Nearby: XMLSpec page
About This Report
This report describes the XML specification ("XMLspec") DTD used for World Wide Web Consortium (W3C) specifications and notes related to XML. It is maintained by Eve Maler (<elm@east.sun.com>, +1 781 442 3190) of Sun Microsystems. This release of the report corresponds to the DTD with the formal public identifier "-//W3C//DTD Specification Version 2.1//EN".
Purpose and Scope
This report describes the DTD used for World Wide Web Consortium (W3C) specifications and notes related to XML.
This report is available at http://www.w3.org/XML/1998/06/xmlspec-report-v21.htm. The DTD file is available at http://www.w3.org/XML/1998/06/xmlspec-v21.dtd. The latest version of the DTD is always available at http://www.w3.org/XML/1998/06/xmlspec.dtd, and the latest version of the report is always available at http://www.w3.org/XML/1998/06/xmlspec-report.htm.
The following people have been major contributors to the DTD design:
| Jon Bosak, Sun |
| Tim Bray, Textuality |
| Dan Connolly, W3C |
| Eve Maler, Sun |
| Gavin Nicol, Inso |
| C. Michael Sperberg-McQueen, W3C |
| Lauren Wood, SoftQuad |
| James Clark |
How to Use This Report
This report is organized as follows:
-
Chapter 1 lists the sources of input used during the DTD design effort, describes the project design parameters, and describes global outstanding issues. Read this to understand the basic principles underlying the design results and to review the issues.
-
Chapter 2 through Chapter 5 contain the markup models for the DTD, and Chapter 6 describes information linking relationships, nontextual data formats, and special symbols that the DTD encodes. Read these chapters to understand how the markup will be used with World Wide Web Consortium XML information, and the reasons for their design.
Note that, where appropriate, some processing expectations have been documented for the markup. This information is not to be considered a complete style specification; it simply records known requirements.
-
Chapter 7 contains the common categories of elements and the commonly used element mixtures in content models. Read this to understand the "mixture" content models described in Chapter 3, Chapter 4, and Chapter 5.
-
Appendix A contains a non-normative list of known applications that do formatting and other processing of XMLspec documents.
-
Appendix B contains a listing of the DTD.
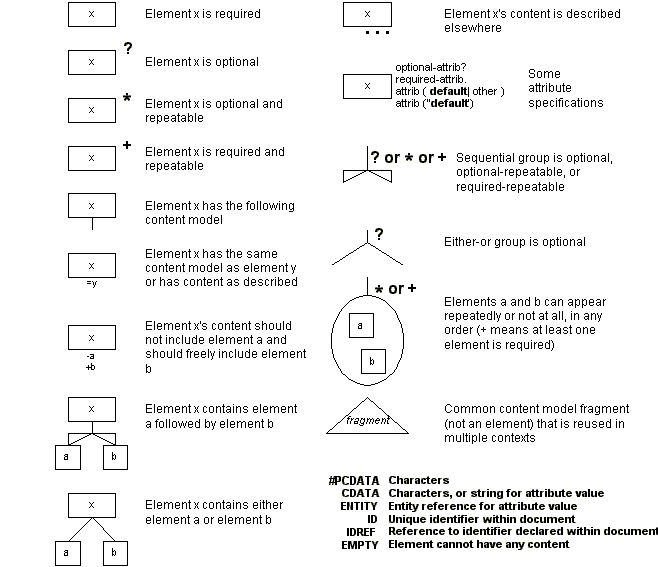
How to Read Elm Tree Diagrams
To understand the graphical "elm tree diagrams" used in this report, use the following legend.
Chapter 1. Introduction
Following is information on the sources of analysis input, the design principles governing the markup model, the implementation principles governing its expression in DTD form, and outstanding issues.
Catalog of Analysis Inputs
The following have been used as analysis input in designing the DTD:
-
The original XML specification DTD, jointly developed and revised by Michael Sperberg-McQueen, Tim Bray, and Jon Bosak
-
Michael's SWEB documentation
-
The XML, XLink, XPointer, DOM, MathML, XSL, and Schema specifications and their customizations of XMLspec
-
The XML/SGML comparison note
Design Principles
Following are the design principles governing the markup model of the DTD.
Scope
Although the DTD has come to be called "XMLspec," it is intended for W3C working drafts, notes, recommendations, and all other document types that fall under the category of "technical reports."
The DTD is responsible for covering three main aspects of XML technical reports:
-
Basic W3C technical report structure and content, including paragraphs, lists, cross-references, and so on
-
Markup structures specific to the XML-related family of W3C technical reports, such as EBNF productions, validity constraints, and element and attribute names
-
Proper headers and metadata for W3C technical reports
Focus
The DTD is intended to support the following functions, in order of priority:
-
Production of technical reports
First and foremost, the DTD should facilitate hassle-free production and publication. Many of the documents in the scope are made available in several output forms, including source XML and derived HTML, RTF, and PostScript. It is important to produce these outputs in a form that meets W3C requirements, and produce them quickly in order to speed the W3C publication release process. Also, it may be useful to extract different parts of the document content (for example, just the productions) for distribution.
In recent revisions, the markup has evolved to capture an increasing amount of technical detail, for example, the IDL structures contributed from the DOM work. This is motivated entirely by considerations of successful publication from a single source to multiple outputs, rather than by abstract concerns about source purity; however, it makes an effective illustration of the power of XML.
-
Creation and modification of content
The DTD should provide an intuitive, efficient interface to the creation process. This means that the DTD shouldn't be overly large or complicated, but that it should provide support for information structures using the jargon, and to the depth, that authors will tend to understand the information.
-
Review of content
To a lesser degree, the DTD should support the informal workflow that goes on when co-editors pass around drafts for review. To this end, the DTD should provide markup for editor "communication" inside the document source.
-
Proof of concept of XML publishing
Finally, where possible, this DTD and its associated applications should use good XML practice and conforming XML tools, because many will look to this application as an example.
This DTD's first few revisions existed before there were any XML parsers, and indeed before XML 1.0 itself was standardized. In today's world, XML's future has been assured and XML tools are plentiful. However, while a "proof of concept" is no longer needed, XMLspec does in fact continue to serve as an example of best practices.
Presentation Independence
The DTD should avoid presentational markup where possible. Sometimes this principle comes into conflict with the production focus, but in general, presentation independence helps serve the goal of production of multiple outputs. In any case, egregious examples of formatting-specific markup should be avoided.
Information for DTD Maintainers
The following information gives background on implementation decisions.
Versioning and Updates
This DTD was previously given a formal public identifier in the following pattern:
-//W3C//DTD XML Specification::yyyymmdd//EN
For easier identification, the DTD now uses a formal public identifier in the following pattern:
-//W3C//DTD XML Specification Version n.n//EN
The current version is identified as:
-//W3C//DTD Specification Version 2.1//EN
The policy, beginning with Version 2.0, is as follows.
Minor revisions (revising n.m to produce n.m+1, for example, going from V2.0 to V2.1 or from V2.1 to V2.2) can add to the markup model, but cannot change it in a backwards-incompatible way. For example, a new kind of list element could be added, but it would not be acceptable for the existing itemized-list model to start requiring two list items inside it instead of only one. Thus, any document conforming to an old version would also conform to the new minor revision.
Major revisions (revising n.m to produce (n+1).0, for example, going from V2.1 to V3.0) can both add to the markup model and make backwards-incompatible changes. Ideally these will be accompanied by XSLT transformation specifications that help legacy documents to conform to the new version.
Always review the change history in any new version of the DTD carefully before deploying it.
Currently, DTD changes are at the discretion of the maintainer and the heaviest users of the DTD within the W3C. A more formal procedure may be put in place later.
This DTD does not yet have an official schema. If you want to refer to the XMLspec vocabulary for namespace management purposes, use the following URI to identify it:
http://www.w3.org/XML/1998/06/xmlspec-v21.dtd
Note that this identifying URI may change in the future.
Naming and Coding Conventions
The element names from the original DTD on which XMLspec was based were mostly kept; changes were made in a few cases only to rationalize the naming scheme.
Hyphens are typically avoided, except in the "w3c-" prefix.
Whitespace and tabs are used relatively sparingly to enhance readability; excessive whitespace is avoided in the interest of a compact and "unthreatening" DTD.
Parameter Entity Typology
Parameter entities are used in several different capacities in the DTD. To indicate their different roles, unique suffixes are used as follows:
- descrip.att
-
The name, declared value, and default value specifications for a set of one or more attributes.
Some descriptions may have a sub-suffix, such as -req, which means that the attribute (or one of the attributes) in question is required.
- descrip.class
-
A set of related elements that are typically available as options in certain content model "free mixtures" (repeatable-OR groups). These entities are referenced from within descrip.mix entity declarations and content models.
If you add a new standalone or phrase-level element, make sure that you add it to the appropriate class entity, or create a new class for it. If you create a new class, incorporate references to that class in the appropriate mixture entity declarations.
- descrip.mix
-
A set of elements that are available to writers in certain contexts as a "free mixture" (repeatable-OR group). These entities are referenced from within content models.
- descrip.pcd.mix
-
A set of #PCDATA and elements that are available to writers in certain contexts as a "free mixture" (repeatable-OR group). These entities are referenced from within content models. The presence of #PCDATA makes these "mixed" content models, which means that document creators can type regular text here and that downstream applications will need to take account of whitespace found here.
- local.descrip.att
-
An empty placeholder that is available to be used in extending an attribute list.
- local.descrip.class
-
An empty placeholder that is available to be used in extending an element class.
- descrip.mdl
-
A content model fragment (other than a "free mixture") that is common or customizable.
The goal in naming the entities was to be consistent and brief, without losing readability. The keyword indicating the entity type always appears last because the location of an entity reference will already give a clue as to the entity type, and so this is not the information that needs to be seen first when the DTD is read. This naming scheme also allows for easier searching.
XML and XLink Usage
The DTD conforms to XML V1.0 and makes use of the XML and XLink namespaces. Because DTDs and namespaces don't mix well, the xlink namespace prefix has been hardwired. (The xml prefix is hardwired into the XML specification itself.)
While XLink is used for all URI-style linking, the IDREF addressing mechanism is still used heavily for internal links. As support for the XPointer construct xpointer(id("xxx")) grows and that specification stabilizes, we will consider moving to this style of addressing for internal linking.
This version of the DTD does not yet conform fully to the latest working draft of the XLink specification, because this would have required backwards-incompatible changes. When the XLink specification reaches Recommendation status and if such backwards-incompatible changes are still required, a new major version of this DTD will be published that will require changes to legacy documents.
Parameterization
The DTD is beginning to be used more widely by W3C contributors (as well as by authors of non-W3C specifications). While this DTD was designed with the needs of XML technical reports firmly in mind, quite a lot of the markup design would be useful for technical reports produced by others in the W3C. Therefore, the DTD has been parameterized to allow for:
-
Modification of certain content models that are likely to be subject to personal and Working Group preference
-
Addition of new elements at the "standalone" and "phrase" levels
-
Some limited removal of existing elements at the "standalone" and "phrase" levels
-
Addition of new attributes to an attribute list
If it is found that the DTD can be made more widely useful solely by heavier parameterization, it would probably be worth it to add the new parameters.
Heed the following advice if you plan to develop a variant of the DTD:
-
Plan and document both the substance of your changes and the reasons for them.
-
Build variants only by redefining the original parameter entities, if possible; don't edit any of the original DTD files.
-
If you plan to interchange your files with other DTD users, favor markup changes that place tighter validation restrictions on documents (subsets), rather than changes that would allow instances that no longer conform to the standard DTD (extensions).
-
Avoid confusion by using a different formal public identifier for your DTD variant if you have changed any element or attribute markup characteristics. You may want to indicate the derivation with an identifier that uses the following pattern:
-//owner-ID//DTD XML Specification Version n.n-Based your-descrip-and-version//lang
Issues
Following are outstanding global issues:
-
Consider adding an optional href to name and affiliation, and allowing them and email in regular text.
-
Revise XLink usage as necessary. Note that in the current version, all the XLink simple linking elements in this DTD do not conform to the latest XLink working draft; a major revision of XMLspec (along with conversions of legacy documents) will be needed to bring it back into sync. See the section called XLink-Related Attributes in Chapter 2 for more information.
-
According to W3C guidelines (http://www.w3.org/Guide/Reports), all references should be to a bibliography entry, and then the bibliography entry should point to the Web resource (if possible). This would suggest that we should freely allow bibref, but allow loc only in the special header fields such as "Latest Version" and in bibliography entries. Consider migrating over to this scheme at the next major revision (because it is backwards incompatible).
-
Research the proper form of Web resource bibliography entries, and consider adding to the structure of bibl to optimize for it.
-
Perhaps related is the fact that titleref is freely allowed in paragraphs as well as in bibl. Since titleref is like a restricted or subclassed form of loc, it may also be obsolescent. In addition, titleref appears to duplicate the hypertext function of bibl (or maybe it's the other way around, since it may be inappropriate to make the entire contents of bibl "hot").
-
Dan Connolly has requested that the element type names in this DTD match HTML wherever possible. The question is, how much is possible? About a dozen of the element types in this DTD are strongly reminiscent of element types in HTML. However, in all cases, there are subtle differences (sometimes simply amounting to different subelements allowed inside the element in question). Should the element type names be made to match?
Following are the potential correspondences:
XML specification DTD HTML Comments loc a The semantic is slightly different p p No change needed ulist ul item li olist ol slist sl For consistency; not HTML-based glist dl Contents are significantly different gitem dli For consistency; not HTML-based label dt def dd blist bl For consistency; not HTML-based eg pre The semantic and contexts are different graphic img The source attribute would also have to be renamed to src emph em
-
If a glossary list is used to organize term definitions, how can termdef properly be used? Currently, at least in the XML Linking drafts, the contents of the label element are surrounded with a termdef element and a term element isn't provided, while the actual definition text in def goes unmarked-up as such.
-
Consider making the nt element be empty, and have its content generated by reference to the production's lhs. This would avoid redundancy.
-
Incorporate the XHTML 1.0 table model, now that it's a Recommendation.
-
Add an inline graphic element.
-
Consider adding attributes to division elements to record whether the division has WG consensus, whether it is obsolete, etc.
-
At the next major revision (because it is backwards-incompatible):
-
Require the abstract to go before the status section
-
Fix the order of prevlocs and latestloc
-
Revise XLink usage in backwards-incompatible ways as necessary
-
Require graphic alt text
-
Require issue heads?
-
Change over to use constraint and constraintnote exclusively, since only the XML spec needs wfc/wfcnote and vc/vcnote?
-
Consider changes to BNF internal structure? (Check against DocBook's use of the BNF structure)
-
DTD Change History
Following is the change history for the DTD. Note that you can search the DTD file for "#" in the first column to see change history comments.
2000 February 15
Added proto element, its arg subelement, and the %argtypes; entity.
Added function, var, sub, sup, phrase, el, att, attval elements.
Expanded emph to %p.pcd.mix;.
Allowed status and abstract to appear in the opposite order.
Updated XLink usage to the latest WD, except for href and source.
Removed the xml:attributes attribute from graphic.
Added %local.graphic.att; to graphic.
Added common diff attribute.
Added div5 element.
Broadened content models of publoc, prevlocs, and latestloc.
Added head, source, resolution, and status attribute to issue.
Added cr, issues, and dispcmts to w3c-doctype attribute on spec.
Added example element.
1999 July 2
Added %loc.class; to all PCD mixes that didn't already have it.
Removed unused %loc.pcd.mix;.
Made version in spec header optional.
Added three new attributes to spec.
Broadened content of edtext.
Added optional copyright element to header.
Reorganized XLink-related parameter entities; added xmlns:xlink.
Changed edtext content from #PCDATA to %p.pcd.mix;.
Added show/actuate atts and default values to all href elements.
Changed versioning scheme from 8-digit dates to version numbers.
Added w3c-doctype, other-doctype, status atts to spec element.
Added prodrecap element inside scrap.
Added headstyle attribute to scrap.
1998 December 3
Fixed character entities with respect to escaping of ampersands.
Added many more explanatory comments.
1998 November 30
Added new unused elements to support DocBook translation.
Updated maler phone numbers.
1998 August 22
Fixed %illus.class; to mention table instead of htable.
Added definitions to %illus.class; for DOM model.
Added DOM definitions element and its substructure.
Updated XLink usage in %href.att; to use xlink:form and #IMPLIED.
Added clarifying comments to HREF-using elements.
1998 May 21
Declared generic constraint and constraintnote elements.
Added constraintnote to %note.class;.
Added constraint to %eg.pcd.mix; and prod content model.
1998 May 14
Fixed mdash, ldquo, and rdquo character entities.
Switched to the full HTML 4.0 table model.
Removed htable/htbody elements and replaced them with table/tbody.
Added issue element to %note.class; and declared it.
Allowed prevlocs and latestloc in either order.
Added key-term, htable, htbody, and statusp as unused elements.
Removed real statusp element in favor of plain p.
1998 March 23
Cleaned up some comments and removed some others.
Added xml:space semi-common attribute to eg and bnf elements.
Added show and embed attributes on all the uses of href.
Added %common.att; to all HTML table elements.
Added a real URI to the "typical invocation" comment.
1998 March 10
Merged the character entity and table modules into the main file.
Added ldquo and rdquo entities.
Added common attributes to prodgroup.
Made the email element in header optional.
Removed reference to the SGML Open table model.
Added ednote element.
Added quote element.
Updated XLink usage to reflect 3 March 1998 WD.
Added "local" entities to the class entities for customization.
Parameterized several content models to allow for customization.
1997 December 29
Moved #PCDATA occurrences to come before GIs in content models.
Removed use of the SGML Open table module.
Added xspecref element.
Ensured that all FPIs contain 4-digit year.
(Modified the character entity module.)
1997 November 28
Added support for prodgroup and its attributes.
Added support for HTML tables.
Added loc and bibref to content of com.
Added loc to general p content models.
Allowed p as alternative to statusp in status.
Added non-null system IDs to external parameter entity declarations.
(Modified the SGML Open table module to make it XML-compliant.)
(Modified the character entity module.)
1997 September 30
Added character entity module and added new entities.
Removed p from appearing directly in self; created %p.mix;.
Added inform-div (non-normative division) element.
Fixed xtermref comment to mention HREF, not ref.
Extended orglist model to allow optional affiliation.
Modified author to make affiliation optional.
Added %speclist.class; and %note.class; to %obj.mix; and %p.mix;.
