxml");
sr.onresult = handleSpeechInput;
sr.start();
}
function handleSpeechInput(event) {
var command = event.result.item(0).interpretation;
getDirections(command.destination, handleDirections);
speakNextInstruction();
}
function getDirections(query, handleDirections) {
// Get location, then get directions from server, pass to handleDirections
}
function handleDirections(newDirections) {
directions = newDirections;
// List for location changes and call speakNextInstruction()
// when appropriate
}
function speakNextInstruction() {
var instruction = directions.pop();
var tts = new TTS();
tts.text = instruction;
tts.play();
}
</script>
<form>
<input type="button" value="Speak" onclick="startSpeech">
</form>
English SRGS XML Grammar (grammar-nav-en.grxml):
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE grammar PUBLIC "-//W3C//DTD GRAMMAR 1.0//EN"
"http://www.w3.org/TR/speech-grammar/grammar.dtd">
<grammar xmlns="http://www.w3.org/2001/06/grammar" xml:lang="en"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2001/06/grammar
http://www.w3.org/TR/speech-grammar/grammar.xsd"
version="1.0" mode="voice" root="nav_cmd"
tag-format="semantics/1.0">
<rule id="nav_cmd" scope="public">
<example> navigate to 76 Buckingham Palace Road, London </example>
<example> go to Phantom of the Opera </example>
<item>
<ruleref uri="#nav_action" />
<ruleref uri="builtin:search" />
<tag>out.action="navigate_to"; out.destination=rules.latest();</tag>
</item>
</rule>
<rule id="nav_action">
<one-of>
<item>navigate to</item>
<item>go to</item>
</one-of>
</rule>
</grammar>
The examples below show a few ways to handle permissions using Speech API.
Hide possible graphical UI related to reco element if permission is denied
<!-- Anywhere in the page -->
<script>
/** When the document has been loaded, iterate through all the
* reco elements and remove the ones which have request.authorizationState
* NOT_AUTHORIZED. For the rest of the reco elements
* add authorizationchange event listener, which will remove the target of
* the event from DOM if its request.authorizationState changes to
*/ NOT_AUTHORIZED.
window.addEventListener("load",
function() {
var recos = document.getElementsByTagName("reco");
for (var i = recos.length - 1; i >= 0; --i) {
if (!removeNotAuthorizedReco(recos[i])) {
recos[i].addEventListener("authorizationchange",
function(evt) { removeNotAuthorizedReco(evt.target); });
}
}
});
function removeNotAuthorizedReco(reco) {
if (reco.request.authorizationState ==
SpeechReco.NOT_AUTHORIZED) {
reco.parentNode.removeChild(reco);
return true;
}
return false;
}
</script>
Ask permission as soon as the page has loaded and if permission is granted activate SpeechRequest object whenever user clicks the page
<!-- Anywhere in the page -->
<script>
var request; // Make sure the request object is kept alive.
window.addEventListener("load",
function () {
request = new SpeechRequest();
request.onresult =
function(evt) {
// Do something with the speech recognition result.
}
request.open(); // Trigger permission handling UI in the user agent.
document.addEventListener("click",
function() {
if (request.authorizationState ==
SpeechReco.AUTHORIZED) {
request.start();
}
});
});
</script>
Domain Specific Grammars Contingent on Earlier Inputs
A use case exists around collecting multiple domain specific inputs sequentially where the later inputs depend on the results of the earlier inputs. For instance, changing which cities are in a grammar of cities in response to the user saying in which state they are located.
This seems trivial, assuming there are a variety of suitable grammars to choose from.
<input id="txtState" type="text"/>
<button id="btnStateMic" type="button" onclick="stateMicClicked()">
<img src="microphone.png"/>
</button>
<br/>
<input id="txtCity" type="text"/>
<button id="btnCityMic" type="button" onclick="cityMicClicked()">
<img src="microphone.png"/>
</button>
<script type="text/javascript">
function stateMicClicked() {
var sr = new SpeechReco();
// add the grammar that contains all the states:
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri("states.grxml");
sr.onmatch = function (e) {
// assume the grammar returns a standard string for each state
// in which case we just need to get the interpretation
document.getElementById("txtState").value =
e.result.item(0).interpretation;
}
sr.start();
}
function cityMicClicked() {
var sr = new SpeechReco();
// The cities grammar depends on what state has been selected
// If state is blank, use major US cities
// otherwise use cities in that state
var state = document.getElementById("txtState").value;
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri(state ? "majorUScities.grxml" : "citiesin" + state + ".grxml");
sr.onresult = function(e) {
document.getElementById("txtState").value =
e.result.item(0).interpretation;
}
sr.start();
}
</script>
Rerecognition
Some sophisticated applications will re-use the same utterance in two or more recognitions turns in what appears to the user as one turn. For example, an application may ask "how may I help you?", to which the user responds "find me a round trip from New York to San Francisco on Monday morning, returning Friday afternoon". An initial recognition against a broad language model may be sufficient to understand that the user wants the "flight search" portion of the app. Rather than get the user to repeat themselves, the application will just re-use the existing utterance for the recognition on the flight search recognition.
<script type="text/javascript">
function listenAndClassifyThenReco() {
var sr = new SpeechReco();
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri("broadClassifier.grxml");
sr.onresult = function (e) {
if ("broadClassifier.grxml" == sr.grammars[0].uri) {
// Also, this switch is a little contrived. no reason why the re-reco grammar
// wouldn't just be returned in the interpretation
switch (getClassification(e.interpretation)) {
case "flightsearch":
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri("flightsearch.grxml");
break;
case "hotelbooking":
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri("hotelbooking.grxml");
break;
case "carrental":
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri("carrental.grxml");
break;
default:
throw ("cannot interpret:" + e.result.item(0).interpretation);
}
sr.inputWaveformUri = getUri(e); // This probably comes from the sessionId that comes back from the service
// re-initialize with new settings:
sr.open();
// start listening:
sr.start();
}
else if ("flightsearch.grxml" == sr.grammars[0].uri) {
processFlightSearch(e.result.item(0).interpretation);
}
else if ("hotelbooking.grxml" == sr.grammars[0].uri) {
processHotelBooking(e.result.item(0).interpretation);
}
else if ("carrental.grxml" == sr.grammars[0].uri) {
processCarRental(e.result.item(0).interpretation);
}
}
sr.saveForRereco = true;
sr.start();
}
</script>
Speech Enabled Email Client
The application reads out subjects and contents of email and also listens for commands, for instance, "archive", "reply: ok, let's meet at 2 pm", "forward to bob", "read message". Some commands may relate to VCR like controls of the message being read back, for instance, "pause", "skip forwards", "skip back", or "faster". Some of those controls may include controls related to parts of speech, such as, "repeat last sentence" or "next paragraph".
This is the other end of the spectrum. It's a huge app, if it works as described. But here's a simplistic version of some of the logic:
<script type="text/javascript">
var sr;
var tts;
// initialize the speech object when the page loads:
function initializeSpeech() {
sr = new SpeechReco();
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri("globalcommands.grxml");
sr.onresult = doSRResult;
sr.onerror = doSRError;
tts = new TTS();
}
function onMicClicked() {
// stop TTS if there is any...
if (tts.paused == false && tts.ended == false) {
tts.controller.pause();
}
sr.start();
}
function doSRError(e) {
// do something informative...
}
function doSRResult(e) {
// I don't want to write this line. How do I avoid it?
if (!e.result.final) {
return;
}
// Assume the interpretation is an object with a
// pile of properties that have been glommed together
// by the grammar
var semantics = e.result.item(0).interpretation;
switch (semantics.command) {
case "reply":
composeReply(currentMessage, semantics.message);
break;
case "compose":
composeNewMessage(semantics.subject, semantics.recipients, semantics.message);
break;
case "send":
currentComposition.Send();
break;
case "readout":
readout(currentMessage);
break;
default:
throw ("cannot interpret:" + semantics.command);
}
}
function readout(message) {
tts.src = "data:,message from " + message.sendername + ". Message content: " + message.body;
tts.play();
}
From the multimodal use case "The ability to mix and integrate input from multiple modalities such as by saying 'I want to go from here to there' while tapping two points on a touch screen map."
In the example below the various speech APIs are used to do a simple multimodal example where the user is presented with a series of buttons and may click one while they are speaking. The click event is sent to the speech service using the sendInfo method on the SpeechReco. The result coming back from the speech service is the integration of the voice command and gesture. The combined multimodal result is represented in the EMMA document along with the EMMA interpretations for the individual modalities.
Simple Multimodal Example JS API Only
<!DOCTYPE html>
<html>
<head>
<title>Simple Multimodal Example</title>
</head>
<body>
<script type="text/javascript">
// Only send gestures if sr is active, start() has been called
sr_started = false;
function speechClick() {
var sr = new SpeechReco();
// Indicate the reco service to be used
sr.serviceURI = "https://example.org/recoService/multimodal";
// Set any parameters
sr.speedVsAccuracy = 0.75;
sr.completeTimeout = 2000;
sr.incompleteTimeout = 3000;
// Specifying the grammar
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri("http://example.org/commands.srgs");
// Say what happens on a match
sr.onresult = function(event) {
sr_started=false;
var af = document.getElementById('asr_feedback');
af.value = event.result.item(0).transcript;
// code to pull out interpretation and execute;
interp = event.result.item(0).interpretation;
// ....
