Example A:
<author>
<name>Janne Saarela</name>
<email>jsaarela@w3.org</email>
</author>
Example B:
<DIV CLASS=author>
<DIV CLASS=name>Janne Saarela</DIV>
<DIV CLASS=email>jsaarela@w3.org</DIV>
</DIV>
Since its conception in the early 90's, the World Wide Web has become a critical component in the strategic thinking of content providers around the world. Targeting the Web as the delivery vehicle for content poses several challenges. How should the publishing process change to take advantage of the Web? How should content be represented to support device independence, searchability, and efficient network throughput?
The protocols and data formats in use on the Web establish a framework within which applications and services can be built. This paper describes how emerging Web standards can be used to implement multi-purpose publishing where the same content is presented on a range of Web devices [footnote1]. Three specifications are discussed in more detail: HTML, XML, and CSS. All of them are recent Recommendations of the World Wide Web Consortium, and we believe they can help content providers face several challenges on the Web:
[footnote1] We use the term "Web device" to denote any hardware or software through which a user accesses Web content.
The World Wide Web Consortium is a coordinating body working with its more than 200 member organizations in developing the underlying technical specifications of the Web. Several of the recent recommendations of W3C extend the functionality of the Web in ways that will be significant for content providers. In particular, this paper discusses how content providers can take advantage of HTML, XML, and CSS.
Computer encodings of documents have long concentrated on preserving the final form presentation, e.g. a nicely laid out paper document. Structured document formats take a different approach; rather than preserving the final form presentation they encode the logical structure of the document. Among the reasons for doing so is the preservation of device independence, document searchability and information re-use in general.
The Standard Generalized Markup Language (SGML) [5] has pioneered the concept of structured documents. The philosophy behind SGML is simple: define a general meta-language that can be used to build application-specific languages to encode structured documents. A language specification, in SGML called a Document Type Definition (DTD), defines the elements, element containment and element attributes used to mark-up a document instance. Several document instances may be valid SGML documents conforming to the same DTD.
______ element ________________________________
| |
| attribute _ |
| | | |
<H1 CLASS=chapter> Multi-purpose publishing </H1>
| | | | | |
|__start tag_____| |________content_______| end tag
Figure 1. Structure of SGML mark-up.
Elements in SGML traditionally encode structure rather than presentation. For example, the headline of a document will be marked as being a headline rather than specifying a certain font size. This adds one level of indirection; in order to find the font size of the headline, a style sheet must be consulted. The style sheet describes the presentation of documents.
SGML became an ISO standard in 1986 and a number of vendors offer SGML-compliant products. SGML is, however, a complex technology that requires significant investment on the part of the content provider. In the last few years, the work on structured documents has centered around simplifications of SGML. We will discuss two of these efforts in more detail: HTML and XML.
The HyperText Markup Language (HTML) has its roots at the European Laboratory for High-Energy Physics (CERN) where the World Wide Web project was started in 1990. At that time, HTML served the needs of physicists who needed to collaborate by sharing scientific articles over the Internet. Although the content of these articles is difficult to read for most of us, their document structure is quite simple. This is reflected in the small set of general elements in HTML, including headings, paragraphs, lists and anchors for hyperlinks. The semantics in HTML is sparse, but is known by millions of Web devices around the world.
HTML was formally specified as an SGML DTD in 1992. This gave the HTML specification a context where further expansion was possible, but it also conflicted with some sentiments in the early Web community. First, SGML is a complex technology and implementing a full SGML parser was beyond the interests of early Web application developers. This resulted in forgiving browsers that accepted non-valid documents, and, as a result, even today few documents on the Web are valid according to the HTML specification. Secondly, HTML came from the structured documents community but was also influenced by presentational document formats, including Postscript. HTML still contains elements such as "B" (for bold) and "I" (for italics) which encode document presentation rather than structure. This breaks with the SGML principle of separating structure from presentation.
Today, the set of HTML elements has stabilized around 80. New elements are slowly added through the W3C working group on HTML that publishes revisions of the HTML specification. HTML 4.0 [12] is the latest version and it contains several noteworthy features for content providers. First, HTML 4.0 deprecates the use of a large set of elements. These elements mainly encode presentation and their function is better served by style sheets.
