See also: IRC log
Morning scribe: Noah Mendelsohn
NW: I am unlikely to have 90 mins worth of material on namespaceDocument-8.
HT: If we have time during the versioning discussion, I could discuss my progress on a more declarative implementation of the TAG soup tool. This would be a sort of "technology interlude" in the discussion.
SW: Maybe at lunch tomorrow.
... Note regrets for all of Friday for Norm.
... Let's consider minutes of 21 May at http://www.w3.org/2001/tag/2007/05/21-tagmem-minutes
DC: Can I edit in the link to Noah's old email after approval?
ALL: Yes.
RESOLUTION: The minutes of 21 May 2007 at http://www.w3.org/2001/tag/2007/05/21-tagmem-minutes are approved.
SW: I think we've got firm dates for Southampton F2F. You can count on the dates.
RL: Would like to know who is local arrangements coordinator.
SW: I'll check. Any interest in extending a 3rd day, presumably without Tim, and if so is there a facility where we could meet.
NW: I'd like to get a train that afternoon.
HT: I'd like to get home that night.
TVR: It's not clear I'll make the meeting at all, if I come 3 days is OK.
<scribe> ACTION: Noah to check on Hursley hosting of a 3rd TAG F2F day. [recorded in http://www.w3.org/2007/05/30-tagmem-irc]
SW: Note tech plenary in Boston week of 5 November.
NW: We need to meet with others there.
SW: I'll send notes to chairs saying we'll be there.
HT: The AC is meeting separately only for 1/2 day, the other day is AC at Tech Plenary.
TVR: We may need to play this by ear. We should hold a room for the TAG for the half day of the AC, and decide based on the agenda when to be in the AC.
SW: Am I hearing a half day meeting on Wed.? I like the idea of bracketing the week, but the Sat. is a problem. How about 1/2 day Monday and Friday?
HT: I'd rather have the TAG meeting on the Thurs.
SW: Tim would probably have to be at AC.
HT: Indeed. Withdraw the suggestion.
SW: I'll go for 1/2 day Monday, 1/2 day Friday.
Latest draft of TAG finding: http://www.w3.org/2001/tag/doc/URNsAndRegistries-50
Henry is about to present the slides at: URNsAndRegistries_notes.html
SW: Henry, you said our goal should be to reconcile the two parts of the draft finding.
HT: I tried to step back and take a fresh look at this.
... Let's remember some pertinent quotes from the Web Arch document.
... It strongly urges the creation of URIs, but unfortunately does not say http URIs, which is clearly what it means.
Several: really?
HT: Because, the discussion around it is about retrieving representations.
TVR: Does scheme tie to protocol?
NM: We have an open issue on that.
TBL: That was broken when we created the appearance that the http scheme was tied to the specific HTTP protocol...we're trying to back out of it. The http scheme is fundamentally a namespace; the HTTP protocol is the current technology for looking up resources identified using that scheme.
NM: Would like to explain why the schemeProtocols issue is separate from the one we're discussing now.
DC: Please don't.
HT: From AWWW, "Global naming leads to network effects". The important point is that citations (scribe thinks Henry meant references using URIs, at least in the case of the Web) can successfully resolve from anywhere.
<DanC_lap> (he's at slide 4/9: Connection with "persistent identifiers")
HT: The TAG has a goal not just to protect the Web as it is, but to extend its reach and success
... The slides I'm showing leadto possible answer of "just use the http scheme", BUT, we need to ask, why do people keep hatching new schemes?
TVR: We have 3 puns, http as scheme, as protocol, and as namespace name.
HT: At very least, the namespace thing is not consensus. The TAG position is that you SHOULD put a document at the URI that is the namespace name.
... So, I felt I should change the document to focus on what appear to be the good reasons people don't want to use the http scheme.
... Leads to "there are good reasons you might want to use something other than http, but there are fewer such reasons than you may think"
... What are legitimate concerns? Seem to be three:
1) Dependence on DNS
2) Apparent lack of central control
3) Commitment to serve a representation (especially relevant for info:)
The real issues seem to be:
A) Trusting the proprietor
B) The core motive for positions that sometimes look like "not invented here" (NIH) to us so
C) Communities want to centralize with well known authority
<timbl> I see this NIH thing as being an artifact of the group/culture/language/boundary sociology in general
HT: So, info: has the appeal that you don't go through IANA to establish it.
... People seem to perceive their chances of reliably hanging onto info: is greater than info.com
DC: misperception
TVR: Some of the value is in just what you see at the head of the string.
