Now that we know how to make a statements in N3, what can we do with them?
You know about how to write your data in N3, and also how to describe the terms you are using in a schema, or ontology. Why is that so useful? Because of all the things you can then do with it. Here we'll learn some basic ways to use cwm, a command line python program. There are lots of other processors for RDF information, and cwm is just one we'll use here. It was designed to show the feasibility of everything in the Semantic Web layer cake, so we can go quite a long way with it. It isn't optimized, though, so you may find it too slow to use for large datasets. This is going to be a completely practical how-to, rather than a theoretical analysis of what is going on. You might like to keep around for reference:
Examples - rather random order supplement
Cwm is a python program, so on most systems you can run it as python
wherever/cwm.py, depending on where you have installed it. From now
on, though, we'll assume you have set up an alias or whatever your system
uses to make it available by simply by the command cwm. You can
always use the long form if you don't have the short form.
Cwm uses the command line as a sequence of operations to perform from left to right. You can input data, process it and output it. The default is to input and output from the standard input and output. So you can read
cwm --rdf foo.rdf --think --n3
as "switch to RDF/XML format, read in foo.rdf, think about it, and then switch to N3 format (for output)".
Any filename is actually a relative URI, so you can suck data off the web just by giving its URI:
cwm http://www.w3.org/2000/10/swap/log.n3
will read in the remote file, and then output it to the terminal.
Converting data formats is simple:
cwm --rdf foo.xml --n3 > foo.n3
converts the RDF/XML file foo.xml into n3, and
cwm bar.n3 --ntriples > bar.nt
converts bar.n3 to ntriples format. The default format at the beginning of the command line is N3. We'll mostly use RDF/N3 from now on, but all the data could equally well be in RDF/XML.
(All these examples involve cwm reading the data into a store, and then
reading it out. This means that the order of the results will be different
(sorted) and the comments will be lost. There is actually
a--pipe option which preserves comments and order, but it only
works with flat RDF files, not with rules and other things which need
formulae. Tip: if the comment you are about to write is
about one of the things your RDF file is about, make it a rdfs:comment
property and it will be carried through the system -- who knows who will find
it useful later?)
The great thing about RDF which you will soon just assume (but you can't do with plain XML documents) is that merging data is trivial.
cwm blue.n3 red.n3 green.n3 > white.n3
reads three n3 files, and then outputs the results in N3 to white.n3.
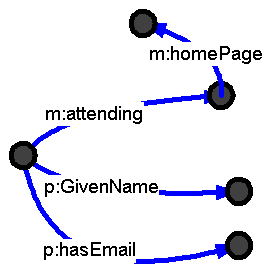
This is particulaly useful if the files have used the same URIs for the same concepts. Suppose the first has that someone is attending a meeting which has a given home page.
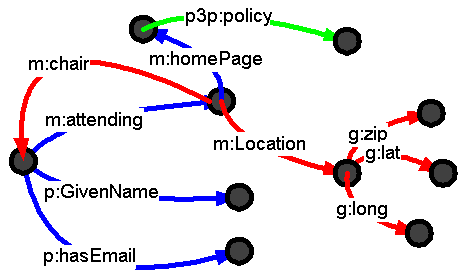
and the second (red) has some information about the meeting, and a third (green) has some information about the meeting's home page. Merging the three gives us an interconnected web, including the fact that the attendee is actuallt chairing the meeting.
Often, you have data in a raw form and the information you want can be deduced from it, and you would like it added to the data set.
In uncle.n3 we state that Fred is the father Joe, and Bob is the brother of Fred; we also describe the logical rule for the uncle relationship:
@prefix : <uncle#>.
:Joe has :father :Fred.
:Fred has :brother :Bob.
@prefix log: <http://www.w3.org/2000/10/swap/log#> .
@forAll :who1, :who2.
{ :who1 :father [ :brother :who2 ] } log:implies { :who1 :uncle :who2 }.
This rule means "whenever someone's father has a brother, then the latter
is their uncle". This rule, once is cwm's store, will cause cwm to deduce the uncle information when it runs
with the command line option --think.
Delivery of packet in the USA has often one price within the
contiguous United States. How could we find those? Well, the test
data set USRegionState.n3
has a list of states of the USA. This includes the borderstate
property which gives a state's neighbors. Contiguous means that you can get
there from here by going from state to neighboring US state. Suppose you are
starting in Boston.so you can get to Massachusetts. Also, any state bordering
a contiguous state must also be contiguous. That's all the rules you need:
{?x us:code "MA"} => { ?x a :ContiguousState }.
{?x a :ContiguousState. ?x us:borderstate ?y} => {?y a :ContiguousState}.
These rules need to be applied more than once to find all the contiguous states. This is where you can see the difference between --rules and --think. Try it with --rules. Try it with --rules --rules. Then try it with --think.s
The result of the above search for contiguous state is too much information. How can we cut it down? Sometimes all we want from the mass of data at our disposal is a single statement.
