<ht_google> Scribe: Henry S. Thompson
<ht_google> ScribeNick: ht_google
some breakfast noodling on upcoming TAG priorities...
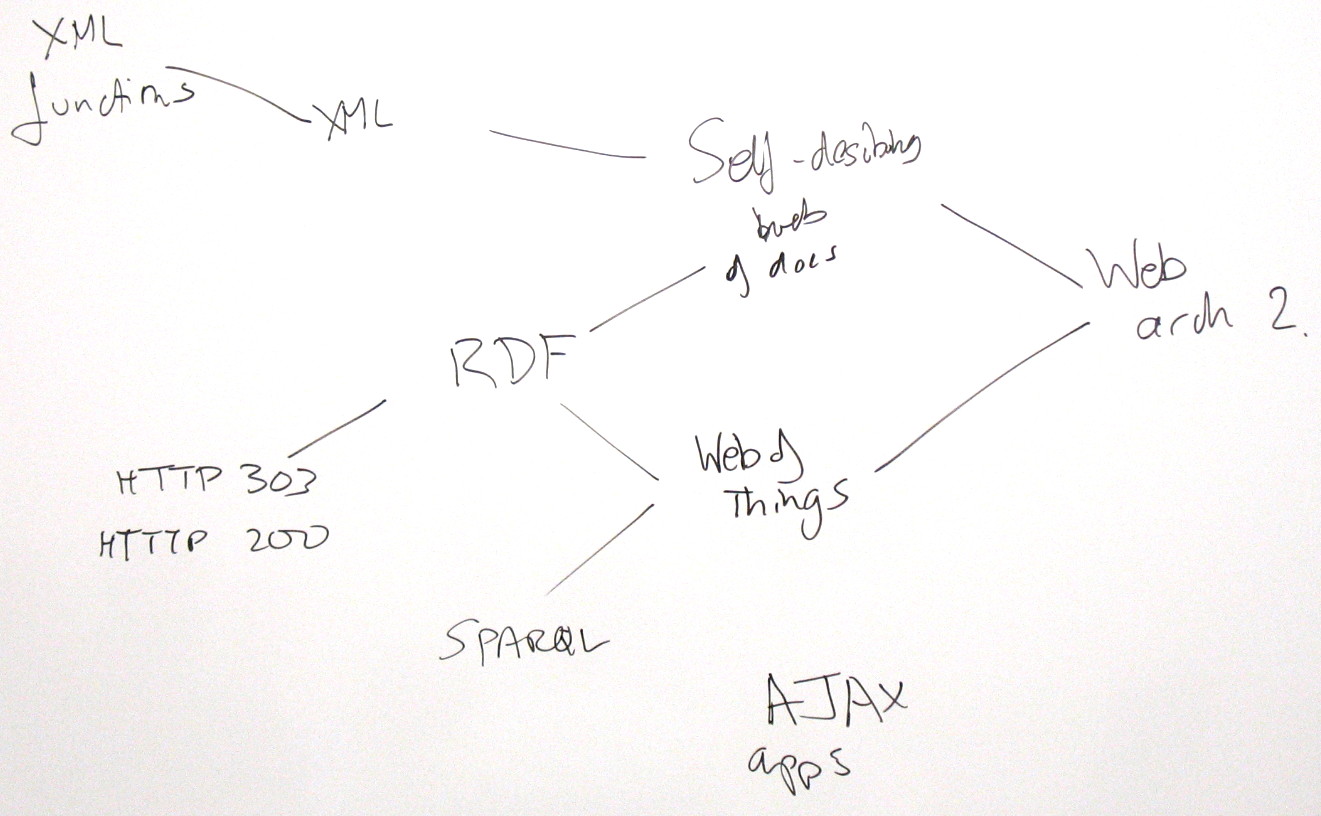
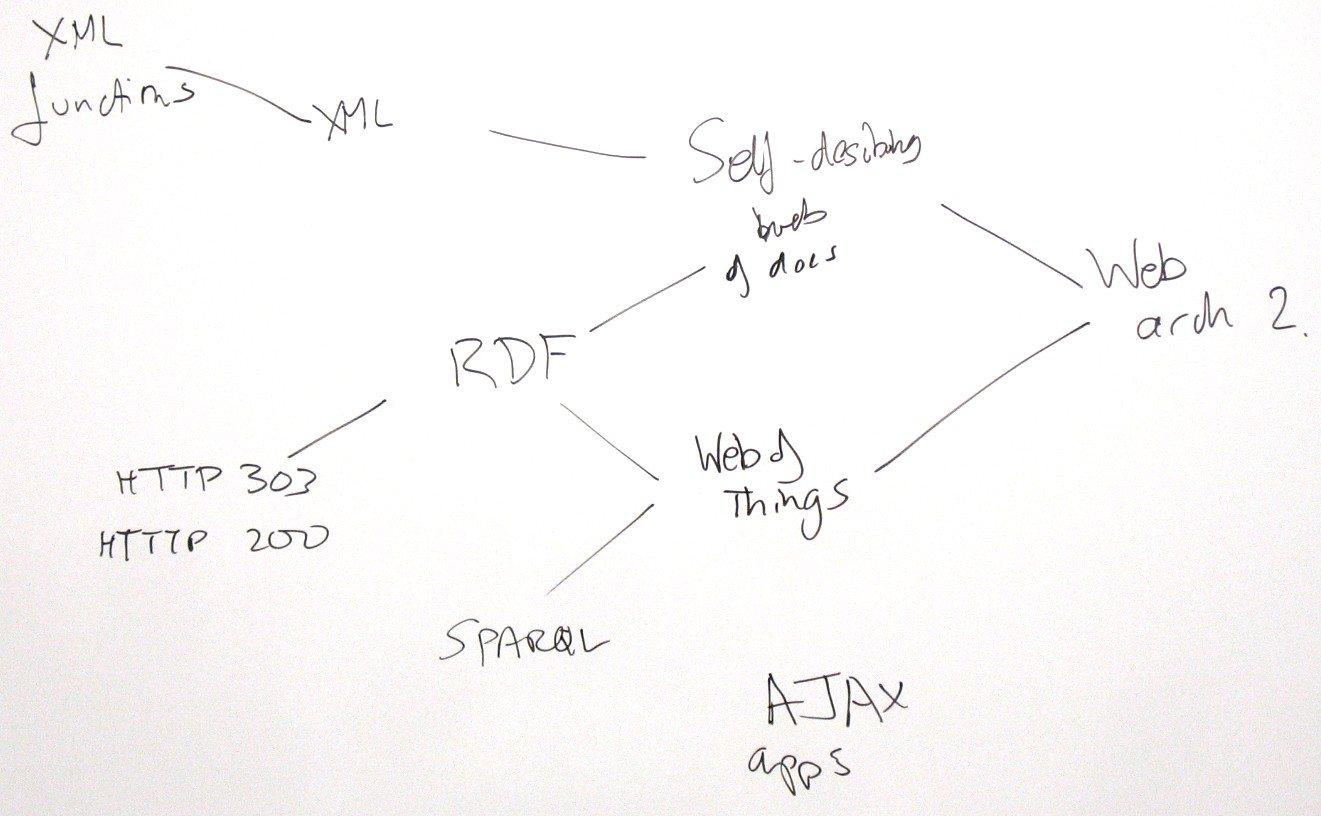
1) Semantic Web Arch
2) Web 2.0
State; programs; what should have URIs, and how
3) Where can we have an impact
4) Injecting more sense of urgency
RESOLUTION: Revisit Monday 1700GMT meeting time after the summer
<Noah> Stuart asked us at breakfast to noodle on upcoming TAG priorities. I heard two big themes:
<Noah> From Tim and later endorsed by Noah: Semantic Web
<Noah> From Henry, Dave and others: Web 2.0
<dorchard> In think our priorities should be guided by how much effect we can have.
<dorchard> That's why we have de-emphasized Web Services
<dorchard> I also think that Stateful clients are becoming much more prevalent as Rich Client Apps become more larger and more stateful
<dorchard> This has effects on REST, use of URIs, and stateful vs stateless apps
<raman> Web Arch is complete with respect to what was well understood in 2000. Things that were left unsaid in Web Arch 1.0 have provided room for innovation --- leading to dynamic Web applications on the data driven Web. Now that we have seen how the Web has evolved, what are the next set of architectural principles we can add to Web Arch to make it more complete with respect to how the Web looks today? This might be an essential step to
<raman> ensure that the next phase of evolution progresses from a well-understood, well-documented base.
NW: Post-WebArch1.0, will the outline of WebArch2.0 emerge?
SW: Updating WebArch1.0 is a
possible work item
... Version identification and Mime Type respect are possible
areas for revision
DC: Working with our customers
would be good, it would identify more possible gaps
... HTML WG, CDF WG
TBL: SWD/SWEO, ATOM
<raman> backplane work
RL: UWA
DC: More approachable W3C specs. . .
TVR: Is that our job?
RL: I don't see the Web2.0/SemWeb divide as very large, there's more in common than there are differences