};
// Also do something on a nomatch
sr.onnomatch() = function(event) {
// even though it is a no match we might have a result
alert("no match: " + event.result.item(0).interpretation);
}
//
// Start will call open for us, if we wanted to open the
// sr on page start we could have to do initial permission checking
sr.start();
sr_started=true;
};
// What do if the user clicks a button during speech capture
// Uses sendInfo to add the click to the stream sent to the service
function sendClick(payload) {
if (sr_started) {
sr.sendInfo('text/xml',payload);
}
};
</script>
<div>
<input id="asr_feedback" name="asr_feedback" type="text"/>
<button name="mic" onclick="speechClick()">SPEAK</button>
<br/>
<br/>
<button name="item1" onclick="sendClick('<click>joe_bloggs</click'">Joe Bloggs</button>
<button name="item2" onclick="sendClick('<click>pam_brown</click>'">Pam Brown</button>
<button name="item3" onclick="sendClick('<click>peter_smith</click>'">Peter Smith</button>
</div>
</body>
</html>
SRGS Grammar (http://example.org/commands.srgs)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE grammar PUBLIC "-//W3C//DTD GRAMMAR 1.0//EN"
"http://www.w3.org/TR/speech-grammar/grammar.dtd">
<grammar version="1.0" mode="voice" root="top" tag-format="semantics/1.0">
<rule id="top" scope="public">
<one-of>
<item>call this person<tag>out._cmd="CALL";out._obj="DEICTIC";</tag></item>
<item>email this person<tag>out._cmd="CALL";out._obj="DEICTIC";</tag></item>
<item>call<tag>out._cmd="CALL";out._obj="DEICTIC";</tag></item>
<item>email<tag>out._cmd="CALL";out._obj="DEICTIC";</tag></item>
</one-of>
</rule>
</grammar>
EMMA Returned
<emma:emma version="1.1"
xmlns:emma="http://www.w3.org/2003/04/emma"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2003/04/emma
http://www.w3.org/TR/2009/REC-emma-20090210/emma.xsd"
xmlns="http://www.example.com/example">
<emma:grammar id="gram1" grammar-type="application/srgs-xml" ref="http://example.org/commands.srgs"/>
<emma:interpretation id="multimodal1"
emma:confidence="0.6"
emma:start="1087995961500"
emma:end="1087995962542"
emma:medium="acoustic tactile"
emma:mode="voice gui"
emma:function="dialog"
emma:verbal="true"
emma:lang="en-US"
emma:result-format="application/json">
<emma:derived-from resource="#voice1" composite="true"/>
<emma:derived-from resource="#gui1" composite="true"/>
<emma:literal><![CDATA[
{_cmd:"CALL",
_obj:"joe_bloggs"}]]></emma:literal>
</emma:interpretation>
<emma:derivation>
<emma:interpretation id="voice1"
emma:start="1087995961500"
emma:end="1087995962542"
emma:process="https://example.org/recoService/multimodal"
emma:grammar-ref="gram1"
emma:confidence="0.6"
emma:medium="acoustic"
emma:mode="voice"
emma:function="dialog"
emma:verbal="true"
emma:lang="en-US"
emma:tokens="call this person"
emma:result-format="application/json">
<emma:literal><![CDATA[
{_cmd:"CALL",
_obj:"DEICTIC"}]]></emma:literal>
</emma:interpretation>
<emma:interpretation id="gui1"
emma:medium="tactile"
emma:mode="gui"
emma:function="dialog"
emma:verbal="false">
<click>joe_bloggs</click>
</emma:interpretation>
</emma:derivation>
</emma:emma>
Speech XG Translating Example
This is a complete example that can be saved as an HTML document.
<html>
<head>
<title>Speech XG Translating Example</title>
</head>
<body>
<script type="text/javascript" src="https://example.org/translation.js"/>
<script type="text/javascript">
function speechClick() {
var sr = new SpeechReco();
sr.lang = document.getElementsById("inlang").value;
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri("builtin:dictation");
sr.serviceURI = "ws://example.org/reco";
// Haven't had a good link with the capture stuff in examples yet
sr.input = document.getElementById("speak").capture;
sr.onopen = function (event) { document.getElementById("p").value = 5; };
sr.onstart = function (event) { document.getElementById("p").value = 10; };
sr.onaudiostart = function (event) { document.getElementById("p").value = 20; };
sr.onsoundstart = function (event) { document.getElementById("p").value = 25; };
sr.onspeechstart = function (event) { document.getElementById("p").value = 30; };
sr.onspeechend = function (event) { document.getElementById("p").value = 60; };
sr.onsoundend = function (event) { document.getElementById("p").value = 65; };
sr.onaudioend = function (event) { document.getElementById("p").value = 70; };
sr.onresult = readResult();
sr.start();
}
function readResult(event) {
document.getElementsById("p").value = 100;
var tts = new TTS();
tts.serviceURI = "ws://example.org/speak";
tts.lang = document.getElementById("outlang").value;
tts.src = "data:text/plain;" + translate(event.result.item(0).interpretation, document.getElementById("inlang").value, tts.lang);
}
</script>
<h1>Speech XG Translating Example</h1>
<form id="foo">
<p>
<label for="inlang">Spoken Language to Translate: </label>
<select id="inlang" name="inlang">
<option value="en-US">American English</option>
<option value="en-GB">UK English</option>
<option value="fr-CA">French Canadian</option>
<option value="es-ES">Spanish</option>
</select>
</p>
<p>
<label>Translation Output Language:
<select id="outlang" name="outlang">
<option value="en-US">American English</option>
<option value="en-GB">UK English</option>
<option value="fr-CA" selected="true">French Canadian</option>
<option value="es-ES">Spanish</option>
</select>
</label>
</p>
<p>
<label for="speak">Click to speak: </label>
<input type="button" name="speak" value="speak" capture="microphone" onclick="speechClick()"/>
</p>
<p>
<progress id="p" max="100" value="0"/>
</p>
</form>
</body>
</html>
Multi-slot Filling Example
This is a complete example that can be saved as an HTML document.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<meta http-equiv="content-type"
content="text/html; charset=ISO-8859-1">
<title>Mult-slot filling</title>
<script type="text/javascript">
function speechClick() {
var sr = new SpeechReco();
//assume some multislot grammar coming from a URL
sr.grammars = new SpeechGrammarList();
sr.grammars.addFromUri("http://bookhotelspeechtools.example.com/bookhotelgrammar.xml");
sr.start();
}
// on a match, extract the appropriate EMMA slots and populate the form
sr.onresult = function(event) {
//get EMMA
var emma = event.EMMAXML;
//the author of this application will know the names of the slots
//there is a root node called "booking" in the application semantics
//there are four slots called "arrival", "departure", "adults" and "children"
var booking = emma.getElementsByTagName("booking").item(0);
//get arrival
var arrivalDate = getEMMAValue(booking, "arrival");
arrival.value = arrivalDate;
// get departure
var departureDate = getEMMAValue(booking, "departure");
departure.value = departureDate;
//get num adults (default is 1)
var numAdults = getEMMAValue(booking, "adults");
adults.value = numAdults;
//get num children (default is 0)
var numChildren = getEMMAValue(booking, "children");
children.value = numChildren;
//In a real application, before submitting, you would
//check that arrival and departure are filled, if either one is
//missing, prompt for user to fill. This could be done
//by initiating a directed dialog with slot-specific grammars.
The user should also be able to type values.
f.submit();
};
getEMMAValue(Node node String name){
return node.getElementsByTagName(name).item(0).nodeValue;
}
}
</script>
</head>
<body>
<h1>Multi-slot Filling Example</h1>
<h2>Welcome to the Speech Hotel!<br>
</h2>
<br>
<form id="f" action="/search" method="GET"> Please tell us your arrival
and departure dates, and how many adults and children will
be staying with us. <br>
For example "I want a room from December 1 to December 4 for two
adults" <br>
Click the microphone to start speaking. <button name="mic"
onclick="speechClick()"> <img
src="http://www.openclipart.org/image/15px/svg_to_png/audio-input-microphone.png"
alt="microphone picture"> </button> <br>
<input id="arrival" name="arrival" type="text"> <br>
<label for="arrival">Arrival Date</label> <br>
<br>
<input id="departure" name="departure" type="text"> <br>
<label for="departure">Departure Date</label> <br>
<br>
<input id="adults" name="adults" value="1" type="text"> <br>
<label for="adults">Adults</label> <br>
<br>
<input id="children" name="children" value="0" type="text"> <br>
<label for="children">Children (under age 12)</label> <br>
<br>
<input value="Check Availability" type="submit"></form>
</body>
</html>
These are inline grammar examples
Referencing external grammar
We could write the grammar to a file and then reference the grammar via URI.
Then we end up with file overhead and temporary files.
<form>
<reco grammar="http://example.com/rosternames.xml">
<input type="text"/>
</reco>
</form>
Inline using data URI
Note that whitespace is only allowed with base64, so we must have a really
long string.
<form>
<reco grammar='data:text/html;charset=utf-8, <?xml version="1.0"
encoding="UTF-8"?>\r\n<!DOCTYPE grammar PUBLIC "-//W3C//DTD GRAMMAR
1.0//EN"\r\n
"http://www.w3.org/TR/speech-grammar/grammar.dtd">\r\n<grammar
xmlns="http://www.w3.org/2001/06/grammar"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2001/06/grammar
http://www.w3.org/TR/speech-grammar/grammar.xsd" xml:lang="en-US"
version="1.0" root="roster"><meta name="help-hint" content="player names"/><rule id="roster"
scope="public"><example>Axel</example><example>Axel Eric and
Ondrej</example><item repeat="1-"><ruleref uri="#players"/></item><item repeat="0-1"> and <ruleref
uri="#players"/></item></rule><rule id="players"
scope="private"><one-of><item>David<tag>David
</tag></item><item>Ondrej<tag>Ondrej </tag></item><item>Eric<tag>Eric
</tag></item><item>Kasraa<tag>Kasraa </tag></item><item>Axel<tag>Axel
</tag></item><item>Marcus<tag>Marcus </tag></item><!-- and so on up to 18
names --></one-of></rule></grammar>'
<input type="text"/>
</reco>
</form>
Inline grammar
Note the following example is not supported by the proposal since we do not support inline grammars in the html content. However,
some in the group wished this to be considered in the future. This examlpes shows what this would be like.
Much easier to read. More easily supports server-side scripting to plug in
names (at least for humans while developing).
Note that the <reco> element is the parent of both the <input> and <grammar> elements.
<form>
<reco>
<input type="text"/>
<grammar xmlns="http://www.w3.org/2001/06/grammar"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2001/06/grammar
http://www.w3.org/TR/speech-grammar/grammar.xsd"
xml:lang="en-US" version="1.0"
root="roster">
<meta name="help-hint" content="player names"/>
<rule id="roster" scope="public">
<example>Axel</example>
<example>Axel Eric and Ondrej</example>
<item repeat="1-"><ruleref uri="#players"/></item>
<item repeat="0-1">
and
<ruleref uri="#players"/>
</item>
</rule>
<rule id="players" scope="private">
<one-of>
<item>David<tag>David </tag></item>
<item>Ondrej<tag>Ondrej </tag></item>
<item>Eric<tag>Eric </tag></item>
<item>Kasraa<tag>Kasraa </tag></item>
<item>Axel<tag>Axel </tag></item>
<item>Marcus<tag>Marcus </tag></item>
<!-- and so on up to 18 names -->
</one-of>
</rule>
</grammar>
</reco>
</form>
7.2 HTML Speech Protocol Proposal
Multimodal interfaces enable users to interact with web applications using multiple
different modalities. The HTML Speech protocol, and associated HTML Speech API,
are designed to enable speech modalities as part of a common multimodal user experience
combining spoken and graphical interaction across browsers. The specific goal of
the HTML Speech protocol is to enable a web application to utilize the same network-based
speech resources regardless of the browser used to render the application. The HTML
Speech protocol is defined as a sub-protocol of WebSockets [WEBSOCKETS-PROTOCOL],
and enables HTML user agents and applications to make interoperable use of network-based
speech service providers, such that applications can use the service providers of
their choice, regardless of the particular user agent the application is running
in. The protocol bears some similarity to [MRCPv2] where
it makes sense to borrow from that prior art. However, since the use cases for HTML
Speech applications are in many cases considerably different from those around which
MRCPv2 was designed, the HTML Speech protocol is not a direct transcript of MRCP.
Similarly, because the HTML Speech protocol builds on WebSockets, its session negotiation
and media transport needs are quite different from those of MRCP.
