Henry S. Thompson, Liam Quin, Felix Sasaki, Michael Sperberg-McQueen
World Wide Web Consortium (W3C)
27 May 2008
- Much of the work reported here was produced by many W3C Working Groups, for whose
labours the authors of this brief survey are very grateful.
- XML is alive and well at the W3C
- Just past its 10th birthday
- Our focus today is on how the XML family of standards supports the
creation, distribution and exploitation of language resources
- We'll look at four areas in particular
- XML Validation with XML Schema and SML
- Search and retrieval within XML documents with XPath/XQuery
- Declarative XML processing with the XProc XML Pipeline language
- Internationalization support from XSL-FO and ITS
- A membership organisation which manages the high-level horizontal
standards of the World Wide Web
- Levels of technology and who manages them:
- The signals: IEEE, e.g. 802.11
- The bits on the wire: IETF, e.g. TCP/IP, DNS, HTTP (jointly)
- The Web: W3C, e.g. HTTP (jointly), HTML, XML
- Details of W3C Process can be found in the published paper
- One key point: all W3C standards are free to use
- As in royalty-free
- W3C exists and succeeds because interoperability (on the Web) is in
everybody's interests:
- Vendors
- Independent developers
- Corporate customers
- Individual users
- ELRA exists and succeeds because interoperability (of language
resources) is in everybody's interests!
- When we founded ELRA, there were two main barriers to interoperability
of language resources:
- Attitudes to resource ownership
- Idiosyncratic approaches to resource representation
- Several 'generations' later, the situation is much improved:
- The "There's no data like more data" viewpoint has triumphed
- Pretty much everybody believes the get more by giving their data
away than by keeping it to themselves
- We have a level of interoperable technologies which
many resources now exploit
- UTF-8 and UTF-16 encodings of UNICODE has mostly replaced the wide
variety of character encodings and character inventories we once had to deal with
- XML has to some extent replaced idiosyncratic line-oriented file formats
- What we don't have
- And technology alone can't provide
- is agreement on descriptive frameworks
- There are two main barriers to agreement on descriptive frameworks for
language resources (at all levels):
- The good reason:
- In many cases the underlying scientific questions simply haven't
been well-answered yet
- The less-good reason:
- The "not invented here" syndrome
- Those barriers are not going away
- Certainly not soon
- Possibly never
- The standards we're concerned with today can't change that
- But they can go a long way to minimizing the damage
- By providing interoperable and easily customised tool-chains for data
conversion and integration
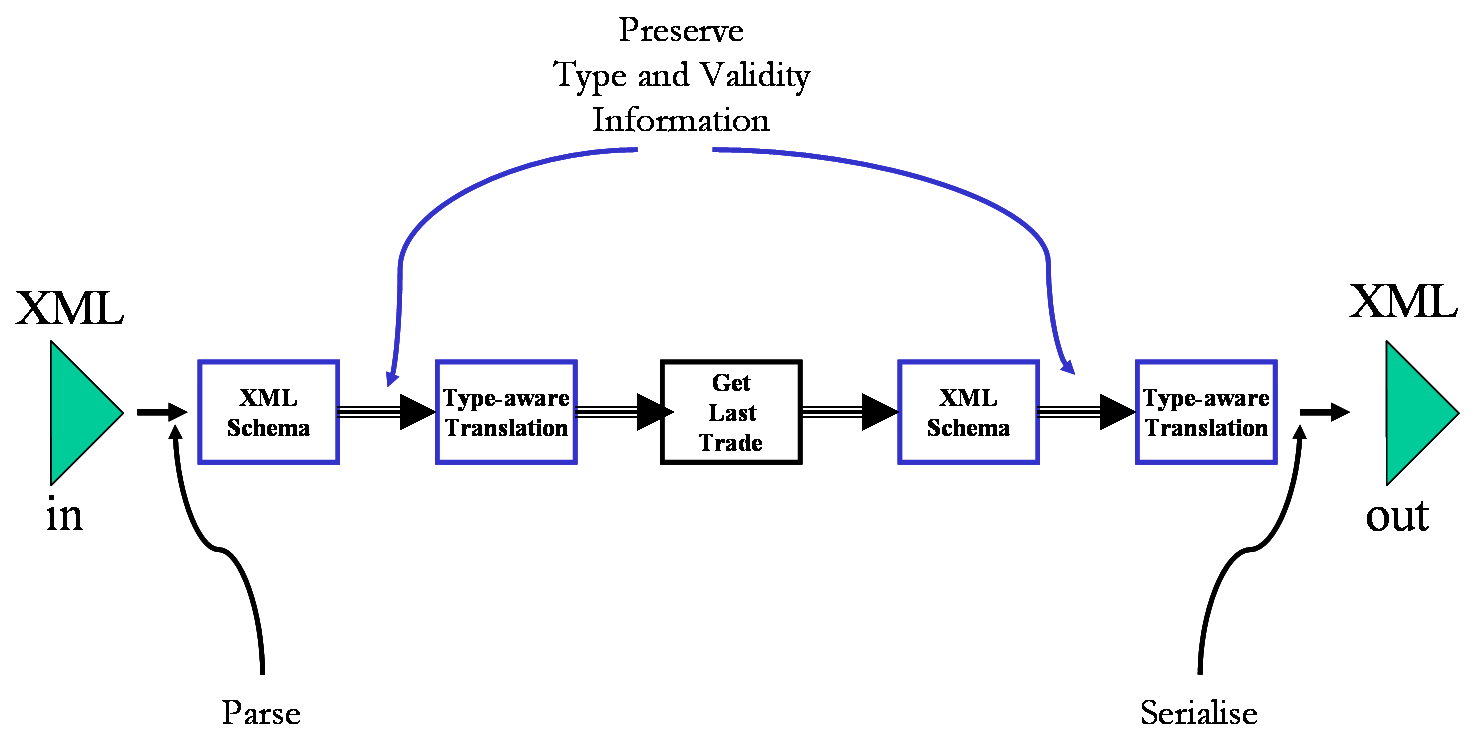
- "Validate at trust boundaries" (Dan Connolly)
- Not because you expect ill-will