NM: Both of these are really just reality checks on what we do, which is independent/foundational wrt both of them
TVR: Both W2.0 and SW are natural evolutions of the original Web, and WebArch should grow to manifest this
SW: WebArch1.0 tried to focus on Identification, Representation and Interaction -- do we need a new one?
HST, TVR: No, but much more on Interaction, which isn't well represented in WebArch1.0
NM: Bill Gates said "The
important standards are the ones on the wire" -- I tend to feel
parallel to that to the effect that the stuff going on between
the user and the browser don't matter very much
... That's wrong, they're important, just perhaps a bit less
than what comes over the wire
TBL: Javascript doesn't change things, it's components are the functions you can call, so its an on-the-wire standard just as well
NM: Yes, but when you start looking at e.g. event percolation up the window hierarchy, I don't see how that was on the wire
SW: I'm with TBL on this
TVR: It's state that makes things
different
... Repeatability of actions, whether its on-screen, by user,
or not, is what matters
NM: Yes, we need to be careful about our definition of Interaction -- it's not just user->machine
SW: What should we focus on at our next f2f?
DO: Versioning and Web2.0
SW: If we did WebArch 2.0, what would be in it
TBL: Norm&I should finish our doc, that would be a start
HST: Add self-describing web and xml functions
SW: What about our public face?
HST: I'd like to carry the summary I did forward, but I don't have the time to commit
TBL does whiteboard and DanC projected editing of possible ToC for WebArch Vol II
<DanC_lap> possible ToC for WebArch Vol II
HST: The Interaction topic reminds me -- another way in which WebArch is not complete is that we can no longer treat "User Agent" as a simple cover term -- the more interaction there is from a page, the less what a browser presents is available to crawlers, indexes, etc.