HT: I looked into state of first dozen URI schemes and URNs in some specific registries.
... Fair number seem to have been abandonned as not well considered.
DC: Have you saved all that information? Very valuable information.
HT: Yes, planned as appendix.
TBL: Considerations for things like dx.doi.org seem different, since there is an >organization< that takes responsibility for the persistence of the identifer.
NM: Is the problem that you have to renew things like domain names?
HT: Yes, in part.
NM: Subtle, because in practice google is unlikely to forget to renew google.com, IBM is unlikely to forget to renew ibm.com. Still, it's a matter of perception.
<Zakim> timbl, you wanted to point out the possible actial lack of depenecy on the RFC.
DC: And also, even if IBM did lose ibm.com, they have a visible investment, probably trademark, etc.
TBL: I don't think they're that worried about the stability of the RFC registration process. One can imagine something like a legal entity just deciding to hijack a scheme in practice.
TVR: Interesting to look at what people did when there was less process. For a long time, people thought they needed to put www. at head of their Web site DNS name. They got there because they already had, e.g. ftp.example.com
<DanC_lap> I think Tim was saying that the U.S. Library of Congress has authority that's independent of, and perhaps higher than, the authority that the IETF/IANA has in RFC4452.
TVR: Not that psychologically different.
HT: IANA has defined process in place for contesting ownership of domain names, but that cuts both ways. Your DNS name could get taken away.
(See slides for more on proposed shift in strategy)
HT: The folks promoting info: are not using either http-scheme or URNs because they seem to want to actively discourage dereferencing, in part because they want to capture >legacy< naming schemes. It appears that the use case is one in which dereferencing is perceived as a negative.
<timbl> I was saying that the meaning of info:, like ibm.com, will easily come to have a social weight which exceeds the formal stability of the RFC document or domain name system. If the RFC was changed by the IETF without LoC's agreeemnt, LoC would just continue.
<timbl> Where do we find the list of info: subschemes?
HT: We can debate whether that conclusion about the desirability of dereferencing is a correct one.
TBL: In tabulator we use ISBN numbers, social security numbers, etc. as reverse-functional means of identifying things.
... So, what's the harm of formalizing such things under info:?
TVR: Someone who invents a browser widget that finds things based on Social Security Numbers is effectively building something resembling a URI.
TBL: In this case, the info: scheme seems intended to be non-threatening to those who would be worried if asked to provide lookup service.
NW: I see Dan's point, which is stop pretending they're URIs.
HT: Shows examples of lots of info: registrations, including interesting one for what appears to be an art collection.
... Seems very dereferenceable in principle.
NM: Is there possibly an httpRange14-like confusion? Maybe they misperceive that info: is for the framed pictures in the back room, and if they ever were to put digitized copies on the Web, then >those< would be the ones to get http-scheme URIs.
TBL: I think we should say that some of what's being discussed is doable, but is a different architecture. It's not the Web. There are many, many people out there proposing to reinvent parts of the Web like this. The point is that there's a real cost to doing so.
<Norm> ht_google, it appears that the site is down
<Zakim> DanC_lap, you wanted to talk about economic value and naming
TBL: I'd like to see some work on the persistence of DNS names.
HT: Henry and Dan Brickley have come up with the possibility of a workshop of the stakeholders with interest in long term survival of DNS names. Would the TAG be interested in, in some sense, sponsoring such a thing?
TBL: One possible result would be a new top level name.
<Zakim> Noah, you wanted to ask whether the downside isn't committing to non-dereferencability
<ht_google> http://info-uri.info/
<Zakim> DanC_lap, you wanted to concur with a workshop for marketing reason, but to disagrees with details (.org, gandi, ...)
NM: I would like to suggest that the finding include a balanced discussion of 1) to what extent is it a misperception that if you do use the http scheme you'll be under ongoing pressure to deploy something, vs. 2) if you use something else, like info:, you are making a gamble that you will never change your mind about wanting to be integrated with the widely deployed infrastructure of the Web.
DC: I'm not so convinced you want or need a new top-level domain. Some of the existing ones like .org may be appropriate if used right. It all comes down to whether people will pay to get the qualities you want over time.
<DanC_lap> (" The top-level domain, .museum ("dot-museum"), was created by and for the global museum community. It enables museums, museums associations and museum professionals to register .museum Web site and e-mail addresses. This, in turn, makes it easy for users to recognize genuine museum activity on the Internet." -- http://about.museum/ )
TVR: Rather than saying "don't invent new URI schemes", we might better say "here's how to know when to invent new schemes", with persistence being one aspect of the discussion.