- But to simplify your conversion and integration task
- Or to satisfy yourself of the quality and utility of your work
- Validation is also useful during development
- for debugging tool-chains
- for regression testing
- Any conversion/integration exercise begins with a comparison of source
and target representation schemas
- There are a number of schema languages around
- XML Schema 1.0 was a reconstruction of DTDs in XML itself
- Better datatypes
- Convergence between elements and attributes
- Built-in support for object-oriented design
- Integration with XML namespaces
- Provision for scoped uniqueness constraints
- Schemas that are well-structured and well-documented are much easier
to work with
- XSD has mechanisms to make both these properties easier to attain
- The tag/type distinction, type derivations, substitution groups,
modular schema construction
- Human- and machine- targetted annotations built-in to the language
- XSD 1.0 was published as a W3C Recommendation in 2001
- With a 2nd edition in 2004
- The next version, XML Schema 1.1, is nearing completion
- The Working Group has addressed some shortcomings
- Both in response to user feedback
- Many of the changes are directed at helping to manage language evolution
- Successful XML languages rarely remain fixed
- Managing the versioning of XML languages is a practical challenge
for many projects and institutions
- partial validity
- weakened wildcards
- open content
- not-in-schema wildcards
- multiple substitution-group heads
- all-group extensions
- default attribute groups
- conditional inclusion
- DTDs (SGML or XML) had a major flaw for use with large resource collections
ID and IDREF are at once too broad and to
restricted an instrument
- Too broad, because you can't limit their scope within a document
- Too restricted, because you can't check integrity
across documents
- XSD addressed the 'too broad' problem by providing scoped integrity constraints
- SML, a new specification, extends integrity constraints across
multiple documents
- XSLT, XSLT 2.0 and XQuery all share the same core mechanism for
identifying points in an XML document, namely XPath
- The XPath 1.0 and XPath 2.0 abstract syntax and data model share certain properties
- Their granularity stops at the string content of elements and attributes
- They address nodes in the element/attribute/whole-string level, not below
- They have very limited ability to select/match based on string content
- Full text changes this
- Includes new selection/matching primitives
- distances
- unit-based (words, sentences,
paragraphs)
- Augments the data model
- stemming
- thesauri
- stop words
- Full Text does not dictate specific algorithms for
full-text search implementations, but instead describes only
the results of operations
- (Thanks to Sean McGrath, from whom I borrowed some of what follows)
- XML pipelines are a declarative approach to developing robust, scaleable, manageable XML processing systems.
