Warning:
This wiki has been archived and is now read-only.
Main Page
This document specifies an actionable HTML annotation format for interactive APIs (iAPIs) able to identify reusable content and functionality inside Web pages. The annotations, together with a dedicated iAPI middleware (a browser extension), provide for advanced reusability via JavaScript (for developers) and via interactive, graphical controls injected into iAPIs (for users). Web browsers without the iAPI middleware installed will ignore the annotations without any further effect.
Version: 0.1
Authors (add yourself after contributing): Florian Daniel
Contents
Context and concept
Most of today's applications are not developed from scratch and instead reuse resources they source from the Web. This reuse happens in two fundamentally different ways: either people use readily available APIs or services, such as RSS/Atom feeds, RESTful/SOAP web services, JavaScript libraries, etc., or they extract/wrap data, functionality or pieces of UI from Web pages. The former practice acts on the Deep Web (the data and functionality behind Web pages), the latter on the Surface Web (the rendered Web pages we browse manually).
In this context, this proposal is motivated by the following observations:
- The Deep Web generally provides access only to a subset of what is provided through the Surface Web (e.g., there are many good Web sites without programmable APIs);
- Wrapping (extracting, scraping) is therefore a practice that will always be needed (e.g., because one nevertheless wants to reuse parts of that Web site);
- Wrapping of Web pages is currently neither supported technically nor expected by the Web site providers. Wrapper logic is therefore hard to implement and not robust against even minimal changes to a source page's HTML markup.
The idea pursued by the interactive API proposal is to design a simple annotation format adding meta-data to HTML markup, so as to enable the identification of reusable parts inside Web pages and their programmatic reuse. Annotations may come from the providers of the Web pages (directly inside the source markup) or from third parties (via external annotations of existing Web pages). The goal is to support the dynamic extraction and reuse of data, functionality and pieces of user interfaces (UI widgets), as well as the automated operation/navigation of Web sites in a stable and principled fashion. The artifact that provides these capabilities is called interactive API, short iAPI.
The name "interactive APIs" further hints at the second goal pursued by this initiative, i.e., that of providing an API that is interactive, that can be inspected, browsed and navigated just like a common Web page, and that - more importantly - can be profitably used also by non-programmers inside their Web browser. The vision is the foundation of a composition/reuse paradigm that is entirely based on UIs and the interactive manipulation of iAPIs: UI-oriented computing [1].
Making iAPIs operative requires the development of a new layer in the Web architecture stack, which makes UIs accessible programmatically and mediates between the Deep Web and the Surface Web. The approach of iAPIs is to split this layer into two complementary aspects: an annotation format that tells what can be reused and an iAPI middleware that knows how to reuse iAPIs. That is, the goal is to develop an approach that does not just annotate content, dumping the burden of the actual reuse on the developer, but that provides concrete, actionable development support to both developers and users.
The focus of this document is the annotation format. The iAPI middleware and development support is developed in parallel as open-source project hosted on GitHub (see the section "Parsing and using iAPIS: iAPI middleware").
iAPI annotation convention
iAPIs are inspired by microformats 2 (http://microformats.org/), which use the HTML class attribute to add meta-data to HTML markup. Tags inside the class attribute (separated by a space character) are interpreted by the browser as CSS classes to be applied to the respective HTML element, provided that the page's style definition contains a class with the tag as name. Otherwise, the tag is ignored.
The iAPI annotation proposes a set of pre-defined tags, i.e., properties, for the class attribute to specify a iAPIs. The root of any iAPI is the h-iapi property, which identifies the scope of an iAPI. For instance, the following example identifies the HTML table as iAPI:
<table id="1" class="h-iapi"> ... </table>
There may be more than one iAPIs per page. Each iAPI inside a page must therefore be scoped by an h-iapi property and uniquely identified by an HTML id attribute.
| Properties | |
|---|---|
| h-iapi | Qualifies the annotated HTML element as iAPI (requires a valid HTML id attribute) |
In line with the convention proposed by the microformats 2 proposal, the iAPI annotation makes use of prefixes to facilitate the implementation of parsers. Specifically, the prefixes used in this document are:
- h-* = root classname that identifies the microformat (as for microformats 2)
- e-* = element to be parsed as HTML (as for microformats 2)
- p-* = text property (as for microformats 2)
- u-* = URL (as for microformats 2)
- i-* = input element (indicates input elements that allow filling content, not extracting content)
Data sources
The goal of annotating data inside HTML markup is to support the extraction of structured data from Web pages, so as to enable their reuse inside other Web pages.