Added %note.class; and %illus.class; to %termdef.pcd.mix;.
Added unused HTML elements.
Put empty system ID next to public ID in entity declarations.
1997 September 14
Changed main attribute of xtermref from def to href.
Added termdef.class to label contents.
1997 September 12
Allowed term element in general text.
Changed bibref to EMPTY.
Added ref.class to termdef.pcd.mix.
1997 September 10
Updated FPI.
Removed namekey element and put key attribute on name element.
Made statusp element and supporting entities.
Added slist element with sitem+ content.
Required head on scrap and added new bnf subelement.
Added an xnt element and allowed it and nt in regular text and rhs.
Removed the ntref element.
Added back the com element to the content of rhs.
Added a key attribute to bibl.
Removed the ident element.
Added a term element to be used inside termdef.
Added an xtermref element parallel to termref.
Beefed up DTD comments.
Chapter 2. Common Attributes
This chapter describes the markup design for attributes that appear on multiple element types in substantially similar form.
Attributes Appearing on Every Element
The following attributes are truly "common"; they are available on every element type and have the same basic meaning everywhere.
id Attribute
Description
The id attribute is for uniquely identifying an element so that it can be linked to from elsewhere. The id attribute is declared as type ID.
The id attribute appears on every element. Its value is optional on most elements; however, a value is required on the following elements because they are always meant to serve as the target of a link:
| issue |
| wfcnote |
| vcnote |
| constraintnote |
| prod |
| termdef |
The %common.att; entity is used for those elements that don't require an id attribute, and the %common-idreq.att; entity is used for those elements that do require an id attribute.
Processing Expectations
ID values may be linked to; each linking element has its own processing expectations.
Rationale
IDs are generally useful in document management. Thus, they are made available on every element, just in case. For those elements that generally serve as targets of links, IDs are made mandatory.
Note that an attribute with type ID can be used both by IDREF attributes and by XPointers. The unique identification of an element does not presume a linking solution.
role Attribute
Description
The role attribute is for extending an element type by giving it an additional descriptive keyword, which a stylesheet can act on if necessary. The role attribute is declared as NMTOKEN. The %common.att; and %common-idreq.att; entities both contain role, in optional form.
Rationale
Roles help extend the life of a DTD between revisions and serve as a way to prototype new DTD extensions.
Note that the XMLspec DTD does not prescribe values for, or dictate usage of, the role attribute in any way. This attribute is intended for extensions to the "official" application. Thus, where an element type is expected to be subclassed on a regular basis, it is given an additional non-role attribute to serve this purpose.
diff Attribute
Description
The diff attribute indicates whether a particular element has changed since the last version of the document, which a stylesheet can act on if necessary. When a value is not provided for an element, it should inherit a value from its parent. If the root element has no value supplied, assume "off". The diff attribute can have one of four values: "add" (the element was added), "chg" (the element or its content was changed), "del" (the element was deleted), or "off" (even though a higher-level element has one of the other three values, this subelement has not changed). The %common.att; and %common-idreq.att; entities both contain diff, in optional form.
Processing Expectations
Difference values may or may not be operated on by stylesheets. For example, changed and added content may be presented in a different color or emboldened, and deleted content may have its text struck through or may be suppressed entirely. Alternatively, the values may be used to control marginal change bars.
Rationale
This attribute is not intended to take the place of a full code versioning or content management system; rather, difference values will help specification authors manage the process of issuing new revisions and accepting comments. Currently, some specification authors use differencing tools to compare the generated HTML versions and produce difference formatting. This markup will allow them to reflect the differences directly in the XML form, which is sometimes used as a final form for viewing.
Attributes Appearing on Selected Elements
The following attributes each appear on a few similar elements, and generally have similar meaning in each case.
See the section called HTML-Style Table (table) in Chapter 4 for information about the common attributes associated with tables.
Key Attribute
Description
The key attribute provides a string that can be used in sorting, indexing, and general description, when it is suspected or known that the element content won't suffice.
The key attribute appears on the following elements:
| name |
| bibl |
Processing Expectations
The value of the attribute is used in sorting, indexing, or generating cross-reference text. See the sections on the individual elements for more information.
Rationale
It was felt that a subelement solution to the problem of sorting (in the case of name) was not ideal, because you need to surround some existing element content with the sorting subelement, and the existing content may not be suitable for sorting. (This is the same problem that index-term markup has.) We decided that an attribute would be more effective and less intrusive.
Definition Attribute
Description
The def attribute points to the element where the relevant definition can be found, using the IDREF mechanism. The %def.att; parameter entity is used for optional def attributes (of which there are currently none), and the %def-req.att; parameter entity is used for required def attributes.
The def attribute appears on the following elements, and is required on all of them:
| wfc |
| vc |
| constraint |
| nt |
| termref |
Processing Expectations
The content of this element should allow the user to link to the definition.
Rationale
The IDREF mechanism was used for now, until the XPointer #id(xxx) mechanism is more widely supported.
Though %def.att; isn't used for now, it's coded in case it's needed later.
Reference Attribute
Description
The ref attribute points to the element where additional information can be found, using the IDREF mechanism. The %ref.att; parameter entity is used for optional ref attributes (of which there are currently none), and the %ref-req.att; parameter entity is used for required ref attributes.
The def attribute appears on the following elements, and is required in all cases:
| bibref |
| specref |
| prodrecap |
Processing Expectations
For the "ref" elements, the content of the element should allow the user to link to the additional information. For the "recap" element, the link should embed the content of the target at the point of reference (much like an XLink "embed", though XLink is not being used here yet).
Rationale
The IDREF mechanism was used for now, until the XPointer #id(xxx) mechanism is more widely supported.
Though %ref.att; isn't used for now, it's coded in case it's needed later.
XLink-Related Attributes
Description
A set of parameter entities helps to manage the XLink-related attributes. The %simple-xlink.att; entity sets up the xmlns:xlink and xlink:type attributes, which declare the following element types to be XLink simple links:
| bibl |
| graphic |
| loc |
| titleref |
| xnt |
| xspecref |
| xtermref |
The %href.att; and %href-req.att; entities set up the href attribute (in optional and required forms), which allows most of the simple XLink elements to point to their targets. When a value for href is supplied (as it will be in all the required cases), The simple links will be traversable. The href attribute is available on the following elements:
| bibl (optional) |
| loc |
| titleref (optional) |
| xnt |
| xspecref |
| xtermref |
Conformance Note: Because the current Working Draft of the XLink specification has removed certain features, proper usage now requires that XLink-related attributes have a namespace prefix. However, because this would require a disruptive backwards-incompatible change, the eight simple XLink elements in XMLspec are not quite conforming. In a future version, the seven elements using href will be changed to have a prefix, and the graphic element (which has a source attribute) will need to switch to a prefixed href attribute.
Several parameter entities are set up for convenience of applying XLink behavior semantics. The %auto-embed.att;, %user-replace.att;, and %user-new.att; entities set up the XLink show and actuate attributes. The simple XLink elements have these settings:
Processing Expectations
See the table above. For detailed information about processing expectations and how to distinguish among the various XLink elements, see the section called Linking Relationships in Chapter 6.
Chapter 3. Document Hierarchy and Metadata Structures
This section describes the major document hierarchy structures:
| spec |
| header |
Overall Specification Structure (spec)
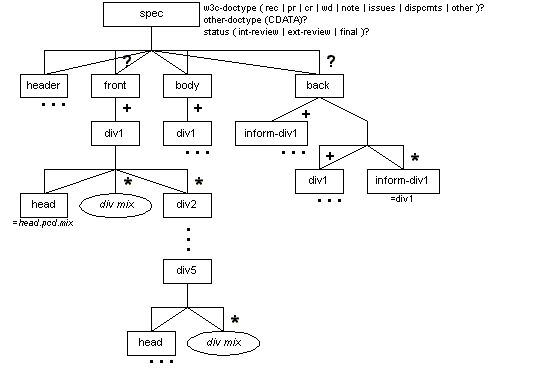
Description
The spec element contains, in order, a header; an optional front; a body; and an optional back.
The header provides metadata about the specification document (see the section called Specification Header (header) for more information). The front matter is for prefatory material. The body matter is primary content. The back matter is supplementary content. All three are organized into divisions.
The elements front and body contain one or more div1 elements. The main element for structuring content is div1, the equivalent of a preface, chapter, or appendix. It can be subdivided to four additional levels, down to div5. At each level, the division contains a head (title), optionally followed by a mixture of standalone elements (see Table 7-1), optionally followed by the next level of subdivision (except in the case of div4).
The back element contains div1 and/or inform-div1 (non-normative or informational division) elements. If both are present, the normative divisions must appear first. The back element cannot be empty.
Attributes
In addition to the common attributes, the spec element has three unique attributes:
- w3c-doctype
-
Indicates the type of document, so that the appropriate stylesheet or workflow routing can be applied. It can optionally have a value of "rec" (Recommendation), "pr" (Proposed Recommendation), "cr" (Candidate Recommendation), "wd" (Working Draft), "note" (Note), "issues" (Issues List), "dispcmts" (Disposition of Comments), or "other". It should not generate any text (such as the "REC-" or "NOTE-" prefix on the W3C designation content). It has no default. If this value is "other", other-doctype should be filled in.
- other-doctype
-
If w3c-doctype is "other", this value should be filled in with a keyword chosen or negotiated by the document authors and rendering application developers. It has no default.
- status
-
Indicates the stage of review of the document. It has no default.
Processing Expectations
Divisions are expected to be numbered, and a report of the numbers and heads should normally be made into a Table of Contents before any front content.
The w3c-doctype attribute should not be used to generate any text (such as the "REC-" or "NOTE-" prefix on the W3C designation content). The value of the status attribute might affect the stylesheet's treatment of editorial notes (for example, whether to output them).
Rationale
Originally, divisions went down to four levels total (to div4), but the MathML specification required one more level.
Elements serving the same function were merged to make a cleaner design.
The original text element, which wrapped all the non-header content, was removed because it didn't add anything to the structure, and its meaning ("a text") doesn't seem very relevant to W3C specifications. The original header contents have been consolidated under the header element, which meant that the original front element was no longer required because its titlepage contents have been done away with. The original backtabs element was removed, as agreed.
The original type attributes on the division elements were removed, as agreed.
Here is where it becomes apparent that the original "special lists" were removed from their special place in the division content models.
Specification Header (header)
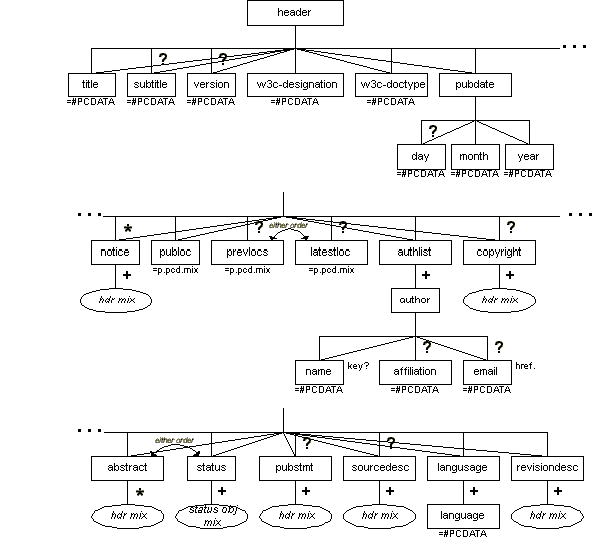
Description
The header contains an ordered series of metadata elements:
- title
-
The title of the technical report, for example, "Extensible Cheese Language (ECL)".
This was previously the wd-title element. It contains character data (see Table 7-2).
- subtitle (optional)
-
The subtitle of the technical report, if it has one. It contains character data (see Table 7-2).
- version (optional)
-
The version of the technical report, for example, "Version 4.0". It contains character data (see Table 7-2).
- w3c-designation
-
The code by which the technical report is known in URIs and such, for example, "WD-xcl-991231".
This was previously the wd-num element. It contains character data (see Table 7-2).
- w3c-doctype
-
The full name for the type of W3C technical report, for example, "W3C Working Draft" or "W3C Note". It contains character data (see Table 7-2).
- pubdate
-
The day (optionally), month, and year of publication of the document, separated out into day, month, and year elements. This should be the date on which the final text has been handed over to the W3C for official publication. Note that in internal interim drafts, you may want to provide a notice explaining the situation. The day, month, and year elements contain character data (see Table 7-2).
This was previously the wd-date element.
- notice (optional and repeatable)
-
A generic notice to readers, for example, "This draft is for public discussion." You can add as many notices as are required.
The notice element contains a mixture of standalone elements (see Table 7-1).
- publoc
-
The one or more Web resources corresponding to the different published forms (for example, XML, HTML, and PostScript) of this technical report. It contains character data and phrase-level elements (see Table 7-2), typically just one or more loc elements.
This was previously the thisver element.
- prevlocs (optional; can appear after latestloc)
-
The one or more Web resources corresponding to the previously published versions of this technical report. It contains character data and phrase-level elements (see Table 7-2), typically just one or more loc elements. If there are no previous versions, the prevlocs element itself should not be provided.
This was previously the previousver element.
- latestloc (optional; can appear before prevlocs)
-
The one or more Web resources corresponding to the latest version of this technical report. It contains character data and phrase-level elements (see Table 7-2), typically just one or more loc elements.
This was previously the latestver element.
- authlist
-
The list of editors contributing to the document. It contains one or more author elements, each of which contains a name (has an optional key attribute), followed by an optional affiliation, followed by an optional email. The last requires an href attribute. The name, affiliation, and email elements contain character data (see Table 7-2).
This was previously the authors element. The affiliation element is optional because some editors may not be affiliated with any organization. The email element is optional to help avoid spamming of the editors.
- copyright (optional)
-
A copyright notice. W3C now requires that specifications have copyright notices.
The copyright element contains a mixture of standalone elements (see Table 7-1). Note that its content should be "cooked," that is, the author should not rely on a rendering process to produce a copyright symbol, punctuation, or other style elements that might make up a proper copyright notice. These should be provided directly in the XML source.
- abstract (can appear after status)
-
A brief description of the document contents. It contains a mixture of zero or more standalone elements (see Table 7-1). Putting the abstract after the status statement is deprecated.
- status (can appear before abstract)
-
A description of the status of the document, following W3C rules. This element contains a normal mixture of standalone elements (see Table 7-1). Putting the status statement before the abstract is deprecated.
- pubstmt (optional)
-
A brief bibliographic statement about this publication according to Text Encoding Initiative rules, for example, "Burlington, Seekonk, et al.: World-Wide Web Consortium, XML Working Group, 1999." It contains a mixture of standalone elements (see Table 7-1), so the example text would have to be inside a p.
- sourcedesc (optional)
-
A brief statement about the original source for this document, for example, "Created in electronic form." It contains a mixture of standalone elements (see Table 7-1), so the example text would have to be inside a p.
- langusage
-
A catalog of languages used in the document. It contains one or more language elements, each of which might have an id attribute on it so that it can be referenced from prod elements. The language element contains character data (see Table 7-2).
- revisiondesc
-
A catalog of changes made to the document, in more or less rigorous form. It contains a mixture of zero or many standalone elements (see Table 7-1); typically, an slist element would be used, with its sitem elements corresponding to individual change descriptions and dates.
Processing Expectations
The various parts of the header are used in creating a title page that follows W3C rules. The content of some elements is used twice or more, while the content of other elements is suppressed from display. Some of the elements (such as publoc) should cause heading text to be generated.
The element name has, in addition to the common attributes, a key attribute, which optionally provides a sort-key string for use in collecting and outputting names mentioned in a document.
The element email has common attributes and a required href attribute.
Rationale
The content of publoc, prevlocs, and latestloc was broadened so that the various published forms and auxiliary resources of a specification can be mentioned. For example, the XML Schema specifications refer not only to the XML source and the HTML published form, but also to the special stylesheet used to produce the output and normative DTDs and schemas associated with the specification.
W3C publication guidelines require the abstract to come before the status statement; it is allowed after the status statement only for backwards compatibility with V2.0 of the DTD.
The content model of header has been parameterized so that the metadata can be customized, subsetted, and extended as necessary.
The metadata elements that were in the original DTD were cherry-picked, based on the data found in a survey of typical W3C technical report cover and title pages. Where an element is optional, generally content is required inside it to ensure that it's not abused or accidentally left empty. The version element was made optional for Version 2.0 of the DTD because versions are not required on Working Drafts.
The subtitle element was added unilaterally because it seemed like a generally good idea.
The w3c-doctype element should perhaps more properly be an attribute with a small set of enumerated values, if the DTD gets wider use and the types are quantified. So far, the element formulation has stood us in good stead because we began to publish "notes" in addition to "working drafts" and did not need to make any stylesheet changes.
The pubdate contains, in order, day (optional), month, and year elements so that different forms of the date could be published in different locations: "31 December 1999" on the title page and "December 1999" on the cover, for example. The content model of pubdate has been parameterized so that a different form of date information can be supplied if necessary.
The status element originally required the statusp variant of the p element because Dan indicated that HTML-style links should be allowed only where they're appropriate. Because inclusions are not allowed in XML and we wanted this DTD to be XML compliant, the only way to allow status to contain loc was to give it a special subelement where loc is allowed. However, we've since found that it's very difficult to excise all need for HTML-style links in the body of the spec, so we ended up extending p to allow it to contain loc and, in preparation for losing statusp entirely, allowed p inside status. Now, statusp is obsolete and has been removed from the DTD.
It was decided to make the copyright element contain "cooked" content for simplicity and so that it is most likely that various renderings of the document will contain the correct copyright notice, whole and uncut. It is expected that if the XML source itself needs to have explicit copyright protection, an XML comment (in each file making up the document) is the right tool for the job.
Chapter 4. Standalone Element Structures
Following are the standalone element structures ("paragraph-level elements"), which make up the bulk of the content of divisions in a technical report. These structures fall into classes, as follows. (Note that the DTD makes slightly finer distinctions than these, for purposes of managing content models.)
-
Paragraphs
-
Regular lists
-
Special lists
-
Notes
-
Illustrations
Paragraphs (p)
Following is the sole member of the paragraph class:
| Paragraph |
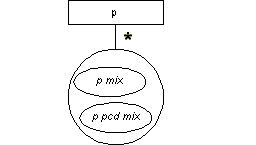
Description
The p element is a general-purpose paragraph which can contain regular character data, phrase-level elements, and some nested standalone elements (see Chapter 7).
