

Figura 1.
Figura 2.
Immaginate di dover andare ad un convegno a Roma. La locazione e' Piazza della Pilotta, ma voi non siete di Roma, e non sapete dov'e' questa piazza. Nessun problema, il Web e' una fonte sterminata di informazioni, la nostra Nuova Biblioteca del Sapere Universale, e quindi e' logico che li' troverete la risposta. Andate quindi sul vostro motore di ricerca preferito (magari, Google), e chiedete "come si arriva a Piazza della Pilotta a Roma?". E quello che ottenete come primi risultati sono, nell'ordine: la pagina del turismo della provincia di La Spezia, una interessante pagina del Touring Club Italiano che vi parlera' anche degli gnocchi fritti (figura 1) dell'Emilia, una pagina su Suzanne Vega (figura 2) al Teatro Regio di Parma, e altre pagine, a seguire, tutte unite dalla costante di non avere nulla a che fare con Piazza della Pilotta a Roma.
|
|
Figura 1. |
Figura 2. |
Certo, se si conosce un po' Internet, si puo' capire come mai compaiono queste cose invece dell'informazione che vogliamo, ma e' proprio questo il problema: invece dell'informazione che vogliamo, otteniamo altro. E perdiamo tempo. Di sicuro, la' fuori nel Web, c'e' una bella mappa di Roma, magari interattiva, che ci puo' guidare alla Piazza della Pilotta di Roma, e magari dirci se c'e' qualcosa di notevole da vedere li' vicino, visto che dobbiamo andarci, e consigliarci sul mezzo migliore per raggiungerla dalla Stazione Termini. Di sicuro, ma il problema e' che la stupida macchina sembra non capire cosa vogliamo.Eppure, non sembrerebbe cosi' difficile...
Problemi come quello appena descritto sono all'ordine del giorno nell'uso del Web. Se e' vero che c'e' una miniera di informazioni che ci aspetta, l'enorme problema e' controllare questa miniera, cavarne fuori qualcosa di sensato, districarsi nella troppa informazione. Da qui nasce l'idea del cosiddetto Semantic Web, il "Web Semantico". E' un termine che va molto di moda tra coloro che operano nel Web, ma il cui significato, come tutti gli slogan troppo abusati, puo' variare e anche di molto. Cos'e' dunque il Semantic Web? In generale, e' un Web dove l'informazione e' presente in maniera piu' sofisticata, dove si possono stabilire proprietà, relazioni, regole, classificazioni, in modo tale che le macchine riescano in un certo senso a fare dei "ragionamenti" al posto nostro. Guardiamo il Web cosi' com'e' fatto ora, e vediamo come l'informazione viene rappresentata. Essenzialmente, si tratta di testo, scritto in linguaggio naturale (italiano, inglese, francese, giapponese eccetera eccetera). Certo, c'e' anche un po' di informazione grafica qua e la', che il linguaggio del Web attuale (HTML) ci permette: metti questo testo in italico, questo scrivilo un po' piu' grosso, qui usa un certo font, qui metti un'immagine e cosi' via. Ma tutte queste sono informazioni prettamente accessorie, per la maggior parte atte solamente a dare ai nostri occhi delle pagine che siano belle da vedere. La sostanza, guardandola bene, e' che l'informazione e' scritta nelle varie lingue che noi umani utilizziamo. Tutte queste lingue, pero', sono essenzialmente incomprensibili per le macchine: non ne comprendono il significato. Pensate ad un giapponese che non conosce l'italiano: prendetelo, chiudetelo dentro ad una scatola, ed obbligatelo a fare il motore di ricerca (del resto, "Google" suona anche un po' giapponese...). Ora riscrivetegli la stessa domanda iniziale: "come si arriva a Piazza della Pilotta a Roma?". Il povero giapponese non capira' nulla del senso della frase (la cosiddetta "semantica"). Tutto quello che potra' fare, e' magari cercare in giro, e vedere se in qualche pagina compaiono dei pezzetti di frase che siano simili, testualmente, ai pezzetti che gli avete fornito. Non c'e' dunque da sorprendersi quindi se, con questo metodo, alla fine vi ridarra' una pagina sugli gnocchi fritti. La differenza, in questo caso, tra il giapponese e la macchina e' che quest'ultima e' molto piu' veloce (il risultato vi arrivera' in una frazione di secondo), ma la grande velocita' non gli permette in ogni caso di capire il senso della frase: la macchina non sa l'italiano, e la sua velocita' non l'aiuta. Un ignorante veloce resta pur sempre un ignorante.