NM: That's close to something we did cover in the Least Power finding
TVR: Not much thought is going into what is visible and what isn't
<Zakim> DanC_lap, you wanted to note "unobtrusive javascript" good stuff from WAI/weblog world and to note that some crawler vendors are looking at javascript runtimes to combat fraud/spam
DC: The basic principle of
"unobtrusive javascript" (?) is that things should still work
if script is turned off
... Sometimes you're just dead in the water
<raman> http://onlinetools.org/articles/unobtrusivejavascript/
<raman> http://www.google.com/search?e=StructuredResults&q=%22loading+%2E%2E%2E%22&num=25 says Web Results 1 - 25 of about 336,000,000 for "loading ...". (0.11 seconds)
<Zakim> DanC_lap, you wanted to note that some crawler vendors are looking at javascript runtimes to combat fraud/spam
DC: Crawler adding javascript engine, to get past innocuous static HTML to the script-generated e.g. porn spam
TVR: Indexers can't afford to run huge amounts of script to get at the material to index
HT, DO: Encouraged by DC's draft ToC
DO: It won't last, but it's a good start
NM: Really mean package this in a
separate volume
... goal is to serve the customer, not to recapitulate our
history
... One volume or two is a decision for later
<DanC_lap> Unobtrusive JavaScript
<Zakim> DanC_lap, you wanted to think out loud about tactics
HST: Similarly, as in WA1, we don't just dump findings in to a document, we summarise and hit highlights of findings which are still published elsewhere
TBL: Dependency diagram is a very useful tool
SW: DC called it a "How-Why" document?
DC: Each arrow is Why in one direction and How in the other
<DanC_lap> timbl drew a how/why diagram on the board. noah takes a photo.
DC: It would be good to have an
editor for this document, so it took on some reality
... E.g. NDW
[General approbation]
NW: I'll give it a try
<DanC_lap> [oops; growing list of things to say]: * group home page (move history) * link to ht's summaries * issue tracking garbage collect, tools * education business model * community/trust experiment * semantic mediawiki
HST: I produced a one para summary of all the areas of current TAG activity for an online mag. -- it would be a good thing if that were prominently linked from the home page and kept up to date
DC: I might try to take that forward a bit
http://www.ariadne.ac.uk/issue51/thompson/
<Norm> I observe that several of us have blogs; if we agreed to use a particular tag (no pun intended), we could aggregate one automatically
SW: I'm very unsatisfied with the way I have to work to maintain the issues list, editing raw XML -- I'd like a forms-based interface
<DanC_lap> yes, aggregation looks cost-effective
SW: There is new support for home page + issues list maintainance from W3C, maybe we should move to that
TVR: We should have a blog, to allow TAG members to write down useful small conclusions
DC: I should take the current
page and reduce its weight, to make it more useful for the TAG
as it tries to do its work
... I'm certainly prepared to look at GCing the issues list and
porting it to Tracker
... Education materials -- W3C is looking at this as a service
which would generate revenue, might look at this
... Would like to try semantic mediawiki some time. . .
RL: +1 to mediawiki
DC: Should we use Technorati tags for the TAG and aggregate from e.g. NW and DO's blogs?
NW, DO: Yes
<DanC_lap> (I don't mean technorati per say; I mean rel="tag")
DO: Blogging is a real
opportunity, we should be doing our business in a more Web2.0
fashion
... recapture the community's interest in what we're doing
RL: Agree we should upgrade our
tools/web resources -- very hard to find things. I've used and
like Tracker
... Prepared to contribute some time
NM: If we do a blog, we need to look very carefully at what it's for and how we use it -- is it for carefully considered and even approved formally, or is it just for as it were scribbling, more like www-tag
SW: We could use it to address the 'not much came out of this meeting/telcon' problem?
NM: Would I show stuff to the TAG first?
NW: No -- just as if your
personal blog
... in principle no different from aggregating wrt TAG tag all
our personal blogs
NW: and of course we don't all have personal blogs
SW: Musings vs. pronouncements
<DanC_lap> Using RDF and OWL to model language evolution
<DanC_lap> Submitted by connolly on Wed, 2006-02-15
<DanC_lap> ^ a blog item I wrote coming out of a TAG ftf
<DanC_lap> Web Architecture and Quality: closing the loop October 11, 2006
<Stuart> http://www.ihmc.us/users/phayes/PatHayes.html
RL: I will do some rewrites based
on the input I got
... There were some open topics wrt return codes, clarifying
the http protocol
DC: Are you prepared to edit in that direction?
RL: Probably, but it depends on the extent and direction of any additions
DC: I'm attracted by the idea of
looking at something from the customer perspective, what advice
do we give to people who want to name things
... Does the current draft do this?