Attributes
The p element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
This element should be presented as vertically set off from other surrounding elements, and its inline text contents should be wrapped as appropriate to fit in the line size available.
Rationale
Originally, only p was made available, and it contained loc . Dan requested that the loc element not be made generally available, because properly these should only occur in the status section of a technical report, and statusp was therefore created because SGML exceptions, which would have allowed for a clean implemention of the restriction, aren't available in XML-compliant DTDs. However, later all the editors came to the conclusion that it was too restrictive not to allow loc anywhere else, and we added loc to regular paragraphs and p to the status section.
The statusp element was a special version of a paragraph that was created to allow loc (see the section called URI Reference (loc) in Chapter 5) inside it. A statusp contained a mixture of one or more %statusobj.mix; and/or %statusp.pcd.mix;. However, this element has finally been removed for simplicity, since p can do the job itself.
Regular Lists
The following are the members of the regular list class:
| Unordered list |
| Ordered list |
| Simple list |
| Glossary list |
Unordered List (ulist) and Ordered List (olist)
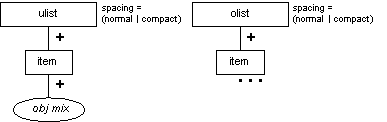
Description
The ulist element identifies unordered lists (for example, with items indicated with bullets) and the olist element identifies ordered lists (for example, with items indicated with arabic numbers). Both ulist and olist contain one or more item elements, which identifies a list item. An item contains one or more standalone elements (see Table 7-1). Thus, a list item intended to contain a simple text string must first contain a paragraph.
Attributes
The ulist, olist, and item elements have the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition to the common attributes, the ulist and olist elements have one unique attribute:
- spacing
-
Specifies the vertical spacing between the list items. Use "normal" to get normal vertical spacing for items; use "compact" to get less spacing. The default is dependent on the stylesheet.
Processing Expectations
List style and formatting are not strictly dictated. An unordered list at the top level (not nested in another unordered list) should generate a bullet for each item. A nested unordered list should typically generate a distinct bullet (e.g., unfilled vs. filled). An ordered list at the top level (not nested in another ordered list) should generate sequenced numbers for its item. A nested ordered list should typically generate a distinct numbering style (e.g., lowercase roman vs. arabic).
Rationale
The ulist element was previously list type="bullets". The olist element was previously list type="number". The element type was split out to achieve greater content model control, and the names were chosen for consistency.
Simple List (slist)
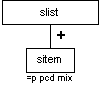
Description
The slist element identifies a simple list, in which the items are presumed to contain only a small word or phrase. The slist contains one or more sitem elements, which contains character data and phrase-level elements (see Table 7-2). Simple list items are unlike regular list items in that the simple version can't contain standalone elements.
Attributes
The slist and sitem elements have the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
List style and formatting are not strictly dictated. Typically, simple list items are each on their own line, with no bullet or other explicit enumeration.
Rationale
The slist element was previously list type="simple". The element type was split out to achieve greater content model control, and the name was chosen for consistency.
Glossary List (glist)
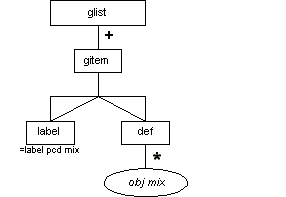
Description
The glist element identifies a glossary list, in which terms or keywords are given a definition. The glist element contains one or more gitem elements. The gitem element is a pair of label and def. A label contains character data and phrase-level elements (see Table 7-2), and a def contains standalone elements (see Table 7-1)
Attributes
The glist, gitem, label, and def elements have the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
List style and formatting are not strictly dictated. Typically, glossary list items are formatted as classic hanging-indent or two-column definition lists.
Rationale
The gitem element is a container for paired items in glist elements. A container wasn't previously available; this should make formatting and other processing (such as sorting) easier.
The def element was previously the item element used in a "paired" context. It's easier to process these two uses of "items" if they have distinct element types.
The glist element was previously list type="gloss". The element type was split out to achieve greater content model control, and the name was chosen for consistency.
Special Lists
The following are the members of the special list class:
| Bibliography list |
| Organization list |
These elements are available in divisions and %obj.mix; content, but are not available inside (for example) paragraphs.
Bibliography List (blist)
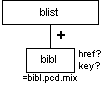
Description
The blist element identifies a bibliography list. It contains one or more bibl elements, each of which optionally functions as a hypertext reference to the referred-to resource through its href attribute.
The bibl element contains character data and phrase-level elements (see Table 7-2). Its content model does not constrain authors to the use of a particular bibliographic format.
Attributes
The blist and bibl elements have the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition to the common attributes, the bibl element has the following semi-common attributes:
| key (see the section called Key Attribute in Chapter 2) |
| href (see the section called XLink-Related Attributes in Chapter 2) |
Processing Expectations
List style and formatting are not strictly dictated. Typically, bibliography list items are formatted on their own line, and may use a definition list format by putting the value of the key attribute as the "term."
Organization List (orglist)
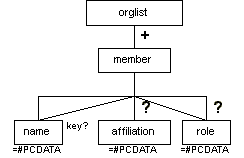
Description
The orglist element identifies an organization list (for example, a list of Working Group or Interest Group members). It contains one or more member elements. A member contains, in order, name, an optional affiliation, and an optional role.
The name, affiliation, and role elements contain character data (see Table 7-2).
Attributes
The orglist, member, affiliation, role, and name elements have the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
The name element also has the following semi-common attribute:
| key (see the section called Key Attribute in Chapter 2) |
Processing Expectations
List style and formatting are not strictly dictated. Typically, organization list items are formatted as a "textual list," wrapped in the content of a paragraph with items and their constituent parts separated by appropriate punctuation.
Rationale
The orglist element was previously the wglist element. The member element was previously the wgm element. The names were changed for consistency and clarity.
Notes
The following are the members of the note class:
| Regular note |
| Issue |
| Well-formedness constraint note |
| Validity constraint note |
| Generic constraint note |
Regular Note (note)
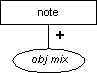
Description
The note element is for admonitions to readers. It contains one or more standalone elements (see Table 7-1).
Attributes
The note element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
Although this element type was originally note place="inline", it was never used in its inline form as far as we can tell; plain notes should be formatted as vertically set-off content with some kind of generated "Note" heading.
Rationale
This was previously note place="inline". The element was split out for greater content model and linking control. We don't expect that notes other than "constraint notes" will be used very often.
Issue (issue)
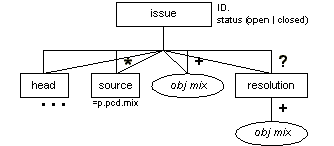
Description
The issue element is for the text of outstanding issues related to the technical report. It contains an optional head, an optional series of source elements that describe the communication (typically a document or email message) in which the issue was raised, a mixture of one or more standalone elements (see Table 7-1), and an optional resolution element.
Attributes
The issue element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id (required) |
| role |
| diff |
In addition to the common attributes, it also has the status attribute, which can have a value of "open" (the default) or "closed". It it possible for an issue with no resolution provided to be closed.
Processing Expectations
Issues should be formatted as vertically set-off content with some kind of generated "Issue" heading, the issue ID, and the issue head (if any) prominently displayed. The source and resolution information should be given generated heading as necessary. It is expected that an xref element referring to an issue will refer to it by its issue ID.
The status attribute may control, for Recommendation-track documents, whether the issue is output at all; closed issues could be suppressed. Issues-list and errata documents might want to print all issues.
Rationale
James added this element for his own purposes in working on XSL, and it seems like a generally good idea.
Constraint Notes (wfcnote, vcnote, and constraintnote)
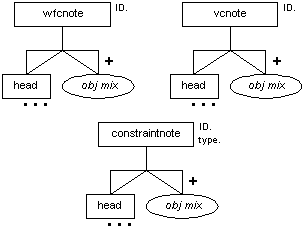
Description
The wfcnote element identifies a well-formedness constraint note and the vcnote element identifies a validity constraint note. The constraintnote element identifies a generic constraint note. All three contain, in order, a head followed by one or more standalone elements (see Table 7-1).
All three elements must each have an id attribute specified so that it can be pointed to from a wfc, vc, or constraint element, respectively, in a production (see the section called Code Scrap (scrap)).
Attributes
The wfcnote, vcnote, and constraintnote elements have the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id (required) |
| role |
| diff |
In addition, the constraintnote element has a unique attribute, type, which the author must fill in to indicate the type of constraint being described.
Processing Expectations
These note elements should be displayed vertically set off, with a generated heading something like "Well-Formedness Constraint" or "Validity Constraint" followed by the specific head provided. The specific head should also be reproduced as part of the display of the related wfc, vc, or constraint elements. The type attribute on constraintnote should be used to trigger the appropriate generated heading and to contribute to the appearance of the related constraint elements.
Rationale
These elements now require an ID so that a constraint element can link to a constraint note element from inside prod. There is no point having a note if there is not at least one corresponding constraint in a production pointing to it.
The two specific elements were previously note type="wf-check" and note type="v-check". The elements were split out for greater content model and linking control.
The generic constraint note element was created because we foresaw a need for additional kinds of constraints when the Namespaces in XML draft was written. (It invented "namespace constraints.") In order to avoid constantly needing to update the DTD to add new constraint types, we chose this solution. Because of the importance of well-formedness and validity constraints to base XML, these specialized types were retained.
Illustrations
The following are the members of the illustration class:
| Code example |
| Example |
| Graphic |
| Code scrap |
| HTML-style table |
| IDL definitions |
| Function prototype |
Code Example (eg)
Description
The eg element identifies technical examples. It contains character data and phrase-level elements (see Table 7-2).
Attributes
The eg element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
It also has an xml:space attribute with a #FIXED value of "preserve" to indicate that all white space inside the example should be retained by applications.
Processing Expectations
The element should be displayed as vertically set off (even if it appears inside a paragraph) and be given a monospaced font to ensure that characters and white space inside the example line up correctly.
Rationale
We expanded its content a bit from just #PCDATA, so that it can contain footnote and highlighting markup if necessary.
Example (example)
Description
The example element identifies code examples accompanied by explanations. It contains an optional head and one or more standalone elements (see Table 7-1).
Attributes
The example element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The element should be displayed as vertically set off (even if it appears inside a paragraph), with a generated "Example" heading of some kind, followed by the supplied head text (if any). Typically, in HTML form it is displayed as a table with one column and a background color that distinguishes it from the surrounding content..
Rationale
The XML Schema specifications, among others, use this heavily in the form of a note with a role on it, so it seemed important enough to have its own element.
Graphic (graphic)
Description
The graphic element is used to reference external graphic files. The graphic data must reside at the location pointed to using the source attribute. The graphic element is declared EMPTY.
Attributes
The graphic element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition to the common attributes, the graphic element has the following unique attributes:
- source
-
A required hypertext reference pointing to the graphic data content to be displayed. Other related attributes are also present. See the section called XLink-Related Attributes in Chapter 2 for more information.
- alt
-
An optional alternate string to display if the graphic data cannot be displayed or viewed.
Processing Expectations
The data content pointed to by the source attribute of the graphic element should be presented in place. The values for the XLink behavior attributes show and actuate are fixed to be "embed" and "auto", respectively.
Rationale
There seems to be no need for a formal figure with a caption or head, nor for an additional layer of container element to allow for the later addition of graphic metadata.
XLink is the obvious mechanism for pointing to the graphic data content, but for now, the graphic element is not strictly XLink-conforming because the ability to do attribute remapping has gone away. The fixed-value attribute xml:attributes on this element was therefore removed.
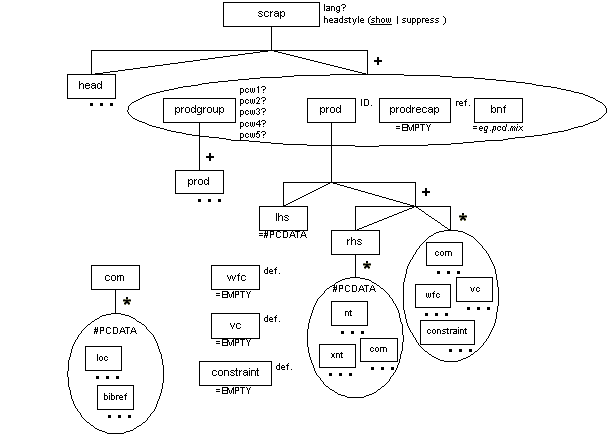
Code Scrap (scrap)
Description
The scrap element identifies a code scrap containing language productions. It contains, in order, a head element containing character data, followed by a free mixture of one or more bnf, prod, prodgroup, and prodrecap elements.
The main element for structuring productions is prod. It contains, in order, an lhs (left-hand side) element identifying the nonterminal that is being defined, followed by one or more groups of rhs (right-hand side fragments) and an optional mixture consisting of com (commentary on the production), wfc (indications of well-formedness constraints), vc (indications of validity constraints), and constraint (generic indications of language constraints). It has a required id attribute so that specref cross-references (see the section called Specification Reference (specref) in Chapter 5) and nt mentions of nonterminals (see the section called Nonterminal Reference (nt) in Chapter 5) can link to it.
The prodgroup element groups productions within a single scrap.
The bnf (Backus-Naur Format) element is for "raw," unformatted productions without internal markup. It contains the same mixture of character data and phrase-level elements as eg does (see Table 7-2).
The prodrecap element links to an existing production for the purpose of reproducing it in this location for the reader's convenience. It is empty and has a required ref attribute to the desired production.
The wfc, vc, and constraint elements are empty. These indications of constraints must each use their required def attribute to link to an actual wfcnote, vcnote, or constraintnote element that defines it.
Attributes
The scrap, head, bnf, prod, prodgroup, prodrecap, lhs, rhs, com, nt, xnt, wfc, vc, and constraint elements all have the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id (an attribute value is required for prod) |
| role |
| diff |
In addition to the common attributes, the wfc, vc, and constraint elements have the following semi-common attribute:
| def (required; see the section called Definition Attribute in Chapter 2). |
In addition to the common attributes, the prodrecap element has the following semi-common attribute:
| ref (required; see the section called Definition Attribute in Chapter 2). |
In addition to the common attributes, the scrap element has two unique attributes:
- lang
-
An optional IDREF link to a description of the language used, found in a language element in the header (see the section called Specification Header (header) in Chapter 3).
- headstyle
-
A presentational attribute to control the output of the scrap head. The default is "show", the other possible value is "suppress". The head should be suppressed only if the scrap appears in like-named section and there is no other content in the section, such that the section head and the scrap head would merely repeat each other.
In addition to the common attributes, the prodgroup element has several unique attributes:
- pcwn
-
Presentational attributes to control the width of the "pseudo-table" columns used to output groups of productions. The first column is pcw1. It can contain up to four more columns, down to pcw5. Values are optional to supply.
Processing Expectations
Each scrap is expected to be displayed vertically set off, with its head used as the label for the whole scrap. Each production should be numbered, and in some presentations, it may be appropriate to produce a "table of productions" at the front that lists the scrap heads, production numbers, and the nonterminals (the content of the lhs) they define. The style of production we have been using involves the generated output of a ::= LHS/RHS equivalence separator. Comments (com) are typically displayed between BNF comment delimiters to the right of each RHS fragment, and possibly italicized. Each RHS fragment is displayed on a separate line. The wfc, vc, and constraint elements should generate in place either "WFC:" or "VC:" or text corresponding to the linked constraintnote element's type attribute, followed by the head of the note they link to. If the scrap element's headstyle attribute is set to "suppress", the scrap head should be suppressed from output.
Rationale
We considered several different "depths" of production markup model, and settled on the current model as the best balance of functionality and presentational control. Modeling EBNF exactly would have required a very heavy markup burden, which most of the editors were not willing to live with, as well as a presenting a difficult formatting challenge, so we compromised by having (for example) several rhs elements per lhs to correspond to each display line.
The prodgroup element and its attributes were added to solve a thorny formatting problem involving the output of tables.
In general, the design here shows very clearly the tension between the design principles of presentation independence and efficient W3C document production.
Originally, the content model for a scrap called for either a bnf element or one or more prod elements or one or more prodgroup elements. This strong separation of each type of scrap content began to seem unwarranted when the prodrecap element was added, since it seems eminently possible to format the result even when all four subelements are mixed freely. Thus, the content model was broadened.
HTML-Style Table (table)
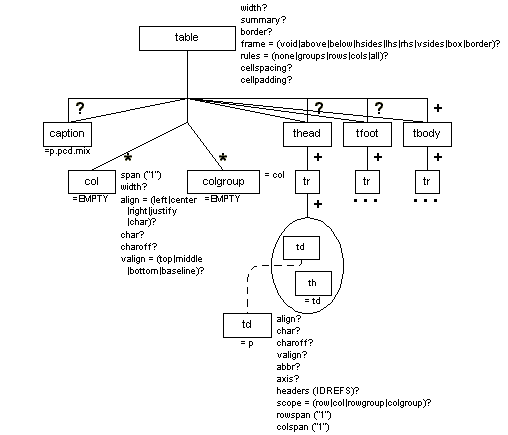
Description
The table element is a full HTML Version 4.0-style table.
Note that the implementation of HTML 4.0 tables in the XMLspec DTD is a new one, with different parameterization, fewer comments, changes to make the DTD fragment compatible with XML, and slight changes to the model. Following are the significant changes made:
-
The names of the table and table body elements were changed back from htable and htbody to table and tbody.
-
The common attributes were added to all the table elements (see the section called Attributes Appearing on Every Element in Chapter 2):
id role diff
-
All the markup names (element types, attribute names, attribute values, and so on) were made lowercase, to help in manual input since XML is case sensitive.
-
The content mixture used for paragraphs was also used for the content of the th and td elements (see Table 7-1 and Table 7-2).
-
The full-SGML OMITTAG flags were removed.
-
Uses of the full-SGML NUMBER attribute type were changed to NMTOKEN.
-
The HTML common, reserved, and datapagesize attributes were removed.
For a full description of the features of HTML 4.0 tables that have been retained in XMLspec, see http://www.w3.org/TR/REC-html40, which is the normative reference for table structure and processing expectations.
Note: The Version 4.0 model removes some attribute defaults that were in force in the simplified 3.2 model used previously. In general, if you want a particular value, make sure to set it yourself.