HT: All the schemes and URN namespaces that were originally behind the creation of this issue, were specifically motivated by persistence.
TVR: It's hard to separate from the other reasons you might want to invent a new URI.
DC: Do you think that's happening here?
TVR: No, probably not in this situation. The risk is that external world would misperceive that we were advising on more than the persistence reason. If it's more complex, then let's deal with the more complex issue.
DC: Doesn't the current draft reference the broader discussion?
HT: Yes, it does mention the other discussion of URI schemes and protocols.
<ht_google> http://weibel-lines.typepad.com/weibelines/2005/11/for_your_info.html
"The "info" URI scheme is predicated on the notion that the current Web identifier architecture is incomplete, and will benefit from a commonly recognized mechanism that:
DC: But aren't they running Web sites to track which ones are used and which not?
HT: I doubt that's happening below the top level. Many predate the Web and are closed.
SW: Do you know where you're going next with this?
HT: I am going to try rewriting the first half from the perspective I outlined.
SW: Structure likely to be similar?
HT: Probably not.
SW: What about the lack of alignment between two halves of the document?
... Second half didn't use the setup from the first.
***MORNING BREAK***
Discussing draft finding "Dereferencing HTTP URIs" at: http://www.w3.org/2001/tag/doc/httpRange-14/2007-05-31/HttpRange-14
RL: Proceeds from the assumption that a lot of the confusion traces to people assuming that URIs are mainly for things that feel like Web pages.
... So, I built an example of RDF being used to discussed a unit of measure, which is a much more intangible abstraction.
... That sets up the discussion of representations of things, vs. representations of associated things. Also talk about packaging representations for several things together.
TBL: Don't you use the 303 for each thing?
NM: He's using #; only the URI for the combined resource is going through the wire, with the fragid being applied at the client.
TBL: (on white board) SI#metre
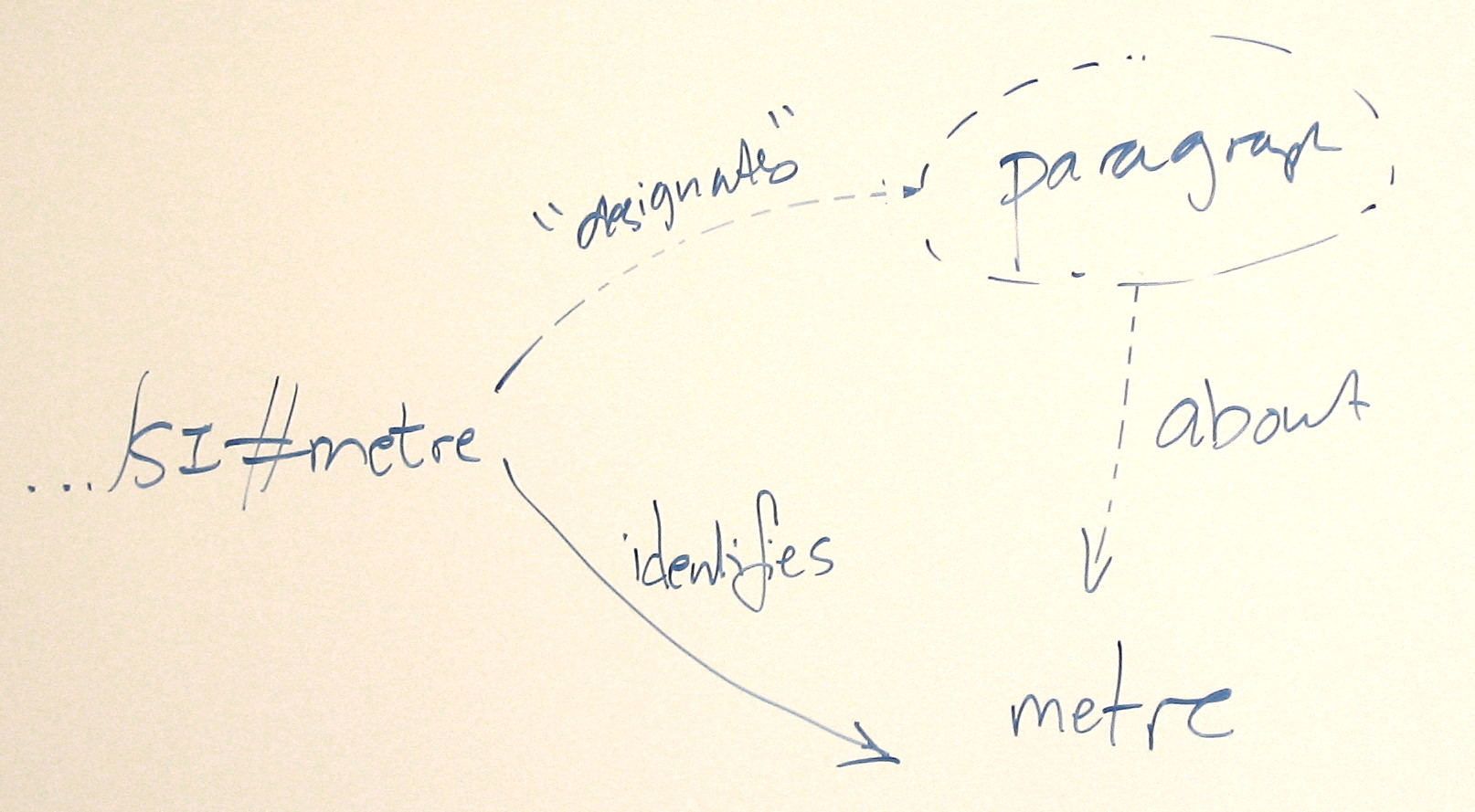
RL: I'm trying to avoid setting up Apache to 303 each one separately.
TBL: Starting with the example, what goes through the wire is just SI. You're giving a 303 on that?
RL: Yes.
TBL: But why? SI is a document with documentation about the various abstractions.
HT: But if it's a document, then why is SI#Metre not a subdocument?
RL: But in mine it isn't a document.
HT: But I'm trying to understand Tim's story.
TBL: Tell the story again.
... .../SI#metre
... Strips to /SI
... Get a 200 on that.
... Gives you a representation.
HT: What media type?
TBL: Say, application/rdf+xml