RL: Yes, but it's not the headline
DC: I could get behind either explaining our original decision or giving guidance about choosing names
TBL: I can only go with 'the original decision' unless we expand to cover at least 301 and 302
SW: I think the title is wrong --
the HTTP spec tells us how to dereference URIs
... Email thread on www-tag is useful, maybe
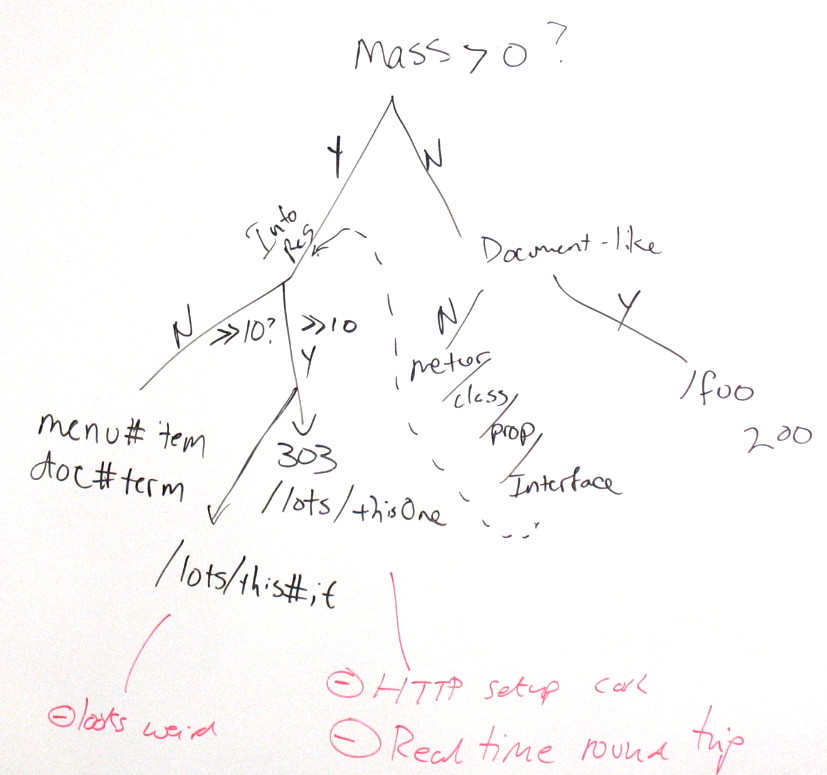
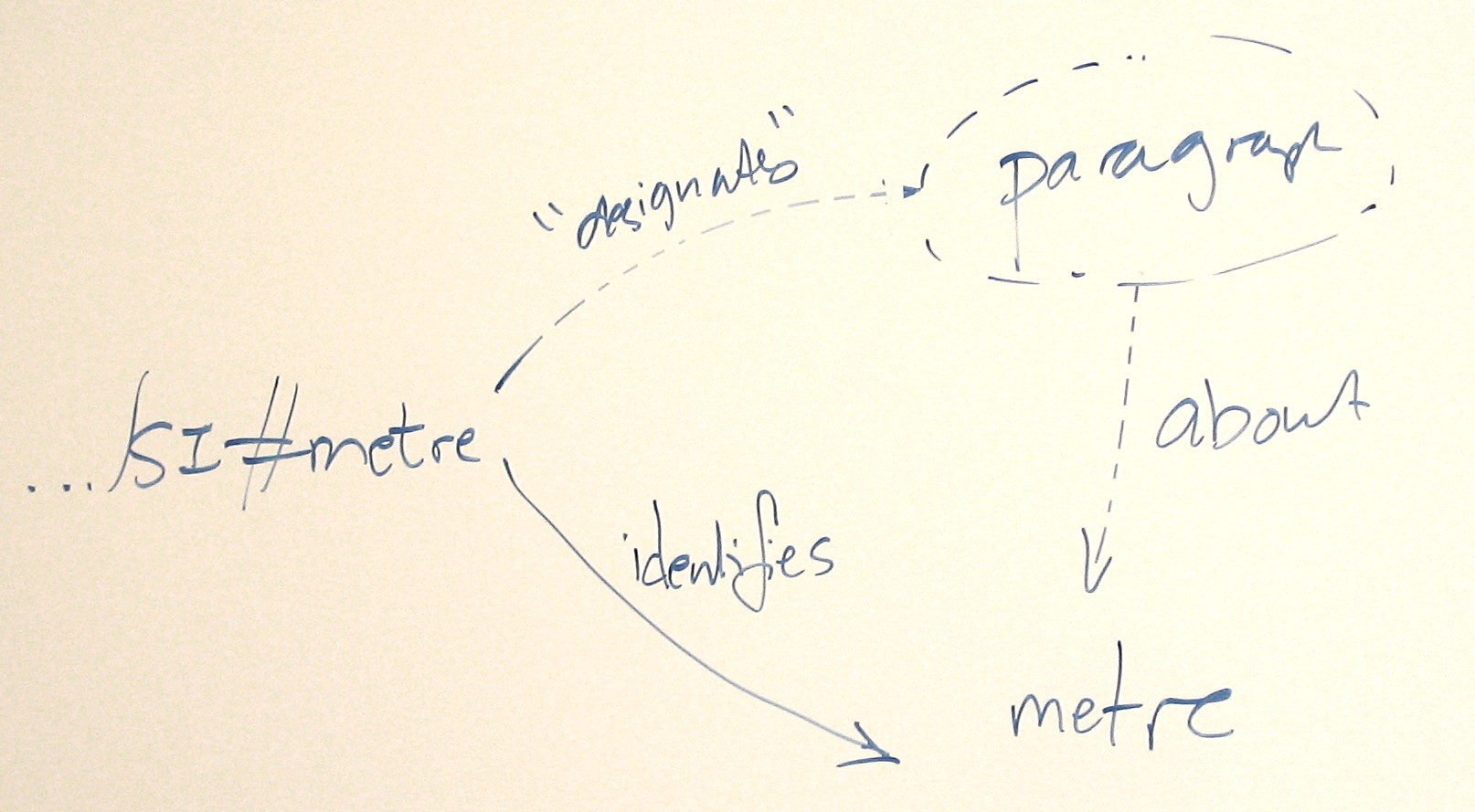
HST: I liked the point that a 200 response code _asserts_ that the URI identifies an information resource, it doesn't _make_ what it identifies _be_ an information resource
DC: [decision tree for giving URIs to things]
SW: Back to the email thread -- the snapshot of the state issue is interesting. . .
