Answer
It may be more interesting to ask who is not using Unicode.
A blog post by Google in January 2012 indicated that already around 80% of the Web in their sample of several billion pages was using the UTF-8 Unicode character encoding, if you include ASCII-encoded characters (approximately 16%). ASCII is a subset of UTF‑8.
In January 2016, the W3Techs site, which surveys home pages for the 10 million most used web sites according to Alexa, put the figure at 86%.
By January 2021, that figure had risen to 96.1%., and by January 2023 the figure was 97.9%.
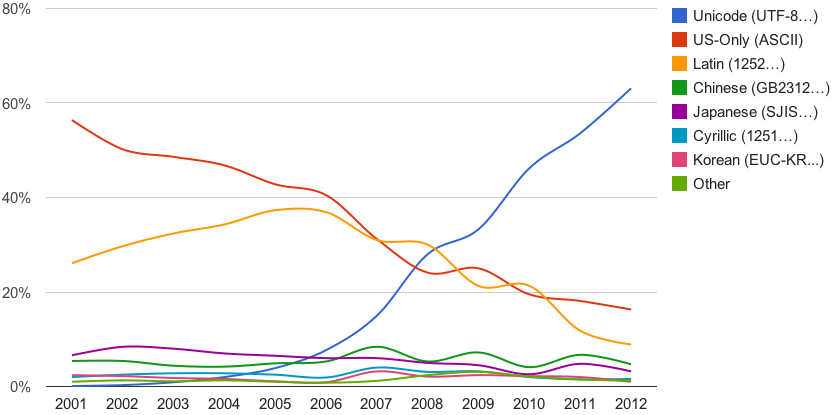
Not only are people using UTF-8 for their pages, but Unicode encodings are the basis of the Web itself. All browsers use Unicode internally, and convert all other encodings to Unicode for processing. As do all search engines. All modern operating systems also use Unicode internally. It has become part of the fabric of the Web.
The W3C strongly recommends that content authors should only use the UTF-8 encoding for their documents. This is partly to avoid the security risks associated with some encodings, but also to ensure world-wide usability of Web pages. It also gives you much more flexibility about what characters you can include in your web page without special escapes, from copyright symbols to emoji. See more advice on choosing character encodings.