7.2.1 Architecture
Client
|-----------------------------|
| HTML Application | Server
|-----------------------------| |--------------------------|
| HTML Speech API | | Synthesizer | Recognizer |
|-----------------------------| |--------------------------|
| Web-Speech Protocol Client |----web-speech/1.0 subprotocol---| Web-Speech Server |
|-----------------------------| |--------------------------|
| WebSockets Client |-------WebSockets protocol-------| WebSockets Server |
|-----------------------------| |--------------------------|
7.2.2 Definitions
- Recognizer
-
Because continuous recognition plays an important role in HTML Speech
scenarios, a Recognizer is a resource that essentially acts as a filter on its
input streams. Its grammars/language models can be specified and changed, as
needed by the application, and the recognizer adapts its processing
accordingly. Single-shot recognition (e.g. a user on a web search page presses
a button and utters a single web-search query) is a special case of this
general pattern, where the application specifies its model once, and is only
interested in one match event, after which it stops sending audio (if it
hasn't already).
A Recognizer performs speech recognition, with the following
characteristics:
- Support for one or more spoken languages and acoustic scenarios.
- Processing of one or more input streams. The typical scenario consists
of a single stream of encoded audio. But some scenarios will involve
multiple audio streams, such as multiple beams from an array microphone
picking up different speakers in a room; or streams of multimodal input such
as gesture or motion, in addition to speech.
- Support for multiple simultaneous grammars/language models, including
but not limited to application/srgs+xml [SPEECH-GRAMMAR].
Implementations may support additional formats, such as ABNF SRGS or an SLM
format.
- Support for continuous recognition, generating events as appropriate such
as match/no-match, detection of the start/end of speech, etc.
- Support for at least one "dictation" language model, enabling
essentially unconstrained spoken input by the user.
- Support for "hotword" recognition, where the recognizer ignores speech
that is out of grammar. This is particularly useful for open-mic
scenarios.
- Support for recognition of media delivered slower than real-time, since network
conditions can and will introduce delays in the delivery of media.
"Recognizers" are not strictly required to perform speech recognition, and
may perform additional or alternative functions, such as speaker verification,
emotion detection, or audio recording.
- Synthesizer
-
A Synthesizer generates audio streams from textual input. It essentially
produces a media stream with additional events, which the user agent buffers and
plays back as required by the application. A Synthesizer service has the
following characteristics:
- Rendering of application/ssml+xml [SPEECH-SYNTHESIS]
or text/plain input to an output audio stream. Implementations may support
additional input text formats.
- Each synthesis request results in a separate output stream that is
terminated once rendering is complete, or if it has been canceled by the
client.
- Rendering must be performed and transmitted at least as rapidly as would
be needed to support real-time playback, and preferably faster. In some
cases, network conditions between service and UA may result in
slower-than-real-time delivery of the stream, and the UA or application will
need to cope with this appropriately.
- Generation of interim events, such as those corresponding to SSML marks,
with precise timing. Events are transmitted by the service as closely as
possible to the corresponding audio packet, to enable real-time playback by
the client if required by the application.
- Multiple Synthesis requests may be issued concurrently rather than queued serially.
This is because HTML pages will need to be able to simultaneously prepare multiple
synthesis objects in anticipation of a variety of user-generated events. A server
may service simultaneous requests in parallel or in series, as deemed appropriate
by the implementation, but it must accept them in parallel (i.e. support having multiple
outstanding requests).
- Because a Synthesizer resource only renders a stream, and is not responsible
for playback of that stream to a user, it does NOT provide any form of shuttle control
(pausing or skipping), since this is performed by the client; nor does it provide
any control over volume, rate, pitch, etc, other than as specified in the SSML input
document.
7.2.3 Protocol Basics
In the HTML speech protocol, the control signals and the media itself are transported
over the same WebSocket connection. Earlier implementations utilized a simple HTTP
connection for speech recognition and synthesis. Use cases involving continuous
recognition motivated the move to WebSockets. This simple design avoids all the
normal media problems of session negotiation, packet delivery, port & IP address
assignments, NAT-traversal, etc, since the underlying WebSocket already satisfies
these requirements. A beneficial side-effect of this design is that by limiting
the protocol to WebSockets over HTTP there should be less problems with firewalls
compared to having a separate RTP connection of other for the media transport. This
design is different from MRCP, which is oriented around telephony/IVR and all its
impediments, rather than HTML and WebServices, and is motivated by simplicity and desire
to keep the protocol within HTTP.
7.2.3.1 Session Establishment
The WebSockets session is established through the standard WebSockets HTTP
handshake, with these specifics:
- The Sec-WebSocket-Protocol header must be "web-speech/1.0". The client
may also request alternative sub-protocols, in which case the server selects
whichever it supports or prefers. This follows standard WebSockets handshake
logic, and allows for extensibility, either for vendor-specific innovation, or
for future protocol versions.
- Service-specific parameters may be passed in the URL query string. Any
parameters set this way can be overridden by subsequent messages sent in the
web-speech/1.0 protocol after the WebSockets session has been established.
The corollary to this is that Service parameters must not be passed in the
HTTP GET message body of the initial WebSockets handshake.
- Prior to sending the 101 Switching Protocols message, the service may send
other HTTP responses to perform useful functions such as redirection, user
authentication, or 4xx errors. This is just standard WebSockets behavior.
For example:
C->S: GET /speechservice123?customparam=foo&otherparam=bar HTTP/1.1
Host: examplespeechservice.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: OIUSDGY67SDGLjkSD&g2
Sec-WebSocket-Version: 9
Sec-WebSocket-Protocol: web-speech/1.0, x-proprietary-speech
S->C: HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
Sec-WebSocket-Protocol: web-speech/1.0
Once the WebSockets session is established, the UA can begin sending requests
and media to the service, which can respond with events, responses or media.
A session may have a maximum of one synthesizer resource and one recognizer
resource. If an application requires multiple resources of the same type (such
as, for example, two synthesizers from different vendors), it must use separate
WebSocket sessions.
There is no association of state between sessions. If a service wishes to
provide a special association between separate sessions, it may do so behind the
scenes (for example, to re-use audio input from one session in another session
without resending it, or to cause service-side barge-in of TTS in one session by
recognition in another session, would be service-specific extensions).
7.2.3.2 Control Messages
The signaling design borrows its basic pattern from [MRCPv2],
where there are three classes of control messages:
- Requests
- C->S requests from the UA to the service. The client requests a method
(SPEAK, LISTEN, STOP, etc) from a particular remote speech resource.
- Status Notifications
- S->C general status notification messages from the service to the UA,
marked as either PENDING, IN-PROGRESS or COMPLETE.
- Named Events
- S->C named events from the service to the UA, that are essentially
special cases of 'IN-PROGRESS' request-state notifications.
control-message = start-line
*(header CRLF)
CRLF
[body]
start-line = request-line | status-line | event-line
header = <Standard MIME header format>
body = *OCTET
The interaction is full-duplex and asymmetrical: service activity is
instigated by requests the UA, which may be multiple and overlapping, and where
each request results in one or more messages from the service back to the
UA.
For example:
C->S: web-speech/1.0 SPEAK 3257
Resource-ID:synthesizer
Audio-codec:audio/basic
Content-Type:text/plain
Hello world! I speak therefore I am.
S->C: web-speech/1.0 3257 200 IN-PROGRESS
S->C: media for 3257
S->C: web-speech/1.0 SPEAK-COMPLETE 3257 COMPLETE
Request Messages
Request messages are sent from the client to the server, usually to request an action
or modify a setting. Each request has its own request-id, which is unique within
a given WebSockets web-speech session. Any status or event messages related to
a request use the same request-id. All request-ids must have a non-negative integer
value of 1-10 decimal digits.
request-line = version SP method-name SP request-id SP CRLF
version = "web-speech/" 1*DIGIT "." 1*DIGIT
method-name = general-method | synth-method | reco-method | proprietary-method
request-id = 1*10DIGIT
NOTE: In some other protocols, messages also include their message length, so that
they can be framed in what is otherwise an open stream of data. In web-speech/1.0,
framing is already provided by WebSockets, and message length is not needed, and
therefore not included.
For example, to request the recognizer to interpret text as if it were
spoken:
C->S: web-speech/1.0 INTERPRET 8322
Resource-Identifier: recognizer
Active-Grammars: <http://myserver.example.com/mygrammar.grxml>
Interpret-Text: Send a dozen yellow roses and some expensive chocolates to my mother
Status Messages
Status messages are sent from the server to the client, to indicate the state of a
request.
status-line = version SP request-id SP status-code SP request-state CRLF
status-code = 3DIGIT
request-state = "COMPLETE"
| "IN-PROGRESS"
| "PENDING"
Specific status code values follow a pattern similar to [MRCPv2]:
- 2xx Success Codes
-
- 200: Success
- 201: Success with some optional header fields ignored.
- 4xx Client Failure Codes
-
- 401: Method not allowed.
- 402: Method not valid in this state.
- 403: Unsupported header field.
- 404: Illegal header field value.
- 405: Resource does not exist.
- 406: Mandatory header field missing.
- 407: Method or operation failed (e.g. grammar compilation failed).
- 408: Unrecognized or unsupported message entity.
- 409: Unsupported header field value.
- 480: No input stream.
- 481: Unsupported content language.
- 5xx Server Failure
-
- 501: Server internal error
- 502: Protocol version not supported
Event Messages
Event messages are sent by the server, to indicate specific data, such as
synthesis marks, speech detection, and recognition results. They are essentially
specialized status messages.
event-line = version SP event-name SP request-id SP request-state CRLF
event-name = synth-event | reco-event | proprietary-event
For example, an event indicating that the recognizer has detected the start
of speech:
S->C: web-speech/2.0 START-OF-SPEECH 8322 IN-PROGRESS
Resource-ID: recognizer
Source-time: 2011-09-06T21:47:31.981+1:30 (when speech was detected)
7.2.3.3 Media Transmission
HTML Speech applications feature a wide variety of media transmission
scenarios. The number of media streams at any given time is not fixed. For example:
- A recognizer may accept one or more input streams, which may start and end at
any time as microphones or other input devices are activated/deactivated by the
application or the user.
- Applications may, and often will, request the synthesis of multiple SSML documents
at the same time, which are buffered by the UA for playback at the application's
discretion.
- The synthesizer needs to return rendered data to the client rapidly (generally
faster than real time), and may render multiple requests in parallel if it has the
capacity to do so.
Whereas a human listener will tolerate the clicks and pops of missing packets so
they can continue listening in real time, recognizers do not require their data
in real-time, and will generally prefer to wait for delayed packets in order to
maintain accuracy.
Advanced implementations of HTML Speech may incorporate multiple channels of audio
in a single transmission. For example, a living-room device with a microphone array
may send separate streams capturing the speech of multiple individuals within the
room. Or, for example, a device may send parallel streams with alternative encodings
that may not be human-consumable but contain information that is of particular value
to a recognition service.