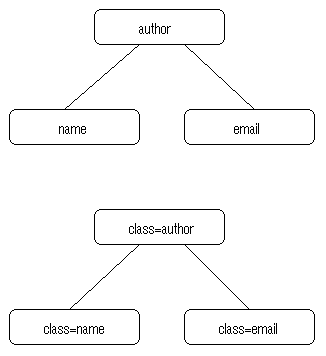
Secondly, HTML 4.0 adds a "CLASS" attribute on all elements. By using this attribute elements can be subclassed into categories of choice -- in effect creating new elements. The CLASS attribute can hold information which would otherwise be lost when converting a document to HTML, and a style sheet can act on the value of the CLASS attribute. See figure 2.
Example A:
<author>
<name>Janne Saarela</name>
<email>jsaarela@w3.org</email>
</author>
Example B:
<DIV CLASS=author>
<DIV CLASS=name>Janne Saarela</DIV>
<DIV CLASS=email>jsaarela@w3.org</DIV>
</DIV>
|
|
Figure 2. Example A shows element containment within an SGML document instance. Example B shows how the similar containment hierarchy can be achieved by complementing HTML semantics with the CLASS attribute.
Having a designated group in charge of HTML development has been a stabilizing factor for the language. No single vendor can single-handedly add new elements to HTML, and the document format remains non-proprietary. Also, the semantics of the various elements is well known: all browsers and search engines know that the "H1" element indicates a first-level headline. Thus, HTML has achieved a unique position as a device-independent, ubiquitous document format.
The downside of the committee approach is that communities with needs for additional markup (beyond subclassing existing HTML elements) cannot easily build on HTML. For example, mathematicians may want to encode formulae inside HTML documents, but HTML does not contain special elements for mathematics. For these sort for applications, XML comes to rescue.
Due to the limited repertoire of HTML elements, content providers cannot easily encode semantics into their documents. An initiative to regain the advantages of SGML on the Web was started in 1996 when a W3C working group was formed to identify a subset of SGML suitable for the Web. Later known as the eXtensible Markup Language (XML), the initiative has gathered support both from the SGML and the Web communities.
XML includes SGML's ability to define new elements. For content providers, this means XML can encode semantics more gracefully than HTML. In addition, XML removes the burden of having to validate documents against a DTD; XML documents may refer to a DTD, but are not required to do so. Instead, a document can claim to be well-formed by following some simple syntactical rules.
The XML specification [1] became a W3C Recommendation in February 1998 and the first uses of XML have appeared. For example, two new data formats for the Web, Synchronized Multimedia Integration Language (SMIL) [6] and RDF, are written in XML.
Resource Description Framework (RDF) is a metadata infrastructure format which allows content providers to encode metadata, i.e., information about information in machine-understandable form. RDF unifies the field of metadata by allowing authors to use assertions from different schemas such as Dublin Core [3] or Platform for Internet Content Selection (PICS) [11] in one single classification entry.
The following example shows how Dublin Core elements are qualified with the DC prefix within an RDF/XML document. The metadata entry gives some information on the electronic counterpart of this article.
<?xml version="1.0"?>
<?xml:namespace ns="http://www.w3.org/schemas/rdf-schema" prefix="RDF"?>
<?xml:namespace ns="http://purl.org/RDF/DC/" prefix="DC"?>
<RDF:RDF>
<RDF:Description RDF:HREF="http://www.w3.org/TR/NOTE-multipurpose">
<DC:title>Multi-purpose publishing using HTML, XML, and CSS</DC:title>
<DC:language>en</DC:language>
<DC:creator>
<RDF:Bag id="authors">
<RDF:li>Håkon Lie</RDF:li>
<RDF:li>Janne Saarela</RDF:li>
</RDF:Bag>
</DC:Creator>
</RDF:Description>
</RDF:RDF>
Figure 3. RDF document mixing assertions from multiple schemas
The knowledge representation issue of metadata is a two-edged sword: keeping the encoding simple will make metadata easy to read with decreased expressivity whereas a more complex encoding will allow for more expressive semantics. RDF builds on a common syntax, XML, and a simple data model based on nodes and arcs. Authoring of these seemingly complex descriptions can, of course, be made easier with the help of specialized applications.
