| Semantic Web Activity: Advanced Development
This document presents the "TR Automation" project; this project, based on the use of Semantic Web tools and technologies, has allowed to streamline the publication paper trail of W3C Technical Reports, to maintain an RDF-formalized index of these specifications and to create a number of tools using these newly available data.
The most visible part of W3C work, its main deliverables are its Technical Reports published by W3C Working Groups. These Technical Reports are published following a well-defined process, defined by the Process Document and detailed in the publication rules (also known as "pubrules") and in the Recommendation Track transition document.
While there are still plenty of opportunities to automate the process behind the publication of W3C Technical Reports, the core of this project has been realized. This is translated in the following deliverables:
Previously done by hand, the process of updating the list of Technical Reports (referred as the TR page
) is now entirely automated; this means that the system is able to extract all the necessary information from a given Technical Report and to process it as described by the W3C Process to produce an updated version of the TR page.
This works as follows:
But going a bit more in the details reveals some interesting points.
To be published a W3C Technical Report, a document has to comply with a set of rules, often referred as pubrules
. While these rules have been developed to enforce requirements from the Process Document and a certain visual consistency between Technical Reports, it happens that these rules are formal enough that:
Since W3C Technical Reports are published normatively as valid HTML or XHTML, and since RDF has an XML serialization, XSLT works pretty well to do the actual work of checking the rules and extracting the metadata - noting that valid HTML can be transformed in XHTML on the fly using for instance tidy.
Also, a fair number of the pubrules consist in checking that some properties of the document are properly and consistently reflected in text and formatting; that means there is a common base between extracting the metadata and checking the compliance to the pubrules.
Thus, there are 3 XSLT style sheets at work:
For instance, applying the RDF/XML Formatter on XML 1.0 (a pubrules compliant document) outputs:
<rdf:RDF xmlns:contact="http://www.w3.org/2000/10/swap/pim/contact#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:doc="http://www.w3.org/2000/10/swap/pim/doc#"
xmlns:org="http://www.w3.org/2001/04/roadmap/org#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rec="http://www.w3.org/2001/02pd/rec54#"
xmlns="http://www.w3.org/2001/02pd/rec54#"
xmlns:mat="http://www.w3.org/2002/05/matrix/vocab#">
<REC rdf:about="http://www.w3.org/TR/2004/REC-xml-20040204">
<dc:date>2004-02-04</dc:date>
<dc:title>Extensible Markup Language (XML) 1.0 (Third Edition)</dc:title>
<cites>
<ActivityStatement rdf:about="http://www.w3.org/XML/Activity"/>
</cites>
<doc:versionOf rdf:resource="http://www.w3.org/TR/REC-xml"/>
<org:deliveredBy rdf:parseType="Resource">
<contact:homePage rdf:resource="http://www.w3.org/XML/Group/Core"/>
</org:deliveredBy>
<doc:obsoletes rdf:resource="http://www.w3.org/TR/2003/PER-xml-20031030"/>
<previousEdition rdf:resource="http://www.w3.org/TR/2004/REC-xml-20040204"/>
<mat:hasErrata rdf:resource="http://www.w3.org/XML/xml-V10-3e-errata"/>
<mat:hasTranslations rdf:resource="http://www.w3.org/2003/03/Translations/byTechnology?technology=REC-xml"/>
<editor rdf:parseType="Resource">
<contact:fullName>Tim Bray</contact:fullName>
<contact:mailbox rdf:resource="mailto:tbray@textuality.com"/>
</editor>
<editor rdf:parseType="Resource">
<contact:fullName>Jean Paoli</contact:fullName>
<contact:mailbox rdf:resource="mailto:jeanpa@microsoft.com"/>
</editor>
<editor rdf:parseType="Resource">
<contact:fullName>C. M. Sperberg-McQueen</contact:fullName>
<contact:mailbox rdf:resource="mailto:cmsmcq@w3.org"/>
</editor>
<editor rdf:parseType="Resource">
<contact:fullName>Eve Maler</contact:fullName>
<contact:mailbox rdf:resource="mailto:elm@east.sun.com"/>
</editor>
<editor rdf:parseType="Resource">
<contact:fullName>François Yergeau</contact:fullName>
<contact:mailbox rdf:resource="mailto:francois@yergeau.com"/>
</editor>
<mat:hasImplReport rdf:resource="http://www.w3.org/XML/2003/09/xml10-3e-implementation.html"/>
</REC>
<FirstEdition rdf:about="http://www.w3.org/TR/2004/REC-xml-20040204"/>
</rdf:RDF>
Open questions
this is a Rec) from guesses (
this is a Last Call)?