Scenarios
- A user wants to use the data rendered inside a table of a page authored by a provider inside his own web page.
- A user wants to use the data underlying a paginated table, without having to browser through the individual pages.
- A user wants to re-format fetched data inside his own page (e.g., using a list instead of a table).
Model
Extracted data are independent of the HTML/CSS formatting of the source page and follow the data model shown in the following figure, which is essentially based on items, attributes and values, where values can be structured again with attributes and items, and so on.
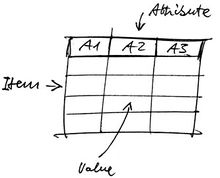
Annotation
Annotating custom data structures
Annotating data requires identifying a data source inside a page, that is, the HTML element from which data can be extracted, and describing the structure of the contained data. Data sources are identified using the h-iapi property together with a e-data property, which also allows to label the data source. Data structures are defined by identifying the data items and their attributes and labeling them. This technique allows the provider of the data source to specify arbitrary data structures and to provide them with the necessary semantics (the labels).
Example:
<table id="1" class="h-iapi e-data:Publications">
<tr class="e-item:Publication">
<td class="p-attr:Authors">F. Daniel and A. Furlan</td>
<td class="p-attr:Title">The Interactive API (iAPI)</td>
<td class="p-attr:Event">ComposableWeb 2013</td>
</tr>
...
</table>
| Properties | |
|---|---|
| e-data:label | Qualifies the iAPI as data source; label provides a human-readable name for the data |
| e-item:label | Identifies data items inside a feed of data; label gives a name to data items |
| p-attr:label | Structures data items into attributes; label gives names to data attributes |
Microformats
If the data to be made available for reuse complies with any of the existing microformats (see http://microformats.org), it is possible to use the respective microformat properties to annotate data inside an iAPI qualified as data source. There is no need for own data structures and/or semantics.
For example, the following properties make use of the h-card microformat to identify business contacts (URL and organization):
<div id="1" class="h-iapi e-data:Organization h-card"> <a class="u-url p-org" href="http://interactive-apis.org">interactive-apis.org</a> </div>
| Properties | |
|---|---|
| h-card | Identifies the h-card microformat (http://microformats.org/wiki/h-card) |
| ... | ... |
Ideally, all existing microformats can be used inside an iAPI to annotate data. Which exact microformat is supported depends on the microformat parsing capabilities of the adopted iAPI middleware.
Linking external data sources
The use of custom annotations and microformats enables the extraction of data from HTML markup. Another option to make data available is to provide access to a remote data API, such as an XML or JSON web service. This allows the user to fetch data directly from the provider's back-end, instead of extracting them from the HTML markup, and may provide access to the full data available without, for instance, having to extract data from multiple pages (e.g., for paginated tables). An iAPI may contain both markup annotations and a link to an data API. It is up to the data provider to choose how to make data available.
Example:
<table id="1" class="h-iapi e-data:Publications u-json:http://source"> ... </table>
| Properties | |
|---|---|
| u-json:url | Identifies a JSON data source; url specifies the URL of the data source |
| u-rss:url | Identifies an RSS data source; url specifies the URL of the data source |
| u-xml:url | Identifies an XML data source; url specifies the URL of the data source |
| ... | ... |
As for the structure of the data fetched from remote web services, this can be specified directly inside the root element of the iAPI with the addition of the element/key/query that uniquely identifies the respective element in the data source.
Example:
<table id="1" class="h-iapi e-data:Publications u-json:http://source e-item:Publication:pubs p-attr:Author:auth p-attr:Tile:title p-attr:Event:event"> ... </table>
| Properties | |
|---|---|
| e-item:label:key | Identifies data items inside an external data source; label gives a name to data items; key tells how to identify the item in the data source, i.e., how to query the data source for data items |
| p-attr:label:key | Structures data items into attributes; label gives names to data attributes; key tells how to identify the attribute in the data source |
Again, which source data format is supported depends on the implementation of the adopted iAPI middleware. Annotation-wise, there is flexibility.
Forms
Forms provide access to remote application logic. They allow one to submit data (inputs), to get them processed remotely on the provider's web server, and to obtain responses (outputs) that depend on the submitted data. Reusing forms can therefore be seen as reusing remote application logic, just like when using conventional web services.
Scenarios
- A user wants to automate a set of search tasks.
