Abstract
In characterizing the structure and content of the Web, it is necessary to
establish precise semantics for Web concepts. The Web has proceeded for a
surprisingly long time without consistent definitions for concepts which have
become part of the common vernacular, such as "Web site" or "Web page". This
can lead to a great deal of confusion when attempting to develop, interpret,
and compare Web metrics.
This document represents an effort on the part of the W3C Web
Characterization Activity to establish a shared understanding of key Web
concepts. The primary goal in preparing this document was to develop a common
interpretation for terminology related to Web characterization research.
However, it is hoped that the Web community at large will also benefit from
the enumeration and definition of important Web concepts.
Status of this document
This document is a working draft for review by W3C members and other
interested parties. It reflects rough consensus of the W3C Web
Characterization Activity Working Group. We do not claim the set of terms
defined in this Working Draft to be exhaustive nor (despite our efforts) that
all definitions are applicable in all situations. The purpose of this Working
Draft is to bring clarity to the terms often used when talking about the Web
as well as to encourage discussion of these and other terms. It is expected
that future changes will be elaborations on the concepts contained in this
document, rather than changes in the concepts themselves. Please send comments
to the <www-wca@w3.org> mailing list
which is archived at "http://lists.w3.org/Archives/Public/www-wca/"
Information on the W3C Web Characterization Activity is located at "http://www.w3.org/WCA/". A list of current
W3C Recommendations and other technical documents can be found at "http://www.w3.org/TR/".
Table of contents
- 1. Primitive Elements
- 2. The Scope of the Web from Perspective of Web
Characterization
- 2.1 Web Clients
- 2.2 Web Servers
- 2.3 Resource Structure
- 3. References
Primitive elements are general concepts and terms that can be used to describe
an information space like the Web. These terms are not necessarily limited to
resources accessible via any particular access mechanism nor are they
guaranteed to be accessible via the Internet.
In this context we use them to describe the information space known as
the Web. However, in addition to illustrating the scope of the Web in
general, the reason why we mention them here is that they are needed to define
a more restrictive set of terms used in Web
characterization research which we can measure and define a set of metrics
for.
The URI
specification describes a resource as the common
term for "...anything that has identity. Familiar examples include an
electronic document, an image, a service (e.g., "today's weather report for
Los Angeles"), as well as a collection of other resources. Not all resources
are network "retrievable"; e.g., human beings, corporations, and bound books
in a library can also be considered resources..." (see also the term Web Resource).
Examples: Web page, collection of Web pages, service
that provides information from a database, e-mail message, Java classes
...
The URI
specification defines a Uniform Resource Identifier
(URI) as a compact string of characters for identifying an abstract or
physical resource.
A resource manifestation is a rendition of a resource at a specific point in
time and space. A conceptual mapping exists between a resource and a resource
manifestation (or set of manifestations), in the sense that the resource has
certain properties - e.g., its URI, its intended purpose, etc. - which are
inherited by each manifestation, although the specific structure, form, and
content of the manifestation may vary according to factors such as the
environment in which it is displayed, the time it is accessed, etc. Regardless
of the form the manifestation's rendering ultimately takes, the conceptual
mapping to the resource is preserved.
Note: For historical reasons, HTTP/1.x calls a
manifestation for an "entity".
Examples: real-time information accessed from a news
Web site on a particular day, up-to-the-minute stock quotes, a rendering of a
multimedia Web page accessed with a particular client ...
A link expresses one or more (explicit or implicit) relationships between
two or more resources.
Note: The type of the relationship can describe
relationships like "authored by", "embedded", etc. Types can themselves be
identified by URIs as for example is the case for RDF.
Examples: An HTML <a
href="http://www.w3.org/Protocols/#News">...</a> element,
an HTML <img src=<http://www.w3.org/icons/w3c-home">
element.
An area within a resource that can be the source or destination of zero,
one or more links. An anchor may refer to the whole
resource, particular parts of the resource, or to particular manifestations of
the resource.
Examples: An HTML <a
name="http://www.w3.org/Protocols/#News">...</a>
element.
The role adopted by an application when it is retrieving and/or rendering
resources or resource manifestations.
Examples: A Web browser, an e-mail reader, a Usenet
reader ...
The role adopted by an application when it is supplying resources or resource
manifestations.
Examples: An HTTP server, a file server, etc
...
A proxy is an intermediary which acts as both a server and a client for the
purpose of retrieving resources or resource manifestations on behalf of other
clients. Clients using a proxy know the proxy is present and that it is an
intermediary.
Examples: An HTTP firewall proxy ...
A gateway is an intermediary which acts as a server on behalf of some other
server with the purpose of supplying resources or resource manifestations from
that other server. Clients using a gateway know the gateway is present but
does not know that it is an intermediary.
Examples: An HTTP to FTP gateway
A unit of communication exchanged between equivalent network layers or
services, located at different hosts.