One way is to decorate the data by marking all the uninteresting bits as being in class log:Chaff. Then, the --purge option of cwm will remove from the store any statement which mentions anything which is in that class. This doesn't need much more discussion.
A more interesting way is to compute just the things which are interesting. This is done with a filter.
In uncleF.n3 we use the uncle example above, but as a filter. When a filter runs (unlike --think) only the information gathered by the rules is preserved: everything else is discarded. We use a filter to select the logical relationships that we want from the mass of what is already known:
@prefix : <uncle#>.
@prefix log: <http://www.w3.org/2000/10/swap/log#> .
@forAll :p.
# What is the relationship between Joe and Bob
{ :Joe :p :Bob } log:implies { :p a :RelationshipBetweeJoeAndBob }.
# Is Bob an Uncle of Joe?
{ :Joe :uncle :Bob } log:implies { :Joe :uncle :Bob }.
When we ask cwm to consider the implication it concludes:
> python cwm.py uncle.n3 --think --filter=uncleF.n3
:Joe :uncle :Bob .
:uncle a :RelationshipBetweeJoeAndBob .
You can read the command line as: read uncle.n3 and the deduce any new information you can given any rules you have. Now just tell me the information selected by the filter uncleF.n3.
Note that any data in the filter is not used. It is easy to imagine that the machine knows something because you can see it in the filter file. However, the filter file is only searched for rules. If you want to include the data, you can put it into a separate input file, or you can even add the filter file as an input file as well as using it as the filter.
In a lot of cases, one wants to take input, decorate the information with
new stuff inferred using rules (with --think) and then filter
out the essence of what is needed. Commands like
cwm income.n3 expenses.n3 categorize.n3 --think --filter=taxable.n3
are common ways of using cwm.
All the examples above process data and leave the result in N3. It is easy of course to generate RDF/XML, too.
What do you do to generate something else, maybe an XHTML page, or an SVG diagram?
If you are used to XML tools such as XSLT, then you can generate the
RDF/XML of your data, and then use XSLT to transform it into a report. When
you do this, you may want to use the rdf output control flags to tell cwm how
you like your output. There is also the --bySubject output
method which prevents the "pretty-printing" of XML.
Another way is to output strings from cwm. This may work well or seem a bit weird, depending on your application. Remembering that all the data in cwm is stored in a big unordered pot, the trick is to tell cwm where you want things on the output stream. This is done by giving each output string a key using log:outputString relationship from key to string.. The --strings option then outputs all the strings which have keys, in order of key. You can use string:concatenation to build the strings out of data. You can also use it to build the key.
{ ?x.context:familyName ?k.
(?x.context:givenName " " ?x.context:familyName "has been invited\n" )
string:concatenation ?s
} => {
?k log:outputString ?s.
}.
This says if k is someone's family name, and a string is made by concatenating their given name, a space, their family name and " has been invited\n", then that string is output in order of key. In other words, in order of family name.
This is all very well, but what happens if it doesn't work? There are a number of ways of looking at problems. They are not in order.
Checking the syntax of files when you have finished editing them can save
both later. You can just load the file with the --no option so
that the syntax is checked by no output is done.
If a rule isn't firing, try commenting out one of the conditions to see which isn't firing.
Try calculating intermediate results, dividing a big rule into more than one step.
You may have misspelled a term. If you do that, it just won't match but it will be perfectly good syntax. To catch this, validate your file using the DAML validator or the cwm validator. These will check that the terms you use are indeed declared in a schema. It'll check a few other things too.
If you think it would help to know what cwm is doing, you can run cwm with
--chatty=50, or any value between 0 and 99. It is often useful
to change the --chatty flag at various times in the command
line, setting it back to zero when you don't need it. You will find 15 tells
you when files are being opened, 25 gives a list of the things cwm has
deduced, then increasing levels give you more and more of the gorey details
of what happens inside. If a rule isn't firing, look for "no way" in the
debug output.
Get cwm to read your input file and output them again (cwm foo.n3
> ,foo.n3). Looking at the file in its new format sometimes shows
up a bug: is that really what you meant?
Think.
When you use N3, you find that all your files, data and rules, can all be
in the same language. Sometimes, when using tools like make, it
is convenient to give files different file extensions depending on their
role. You might want to leave the rule files as .n3, but make the sensor data
.sen and the analyzed data as .ana. Then you can
make makefile rules to map create .ana files from
.sen files.
If you need to pass parameters to your rules, for example something to
search for, or your name, then pass them as command line arguments, putting
them at the very end of the cwm command line, after a --with. Then, the
os:argv builtin function can be used to pick up the value of
each argument, as "1".os:argv and so on.
At this point, you should be getting the hang of it and be writing stuff. To give you some more ideas, though, there is a longer list of more complex and varied examples. These come with less tutorial explanation.
Have fun!