SMIL and RDF both use XML to describe structure (using tags) but they have little or no content (e.g. text). Strictly speaking, these formats are not "markup" languages, but they show a trend: most uses of XML on the Web are for data, not documents.
The notion of style sheets is complementary to structured documents; documents contain content and structure, while style sheets describe how documents are to be presented. This separation is a requirement for device-independent documents (all device-specific information is left to the style sheet) and simplifies document management (since one style sheet can describe many documents).
For example, if an XML document uses element names like "author", "name" and "email" (see figure 4), there is no hint on how to present the content on, e.g., A4 paper.
Markup:
<author>
<name>Janne Saarela</name>
<email>jsaarela@w3.org</email>
</author>
Style sheet:
author { font: 12pt Times }
name { font-weight: bold }
email { font-style: italic }
Figure 4. A simple XML fragment with an associated CSS style sheet.
Cascading Style Sheets (CSS) [7] is a style sheet language developed for use on the Web. The work on CSS began at CERN in 1994 when authors requested stylistic control beyond the scope of HTML. In 1996, CSS1 (the first level of CSS) became a W3C Recommendation [8], and during 1997 major browsers (including Netscape Navigator 4 and Microsoft Internet Explorer 4) and authoring tools have added support for CSS1.

Figure 5. The same document shown with two different CSS style sheets. The underlying HTML source of the document is identical, only the link to the style sheet is different.
CSS uses declarative rules to attach style to elements. A simple rule might say that all P elements of class "warning" are to be displayed in red text on a white background:
P.warning { color: red; background: white }
CSS1 supports screen-based formatting, including fonts, colors, and layout. Before style sheets, Web authors had to make pictures of text to convey colors and fonts. This has resulted in a Web where most of the network bandwidth is used not for text, but for pictures of text. Therefore, the use of style sheets has the potential of significantly improving network performance as concluded in a recent study on the network performance effects of new Web technologies [10]:
To our surprise, style sheets promise to be the biggest possibility of major network bandwidth improvements, whether deployed with HTTP/1.0 or HTTP/1.1, by significantly reducing the need for in-lined images to provide graphic elements, and the resulting network traffic.
Using style sheets instead of images also improves Web accessibility. A speech synthesizer can easily read an HTML-encoded text to a blind user, or the text can be presented using a braille tactile feedback device. Images, on the other hand, deny non-visual access.
CSS2, the next level of Cascading Style Sheets which became a W3C Recommendation in May 1998 [9], further strengthens Web accessibility by adding the concept of media-specific style sheets. For example, a style sheet can describe an aural rendering of a document:
@media speech {
BODY { voice-family: female }
H1 { volume: loud }
}
The above style sheet will apply to all Web devices which support speech output. Such media-specific style sheets enable designers to carefully describe presentations for groups of devices while allowing the underlying documents to remain device-independent.
Hand-held Web devices also require special attention from style sheets due to their small display surface. For example, there may not be room for images, and only a shortened version of the document should be presented. The style sheet below turns off the display of images and normal paragraphs. Only paragraphs of class "ingress" will be shown:
@media handheld {
IMG { display: none }
P { display: none }
P.ingress { display: block }
}
A CSS style sheet is typically processed in the Web device itself. However, to save bandwidth for mobile handheld devices it may be beneficial to process the style sheet in a stationary proxy server. In the example above the style sheet turns off the display of images and the proxy server could therefore withhold images from the mobile device. This way, valuable bandwidth will be saved and the perceived performance of the Web will increase.
The eXtensible Style Language (XSL) is currently being defined by a W3C Working Group. XSL takes the concept of style sheets one step further by also being able to transform the structure of documents. For example, an XSL style sheet can automatically generate a table of contents by extracting all chapter titles from a document.
XSL will build on the experience of CSS by sharing the same underlying formatting model (including property names and allowed stylistic values). XSL will differ in the syntax (it's written in XML) and by being user-extensible (through the ECMAscript language [4]).
The use of XSL to transform XML data into structured documents such as HTML will play an important part in multi-purpose publishing.