Ricapitoliamo dunque la situazione attuale: da un lato, ci siamo noi umani, che mettiamo informazione sul Web. Per farlo, usiamo essenzialmente la lingua che ci e' piu' congeniale. Morale: per noi e' facilissimo mettere informazione sul Web (e questo spiega l'enorme diffusione che il Web ha avuto in cosi' poco tempo). Dall'altro lato, ci sono le macchine, che a differenza nostra, non capiscono quasi nulla di quello che noi scriviamo. Morale: cercano di districarsi come possono, con i risultati mediocri che abbiamo sotto gli occhi.
Il Web Semantico cerca di ribaltare questa incomprensione di fondo. Se riuscissimo a farci capire un po' meglio dalle macchine, allora si' che le cose potrebbero andare molto meglio. Tutta quella mole d'informazione presente nel Web, troppo grande per un umano, potrebbe essere un po' capita da una macchina. E le macchine non si lasciano spaventare dalla grandezza, perche' sono veloci. E a questo punto, pensate alle possibilita': le macchine potrebbero aiutarci sul serio, perche' improvvisamente, quelle pagine che finora erano solo un ammasso di segni, diventerebbero parte di un qualcosa con del significato (della "semantica"). Ed allora, potrebbero risponderci proprio come vogliamo noi: niente gnocchi fritti (che c'entrano...?), bensi' indicazioni stradali. E magari, potrebbero fare cose piu' ambiziose che semplici ricerche, potrebbero ragionare, certo in modo molto semplice e limitato, ma pur sempre molto veloce. "Hmmm, vediamo, vuoi indicazioni per piazza della Pilotta? Ma da dove vorresti partire, dalla Stazione Termini? E, visto che non conosci il posto, sei interessato anche al turismo, ti interessano le attrazioni della zona? Vuoi che ti cerchi un hotel? Hai gia' tutti i biglietti che ti servono? ... ".
Ma allora, come si arriva al Web Semantico? Ovviamente, non c'e' una sola via, perche' molte tecniche sono possibili. C'e' comunque una via preferenziale, perche' e' quella su cui la maggior parte della gente che lavorano alla costruzione del Web Semantico sembra essere abbastanza d'accordo. E per capire questa via, dobbiamo addentrarci nella cosiddetta Torre del Web Semantico (figura 3).
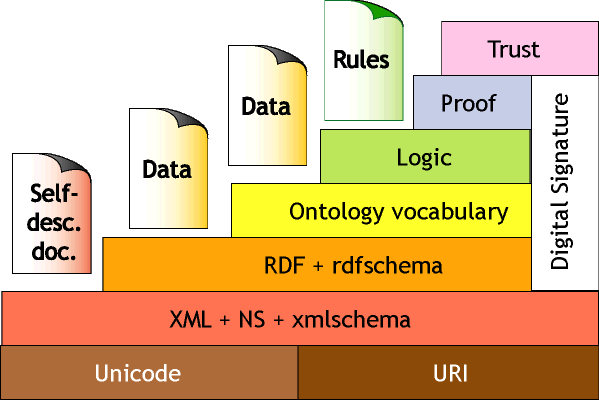
Figura 3.
La Torre del Web Semantico e' una figura sui cui sviluppi un solo libro non basterebbe, ma si puo' certamente cercare di dare una breve spiegazione sul suo significato. Anzitutto, partiamo dalla base: su cosa dovra' essere basato questo web del futuro? Il blocco portante di base e' essenzialmente costituito da XML, il nuovo linguaggio universale di cui tanto si parla. Non dovrebbe stupire che XML sia la base portante del Web Semantico, visto che XML, per come e' stato costruito, ambisce ad essere il linguaggio universale della rete. E' quindi comprensibile che il Web Semantico, che e' una particolare visione dell'informazione sul Web, sia e debba essere espresso in XML. Il vero contenuto innovativo, quello che distingue il Web Semantico da XML, e' dato dagli strati superiori della Torre, in particolare dal primo strato successivo ad XML, quello di RDF.
RDF e' il vero primo strato fondante proprio del Semantic Web. E per capire RDF, dobbiamo tornare alle macchine, ovvero, nel nostro paragone, al giapponese che non capisce l'italiano. Cosa potremmo fare per farci comprendere da lui? Cominceremmo ovviamente ad insegnargli un po' la nostra lingua. Ovviamente non possiamo cominciare con un italiano forbito, dobbiamo cominciare dalle basi, come se avessimo un bambino di fronte. Quando eravamo bambini, ai nostri inizi negli studi, il linguaggio sembrava semplice, non c'erano regole troppo complesse. Ricordate le prime lezioni di grammatica? Per esprimere un concetto usiamo delle frasi. Ogni frase e' costituita da un soggetto, un predicato, ed un complemento oggetto. Ed RDF, essenzialmente, e' proprio un linguaggio di base come questo: per esprimere l'informazione, usa delle frasi composte da "triple": soggetto, predicato, complemento oggetto. Le triple, cioe' queste frasette dalla struttura semplicissima, sono il mattoncino fondante che RDF ci offre, per codificare informazione via via sempre piu' complessa. A partire da questi mattoncini, RDF offre anche altri costrutti di base, quali per esempio congiunzioni, liste e cosi' via, che ci permettono di creare frasi un po' meno banali, e purtuttavia sempre molto semplici. Perche' l'idea di RDF e' proprio questa: non possiamo pretendere di insegnare da subito al nostro giapponese cose troppo complicate: insegnamogli come si scrivono frasi molto semplici, che lui poi potra' usare per dire molte cose anche complesse.