HT: How do we know about the individual concepts described?
<DanC_lap> (following my nose... got as far as ... http://www.iana.org/assignments/media-types/application/ )
<DanC_lap> (got to section 3. Fragment Identifiers of http://www.ietf.org/rfc/rfc3870.txt )
HT: RFC 3870 says, not super clearly, a story about how you can define things that can be referenced with fragids. The thing identified "does not necessarily bear any particular relationship to the thing identified by the URI alone". Refers to RDF concepts document for more information.
TVR: Given that media types play implicitly in all of this, why are they only one level deep with "/", and then the thing with the +?
TBL: The plus is just a convention?
DC: Accident of history.
... Do we agree that the 200 story is OK?
All: yes.
HT: Does the 303 story include....
RL: 303 story is two parts, one for no fragid, the other I found in an example. See email we just got from Leo Sauermann: http://lists.w3.org/Archives/Public/www-tag/2007May/0056.html.
SW: I read to the end, but it said nothing about the distinction between URIs with and without fragids.
NW: Whether to discuss here seems open. I don't think we've ever had debate about whether a URI with fragid can reference anything. The question is what the range is of things >without< fragids, so I'm not hugely troubled by lack of fragid discussions.
TBL: There can be performance problems doing a separate 303 for each term. Tabulator got slow when Dublin core went to 303.
RL: I think the rationale for giving a 303 on the base document was in part that.
SL: Can the local cache help you?
TBL: We're talking about the "no #" case, so you don't strip.
<RhysL> the mail points to a link http://www.dfki.uni-kl.de/~sauermann/2006/11/cooluris/
NM: I think the main point should be about why 200 is inappropriate for a non-information resource.
TBL: Yes, in fact you may be understating it. That is the point here, and should be the main conclusion of the finding: if you get a 200, that means you've got an information resource.
TVR: Can it change over time?
TBL: Yes, but that's not a story we need to tell. There are all kinds of subtleties.
DC: See AWWW, which emphasizes physical resources as being non-info resource.
TBL: Maybe we should add metre to arch doc?
DC: Unconvinced.
<Zakim> DanC_lap, you wanted to note that webarch doesn't say that units, e.g. meter are not information resources. it only clearly says that things with physical mass (people, buildings)
NM: Suggest that when you replace "metre" with something more tangible, you also be sure to make it something where it's really obvious why you'd like it to be the subject of RDF statements. I'm not convinced metre quite passes that test either.