http://lists.w3.org/Archives/Public/www-tag/2007May/0058.html
[the URI/URIref distinction brief rathole]
DC: (and TBL) corner cases wrt
information resource: e.g. integer, WSDL interfaces
... Document vs. Information resource
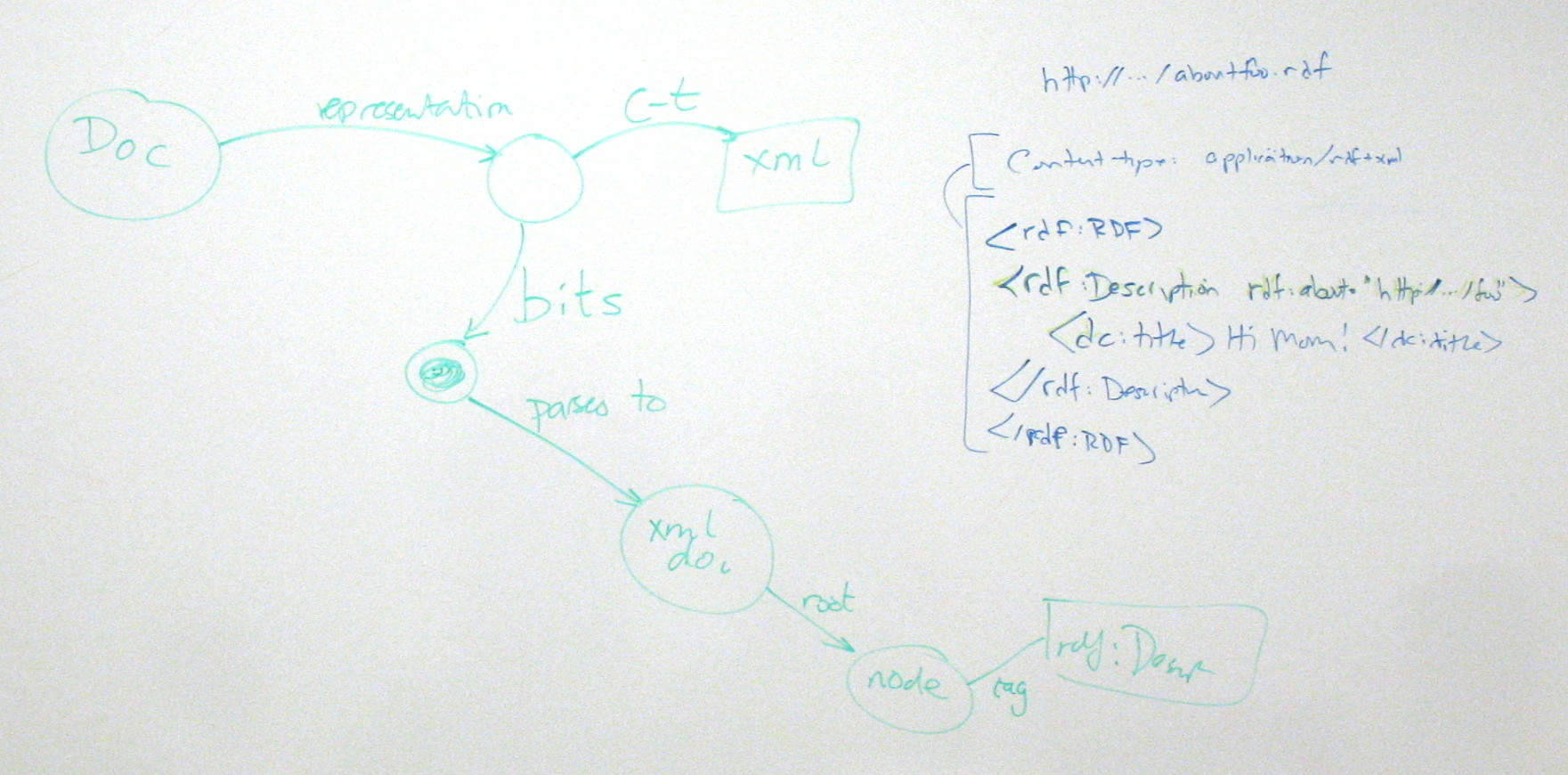
TBL: RDF graph is not a document
NM: But we can convey the essense of a graph in a message
TBL: It's the same as the difference between a document and a parse tree
HST: Back to the units example -- http://www.example.org/.../units -> application/rdf+xml -- identifies what? An RDF graph?
TBL: no -- identifies the document == the information conveyed by that RDF graph
SW: Two meanings of 'document' -- got to be careful about that
NM: The last chapter definitely comes after the first, but that's not true about e.g. rows in a DB
HST: That's SW's point
DC: So this brings me back to the
question of when you can return 200
... What about individual XML elements, e.g.
"<q>....</q>" ?