Rationale
At first, the DTD offered only SGML Open Exchange tables, for which DSSSL formatting support already existed. However, HTML is the primary output for W3C documents, and HTML table formatting was written in DSSSL, so we added the HTML table model as well. More recently, we removed the SGML Open model because only the HTML model was actually being used.
We can easily add the SGML Open table model again if it is ever needed.
Most recently, we switched from an extremely simple HTML-style table model to full HTML 4.0 tables on request from the DOM group. This was to avoid unnecessary transformations in converting to HTML and to allow authors to take full advantage of the geometrical table capabilities that HTML 4.0 offers.
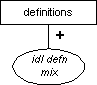
IDL Definitions (definitions)
The definitions element structure was contributed by the W3C DOM Working Group. No detailed descriptions, processing expectations, or design rationales have been supplied. This section offers only a structural description.
Note: This model may change in backwards-incompatible ways in the future, to account for the manner in which the markup is actually being used by the DOM group. See the XML source for the DOM Recommendation for examples, and use this model with caution.
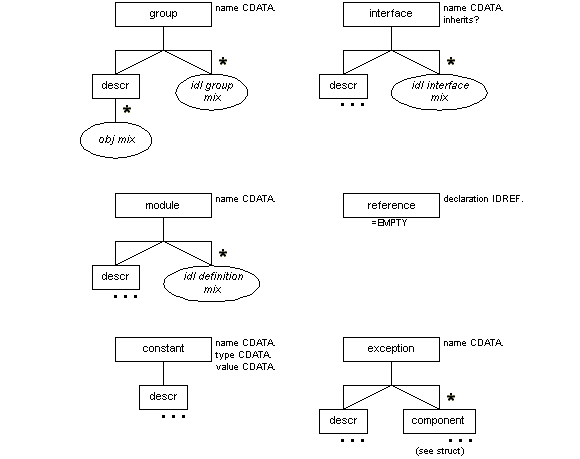
Following are the IDL element classes. Every class entity has the naming scheme %name.class;, and has an empty %local.name.class; entity in it for customization purposes.
-
Descriptive elements (%idl-desc.class;)
Paragraph (p) Note (note) -
Type definition elements (%idl-tdef.class;)
typedef constant exception reference group -
Module/interface elements (%idl-mod.class;)
module interface -
Struct elements (%idl-struct.class;)
struct enum sequence union typename -
Method/attribute elements (%idl-meth.class;)
method attribute
Table 4-1 shows the element mixtures built up out of the IDL-related elements.
Table 4-1. IDL-Related Mixtures
| desc | tdef | mod | struct | meth | |
|---|---|---|---|---|---|
| %idl-grp.mix; (used in group) | X | X | X | X | X |
| %idl-defn.mix; (used in definitions, module) | X | X | X | ||
| %idl-intfc.mix; (used in interface) | X | X | X | ||
| %idl-type.mix; (used in typdef, component, case as mutually exclusive choices) | X |
The model for definitions is as follows.
The models for group, interface, module, reference, constant, and exception are as follows.
The model for typedef and its contents is as follows.

The models for method and attribute are as follows.
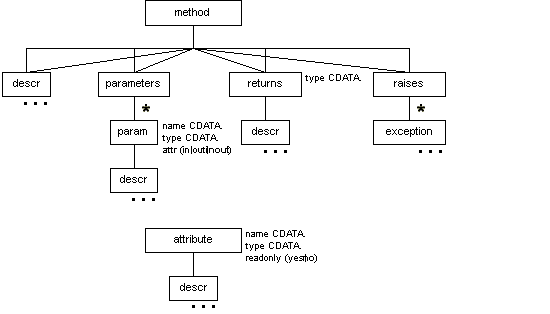
Function Prototype (proto)
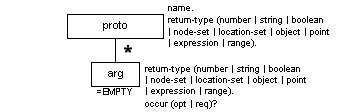
Description
The proto element structure was contributed by the W3C XSL Working Group. Only limited descriptions, processing expectations, and design rationales are provided here.
The proto element describes functions available in XSLT and similar languages. It contains a series of zero or more arg elements.
Attributes
The proto element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition to the common attributes, the proto element has the following unique attributes:
- name
-
The name of the function. A value is required.
- return-type
-
The type of value returned by the function. It is required; the value can be "boolean", "expression", "location-set", "node-set", "number", "object", "point", "string", or "range".
Processing Expectations
Each function prototype is expected to be displayed vertically set off, with the function name emphasized. It should be flanked on the left by the return type and on the right by a list of argument types. If a particular argument is optional, is should be indicated so. Depending on the language being described, the list is typically parenthesized and the argument types separated by commas, with optional arguments being followed by question marks.
Chapter 5. Phrase-Level Structures
Following are the phrase-level element structures ("inline-level elements"), which are typically used along with character data. These structures fall into classes, as follows. (Note that the DTD makes slightly finer distinctions than these, for purposes of managing content models.)
-
Annotations
-
Terms and definitions
-
Emphasized text
-
References
-
Technical
-
Editorial note
Annotations (footnote)
The footnote element is the only member of the annotation class.
Description
The footnote element serves as both a marker for the location of the footnote callout and a container for the footnote content. It contains one or more elements in the %obj.mix; mixture.
Attributes
The footnote element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
For print, the location of the footnote element should be given a generated superscripted number or symbol that serves as a callout, and the footnote content should be presented along with the callout at the bottom of the page. In online presentation, the footnote could be presented as a pop-up dialog box keyed to an icon placed at the location of the footnote element.
Terms and Definitions
The following are the members of the term/definition class:
| Defined term |
| Term definition |
Defined Term (term)
Description
The term element identifies a term being defined in text. It contains character data (see Table 7-2). It is mostly used as a substructure of termdef, though it may occasionally be used outside of a termdef context for an "informally" defined term. For information on cross-referencing a term, see the section called Term Reference (termref) and the section called External Term Definition Reference (xtermref).
Attributes
The term element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
This element should be given some sort of typographical emphasis, for example italics.
Rationale
This element exists mostly to allow control of the typographical emphasis, since the term attribute on termdef does the work of supplying a "canonical" form of the term for use in generating definitions. If the canonical term and the term as it appears in text are identical, there is some slight redundancy, but the overhead of using the canonical term in the flow of text (or modifying it if it's inappropriately pluralized or capitalized) isn't worth it.
Term Definition (termdef)
Description
The element termdef contains a term definition embedded in text. It contains a mixture of character data and phrase-level elements (see Table 7-2), including somewhere within it a mention of the term being defined (in a term element). Note that because the termdef element has mixed content, the presence of term within it can't be guaranteed by means of a validating XML processor. However, there is an editorial expectation that term will be present. (See issue 7 in the section called Issues in Chapter 1.)
Attributes
The termdef element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2). It must have an id attribute so that it can be linked to from termref elements ( the section called External Term Definition Reference (xtermref)).
| id (required) |
| role |
| diff |
In addition to the common attributes, termdef has one unique attribute:
- term
-
The canonical form of the term or phrase being defined must appear in this attribute, even if the term or phrase also appears in the element content in identical form (in the term element).
Processing Expectations
While no special behavior or formatting is required, there are some opportunities for clever definition handling. For example, the terms and definitions could be assembled into a generated glossary, or definitions could be given some sort of boxing or generated-text boundaries in running text.
Rationale
Because we wanted to continue to allow definitions in running text, the mixed-content solution was the only reasonable choice even though it means that the DTD can't ensure that proper markup has been used.
Emphasized Text
The following are the members of the emphasized text class:
| Emphasized text |
| Phrase |
| Quoted text |
| Subscripted text |
| Superscripted text |
Emphasized Text (emph)
Description
The emph element identifies text that should be given extra rhetorical emphasis. It contains character data (see Table 7-2).
Attributes
The emph element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The content of the emph element should be given typographical emphasis, typically italic or boldface.
Rationale
If not abused, this element can be useful, and its presence probably forestalls abuse of other elements that happen to produce typographical emphasis. Since it is expected to contain only a word or two of natural language, it need only contain #PCDATA.
Phrase (phrase)
Description
The phrase element identifies text that needs attribute values set on it, but is otherwise undistinguished from the surrounding text. It contains a mixture of character data and the same phrase-level elements that are allowed in paragraphs (see Table 7-2).
Attributes
The phrase element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The content of the phrase should be given no special typographical emphasis compared to the surrounding text, except as dictated by the attributes on the element. For example, a role or diff value could have an effect on presentation.
Rationale
This element was added to help manage the process of adding casual quotes. In an XML-aware environment, it is often easier to manage content in containers rather than as discrete symbols (for example, a left quote, then some text, then a right quote).
Quoted Text (quote)
Description
The quote element identifies text that needs "scare quotes." It contains a mixture of character data and the same phrase-level elements that are allowed in paragraphs (see Table 7-2).
Attributes
The quote element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The content of the element should be presented with quotation marks around it, as appropriate for the language of the text in the document.
Rationale
This element was added to help manage the process of adding casual quotes. In an XML-aware environment, it is often easier to manage content in containers rather than as discrete symbols (for example, a left quote, then some text, then a right quote).
Special-Script Text (sub and sup)
Description
The sub and sup elements are for subscripted and superscripted text. They contain character data (see Table 7-2).
Attributes
The sub and sup elements have the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The content of the sub element should be presented smaller and lower than the surrounding text. The content of the sup element should be presented smaller and higher than the surrounding text.
References
The following are the members of the reference class:
| Bibliography reference |
| URI reference |
| Specification reference |
| Term reference |
| Title reference |
| External specification reference |
| External term definition reference |
Bibliography Reference (bibref)
Description
The bibref element identifies a reference to a bibliography entry in a blist element in the current document. It is declared to be empty. It links to the bibl element that describes the resource; in other words, this is only an indirect reference to the resource.
Attributes
The bibref element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition to the common attributes, the bibref element has the following semi-common attribute:
| ref (required; see the section called Reference Attribute in Chapter 2) |
Processing Expectations
This element should generate, in square brackets, the value of the key attribute on the referenced bibl element (see the section called Bibliography List (blist) in Chapter 4).
Rationale
This element is allowed in a wide variety of places because (as noted in issue 3 in the section called Issues in Chapter 1) the proper way to refer to any resource is by means of a bibliography reference. It is empty so that the proper reference text can be generated automatically.
URI Reference (loc)
Description
The loc element identifies a World Wide Web resource by its URI and functions as a hypertext link to a resource, essentially the same as an HTML A element does. (Ideally, the content of the loc element will also mention the URI , so that readers of the printed version will be able to locate the resource.) It contains character data (see Table 7-2).
Typically, loc elements should be avoided anywhere in a specification in favor of bibref. See issue 3 in the section called Issues in Chapter 1 for more information.
Attributes
The loc element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition to the common attributes, it has the following semi-common attribute:
| href (required; see the section called XLink-Related Attributes in Chapter 2) |
Processing Expectations
In electronic presentation, the content of this element should be "hot" to allow a user to traverse the link to the referenced resource. In print presentation, there may or may not be typographical distinction.
Rationale
This element was added early on, before W3C policy seemed to have solidified on the issue. The element may now be obsolescent.
Its name was chosen before the decision to use URIs instead of just URLs in XML. Such a reference might specify a physical location, a universal identifier for the resource, or something partway between the two.
Specification Reference (specref)
Description
The specref element identifies a cross-reference to another location in the current specification. It is declared to be empty. It is intended to be used to link to a div (division), an item in an olist (numbered list item), a prod (language production), or an issue (specification issue) in the current specification.
Attributes
The specref element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition to the common attributes, it also has the following semi-common attribute:
| ref (required; see the section called Reference Attribute in Chapter 2) |
Processing Expectations
The specref element should generate a unique pattern of text depending on the cross-reference target:
-
For div, it should generate "Section sec-num.subsec-num, Title of the Section".
-
For item in olist, it should generate "item-number".
-
For prod, it should generate "[prod-number]".
-
For issue, it should generate "Issue issue-ID".
In electronic presentation, the generated text should be "hot" to allow a user to traverse the link to the referenced resource.
Rationale
Having this element be empty ensures that consistent and correct cross-reference text will be generated.
The original reason that this element is separate from xspecref is that this one uses the ID/IDREF method of linking and xspecref uses the XLink/XPointer method. However, even if this element later switches to XLink, it may still be useful to have two separate elements, since this one does not document a cross-document dependency and xspecref does.
Term Reference (termref)
Description
The termref element identifies a mention of a term that is defined elsewhere in the current specification; the mention also serves as a reference to the definition by linking to the termdef element that defines the term (see the section called Defined Term (term)). The termref element contains character data (see Table 7-2).
It is expected that not every mention will be marked up. If a particular term is used with regularity in a single passage or section, it is more reasonable to mark up only the first occurrence of that term within the passage or section.
Attributes
The termref element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition to the common attributes, it also has the following semi-common attribute:
| def (required; see the section called Definition Attribute in Chapter 2) |
Processing Expectations
In electronic presentation, the content of the element should be "hot" to allow a user to traverse the link to the referenced resource. In print presentation, typically it is given typographical distinction (such as italics).
Title Reference (titleref)
Description
The titleref element identifies a citation of the title of another work. A title reference can optionally function as a hypertext link to the resource that has this title. It contains character data (see Table 7-2).
The titleref element is typically expected to be used inside the bibl element, to supply the title of the work being identified in the bibliography entry. Note that both the bibl element and the titleref element can function as a hypertext link to the referenced resource; see issue 5 in the section called Issues in Chapter 1.
Attributes
The titleref element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition to the common attributes, it also has the following semi-common attribute:
| href (see the section called XLink-Related Attributes in Chapter 2) |
Processing Expectations
In electronic presentation, the content of this element should be "hot" to allow a user to traverse the link to the referenced resource. In all presentations, the title of the work will typically be rendered in italics.
Rationale
It is fairly clear that a means to mark up a reference to a title is appropriate, since at the very least such references are made to look different from their surroundings are aren't just "emphasized text." However, the hypertext function is less clearly needed. See issue 5 in the section called Issues in Chapter 1.
External Specification Reference (xspecref)
Description
The xspecref element is a reference to all or part of another W3C specification. It must hyperlink to the targeted resource. It contains character data (see Table 7-2).
Attributes
The xspecref element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition to the common attributes, it also has the following semi-common attribute:
| href (required; see the section called XLink-Related Attributes in Chapter 2) |
Processing Expectations
In electronic presentation, the content of this element should be "hot" to allow a user to traverse the link to the referenced resource. In print presentation, there may or may not be typographical distinction.
Rationale
The xspecref element was added in response to a need to make hyperlinks to "base" specifications from specifications that properly depend on them. For example, the XML specification develops some concepts that are used in the XLink specification. Since this is more than a simple citation to another resource but rather provides details on the dependency, it seems appropriate to make this different from a regular specref.
The original reason that this element is separate from specref is that specref uses the ID/IDREF method of linking and this element uses the XLink/XPointer method. However, even if specref later switches to XLink, it is still be useful to have two separate elements.
External Term Definition Reference (xtermref)
Description
The xtermref element identifies a mention of a term that is defined in another specification; the mention also serves as a reference to the definition by linking to the termdef element in the other specification that defines the term (see the section called Defined Term (term)). It contains character data (see Table 7-2).
Attributes
The xtermref element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition to the common attributes, it also has the following semi-common attribute:
| href (required; see the section called XLink-Related Attributes in Chapter 2) |
Processing Expectations
In electronic presentation, the content of this element should be "hot" to allow a user to traverse the link to the referenced resource. In print presentation, there may or may not be typographical distinction.
Rationale
The xtermdef element was added in response to a need to make hyperlinks to "base" definitions from specifications that properly depend on these definitions. For example, the XML specification defines some terms that are used in the XLink specification. Since this is more than a simple citation to another resource but rather provides details on the dependency, it seems appropriate to make this different from a regular termdef.
The original reason that this element is separate from termdef is that termdef uses the ID/IDREF method of linking and this element uses the XLink/XPointer method. However, even if termdef later switches to XLink, it is still be useful to have two separate elements.
Technical
The following are the members of the technical class:
| Attribute name |
| Attribute value |
| Code fragment |
| Element type name |
| Function |
| Keyword |
| Nonterminal reference |
| Variable |
| External nonterminal reference |
Attribute Name (att)
Description
The att element contains the mention of an attribute name in text. (Note that it is not the same and does not have the same purpose as the attribute element, used exclusively in the definitions element.) It contains a mixture of character data and phrase-level elements (see Table 7-2).
This element is more precise than the kw or code element and should be used only when an XML attribute name appears by itself in text. An entire start-tag with attribute specifications, for example, should use code.
Attributes
The att element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The content of the element should be given typographical distinction. The element could also be pulled into a paper or electronic index for reference to the locations where the attribute is mentioned.
Rationale
Now that W3C specifications are increasingly used to document XML vocabularies themselves, this element is useful.
Attribute Value (attvalue)
Description
The attvalue element contains the mention of an attribute value or potential attribute value in text. (Note that it is not the same and does not have the same purpose as the attribute element, used exclusively in the definitions element.) It contains a mixture of character data and phrase-level elements (see Table 7-2).
This element is more precise than the kw or code element and should be used only when an XML attribute value appears by itself in text. An entire start-tag with attribute specifications, for example, should use code. This element is useful, for example, for explaining the individual token values available on an attribute.
Attributes
The attvalue element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The content of the element should be given typographical distinction, possibly being surrounded by quotation marks. The element could also be pulled into a paper or electronic index for reference to the locations where the attribute value is mentioned.
Rationale
Now that W3C specifications are increasingly used to document XML vocabularies themselves, this element is useful.
Code Fragment (code)
Description
The code element contains a code fragment. It contains a mixture of character data and phrase-level elements (see Table 7-2).
This element should be used whenever a code fragment can't be identified more precisely as a keyword or nonterminal. For example, a sample XML start-tag with attribute specifications provided in text might use the code element.
Attributes
The code element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The content of the element should be given typographical distinction, typically a monospaced font.
Rationale
This element is useful as the escape hatch for technical content. (Therefore, care should be taken not to abuse it.)
Element Type Name (el)
Description
The el element contains the mention of an element type name, or generic identifier (GI), in text. It contains a mixture of character data and phrase-level elements (see Table 7-2).
This element is more precise than the kw or code element and should be used only when an XML element type name appears by itself in text. An entire start-tag with attribute specifications, for example, should use code.
Attributes
The el element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The content of the element should be given typographical distinction, possibly surrounded by angle brackets. The element could also be pulled into a paper or electronic index for reference to the locations where the element type is mentioned.