TBL: Discussing http://www.dfki.uni-kl.de/~sauermann/2006/11/cooluris/
... Risk is confusion, when 200 is returned with HTML, about whether you're getting the document or what the document is about.
DC: Hmm. That's a problem? GRDDL does that. The TAG didn't comment.
<ht_google> http://www.rfc-editor.org/rfc/rfc2854.txt
ALL: Somewhat rambling discussion of whether you can get a 200 on HTML, and have a fragid refer to the concept described by the corresponding piece of the HTML (scribe doubts this quite got the subtlety).
HT: Is it OK for the referent to depend on the media type in the accept header?
SW: What guidance can we give Rhys?
RL: Q. Whould the finding address fragment ids?
TBL: A. Yes.
HT: A. Yes.
SW: Is there a terminology issue, since URI syntax includes fragids?
DC: With respect the question about fragids, my answer was "no".
HT: The email that motivated the issue was only about 303, and not about fragids.
TBL: If you're going to talk about the semantics of 303, we would be doing a service to also talk about 301 and 302. Surely you're doing 200, right?
RL: Yes, I'm doing 200.
TBL: e.g. if I get a 301 or a 303, does it imply what you'll get would necessarily imply you'll get a document? (scribe isn't sure how original statement by Tim parsed...sorry)
RL: Could be chains of 303 indirections.
TBL: I think 303 carries an expectation.
RL: Roy's email doesn't say that.
NW: I'd say if using 303 for this purpose, you should point to a document.
<DanC_lap> coherent options (that perhaps the chair will poll on): A: write a finding whose scope is bounded by the existing decision on httpRange-14 (which says nothing about #-uris) B: write a finding about httpRange-14 _and_ best practices for URIs for units of measure and cars [which involves substantial discussion of fragmentInXML-28 and perhaps the GRDDL case]
TBL: Any <img> tag establishes an expectation that there's an image.
<DanC_lap> (looking at http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.3.4 ... hmm... )
NM: Yes, but crucially, it does not make the referent an image. In the error case, it might not be. You might get another HTML page instead of an image. The story we tell is "The IMG tag was in error, in that it established an expectation that referent R would be an image, when in fact it proves not to be." Crucially, the <img> tag cannot make it be an image.
HT: I've had some concern about the notion that an RDF graph is an information resource, and that there is therefore a question of whether using 200 for application/rdf+xml is appropriate. But, on reflection, I'm now convinced.
... Have we said that?
DC: Yes, in Roy's mail http://lists.w3.org/Archives/Public/www-tag/2005Jun/0039.html
... But we have to make sure the finding captures that.
... si/meter redirects with 303 to si/meter/info
TBL: I conclude from the 303 that si/meter/info should be a document.
RL: What if it isn't?
NM: Tim and I went over that. It's in some sense a claim by the entity doing the 303 that it will be an info resource. If it proves not to be, then the 303 should not have been used.
NW: Not convinced. Have we said that --/love can't redirect with 303 to --/fondness
TBL: I would like that not to be ok.
NW: Why? It's a "see also". I'm saying if you're interested in love, you might also be interested in fondness. Why should fondness therefore be an information resource any more than love was?
TBL: (from earlier) when there's a chain of two 303's connecting three resources, the second 303 is expressing a relationship between the second and third resources, not in general transitively back to the first.
NM: Where do we stand on 303?
NW: Well, I could sign onto a TAG finding that says use it this way.
RL: But 303 means what the HTTP spec says it means.
TBL: We have to explain how this all works.
HT: If I fetch from si/meter with accept of application/rdf+xml, why shouldn't I return the length with code 302?
TBL: That suggests the URI can be used in the future.
NW: 301 - moved permanently, use the new one in the future; 302 - found, temporarily under new URI; 307 - Temporary redirect.
HT: I think 307 says show the user this URI.
TBL: Not sure how 302 and 307 differ.
TVR: What about HTTP vary headers? We talked about that in the generic resource finding.
HT: In that case, they all refer to the same resource, which in that case should be an information resource.
TBL: I want to set down this stuff.
HT: I've come to believe that the New York Times home page, which is very core to popularity of the Web, has many representations.
TBL: Conneg happens on 303's as well as 200s.
HT: I ask for non-info resource about city of Dublin, the 303 might give a different URI according to what the original accept header said.
... APIs wrap some of this.
DC: Yes, in fact W3C has a spec in last call.
HT: But that doesn't constrain, e.g. how Python, does it?
DC: Yes, indirectly, by establishing common practice.