... [disagreement among DC, TBL, HST]
HST: In DC's picture, the
'document' in "Document-like" is document-sub-1 -- something
linguistic, in other words
... No, that's wrong, because that appears to descriminate
against e.g. image/jpg or audio/mp3, which we shouldn't do
TBL: So I think it's clear that classes and properties are not information resources
SW: Norm's document [photo here?] is an information resource. What the status of the subject of the RDF description therein is a different question
DC: I don't agree wrt class and
properties -- I have counterexamples in mind
... In summary, when it's clear things are/are not information
resources, name them as you like and return 200/either package
them and use # (and 200) if there are a modest number, or name
them individually and do the 303 thing
SW: I'm not sure about what the GRDDL case is, but does the same question arise with client-side application of a stylesheet?
NM: How does this raise a question?
DC: As HST asked yesterday, the question is how/why do same-document URIrefs work (e.g. href="#foo") in stylesheet output
NM: Simple case: HTTP GET, 200,
media type is well-known, fragids identify secondary resources,
all cool
... Harder case -- HTTP GET, 200, media type is xml, there's a
stylesheet, result of ss application seems like a different
media type, so we now have something rather different than the
message
<DaveO> I asked about the relationship between the "many things" case tying into Web 2.0 with many "embedded" things..
<DaveO> And particularly, does this guidance apply to Web 2.0 things like Google maps
DC: Not the same as the GRDDL case, which is, does #jackson refer to the HTML paragraph or the baseball player
NW: I tend to think of fragids as
identifying something 'in' the document, but of course e.g.
Google Maps could have a very small Javascript document whose
URI was, say, .../map, and the code interprets a fragid to
focus on any point in the world
... The WordNet bug is what we want to avoid, namely,
retrieving all of WordNet in order to deal with
.../wordnet#democracy
TBL: If DC's proposal involves a title change, I'm opposed to the change
SW: My understanding is that it does
RL: I wasn't planning to make a title change yet
<Noah> Note that six photos of diagrams from the whiteboard are now available on the Web. Yes, for uninteresting reasons, the first one has an extension of uppercase JPG and the others have the friendlier jpg
<Noah> http://www.w3.org/2001/tag/2007/05/TagThursDiagram1.JPG
<Noah> http://www.w3.org/2001/tag/2007/05/TagThursDiagram2.jpg
<Noah> http://www.w3.org/2001/tag/2007/05/TagThursDiagram3.jpg
<Noah> http://www.w3.org/2001/tag/2007/05/TagThursDiagram1.jpg
<Noah> http://www.w3.org/2001/tag/2007/05/TagThursDiagram2.jpg
<Noah> http://www.w3.org/2001/tag/2007/05/TagThursDiagram3.jpg
RL: and was not planning to fill in more wrt 301, 302 etc. yet
<Noah> ARGH, those are wrong...trying again:
<Noah> http://www.w3.org/2001/tag/2007/05/TagWedDiagram1.JPG
<Noah> http://www.w3.org/2001/tag/2007/05/TagWedDiagram2.jpg
<Noah> http://www.w3.org/2001/tag/2007/05/TagWedDiagram3.jpg
<Noah> http://www.w3.org/2001/tag/2007/05/TagThursDiagram1.jpg
<Noah> http://www.w3.org/2001/tag/2007/05/TagThursDiagram2.jpg
<Noah> http://www.w3.org/2001/tag/2007/05/TagThursDiagram3.jpg
TBL: I want to cover the space of response codes (and sequences of them)
DC: Why should this include 301 or 302?
TBL: because I need to know what cases my code needs to deal with
<DanC_lap> (ht, which of the .jpg's above is the proposed table?)
Table is from yesterday
I haven't looked in yesterday's log yet to findit
<DanC_lap> the table seems to be http://www.w3.org/2001/tag/2007/05/TagWedDiagram2.jpg ; the cells are blank.
<DanC_lap> I'm OK for TimBL to take an action to write it up, and we'll review it.
<DanC_lap> ok I'm OK for rhys to give it a try
<DanC_lap> Diagram3 has some stuff.
<DanC_lap> IH: perhaps: good practice: design a language so that revisions to the language don't cause problems for user agents
<DanC_lap> Scribe: Dan Connolly
<DanC_lap> ScribeNick: DanC_lap
IH stops by
IH: perhaps: good practice: design a language so that revisions to the language don't cause problems for user agents
taking a look at http://www.w3.org/TR/webarch/#pr-version-info
DO: so perhaps the version
information technique should be subordinated under "plan for
extensions, compatibility... "
... this section of /TR/webarch resulted from a snapshot of the
versioning finding from years ago; the versioning finding has
come along way since then; perhaps there's a better snapshot to
take from
... we could update /TR/webarch or publish separately or
whatever
NM: so re version identification,
we're not defending the webarch/#pr-version-info strongly as
written
... right?
(many nods)
TVR: if we had a blog...
DanC: we can get one for the cost
of a request...
... to the systems team
(NM got some clarification on writing a blog item after review by the TAG; DanC needs a few more parameters before requesting a blog get set up)
DO: I'd like us to follow up on the details of the versioning techniques... costs/benefits...