Rationale
Now that W3C specifications are increasingly used to document XML vocabularies themselves, this element is useful.
Function (function)
Description
The function element contains a mention of a function name in text, possibly followed by empty parentheses. It contains a mixture of character data and phrase-level elements (see Table 7-2).
Attributes
The function element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The content of the element should be given typographical distinction, typically a monospaced font.
Rationale
This element became necessary when specifications using the DTD started to document functions. It is used in conjunction with the proto element.
Keyword (kw)
Description
The kw element contains a keyword in the language being described in the document. For example, it might be used for describing enumerated attribute value tokens in an XML-based markup language. It contains a mixture of character data and phrase-level elements (see Table 7-2).
Attributes
The kw element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The content of the element should be given typographical distinction, typically a monospaced font. Depending on the presentation, other processing, such as indexing each keyword in a paper index as "name keyword", might be appropriate.
Rationale
It is useful to mark up keywords separately from random strings of code because it can be desirable to index the keywords specially.
Nonterminal Reference (nt)
Description
The nt element is a mention of a nonterminal symbol that appears in a language production in the current specification. It must link to the production that defines the nonterminal. It contains character data (see Table 7-2).
Attributes
The element nt has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition to the common attributes, it also has the following semi-common attribute:
| def (required; see the section called Definition Attribute in Chapter 2) |
Processing Expectations
The content of the element should be given typographical distinction, typically a monospaced font. Depending on the presentation, other processing, such as indexing each mention in a paper index, might be appropriate. In electronic presentation, the content of this element should be "hot" to allow a user to traverse the link to the referenced resource.
Rationale
Since nonterminals are often the basis of the formal definition of a language in a W3C specification, it makes sense to treat them specially. Mentions of nonterminals are required to link to the relevant production not just as an aid to the reader, but also to provide another check that every nonterminal has its own production.
Variable (var)
Description
The var element identifies a string that, in actual usage, should be supplied by a human or computer according to the circumstances. This is somewhat similar to the MathML element mi. For example, reference to "some node x" would use var for the "x" part. It contains a mixture of character data and phrase-level elements (see Table 7-2).
Note that this element is not for programming or system variable names.
Attributes
The var element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The content of the var element should be given typographical emphasis, typically italic.
Rationale
The emph element was being abused to stand for variable strings. Having a separate element allows them to have difference typographical treatment and reflects their fundamental difference of purpose.
External Nonterminal Reference (xnt)
Description
The xnt element identifies a mention of a nonterminal symbol whose production appears in another specification; the mention also serves as a reference to the production by linking to the prod element in the other specification that defines the term (see the section called Code Scrap (scrap) in Chapter 4). It contains character data (see Table 7-2).
Attributes
The xnt element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
In addition, it contains the following semi-common element:
| href (required; see the section called XLink-Related Attributes in Chapter 2) |
Processing Expectations
The content of the element should be given typographical distinction, typically a monospaced font. Depending on the presentation, other processing, such as indexing each mention in a paper index, might be appropriate. In electronic presentation, the content of this element should be "hot" to allow a user to traverse the link to the referenced resource.
Rationale
Since nonterminals are often the basis of the formal definition of a language in a W3C specification, it makes sense to treat them specially. Mentions of nonterminals are required to link to the relevant production not just as an aid to the reader, but also to provide another check that every nonterminal has its own production. The xnt element was added in response to a need to make hyperlinks to "base" productions from specifications that properly depend on these productions. For example, the XML specification defines some nonterminals that are used in the XLink specification. Since this is more than a simple citation to another resource but rather provides details on the dependency, it seems appropriate to make this different from a regular nt.
The original reason that this element is separate from nt is that nt uses the ID/IDREF method of linking and this element uses the XLink/XPointer method. However, even if nt later switches to XLink, it is still be useful to have two separate elements.
Editorial Notes (ednote)
The ednote element is the only member of the editorial note class.
Description
The ednote element identifies commentary passed between editors and authors of a document. It contains an optional name element (the name of the person making the commentary), followed by an optional date element (the date the commentary was made), followed by an edtext element (the substance of the commentary). The date element contains character data, and the edtext element contains a mixture of character data and phrase-level elements (see Table 7-2).The name element is discussed along with the specification header element, in the section called Specification Header (header) in Chapter 3.
Attributes
The ednote element has the common attributes (see the section called Attributes Appearing on Every Element in Chapter 2):
| id |
| role |
| diff |
Processing Expectations
The content of this element should be suppressed in all "official" versions of a document, but in draft versions, the various parts of its content could be displayed and even given prominence.
Rationale
XML comments aren't usually sufficient for communications between authors because, in output versions of a document, comments don't appear. Having an element makes the communications more manageable and trackable, while not requiring a whole workflow system. The name and date "metadata" were made elements simply for convenience of input; in many XML-aware environments, it can be easiser to insert elements than attributes, and hopefully this will encourage their use.
Originally, we thought that the content of edtext need not be more complicated than #PCDATA because the note doesn't need to contribute to the "real" content of the document. However, editors were finding it useful to transplant "temporary" text to and from editorial notes, so starting to allow inline markup made sense.
Chapter 6. Making Connections
Linking Relationships
The following table shows the expected linking relationships among pieces of information using this DTD. See the section called Issues in Chapter 1 and the section called XLink-Related Attributes in Chapter 2 for information on outstanding issues related to linking.
Table 6-1. Linking Relationships
| Source of Link | Target of Link | Opt or Req | Scope of Link | Description and Examples | Processing Expectations |
|---|---|---|---|---|---|
| XLinks | |||||
| bibl | External resource | Opt | URI | Use if you want to make the entire contents of a bibliography entry "hot." It is better to use titleref than this element. | Allow traversal from bibliographic entry to resource by clicking (XLink "user"/"replace"). |
| External resource | Req | URI |
Use for email addresses that appear in text. This element allows the appearance of the email address in text to serve as a (usually mailto:) URL that can be accessed. For example:<email href="mailto:elm@arbortext.com">elm@arbortext.com</email> It could be argued that this is a redundant form. However, it is desirable to allow this element to be an XLink-conforming element that has the desired behavior, without the need for transformation into HTML. |
Allow traversal from email address to resource by clicking (XLink "user"/"new"). | |
| graphic | External resource | Req | URI | Use to pull in a graphic. For example: <graphic source="face.gif"/> | Pull in graphic data and display in place automatically (if image loading is on) (XLink "auto"/"embed"). |
| loc | External resource | Req | URI | Use for generic HTML A-type references that don't fall into any of the other categories of URI-mechanism links. Because XML specifications are often read in hardcopy form, try to include the URL in the actual document text. It's better to make a proper bibliography entry and include the URL as part of the entry. | Allow traversal from the mention of the location to the location itself by clicking (XLink "user"/"replace"). |
| titleref | External resource | Opt | URI | Use for making the mention of a title of a Web resource "hot." Best used only in the context of a bibliography entry, so that external references are relegated to the bibliography as much as possible. For example: <titleref href="http://www.pmi.org/publictn/pmboktoc.htm">PMI Body of Knowledge</titleref> | Allow traversal from the mention of the document's title to the document itself by clicking (XLink "user"/"new"). |
| xnt | External resource | Req | URI | Use to associate the mention of a nonterminal with the production in another specification that has this nonterminal as its left-hand side. For example: <xnt def="http://www.w3.org/TR/WD-xml#foo-prod">foo</xnt> | Allow traversal from the mention of the nonterminal to the (remote) production for it by clicking (XLink "user"/"new"). |
| xspecref | External resource | Req | URI | Use for making a cross-reference to an external specification (or a portion of one). For example: <xspecref def="http://www.w3.org/TR/WD-xml-names">Namespaces in XML</xspecref> | Allow traversal from the mention of the spec reference to the (remote) location where the spec is discussed by clicking (XLink "user"/"new"). |
| xtermref | External resource | Req | URI | Use for associating the mention of a term with its definition in another specification. For example: <xtermref def="http://www.w3.org/TR/REC-xml#entity-def">entity</xtermdef> | Allow traversal from the mention of the term to the (remote) location where the term is defined by clicking (XLink "user"/"new"). |
| ID/IDREF Links | |||||
| bibref | bibl | Req | IDREF | Use to associate a bibliographic citation in text with the corresponding bibliography entry. For example: <bibref ref="rfc1234"/> | Allow traversal from bibliographic reference to the bibliographic entry by clicking (analogue of XLink "user"/"new"). |
| constraint | constraintnote | Req | IDREF | Use to associate the constrained production with the explanation of the constraint. For example: <constraint def="constraint3"/> | Generate the head text of the note and other surrounding text, and output in place; use the type attribute on the note to determine the type. |
| nt | prod | Req | IDREF | Use to associate the mention of a nonterminal with the production that has this nonterminal as its left-hand side. For example: <nt def="foo-prod">foo</nt> | Allow traversal from the nonterminal to the production that defines it by clicking (analogue of XLink "user"/"new"). |
| prodrecap | prod | Req | IDREF | Use to pull in an extra copy of a production in the location of the link. For example: <prodrecap ref="QName.prod"/> | Reproduce the entire production (without a number next to it, or with some other indication that this is not the primary place where the production is defined) and display in place automatically (analogue of XLink "auto"/"embed"). |
| scrap | language in langusage | Req | IDREF | Use to indicate the language used in the code scrap. For example: <scrap lang="ebnf">...</scrap> | None. |
| specref | div1, div2, div3, inform-div1 | Req | IDREF | Use for making a cross-reference to a division in the current document. | Generate, in place, an italic "[n.n], Section Title" reference based on the relevant information from the referenced division; allow traversal from the generated text to the division by clicking (analogue of XLink "user"/"new"). |
| specref | item in olist | Req | IDREF | Use for making a cross-reference to a list item in the current document. | Generate, in place, the sequential number of the referenced item; allow traversal from the generated text to the item by clicking (analogue of XLink "user"/"new"). |
| specref | prod | Req | IDREF | Use for making a cross-reference to a production in the current document. | Generate, in place, the number of the production in brackets; allow traversal from the generated text to the production by clicking (analogue of XLink "user"/"new"). |
| specref | issue | Req | IDREF | Use for making a cross-reference to an issue in the current document. | Generate, in place, "Issue" and the number of the issue; allow traversal from the generated text to the issue by clicking (analogue of XLink "user"/"new"). |
| termref | termdef | Req | IDREF | Use for associating the mention of a term with its definition. For example: <termdef def="entity-def">entity</termdef> | Allow traversal from the mention of the term to the location where the term is defined by clicking (analogue of XLink "user"/"new"). |
| vc | vcnote | Req | IDREF | Use to associate the constrained production with the explanation of the constraint. For example: <vc def="vconstraint2"/> | Generate the head text of the note and other surrounding text, and output in place. |
| wfc | wfcnote | Req | IDREF | Use to associate the constrained production with the explanation of the constraint. For example: <wfc def="wfconstraint1"/> | Generate the head text of the note and other surrounding text, and output in place. |
Characters and Symbols
The following table summarizes the character and symbol entities defined in the DTD.
Table 6-2. Character Entities
| Symbol | Name | Definition | Description |
|---|---|---|---|
| & | amp | &#38; | Ampersand (XML predefined entity) |
| ' | apos | ' | Apostrophe (XML predefined entity) |
| > | gt | > | Greater than sign (XML predefined entity) |
| " | ldquo | &#x201C; | Left double quotation mark |
| < | lt | &#60; | Less than sign (XML predefined entity) |
| -- | mdash | &#x2014; | Em dash |
| nbsp | &#160; | No break (required) space | |
| ' | quot | &#34; | Double quotation mark (XML predefined entity) |
| " | rdquo | &#x201D; | Right double quotation mark |
Chapter 7. Element Classes and Mixtures
Following are the general element classes and mixtures used in this DTD. (See the section called IDL Definitions (definitions) in Chapter 4 for IDL-specific classes and mixtures.)
Standalone Element Classes and Mixtures
Following are the precise standalone element classes. Every class entity has the naming scheme %name.class;, and has an empty %local.name.class; entity in it for customization purposes.
-
Paragraphs (%p.class;)
Paragraph (p) -
Regular lists (%list.class;)
Unordered list (ulist) Ordered list (olist) Simple list (slist) Glossary list (glist) -
Special lists (%speclist.class;)
Bibliography list (blist) Organization list (orglist) -
Notes (%note.class;)
Regular note (note) Issue (issue) Well-formedness constraint note (wfcnote) Validity constraint note (vcnote) Generic constraint note (constraintnote) -
Illustrations (%illus.class;)
Code example (eg) Example (example) Graphic (graphic) Code scrap (scrap) HTML-style table (table) IDL definitions (definitions) Function prototype (proto)
Table 7-1 shows the element mixtures built up out of standalone elements. Note that some of the standalone mixtures also include the phrase-level element ednote.
Table 7-1. Standalone Mixtures
| p | list | speclist | note | illus | ednote | |
|---|---|---|---|---|---|---|
| %div.mix; (used in div1, inform-div1div2, div3, div4) | X | X | X | X | X | X |
| %obj.mix; (used in item, def, note, wfcnote, vcnote, footnote, resolution, example) | X | X | X | X | X | X |
| %p.mix; (used in p) | X | X | X | X | ||
| %hdr.mix; (used in notice, abstract, pubstmt, sourcedesc, revisiondesc) | X | X | X | |||
| %termdef.mix; (used in termdef) | X | X |
Phrase-Level Element Mixtures
Following are the precise phrase-level element classes. Every class entity has the naming scheme %name.class;, and has an empty %local.name.class; entity in it for customization purposes.
-
Annotations (%annot.class;)
Footnote (footnote) -
Term/definition (%termdef.class;)
Term definition (termdef) Defined term (term) -
Emphasis (%emph.class;)
Emphasized text (emph) Phrase (phrase) Quoted text (quote) Subscripted text (sub) Superscripted text (sup) -
References (%ref.class;)
Bibliography reference bibref Specification reference specref Term reference termref Title reference titleref External specification reference xspecref External term definition reference xtermref -
Web location references (%loc.class;)
Web location reference (loc) -
Technical (%tech.class;)
Keyword (kw) Nonterminal reference (nt) External nonterminal reference (xnt) Code fragment (code) Function (function) Variable (var) Element type name (el) Attribute name (att) Attribute value (attval) -
Editorial note (%ednote.class;)
Editorial note (ednote)
Table 7-2 shows the element mixtures built up out of "character data" (here standing for #PCDATA, entity references, and character references) and phrase-level elements. Note that many phrase-level elements themselves allow phrase-level subelements; these elements are represented on both axes.
Table 7-2. Phrase-Level Mixtures
| #PCD | annot | termdef | emph | ref | tech | loc | ednote | |
|---|---|---|---|---|---|---|---|---|
| %p.pcd.mix; (used in p, sitem, td, quote, emph, publoc, prevlocs, latestloc) | X | X | X | X | X | X | X | X |
| %head.pcd.mix; (used in head) | X | X | X | X | X | X | ||
| %label.pcd.mix; (used in label) | X | X | X | X | X | X | X | |
| %eg.pcd.mix; (used in eg, bnf) | X | X | X | X | X | |||
| %termdef.pcd.mix; (used in termdef) | X | term | X | X | X | X | X | |
| %bibl.pcd.mix; (used in bibl) | X | X | X | X | X | X | ||
| %tech.pcd.mix; (used in code, kw, el, att, attval, function, var, ) | X | X | X | |||||
| rhs | X | nt, xnt, com | ||||||
| com | X | loc, bibref | ||||||
| title, subtitle, version, w3c-designation, w3c-doctype, day, month, year, name, affiliation, email, language, role, lhs, date, edtext, loc, nt, term, termref, titleref, xnt, xspecref, xtermref, sub, sup, | X | |||||||
Appendix A. XMLspec Processing Applications
Following are known applications that format or otherwise process XMLspec documents. No claims are made about their usability, or to their conformance to new versions of the XMLspec DTD. If you have a processing application for XMLspec that you'd like to publicize, please contact Eve Maler.
| Name | Description | Status | Author | Availability |
|---|---|---|---|---|
| Jade stylesheets | DSSSL stylesheets for formatting XMLspec documents, one version using standard DSSSL flow objects for producing hardcopy (RTF, TeX etc) and one version using SGML transformation flow objects for producing HTML. | Developed as far as needed for production of original versions of XML and XSL specs. | James Clark. | Freely available. |
| Lark custom processor | Custom script used to generate the official HTML version of the XML V1.0 specification, among others. | Developed as far as needed for production of XML-related specs. | Tim Bray. | Freely available with the Lark processor. |
| Tcl scripts for DOM spec | The DOM specifications are written in XMLspec; the IDL, Java, and ECMAScript "bindings" are automatically generated from the XML, as is the published HTML document. | In use since early 1998 to produce the DOM specifications. | Written by Gavin Nicol. Maintained by Arnaud LeHors. | Available to W3C members. Requires the CoST and Tcl/XML utilities. |
| XSL stylesheets | XSLT stylesheet to convert both the XML specification and the XSL specification into HTML. It was developed as as an exercise to identify missing functionality in XSL. | This is an experimental stylesheet, written for a limited purpose. No commitment is made to keep it up to date. Note that the stylesheet uses two extensions to XSL [next-element() and previous-element()] implemented only in James Clark's 19990307 version of XT. | Eduardo Gutentag. | Freely available. |
| XSLT stylesheet for XML Schema specifications. | Only works with a modified version of XMLspec V2.0. | Henry Thompson. | See 25 Feb 2000 draft of the Part 1 spec for pointers to the DTD and stylesheet. | |
| XSLT stylesheet intended to provide 100% coverage of the official XMLspec DTD. | Nearly complete. | Ben Trafford. | Available on request. | |
| CSS stylesheet | CSS stylesheet that makes raw XMLspec source look acceptable in a browser. | This is an experimental stylesheet, written for a limited purpose. No commitment is made to keep it up to date. | Lauren Wood. | Available on request. |
| Arbortext doctype | FOSI and associated configuration files for editing XMLspec documents in Arbortext products with useful screen formatting, and for publishing them to PostScript for paper output. | Developed as far as needed for draft print production of XML-related specs. | Paul Grosso. | Available on request. Usable only with Arbortext products. |
Appendix B. XMLspec DTD Listing
Following is a listing of the entire XMLspec DTD, with important changed portions highlighted. The DTD file is available at http://www.w3.org/XML/1998/06/xmlspec-v21.dtd.