... Think about 3 cases 1) Meter unit of measure 2) city of Dublin 3) GRDDL case (text html with fragid of baseball player)
... How many of these are in scope for this finding?
SW: I would have said first two, not last?
NM: Is the metre case making a different point than Dublin?
HT: Don't think so.
SW: Well, less clear cut whether metre is an info resource.
NM: I think Dublin vs. metre should be orthogonal to whether to cover # or not. Dublin is a better example of a non-info resource than metre either way.
... So, I propose we first decide whether to cover # or just non-#, then use Dublin (or something tangible) for whatever survives.
Tim is putting a diagram on the board, with status codes down the left, and two columns for each: what the request URI identifies, and what the returned URI identifies.

TBL: We need to say how the Web works.
DC: Aren't we changing the HTTP spec?
TBL: No we are formalizing it a bit.
TVR: Tim discouraged me from going into the time issue, but I need to.
TBL: I really don't want to talk about time.
HT: The rfc uses SHOULD in refer to obligations for the future.
<raman> Minutes: T. V. Raman
Early afternoon scribe: T.V. Raman
<DanC_lap> Stuart: so looking at the collection... opinions on how to move it forward?
<DanC_lap> DO: I don't hear many "you're missing X" comments lately... have we got a bound on scope?
<DanC_lap> DanC: trying to remember some "you're missinig X" comments... Relax-NG? OWL/RDF?
<DanC_lap> DO: I haven't written about those. but other than that, I'm fairly confident.
Supposedly scribing here but having a hard time deciding what to write
Summary of discussion around scoping of XML Versioning document.
Avoid further feature creep, add explanation where needed, but be aware that adding more explanations might also raise more questions.
tvr: suggestion: reach closure on parts of the finding, rather than waiting fo rthe whole
DanC: is it just about syntax? clearly meaning of an element does come into it.
tvr: version can have 3 interpretations: lang:foo version:bar 3 variants: as specified by lang designer, as generated by producers, and as interpreted by consumers.
DaveC: The definition in the terminology section works, though at present it's a 2 part definition.
tvr: how far down tag soup land do we go with respect to accept set of a language --- as an edge-case: what do we say about self-modifying content?
NW: put cones around that hole and dont fall into it
discussion around definition of backward compatibility in terminology section.
<DanC_lap> TVR discussed implementations that have 1 codepath to grok v.n+1 that as a matter of course groks v.n, vs having a switch
<DanC_lap> TimBL gives XHTML as an example.
<DanC_lap> (hmm... I'm getting there, but not sure I get it... if I get it, it's orthogonal to the definitions)
TimBL: points out that backward compatibility can be defined based on how one gets there via implementation --- consumers saying L+1 == L +L' vs L+1 must directly consume both L and all parts of L' on a single code path
<dorchard> I think there's a software design question about where the "re-use" is, and which is where and how many "switches" are there.
<Noah> NM: I just noted a few things about the Example 2 diagram, as suggestions...
<Noah> NM: 1) You could more clearly indicate that its the languages, and/or particular texts that are what you're referring to when the diagram says "Forwards compatible"
<Noah> NM: 2) The running text might already say this, not sure, but there is an opportunity to say "by the way, if language N+1 includes all of language N, and with all the same mappings to information, then it follows that we have backwards compatibility"
tvr: another example of graceful degradation getting confused with backward compatibility of languages is the difference between introducing attributes vs new elements in XML based languages. Also, observe that it's not just because of structure playing a role, in the microformats world, attributes carry structure.
DO: Might be an indication that the microformats world will have issues of versioning as it evolves
<DanC_lap> (re "microformats might run into versioning problems", their approach is to just stipulate to that, and manage it sorta centrally, i.e. in "everybody talks to everybody all the time" fashion)
Scribe for remainder of day: Tim Berners-Lee
<timbl> scribenick: timbl
[reconvene after break]
Scribe for the following is Tim.
<DanC_lap> DO: ah... good point, Noah... semantics/information
<DanC_lap> ... and connection to terminology
NM: This drops into XML sometimes without much of an explanation.
DC: To what extent is 1.1 'argument by assertion'? Do we present evidence alter? 'It is almost unheard of' etc
NM: I felt the same.
DO: I didn't do a survey .. it is anecdotal.
DC: (Though no actual anecdotes either)
<DanC_lap> (I could live without 1.1 Why Worry About Extensibility and Versioning? )
NM: Many languages just get set and never are revised.
NW: The atom folks say they will never change Atom.