- based on proven software engineering (and mechanical
manufacturing) design patterns. Specifically:
- Assembly Lines (divide and conquer)
- Component assembly and component re-use
- Starting point:
- Input data conforming to spec.
A
- Output data conforming to spec. B
- Decompose the problem of getting from A to B into independent XML in, XML out stages
- Decide what transformation components you already have.
- Implement the ones you don't make them re-usable for the next transformation project.
- Before:

Amorphous blob of code
- After:
Pipeline
- A simple pipeline
<p:pipeline xmlns:p="http://www.w3.org/ns/xproc">
<p:xinclude/>
<p:validate-with-xml-schema>
<p:input port="schema">
<p:document href="http://example.com/path/to/schema.xsd"/>
</p:input>
</p:validate-with-xml-schema>
<p:xslt>
<p:input port="stylesheet">
<p:document href="http://example.com/path/to/stylesheet.xsl"/>
</p:input>
</p:xslt>
</p:pipeline>
Internationalization of XML
Summary of ITS data categories (1)
- "Translate" separating translatable from non-translatable content
- "Localization Notes" providing notes for localizers
- "Terminology" identification of terms and related information
Summary of ITS data categories (2)
- "Directionality" providing information to support mixed-script text
display
- "Ruby" markup for additional, e.g. pronounciation information
used often for Kanji characters
- "Language Information" identifying language information
following
BCP 47
- "Elements Within Text" identification of
different types of text flow behavior, like "mixed content"
vs. "block level" element
Using ITS locally
@translate identifies (non)
translatability of elements- "Translate" provides also defaults (attributes
not translatable, elements translatable)
<help xmlns:its="http://www.w3.org/2005/11/its" its:version="1.0"> [...]
<p>To re-compile all the modules of the Zebulon toolkit you need to go in the
<path
its:translate="no">\Zebulon\Current Source\binary</path> directory.
Then from there, run batch file
<cmd its:translate="no">Build.bat</cmd>.</p> [...]
</help>
- Short for "XML Style Language -- Formatting Objects
- Rich and powerful language for detailed control of document rendering
- Excellent support for different writing systems
- The W3C family of XML standards enable a toolchain for language
resource integration, conversion and exploitation
- Don't try to dominate, accommodate instead, using standards!
The next sections were
shown only briefly during the talk
- Think of XML processing in terms of XML infoset dataflows rather
than object APIs.
- This is critical and non-trivial focus-shift for many programmers!
- Pipelines provide a clean, robust and standards-based way to manage complex XML transformation projects.
- A series of small, manageable, 'stand alone' problems with an
XML input spec and an XML output spec
- Many steps just need XML standard technology
- Very team development friendly
- parallel development of loosely coupled
components
- Very debugging friendly
- XML processing for the forseable future will mostly consist of infoset-to-infoset transformation
- A lot of non-XML processing can consist of infoset to infoset
transformations with the addition of conversions from and to non-XML
formats at the margins
- The pipeline approach to data processing:
- Get data into XML and then infosets as quickly as possible
- Keep it as infosets until the last possible minute
- Bring all your XML tools to bear on solving the processing
problem
- Only write code as a last resort
"Terminology" example
<doc its:version="1.0" xmlns:its="http://www.w3.org/2005/11/its">
<section xml:id="S001">
<par>A <kw its:term="yes"
its:termInfoRef="http://en.wikipedia.org/wiki/Motherboard">motherboard</kw>,
also known as a <kw its:term="yes">logic <span its:term="yes">board</span></kw> on
Apple Computers, is the primary circuit board making up a modern computer.</par>
</section>
</doc>
The next sections were
not shown at all during the talk
- Pipelines are composed of steps; steps perform specific processes
- Steps are connected together so the output of one step can be
consumed by another
- Steps may have options and parameters
- XPath expressions are used to compute option and parameter values, identify
documents or portions of documents to process, and to select what steps
are performed.