Examples: A datagram sent from one Internet layer to
another, an e-mail sent from one e-mail reader and received at another
...
A message describing an atomic operation to be carried out in the context of a
specified resource.
Examples: HTTP GET, POST, PUT, and HEAD requests
...
A message containing the result of an executed request.
Examples: An HTML document, a server error message
...
The principal using a client to interactively retrieve and render resources or
resource manifestations.
Examples: A person using a Web browser, a person using
an e-mail reader, a person using a CRT terminal emulator ...
The principal responsible for the publication of a given resource and for
the mapping between the resource and any of its resource manifestations. See
also the term Web Site Publisher
Examples: A person writing an e-mail message, a person
composing a Web page
The primitive elements defined above are useful when talking about the Web
in general but are too broad in practice to enable us to characterize the Web
with the desired level of rigor. This does not mean that we do not consider
the general terms important or interesting, but that we need a mechanism for
limiting the scope of the problem of characterizing the Web.
Therefore, we define the following terms to address the question of "What
is the Web?" from the perspective of Web Characterization. For the purposes of
Web Characterization research, the Web may be viewed as consisting of three
components: the core, the neighborhood, and the periphery:
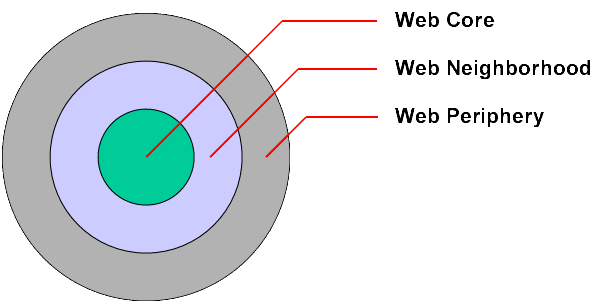
where
The collection of resources residing on the Internet that can be accessed
using any implemented version of HTTP as part of the protocol stack (or its
equivalent), either directly or via an intermediary.
Notes: By the term "or its equivalent" we consider any
version of HTTP that is currently implemented as well as any new standards
which may replace HTTP (HTTP-NG, for example). Also, we include any protocol
stack including HTTP at any level, for example HTTP running over SSL.
A resource, identified by a URI, that is a member of the Web Core.
Note: The URI identifying the Web Resource does not
itself have to be found within the Web Core. That is, a URI written on a bus
identifying a resource that is a member of the Web
Core identifies a Web Resource.
A resource manifestation generated by a Web resource.
The collection of resources directly linked from a Web resource.
A resource, identified by a URI, that is a member of the Web Neighborhood.
Examples: An "ftp" link within an HTML
document which can be accessed via HTTP, a "mailto" link within
an HTML document which can be accessed via HTTP.
The collection of resources on the Web which is not part of the Web Core or the Web
Neighborhood.
Concepts relating to the process of accessing Web resources and render Web resource manifestations.
A client that is capable of accessing Web resources by issuing requests and
render responses containing Web resource manifestations.
Examples: A Web browser, a harvester, a spider
...
A Web request is a request issued by a Web client. A Web request can be described as either:
- Explicit Web request:
-
A request that is initiated manually by the user.
- Implicit Web request:
-
A request that is initiated transparently by the Web
client, without manual intervention on the part of the user, as an
ancillary event corresponding to an explicit Web request.
and as either:
- Embedded Web request:
-
A request for dereferencing a URI embedded within a Web resource
manifestation: e.g., following the link in an HTML
document, etc.
- User-input Web request:
-
A request for dereferencing a URI supplied by the user directly to the Web
client: e.g., typed into the address window, bookmarks, history, etc.
Examples: a) A user follows a link appearing
in a HTML document (explicit, embedded Web request). The Web client retrieves
the requested HTML document, and also makes an additional request for an image
referenced in the HTML document (implicit, embedded Web request); b) A user
reads the URI printed on a bus and feeds it to the Web client (explicit,
user-input Web request).
The request header contains information about the request, information
about the client itself, and potentially information about any resource
manifestation included in the request.
Examples: Sample HTTP request
header
Web Request Body
The request body (if any) of an HTTP request is used to carry the payload
of the HTTP message.
A delimited set of user clicks across one or more Web servers.
Example: At a library, a patron sits down at a public Internet-access
terminal, accesses one or more Web resources, then relinquishes control of the
terminal to another patron.
A subset of related user clicks that occur within a user session.
Example: Continuing the previous example, the library patron accesses a
weather report (episode 1), checks stock prices (episode 2), then downloads a
patch for his operating system (episode 3).
Concepts relating to the process of supplying Web resource manifestations.
A server that provides access to Web resources and which supplies Web resource
manifestations to the requestor.
A Web response is a response issued by a Web server.
The response header contains information about the response, information about
the server itself, and potentially information about any resource
manifestation which may or may not be included in the response.
