Il est important de tenir compte de la normalisation si vous créez des pages HTML avec des feuilles de style CSS en UTF-8 (ou tout autre encodage Unicode), tout particulièrement si vous avez affaire à du texte dans un script qui utilise des accents ou autres signes diacritiques.
This page addresses the question: Que sont les formes de normalisation, et pourquoi dois-je les connaître lors de la création de contenu HTML et CSS?
Que sont les formes de normalisation ?
En Unicode, il est possible de produire le même texte avec différentes séquences de caractères. Prenons par exemple le mot hongrois világ. La quatrième lettre peut être stockée en mémoire sous forme précomposée: U+00E1 LETTRE MINUSCULE LATINE A ACCENT AIGU (un seul caractère) ou par une séquence décomposée: U+0061 LETTRE MINUSCULE LATINE A, suivie de U+0301 DIACRITIQUE ACCENT AIGU (deux caractères).
La norme Unicode autorise chacune de ces alternatives, mais exige que les deux soient considérées identiques. Pour améliorer l'efficacité, une application normalise généralement le texte avant d'effectuer des recherches ou des comparaisons. La normalisation, dans ce cas, consiste à convertir le texte afin d'utiliser uniquement des caractères précomposés ou bien uniquement des caractères décomposés.
Quatre formes de normalisation sont spécifiées par le standard Unicode : NFC, NFD, NFKC et NFKD. Le C signifie (pré)composé, et le D décomposé. Le K signifie compatibilité.
NFD uses Unicode rules to maximally decompose a code point into component parts. For example, the Vietnamese letter ề [U+1EC1 LATIN SMALL LETTER E WITH CIRCUMFLEX AND GRAVE] becomes the sequence ề [U+0065 LATIN SMALL LETTER E + U+0302 COMBINING CIRCUMFLEX ACCENT + U+0300 COMBINING GRAVE ACCENT].
NFC runs that process in reverse, and will also completely compose partially decomposed sequences. However, this composition process is only applied to a subset of the Unicode repertoire. For example, the sequence g̀ [U+0067 LATIN SMALL LETTER G + U+0300 COMBINING GRAVE ACCENT] has no precomposed form, and is unaffected by normalization.
NFKC and NFKD were introduced to handle characters that were included in Unicode in order to provide compatibility with other character sets. This applies to code points that represent such things as glyph variants, shaped forms, alternative compositions, and so on. NFKD and NFKC normalization replaces these code points with canonical characters or character sequences, and you cannot convert back to the original code points. In principle, such compatibility variants should not be used.
Que dois-je savoir sur la normalisation?
Choosing a normalization form
Natural language content aimed at human consumption does not need to all be in one normalized form – there may sometimes be good reasons to mix normalized forms. Applications that try to match one piece of text with another should, however, compare normalized versions of both.
Malheureusement, la normalisation n'a pas toujours lieu avant que le contenu soit comparé. Un cas particulièrement important est l'utilisation de noms de sélecteurs et de classes ou d'id en HTML et CSS. Si le mot világ est utilisé sous la forme précomposée en HTML (ex. <span class="vilag">), mais sous la forme décomposée en CSS (ex. .világ { font-style: italic; }), alors le sélecteur ne correspondra pas au nom de la classe.
The following example shows this. The CSS selector is decomposed, whereas one class name in the HTML is decomposed and the other precomposed. As you should be able to see, only the decomposed class name is matched to the style. But notice also that it is not possible to distinguish the two forms in the source text.
Cela signifie que lorsque vous produisez du contenu, vous devez vous assurer que les noms des sélecteurs, des classes et des id sont les mêmes, caractère par caractère. Cela risque particulièrement de poser problème si le HTML et le CSS n'ont pas été créés ou maintenus par les mêmes personnes.
Le meilleur moyen de vérifier que tout est cohérent est d'utiliser une seule forme de normalisation Unicode pour tout le contenu créé. It doesn't really matter whether you use the NFC or NFD normalization form, it's more important that you are consistent. NFC is, however, a good recommendation because this is what many (but not all) keyboards tend to produce. (Most keyboards for European languages output text in NFC already, but this is less likely to be the case if dealing with many non-European languages.)
We don't recommend using any of the K forms in this way.
Converting the normalization form of a page
You should also try to avoid automatically converting content from one normalization form to another, as it may obliterate some important code point distinctions, such as in the carefully crafted examples of világ above, or in filenames or URLs, or text included in the page from elsewhere, etc.
It may also introduce a security risk, especially in code syntax. For example, the following code points are canonically equivalent: ≯ [U+003E GREATER-THAN SIGN + U+0338 COMBINING LONG SOLIDUS OVERLAY] and ≯ [U+226F NOT GREATER-THAN]. Therefore source code in XML such as <character≯</character> can be corrupted by normalising to NFC.
Sometimes people choose to use compatibility characters in their content, most likely without realising what they are. Examples might include ¼ [U+00BC VULGAR FRACTION ONE QUARTER], ² [U+00B2 SUPERSCRIPT TWO] (eg. for m²), and № [U+2116 NUMERO SIGN]. Blind normalization of that content would change those characters to the ASCII code points 1⁄4, 2, and No, respectively. In some cases this may affect the look of the text; in others it may affect the readability.
Normalization settings in your editor
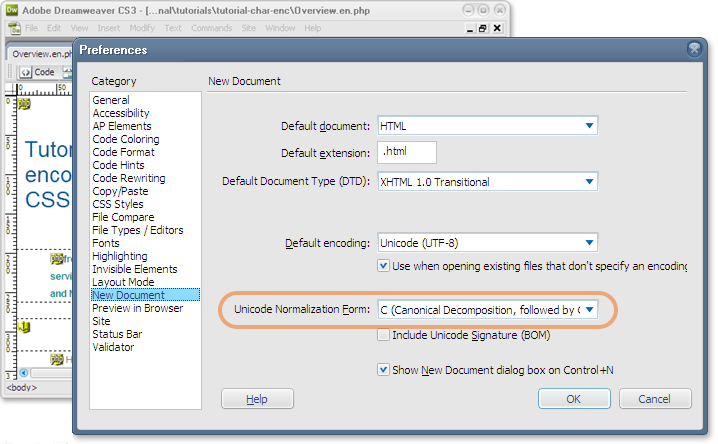
Dans certains cas, votre éditeur peut vous permettre d'enregistrer les données en choisissant parmi plusieurs formes de normalisation. L'image ci-dessous montre une option permettant de définir une forme de normalisation utilisée par défaut lors de l'ouverture de nouveaux fichiers dans Dreamweaver (NFC est sélectionné). Un choix similaire s'affiche lors de l'enregistrement d'un document.
If you have set up your editing environment like this, you may find yourself in a situation where you want to deviate from the default normalisation form, for instance to create the examples above. However, as soon as you save the file, it will obliterate those carefully implemented variant forms. A way around this is to use character escapes. If you write the word világ in your source code as világ it will not be normalized during the save.
Comment puis-je rechercher si les pages présentent des problèmes?
En utilisant W3C Internationalization Checker, vous pouvez vérifier si une page HTML contient des noms de classes et des valeurs d'ID qui ne sont pas normalisés en NFC. (Look for the row Markup / Non-NFC class or id names.)