I mattoncini RDF possono appunto essere, come dei Lego, uniti tra loro, aggregando differenti informazioni. Questo permette di aggregare informazione proveniente da diverse parti del Web, con ovvi benefici. Analogamente, se abbiamo una informazione complessa espressa in RDF, possiamo estrarre da questi i mattoncini che vogliamo (piu' semplici), e fare dei ragionamenti su di essi. Questo ci permette, in presenza di tanta informazione (si pensi alla possibile taglia dell'informazione sul Web...), di estrarre facilmente dell'informazione piu' piccola e trattabile, velocizzando i tempi del ragionamento. A questo riguardo, c'e' un importante costrutto di RDF che merita attenzione, la cosiddetta reificazione (reification). Anche se il nome appare complicato, la reificazione in realta' non e' altro che un'operazione molto semplice, quella che in un linguaggio naturale viene di solito chiamata una citazione. Per fare un esempio, si pensi a quello che accade nel cortometraggio "A Grand Day Out" (figura 4), dove Gromit pensa che la luna e' fatta di formaggio. Ora, e' indubbio che Gromit pensi che la luna e' fatta di formaggio; questo pero' non significa che la luna sia veramente fatta di formaggio. Con la reificazione, possiamo trattare "la luna e' fatta di formaggio" come una citazione, cioe' non prenderci la responsabilita' di quest'asserzione, visto che stiamo citando qualcun altro. In altre parole, la reificazione in RDF ci permette di introdurre quelle virgolette intermedie che indicano la citazione: Gromit dice che "la luna e' fatta di formaggio". Senza la reificazione, dalla sequenza di mattoncini "Gromit pensa che la luna e' fatta di formaggio" potremmo invece liberamente estrarre il mattoncino "la luna e' fatta di formaggio", e questo sarebbe molto pericoloso, perche' essenzialmente ogni volta che si fosse nominato qualcosa detto da altri, finiremmo per assumercene la responsabilita'.

Figura 4.
Ora che abbiamo imparato i fondamenti del linguaggio di base con cui esprimere informazione sul Web (RDF), possiamo rivolgerci agli strati superiori della Torre del Web Semantico. Il primo, le cosiddette "ontologie", altro non sono che dei sistemi di classificazione. Con RDF abbiamo le frasi, con le ontologie abbiamo il concetto di "classe" (o categoria), cioe' un insieme di oggetti. Usando queste classificazioni, possiamo estendere la qualita' del nostro ragionamento. Per esempio, un motore di ricerca intelligente potrebbe avere non solo informazione su oggetti singoli (Roma, Piazza della Pilotta etc etc), ma anche informazioni piu' generali su "classi": ad esempio, una classe per le "citta'". E allora, al suo interno potrebbe a questo punto avere l'informazione che l'oggetto "Roma" e' una "citta'".
I due livelli successivi sono quelli della Logica (Logic) e della Prova (Proof). Sono livelli intimamente correlati, ed essenzialmente, sono i livelli che permettono di effettuare dei ragionamenti, anche complessi, solitamente tramite l'uso di "regole" (rules) che sono l'equivalente di un linguaggio di programmazione ad altissimo livello. Ad esempio, un motore intelligente potrebbe avere una regola secondo cui, se qualcuno chiede delle indicazioni per arrivare in qualche posto dentro ad una certa citta', allora possiamo chiedergli se vuole le vicine attrazioni turistiche (e gli hotels, e i biglietti, eccetera).
A questo punto, vediamo di ricapitolare con un esempio: una domanda del tipo "come si arriva a Piazza della Pilotta a Roma?" potrebbe scatenare all'interno del nostro motore di ricerca intelligente una sequenza di ragionamenti di questo tipo: "hmmm, vuoi arrivare in qualche posto a Roma. Che e' una citta'. Quindi, ne deduco che non conosci tanto bene Roma, magari sei un turista. Posso allora chiederti se cerchi anche attrazioni turistiche/hotels/biglietti eccetera. Tra l'alto, visto che Roma e' una citta', posso offrirti un punto di partenza ben definito per cominciare il tuo cammino. Vediamo, passa la ferrovia a Roma? Altrimenti potrei provare con la piazza principale... Ma, no, ecco qui, c'e' la ferrovia a Roma, quindi ti offriro' come punto di partenza la stazione principale della citta'... che e', eccola qui, la Stazione Termini." Questa sequenza di ragionamenti e' il frutto, come detto, di regole generali, combinate con l'uso di classi (citta') e dei fatti conosciuti dal motore (che Roma e' una citta'), che a questo punto puo' interrogare le fonti opportune per continuare nei suoi ragionamenti (in questa citta' passa la ferrovia? se si', qual'e' la stazione principale?).