Among the first additions to HTML after it escaped from CERN were forms which let users interact with pages by filling in text fields and pressing buttons. Later, the introduction of scripts (e.g. JavaScript, now being standardized as ECMAScript and Java applets) has enabled applications to be distributed over the Web.
Many Web pages mix declarative data (such as HTML, XML and CSS) with executable programs (such as scripts and applets). Often, the motivation for using programs is to achieve presentational effects, for example an animated headline or a certain popup menu.
When aiming for multi-purpose publishing, it's important to carefully consider the costs and benefits before relying on scripts and applets to present your information. Among the costs are:
As the development of style sheets progresses, it is expected that the most popular presentational effects achieved through programming will find their way to declarative style rules. For example, CSS2 includes functionality for hi-lighting an element when the mouse moves over it; this has only been possible through scripts up to now.
W3C has initiated an activity to describe the interface between programs and documents. The goal of the Document Object Model (DOM) activity is to define a language-independent API that applications can use to access and modify the structure, content, and style of HTML and XML documents.
As we have seen, structured documents with style sheets allow the same document to be presented on a variety of Web devices. Indeed, the goal of multi-purpose publishing is to have only one source document which is flexible enough to be used in different environments. However, sometimes it may be necessary to translate the document from one representation format to another before publishing it on the Web. This section discusses the problems related to managing the content in a different representation than actually served.
Our central claim is that HTML, together with style sheets, is rich enough to serve as a master document format for many publishers. Outside of traditional documents, however, other data formats written in XML will be able to capture semantics.
The terms "down-translation" and "up-translation" are often used when discussing translation of documents from one format to another. Down-translation refers to a process where the resulting document has less semantically significant markup available than the original source document. Up-translation refers to a reversed process where the source document may exist in any format and specialized rules are used to remove presentation-oriented, often proprietary markup. The goal is to produce a higher level representation with abstract markup elements suitable for a platform- and device-independent document description.
Up-translation can be seen as a preparatory process for the multi-purpose publishing as it leverages the value of the information content to a level where new applications can be implemented. The actual down-translation is then often a straight-forward process fine-tuned with in-house rules to do the actual translation to other document formats.
The down-translation process also has to cope with the real-life requirements of the publishing schedule. For example, this process may take place once a year in the context of encyclopedias or 50 times a second for interactive on-line services.
Leveraging the existing information with up-translation and learning to use new authoring tools or the existing tools in new ways will be an investment that is justified by a long-term vision on the value of the information. Let us outline a few scenarios to illustrate what sort of applications might become possible with more semantic markup and metadata:
As these examples demonstrate, there is room for improvement in the way information is represented and re-used on the Web. An important catalyst for new applications on the Web will be the successful incorporation of additional semantics in machine-understandable form.
In the previous discussion we have demonstrated that simple HTML documents, augmented with style sheets, preserve device independence and accessibility, while improving network performance. If you publish documents on the Web, the ubiquitous HTML is likely to be your document format of choice for years to come.
Today, users should require more from the information they access. Those authoring HTML can enhance their content by using the full semantics of HTML and adding style sheets. Those authoring content in other formats before putting them on the Web should ensure that the translation to HTML preserves the original semantics. This requires additional efforts during authoring but will pay off as new Web applications become possible. XML allows you to encode highly structured data and should be carefully considered when designing new Web applications.
In general, declarative data formats such as HTML, XML, and CSS are recommended over scripts and applets for stylistic effects in multi-purpose publishing. Declarative data is easy to convert to other formats, is more likely to be device-independent, and tend to live longer than programs.
The Web is generous enough to accommodate any content we place there. We should, however, ensure that our content meets the high standards of the Web.
The authors would like to thank Bert Bos and Janet Bertot for valuable comments on this article.

| Håkon Wium Lie is the leader of the style sheets activity at W3C. He first proposed Cascading Style Sheets while working in the World Wide Web project at CERN, the birthplace of the Web. He holds MS in Visual Studies from the MIT Media Laboratory. |

| Janne Saarela is a visiting scientist at W3C. Having previously worked at CERN and at the Helsinki University of Technology on document management issues, he is now preparing his Ph.D on leveraging electronic publishing with metadata. |