In web-speech/1.0, audio (or other media) is packetized and transmitted as a
series of WebSockets binary messages, on the same WebSockets session used for
the control messages.
media-packet = binary-message-type
binary-stream-id
binary-data
binary-message-type = OCTET
binary-stream-id = 3OCTET
binary-data = *OCTET
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
+---------------+-----------------------------------------------+
| ... |
| Data |
| ... |
+---------------------------------------------------------------+
The binary-stream-id field is used to identify the messages for a
particular stream. It is a 24-bit unsigned integer. Its value for any given
stream is assigned by the sender (client or server) in the initial message of the
stream, and must be unique to the sender within the WebSockets session.
A sequence of media messages with the same stream-ID represents an in-order
contiguous stream of data. Because the messages are sent in-order and audio
packets cannot be lost (WebSockets uses TCP), there is no need for sequence
numbering or timestamps. The sender just packetizes audio from the encoder and
sends it, while the receiver just un-packs the messages and feeds them to the
consumer (e.g. the recognizer's decoder, or the TTS playback buffer). Timing of
coordinated events is calculated by decoded offset from the beginning of the
stream.
The WebSockets stack de-multiplexes text and binary messages, thus separating signaling
from media, while the stream-ID on each media message is used to de-multiplex the
messages into separate media streams.
The binary-message-type field has these defined values:
- 0x01: Start of Stream
-
The message indicates the start of a new stream. This must be the first message
in any stream. The stream-ID must be new and unique to the session. This same stream-ID
is used in all future messages in the stream. The message body contains a 64-bit
NTP timestamp [NTP] containing the local time at
the stream originator, which is used as the base time for calculating event timing.
The timestamp is followed by the ASCII-encoded MIME media type (see [RFC3555]) describing the format that the stream's media is encoded in (usually
an audio encoding). All implementations must support 8kHz single-channel mulaw (audio/basic)
and 8kHz single-channel 16-bit linear PCM (audio/L16;rate=8000). Implementations
may support other content types, for example: to recognize from a video stream;
to provide a stream of recognition preprocessing coefficients; to provide textual
metadata streams; or to provide auxiliary multimodal input streams such as touches/strokes,
gestures, clicks, compass bearings, etc.
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|1 0 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
|1 0 0 0 1 0 1 1 1 1 0 0 0 0 0 1 0 1 1 0 0 0 1 0 1 0 0 1 0 1 1 0|
|0 0 0 0 0 1 1 0 0 1 1 0 1 0 0 0 1 1 0 1 1 0 0 0 0 1 0 1 0 1 0 1|
| 61 75 64 69 |
| 6F 2F 61 6D |
| 72 2D 77 62 |
+---------------------------------------------------------------+
- 0x02: Media
- The message is a media packet, and contains encoded media data.
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|0 1 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
| encoded audio data |
| ... |
| ... |
| ... |
+---------------------------------------------------------------+
The encoding format is specified in the start of stream message
(0x01).
There is no strict constraint on the size and frequency of audio messages.
Nor is there a requirement for all audio packets to encode the same duration of
sound. However, implementations should seek to minimize interference with the
flow of other messages on the same socket, by sending messages that encode
between 20 and 80 milliseconds of media. Since a WebSockets frame header is
typically only 4 bytes, overhead is minimal and implementations should err on
the side of sending smaller packets more frequently.
A synthesis service may (and typically will) send audio faster than
real-time, and the client must be able to handle this.
A recognition service must be prepared to receive slower-than-real-time audio
due to practical throughput limitations of the network.
The design does not permit the transmission of binary media as base-64 text
messages, since WebSockets already provides native support for binary messages.
Base-64 encoding would incur an unnecessary 33% transmission overhead.
- 0x03: End-of-stream
- The 0x03 end-of-stream message indicates the end of the media stream, and
must be used to terminate a media stream. Any future media stream messages
with the same stream-id are invalid.
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|1 1 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
Although most services will be strictly either recognition or synthesis
services, some services may support both in the same session. While this is a
more advanced scenario, the design does not introduce any constraints to prevent
it. Indeed, both the client and server may send audio streams in the same
session.
7.2.3.4 Security
Both the signaling and media transmission aspects of the web-speech/1.0
protocol inherit a number of security features from the underlying WebSockets
protocol [[!WEBSOCKETS-PROTOCOL]:
- Server Authentication
-
Clients may authenticate servers using standard TLS [TLS], simply by using the WSS:
uri scheme rather than the WS: scheme in the service URI. This is standard
WebSockets functionality in much the same way as HTTP specifies TLS by using the
HTTPS: scheme.
- Encryption
-
Similarly, all traffic (media and signaling) is encrypted by TLS, when using
the WSS: uri scheme.
In practice, to prevent man-in-the-middle snooping of a user's voice, user agents
should not use the WS: scheme, and should ONLY use the WSS: scheme. In non-mainstream
cases, such as service-to-service mashups, or specialized user agents for secured
networks, the unencrypted WS: scheme may be used.
- User Authentication
-
User authentication, when required by a server, will commonly be done using
the standard [HTTP11] challenge-response mechanism in
the initial websocket bootstrap. A server may also choose to use TLS client
authentication, and although this will probably be uncommon, WebSockets stacks
should support it.
- Application Authentication:
-
Web services may wish to authenticate the application requesting service. There
is no standardized way to do this. However, the Vendor-Specific-Parameters header
can be used to perform proprietary authentication using a key-value-pair scheme
defined by the service.
HTML speech network scenarios also have security boundaries outside of
signaling and media:
- Transitive Access to Resources
-
A client may require a server to access resources from a third location. Such resources
may include SRGS documents, SSML documents, audio files, etc. This may either be
a result of the application referring to the resource by URI; or of an already loaded
resource containing a URI reference to a separate resource. In these cases the server
will need permission to access these resources. There are three ways in which this
may be accomplished:
- Out-of-band configuration. The developer, administrator, or a provisioning system
may control both the speech server and the server containing the referenced
resource. In this case they may configure appropriate accounts and network access permissions
beforehand.
- Limited-use URIs. The server containing the resource may issue limited-use
URIs, that may be valid for a small finite number of uses, or for a limited period,
in order to minimise the exposure of the resource. The developer would obtain these
URIs as needed, using a mechanism that is proprietary to the resource server.
- Cookies. The client may have a cookie containing a secret that is used
to authorize access to the resource. In this case, the cookie may be passed to
the speech server using cookie headers in a request. The speech server would then use
this cookie when accessing resources required by that request.
- Access to Retained Media
-
Through the use of certain headers during speech recognition, the client may request
the server to retain a recording of the input media, and make this recording available
at a URL for retrieval. The server that holds the recording may secure this recording
by using standard HTTP security mechanisms: it may authenticate client using standard
HTTP challenge/response; it may use TLS to encrypt the recording when transmitting
it back to the client; and it may use TLS to authenticate the client. The server
that holds a recording may also discard a recording after a reasonable period, as
determined by the server.
7.2.3.5 Time Stamps
Timestamps are used in a variety of headers in the protocol. Binary messages use
the 64-bit NTP timestamp format, as defined in [NTP].
Text messages use the encoding format defined in [RFC3339], and reproduced here:
date-time = full-date "T" full-time
full-date = date-fullyear "-" date-month "-" date-mday
full-time = partial-time time-offset
date-fullyear = 4DIGIT
date-month = 2DIGIT ; 01-12
date-mday = 2DIGIT ; 01-28, 01-29, 01-30, 01-31 based on
; month/year
partial-time = time-hour ":" time-minute ":" time-second
[time-secfrac]
time-hour = 2DIGIT ; 00-23
time-minute = 2DIGIT ; 00-59
time-second = 2DIGIT ; 00-58, 00-59, 00-60 based on leap second
; rules
time-secfrac = "." 1*DIGIT
time-numoffset = ("+" / "-") time-hour ":" time-minute
time-offset = "Z" / time-numoffset
7.2.4 General Capabilities
7.2.4.2 Capabilities Discovery
The web-speech/1.0 protocol provides a way for the
application/UA to determine whether a resource supports the basic capabilities
it needs. In most cases applications will know a service's resource capabilities
ahead of time. However, some applications may be more adaptable, or may wish to
double-check at runtime. To determine resource capabilities, the UA sends a
GET-PARAMS request to the resource, containing a set of capabilities, to which
the resource responds with the specific subset it actually supports.
The GET-PARAMS request is much more limited in scope than its [MRCPv2]
counterpart. It is only used to discover the capabilities of a resource. Like all
messages, they must always include the Resource-ID header.
general-method = "GET-PARAMS"
header = capability-query-header
| interim-event-header
| reco-header
| synth-header
capability-query-header =
"Supported-Content:" mime-type *("," mime-type)
| "Supported-Languages:" lang-tag *("," lang-tag)
| "Builtin-Grammars:" "<" URI ">" *("," "<" URI ">")
interim-event-header =
"Interim-Events:" event-name *("," event-name)
event-name = 1*UTFCHAR
- Supported-Languages
- This read-only property is used by the client to discover whether a
resource supports a particular set of languages. Unlike most headers, when a
blank value is used in GET-PARAMS, the resource will respond with a blank
header rather than the full set of languages it supports. This avoids the
resource having to respond with a potentially cumbersome and possibly
ambiguous list of languages and dialects. Instead, the client must include the
set of languages in which it is interested as the value of the
Supported-Languages header in the GET-PARAMS request. The service will respond
with the subset of these languages that it actually supports.
- Supported-Content
- This read-only property is used to discover whether a resource supports
particular encoding formats for input or output data. Given the broad variety
of codecs, and the large set of parameter permutations for each codec, it is
impractical for a resource to advertize all media encodings it could possibly
support. Hence, when a blank value is used in GET-PARAMS, the resource will
respond with a blank value. Instead, the client must supply the of data
encodings it is interested in. The resource responds with the subset it
actually supports. This is used not only to discover supported media encoding
formats, but also, to discover other input and output data formats, such as
alternatives to SRGS, EMMA and SSML.
- Builtin-Grammars
- This read-only property is used by the client to discover whether a
recognizer has a particular set of built-in grammars. The client provides a
list of builtin: URIs in the GET-PARAMS request, to which the recognizer
responds with the subset of URIs it actually supports.
- Interim-Events
- This read/write property contains the set of interim events the client
would like the service to send (see
Interim Events below).