- Document1 → XInclude → Document2
- Load → Document
- Document1, Stylesheet → XSLT 1.0 → Document2
- Documentsi…k, Stylesheet → XSLT 2.0 → Documentsm…n
- Document → Render-to-PDF
- Document1, Document2 → Compare → Document3
- Some steps contain other steps, the task they perform is at least partly
determined by the steps they contain.
- These steps provide the basic control structures of XProc:
- Grouping
- Conditional evaluation
- Exception handling
- Iteration
- Selective processing
- Pipelines
- Consider the XInclude+XSLT steps from the earlier slide:
- → XInclude → XML2, XSL → XSLT →
- You can construct a pipeline that performs these steps:
- → XInclude → XML2, XSL → XSLT →
- Pipelines can be called as atomic steps:
- Document1 → XInclude+XSLT → Document2
- Steps have a type and a name
- Steps have named ports
- The names of the ports on any given step are a fixed part of its signature
(the XSLT step has two input ports, “source”
and “stylesheet” and two output ports “result” and “secondary”)
- Inputs bind document streams to ports
- Started November 2005
- Members from large and small companies
- Several with Pipeline products already
- Several Working Drafts published
- Room for more members -- please consider joining us
- Many pipelines are linear or mostly linear.
- Many steps have a pretty obvious “primary” input and “primary” output
- Taken together, these to observations allow us to introduce a simple
syntactic shortcut: in two adjacent steps, in the absence of an explicit
binding, the primary output of the first step is automatically connected
to the primary input of the second.
- A
p:input binds input to a
port; its subelements identify a document or
sequence of documents:
<p:document href="uri"/>
reads input from a URI.
<p:inline>...</p:inline>
provides the input as literal content in the pipeline document.
<p:pipe step="stepName" port="portName"/>
reads from a readable port on some other step.
<p:empty/> is an empty sequence of documents.
- Compound steps contain other steps (subpipelines)
- Compound steps don't have separate declarations; the number
of inputs, outputs, options, and parameters that they accept can vary on
each instance.
- There's no mechanism in XProc V1.0 for user-defined
compound steps.
- Conditional processing:
p:choose
- Iteration:
p:for-each
- Selective processing:
p:viewport
- Exception handling:
p:try/p:catch
- Building libraries:
p:pipeline-library
- Choose one of a set of subpipelines based on runtime evaluation
of an XPath expression
- The XPath context can be any document, even documents generated by preceding
steps.
- Constraint: all of the subpipelines must have the same number of
inputs and outputs, with the same names. This makes the actual subpipeline
selected at runtime irrelevant for static analysis.
- Apply the same subpipeline to a sequence of documents
- A sequence can be constructed in several ways:
- As the result of a previous step
- By selecting nodes from a document or set of documents
- Literally in the
p:input binding
- XProc doesn't support counted iteration (do this three times) or
iteration to a fixed point (do this until some condition is true)
- Apply a subpipeline to some subtree in a document
- In other words, process just a “data island” in a document,
without changing the surrounding context
- Try to run the specified subpipeline
- If something goes wrong, catch the error and try the recovery subpipeline
- All the output from the initial pipeline must be discarded
- If something goes wrong in the catch, the try fails
- Constraint: both the subpipelines must have the same number of
inputs and outputs, with the same names. This makes the actual subpipeline
that produces the output irrelevant for static analysis.
- Useful pipelines can be stored in a library.
- Libraries can be imported to provide that functionality in a new
pipeline.
- 30 required steps
- add-attribute,
add-xml-base,
compare,
count,
delete,
directory-list,
error,
escape-markup,
http-request,
identity,
insert,
label-elements,
load,
make-absolute-uris,
namespace-rename,
pack,
parameters,
rename,
replace,
set-attributes,
sink,
split-sequence,
store,
unescape-markup,
string-replace,
unwrap,
wrap,
wrap-sequence,
xinclude,
xslt
- 10 optional steps
- exec,
hash,
uuid,
validate-with-relax-ng,
validate-with-schematron,
validate-with-xml-schema,
www-form-urldecode,
www-form-urlencode,
xquery,
xsl-formatter
- "Ready for prime time"!