<!-- ............................................................... -->
<!-- XML specification DTD ......................................... -->
<!-- ............................................................... -->
<!--
TYPICAL INVOCATION:
# <!DOCTYPE spec PUBLIC
# "-//W3C//DTD Specification V2.1//EN"
# "http://www.w3.org/XML/1998/06/xmlspec-v21.dtd">
PURPOSE:
This XML DTD is for W3C specifications and other technical reports.
It is based in part on the TEI Lite and Sweb DTDs.
DEPENDENCIES:
None.
CHANGE HISTORY:
The list of changes is at the end of the DTD.
For all details, see the design report at:
# <http://www.w3.org/XML/1998/06/xmlspec-report-v21.htm>
Search this file for "#" in the first column to see change history
comments. To find changes made this time, search for "2000-03-07".
MAINTAINER:
Eve Maler
Sun Microsystems, Inc.
elm@east.sun.com
voice: +1 781 442 3190
fax: +1 781 442 1437
-->
<!-- ............................................................... -->
<!-- Entities for characters and symbols ........................... -->
<!-- ............................................................... -->
<!--
#1998-03-10: maler: Added “ and ”.
# Used 8879:1986-compatible decimal character
# references.
# Merged charent.mod file back into main file.
#1998-05-14: maler: Fixed ldquo and rdquo. Gave mdash a real number.
#1998-12-03: maler: Escaped the leading ampersands.
-->
<!ENTITY lt "&#60;">
<!ENTITY gt ">">
<!ENTITY amp "&#38;">
<!ENTITY apos "'">
<!ENTITY quot """>
<!ENTITY nbsp " ">
<!ENTITY mdash "&#x2014;">
<!ENTITY ldquo "&#x201C;">
<!ENTITY rdquo "&#x201D;">
<!-- ............................................................... -->
<!-- Entities for classes of standalone elements ................... -->
<!-- ............................................................... -->
<!--
#1997-10-16: maler: Added table to %illus.class;.
#1997-11-28: maler: Added htable to %illus.class;.
#1997-12-29: maler: IGNOREd table.
#1998-03-10: maler: Removed SGML Open-specific %illus.class;.
# Added "local" entities for customization.
#1998-05-14: maler: Added issue to %note.class;.
# Removed %[local.]statusp.class;.
#1998-05-21: maler: Added constraintnote to %note.class;.
#1998-08-22: maler: Changed htable to table in %illus.class;.
# Added definitions to %illus.class;.
#2000-03-07: maler: Added proto and example to %illus.class;.
-->
<!ENTITY % local.p.class "">
<!ENTITY % p.class "p
%local.p.class;">
<!ENTITY % local.list.class "">
<!ENTITY % list.class "ulist|olist|slist|glist
%local.list.class;">
<!ENTITY % local.speclist.class "">
<!ENTITY % speclist.class "orglist|blist
%local.speclist.class;">
<!ENTITY % local.note.class "">
<!ENTITY % note.class "note|issue|wfcnote|vcnote
|constraintnote %local.note.class;">
<!ENTITY % local.illus.class "">
<!ENTITY % illus.class "eg|graphic|scrap|table|definitions
|proto|example
%local.illus.class;">
<!-- ............................................................... -->
<!-- Entities for classes of phrase-level elements ................. -->
<!-- ............................................................... -->
<!--
#1997-12-29: maler: Added xspecref to %ref.class;.
#1998-03-10: maler: Added %ednote.class;.
# Added "local" entities for customization.
#2000-03-07: maler: Added function, var, el, att, and attval to
# %tech.class;.
# Added sub, sup, and phrase to %emph.class;.
-->
<!ENTITY % local.annot.class "">
<!ENTITY % annot.class "footnote
%local.annot.class;">
<!ENTITY % local.termdef.class "">
<!ENTITY % termdef.class "termdef|term
%local.termdef.class;">
<!ENTITY % local.emph.class "">
<!ENTITY % emph.class "emph|phrase|quote|sub|sup
%local.emph.class;">
<!ENTITY % local.ref.class "">
<!ENTITY % ref.class "bibref|specref|termref|titleref
|xspecref|xtermref
%local.ref.class;">
<!ENTITY % local.loc.class "">
<!ENTITY % loc.class "loc
%local.loc.class;">
<!ENTITY % local.tech.class "">
<!ENTITY % tech.class "kw|nt|xnt|code|function|var
|el|att|attval
%local.tech.class;">
<!ENTITY % local.ednote.class "">
<!ENTITY % ednote.class "ednote
%local.ednote.class;">
<!-- ............................................................... -->
<!-- Entities for mixtures of standalone elements .................. -->
<!-- ............................................................... -->
<!--
#1997-09-30: maler: Created %p.mix; to eliminate p from self.
#1997-09-30: maler: Added %speclist.class; to %obj.mix; and %p.mix;.
#1997-09-30: maler: Added %note.class; to %obj.mix; and %p.mix;.
#1997-10-16: maler: Created %entry.mix;. Note that some elements
# left out here are still allowed in termdef,
# which entry can contain through %p.pcd.mix;.
#1997-11-28: maler: Added %p.class; to %statusobj.mix;.
#1998-03-10: maler: Added %ednote.class; to all mixtures, except
# %p.mix; and %statusobj.mix;, because paragraphs
# and status paragraphs will contain ednote
# through %p.pcd.mix;.
#1998-03-23: maler: Added %termdef.mix; (broken out from
# %termdef.pcd.mix;).
#1998-05-14: maler: Removed %statusobj.mix; and all mentions of
# %statusp.mix;.
-->
<!ENTITY % div.mix
"%p.class;|%list.class;|%speclist.class;|%note.class;
|%illus.class;|%ednote.class;">
<!ENTITY % obj.mix
"%p.class;|%list.class;|%speclist.class;|%note.class;
|%illus.class;|%ednote.class;">
<!ENTITY % p.mix
"%list.class;|%speclist.class;|%note.class;|%illus.class;">
<!ENTITY % entry.mix
"%list.class;|note|eg|graphic|%ednote.class;">
<!ENTITY % hdr.mix
"%p.class;|%list.class;|%ednote.class;">
<!ENTITY % termdef.mix
"%note.class;|%illus.class;">
<!-- ............................................................... -->
<!-- Entities for mixtures of #PCDATA and phrase-level elements .... -->
<!-- ............................................................... -->
<!-- Note that %termdef.pcd.mix contains %note.class;
and %illus.class;, considered standalone elements. -->
<!--
#1997-09-30: maler: Added scrap and %note.class; to %termdef.pcd.mix;.
#1997-11-28: maler: Added %loc.class; to %p.pcd.mix;.
#1998-03-10: maler: Added %ednote.class; to all mixtures.
#1998-03-23: maler: Moved some %termdef.pcd.mix; stuff out to
# %termdef.mix;.
#1998-05-14: maler: Removed %statusp.pcd.mix;.
#1998-05-21: maler: Added constraint element to %eg.pcd.mix;.
#1999-07-02: maler: Added %loc.class; to %head.pcd.mix;,
# %label.pcd.mix;, %eg.pcd.mix;, %termdef.pcd.mix;,
# %tech.pcd.mix; (net: all PCD mixes have it).
# Removed unused %loc.pcd.mix;.
-->
<!ENTITY % p.pcd.mix
"#PCDATA|%annot.class;|%termdef.class;|%emph.class;
|%ref.class;|%tech.class;|%loc.class;|%ednote.class;">
<!ENTITY % head.pcd.mix
"#PCDATA|%annot.class;|%emph.class;|%tech.class;
|%loc.class;|%ednote.class;">
<!ENTITY % label.pcd.mix
"#PCDATA|%annot.class;|%termdef.class;|%emph.class;
|%tech.class;|%loc.class;|%ednote.class;">
<!ENTITY % eg.pcd.mix
"#PCDATA|%annot.class;|%emph.class;|%loc.class;
|%ednote.class;|constraint">
<!ENTITY % termdef.pcd.mix
"#PCDATA|term|%emph.class;|%ref.class;|%tech.class;
|%loc.class;|%ednote.class;">
<!ENTITY % bibl.pcd.mix
"#PCDATA|%emph.class;|%ref.class;|%loc.class;|%ednote.class;">
<!ENTITY % tech.pcd.mix
"#PCDATA|%loc.class;|%ednote.class;">
<!-- ............................................................... -->
<!-- Entities for customizable content models ...................... -->
<!-- ............................................................... -->
<!--
#1998-03-10: maler: Added customization entities.
#1998-05-14: maler: Allowed prevlocs and latestloc in either order.
#1999-07-02: maler: Made version optional; added copyright element.
#2000-03-07: maler: Allowed status and abstract in opposite order.
-->
<!ENTITY % spec.mdl
"header, front?, body, back?">
<!ENTITY % header.mdl
"title, subtitle?, version?, w3c-designation, w3c-doctype,
pubdate, notice*, publoc, ((prevlocs, latestloc?) |
(latestloc, prevlocs?))?, authlist, copyright?,
((status, abstract) | (abstract, status)), pubstmt?,
sourcedesc?, langusage, revisiondesc">
<!ENTITY % pubdate.mdl
"day?, month, year">
<!-- ............................................................... -->
<!-- Entities for common attributes ................................ -->
<!-- ............................................................... -->
<!--
#2000-03-07: maler: Added %argtypes;.
-->
<!-- argtypes:
Values for function prototype argument datatypes. -->
<!ENTITY % argtypes
'(boolean
|expression
|location-set
|node-set
|number
|object
|point
|range
|string)'>
<!-- key attribute:
Optionally provides a sorting or indexing key, for cases when
the element content is inappropriate for this purpose. -->
<!ENTITY % key.att
'key CDATA #IMPLIED'>
<!-- def attribute:
Points to the element where the relevant definition can be
found, using the IDREF mechanism. %def.att; is for optional
def attributes, and %def-req.att; is for required def
attributes. -->
<!ENTITY % def.att
'def IDREF #IMPLIED'>
<!ENTITY % def-req.att
'def IDREF #REQUIRED'>
<!-- ref attribute:
Points to the element where more information can be found,
using the IDREF mechanism. %ref.att; is for optional
ref attributes, and %ref-req.att; is for required ref
attributes. -->
<!ENTITY % ref.att
'ref IDREF #IMPLIED'>
<!ENTITY % ref-req.att
'ref IDREF #REQUIRED'>
<!--
#1998-03-23: maler: Added show and actuate attributes to href.
# Added semi-common xml:space attribute.
#1998-08-22: maler: Used new xlink:form and #IMPLIED features.
#1999-07-02: maler: Reorganized XLink-related entities completely;
# added xmlns:xlink attribute to the mix.
#2000-03-07: maler: Updated XLink usage to February 2000 draft,
# except that href still has no namespace prefix.
-->
<!-- xmlns:xlink and xlink:type attributes:
xmlns:xlink declares the association of the xlink prefix
with the namespace created by the XLink specification.
xlink:type identifies an element as an XLink "simple" linking
element. -->
<!ENTITY % simple-xlink.att
'xmlns:xlink CDATA #FIXED
"http://www.w3.org/1999/xlink"
xlink:type CDATA #FIXED "simple" '>
<!-- href attributes:
The href attribute locates the remote-resource half of a
simple link; the element on which the href appears is the
local-resource half. Some elements are usable links only if
the author chooses to supply a functional href. The attribute
name should really be xlink:href, but is kept without the
prefix for now in order to be backwards-compatible. -->
<!ENTITY % href.att
'href CDATA #IMPLIED '>
<!ENTITY % href-req.att
'href CDATA #REQUIRED '>
<!-- xlink:show and xlink:actuate attributes:
These attributes offer instructions to the display engine
about how to handle traversal to resource indicated by an
href locator. -->
<!ENTITY % auto-embed.att
'xlink:show CDATA #FIXED "embed"
xlink:actuate CDATA #FIXED "onLoad" '>
<!ENTITY % user-replace.att
'xlink:show CDATA #FIXED "replace"
xlink:actuate CDATA #FIXED "onRequest" '>
<!ENTITY % user-new.att
'xlink:show CDATA #FIXED "new"
xlink:actuate CDATA #FIXED "onRequest" '>
<!-- xml:space attribute:
Indicates that the element contains whitespace that the
formatter or other application should retain, as appropriate
to its function. -->
<!ENTITY % xmlspace.att
'xml:space (default
|preserve) #FIXED "preserve" '>
<!--
#2000-03-07: maler: Added common diff attribute. Made %role.att;.
-->
<!-- diff attribute:
Indicates in what way the element has changed. When a value
is not provided, that subelement should inherit a value from
its parent. If the root element has no value supplied,
assume "off". -->
<!ENTITY % diff.att
'diff (chg
|add
|del
|off) #IMPLIED'>
<!-- role attribute:
Extends the useful life of the DTD by allowing authors to
make a subtype of any element. No default. -->
<!ENTITY % role.att
'role NMTOKEN #IMPLIED'>
<!-- Common attributes:
Every element has an ID attribute for links, a role
attribute, and a diff attribute. %common.att; is for
common attributes where the ID is optional, and
%common-idreq.att; is for common attributes where the
ID is required. -->
<!ENTITY % common.att
'id ID #IMPLIED
%role.att;
%diff.att;'>
<!ENTITY % common-idreq.att
'id ID #REQUIRED
%role.att;
%diff.att;'>
<!-- ............................................................... -->
<!-- Common elements ............................................... -->
<!-- ............................................................... -->
<!-- head: Title on divisions, productions, and the like -->
<!ELEMENT head (%head.pcd.mix;)*>
<!ATTLIST head %common.att;>
<!-- ............................................................... -->
<!-- Major specification structure ................................. -->
<!-- ............................................................... -->
<!--
#1998-03-10: maler: Made spec content model easily customizable.
#1999-07-02: maler: Added doctype atts and status att.
#2000-03-07: maler: Added cr, issues, and dispcmts to w3c-doctype.
-->
<!ELEMENT spec (%spec.mdl;)>
<!-- w3c-doctype attributes:
Indicates the type of document, so that the appropriate
stylesheet or workflow routing can be applied. Should
*not* generate any text (such as the "REC-" or "NOTE-"
prefix on the W3C designation content). No default. If
w3c-doctype is "other", other-doctype should be filled in.
status attribute:
Indicates the stage of review of the document. May affect
the stylesheet's treatment of ednotes (e.g., whether to
output them). No default. -->
<!ATTLIST spec
%common.att;
w3c-doctype (cr
|dispcmts
|issues
|note
|other
|pr
|rec
|wd) #IMPLIED
other-doctype CDATA #IMPLIED
status (int-review
|ext-review
|final) #IMPLIED
>
<!ELEMENT front (div1+)>
<!ATTLIST front %common.att;>
<!ELEMENT body (div1+)>
<!ATTLIST body %common.att;>
<!--
#1997-09-30: maler: Added inform-div1 to back content.
-->
<!ELEMENT back ((div1+, inform-div1*) | inform-div1+)>
<!ATTLIST back %common.att;>
<!ELEMENT div1 (head, (%div.mix;)*, div2*)>
<!ATTLIST div1 %common.att;>
<!--
#1997-09-30: maler: Added inform-div1 declarations.
#2000-03-07: maler: Added div5 level.
-->
<!-- inform-div1: Non-normative division in back matter -->
<!ELEMENT inform-div1 (head, (%div.mix;)*, div2*)>
<!ATTLIST inform-div1 %common.att;>
<!ELEMENT div2 (head, (%div.mix;)*, div3*)>
<!ATTLIST div2 %common.att;>
<!ELEMENT div3 (head, (%div.mix;)*, div4*)>
<!ATTLIST div3 %common.att;>
<!ELEMENT div4 (head, (%div.mix;)*, div5*)>
<!ATTLIST div4 %common.att;>
<!ELEMENT div5 (head, (%div.mix;)*)>
<!ATTLIST div5 %common.att;>
<!-- ............................................................... -->
<!-- Specification header .......................................... -->
<!-- ............................................................... -->
<!--
#1998-03-10: maler: Made header content model easily customizable.
-->
<!ELEMENT header (%header.mdl;)>
<!ATTLIST header %common.att;>
<!-- Example of title: "Extensible Cheese Language (XCL)" -->
<!ELEMENT title (#PCDATA)>
<!ATTLIST title %common.att;>
<!-- Example of subtitle: "A Cheesy Specification" -->
<!ELEMENT subtitle (#PCDATA)>
<!ATTLIST subtitle %common.att;>
<!-- Example of version: "Version 666.0" -->
<!ELEMENT version (#PCDATA)>
<!ATTLIST version %common.att;>
<!-- Example of w3c-designation: "WD-xcl-19991231" -->
<!ELEMENT w3c-designation (#PCDATA)>
<!ATTLIST w3c-designation %common.att;>
<!-- Example of w3c-doctype: "W3C Working Draft" -->
<!ELEMENT w3c-doctype (#PCDATA)>
<!ATTLIST w3c-doctype %common.att;>
<!--
#1998-03-10: maler: Made pubdate content model easily customizable.
-->
<!ELEMENT pubdate (%pubdate.mdl;)>
<!ATTLIST pubdate %common.att;>
<!ELEMENT day (#PCDATA)>
<!ATTLIST day %common.att;>
<!ELEMENT month (#PCDATA)>
<!ATTLIST month %common.att;>
<!ELEMENT year (#PCDATA)>
<!ATTLIST year %common.att;>
<!--
#1999-07-02: maler: Declared copyright element.
-->
<!ELEMENT copyright (%hdr.mix;)+>
<!ATTLIST copyright %common.att;>
<!-- Example of notice: "This draft is for public comment..." -->
<!ELEMENT notice (%hdr.mix;)+>
<!ATTLIST notice %common.att;>
<!--
#2000-03-07: maler: Broadened models of *loc to %p.pcd.mix;.
-->
<!ELEMENT publoc (%p.pcd.mix;)*>
<!ATTLIST publoc %common.att;>
<!ELEMENT prevlocs (%p.pcd.mix;)*>
<!ATTLIST prevlocs %common.att;>
<!ELEMENT latestloc (%p.pcd.mix;)*>
<!ATTLIST latestloc %common.att;>
<!-- loc (defined in "Phrase-level elements" below) -->
<!ELEMENT authlist (author+)>
<!ATTLIST authlist %common.att;>
<!--
#1997-09-30: maler: Made affiliation optional.
#1998-03-10: maler: Made email optional.
