Introduction
RDFa provides a means to enable machine-readable markup of structured data in human-readable Web documents. Structured data that is contained in documents, such as people, films, companies, events, and so on, can provide an added layer of information to Web Applications. The RDFa API provides a set of interfaces that make it easy to access structured data in Web documents.
A document that contains RDFa effectively provides two data layers. The first layer is the information about the document itself, such as the relationship between the elements, the value of its attributes, the origin of the document, and so on, and this information is usually provided by the Document Object Model, or DOM [[DOM-LEVEL-1]].
The second data layer comprises information provided by embedded metadata, such as company names, film titles, ratings, and so on, and this is usually provided by RDFa [[RDFA-CORE]], Microformats [[MICROFORMATS]], DC-HTML, GRDDL, or Microdata.
Whilst this embedded information could be accessed via the usual DOM interfaces -- for example, by iterating through child elements and checking attribute values -- the potentially complex interrelationships between the data mean that it is more efficient for developers if they have direct access to the data after it has been extracted.
For example, a document may contain the name of a person in one section and the phone number of the same person in another; whilst the basic DOM interfaces provide access to these two pieces of information through normal navigation, it is more convenient for authors to have these two pieces of information available in one object.
This specification defines the RDFa API, which may be used by developers and Web Applications to access structured data contained in Web documents.
Design Considerations
RDFa 1.0 [[RDFA-SYNTAX]] has seen substantial growth since it became an official W3C Recommendation in October 2008. It has seen wide adoption among search companies, e-commerce sites, governments, and content management systems. There are numerous interoperable implementations and growth is expected to continue to rise with the latest releases of RDFa 1.1 [[!RDFA-CORE]], XHTML+RDFa 1.1 [[!XHTML-RDFA]], and HTML+RDFa 1.1 [[!HTML-RDFA]].
In an effort to ensure that Web applications are able to fully utilize RDFa, this specification outlines an API and a set of interfaces that extract RDF data from Web documents and other document formats that utilize RDFa. The RDFa API is designed with maximum code expressiveness and ease of use in mind. Furthermore, a deep understanding of RDF and RDFa is not necessary in order to extract and utilize the structured data embedded in RDFa documents.
Since there are many Web browsers and programming environments for the Web, the rapid adoption of RDFa requires an interoperable API that Web document designers can count on being available in all Web browsers. The RDFa API provides a uniform and developer-friendly interface for extracting RDFa from Web documents.
Since most browser-based applications and browser extensions that utilize Web documents are written in ECMAScript [[ECMA-262]], the implementation of the RDFa API is primarily concerned with ensuring that concepts covered in this document are easily utilized in ECMAScript.
While ECMAScript is of primary concern, the RDFa API specification is language independent and is designed such that DOM tool developers may implement it in many of the other common Web programming languages such as Python, Java, Perl, and Ruby. Objects that are defined by the RDFa API are designed to work as seamlessly as possible with language-native types, operators, and program flow constructs.
Goals
The design goals that drove the creation of the APIs that are described in this document are:
- Ease of Use and Expressiveness
- While this should be a design goal for all APIs, special care is taken to ensure that developers can accomplish common tasks using a minimal amount of code. While execution speed is always an important factor to consider, it is secondary to minimizing the amount of work a developer must perform to extract and use data contained in the document.
- Modularity and Pluggability
- This high-level API is part of a larger family of lower-level APIs for interfacing with RDF data on the Web. Special care has been taken to ensure that this API can be implemented without requiring the larger family of APIs. If the larger family of APIs is available, however, this API fits in nicely with those RDF APIs.
