XML+namespaces promotes precise identification of terms in the web. Inferencing over these terms appears to be taking two divergent paths: XPath/XQuery and RDF. There appears to be little communication between the two communities. The purpose of this document is to provide some shared context with which the two may understand the intent and capabilities of each other's approaches.
An example presented in the A Rule-based Language for Querying and Transforming XML Data - Sebastian Schaffert paper invloves the merging of data from two formats of bookstore catalogs and finding the least expensive vendor for a book. These examples provide an excellent example of XPath-accessed documents:
Bookstore 1
<bib> <book> <title>Cryptonomicon</title> <authors> <author>Alice</author> <author>Bob</author> </authors> <price>39.95</price> </book> <book> <title>Applied Cryptography</title> <author>Alice</author> <price>34.95</price> </book> ... </bib>
[ Sebastian Scha ert Page 3 ]
You could fetch this data with:
Query 1
<books-with-prices> { FOR $a in document("A/bib.xml")//book, $b in document("B/reviews.xml")//entry WHERE $b/title = $a/title RETURN <book-with-prices> { $b/title } <price-A> { $a/price/text() } </price-A> <price-B> { $b/price/text() } </price-B> </book-with-prices> } </books-with-prices>
[ Sebastian Scha ert Page 7 ]
to get:
Result 1
<books-with-prices> <book-with-prices> <title>Applied Cryptography</title> <price-A>34.95</price-A> <price-B>36.95</price-B> </book-with-prices> <book-with-prices> <title>Cryptonomicon</title> <price-A>39.95</price-A> <price-B>31.95</price-B> </book-with-prices> ... </books-with-prices>
[ Sebastian Scha ert Page 5 ]
Now confound the problem with another schema presenting similar data:
Bookstore B.
<reviews> <entry> <title>Applied Cryptography</title> <price>36.95</price> <comment>A good book on cryptography</comment> </entry> <entry> <title>Cryptonomicon</title> <price>31.95</price> <comment>A must-have for your private intelligence service</comment> </entry> ... </reviews>
[ Sebastian Scha ert Page 4 ]
Sebastian Schaffert proposes a more flexible query language, Xcerpt. Xcerpt is a combination of F-Logic and traditional infoset accessors like XQuery and the DOM. Xcerpt expresses rules to act upon XML documents. The paths of the logic expressions are tailored for a particular DTD or schema of XML document.
Xcerpt Query 1
<book-with-prices> <title>T</title> <price-A>Pa</price-A> <price-B>Pb</price-B> </book-with-prices> where in A/bib.xml: <book> <title>T</title> <price>Pa</price> </book> and in B/reviews.xml: <entry> <title>T<title> <price>Pb</price> </entry>
[ Sebastian Scha ert Page 10 ]
//foo tend to be inefficient as they require that all elements be searched to see if they contain a foo element. Contrast this with the RDF approach where subject-accessed may be most efficient, but it is easier to index other accessors (predicate and object). This issue is componded when addressing multiple documents. It tends tbe be easier to put RDF into a database.RDF constrains data expression to a directed labeled graph (DLG). The edges in this graph reperesent binary relations between nodes. The use of binary relations complicates the expression of n-ary relationships but permits a homogeneous data modeln (see see connection trap below).
The data expressed in the Xcerpt bookstore data exmaple could be expressed in RDF triples as:
Bookstore 1
book1 --store1:type-> store1:Book book1 --store1:title-> "Catcher In the Rye" book1 --store1:Author-> "J. D. Salinger" book1 --store1:cost-> "39.95"
Bookstore 2
book1 --store2:type-> store2:Book book1 --store2:title-> "Catcher In the Rye" book1 --store2:Author-> "J. D. Salinger" vendor1 --store2:saleItem-> sale1 sale1 --store2:book-> book1 sale1 --store2:cost-> "39.95"
This example shows two bookstores that use very different schemas to represent their sale prices. The prices can be extracted with the following RDF rules:
...need to find the actual example - EGP
| Xcerpt | RDF | |
|---|---|---|
| expressivity | author may create any structure | restricted to using DLG |
| re-use of terms | not common in XML documents | common and encouraged |
| access | naturally access-limited | triples may be serviced from anywhere |
| logic expression | separate language | expressed somewhat within the model |
XML documents assume a closed world where the range of valid documents is known and expressible. XML schemas can be used to constrain a document and provide structure-level validation. RDF assumes an open world where the validity of documents is more abstract. RDF schema is generally used for type inferencing. For instance, RDF schema allows an application to assume that, if something has a PersonelRecord, it is an Employee. These types are additive. Observing that the previous object also has a child would allow the same application to discover that the object is an Employee and a Parent. Data integrity constraints are more difficult to express in a world where anyone can say anything about anything, and most of it may be valid for some purposes. DAML+OIL, a description logic application, adds more type inferencing to RDF schema and provides a mechanism to say that certain types or disjoint. For example, suppose Employee is a subclass of Human and Human is disjoint from Machine. The application would know there was a data integrity error upon observing an object with both a PersonelRecord and a PartNumber.