For example, discovering whether the recognizer supports the desired CODECs, grammar
format, languages/dialects and built-in grammars:
C->S: web-speech/1.0 GET-PARAMS 34132
resource-id: recognizer
supported-content: audio/basic, audio/amr-wb,
audio/x-wav;channels=2;formattag=pcm;samplespersec=44100,
audio/dsr-es202212; rate:8000; maxptime:40,
application/x-ngram+xml
supported-languages: en-AU, en-GB, en-US, en
builtin-grammars: <builtin:dictation?topic=websearch>,
<builtin:dictation?topic=message>,
<builtin:ordinals>,
<builtin:datetime>,
<builtin:cities?locale=USA>
S->C: web-speech/1.0 34132 200 COMPLETE
resource-id: recognizer
supported-content: audio/basic, audio/dsr-es202212; rate:8000; maxptime:40
supported-languages: en-GB, en
builtin-grammars: <builtin:dictation?topic=websearch>, <builtin:dictation?topic=message>
For example, discovering whether the synthesizer supports the desired CODECs, languages/dialects,
and content markup format:
C->S: web-speech/1.0 GET-PARAMS 48223
resource-id: synthesizer
supported-content: audio/ogg, audio/flac, audio/basic, application/ssml+xml
supported-languages: en-AU, en-GB
S->C: web-speech/1.0 48223 200 COMPLETE
resource-id: synthesizer
supported-content: audio/basic, application/ssml+xml
supported-languages: en-GB
7.2.4.3 Interim Events
Speech services may care to send optional vendor-specific interim events
during the processing of a request. For example: some recognizers are capable of
providing additional information as they process input audio; and some
synthesizers are capable of firing progress events on word, phoneme, and viseme
boundaries. These are exposed through the HTML Speech API as events that the
webapp can listen for if it knows to do so. A service vendor may require a
vendor-specific value to be set in a LISTEN or SPEAK request before it starts to fire
certain events.
interim-event = version request-ID SP INTERIM-EVENT CRLF
*(header CRLF)
CRLF
[body]
event-name-header = "Event-Name:" event-name
The Event-Name header is required and must contain a value that was
previously subscribed to with the Interim-Events header.
The Request-ID and Content-Type headers are required, and any data conveyed
by the event must be contained in the body.
For example, a synthesis service might choose to communicate visemes through interim events:
C->S: web-speech/1.0 SPEAK 3257
Resource-ID:synthesizer
Audio-codec:audio/basic
Content-Type:text/plain
Hello world! I speak therefore I am.
S->C: web-speech/1.0 3257 200 IN-PROGRESS
S->C: media for 3257
S->C: web-speech/1.0 INTERIM-EVENT 3257 IN-PROGRESS
Resource-ID:synthesizer
Event-Name:x-viseme-event
Content-Type:application/x-viseme-list
"Hello"
0.500 H
0.850 A
1.050 L
1.125 OW
1.800 SILENCE
S->C: more media for 3257
S->C: web-speech/1.0 INTERIM-EVENT 3257 IN-PROGRESS
Resource-ID:synthesizer
Event-Name:x-viseme-event
Content-Type:application/x-viseme-list
"World"
2.200 W
2.350 ER
2.650 L
2.800 D
3.100 SILENCE
S->C: etc
7.2.4.4 Resource Selection
Applications will generally want to select resources with certain
capabilities, such as the ability to recognize certain languages, work well in
specific acoustic conditions, work well with specific genders or ages, speak
particular languages, speak with a particular style, age or gender, etc.
There are three ways in which resource selection can be achieved, each of
which has relevance:
- By URI
-
This is the preferred mechanism.
Any service may enable applications to encode resource requirements as
query string parameters in the URI, or by using specific URIs with known
resources. The specific URI format and parameter scheme is by necessity not
standardized and is defined by the implementer based on their architecture and
service offerings.
For example, a German recognizer with a cell-phone acoustic environment model:
ws://example1.net:2233/webreco/de-de/cell-phone
A UK English recognizer for a two-beam living-room array microphone:
ws://example2.net/?reco-lang=en-UK&reco-acoustic=10-foot-open-room&sample-rate=16kHz&channels=2
Spanish recognizer and synthesizer, where the synthesizer uses a female voice provided by AcmeSynth:
ws://example3.net/speech?reco-lang=es-es&tts-lang=es-es&tts-gender=female&tts-vendor=AcmeSynth
A pre-defined profile specified by an ID string:
ws://example4.com/profile=af3e-239e-9a01-66c0
- By Request Header
-
Request headers may also be used to select specific resource capabilities.
Synthesizer parameters are set through the SPEAK request; whereas
recognition paramaters are set either through the LISTEN request. There is a
small set of standard headers that can be used with each resource: the
Speech-Language header may be used with both the recognizer and synthesizer,
and the synthesizer may also accept a variety of voice selection parameters as
headers. A resource may honor these headers, but does not need to where it
does not have the ability to so. If a particular header value is unsupported,
the request should fail with a status of 409 "Unsupported Header Field Value".
For example, a client requires Canadian French recognition but it isn't available:
C->S: web-speech/1.0 LISTEN 8322
Resource-ID: Recognizer
Speech-Language: fr-CA
S->C: web-speech/1.0 8322 409 COMPLETE
resource-id: Recognizer
A client requres Brazilian Portuguese, and is successful:
C->S: web-speech/1.0 LISTEN 8323
Resource-ID: Recognizer
Speech-Language: pt-BR
S->C: web-speech/1.0 8323 200 COMPLETE
resource-id: Recognizer
Speak with the voice of a Korean woman in her mid-thirties:
C->S: web-speech/1.0 SPEAK 8324
Resource-ID: Synthesizer
Speech-Language: ko-KR
Voice-Age: 35
Voice-Gender: female
Speak with a Swedish voice named "Kiana":
C->S: web-speech/1.0 SPEAK 8325
Resource-ID: Synthesizer
Speech-Language: sv-SE
Voice-Name: Kiana
This approach is very versatile. However some implementations will be incapable
of this kind of versatility in practice.
- By Input Document
-
The [SPEECH-GRAMMAR]
and [SPEECH-SYNTHESIS]
input documents for the recognizer and synthesizer will specify the language
for the overall document, and may specify languages for specific subsections
of the document. The resource consuming these documents should honor these
language assignments when they occur. If a resource is unable to do so, it
should error with a 481 status "Unsupported content language". (It should be
noted that at the time of writing, most currently available recognizer and
synthesizer implementations will be unable to suppor this
capability.)
Generally speaking, given the current typical state of speech technology, unless
a service is unusually adaptable, applications will be most successful using specific
proprietary URLs that encode the abilities they need, so that the appropriate resources
can be allocated during session initiation.
7.2.5 Recognition
A recognizer resource is either in the "listening" state, or the "idle"
state. Because continuous recognition scenarios often don't have dialog turns or
other down-time, all functions are performed in series on the same input
stream(s). The key distinction between the idle and listening states is the
obvious one: when listening, the recognizer processes incoming media and
produces results; whereas when idle, the recognizer should buffer audio but will
not process it.
Recognition is accomplished with a set of messages and events, to a certain
extent inspired by those in [MRCPv2].
Idle State Listening State
| |
|--\ |
| DEFINE-GRAMMAR |
|<-/ |
| |
|--\ |
| INFO |
|<-/ |
| |
|---------LISTEN------------>|
| |
| |--\
| | INTERIM-EVENT
| |<-/
| |
| |--\
| | START-OF-SPEECH
| |<-/
| |
| |--\
| | START-INPUT-TIMERS
| |<-/
| |
| |--\
| | END-OF-SPEECH
| |<-/
| |
| |--\
| | INFO
| |<-/
| |
| |--\
| | INTERMEDIATE-RESULT
| |<-/
| |
| |--\
| | RECOGNITION-RESULT
| | (when mode = recognize-continuous)
| |<-/
| |
|<----RECOGNITION-RESULT-----|
|(when mode = recognize-once)|
| |
| |
|<--no media streams remain--|
| |
| |
|<----------STOP-------------|
| |
| |
|<---some 4xx/5xx errors-----|
| |
|--\ |--\
| INTERPRET | INTERPRET
|<-/ |<-/
| |
|--\ |--\
| INTERPRETATION-COMPLETE | INTERPRETATION-COMPLETE
|<-/ |<-/
| |
7.2.5.1 Recognition Requests
reco-method = "LISTEN"
| "START-INPUT-TIMERS"
| "STOP"
| "DEFINE-GRAMMAR"
| "CLEAR-GRAMMARS"
| "INTERPRET"
| "INFO"
- LISTEN
-
The LISTEN method transitions the recognizer from the idle state to the
listening state. The recognizer then processes the media input streams against
the set of active grammars. The request must include the Source-Time header,
which is used by the Recognizer to determine the point in the input stream(s)
that the recognizer should start processing from (which won't necessarily be
the start of the stream). The request must also include the Listen-Mode header
to indicate whether the recognizer should perform continuous recognition, a
single recognition, or vendor-specific processing.
A LISTEN request may also activate or deactivate grammars and rules using
the Active-Grammars and Inactive-Grammars headers. These grammars/rules are
considered to be activated/deactivated from the point specified in the
Source-Time header.
When there are no input media streams, and the Input-Waveform-URI header has not
been specified, the recognizer cannot enter the listening state, and the listen
request will fail (480). When in the listening state, and all input streams have
ended, the recognizer automatically transitions to the idle state, and issues a
RECOGNITION-RESULT event, with Completion-Cause set to 080 ("no-input-stream").
A LISTEN request that is made while the recognizer is already listening
results in a 402 error ("Method not valid in this state", since it is already
listening).
- START-INPUT-TIMERS
-
This is used to indicate when the input timeout clock should start. For example,
when the application wants to enable voice barge-in during a prompt, but doesn't
want to start the time-out clock until after the prompt has completed, it will delay
sending this request until it's finished playing the prompt.
- STOP
-
The STOP method transitions the recognizer from the listening state to the
idle state. No RECOGNITION-RESULT event is sent. The Source-Time header must
be used, since the recognizer may still fire a RECOGNITION-RESULT event for
any completion state it encounters prior to that time in the input stream.
A STOP request that is sent while the recognizer is idle results in a
402 response (method not valid in this state, since there is nothing to
stop).
- DEFINE-GRAMMAR
-
The DEFINE-GRAMMAR method does not activate a grammar. It simply causes the recognizer
to pre-load and compile it, and associates it with a temporary URI that can then
be used to activate or deactivate the grammar or one of its rules. DEFINE-GRAMMAR
is not required in order to use a grammar, since the recognizer can load grammars
on demand as needed. However, it is useful when an application wants to ensure a
large grammar is pre-loaded and ready for use prior to the recognizer entering the
listening state. DEFINE-GRAMMAR can be used when the recognizer is in either the
listening or idle state.
All recognizer services must support grammars in the SRGS XML format, and may support
additional alternative grammar/language-model formats.
The client should remember the temporary URIs, but if it loses track, it can always
re-issue the DEFINE-GRAMMAR request, which must not result in a service error as
long as the mapping is consistent with the original request. Once in place, the
URI must be honored by the service for the duration of the session. If the service
runs low in resources, it is free to unload the URI's payload, but must always continue
to honor the URI even if it means reloading the grammar (performance notwithstanding).
Refer to [MRCPv2] for more details on this method.
- CLEAR-GRAMMARS
-
In continuous recognition, a variety of grammars may be loaded over time,
potentially resulting in unused grammars consuming memory resources in the
recognizer. The CLEAR-GRAMMARS method unloads all grammars, whether active or
inactive. Any URIs previously defined in DefineGrammar become invalid.
- INTERPRET
-
The INTERPRET method processes the input text according to the set of grammar rules that are
active at the time it is received by the recognizer. It must include the
Interpret-Text header. The use of INTERPRET is orthogonal to any audio
processing the recognizer may be doing, and will not affect any audio
processing. The recognizer can be in either the listening or idle
state.