NM: How about 'many languages'?
DC: How about getting rid of section 1.1? Or all except the second-to-last paragraph?
NM: That could become the last para of 1.2.
DO: This section [1.1] gives the motivation for this. The point about keeping languages small is not made anywhere else.
NM: Suppose you keep your existing part 1 and then go into a section on why language change... to me it would be tighter and get to the point. I wouldn't miss [1.1]
NW: I don't object to losing it
NM: 'Component' is defined in part 3 now. This is all discussing XML, but we're still in part 2, which I thought was more general. Have we turned this all into an XML discussion? We need to say generally that languages are texts and can change. Many languages we talk about have some markup substructure. A lot has to deal with how the markup evolves. Maybe in 1.3 we should say that a component is markup.
DanC: There is a reference to the defintions ... but suppose you don't follow them and use a general dictionary. It still works, I think.
... if you were relying on the given definition, I would want it bolded or something.
... Here you could change 'components' to 'parts' even
NM: We could say "here we use XML as an example"?
TBL: I think that the way the components combine in, say, RDF is totally different from for a Markup language. There are several different forms of language.
DC: When I see XML I skip over it and the rest works for RDF here. 'Allowable content may include additions or deletions', for example.
HT: 'Terms' is not defined in the second para, but otherwise his works.
NM: I agree with Tim, and had the concern that section 1.3 doesn't really give much useful guidance for anything other than XML/markup languages. I'd prefer to see it add some insights on those other languages.
<timbl_> I would like to see a hand-off to a future 'versioning RDF-based systems' document
<DanC_lap> HT: 1.3 could perhaps start "One of the most important aspects of a change is whether or not it is backwards or forwards compatible."
<DanC_lap> (after 20 seconds of thought, I prefer it as is.)
http://www.w3.org/2001/tag/doc/versioning-strategies-20070518.html
[discussion of the sections 1.1-1.3 seems to settle on a conensus more or less with it as it is]
adding optional components (e.g. elements and/or attributes, or classes and properties)
^ suggests
NM: How about adding under "Some typical incompatible changes:" adding "Adding new components which change the semantcis of existing ones".
... ... For example, "If this doesn't work, then none of that happens"
TBL: Many languages non markup-like have a form of compoents, such as RDF graphs which have ontology terms, or C which has a generic syntax but a set of library routines, etc. Not only XML.
DC: 1.4 also defines this in a way.
NM: Any merit to moving 1.4 ahead of 1.3 (and maybe ahead of 1.2) to set up the types of languages, which could lead into definition of component?
[moving to 1.3.1]
<DanC_lap> DanC: in 1.3.1, is "instances" useful in "The primary motivation to allow instances of a language to be extended" ?
NM: What does "changing instances" mean?
SW: I think it means changing set of possible instances [in 1.3.1]
NM: We are talking about the thought processes of those involved?
DO: Specifically the decentralized process.
NM: Do we need to distinguish instances from texts, or just say texts?
DO: texts.
<DanC_lap> (yes, I'd be happy to never use "instance"; "text" works for me.)
NM: I think 1.4 misses the opportunity to talk about the recursive nature of this when text is nested within markup and markup nested in text, so the whole versioning applies recursively.
TBL: Say 'embed' of elements before 'recursive' of languages.
NM: Suppose I have a story about a document about colours , red, blue, green... [missed] now the finding is writing mainly about documents and markup .. but the attribute value color options are in fact a very important and overlooked part of the language's evolution. If new colors are allowed, or old ones disallowed, that's an important versioning change, but the markup is unaffected.
TVR: When in python, I mention at the top of the document things I will import, then if foo() occurs inside the document without having been imprted is illegal.
NM: Many different ways of composing vocabularies.
TVR: That example is one of structure masquerading as text.
NM: What about the change from an attribute to 'red' or 'green' to 'red', green , or flashing amber?
<DanC_lap> (ok, yes, a sentence or two added to the last para in 1.4 Kinds of Languages could usefully discuss embedding/recursion.)
TBL: I agree that the embedding of languages is very widespread and often overlooked. in fact to check a web page is safe (in email, say) you have to check the embedded script, to see what it doesn. That may contain embedded CSS. RDF XML literals can contain XHTML, and so on. I would like validators to validate recurively, but this involves a lot of cross-reefrence and recursion.
[We move to section 2.0]
Subtopic: Section 2.0
NM: It seems you have a scale from none to big bang, but you're missing some variants. For example, mechanisms like 'must understand' are interesting in part because they are in-band controls in each text.