Examples: Sample HTTP Response
Header
The response body (if any) of an HTTP response is used to carry the payload of
the HTTP message.
A collection of user clicks to a single Web server during a user session.
Also called a visit.
Data sent by a Web server to a Web client, to be stored locally by the client
and sent back to the server on subsequent requests.
Example: When the Web site of an online retail store is accessed for
the first time by a particular client, a unique hashcode is sent back to the
client to be stored locally. Then, when the client requests URLs from the
site, the hashcode is appended to the URL request, allowing the Web site
administrators to track the surfing pattern of the customer through the
site.
The following concepts relates to the structure of Web content.
A collection of information, consisting of one or more Web resources, intended
to be rendered simultaneously, and identified by a single URI. More
specifically, a Web page consists of a Web resource
with zero, one, or more embedded Web resources
intended to be rendered as a single unit, and referred to by the URI of the
one Web resource which is not embedded.
Examples: An image file, an applet, and an HTML file
identified and accessed through a single URI, and rendered simultaneously by a
Web client.
Note: The components of a Web page can reside at
different network locations. The location of the Web page, however, is
determined by the URI identifying the page.
Note: The scope of a Web page is limited to the
collection of Web resources which are displayed simultaneously by requesting
the Web page's URI. The components of a Web page actually rendered in a page
view is client-dependent.
Visual rendering of a Web page in a specific client environment at a specific
point in time.
Examples: Displaying a particular Web page in Internet
Explorer is a pageview; displaying the same page in Netscape Navigator is a
different page view.
A Web page identified by a URI containing an <authority>
component but where the <path> component is either empty or
simply consists of a single "/" only.
Examples: The Web pages identified by
http://www.w3.org and http://www.cern.ch are host
pages
A collection of interlinked Web pages, including a host
page, residing at the same network location. "Interlinked" is understood
to mean that any of a Web site's constituent Web pages can
be accessed by following a sequence of references beginning at the site's host page; spanning zero, one or more Web
pages located at the same site; and ending at the Web page in question.
Examples: The Web page consisting of the
article "Thought Paper on Automatic Recharacterization" is part of the W3C Web site, since it satisfies the two
properties mentioned above. First, it resides at the same network location as
the W3C host page,
http://www.w3.org. Second, we can begin at the
W3C host page (http://www.w3.org) and follow a
sequence of internal links, ending at the article: specifically:
-
http://www.w3.org to http://www.w3.org/WCA/,
and
-
http://www.w3.org/WCA/ to
http://www.w3.org/WCA/1998/12/aut_char.html
Notes: It is not uncommon for Web sites to be
duplicated, or mirrored, on multiple physical host machines (e.g., for load
balancing purposes). Typically, it is immaterial to the client (or user) which
host machine is used to access the Web site. In this case, it may be
useful to consider this collection of "physical" Web sites, located at
multiple host machines, as one "logical" Web site. This is possible
in the case where a single domain name is mapped to each of the host machines;
the logical Web site can then be identified using the unique domain name.
If there is no unique domain name that can be applied to the
collection of duplicate sites, we consider each physical host machine as a
separate Web site.
A Web page that is not part of the Web site associated with its network
location. Specifically, it is not possible to reach the Web page in question
by traversing a sequence of links internal to the Web site, beginning at the
host page.
Examples: If a page is mounted on a Web server, but is
not linked to by any page on the Web site associated with the server, then the
page is like an "island" on the Web. The only way the page can be accessed is
through explicit knowledge of its URI.
A person or corporate body that is the primary claimant to the rewards or
benefits resulting from usage of the Web site, incurs at least part of the
costs necessary to produce and distribute the site, and exercises editorial
control over the finished form of the Web site and its content. See also the
term publisher.
Examples: The W3C is the publisher of the site located
at http://www.w3.org/ ...
A cluster of Web pages within a Web site, that is maintained by a different
publisher than that of the parent Web site, or host site. The subsite
publisher exercises editorial control over the Web pages comprising the
subsite, perhaps restrained by some broad guidelines imposed by the host site
publisher.
Examples: An Internet service provider supplying
hosting services to its customers. All of the customers' Web sites may be
located at the same IP address, but nevertheless represent logically
independent sites (and, in the case of virtual hosting, may even have distinct
domain names).
A portion or section of a Web site, consisting of two or
more Web pages, that represents a non-trivial, self-contained resource, but is
still maintained by the same publisher of the overall Web
site.
Examples: Web journal, electronic monograph, photo
gallery ...
A single, logical Web site that extends over multiple
network locations, but is intended to be viewed as a single Web site. It is transparent to the user that the site is
distributed over multiple locations. A single host page
applies to the entire supersite.
Examples: The resources available from a particular
entity may be distributed over multiple servers, but users access the
supersite through one host page, and view the distributed
resources as one logical site.
Other useful places to look for terminology sections are
@(#) $Id: 01.html,v 1.47 2017/10/02 10:21:40 denis Exp $