
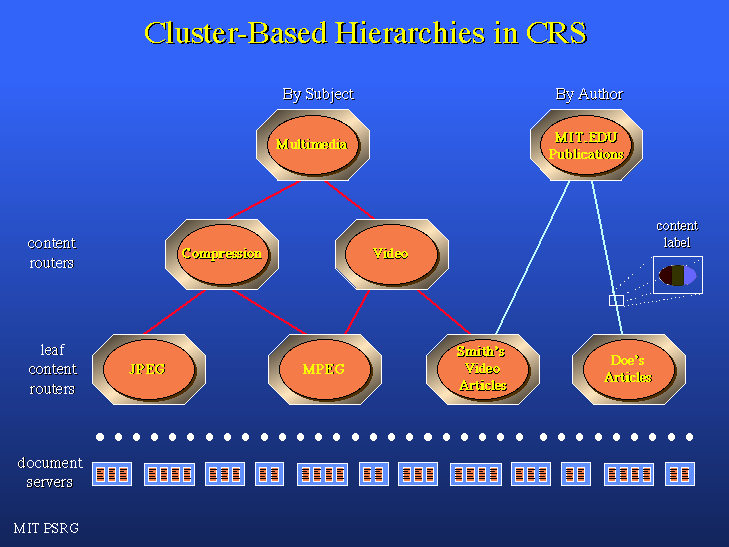
Hierarchical organizations of information servers, such as content routing systems, provide a framework for distributed searching and browsing in large information spaces. Such hierarchies, as shown in the figure, consist of documents stored on document servers (e.g., Web sites) and information servers that organize and index documents and other information servers. Experience with several prototype content routing systems, including CRS-WAIS, Discover, and HyPursuit has led us to believe that effective search engines must provide a spectrum of browsing and searching capabilities, together with facilities for helping users focus queries. We have also learned that underlying metadata representations of server contents are critical to providing scalable implementations for high level information services.
Information servers must support interleaved searching and browsing activities ranging over a spectrum from a well-defined search for a specific document to a non-specific desire to understand what information is available. To support these activities, our systems use metadata information (content labels) to provide services that help refine user queries to focus a search, automatically route queries to relevant servers, and cluster related items.
Query refinement helps overcome the problem of excessively large result sets frequently returned by global searches by suggesting modifications to focus user queries. Relying exclusively on result set ranking functions is inadequate. Our prototypes dynamically compute and suggest terms that frequently co-occur with the user's query terms. When a query is sufficiently narrow to be efficiently processed, it may be automatically routed to relevant servers so the results can be merged and presented to the user. Metadata structures to support query refinement and routing include term collocation and frequency information.
The organization of information into clusters of related items assists both the users and the system in coping with large information spaces. The cluster abstraction allows a large information space to be treated as a unit, without regard for the details of its contents. A user exploring the portion of the information space relating to biology may want to identify all clusters (not all documents) that are related to DNA computation. Thus, the user may interact with the system at a level of granularity that is appropriate to the specificity of the information need and the complexity of the information space. Clusters also provide convenient units for the partitioning of work and resource allocation among the distributed components of the system. The HyPursuit prototype content labels incorporate metadata descriptions of clusters that consist of representative terms and documents.
We propose to investigate metadata representations that are extensible, scalable, and support the requirements outlined above. To insure that the architecture supports new user services, metadata representations should consist of an extensible set of information service specific components. To achieve scalability, the system must implement service-specific mechanisms to control information loss. The result of performing an operation, e.g., a search, on these content label components approximates the result of performing the operation on the entire information summarized by the content label.
{kind=link}