
10 May 2005, Makuhari, Chiba, Japan
Martin J. Dürst (duerst@it.aoyama.ac.jp)
Department of Integrated Information
Technology
College of Science and Engineering
Aoyama Gakuin University
Tokyo/Sagamihara, Japan
© 2005 Martin J. Dürst Aoyama Gakuin University
Character encoding is a very central and basic necessity for internationalization. For computer communication, characters have to be encoded into bytes. There are very simple encodings, but also more complicated ones. Over the years and around the world, a long list of corporate, national, and regional encodings has developed, which cover different sets of characters. The most complicated and the largest character encodings have been developed and are in use in Asia.
Unicode/ISO 10646 is steadily replacing these encodings in more and more places. Unicode is a single, large set of characters including all presently used scripts of the world, with remaining historic scripts being added. Unicode comes with two main encodings, UTF-8 and UTF-16, both very well designed for specific purposes. Because Unicode includes all the characters of all the well-used legacy encodings, mapping from older encodings to Unicode is usually not a problem, although there are some issues where care is necessary in particular for East Asian character encodings.
In general, character encoding deals with how to denote characters by more basic or primitive elements, such as numbers, bytes (octets) or bits. This includes a number of separable decisions, and a number of abstract layers of representation, which we will look at in greater detail later. For the moment, we will use the term encoding somewhat loosely.
General developments:
The history of character encodings contains many ingenious designs, but also quite a few accidental developments. The search for the best encoding always to some extent was in conflict with the need to use a common encoding that met many needs, even if somewhat incompletely.
A brief history of character encoding is provided in Richard Gillam, Unicode Demystified, pp. 25-59.
One tendency that can clearly be identified in the history of character encodings is the increase in the number of characters in a typical encoding. This increase is mainly due to the strong limitations of memory and display/printing capabilities of early technology.
Character encodings in most cases started out with a large variety of encodings, but converged sooner or later.
Basic idea: A single encoding for the whole world
Originally two separate projects:
Merged between 1991 and 1993 to avoid two global encodings.
For simplicity, this talk uses the term Unicode for the common product unless it is ambiguous.
We use the term Unicode here for what is essentially two standards.
The term character set has been used in various ways in the industry. Here we are talking about a set in the mathematical sense. To avoid confusion, this is often also called a character repertoire.
For CJKV ideographs, more systematic approach needed:
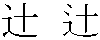 , U+8FBB)
, U+8FBB)Identifying the characters to encode is the first step; the next step is to give each character a number. and to arrange the characters in a table.
Code point is used for numbers that are not really characters
When emphasizing the fact of looking at the numbers or positions in the table, which may or may not be occupied by real characters, the term code point is often used.
It would have been nice if a single encoding for Unicode addressed all encoding needs. Unfortunately, due to @@@@, this is not (yet?) the case. Unicode defines three encodings with different size code unit for different purposes.
| from | to | usage | byte number | |||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| U+0000 | U+007F | US-ASCII | 0xxx xxxx | - | - | - |
| U+0080 | U+07FF | Latin,..., Arabic | 110x xxxx | 10xx xxxx | - | - |
| U+0800 | U+FFFF | rest of BMP | 1110 xxxx | 10xx xxxx | 10xx xxxx | - |
| U+10000 | U+10FFFF | non-BMP | 1111 0xxx | 10xx xxxx | 10xx xxxx | 10xx xxxx |
Only shortest encoding allowed.
See The Properties and Promises of UTF-8
The term code unit was specially created to deal with the fact that encoding characters with UTF-16 is a tree-step process, with code units as an additional step between code points and bytes.
16-bit values get stored differently on big-endian and little-endian machines
Only in the Unicode Standard, not part of ISO/IEC 10646
[and a break!]