Détails
Les bases
Utilisez toujours un attribut de langue sur l’élément html. Il sera hérité par
tous les autres éléments, et ainsi il fixera la langue par défaut de tout le texte contenu dans l’élément head du document.
Notez bien que vous devriez utiliser l’élément html plutôt que l’élément
body, puisque l’élément body ne couvre pas le texte contenu par l’élément
head du document.
Si votre page comporte du contenu qui est dans une langue différente de celle déclarée dans l’élément html, utilisez des attributs de langue sur les éléments qui entourent ce contenu. Cela vous
permet de le styler ou de le traiter différemment.
Dans certaines parties de votre code vous pouvez avoir un problème : si un texte multilingue est présent dans l’élément
title, vous ne pourrez pas indiquer que des parties de ce texte sont dans
différentes langues parce que l’attribut title ne permet que des caractères,
pas de balisage. Il en va de même pour les langues multiples dans les valeurs d’attributs. Il n’existe pas de bonne
solution pour le moment.
Choisir le bon attribut
Si votre document est en HTML (c’est à dire qu’il est servi en tant que text/html),
utilisez l’attribut lang pour fixer la langue du document ou d’un segment
de texte. Par exemple, le code suivant fixe la langue par défaut à français :
<html lang="fr">
Quand vous servez du XHTML 1.x ou des pages polyglottes en tant que text/html,
utilisez ensemble les deux attributs lang et xml:lang chaque fois que vous voulez fixer la langue. L’attribut xml:lang est la façon
standard d’identifier une information de langue en XML. Assurez-vous que les valeurs des deux attributs sont identiques.
<html lang="fr" xml:lang="fr" xmlns="http://www.w3.org/1999/xhtml">
L’attribut xml:lang n’est pas réellement utile pour manipuler le fichier en
tant que HTML, mais il devient prioritaire chaque fois que vous traitez ou que vous servez le document en tant que
XML. L’attribut lang est permis par la syntaxe XHTML, et peut aussi être reconnu
par les navigateurs. Quand on s’appuie sur d’autres analyseurs de XML (comme la fonction lang() de XSLT), on ne doit pas s’attendre à ce que l’attribut lang soit reconnu.
Si vous servez votre page en tant que XML (par exemple à l’aide du type MIME application/xhtml+xml),
vous n’avez pas besoin de l’attribut lang. L’attribut xml:lang seul suffira.
<html xml:lang="fr" xmlns="http://www.w3.org/1999/xhtml">
Que faire si le contenu d’un élément et son attribut sont dans des langues différentes ?
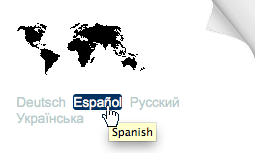
De temps en temps la langue du texte dans un attribut et celle du contenu d’un élément diffèrent. Par exemple dans
le coin supérieur droit de cet article, il y a des liens vers des versions traduites de cette page. Le texte du lien
montre la langue de la page cible en utilisant la langue de la page cible, mais un attribut title associé contient une information dans la langue de la page actuelle :
Si votre code ressemble à ce qui suit, les attributs de langue indiqueraient que non seulement le contenu mais aussi
l’attribut title sont en espagnol. À l’évidence c’est incorrect.
<a lang="es" title="Espagnol"
href="qa-html-language-declarations.es">Español</a>
Au lieu de ça, déplacez l’attribut contenant le texte dans une autre langue vers un autre élément, comme dans cet exemple,
où l’élément span hérite du réglage fr par défaut de l’élément html.
<span title="Espagnol"><a lang="es"
href="qa-html-language-declarations.es">Español</a></span>
Que faire si vous ne trouvez aucun élément auquel raccrocher l’attribut ?
Si vous voulez spécifier la langue d’un contenu mais qu’il n’est pas encadré par du code, utilisez un élément tel que
span ou div autour du contenu. Voici
un exemple :
<p>Vous diriez en chinois : <span lang="zh-Hans">中国科学院文献情报中心</span>.</p>
Choisir les valeurs de langues
Pour vous assurer que tous les agents utilisateurs comprennent quelle langue vous avez précisée, vous devez suivre une approche standard en précisant les valeurs d’attribut de langue. Vous devez aussi considérer comment faire référence de manière standard à différentes formes dialectales, comme par exemple entre l’anglais américain et l’anglais britannique, qui divergent significativement en termes d’orthographe et de prononciation.
Les règles de création des valeurs d’attribut de langue sont décrites par une spécification de l’IETF appelée BCP 47. En plus de spécifier comment utiliser des étiquettes de langues simples, telles que en pour l’anglais ou fr pour le français, BCP 47 décrit comment composer des étiquettes de langue qui vous permettent de spécifier des dialectes
régionaux, des graphies et d’autres variantes liées à cette langue.
BCP 47 intègre, mais va plus loin que, les règles ISO de langues et de codes de pays. Pour trouver les codes pertinents référez-vous au Registre IANA de Sous-étiquettes de Langues.
Pour une introduction abordable mais assez complète à la syntaxe des étiquettes BCP 47, lisez Étiquettes de langues en HTML et XML. Pour obtenir de l’aide dans le choix de l’étiquette de langue parmi toutes les étiquettes et les combinaisons, référez-vous à Choisir une étiquette de langue.