- A user wants to extend a given data set with data accessed through a form.
- A user wants to integrate two or more applications by passing data among them.
Model
The figure below illustrates the basic form model: a typical form interaction consists of filling a set of input fields/elements (e.g., text fields or checkboxes), submitting the entered data for processing, and inspecting the result. This latter may be provided inside the same page of the form or it may be provided in another page. In addition, forms may be split into multiple steps, i.e., pages, and may therefore require to traverse multiple pages to reach a final result.
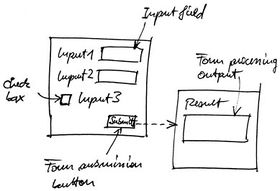
Reusing a form as a programmatic function therefore requires annotating the form and input fields, which allow one to provide inputs, as well as the data produced by submitting the inputs for processing. Forms are annotated using the properties explained in the following; data are annotated as described above.
Annotation
Example:
| Properties | |
|---|---|
| e-form:label | Identifies a form inside a web page and assigns a label to it |
| i-text:label | Identifies a text input with name label |
| i-password:label | Identifies a password input with name label |
| i-file:label | Identifies a file input with name label |
| i-button:label | Identifies a button with name label |
| i-radiobutton:label | Identifies a radiobutton with name label |
| i-image:label | Identifies a image input with name label |
| i-reset:label | Identifies a reset button with name label |
| i-checkbox:label | Identifies a checkbox with name label |
| i-result:label | Identifies the result of the computation and assigns a label |
| i-submit | Identifies the form submission button inside the form |
A sample form that could be used for a log in:
<form class="h-iapi e-form:login" id="1" method="post" action="Login">
<input class="i-text:username" type="text" id="username" name="username"/>
<input class="i-password:password" type="password" id="password" name="password" />
<input class="i-submit" type="submit" id="btnSubmit" value="submit">
</form>
UI widgets
The idea of UI widgets is to enable the extraction of complete pieces of UI (the so-called widgets) from web pages, however without the need to follow complex widget implementations and in a fashion that is almost for free to the developer sharing the widget.
Scenarios
- A user wants to copy and paste a given table into his own website.
- A user wants to include a full-fledged payment widget (e.g., PayPal) into his website.
- A user wants to construct a new UI out of existing pieces of UI.
Model
The UI widget model of iAPIs is that of a standard web UI (see the figure below). It consists of some HTML markup that can be identified via the h-iapi annotation, CSS styles, possible linked resources (e.g., images or videos), and optional JavaScript instructions for dynamic behavior.
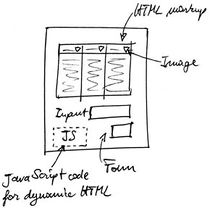
While making available data or form functionality can be achieved by suitably annotating the respective HTML markup, making UI widgets reusable requires the provider of the UI widget to both annotate the widget and to follow some (simple) implementation guidelines, which guarantee that the widget can correctly be extracted at runtime:
- HTML markup: this can easily be extracted via copy/paste;
- CSS styles: these can be extracted by reading the browser's computed style properties for each element included in the HTML markup;
- Linked resources: these can be either not extracted at all (and the cloned UI widget refers to the original resources) or they can be copied locally (and the cloned widget refers to the local copies of the resources);
- JavaScript instructions: these are harder to extract automatically; the convention therefore is that JavaScript is either included via the <script> element directly inside the HTML markup to be cloned, or it the developer provides a link to a .js file containing all the necessary scripts to make the widget work also independently (and nothing more).
Annotation
Example:
| Properties | |
|---|---|
| e-widget:label | Identifies a UI widget inside a web page and assigns a label to it |
| u-js:url | References a possible JavaScript library implementing widget-internal, dynamic behavior |
| u-css:url | References a possible CSS style sheet for the widget |
iAPI middleware
A first version of an iAPI middleware in the form of a Google Chrome browser extension is currently under development here (Interactive API (iAPI) middleware for UI-oriented computing). The goal of the browser extension is to provide a middleware for the reuse of iAPIs, a JavaScript API and jQuery plug-in for the programmatic reuse of iAPIs (for developers), and an graphical, in-browser editor for the interactive manipulation of iAPIs (for users without programming knowledge).
References
[1] F. Daniel and A. Furlan. The Interactive API (iAPI). Proceedings of ComposableWeb 2013 / ICWE 2013 Workshops, LNCS 8295, pp. 3–15, 2013, Springer.