- Start looking at how you can use pipelines in your business
- wildcards now allowed
- maxOccurs may be > 1
- may be extended
- extension of an all-group results in a new all-group
- must be true, for the instance to be valid
- expressed using XPath 2.0
- can point down, but not up
- like assert rules in Schematron
- like CHECK clauses in SQL
- For example "Every element of type haystack
must contain (somewhere) at most one needle element."
- For example "The value of the total
element must be the sum of the values of the item elements."
- decides which of several possible types to assign
- expressed using XPath 2.0
- can point at attributes, but not down, and not up
- E.g. (for ATOM)
"If the attribute@message-type is "text",
then
the element gets the type my:text-type;
else if the attribute@message-type is "html",
then
the element gets the type my:html-type;
else if the attribute@message-type is "xhtml",
then
the element gets the type my:xhtml-type;
else
the element gets the type my:text-type."
- easier to use wildcards
- fewer conflicts with elements ('weakened wildcards')
- automatic wildcards
- negative wildcards
- not-in-schema wildcards
- Versions of a vocabulary will differ
- just as different models may
- because we learn things
- Solution design for extensibility and induce V1 programs to accept V2 data
- Problem how?
- One way Distinguish
- Messages fully understood by V1 processors
- Messages tolerated by V1 processors
- Cf. HTML rule: "Ignore what you don't understand"
- This works for well-defined processing semantics
- Open content makes it easy
- Automagic wildcards inserted into content model
-
Details of the wildcard under user control
- elements in this namespace
- elements in other namespaces
- elements not declared in this schema
- ...
- Conditional inclusion allows schemas to
- use new constructs if the processor supports them
- fall back to other definitions if the processor does not
- "If the validator understands version 1.1,
then [define using open content and assertions],
else [define using XML Schema 1.0]."
- XML Schema 1.1 makes it easier to make vocabularies easier to version.
- Open content comes closer to redeeming the hopes many had for XML in the first place.
- XML standards work continues at W3C
- XML validation, data binding and processing will continue to get easier
and more powerful
- If you use XML at all
- Please read and comment on the forthcoming drafts
Using ITS globally (1)
- Identifying target markup with XPath
adding "Translate" information
<its:rules version="1.0">
<its:translateRule selector="//path | //cmd" translate="no"/>
</its:rules>
<help> [...]
<p>To re-compile all the modules of the Zebulon toolkit you need to go in the
<path>\Zebulon\Current Source\binary</path> directory.
Then from there, run batch file
<cmd>Build.bat</cmd>.</p> [...]
</help>
Using ITS globally (2)
- Referring to existing information in an
XML document
- Example: referring to an existing
"language information" BCP 47 value
(here
langinfo attribute)
<its:rules xmlns:its="http://www.w3.org/2005/11/its" version="1.0">
<its:langRule selector="//*[@langinfo] langInfoPointer="@langinfo"/>
</its:rules>
"Elements within Text" example
<doc>
<head>
<its:rules version="1.0" xmlns:its="http://www.w3.org/2005/11/its">
<its:withinTextRule withinText="yes" selector="//b|//u|//i"/>
<its:withinTextRule withinText="nested" selector="//fn"/>
</its:rules>
</head>
<body>
<p>This is a paragraph with <b>bold</b>, <i>italic</i>, and <u>underlined</u>.</p>
<p>This is a paragraph with a footnote
<fn>This is the text of the footnote</fn> at the middle.</p>
</body>
</doc>
Ruby example
<text xmlns:its="http://www.w3.org/2005/11/its">
<head> ...
<its:rules version="1.0">
<its:rubyRule selector="/text/body/img[1]/@alt">
<its:rubyText>World Wide Web Consortium</its:rubyText>
</its:rubyRule>
</its:rules>
</head>
<body>
<img src="w3c_home.png" alt="W3C"/> ...
</body>
</text>
Application areas of ITS
- Supporting (automatic) translation tools and
localization tools
- Term extraction
- Spell check support
- etc.