An INTERPRET request may also activiate or deactivate grammars and rules using the
Active-Grammars and Inactive-Grammars headers, but only if the recognizer is in
the Idle state. These grammars/rules are considered to be activated/deactivated
from the point specified in the Source-Time header.
- INFO
-
In multimodal applications, some recognizers will benefit from additional
context. Clients can use the INFO request to send this context. The
Content-Type header should specify the type of data, and the data itself is
contained in the message body.
7.2.5.2 Recognition Events
Recognition events are associated with 'IN-PROGRESS' request-state
notifications from the 'recognizer' resource.
reco-event = "START-OF-SPEECH"
| "END-OF-SPEECH"
| "INTERIM-EVENT"
| "INTERMEDIATE-RESULT"
| "RECOGNITION-RESULT"
| "INTERPRETATION-COMPLETE"
- END-OF-SPEECH
-
END-OF-INPUT is the logical counterpart to START-OF-INPUT, and indicates
that speech has ended. The event must include the Source-Time header, which
corresponds to the point in the input stream where the recognizer estimates
speech to have ended, NOT when the endpointer finally decided that speech
ended (which will be a number of milliseconds later).
- INTERIM-EVENT
-
See Interim Events above. For example, a recognition
service may send interim events to indicate it's begun to recognize a phrase, or
to indicate that noise or cross-talk on the input channel is degrading accuracy.
- INTERMEDIATE-RESULT
-
Continuous speech (aka dictation) often requires feedback about what has
been recognized thus far. INTERMEDIATE-RESULT provides this intermediate
feedback without having to waiting for a finalized recognition result. As with RECOGNITION-RESULT, contents are assumed to be EMMA unless
an alternate Content-Type is provided.
- INTERPRETATION-COMPLETE
-
This event contains the result of an INTERPRET request.
- RECOGNITION-RESULT
-
This method is similar to the [MRCPv2]
RECOGNITION-COMPLETE method, except that application/emma+xml (EMMA) is the
default Content-Type. The Source-Time header must be included, to indicate the
point in the input stream when the event occurred. When the Listen-Mode is
reco-once, the recognizer will transition from the listening state to the idle
state when this message is fired, and the Recognizer-State header in the event
is set to "idle". Note that in continuous mode the request-state will indicate whether recognition is ongoing (IN-PROGRESS) or complete (COMPLETE).
Where applicable, the body of the message should contain an EMMA that is consistent
with the Completion-Cause.
- START-OF-SPEECH
-
Indicates that start of speech has been detected. The Source-Time header
must correspond to the point in the input stream(s) where speech was estimated
to begin, NOT when the endpointer finally decided that speech began (a number
of milliseconds later).
7.2.5.4 Predefined Grammars
Speech services may support pre-defined grammars that can be referenced
through a 'builtin:' uri. For example:
builtin:dictation?context=email&lang=en_US
builtin:date
builtin:search?context=web
These can be used as top-level grammars in
the Grammar-Activate/Deactivate headers, or in rule references within other
grammars. If a speech service does not support the referenced builtin or if it
does not specify the builtin in combination with other active grammars, it
should return a grammar compilation error.
The specific set of predefined grammars is to be defined later. However,
there must be a certain small set of predefined grammars that a user agent's
default speech recognizer must support. For non-default recognizers, support for
predefined grammars is optional, and the set that is supported is also defined
by the service provider and may include proprietary grammars (e.g.
builtin:x-acme-parts-catalog).
7.2.5.5 Recognition Examples
Example of reco-once
C->S: binary message: start of stream (stream-id = 112233)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|1 0 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
|1 0 0 0 1 0 1 1 1 1 0 0 0 0 0 1 0 1 1 0 0 0 1 0 1 0 0 1 0 1 1 0|
|0 0 0 0 0 1 1 0 0 1 1 0 1 0 0 0 1 1 0 1 1 0 0 0 0 1 0 1 0 1 0 1|
| 61 75 64 69 |
| 6F 2F 61 6D |
| 72 2D 77 62 |
+---------------------------------------------------------------+
C->S: binary message: media packet (stream-id = 112233)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|0 1 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
| encoded audio data |
| ... |
| ... |
| ... |
+---------------------------------------------------------------+
C->S: more binary media packets...
C->S: web-speech/1.0 LISTEN 8322
Resource-Identifier: recognizer
Confidence-Threshold:0.9
Active-Grammars: <built-in:dictation?context=message>
Listen-Mode: reco-once
Source-time: 2011-09-06T21:47:31.981+1:30
S->C: web-speech/2.0 START-OF-SPEECH 8322 IN-PROGRESS
C->S: more binary media packets...
C->S: binary audio packets...
C->S: binary audio packet in which the user stops talking
C->S: binary audio packets...
S->C: web-speech/1.0 END-OF-SPEECH 8322 IN-PROGRESS
C->S: binary audio packet: end of stream
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|1 1 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
S->C: web-speech/1.0 RECOGNITION-RESULT 8322 COMPLETE
Resource-Identifier: recognizer
<emma:emma version="1.0"
C->S: binary message: start of stream (stream-id = 112233)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|1 0 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
|1 0 0 0 1 0 1 1 1 1 0 0 0 0 0 1 0 1 1 0 0 0 1 0 1 0 0 1 0 1 1 0|
|0 0 0 0 0 1 1 0 0 1 1 0 1 0 0 0 1 1 0 1 1 0 0 0 0 1 0 1 0 1 0 1|
| 61 75 64 69 |
| 6F 2F 61 6D |
| 72 2D 77 62 |
+---------------------------------------------------------------+
C->S: binary message: media packet (stream-id = 112233)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|0 1 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
| encoded audio data |
| ... |
| ... |
| ... |
+---------------------------------------------------------------+
C->S: more binary media packets...
C->S: web-speech/1.0 LISTEN 8322
Resource-Identifier: recognizer
Confidence-Threshold:0.9
Active-Grammars: <built-in:dictation?context=message>
Listen-Mode: reco-continuous
Partial: TRUE
Source-time: 2011-09-06T21:47:31.981+1:30 (where in the input stream recognition should start)
C->S: more binary media packets...
S->C: web-speech/2.0 START-OF-SPEECH 8322 IN-PROGRESS
Source-time: 12753439912 (when speech was detected)
C->S: more binary media packets...
S->C: web-speech/2.0 INTERMEDIATE-RESULT 8322 IN-PROGRESS
C->S: more binary media packets...
S->C: web-speech/1.0 END-OF-SPEECH 8322 IN-PROGRESS (i.e. the recognizer has detected the user stopped talking)
C->S: more binary media packets...
S->C: web-speech/1.0 RECOGNITION-RESULT 8322 IN-PROGRESS (because mode = reco-continuous, the request remains IN-PROGRESS)
C->S: more binary media packets...
S->C: web-speech/2.0 START-OF-SPEECH 8322 IN-PROGRESS
S->C: web-speech/2.0 INTERMEDIATE-RESULT 8322 IN-PROGRESS
S->C: web-speech/1.0 RECOGNITION-RESULT 8322 IN-PROGRESS
S->C: web-speech/2.0 INTERMEDIATE-RESULT 8322 IN-PROGRESS
S->C: web-speech/1.0 RECOGNITION-RESULT 8322 IN-PROGRESS (because mode = reco-continuous, the request remains IN-PROGRESS)
S->C: web-speech/1.0 END-OF-SPEECH 8322 IN-PROGRESS (i.e. the recognizer has detected the user stopped talking)
C->S: binary audio packet: end of stream (i.e. since the recognizer has signaled end of input, the UA decides to terminate the stream)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|1 1 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
S->C: web-speech/1.0 RECOGNITION-RESULT 8322 COMPLETE
Recognizer-State:idle
Completion-Cause: 080
Completion-Reason: No Input Streams
1-Best EMMA document
Example showing 1-best with an XML semantics within emma:interpretation. The 'interpretation'
is contained within the emma:interpretation element. The 'transcript' is the value
of emma:tokens and 'confidence' is the value of emma:confidence.
<emma:emma version="1.0"
xmlns:emma="http://www.w3.org/2003/04/emma"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2003/04/emma
http://www.w3.org/TR/2009/REC-emma-20090210/emma.xsd"
xmlns="http://www.example.com/example">
<emma:grammar id="gram1"
grammar-type="application/srgs-xml"
ref="http://example.com/flightquery.grxml"/>
<emma:interpretation id="int1"
emma:start="1087995961542"
emma:end="1087995963542"
emma:medium="acoustic"
emma:mode="voice"
emma:confidence="0.75"
emma:lang="en-US"
emma:grammar-ref="gram1"
emma:media-type="audio/x-wav; rate:8000;"
emma:signal="http://example.com/signals/145.wav"
emma:tokens="flights from boston to denver"
emma:process="http://example.com/my_asr.xml">
<origin>Boston</origin>
<destination>Denver</destination>
</emma:interpretation>
</emma:emma>
N-Best EMMA Doucment
Example showing multiple recognition results and their associated interpretations.
<emma:emma version="1.0"
xmlns:emma="http://www.w3.org/2003/04/emma"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2003/04/emma
http://www.w3.org/TR/2009/REC-emma-20090210/emma.xsd"
xmlns="http://www.example.com/example">
<emma:grammar id="gram1"
grammar-type="application/srgs-xml"
ref="http://example.com/flightquery.grxml"/>
<emma:grammar id="gram2"
grammar-type="application/srgs-xml"
ref="http://example.com/pizzaorder.grxml"/>
<emma:one-of id="r1"
emma:start="1087995961542"
emma:end="1087995963542"
emma:medium="acoustic"
emma:mode="voice"
emma:lang="en-US"
emma:media-type="audio/x-wav; rate:8000;"
emma:signal="http://example.com/signals/789.wav"
emma:process="http://example.com/my_asr.xml">
<emma:interpretation id="int1"
emma:confidence="0.75"
emma:tokens="flights from boston to denver"
emma:grammar-ref="gram1">
<origin>Boston</origin>
<destination>Denver</destination>
</emma:interpretation>
<emma:interpretation id="int2"
emma:confidence="0.68"
emma:tokens="flights from austin to denver"
emma:grammar-ref="gram1">
<origin>Austin</origin>
<destination>Denver</destination>
</emma:interpretation>
</emma:one-of>
</emma:emma>
No-match EMMA Document
In the case of a no-match the EMMA result returned must be annotated as emma:uninterpreted="true".
<emma:emma version="1.0"
xmlns:emma="http://www.w3.org/2003/04/emma"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2003/04/emma
http://www.w3.org/TR/2009/REC-emma-20090210/emma.xsd"
xmlns="http://www.example.com/example">
<emma:interpretation id="interp1"
emma:uninterpreted="true"
emma:medium="acoustic"
emma:mode="voice"
emma:process="http://example.com/my_asr.xml"/>
</emma:emma>
In the case of a no-match the EMMA interpretation returned must be annotated as
emma:no-input="true" and the <emma:interpretation> element must be empty.
