Michael(tm) Smith
W3C HTML WG Co-Chair
W3C Web Apps WG Co-Team Contact
with extensive borrowings from Anne van Kesteren and Simon Pieters
“HTML5: A vocabulary and associated APIs for HTML and XHTML”
original title: “Web Applications 1.0”
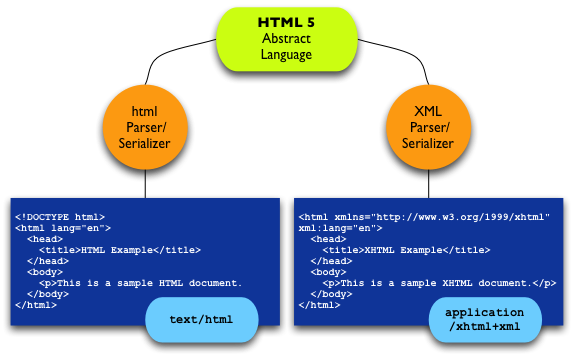
(re)defines HTML as an abstract language
text/html

What does HTML5 not do?
HTML5 does not treat HTML as SGML
HTML5 does not use DTDs
Browsers do not have SGML parsers — they don’t check DTDs or follow other SGML parsing rules.
Instead, they use custom parsers built specifically for parsing HTML
HTML5 does specify an XML serialization of HTML…
…but HTML5 does not restrict HTML to only a (well-formed) XML-based serialization
text/html: attribute syntaxAll of the examples below are conformant HTML
<input disabled="disabled"><input disabled><input value=yes><input type='checkbox'><input name="be evil"><!DOCTYPE html PUBLIC
"-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><!doctype html><meta
http-equiv="Content-Type"
content="text/html;
charset=utf-8"><meta charset="utf-8">Why not restrict HTML to well-formed XML (that is, XHTML)?
XML requires draconian error handling for all content served as XHTML…
…which means that for any XHTML page that contains even one single minor error…
…a browser must fail to display the page at all…
…and because the vast majority of HTML on the Web is not well-formed XML…
…we need to interoperably handle that “real world” (or “tag soup”) HTML
HTML5 includes a precise algorithm for exactly how conformant UAs/browsers must parse HTML (an algorithm that closely matches existing browser implementations)…
…including parsing of HTML that may not
be well-formed XML and is served up as
text/html
Recognizing that many authors produce non-conformant documents and that apps need to deal with such documents, HTML5 precisely specifies handling of markup errors and other classes of errors — so that such errors will be handled in an interoperable way across UAs/browsers
We need to specify error handling behavior to ensure interoperability “even in the face of documents that do not comply to the letter of the specifications”.
Authors will write invalid content regardless of what we spec. So the spec states “what authors must not do, and then tells implementors what they must do when an author does it anyway”.
see http://esw.w3.org/topic/HTML/DraconianErrorHandling and Ian Hickson’s “Error handling and Web language design”, http://ln.hixie.ch/?start=1074730186
So what’s new/different in HTML5?
<input>New elements…
New elements for better document structure…
<section><nav><article><aside><header><footer>canvas element: img, but scripted…
Used on Y! Pipes…
<canvas width="150" height="200" id="demo">
<!-- fallback content here -->
</canvas>
<script type="text/javascript">
var canvas = document.getElementById("demo"),
context = canvas.getContext("2d")
context.fillStyle = "lime"
context.fillRect(0, 0, 150, 200)
</script>
video and audio elementsAlong with new elements, we also have new APIs
Persistent client-side data storage
Standards-based Web applications work the same across browsers, so users are not locked into using any particular product from any particular vendor. Users get to choose.