DO: If you put in an unexpect version and a must-understand, then you have used a new version of the language.
NM: Not obvious from the text. I would thought that the SOAP language for example would contain all possible headers.
DO: You asked about recursion. The features of SOAP allow headers to be carried.
DC: This is cleared up at 2.2.1, last of the three bullets "SOAP Header Blocks with the mustUnderstand attribute is an example."
NM: I back off my suggested change.
DO: When you add in XML and SOAP and headers, you really have three levels here. XML includes the purchase order language for example.
NW: What to you mean by 'flavors'?
DO: I think the classic is the three namespaces for XHTML: Basic, Strict and Transitional.
DC: I don't think those words convey that .. add more words or delete the bullet.
[2.0, flavors]
DC: Note changes of style from addressing the audience as 'you' or not.
... More editorial suggestions to come.
[jump to XSLT2 versioning.]
DO: That is really slick.
TBL: How so ... being able to run xslt2 by an xslt1 processor?
Subtopic: 2.2.4
... 2.2.2.4
subsubsubtopic: JK
DO: There is not enough treatment of XSLT. It is a case study in how to do versioning.
Subtopic: 2.1
NM: Saying "It's probably obvious that attempting to deploy a system that provides no versioning mechanism is fraught with peril." is fraught with peril. Using or not using an explicit version control architecture is an engineering tradeoff. I think the strategy of just not having any versioning can often work, for large or small systems.
... The versioning can add a lot of complexity.
DO: Should we have an advocacy position?
DC: We currently state but to not support this essential.
TBL: What is included in "versioning mechanism"? 'ignore unknown tags?' 'unknown unknown triples" or verison number on documents?
NM: Reword to mention that it can be very hard for consumers .
... I will skip editorial comments
... "extend existing texts' .. this is extending the defined text set?
DO: yes
[discussion of the difference]
NM: The idea of a processing model is not the right basis for this discussion. We should talk about compatibility of texts, and the compatibility of information inferred from those texts.
TBL: I agree. Specs should not define processing models, it is better to define the meanng of documents in the language. (generalization)
NM: I think by the way that the defined set and e accept set is less useful than we thought. This is a matter of degre, and I would tell a stotu more like: A language whoch can be deteriend from any texts in its set, where I am not distinguishing two sets.
Suppose my language is defined to extensive, and is, say, an address language. Assume that version 1 requires some fixed markup such as Street, City, State, etc., but allows arbitrary additional markup immediately following the state. Importantly, assume the specification says that the information from such additional markup is not to be ignored completely, but is to be considered part of the address, formatted in some generic way (perhaps tagname=value) when the address is printed, etc.
Then in the second version I add countries, allowing country USA. That was originally in the accept set , but I move it into the defined set.
I can say that for example for a pretty-print application or a shipping label printer, should present or store or print the extension tags.
I could as inventor of the language write that down.
In version 2 of the language, I document the 'country' tag.
but what I get from this 'accept set' and 'defined set' is saying that the first languag ehas a defined set which excludes the country. This suggests that the country is not in the defined sem so dropign the country is mandatory according to DO's document. However, you can print and store stuff which is more or less in the accept set but not the defined set.
DC: In 2.2..1.1, it could be read as "ALL langauge ALWAYS must ".. a misreading.
NM: Beware the 'Must'. they say you must do this in terms of subsitutions.
... I don't think that is a good rule. I think the original language should say what you can get.
... What about 'view source' .. should it ignore ignored tags and not show them?
TBL: Objection .. that is a debugging tool, not the main application.
NM: I would say that the old language has limited semantics for the country tag, and the new one has much richer.
TVR: I think it is interesting to think about the fact that it is consuming a subset of the labnguage. Back-compatability requires that every V4 consumer MUST consume every Version 3 document.
<DanC_lap> (a) I think I see Noah's point that the good practice notes simplify in a way that exclude some designs (b) I think that simplification does more good than harm, but (c) I'm afraid you have to be in this room to know enough to grok it as written
NM: I think the compatablity rule for Forwards compatability should be that, starting with a particulat text, that none of the semantics applied by the newer spec can be inconsistent with that applied by the older spec.
... Lets say that the spec for the old language said, "Everything here must be have to do with the address' then if it is to do with hte address, then the label printer still works. The first spec gets to say that in its own terms.
<timbl_> People do that all the time, stick stuff on labels.
[meta discussion]
<dorchard> how about namespace-range-versioning?