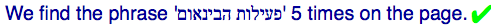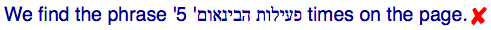This article looks at how content authors can apply direction metadata to bidirectional text when markup is not available.
Right-to-left text in code samples is represented by UPPERCASE TRANSLATIONS, and left-to-right text by lowercase.
The article assumes that you are familiar with bidirectional text concepts and managing bidirectional text using HTML markup, but that you need to know how to do similar things with Unicode control characters, such as when writing plain text. If you are not familiar with how bidirectional text works in Unicode, you should read through the article Unicode Bidirectional Algorithm basics before continuing.
You will still need to use markup to establish the default direction for a document as a whole (eg. in the html tag), and to change direction for block container elements. Because control codes don't cross paragraph (read as block element) boundaries, and because control codes cannot manage inheritance and scoping through the markup hierarchy, they are only appropriate for inline use.
For example, although a title element in the header of an HTML page cannot contain markup, it is still possible to set a default base direction on the title element tag (or for it to inherit the direction set on the html tag). This article is about how to apply directional changes in inline or other plain text situations, such as within the title element or a title attribute, or how to apply a direction to attribute text which is different from that of the surrounding element, and so on. It also applies to plain text formats such as WebVTT and CSV.
Changing the direction of an inline range of text
If you want to change the direction for a run of inline text you need to indicate a start and end point. For this you need to use one of the following characters to indicate the start of the embedded direction change.
Character
Name
Code point
Equivalent markup
Notes
LRI
LEFT-TO-RIGHT ISOLATE
U+2066
dir="ltr"
sets direction to LTR and isolates the embedded content from the surrounding text
RLI
RIGHT-TO-LEFT ISOLATE
U+2067
dir="rtl"
ditto, but for RTL
FSI
FIRST-STRONG ISOLATE
U+2068
dir="auto"
isolates the content and sets the direction according to the first strongly typed directional character
LRE
LEFT-TO-RIGHT EMBEDDING
U+202A
dir="ltr"
sets direction to LTR but allows embedded text to interact with surrounding content, so risk of spillover effects
RLE
RIGHT-TO-LEFT EMBEDDING
U+202B
dir="rtl"
ditto, but for RTL
LRO
LEFT-TO-RIGHT OVERRIDE
U+202D
<bdo dir="ltr">
overrides the bidirectional algorithm to display characters in memory order, progressing from left to right
RLO
RIGHT-TO-LEFT OVERRIDE
U+202E
<bdo dir="rtl">
as previous, but display progresses from right to left
You need to close the range with one of the following.
Character
Name
Code point
Equivalent markup
Comment
PDI
POP DIRECTIONAL ISOLATE
U+2069
end tag
used for RLI, LRI or FSI
PDF
POP DIRECTIONAL FORMATTING
U+202C
end tag
used for RLE or LRE
</bdo>
used for RLO or LRO
These characters are invisible, although in some editors it may be possible to show symbols that represent them. You could also use character escapes to represent them, such as ⁧, but in bidirectional source text you may find that the characters in the escape don't stay together. (See Working with source code markup and code examples for RTL scripts for more on this.)
When you apply directional formatting characters to indicate the boundaries of a directional run, you really want to avoid what's inside the boundaries interacting with what's outside – ie. you want to isolate it. For this reason, in an ideal world you would want to follow the recommendation of the Unicode Standard to use RLI and LRI, and avoid using RLE and LRE.
The following example shows how these control characters could be used in
plain text. It shows a tooltip in HTML that includes the title of the document linked to (which includes the abbreviation 'FAQ'), plus some text indicating the language of the destination document. Note how the text '(FAQ)' appears to the right of the Persian text. This is incorrect, since it is part of the (right-to-left) document title.
The correct title has the text '(FAQ)' to the left of the Persian text, as shown here.
To achieve the correct effect we add the two invisible control characters, U+2067 RIGHT-TO-LEFT ISOLATE (RLI), and U+2069 POP DIRECTIONAL ISOLATE (PDI), represented in the code snippet below as numeric character entities. Characters are shown in 'logical' order, rather than in the order they will be rendered.
In some cases the bidi algorithm copes fine with bidirectional text, and in others it needs some help. In Inline markup and bidirectional text in HTML we make the case that the easiest approach to marking up bidirectional text is to put markup at the start and end of each directional change in the text. This doesn't do any harm, it avoids the likelihood of missing a situation where markup is needed, and it makes the life of the content author much simpler. You should wrap the relevant text tightly.
Similarly, when dealing with Unicode control characters it makes sense to put directional formatting characters at the start and end of each directional change in the text.
However, it's important to bear in mind that ranges need to be nested appropriately. If you have an embedded LTR range in a RTL context, and that LTR range has some RTL text inside it, it won't produce the right result if your ranges are side by side rather than nested. Note how the direction changes are embedded in the following example, rather than side by side.
The title is ⁧AN INTRODUCTION TO ⁦C++⁩⁩ in Arabic.
Output in your browser:
The title is مدخل إلى C++ in Arabic.