NM: do we have an errata process?
http://www.w3.org/2001/tag/webarch/errata.html
DO: putting it there isn't
enough
... I'd like to put it right in /TR/webarch ... but maybe it's
not worth the cost of a WD
<scribe> ACTION: NDW to note a problem near webarch/#pr-version-info in the errata [recorded in http://www.w3.org/2007/05/31-tagmem-irc]
<scribe> ACTION: NM to draft a blog item on possible semantics of version identifiers for review and, pending creation of a TAG blog mechanism, post it [recorded in http://www.w3.org/2007/05/31-tagmem-irc]
DO: continuing discussion of section 2.2.2 Forward Compatible ... I ack concerns around "processing model" in the Good Practice note
NM: "ignore what you don't understand" removes the possibility that unknown tags might appear in the DOM
<dorchard> HTML 2.0 says markup in the form of a start-tag or end-g, whose generic identifier is not declared is mapped to nothing during tokenization.
NM: if you'd written the "ignore tags you don't understand" part of the HTML spec knowing the TAG versioning teminology, let's think about how you'd do it...
<dorchard> HTML 2.0 also says ".. the installed base of HTML user agents supports a superset of the HTML 2.0 language by reducing it to HTML 2.0:
http://www.w3.org/MarkUp/html-spec/html-spec_4.html#SEC4.2.1
DO: the HTML 2 spec follows this model quite closely... it gives a substitution model...
NM: but this isn't the only way to do it...
DC: this has happened before... these good practice notes are being read as applying in all cases, where it's clear that you (DO) meant them as menu options
<Norm> Ok.
NM: the semantics you define for every [lots more words that made the scribe forget these]
<dorchard> IH makes the point that the "text" case is actually a very small case, it's always generated by code, no "document" or "text"
IH: question... what's the audience? spec authors? [yes] what's a text? [sequence of characters] well, the HTML5 semantics hang on the tree, not on the texts. we don't always even have a text
DanC: but you have to say what happens when you start with a text, right?
IH: yes, but that's more of a corner case
DanC: you've got a harder problem than the one we're advising on so far
NM: yes, synthetic infosets matter, etc.
IH: there are some DOMs that can't be serialized. [SKW: example?] a comment that contains two dashes in a row. a table inside a p
NM: while the case of no network connection, totally synthetic DOM is important, we've been focussed on the large scale case where text comes over the wire
HT: while using character sequences vs abstract syntax is somewhat arbitrary, I don't think much of this would change if we switched to abstract syntax
[missed some]
HT: consider <banana>...</banana> ... with style...
IH: yes, it's gets styled
NM: that's why I don't like the substitution model as a "MUST"
DO: ack.
TimBL: [missed]
<Zakim> DanC_lap, you wanted to suggest that readers are going to need more of a story/example for 2.2.2... (terminology has the story, but I'd like that to be inessential)
DO: reasonable suggestion
<Zakim> Rhys, you wanted to say its not a must ignore, its a substitution rule
DanC: hmm... not clear...
<Zakim> dorchard, you wanted to propose some rewording during a break
DO: concerning 5 Identifying and
Extending Languages... stipulate "A fundamental ... determine
the language" needs work...
... perhaps I should move some of [this material in section 5]
up?
... I could try a edit in a break
DanC: sounds good; how about skipping to section 3 for the remaing few minutes before the break
DO: stipulate in 3.3 "substitution... required..." needs work.
SKW: I wonder if these are requirements...
HT: "Candidate" requirement...
DO: makes sense... s/Can ...?/ to
/.../
... [summarizing the draft] it continues with a dozen or so
requirement questions, then raises design questions, then
surveys several languages showing how they answered the design
questions.
DanC: consider moving one of them up
DO: or carrying one of them... maybe HTML... thru
[BREAK]
<Norm> scribenick: Norm
Reconvene
DO: I did a quick rewrite of 2.2.2, Forwards Compatible
<Zakim> DanC_lap, you wanted to note that <img> is a pretty bad example of forward compatibility
DC: The alternate text should have been content, not in an attribute
DO: I like it because it's not tokenized if the img isn't recognized
DC: Users don't like to have images ignored, they want to see the alt text.
DO: I'm talking about HTML 2.0.
NM: This is what I was trying to say before: there's a question of what information is available and what the application expectations are.
DC: It's a bad example of
extensibility.
... The strong tag is a better example
DO: Maybe img isn't a good
example of a system, but it's a good example of a particular
set of choices
... We can point out the flaws later.
DC: I think img is a much better example of backwards compatibility
NM: I'm a little concerned about
the first GPN: fowards-compatibility requires extensibilyt
rule: Any language intended for forwards-compatible versioning
MUST have extensibility.
... But Henry provided a counter example yesterday: a language
that gets smaller.
... Ten features become five; and that first language had no
extensibility model.
... I think you have to change from any to most.
DO: I'd like a MUST
DC: Don't say should or must, say "this is a pattern that is known to work well"
HT: If you anticipate your language evolving by adding new features, then you need an extensibility rule.
<DanC_lap> (agenda request, sorta... I started exploring an alternative set of definitions that re-package the accept/defined stuff. I didn't really finish my exploration, but folks might find it interesting. I guess I should have showed it to Noah during a break. I wonder if it's worth meeting time)
DO: WS-Security does not allow
for forward compatibility; it allows extension but says you
must fault if you don't understand the extension.
... And you need to say both parts; you have to provide
extensibility *and* you must say what it means when one is
encountered.
NM: Many languages are understood
in terms of "the stuff I understand" and "this other
stuff"
... Ian's earlier example of "banana" tags was a good example.
They get added to the DOM, they get styled by CSS. Etc. I could
have said that *all* these tags were in the language.