-->
<!ELEMENT author (name, affiliation?, email?)>
<!ATTLIST author %common.att;>
<!ELEMENT name (#PCDATA)>
<!ATTLIST name
%common.att;
%key.att;>
<!ELEMENT affiliation (#PCDATA)>
<!ATTLIST affiliation %common.att;>
<!--
#1999-07-02: maler: Added show/actuate attributes and default values.
-->
<!ELEMENT email (#PCDATA)>
<!-- href attribute:
email functions as a hypertext reference through this
required attribute. Typically the reference would use
the mailto: scheme. E.g.:
<email href="mailto:elm@arbortext.com">elm@arbortext.com</email>
-->
<!ATTLIST email
%common.att;
%simple-xlink.att;
%href-req.att;
%user-new.att;>
<!--
#1998-05-15: maler: Changed status content from %statusobj.mix;
# to plain %obj.mix;. statusp is obsolete.
-->
<!ELEMENT status (%obj.mix;)+>
<!ATTLIST status %common.att;>
<!ELEMENT abstract (%hdr.mix;)*>
<!ATTLIST abstract %common.att;>
<!ELEMENT pubstmt (%hdr.mix;)+>
<!ATTLIST pubstmt %common.att;>
<!ELEMENT sourcedesc (%hdr.mix;)+>
<!ATTLIST sourcedesc %common.att;>
<!ELEMENT langusage (language+)>
<!ATTLIST langusage %common.att;>
<!ELEMENT language (#PCDATA)>
<!ATTLIST language %common.att;>
<!ELEMENT revisiondesc (%hdr.mix;)+>
<!ATTLIST revisiondesc %common.att;>
<!-- ............................................................... -->
<!-- Paragraph ..................................................... -->
<!-- ............................................................... -->
<!--
#1997-09-30: maler: Changed from %obj.mix; to %p.mix;.
#1997-12-29: maler: Changed order of %p.mix; and %p.pcd.mix;
# references.
#1997-12-29: maler: Changed order of %statusobj.mix; and
# %statusp.pcd.mix; references.
#1998-05-14: maler: Removed statusp declarations.
-->
<!ELEMENT p (%p.pcd.mix;|%p.mix;)*>
<!ATTLIST p %common.att;>
<!-- ............................................................... -->
<!-- Regular lists ................................................. -->
<!-- ............................................................... -->
<!-- ulist: Unordered list, typically bulleted. -->
<!ELEMENT ulist (item+)>
<!-- spacing attribute:
Use "normal" to get normal vertical spacing for items;
use "compact" to get less spacing. The default is dependent
on the stylesheet. -->
<!ATTLIST ulist
%common.att;
spacing (normal|compact) #IMPLIED>
<!-- olist: Ordered list, typically numbered. -->
<!ELEMENT olist (item+)>
<!-- spacing attribute:
Use "normal" to get normal vertical spacing for items;
use "compact" to get less spacing. The default is dependent
on the stylesheet. -->
<!ATTLIST olist
%common.att;
spacing (normal|compact) #IMPLIED>
<!ELEMENT item (%obj.mix;)+>
<!ATTLIST item %common.att;>
<!-- slist: Simple list, typically with no mark. -->
<!ELEMENT slist (sitem+)>
<!ATTLIST slist %common.att;>
<!ELEMENT sitem (%p.pcd.mix;)*>
<!ATTLIST sitem %common.att;>
<!-- glist: Glossary list, typically two-column. -->
<!ELEMENT glist (gitem+)>
<!ATTLIST glist %common.att;>
<!ELEMENT gitem (label, def)>
<!ATTLIST gitem %common.att;>
<!ELEMENT label (%label.pcd.mix;)*>
<!ATTLIST label %common.att;>
<!ELEMENT def (%obj.mix;)*>
<!ATTLIST def %common.att;>
<!-- ............................................................... -->
<!-- Special lists ................................................. -->
<!-- ............................................................... -->
<!-- blist: Bibliography list. -->
<!ELEMENT blist (bibl+)>
<!ATTLIST blist %common.att;>
<!--
#1999-07-02: maler: Added show/actuate attributes and default values.
-->
<!ELEMENT bibl (%bibl.pcd.mix;)*>
<!-- href attribute:
bibl optionally functions as a hypertext reference to the
referred-to resource through this attribute. E.g.:
<bibl href="http://www.my.com/doc.htm">My Document</bibl>
-->
<!ATTLIST bibl
%common.att;
%simple-xlink.att;
%href.att;
%user-replace.att;
%key.att;>
<!-- orglist: Organization member list. -->
<!ELEMENT orglist (member+)>
<!ATTLIST orglist %common.att;>
<!--
#1997-09-30: maler: Added optional affiliation.
-->
<!ELEMENT member (name, affiliation?, role?)>
<!ATTLIST member %common.att;>
<!-- name (defined in "Specification header" above) -->
<!-- affiliation (defined in "Specification header" above) -->
<!ELEMENT role (#PCDATA)>
<!ATTLIST role %common.att;>
<!-- ............................................................... -->
<!-- Notes ......................................................... -->
<!-- ............................................................... -->
<!ELEMENT note (%obj.mix;)+>
<!ATTLIST note %common.att;>
<!--
#1998-05-14: maler: Declared issue element.
#2000-03-07: maler: Added head, source, resolution, and status.
-->
<!ELEMENT issue (head?, source*, (%obj.mix;)+, resolution?)>
<!-- status attribute:
Indicates whether the issue is open or closed. Note that
the lack of a resolution element does not necessarily mean
that the issue is still open. -->
<!ATTLIST issue
id ID #REQUIRED
%role.att;
%diff.att;
status (open
|closed) "open"
>
<!ELEMENT source (%p.pcd.mix;)*>
<!ATTLIST source
%common.att;>
<!ELEMENT resolution (%obj.mix;)+>
<!ATTLIST resolution %common.att;>
<!-- wfcnote: Well-formedness constraint note. -->
<!ELEMENT wfcnote (head, (%obj.mix;)+)>
<!-- ID attribute:
wfcnote must have an ID so that it can be pointed to
from a wfc element in a production. -->
<!ATTLIST wfcnote
%common-idreq.att;>
<!-- vcnote: Validity constraint note. -->
<!ELEMENT vcnote (head, (%obj.mix;)+)>
<!-- ID attribute:
vcnote must have an ID so that it can be pointed to
from a vc element in a production. -->
<!ATTLIST vcnote
%common-idreq.att;>
<!--
#1998-05-21: maler: Declared generic constraintnote element.
-->
<!-- constraintnote: Generic constraint note. -->
<!ELEMENT constraintnote (head, (%obj.mix;)+)>
<!-- ID attribute:
constraintnote must have an ID so that it can be
pointed to from a constraint element in a production. -->
<!-- type attribute:
constraintnote must have a type value keyword so that
it can be correctly characterized in the specification. -->
<!ATTLIST constraintnote
%common-idreq.att;
type NMTOKEN #REQUIRED>
<!-- ............................................................... -->
<!-- Basic display elements ........................................ -->
<!-- ............................................................... -->
<!--
#1998-03-23: maler: Added xml:space attribute.
-->
<!-- eg: Example element, with whitespace respected. -->
<!ELEMENT eg (%eg.pcd.mix;)*>
<!ATTLIST eg
%common.att;
%xmlspace.att;>
<!--
#2000-03-07: maler: Removed the xml:attributes attribute.
# Added %local.graphic.att;.
-->
<!-- graphic: Displayed graphic. Graphic data should be
displayed at the point where it is referenced. Not
actually conforming to XLink right now. -->
<!ELEMENT graphic EMPTY>
<!-- source attribute:
The graphic data must reside at the location pointed to. -->
<!ENTITY % local.graphic.att "">
<!ATTLIST graphic
%common.att;
%simple-xlink.att;
source CDATA #REQUIRED
%auto-embed.att;
alt CDATA #IMPLIED
%local.graphic.att;>
<!--
#2000-03-07: maler: Added proto element structure.
-->
<!-- proto: Function prototype, in the XPath/XPointer style. -->
<!ELEMENT proto (arg*)>
<!ATTLIST proto
%common.att;
name NMTOKEN #REQUIRED
return-type %argtypes; #REQUIRED
>
<!ELEMENT arg EMPTY>
<!ATTLIST arg
%common.att;
type %argtypes; #REQUIRED
occur (opt|req) #IMPLIED
>
<!--
#2000-03-07: maler: Added example element.
-->
<!ELEMENT example (head?, (%obj.mix;)+)>
<!ATTLIST example %common.att;>
<!-- ............................................................... -->
<!-- EBNF .......................................................... -->
<!-- ............................................................... -->
<!--
#1997-11-28: maler: Added prodgroup to scrap and defined it.
#1998-05-21: maler: Added constraint to prod.
#1999-07-02: maler: Added prodrecap to scrap; broadened scrap model.
# Added headstyle attribute to scrap.
-->
<!-- scrap: Collection of EBNF language productions. -->
<!ELEMENT scrap (head, (prodgroup | prod | bnf | prodrecap)+)>
<!-- lang attribute:
The scrap can link to a description of the language used,
found in a language element in the header.
headstyle attribute:
Allows a scrap title to be suppressed from output. To be
used only when a scrap title directly next to a section
title is distracting or repetetive. -->
<!ATTLIST scrap
%common.att;
lang IDREF #IMPLIED
headstyle (show|suppress) "show"
>
<!-- prodgroup: Sub-collection of productions, needed for
formatting reasons. -->
<!ELEMENT prodgroup (prod+)>
<!-- pcw<n> attributes:
Presentational attributes to control the width
of the "pseudo-table" columns used to output
groups of productions. -->
<!ATTLIST prodgroup
%common.att;
pcw1 CDATA #IMPLIED
pcw2 CDATA #IMPLIED
pcw3 CDATA #IMPLIED
pcw4 CDATA #IMPLIED
pcw5 CDATA #IMPLIED
>
<!-- prod: EBNF language production. -->
<!ELEMENT prod (lhs, (rhs, (com|wfc|vc|constraint)*)+)>
<!-- ID attribute:
The production must have an ID so that cross-references
(specref) and mentions of nonterminals (nt) can link to
it. -->
<!ATTLIST prod
%common-idreq.att;>
<!-- lhs: Left-hand side of production. -->
<!ELEMENT lhs (#PCDATA)>
<!ATTLIST lhs %common.att;>
<!-- rhs: Right-hand side of production; may have many
"right-hand sides," one to a line. -->
<!ELEMENT rhs (#PCDATA|nt|xnt|com)*>
<!ATTLIST rhs %common.att;>
<!-- nt and xnt (defined in "Phrase-level elements" below) -->
<!--
#1997-11-28: maler: Added loc and bibref to com content.
-->
<!-- com: Production comment. -->
<!ELEMENT com (#PCDATA|loc|bibref)*>
<!ATTLIST com %common.att;>
<!-- wfc: Reference to a well-formedness constraint; should
generate the head of the wfcnote pointed to. -->
<!ELEMENT wfc EMPTY>
<!-- def attribute:
Each well formedness tagline in a production must link to the
wfcnote that defines it. -->
<!ATTLIST wfc
%def-req.att;
%common.att;>
<!-- vc: Reference to a validity constraint; should generate
the head of the vcnote pointed to. -->
<!ELEMENT vc EMPTY>
<!-- def attribute:
Each validity tagline in a production must link to the vcnote
that defines it. -->
<!ATTLIST vc
%def-req.att;
%common.att;>
<!--
#1998-05-21: maler: Declared generic constraint element.
-->
<!-- constraint: Reference to a generic constraint; should
generate the head of the constraintnote pointed to. -->
<!ELEMENT constraint EMPTY>
<!-- def attribute:
Each constraint tagline in a production must link to the
constraint note that defines it. -->
<!ATTLIST constraint
%def-req.att;
%common.att;>
<!--
#1998-03-23: maler: Added xml:space attribute.
-->
<!-- bnf: Un-marked-up EBNF production, with whitespace
respected. -->
<!ELEMENT bnf (%eg.pcd.mix;)*>
<!ATTLIST bnf
%common.att;
%xmlspace.att;>
<!--
#1999-07-02: maler: Declared prodrecap.
-->
<!-- prodrecap: Reference to production or bnf that appears
in its "normative" form elsewhere in the spec; should
generate a copy of the original production, without
a production number next to it. -->
<!ELEMENT prodrecap EMPTY>
<!ATTLIST prodrecap
%common.att;
%ref-req.att;>
<!-- ............................................................... -->
<!-- Table ......................................................... -->
<!-- ............................................................... -->
<!--
#1997-10-16: maler: Added table mechanism.
#1997-11-28: maler: Added non-null system ID to entity declaration.
# Added HTML table module.
#1997-12-29: maler: IGNOREd SGML Open table model.
#1998-03-10: maler: Removed SGML Open table model.
# Merged html-tbl.mod file into main file.
# Added %common.att; to all HTML table elements.
#1998-05-14: maler: Replaced table model with full HTML 4.0 model.
# Removed htable in favor of table.
# Removed htbody in favor of tbody.
-->
<!ENTITY % cellhalign.att
'align (left|center
|right|justify
|char) #IMPLIED
char CDATA #IMPLIED
charoff CDATA #IMPLIED'>
<!ENTITY % cellvalign.att
'valign (top|middle
|bottom
|baseline) #IMPLIED'>
<!ENTITY % thtd.att
'abbr CDATA #IMPLIED
axis CDATA #IMPLIED
headers IDREFS #IMPLIED
scope (row
|col
|rowgroup
|colgroup) #IMPLIED
rowspan NMTOKEN "1"
colspan NMTOKEN "1"'>
<!ENTITY % width.att
'width CDATA #IMPLIED'>
<!ENTITY % span.att
'span NMTOKEN "1"'>
<!-- table: HTML-based geometric table model. -->
<!ELEMENT table
(caption?, (col*|colgroup*), thead?, tfoot?, tbody+)>
<!ATTLIST table
%common.att;
%width.att;
summary CDATA #IMPLIED
border CDATA #IMPLIED
frame (void|above
|below|hsides
|lhs|rhs
|vsides|box
|border) #IMPLIED
rules (none|groups
|rows|cols
|all) #IMPLIED
cellspacing CDATA #IMPLIED
cellpadding CDATA #IMPLIED>
<!ELEMENT caption (%p.pcd.mix;)*>
<!ATTLIST caption %common.att;>
<!ELEMENT col EMPTY>
<!ATTLIST col
%common.att;
%span.att;
%width.att;
%cellhalign.att;
%cellvalign.att;>
<!ELEMENT colgroup (col)*>
<!ATTLIST colgroup
%common.att;
%span.att;
%width.att;
%cellhalign.att;
%cellvalign.att;>
<!ELEMENT thead (tr)+>
<!ATTLIST thead
%common.att;
%cellhalign.att;
%cellvalign.att;>
<!ELEMENT tfoot (tr)+>
<!ATTLIST tfoot
%common.att;
%cellhalign.att;
%cellvalign.att;>
<!ELEMENT tbody (tr)+>
<!ATTLIST tbody
%common.att;
%cellhalign.att;
%cellvalign.att;>
<!ELEMENT tr (th|td)+>
<!ATTLIST tr
%common.att;
%cellhalign.att;
%cellvalign.att;>
<!ELEMENT th (%p.pcd.mix;|%p.mix;)*>
<!ATTLIST th
%common.att;
%thtd.att;
%cellhalign.att;
%cellvalign.att;>
<!ELEMENT td (%p.pcd.mix;|%p.mix;)*>
<!ATTLIST td
%common.att;
%thtd.att;
%cellhalign.att;
%cellvalign.att;>
<!-- ............................................................... -->
<!-- IDL structures for DOM specifications ......................... -->
<!-- ............................................................... -->
<!-- ............................................................... -->
<!-- Specialized entities for classes .............................. -->
<!ENTITY % idl-desc.class
"p|note">
<!ENTITY % idl-tdef.class
"typedef|constant|exception|reference|group">
<!ENTITY % idl-mod.class
"module|interface">
<!ENTITY % idl-struct.class
"struct|enum|sequence|union|typename">
<!ENTITY % idl-meth.class
"method|attribute">
<!-- ............................................................... -->
<!-- Specialized entities for mixtures ............................. -->
<!-- Quick reference to content model mixtures:
desc tdef mod struct meth
group x x x x x
definitions, module x x x
interface x x x
typedef, case, component x
-->
<!ENTITY % idl-grp.mix
"%idl-desc.class;|%idl-tdef.class;|%idl-mod.class;
|%idl-struct.class;|%idl-meth.class;">
<!ENTITY % idl-defn.mix
"%idl-desc.class;|%idl-tdef.class;|%idl-mod.class;">
<!ENTITY % idl-intfc.mix
"%idl-desc.class;|%idl-tdef.class;|%idl-meth.class;">
<!ENTITY % idl-type.mix
"%idl-struct.class;">
<!-- ............................................................... -->
<!-- Specialized entities for common attributes .................... -->
<!-- name attribute:
Provides a name. Required. -->
<!ENTITY % idl-name.att
'name CDATA #REQUIRED'>
<!-- type attribute:
Provides a type. Required. -->
<!ENTITY % idl-type.att
'type CDATA #REQUIRED'>
<!-- ............................................................... -->
<!-- Common IDL element ............................................ -->
<!ELEMENT descr ((%obj.mix;)*)>
<!ATTLIST descr %common.att;>
<!-- ............................................................... -->
<!-- IDL definition elements ....................................... -->
<!-- definitions: Top-level element for definitions. -->
<!ELEMENT definitions (%idl-defn.mix;)+>
<!ATTLIST definitions %common.att;>
<!-- group: Element used to group a set of definitions. -->
<!ELEMENT group (descr, (%idl-grp.mix;)*)>
<!ATTLIST group
%common.att;
%idl-name.att;>
<!-- interface: Definition of an interface. -->
<!ELEMENT interface (descr, (%idl-intfc.mix;)*)>
<!ATTLIST interface
%common.att;
%idl-name.att;
inherits CDATA #IMPLIED>
<!-- module: Definition of a module. -->
<!ELEMENT module (descr, (%idl-defn.mix;)*)>
<!ATTLIST module
%common.att;
%idl-name.att;>
<!-- reference: Reference to some other declaration. -->
<!ELEMENT reference EMPTY>
<!ATTLIST reference
%common.att;
declaration IDREF #REQUIRED>
<!-- typedef: Definition of a named type. -->
<!ELEMENT typedef (descr, (%idl-type.mix;))>
<!ATTLIST typedef
%common.att;
%idl-name.att;
array.size NMTOKEN #IMPLIED>
<!-- struct: Declaration of a struct type. -->
<!ELEMENT struct (descr, component+)>
<!ATTLIST struct
%common.att;
%idl-name.att;>
<!-- component: Declaration of a structural member. -->
<!ELEMENT component (%idl-type.mix;)>
<!ATTLIST component
%common.att;
%idl-name.att;>
<!-- union: Declaration of a union type. -->
<!ELEMENT union (descr, case+)>
<!ATTLIST union
%common.att;
%idl-name.att;
switch.type CDATA #REQUIRED>
<!ELEMENT case (descr, (%idl-type.mix;))>
<!ATTLIST case
%common.att;
labels CDATA #REQUIRED>
<!-- enum: Declaration of an enum type. -->
<!ELEMENT enum (descr, enumerator+)>
<!ATTLIST enum
%common.att;
%idl-name.att;>
<!ELEMENT enumerator (descr)>
<!ATTLIST enumerator
%common.att;
%idl-name.att;>
<!-- sequence: Declaration of a sequence type (not named). -->
<!ELEMENT sequence (sequence*)>
<!ATTLIST sequence
%common.att;
%idl-type.att;
size NMTOKEN #IMPLIED>
<!-- constant: Declaration of a named constant. -->
<!ELEMENT constant (descr)>
<!ATTLIST constant
%common.att;
%idl-name.att;
%idl-type.att;
value CDATA #REQUIRED>
<!-- exception: Declaration of an exception. -->
<!ELEMENT exception (descr, component*)>
<!ATTLIST exception
%common.att;
%idl-name.att;>
<!-- component (defined under struct, above)-->
<!-- attribute: Declaration of an attribute (data member). -->
<!ELEMENT attribute (descr)>
<!ATTLIST attribute
%common.att;
%idl-name.att;
%idl-type.att;
readonly (yes
|no) "no">
<!-- method: Declaration of a method. -->
<!ELEMENT method (descr, parameters, returns, raises)>
<!ATTLIST method
%common.att;
%idl-name.att;>
<!ELEMENT parameters (param*)>
<!ATTLIST parameters %common.att;>
<!ELEMENT param (descr)>
<!ATTLIST param
%common.att;
%idl-name.att;
%idl-type.att;
attr (in
|out
|inout) "inout">
<!ELEMENT returns (descr)>
<!ATTLIST returns
%common.att;
%idl-type.att;>
<!ELEMENT raises (exception*)>
<!-- exception (defined under constant, above)-->
<!ELEMENT typename (#PCDATA)>
<!ATTLIST typename %common.att;>
<!-- ............................................................... -->
<!-- Phrase-level elements ......................................... -->
<!-- ............................................................... -->
<!--
#2000-03-07: maler: Added att and attval elements.