<emma:emma version="1.0"
xmlns:emma="http://www.w3.org/2003/04/emma"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2003/04/emma
http://www.w3.org/TR/2009/REC-emma-20090210/emma.xsd"
xmlns="http://www.example.com/example">
<emma:interpretation id="int1"
emma:no-input="true"
emma:medium="acoustic"
emma:mode="voice"
emma:process="http://example.com/my_asr.xml"/>
</emma:emma>
Multimodal EMMA Document
Example showing a multimodal interpretation resulting from combination of speech
input with a mouse event passed in through a control metadata message.
<emma:emma version="1.0"
xmlns:emma="http://www.w3.org/2003/04/emma"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2003/04/emma
http://www.w3.org/TR/2009/REC-emma-20090210/emma.xsd"
xmlns="http://www.example.com/example">
<emma:interpretation
emma:medium="acoustic tactile"
emma:mode="voice touch"
emma:lang="en-US"
emma:start="1087995963542"
emma:end="1087995964542"
emma:process="http://example.com/myintegrator.xml">
<emma:derived-from resource="voice1" composite="true"/>
<emma:derived-from resource="touch1" composite="true"/>
<command>
<action>zoom</action>
<location>
<point>42.1345 -37.128</point>
</location>
</command>
</emma:interpretation>
<emma:derivation>
<emma:interpretation id="voice1"
emma:medium="acoustic"
emma:mode="voice"
emma:lang="en-US"
emma:start="1087995963542"
emma:end="1087995964542"
emma:media-type="audio/x-wav; rate:8000;"
emma:tokens="zoom in here"
emma:signal="http://example.com/signals/456.wav"
emma:process="http://example.com/my_asr.xml">
<command>
<action>zoom</action>
<location/>
</command>
</emma:interpretation>
<emma:interpretation id="touch1"
emma:medium="tactile"
emma:mode="touch"
emma:start="1087995964000"
emma:end="1087995964000">
<point>42.1345 -37.128</point>
</emma:interpretation>
</emma:derivation>
</emma:emma>
Lattice EMMA Document
As an example of a lattice of semantic interpretations, in a travel application
where the source is either "Boston" or "Austin"and the destination is either "Newark"
or "New York", the possibilities might be represented in a lattice as follows:
<emma:emma version="1.0"
xmlns:emma="http://www.w3.org/2003/04/emma"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2003/04/emma
http://www.w3.org/TR/2009/REC-emma-20090210/emma.xsd"
xmlns="http://www.example.com/example">
<emma:grammar id="gram1"
grammar-type="application/srgs-xml"
ref="http://example.com/flightquery.grxml"/>
<emma:interpretation id="interp1"
emma:medium="acoustic"
emma:mode="voice"
emma:start="1087995961542"
emma:end="1087995963542"
emma:medium="acoustic"
emma:mode="voice"
emma:confidence="0.75"
emma:lang="en-US"
emma:grammar-ref="gram1"
emma:signal="http://example.com/signals/123.wav"
emma:media-type="audio/x-wav; rate:8000;"
emma:process="http://example.com/my_asr.xml">
<emma:lattice initial="1" final="8">
<emma:arc from="1" to="2">flights</emma:arc>
<emma:arc from="2" to="3">to</emma:arc>
<emma:arc from="3" to="4">boston</emma:arc>
<emma:arc from="3" to="4">austin</emma:arc>
<emma:arc from="4" to="5">from</emma:arc>
<emma:arc from="5" to="6">portland</emma:arc>
<emma:arc from="5" to="6">oakland</emma:arc>
<emma:arc from="6" to="7">today</emma:arc>
<emma:arc from="7" to="8">please</emma:arc>
<emma:arc from="6" to="8">tomorrow</emma:arc>
</emma:lattice>
</emma:interpretation>
</emma:emma>
7.2.6 Synthesis
In HTML speech applications, the synthesizer service does not participate directly
in the user interface. Rather, it simply provides rendered audio upon request, similar
to any media server, plus interim events such as marks. The UA buffers the rendered
audio, and the application may choose to play it to the user at some point completely
unrelated to the synthesizer service. It is the synthesizer's role to render the
audio stream in a timely manner, at least rapidly enough to support real-time playback.
The synthesizer may also render and transmit the stream faster than required for
real time playback, or render multiple streams in parallel, in order to reduce latency
in the application. This is a stark contrast to the IVR implemented by MRCP, where
the synthesizer essentially renders directly to the user's telephone, and is an
active part of the user interface.
The synthesizer must support [SPEECH-SYNTHESIS]
AND plain text input. A synthesizer may also accept other input formats. In all
cases, the client should use the content-type header to indicate the input
format.
7.2.6.1 Synthesis Requests
synth-method = "SPEAK"
| "STOP"
| "DEFINE-LEXICON"
The set of synthesizer request methods is a subset of those defined in [MRCPv2]
- SPEAK
-
The SPEAK method operates similarly to its [MRCPv2]
namesake. The primary difference is that SPEAK results in a new audio stream
being sent from the server to the client, using the same Request-ID. A SPEAK
request must include the Audio-Codec header. When the rendering has completed,
and the end-of-stream message has been sent, the synthesizer sends a
SPEAK-COMPLETE event.
- STOP
-
When the synthesizer receives a STOP request, it ceases rendering the
requests specified in the Active-Request-ID header. If the Active-Request-ID
header is missing, it ceases rendring all active SPEAK requests. For any SPEAK
request that is ceased, the synthesizer sends an end-of-stream message, and a
SPEAK-COMPLETE event.
- DEFINE-LEXICON
-
This is used to load or unload a lexicon, and is identical to its namesake in [MRCPv2].
7.2.6.2 Synthesis Events
Synthesis events are associated with 'IN-PROGRESS' request-state
notifications from the synthesizer resource.
synth-event = "INTERIM-EVENT"
| "SPEECH-MARKER"
| "SPEAK-COMPLETE"
- INTERIM-EVENT
-
See Interim
Events above.
- SPEECH-MARKER
-
This event indicates that an SSML mark has been rendered. It uses the Speech-Marker
header, which contains a timestamp indicating where in the stream the mark occurred,
and the label associated in the mark.
Implementations should send the SPEECH-MARKER as closely as possible to the
corresponding media packet so clients may play the media and fire events in
real time if needed.
- SPEAK-COMPLETE
-
Indicates that rendering of the SPEAK request has completed.
7.2.6.4 Synthesis Examples
Simple rendering of plain text
The most straightforward use case for TTS is the synthesis of one utterance at a
time. This is inevitable for just-in-time rendition of speech, for example in dialogue
systems or in in-car navigation scenarios. Here, the web application will send a
single speech synthesis SPEAK request to the speech service.
C->S: web-speech/1.0 SPEAK 3257
Resource-ID:synthesizer
Audio-codec:audio/flac
Speech-Language: de-DE
Content-Type:text/plain
Hallo, ich heiße Peter.
S->C: web-speech/1.0 3257 200 IN-PROGRESS
Resource-ID:synthesizer
Stream-ID: 112233
Speech-Marker:timestamp=2011-09-06T10:33:16.612Z
S->C: binary message: start of stream (stream-id = 112233)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|1 0 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
|1 0 0 0 1 0 1 1 1 1 0 0 0 0 0 1 0 1 1 0 0 0 1 0 1 0 0 1 0 1 1 0|
|0 0 0 0 0 1 1 0 0 1 1 0 1 0 0 0 1 1 0 1 1 0 0 0 0 1 0 1 0 1 0 1|
| 61 75 64 69 |
| 6F 2F 66 6C |
| 61 63 +-------------------------------+
+-------------------------------+
S->C: more binary media packets...
S->C: web-speech/1.0 SPEAK-COMPLETE 3257 COMPLETE
Resource-ID:Synthesizer
Completion-Cause:000 normal
Speech-Marker:timestamp=2011-09-06T10:33:26.922Z
S->C: binary audio packets...
S->C: binary audio packet: end of stream ( message type = 0x03 )
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|1 1 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
Simple Rendering of SSML
For richer markup of the text, it is possible to use the SSML format for
sending an annotated request. For example, it is possible to propose an
appropriate pronunciation or to indicate where to insert pauses. (SSML example adapted
from http://www.w3.org/TR/speech-synthesis11/#edef_break)
C->S: web-speech/1.0 SPEAK 3257
Resource-ID:synthesizer
Voice-gender:neutral
Voice-Age:25
Audio-codec:audio/flac
Prosody-volume:medium
Content-Type:application/ssml+xml
<?xml version="1.0"?>
<speak version="1.1" xmlns="http://www.w3.org/2001/10/synthesis"
xml:lang="en-US">
Please make your choice. <break time="3s"/>
Click any of the buttons to indicate your preference.
</speak>
Remainder of example as above
Bulk Requests for Synthesis
Some use cases require relatively static speech output which can be
known at the time of loading a web page. In these cases, all required
speech output can be requested in parallel as multiple concurrent
requests. Callback methods in the web api are responsible to relate each
speech stream to the appropriate place in the web application.
On the protocol level, the request of multiple speech streams
concurrently is realized as follows.
C->S: web-speech/1.0 SPEAK 3257
Resource-ID:synthesizer
Audio-codec:audio/basic
Speech-Language: es-ES
Content-Type:text/plain
Hola, me llamo Maria.
C->S: web-speech/1.0 SPEAK 3258
Resource-ID:synthesizer
Audio-codec:audio/basic
Speech-Language: en-UK
Content-Type:text/plain
Hi, I'm George.
C->S: web-speech/1.0 SPEAK 3259
Resource-ID:synthesizer
Audio-codec:audio/basic
Speech-Language: de-DE
Content-Type:text/plain
Hallo, ich heiße Peter.
S->C: web-speech/1.0 3257 200 IN-PROGRESS
S->C: media for 3257
S->C: web-speech/1.0 3258 200 IN-PROGRESS
S->C: media for 3258
S->C: web-speech/1.0 3259 200 IN-PROGRESS
S->C: media for 3259
S->C: more media for 3257
S->C: web-speech/1.0 SPEAK-COMPLETE 3257 COMPLETE
S->C: more media for 3258
S->C: web-speech/1.0 SPEAK-COMPLETE 3258 COMPLETE
S->C: more media for 3259
S->C: web-speech/1.0 SPEAK-COMPLETE 3259 COMPLETE
The service may choose to serialize its processing of certain requests (such
as only rendering one SPEAK request at a time), but must still accept multiple
active requests.
Multimodal Coordination with Bookmarks
In order to synchronize the speech content with other events in the
web application, it is possible to mark relevant points in time using
the SSML <mark> tag. When the speech is played back, a callback method
is called for these markers, allowing the web application to present,
e.g., visual displays synchronously.
(Example adapted from http://www.w3.org/TR/speech-synthesis11/#S3.3.2)
C->S: web-speech/1.0 SPEAK 3257
Resource-ID:synthesizer
Voice-gender:neutral
Voice-Age:25
Audio-codec:audio/flac
Prosody-volume:medium
Content-Type:application/ssml+xml
<?xml version="1.0"?>
<speak version="1.1" xmlns="http://www.w3.org/2001/10/synthesis"
xml:lang="en-US">
Would you like to sit <mark name="window_seat"/> here at the window, or
rather <mark name="aisle_seat"/> here at the aisle?