TV: When browsers implement XBL, this will get even more interesting. You'll be able to provide both style and interaction.
DO: It feels different to
me.
... I think when people think about extensibility, they think
about designing a language with the things that they know and
they say very little about the other stuff.
NM: Part of our role is to educate people; if what we discover with CSS and XBL is that you might be fooling yourself, it's more subtle than you think. We should think hard about telling that story.
TV: This is not much different
from moving code around.
... You can say anything is allowed, then you can say that only
three namespaces are allowed, etc.
NM: Bananas can be styled differently from Peaches; they aren't strictly synonyms.
DO: So items in the accept set, not the defined text set, may have a certain amount of processing associated with them.
NM: We're going in circles.
SW: Two questions: 1. do we have
a test for "MUST have extensibility"? Can we tell if a language
does or doesn't have extensiblity? And 2. what about any
language?
... We've been talking about HTML 2.0 as a language and HTML
3.0 as a language, and also an abstract language called HTML of
which HTML 2.0 is a version.
<dorchard> Definition: Extensible if the syntax of a language allows information that is not defined in the current version of the language.].
<dorchard> from versioning
<dorchard> prefix with Languages are defined to be
SW: I asked if we have a test. Is that a test?
DO: HTML is extensible because banana isn't defined but it is allowed
NM: I'd approach it differently:
I'd say they were all in the language but it's extensible if a
more interesting definition can be provided later.
... For example, he allows bananas and he allows CSS styling.
What could he do next?
... Would it be compatible if they were changed to being block
by default?
... I think you have to look at the individual languages to
answer some of these questions.
... It seems to be that we can add attributes to existing
elements which is also a kind of extensibility.
SW: My second question was about "any language". It seems to be talking about a family of languages.
DO: I meant any in terms of any language that you might want to design for forwards compatibility.
SW: Ok, I see what you mean
DC: I started exploring an
alternative set of definitions that re-package the
accept/defined stuff. I didn't really finish my exploration,
but folks might find it interesting. I guess I should have
showed it to Noah during a break. I wonder if it's worth
meeting time
... Nevermind. I don't have the bits.
... It's on another machine.
SW: Worth going further?
NM: I'm starting to feel a little overloaded, I wouldn't like to think this was my last chance to comment.
SW: We could look at the XML piece, or we could look at the tag soup work that Henry has been doing
<scribe> ACTION: NM to write up his paper comments on extensibility and versioning [recorded in http://www.w3.org/2007/05/31-tagmem-irc]
HT: I thought instead of telling
the HTML WG that they should describe HTML 5.0 declaratively, I
should just do it myself.
... I think what we want is "formalized tidy", but tidy is just
a bunch of C code.
... John Cowan's tagsoup is as close as we get.
... Tagsoup consists of two parts: a table driven scanner
(tokenizer). It has a fairly nice declarative interface.
... The scanner includes some ability to do fixup.
TV: I second what Henry says; I've looked at the code and it's very nice.
HT: The second thing you get is
an improved sequence of angle brackets and text but not yet a
balanced set of start/end tags.
... The second half of tag soup as its written takes a fairly
complicated description of the language, in terms of ancestry
and other things, which leaves out a bunch of stuff (like
cardinality and sequencing) but adds a bunch of other
stuff.
... And doesn't expose the connection between where you are and
what you do for recovery. They're welded into the code.
... It recognizes a half dozen kind of problems, but the
responses are welded in. I wasn't terribly happy with
that.
... I wanted to expose the fixup rules.
... The markup for this is called PYXup which is something like
the ESIS output from sgmls, if you remember what that
was.
... Tagsoup can be told to simply output the pyx stream instead
of performing the fixup.
Some discussion of the examples from Henry's Extreme Markup Languages 2007 paper
HT: I can reconstruct all the things that tagsoup does with this model
TV: One question to ask is what
happens in cases like
<table><form><tr><td></form><td>...
... What's your goal? To make something that's valid or to make
something that mirrors the behavior of current browsers.
HT: It has to be the latter.
TV: Right. But if you look at the test cases, you'll find that you don't get a well-formed DOM in some of these cases.
HT: There's no question that the current code doesn't do enough. The trick, I think, is to allow the recovery actions to be sensitive to annotations in the grammar. Table and form are good examples of cases where you need annotations.
TV: In the HTML discussion this
is tangled up with the script processing.
... The folks who don't want declarative rules just don't agree
with some of the results that the fixup does, particularly in
the case where script mangles the DOM.
... TeX has done a better job of this because you can change
the \catcode of characters.
... In some sense, this is what script is doing. Knuth
describes this in terms of the mouth and the throat and the
gullet.
... So some changes occur in the "mouth" so they don't get down
into the "stomach".
... The whole formalism argument is going to be thrown out
unless script can be addressed.
HT: I don't feel too worried
about the 90% case of scripting because what the fixup works
with is a string of start-tag/end-tag tokens.
... If you recognize the start script tag you can hand over
tokenizing to the script engine.
TV: But you also need to provide the token stream you've already seen so that script can munge it.
HT: Right. That's not the 90%
case.
... Ian objected to "scripts must produce balanced tags", but
my next question would have been, can you live with scripts
that don't change the preceding tokens.
... What I heard Ian say was, "if two browsers do it" it has to
be in.
TV: They are caught in a hole.
Some more casual discussion begins...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}