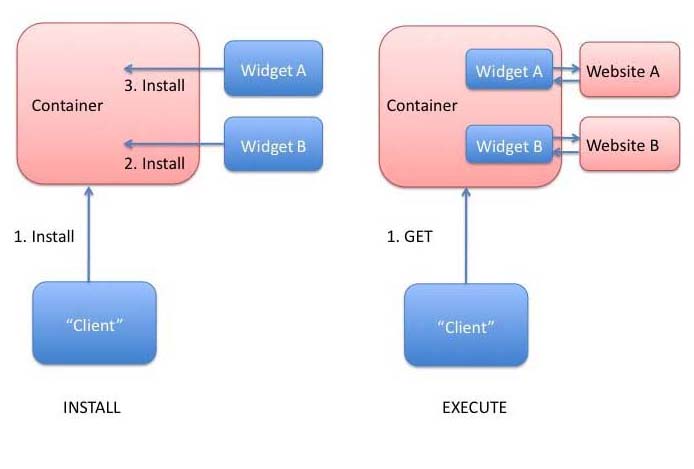
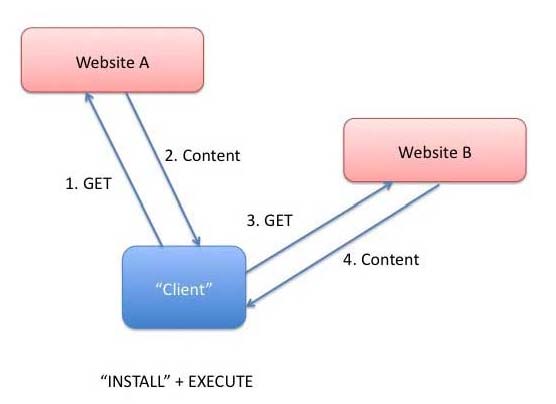
The general architecture for Web Applications can be described as a user, from a
browser, initiating an application that may run on one or more websites. The websites
communicate to one another and may exchange data or start processes.
The user initiates the application on one websites, sending parameters and other
customizing information to it. This website may enlist the aid of other websites.
The display on the user's browser, in general, may consist of data from several
websites as described in Architecture 3.
In some cases, code may be transferred to run on the user's browser.
See Architecture 1.
In addition to the usual conerns with browsers and URIs this architecture
provides several additional challenges. For example:
Secure communication between the websites
Trust between the cooperating websites (see MashSSL)
Need for client-side storage
Client-side Storage
Note that the multiple websites in this model could be copies of the same website.
Thus, you could be executing a single transaction in which you buy two different
airline tickets from the same website. If you use cookies to remember the details
of the tickets, the cookies would go to both copies of the website and the details
of the tickets would get mixed up.
What is needed is, clearly, separate "cookies" for each copy of the website.
The Web Applications WG is attempting to address this requirement with a facility
called Session Storage. See Web Storage. This essentially, provides a local database that can be used to store name-value pairs for each session with a website.
The second requirement comes from a situation where the user is working with
multiple windows, and wants the session to persist across interruptions in
connectivity. To enable this a local database can be used to store name-value pairs
and this data can be used while the website is offline.
Again, cookies do not handle this case well, because they are transmitted with every request. This requirement is also being addressed by the Web Applications WG with a
facility called Local Storage which allows name-value pairs to be stored locally.
See Web Storage.
Such a facility can also be used to improve performance. The user may wish to store
megabytes of user data, such as entire user-authored documents or a user's mailbox,
on the client side and work on them offline.
While Session Storage and Local Sorage provide simple name-value pair storage
to cover the abovementioned usecases, they do not provide advanced "database"
facilities such as in-order retrieval of keys, efficient searching over values, r storage of duplicate values for a key. To provide such facilities the Web Applications WG
is working on a specification called Indexed Database API. A competing specification that provides similar
capabilities called Web SQL Database. This specification seems to be on hold for the time being.
Some have argued against it because, despite its name, it does not follow the SQL
standard. Others have argued against it because it is based on a proprietary product
and it is difficult to get two independent implementations.
These days several vendors offer in-memory databases that work quite well even on
notebooks. So, for these advanced capabilities, why not merely add a SQL database
interface to HTML? [I think there was such an interface in earlier versions of
the HTML5 spec.]