L'ultimo strato della Torre, la cima, e' costituito dal cosiddetto "Trust", cioe' dal problema della fiducia. Finora, salendo man mano per la Torre, abbiamo visto come si puo' inserire nel Web Semantico una informazione che e' bene articolata, classificabile, su cui operare dei ragionamenti. E tuttavia, una caratteristica fondamentale del Web e' che e' un ambiente distribuito. Come direbbe Whitman, ognuno puo' contribuire con un verso (o una pagina). E proprio qui sta la ricchezza del Web, dal fatto che moltissime persone, indipendentemente l'una dall'altra (quindi, senza ritardi dovuti a controlli o censure), puo' contribuire con informazione sul Web. Questa ricchezza e liberta', comunque, comporta anche, come in ogni comunita', dei possibili problemi, proprio perche' non tutta l'informazione presente sul Web potrebbe essere vera. Supponiamo che, per burla, qualcuno inserisca sul Web l'informazione che Roma si trova sulle Alpi, ed e' la capitale dello gnocco fritto. A questo punto, il nostro motore di ricerca "intelligente" darebbe informazioni totalmente sballate, simili a quelle informazioni che ora otteniamo dai motori di ricerca attuali. Il problema di fondo e': di chi ci possiamo fidare? E lo strato del "trust", della fiducia, dovrebbe appunto fornire i mezzi, all'interno del Web Semantico, per cercare di distinguere fonti che sono piu' o meno autorevoli per l'informazione. Ad esempio, un motore di ricerca che si trovasse di fronte al dilemma di situare Roma nel centro-Italia o nelle Alpi (con conseguenze sul proporci poi o meno gnocchi fritti...) potrebbe ragionare piu' o meno in questo modo: "hmmm, il sito della Treccani mi dice che Roma e' nel centro-Italia... io mi fido di quel sito... Invece, la pagina web di questo signore che io non conosco, afferma che Roma e' nelle Alpi.... beh, vada per la Treccani: centro-Italia".
Ora che abbiamo visto brevemente la Torre del Web Semantico, potremmo chiederci a che punto si e' nella sua costruzione. Ovviamente, il gradino di base (XML) e' pronto, e da tempo. Il gradino di RDF e' praticamente completato. Il gradino successivo (quello delle ontologie/classificazioni) e' in dirittura d'arrivo, con uno standard che si chiama OWL (che sta per Ontology Web Language, linguaggio per le ontologie web), che riesce parzialmente a toccare anche lo strato superiore (quello logico). Sui rimanenti strati si sta ancora discutendo, e ci sono ancora varie possibilita' aperte per la definizione di standard a livello mondiale.
Torniamo dunque al confronto con la situazione ai giorni nostri: mentre attualmente, per noi umani e' facilissimo mettere informazione sul Web, ed e' difficilissimo per le macchine capirci, con il Web Semantico la situazione cambiera'. I vantaggi, come detto, saranno che le macchine, finalmente, cominceranno a capirci, e quindi potranno assisterci in maniera notevolmente piu' efficace. Il potenziale dunque, come si puo' ben capire, e' enorme. Ma, ci sono anche degli svantaggi? Si', lo svantaggio e' che per gli umani sara' un po' meno immediato mettere informazione sul Web (non bastera' piu' il nostro linguaggio, ma dovremo fornire qualche mattoncino in RDF). Ovviamente, questo e' un fattore critico per il successo del Web Semantico: se si rende troppo difficile mettere informazione qualificata nel Web, pochissimi faranno tale sforzo, e le cose resteranno come prima. E' questo il motivo per cui gran parte del successo nel passare dal Web attuale al piu' ricco Web Semantico si avra' non solo dalle applicazioni intelligenti (come motori di ricerca avanzati), ma anche e soprattutto dalla capacita' di sviluppare interfacce abbastanza semplici, con cui creare pagine web che siano essenzialmente molto simili a quelle attuali, ma permettano anche in maniera abbastanza rapida di creare (in maniera automatica, o semi-automatica) alcune informazioni aggiuntive (i mattoncini RDF) che sono necessari alle macchine per capirci.
Per concludere, ci si potrebbe chiedere se l'esempio di Piazza della Pilotta a Roma sia stato volutamente scelto apposta per via dello gnocco fritto. Nulla di tutto cio': semplicemente, a Piazza della Pilotta quest'anno si e' appena tenuto il primo convegno italiano sul... Web Semantico (!).