Dealing with spillover issues
A classic example of a spillover effect is the following, where the opposite-direction phrase is followed by a logically separate number. This is the code with RLE...PDF around the opposite-direction text:
Bad code. Don't copy!
We find the phrase '‫INTERNATIONALIZATION ACTIVITY‬' 5 times on the page.
Output in your browser:
We found the phrase "פעילות הבינאום" 5 times on the page.
You would expect to see:
You would actually see:
This happens because the bidi algorithm tells the browser to treat the "5″ as part of the Hebrew text, ignoring that the preceding text is in a different embedding level. This is not appropriate. We need to find a way to say that the name and the number are separate things, ie. to isolate the inserted name from the number.
The RLI/LRI control codes solve this problem by isolating the embedded text from the number that follows it. You would simply use RLI...PDI instead of RLE...PDF.
We find the phrase '⁧INTERNATIONALIZATION ACTIVITY⁩' 5 times on the page.
Output in your browser:
We found the phrase "نشاط التدويل" 5 times on the page.
RLM and LRM
Unicode provides two other invisible format characters related to direction.
Character
Name
Code point
Equivalent markup
Comment
LRM
LEFT-TO-RIGHT MARK
U+200E
none
strongly typed LTR character
RLM
RIGHT-TO-LEFT MARK
U+200F
none
strongly typed RTL character
They are less problematic because they are used singly, ie. they are not used in pairs to delimit ranges of text like the other control characters we have discussed. However, they don't have the same power as the paired formatting codes. Because they are strongly-typed characters, they extend or break the ranges established by default by the bidi algorithm.
In the example above, we need to tell the bidi algorithm that the 5 is part of the LTR text. To do that, we can insert an LRM character before it.
We find the phrase 'INTERNATIONALIZATION ACTIVITY'‎ 5 times on the page.
Output in your browser:
We found the phrase "نشاط التدويل" 5 times on the page.
This will now produce the display we expect. Because the LRM code point is strongly LTR in direction, it breaks the link between the number and the preceding RTL text.
However, one thing these single characters cannot do is establish a base direction for an embedded range of inline text so that punctuation and nested direction changes are handled properly. For those use cases you need to use the paired characters.
Related issues
In this section we illustrate some additional spillover problems that can be solved using directional formatting characters.
In our first example, we have a list of same-direction runs of text (in this case RTL), which need to be ordered according to the overall context (in this case LTR).
Neutral characters between same directional runs can sometimes be misinterpreted by the bidi algorithm. In this use case we have several country names in Arabic listed in a LTR paragraph. This is an example of an opposite-direction phrase followed by another, but logically separate, opposite-direction phrase.
We expect to see the following:
If no formatting codes are used the actual result is that the first two Arabic words are reversed and the intervening comma is moved to the right side of the space between the words.
The reason for the failure is that, with a strongly typed right-to-left (RTL) character on either side, the bidirectional algorithm sees the neutral comma and space as part of the Arabic text. It is interpreting the first two Arabic words and the comma and space as a single directional run in Arabic. In fact the comma and space are part of the English text, and should mark the boundary between the two separate right-to-left directional runs in
Arabic.
The solution for this use case is to break the first two items of the list apart by either surrounding each list item with paired RLI/PDI codes, or by inserting the strong LTR-typed LRM character.
The names of these states in Arabic are ⁧EGYPT⁩, ⁧BAHRAIN⁩ and ⁧KUWAIT⁩ respectively.
The names of these states in Arabic are EGYPT‎, BAHRAIN and KUWAIT respectively.
Output in your browser:
The names of these states in Arabic are مصر, البحرين and الكويت respectively.
The names of these states in Arabic are مصر, البحرين and الكويت respectively.
Punctuation
It is very common for punctuation or some other neutral character to appear at the end of an opposite direction phrase and belong with that phrase.
Unfortunately, such neutrals between different directional runs are typically misinterpreted unless the Bidi Algorithm is given additional help. In the following example, the exclamation mark is part of the Arabic text and so should appear to
its left, like this:
Unfortunately, if we rely solely on the bidirectional algorithm we see this:
Given an understanding of the bidi algorithm we can easily understand why this happened. Because the exclamation mark was typed in
between the last RTL letter 'ب' (on the left) and the LTR letter 'i' (of the word 'in') its directionality is determined by the base direction of
the paragraph, ie. LTR in this case. Because the exclamation mark is seen as LTR it joins the directional run that includes the text
'in Arabic'.
We can fix this easily in one of two ways. We can simply add an RLM/LRM character after the exclamation mark. You need to choose the character that has the same directionality as the preceding phrase, thereby extending the length of the directional run to include the punctuation.
The title is "INTERNATIONALIZATION ACTIVITY!‏" in Arabic.
Output in your browser:
The title is "نشاط التدويل!" in Arabic.
Alternatively, you could wrap the opposite-direction phrase in paired controls, in this case RLI followed by PDI.
the title is "⁧INTERNATIONALIZATION ACTIVITY!⁩" in Arabic.
' [in persian]")
 SNOITSEUQ DEKSA YLTNEUQERF' [in persian]")