XML Query uses a non-XML syntax to specify queries over data stored in XML documents. It uses XPath as well as a large amount of its own syntax to select pieces of the infosets from these documents. It is likely that some RDF query engines will provide a subset of XML Query functions to manipulate RDF literals, especially XML trees specified via parseType="literal" properties.
The Syntactic Web, by Jonathan Robie, outlines an alternative technique to storing RDF (or triples) in XML. The approach is to create a list of n-triples inside an XML root element.
<statement>
<subject>http://www.artchive.com/rembrandt/artist_at_his_easel.jpg</subject>
<predicate>c:mime-type</predicate>
<object>image/jpeg</object>
</statement>
This "canonicalized" RDF datas eliminates the need to do syntactic queries over variants of the syntax based on tree nesting or abbreviated syntax. The advantage is that XML Query Language can be used for graph queries confined to the scope of the document. UUIDs can be used to assure the ability to merge graphs from multiple documents. This amounts to performing a SQL join on a flat triple store.
This example applies a query used in RDF Query and Rules: A Framework and Survey.
LET $t := document("Snowboard.rdf")/rdf/statement
FOR $serviceType in $t[predicate="rdf:type" and object="wsdl:service"],
$servicePort in $t[predicate="wsdl:hasPort"],
$portBinding in $t[predicate="wsdl:binding"],
$bindingStyle in $t[predicate="wssoap:style"],
$bindingTransport in $t[predicate="wssoap:transport"],
$bindingName in $t[predicate="wsdl:name"],
WHERE $serviceType/subject=$servicePort/subject
AND $servicePort/object=$portBinding/subject
AND $bindingStyle/object=$bindingTransport/subject
AND $bindingTransport/object=$bindingName/subject
RETURN $servicePort/object, $bindingName/object
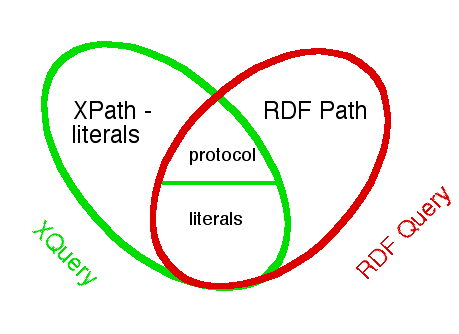
Another approach to leveraging off the investment of XQuery and promote interoperability where possible is to re-use as much of XQuery as possible, replacing portions that are used to traverse syntactic XML trees with functionality to traverse RDF graphs. Pictorially, this could be viewed as replacing XPath (except for that needed to peer into literals) with an RDF path language.
Procedurally, this intersection can be determined by examining the XQuery language data model and semantics. Practically, this would involve providing some built-in functions to access a projection of RDF data onto an XQuery data model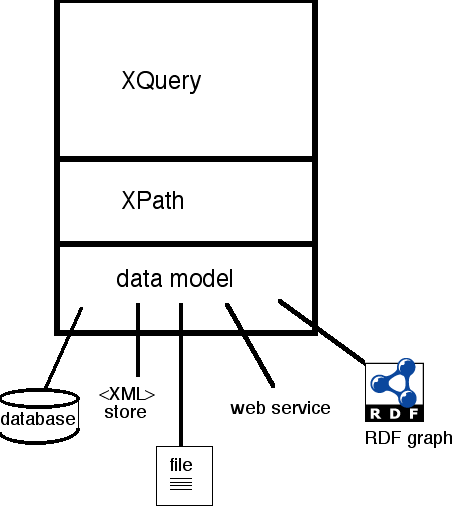 .
.
FOR $a in //node,
$b in //node,
$c in //node
WHERE holds($a, p4, $b)
AND holds($b, p5, $c)
RETURN
<node>{$a, $c}</node>
where //node and holds are language extensions importing RDF data stores into the XQuery data model. This approach seems not to re-use much of XML, but could in cases like
FOR $a in //node[typeof(???)=xsd:integer]
A variant of this is to keep the XPath portion for traversal of XMLLiterals.
Define a modest graph traversal language, with conjunctions and possibly disjunctions and safe negation. Define interactions between this graph "grepping" lanuage and XQuery. Applications would rely on the "graph grep" to find nodes and then on XQuery to look into literals.