</speak>
S->C: web-speech/1.0 3257 200 IN-PROGRESS
Resource-ID:synthesizer
Stream-ID: 112233
Speech-Marker:timestamp=2011-09-06T10:33:16.612Z
S->C: binary message: start of stream (stream-id = 112233)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|1 0 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
|1 0 0 0 1 0 1 1 1 1 0 0 0 0 0 1 0 1 1 0 0 0 1 0 1 0 0 1 0 1 1 0|
|0 0 0 0 0 1 1 0 0 1 1 0 1 0 0 0 1 1 0 1 1 0 0 0 0 1 0 1 0 1 0 1|
| 61 75 64 69 |
| 6F 2F 66 6C |
| 61 63 +-------------------------------+
+-------------------------------+
S->C: more binary media packets...
S->C: web-speech/2.0 SPEECH-MARKER 3257 IN-PROGRESS
Resource-ID:synthesizer
Stream-ID: 112233
Speech-Marker:timestamp=2011-09-06T10:33:18.310Z;window_seat
S->C: more binary media packets...
S->C: web-speech/2.0 SPEECH-MARKER 3257 IN-PROGRESS
Resource-ID:synthesizer
Stream-ID: 112233
Speech-Marker:timestamp=2011-09-06T10:33:21.008Z;aisle_seat
S->C: more binary media packets...
S->C: web-speech/1.0 SPEAK-COMPLETE 3257 COMPLETE
Resource-ID:Synthesizer
Completion-Cause:000 normal
Speech-Marker:timestamp=2011-09-06T10:33:23.881Z
S->C: binary audio packets...
S->C: binary audio packet: end of stream ( message type = 0x03 )
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| message type | stream-id |
|1 1 0 0 0 0 0 0|1 0 0 1 0 1 1 0 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0|
+---------------+-----------------------------------------------+
7.2.7 Examples
This example shows the protocol interactions on the "Testing this
example, and launching this missile. < cough>" user utterance.
???
// Preload large grammar
C->S: web-speech/1.0 DEFINE-GRAMMAR 257
Resource-ID:recognizer
Content-Type:text/uri-list
Content-ID:Precompile-123
builtin:dictation?type=x-acme-military-control
S->C: web-speech/1.0 257 200 COMPLETE
Completion-Cause: 000 Success
C->S: web-speech/1.0 LISTEN 258
Resource-ID:recognizer
Source-Time: 6023
Listen-Mode: continuous
Active-Grammars: session:Precompile-123
S->C: web-speech/1.0 258 200 IN-PROGRESS
// User starts speaking
User Speech: "test"
S->C: web-speech/1.0 258 START-OF-SPEECH IN-PROGRESS
Source-Time: 6035
S->C: web-speech/1.0 INTERMEDIATE-RESULT 258 IN-PROGRESS
Resource-ID:recognizer
Content-Type:application/emma+xml
Source-Time: 6035
Result-Index: 0
<emma:emma version="1.0" ...>
<emma:one-of id="r1" emma:mode="voice">
<emma:interpretation id="int1" emma:confidence="0.65"
emma:tokens="text"/>
<emma:interpretation id="int2" emma:confidence="0.60"
emma:tokens="test"/>
</emma:one-of>
</emma:emma>
API Event1: [0] {"text", "test"}-I
Aggregate result: [{"text", "test"}-I]
// Modifying top choice
S->C: web-speech/1.0 INTERMEDIATE-RESULT 258 IN-PROGRESS
Resource-ID:recognizer
Content-Type:application/emma+xml
Source-Time: 6035
Result-Index: 0
<emma:emma version="1.0" ...>
<emma:one-of id="r1" emma:mode="voice">
<emma:interpretation id="int1" emma:confidence="0.65"
emma:tokens="test"/>
<emma:interpretation id="int2" emma:confidence="0.50"
emma:tokens="text"/>
</emma:one-of>
</emma:emma>
API Event2: [0] {"test", "text"}-I
Aggregate result: [{"test", "text"}-I]
User Speech: "ing"
S->C: web-speech/1.0 INTERMEDIATE-RESULT 258 IN-PROGRESS
Resource-ID:recognizer
Content-Type:application/emma+xml
Source-Time: 6035
Result-Index: 0
<emma:emma version="1.0" ...>
<emma:one-of id="r1" emma:mode="voice">
<emma:interpretation id="int1" emma:confidence="0.70"
emma:tokens="test sting"/>
<emma:interpretation id="int2" emma:confidence="0.50"
emma:tokens="texting"/>
</emma:one-of>
</emma:emma>
API Event3: [0] {"test sting", "texting"}-I
Aggregate result: [ {"test sting"], ["texting"}-I ]
User Speech: "this"
// Combining words within a phrase
S->C: web-speech/1.0 INTERMEDIATE-RESULT 258 IN-PROGRESS
Resource-ID:recognizer
Content-Type:application/emma+xml
Source-Time: 6035
Result-Index: 0
<emma:emma version="1.0" ...>
<emma:one-of id="r1" emma:mode="voice">
<emma:interpretation id="int1" emma:confidence="0.75"
emma:tokens="testing this"/>
<emma:interpretation id="int2" emma:confidence="0.50"
emma:tokens="texting this"/>
</emma:one-of>
</emma:emma>
API Event4: [0] {"testing this", "texting this"}-I
Aggregate result: [ {"testing this"], ["texting this"}-I ]
User Speech: "example <small pause> and"
S->C: web-speech/1.0 INTERMEDIATE-RESULT 258 IN-PROGRESS
Resource-ID:recognizer
Content-Type:application/emma+xml
Source-Time: 6035
Result-Index: 0
<emma:emma version="1.0" ...>
<emma:one-of id="r1" emma:mode="voice">
<emma:interpretation id="int1" emma:confidence="0.75"
emma:tokens="testing this example and"/>
<emma:interpretation id="int2" emma:confidence="0.50"
emma:tokens="texting this sample ant"/>
</emma:one-of>
</emma:emma>
API Event5: [0] {"testing this example and", "texting this sample
ant"}-I
Aggregate result: [ {"testing this example and", "texting this sample
ant"}-I ]
User Speech: "launching"
// Moving words across phrase boundaries
S->C: web-speech/1.0 INTERMEDIATE-RESULT 258 IN-PROGRESS
Resource-ID:recognizer
Content-Type:application/emma+xml
Source-Time: 6035
Result-Index: 0
<emma:emma version="1.0" ...>
<emma:one-of id="r1" emma:mode="voice">
<emma:interpretation id="int1" emma:confidence="0.75"
emma:tokens="testing this example"/>
<emma:interpretation id="int2" emma:confidence="0.50"
emma:tokens="texting this sample"/>
</emma:one-of>
</emma:emma>
API Event6: [0] {"testing this example", "texting this sample"}-I
Aggregate result: [ {"testing this example", "texting this sample"}-I ]
S->C: web-speech/1.0 INTERMEDIATE-RESULT 258 IN-PROGRESS
Resource-ID:recognizer
Content-Type:application/emma+xml
Source-Time: 10032
Result-Index: 1
<emma:emma version="1.0" ...>
<emma:one-of id="r1" emma:mode="voice">
<emma:interpretation id="int1" emma:confidence="0.65"
emma:tokens="ant launching"/>
<emma:interpretation id="int2" emma:confidence="0.45"
emma:tokens="ant lunching"/>
</emma:one-of>
</emma:emma>
Event7: [1] {"and launching", "ant lunching"}-I
Aggregate result: [ {"testing this example", "texting this sample"}-I,
{"and launching", "ant lunching"}-I ]
User Speech: "this missile"
S->C: web-speech/1.0 INTERMEDIATE-RESULT 258 IN-PROGRESS
Resource-ID:recognizer
Content-Type:application/emma+xml
Source-Time: 10032
Result-Index: 1
<emma:emma version="1.0" ...>
<emma:one-of id="r1" emma:mode="voice">
<emma:interpretation id="int1" emma:confidence="0.70"
emma:tokens="and launching this missile"/>
<emma:interpretation id="int2" emma:confidence="0.40"
emma:tokens="ant lunching this thistle"/>
</emma:one-of>
</emma:emma>
Event8: [1] {"and launching this missile", "ant lunching this
thistle"}-I
Aggregate result: [ {"testing this example", "texting this sample"}-I,
{"and launching this missile", "ant lunching this thistle"}-I ]
// First result is finalized
S->C: web-speech/1.0 INTERMEDIATE-RESULT 258 IN-PROGRESS
Resource-ID:recognizer
Content-Type:application/emma+xml
Source-Time: 6035
Result-Index: 0
Result-Status: final
<emma:emma version="1.0" ...>
<emma:one-of id="r1" emma:mode="voice">
<emma:interpretation id="int1" emma:confidence="0.80"
emma:tokens="testing this example"/>
<emma:interpretation id="int2" emma:confidence="0.45"
emma:tokens="texting this sample"/>
</emma:one-of>
</emma:emma>
Event8: [0] {"testing this example", "texting this sample"}-F
Aggregate result: [ {"testing this example", "texting this sample"}-F,
{"and launching this missile", "ant lunching this thistle"}-I ]
User Speech: "<cough>"
S->C: web-speech/1.0 INTERMEDIATE-RESULT 258 IN-PROGRESS
Resource-ID:recognizer
Content-Type:application/emma+xml
Source-Time: 13022
Result-Index: 2
<emma:emma version="1.0" ...>
<emma:one-of id="r1" emma:mode="voice">
<emma:interpretation id="int1" emma:confidence="0.45"
emma:tokens="confirm"/>
</emma:one-of>
</emma:emma>
Event9: [2] {"cancel"}-I
Aggregate result: [ {"testing this example", "texting this sample"}-F,
{"and launching this missile", "ant lunching this thistle"}-I,
{"confirm"}-I ]
// Retracts spurious result
S->C: web-speech/1.0 INTERMEDIATE-RESULT 258 IN-PROGRESS
Resource-ID:recognizer
Result-Index: 2
Source-Time: 13022
Result-Status: final
Event10: [2] {}-F
Aggregate result: [ {"testing this example", "texting this sample"}-F,
{"and launching this missile", "ant lunching this thistle"}-I ]
// Second result finalized, which completes transaction
S->C: web-speech/1.0 RECOGNITION-RESULT 258 COMPLETE
Resource-ID:recognizer
Content-Type:application/emma+xml
Result-Index: 1
Source-Time: 10032
Result-Status: final
<emma:emma version="1.0" ...>
<emma:one-of id="r1" emma:mode="voice">
<emma:interpretation id="int1" emma:confidence="0.75"
emma:tokens="and launching this missile"/>
<emma:interpretation id="int2" emma:confidence="0.40"
emma:tokens="ant lunching this thistle"/>
</emma:one-of>
</emma:emma>
Event11: [1] {"and launching this missile", "ant lunching this
thistle"}-F
Aggregate result: [ {"testing this example", "texting this sample"}-F,
{"and launching this missile", "ant lunching this thistle"}-F ]