- DOM Orthogonality
-
Interfaces defined on the Document should match programming
paradigms that are familiar to developers. For example, if one were to
attempt to retrieve Element Nodes by Subject, the name of the method should
be
document.getElementsBySubject(), which roughly mirrors thedocument.getElementsByClassName()functionality that is a part of [[DOM-LEVEL-1]]. - Native Language Constructs
-
Data is exposed and processed in a way that is natural for ECMAScript and
many other Web programming languages like Python, Ruby and even C++. For
example,
Projection s are exposed as native language constructs.Graph s can be iterated over by providing an anonymous function or function pointer. By ensuring that programming language constructs are considered in the design of the API, we ensure that the API won't fight the language and thus, the developer. - CURIEs and Templates
- Some of the mechanisms that underpin RDF are difficult to use in everyday
programming. For example, having to type out an entire URI is not only
laborious for a programmer, but also error prone and overly-verbose. RDFa
Core [[RDFA-CORE]] introduces the concept of a Compact URI Expression, or
CURIE. This API builds on the CURIE concept and allows URIs to be expressed
as CURIEs. The API should also provide short-cuts that reduce the amount of
code that has to be repeated.
Projection Template s are one example of reducing repetitive code writing as it can be stored in a single variable and re-used when building Projetions.
Concept Diagram
The following diagram describes the relationship between all concepts discussed in this document.
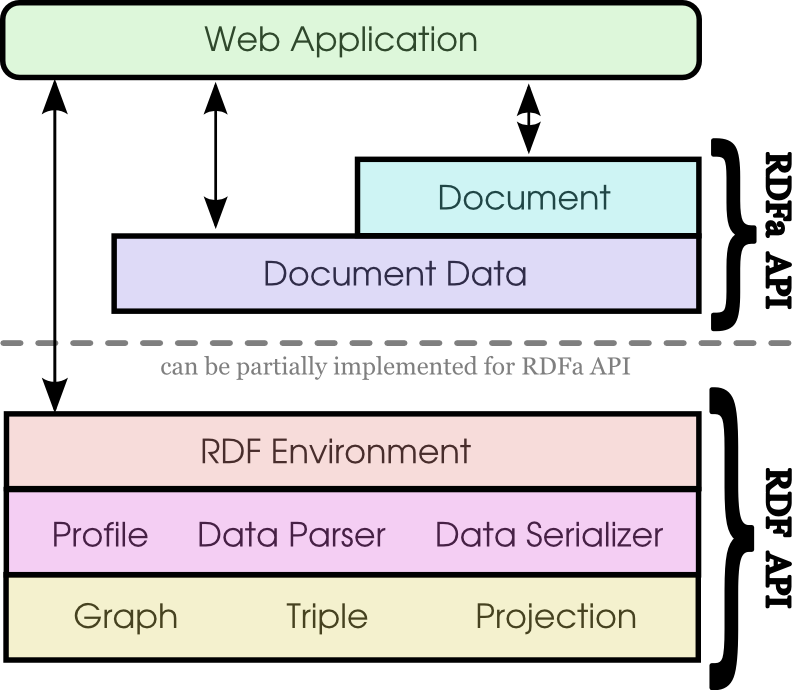
Concept Stack for the RDFa API and RDF API
The RDFa API is layered on top of concepts defined by the RDF API. The lowest level concepts are Triples, Graphs and Projections. Triples, Graphs and Projections are data structures used by Web Developers to work with data expressed in RDF languages. Working directly with the data structures can be cumbersome at times, such as the requirement to use absolute URIs when accessing properties, thus Profiles are provided to support accessing the data using compact URIs (CURIEs). Data Parsers and Data Serializers provide mechanisms to both read and write RDF data in a variety of RDF languages. All of these concepts are provided via a high-level interface called the RDF Environment.
API implementers should note that only the portions of the RDF API that are directly used by this API need to be implemented for a conforming RDFa API implementation. That is, only Projections are required to be implemented from the RDF API for a fully conformant RDFa API implementation.
The higher-level RDFa API provides two interfaces for accessing data in the document. Simple queries for DOM data may be performed using the Document interface, while more complex queries for structured data may be performed using the Document Data interface.