-->
<!-- att: Attribute name. -->
<!ELEMENT att (%tech.pcd.mix;)*>
<!ATTLIST att %common.att;>
<!-- attval: Attribute value. -->
<!ELEMENT attval (%tech.pcd.mix;)*>
<!ATTLIST attval %common.att;>
<!-- bibref: Reference to a bibliography list entry; should
generate, in square brackets, "key" on bibl. -->
<!ELEMENT bibref EMPTY>
<!-- ref attribute:
A bibliography reference must link to the bibl element that
describes the resource. -->
<!ATTLIST bibref
%common.att;
%ref-req.att;>
<!ELEMENT code (%tech.pcd.mix;)*>
<!ATTLIST code %common.att;>
<!--
#1998-03-10: maler: Declared ednote and related elements.
#1999-07-02: maler: Changed edtext content from #PCDATA to %p.pcd.mix;.
-->
<!-- ednote: Editorial note for communication among editors. -->
<!ELEMENT ednote (name?, date?, edtext)>
<!ATTLIST ednote %common.att;>
<!ELEMENT date (#PCDATA)>
<!ATTLIST date %common.att;>
<!ELEMENT edtext (%p.pcd.mix;)*>
<!ATTLIST edtext %common.att;>
<!--
#2000-03-07: maler: Added el element.
-->
<!-- el: Element type name (GI). -->
<!ELEMENT el (%tech.pcd.mix;)*>
<!ATTLIST el %common.att;>
<!--
#2000-03-07: maler: Expanded emph to %p.pcd.mix;.
-->
<!ELEMENT emph (%p.pcd.mix;)*>
<!ATTLIST emph %common.att;>
<!-- footnote: Both footnote content and call to footnote. -->
<!ELEMENT footnote (%obj.mix;)+>
<!ATTLIST footnote %common.att;>
<!--
#2000-03-07: maler: Added function and gave it content of
# %tech.pcd.mix; instead of XPath's #PCDATA.
-->
<!ELEMENT function (%tech.pcd.mix;)*>
<!ATTLIST function %common.att;>
<!ELEMENT kw (%tech.pcd.mix;)*>
<!ATTLIST kw %common.att;>
<!--
#1999-07-02: maler: Added show/actuate attributes and default values.
-->
<!-- loc: Generic link to a Web resource, similar to HTML's A. -->
<!ELEMENT loc (#PCDATA)>
<!-- href attribute:
The purpose of a loc element is to function as a A-like
hypertext link to a resource. (Ideally, the content of loc
will also mention the URI of the resource, so that readers of
the printed version will be able to locate the resource.) E.g.:
<loc href="http://www.my.com/doc.htm">http://www.my.com/doc.htm</loc>
-->
<!ATTLIST loc
%common.att;
%simple-xlink.att;
%href-req.att;
%user-replace.att;>
<!-- nt: Mention of a nonterminal in text, along with a link to
the production in the current document that defines it. -->
<!ELEMENT nt (#PCDATA)>
<!-- def attribute:
The nonterminal must link to the production that defines
it. -->
<!ATTLIST nt
%common.att;
%def-req.att;>
<!--
#2000-03-07: maler: Declared phrase.
-->
<!-- phrase: "Attribute hanger" for small bits of (e.g.) differenced
text in a paragraph or similar, when another element isn't handy.
Beware that its content model may allow more nested elements than
would normally be allowed in some contexts. -->
<!ELEMENT phrase (%p.pcd.mix;)*>
<!ATTLIST phrase %common.att;>
<!--
#1998-03-10: maler: Declared quote.
-->
<!-- quote: Scare quotes and other purely presentational quotes. -->
<!ELEMENT quote (%p.pcd.mix;)*>
<!ATTLIST quote %common.att;>
<!-- specref: Reference to a div, olist item, prod, or issue
in the current document; should generate italic "[n.n],
Section Title" for div, "n" for numbered item, "[n]" for
production, or "Issue id" for issue. -->
<!ELEMENT specref EMPTY>
<!-- ref attribute:
The purpose of a specref element is to link to a div, item
in an olist, or production in the current spec. -->
<!ATTLIST specref
%common.att;
%ref-req.att;>
<!--
#2000-03-07: maler: Added sub and sup.
-->
<!-- sub: Subscript. -->
<!ELEMENT sub (#PCDATA)>
<!ATTLIST sub %common.att;>
<!-- sup: Superscript. -->
<!ELEMENT sup (#PCDATA)>
<!ATTLIST sup %common.att;>
<!-- term: The term in text that is being defined in text. -->
<!ELEMENT term (#PCDATA)>
<!ATTLIST term %common.att;>
<!-- termdef: Definition of a term in text. -->
<!ELEMENT termdef (%termdef.pcd.mix;|%termdef.mix;)*>
<!-- ID attribute:
A term definition must have an ID so that it can be linked
to from termref elements. -->
<!-- term attribute:
The canonical form of the term or phrase being defined must
appear in this attribute, even if the term or phrase also
appears in the element content in identical form (e.g., in
the term element). -->
<!ATTLIST termdef
%common-idreq.att;
term CDATA #REQUIRED>
<!-- termref: Mention of a term, along with a link to the
definition in the current document. -->
<!ELEMENT termref (#PCDATA)>
<!-- ref attribute:
A term reference must link to the termdef element that
defines the term. -->
<!ATTLIST termref
%common.att;
%def-req.att;>
<!--
#1999-07-02: maler: Added show/actuate attributes and default values.
-->
<!-- titleref: Citation of another document, which can also
link to that document if it is a Web resource. -->
<!ELEMENT titleref (#PCDATA)>
<!-- href attribute:
A title reference can optionally function as a hypertext
link to the resource with this title. E.g.:
<loc href="http://www.my.com/doc.htm">http://www.my.com/doc.htm</loc>
-->
<!ATTLIST titleref
%common.att;
%simple-xlink.att;
%href.att;
%user-new.att;>
<!--
#2000-03-07: maler: Added var.
-->
<!-- var: String standing for a variable value that the user
or system will supply. For example: "For each node
<var>x</var> in this node-set..." -->
<!ELEMENT var (%tech.pcd.mix;)*>
<!ATTLIST var %common.att;>
<!--
#1999-07-02: maler: Added show/actuate attributes and default values.
-->
<!-- xnt: Mention of a nonterminal in text, along with a link to
the production in another document that defines it. -->
<!ELEMENT xnt (#PCDATA)>
<!-- href attribute:
The nonterminal must hyperlink to a resource that serves
to define it (e.g., a production in a related XML
specification). E.g.:
<xnt href="http://www.w3.org/TR/spec.htm#prod3">Name</xnt>
-->
<!ATTLIST xnt
%common.att;
%simple-xlink.att;
%href-req.att;
%user-new.att;>
<!--
#1997-12-29: maler: Declared xspecref.
#1999-07-02: maler: Added show/actuate attributes and default values.
-->
<!-- xspecref: Reference to a div, olist item, prod, or issue
in a related specification document; should generate
no special text. -->
<!ELEMENT xspecref (#PCDATA)>
<!-- href attribute:
The spec reference must hyperlink to the resource to
cross-refer to (e.g., a section in a related XML
specification). E.g.:
<xspecref href="http://www.w3.org/TR/spec.htm#sec2">
the section on constraints</xspecref>
-->
<!ATTLIST xspecref
%common.att;
%simple-xlink.att;
%href-req.att;
%user-new.att;>
<!--
#1999-07-02: maler: Added show/actuate attributes and default values.
-->
<!-- termref: Mention of a term, along with a link to the
definition in a related document. -->
<!ELEMENT xtermref (#PCDATA)>
<!-- href attribute:
The term reference must hyperlink to the resource that
serves to define the term (e.g., a term definition in
a related XML specification). E.g.:
<xtermref href="http://www.w3.org/TR/spec.htm#term5">
entity
</xtermref>
-->
<!ATTLIST xtermref
%common.att;
%simple-xlink.att;
%href-req.att;
%user-new.att;>
<!-- ............................................................... -->
<!-- Unused elements for ADEPT ..................................... -->
<!-- ............................................................... -->
<!--
#1997-09-30: maler: Added unusued elements.
#1997-10-14: maler: Fixed div to move nested div to the mixture.
#1998-05-14: maler: Added key-term, htable, and htbody.
#1998-11-30: maler: Added para, listitem, itemizedlist, and orderedlist.
-->
<!-- The following elements are purposely declared but never
referenced. Declaring them allows them to be pasted from
an HTML document, an earlier version of an XMLspec document,
or a DocBook document into a document using this DTD in ADEPT.
The ATD Context Transformation mechanism will try to convert
them to the appropriate element for this DTD. While this
conversion will not work for all fragments, it does allow many
cases to work reasonably well. -->
<!ELEMENT div
(head?, (%div.mix;|ul|ol|h1|h2|h3|h4|h5|h6|div)*)>
<!ELEMENT h1 (%head.pcd.mix;|em|a)*>
<!ELEMENT h2 (%head.pcd.mix;|em|a)*>
<!ELEMENT h3 (%head.pcd.mix;|em|a)*>
<!ELEMENT h4 (%head.pcd.mix;|em|a)*>
<!ELEMENT h5 (%head.pcd.mix;|em|a)*>
<!ELEMENT h6 (%head.pcd.mix;|em|a)*>
<!ELEMENT pre (%eg.pcd.mix;|em)*>
<!ELEMENT ul (item|li)*>
<!ELEMENT ol (item|li)*>
<!ELEMENT li (#PCDATA|%obj.mix;)*>
<!ELEMENT em (#PCDATA)>
<!ELEMENT a (#PCDATA)>
<!ELEMENT key-term (#PCDATA)>
<!ELEMENT htable
(caption?, (col*|colgroup*), thead?, tfoot?, tbody+)>
<!ELEMENT htbody (tr)+>
<!ELEMENT statusp (%p.pcd.mix;|%p.mix;)*>
<!ELEMENT itemizedlist (listitem*)>
<!ELEMENT orderedlist (listitem*)>
<!ELEMENT listitem (para*)>
<!ELEMENT para (#PCDATA)>
<!-- ............................................................... -->
<!-- Change history ................................................ -->
<!-- ............................................................... -->
<!--
#1997-08-18: maler
#- Did a major revision.
#1997-09-10: maler
#- Updated FPI.
#- Removed namekey element and put key attribute on name element.
#- Made statusp element and supporting entities.
#- Added slist element with sitem+ content.
#- Required head on scrap and added new bnf subelement.
#- Added an xnt element and allowed it and nt in regular text and rhs.
#- Removed the ntref element.
#- Added back the com element to the content of rhs.
#- Added a key attribute to bibl.
#- Removed the ident element.
#- Added a term element to be used inside termdef.
#- Added an xtermref element parallel to termref.
#- Beefed up DTD comments.
#1997-09-12: maler
#- Allowed term element in general text.
#- Changed bibref to EMPTY.
#- Added ref.class to termdef.pcd.mix.
#1997-09-14: maler
#- Changed main attribute of xtermref from def to href.
#- Added termdef.class to label contents.
#1997-09-30: maler
#- Added character entity module and added new entities.
#- Removed p from appearing directly in self; created %p.mix;.
#- Added inform-div (non-normative division) element.
#- Fixed xtermref comment to mention href, not ref.
#- Extended orglist model to allow optional affiliation.
#- Modified author to make affiliation optional.
#- Added %speclist.class; and %note.class; to %obj.mix; and %p.mix;.
#- Added %note.class; and %illus.class; to %termdef.pcd.mix;.
#- Added unused HTML elements.
#- Put empty system ID next to public ID in entity declarations.
#1997-10-14: maler
#- Fixed "unused" div content model to move nested div to mixture.
#1997-10-16: maler
#- Added SGML Open Exchange tables.
#1997-11-28: maler
#- Added support for prodgroup and its attributes.
#- Added support for HTML tables.
#- Added loc and bibref to content of com.
#- Added loc to general p content models.
#- Allowed p as alternative to statusp in status.
#- Added non-null system IDs to external parameter entity declarations.
#- (Modified the SGML Open table module to make it XML-compliant.)
#- (Modified the character entity module.)
#1997-12-29: maler
#- Moved #PCDATA occurrences to come before GIs in content models.
#- Removed use of the SGML Open table module.
#- Added xspecref element.
#- Ensured that all FPIs contain 4-digit year.
#- (Modified the character entity module.)
#1998-03-10: maler
#- Merged the character entity and table modules into the main file.
#- Added ldquo and rdquo entities.
#- Added common attributes to prodgroup.
#- Made the email element in header optional.
#- Removed reference to the SGML Open table model.
#- Added ednote element.
#- Added quote element.
#- Updated XLink usage to reflect 3 March 1998 WD.
#- Added "local" entities to the class entities for customization.
#- Parameterized several content models to allow for customization.
#1998-03-23: maler
#- Cleaned up some comments and removed some others.
#- Added xml:space semi-common attribute to eg and bnf elements.
#- Added show and embed attributes on all the uses of href.
#- Added %common.att; to all HTML table elements.
#- Added a real URI to the "typical invocation" comment.
#1998-05-14: maler
#- Fixed mdash, ldquo, and rdquo character entities.
#- Switched to the full HTML 4.0 table model.
#- Removed htable/htbody elements and replaced them with table/tbody.
#- Added issue element to %note.class; and declared it.
#- Allowed prevlocs and latestloc in either order.
#- Added key-term, htable, htbody, and statusp as unused elements.
#- Removed real statusp element in favor of plain p.
#1998-05-21: maler
#- Declared generic constraint and constraintnote elements.
#- Added constraintnote to %note.class;.
#- Added constraint to %eg.pcd.mix; and prod content model.
#1998-08-22: maler
#- Fixed %illus.class; to mention table instead of htable.
#- Added definitions to %illus.class; for DOM model.
#- Added DOM definitions element and its substructure.
#- Updated XLink usage in %href.att; to use xlink:form and #IMPLIED.
#- Added clarifying comments to href-using elements.
#1998-11-30: maler
#- Added new unused elements to support DocBook translation.
#- Updated maler phone numbers.
#1998-12-3: maler
#- Fixed character entities with respect to escaping of ampersands.
#- Added many more explanatory comments.
#1999-07-02: maler
#- Added %loc.class; to all PCD mixes that didn't already have it.
#- Removed unused %loc.pcd.mix;.
#- Made version in spec header optional.
#- Added three new attributes to spec.
#- Broadened content of edtext.
#- Added optional copyright element to header.
#- Reorganized XLink-related parameter entities; added xmlns:xlink.
#- Changed edtext content from #PCDATA to %p.pcd.mix;.
#- Added show/actuate atts and default values to all href elements.
#- Changed versioning scheme from 8-digit dates to version numbers.
#- Added w3c-doctype, other-doctype, status atts to spec element.
#- Added prodrecap element inside scrap.
#- Added headstyle attribute to scrap.
#2000-03-07: maler
#- Added proto element, its arg subelement, and the %argtypes; entity.
#- Added function, var, sub, sup, phrase, el, att, attval elements.
#- Expanded emph to %p.pcd.mix;.
#- Allowed status and abstract to appear in the opposite order.
#- Updated XLink usage to the latest WD, except for href and source.
#- Removed the xml:attributes attribute from graphic.
#- Added %local.graphic.att; to graphic.
#- Added common diff attribute.
#- Added div5 element.
#- Broadened content models of publoc, prevlocs, and latestloc.
#- Added head, source, resolution, and status attribute to issue.
#- Added cr, issues, and dispcmts to w3c-doctype attribute on spec.
#- Added example element.
-->
<!-- ............................................................... -->
<!-- End of XML specification DTD .................................. -->
<!-- ............................................................... -->