transformation reference (but see issue about inferencing)?The current publication process use the RDF data at its core as follows:
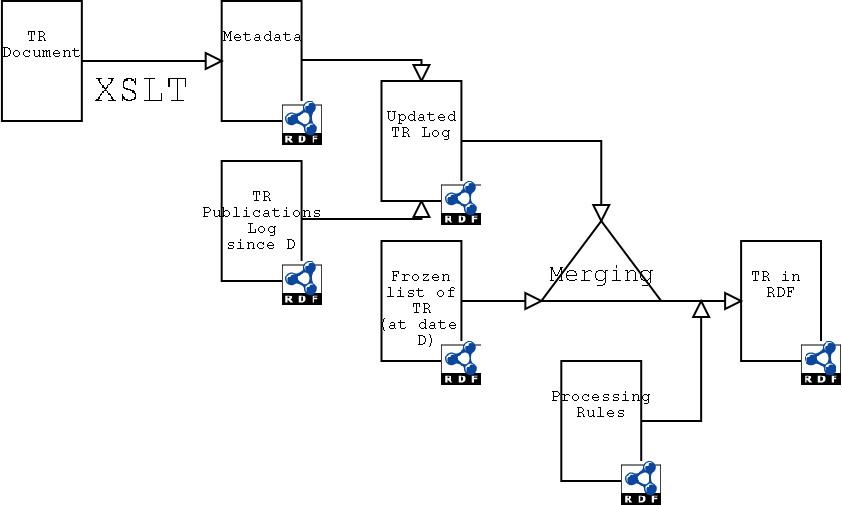
This process is a good example of a paper trail machine.
Note: The freezing of the TR page happens regularly (every 6 months); at some point, it could be approved by the AC Forum as part of the process(at least at the first time).
@@@
@@@
The publication process (through its many variations) had been enforced mostly by human-only interactions since the start of W3C, but with growing pain as the number of Working Groups and Technical Reports raised over time.
The main bottleneck that had started to appear was around the work done by the W3C Webmaster, who, in this process, is in charge of:
http://www.w3.org/TR/,While these tasks may not seem overwhelming, the detailed analysis that some of the "pubrules" require and the ever growing size of the Technical Reports list made the exercise error-prone, particularly when in peak times, the number of (rather big) documents published was reaching 15 per day.
The automation needs were divided [member only] in 3 separate steps:
The idea that this should be automated gets back at least to September 1997 (see Dan Connolly email on this topic, and the follow-up meeting series - Team-only), and tools that helped the Webmaster assess the readiness of a document grew in parallel with the matching rules. For instance, the now indepedent W3C Linkchecker comes from a tool initially developed by one of the W3C Webmasters to help finding broken links in the to be published documents.
The culmination of these tools came with the pubrules checker, an XSLT-based tool that allows to see at a glance what rules are not met by the document being checked.
With the pubrules checker, it became possible to check semi-automatically if a document may be published and to extract the data that had to be added to the technical reports list.
To automate the publication process, the first step was to formalize these data - in RDF since the extracted metadata are in RDF. Dan Connolly had started to work on this step in March 2000 (Team-only), developing a fairly simple style sheet allowing to extract RDF data about all the latest versions information given in the TR list at that time.
As always, the evil was in the details and some side-cases had to be taken into account in this process. Some rare cases were handled on the side.
But this only got information about the latest versions, and to make a reasonably useful system, the dated versions URIs were needed to.
This meant getting the data from the filesystem, which was back then the only official encoding of latest/this versions relationships. This proved to be quite challenging, for various reasons, but mainly because the filesystem usage (usually symbolic links) had changed over the time and finding consistency was not necessarily easy. First we had to extract the core data from the filesystem and then specify the data that were incorrectly deduced from it.
@@@@
Once all those data collected, it just needed to be aggregated and sorted out, which was done using cwm and a filter as specified in a Makefile. The result was the first version a RDF formalized list of W3C digital library.
This allows to build the TR page from this list using a style sheet to create a HTML human readable version of the RDF data. Other views of the page can be generated pretty easily with the appropriate style sheet:
With a little more work and interaction with other RDF data, a list of TR by W3C Activities has also been produced.
See also the ideas of what else could be automated in the TR publication process.
{kind=link}