This document is an early draft of a submission to the VLDB conference. This is not endorsed by the W3C or its membership.
Much of the world's data are found inside databases of one kind or another, primarily relational databases. Even greater amounts of data reside in ordinary flat files, email archives, and the like. Integration of all of that data would provide tremendous benefits to the organizations that own the data.
RDF is a general proposition language for the Web, unifying data from diverse sources. SPARQL, a query language for RDF, can join data from different databases, as well as documents, inference engines, or anything else that might express its knowledge as a directed labeled graph. SPARQL is an excellent language to unify data in relational databases with other databases, as well as these other data sources.
The emergence of the Semantic Web has inspired several gateways between RDF and conventional relational stores. Systems like Virtuoso, D2RQ and SquirrelRdf rewrite SPARQL queries to SQL. Oracle's 10.2 release and the MySQL SPASQL module compile SPARQL queries directly into an evaluation structure to be executed by the relational engine. Adding native SPARQL support to the database allows the same performance as for well-tailored SQL queries.
Conventional relational databases are most commonly accessed through SQL. The relationship between data in different databases is managed by custom data warehousing tools that have specific knowledge about a small set of databases and present a view of combined data. This set-wise combination requires warehouse developers to stay ahead of users' demands or sharply constrains users' capacity to join disparate data sources. As the number of data sets grows, the interactions between the grows exponentially, rendering conventioal warehousing techniques impractical for large amounts of data sources.
One challenge in integrating disparate relational data sources within a single query is the need for universally grounded identifiers for tuples and attributes. For example, one could imagine making an SQL-like language with URLs for the table column names and to identify each tuple.
RDF essentially provides this universal grounding, by naming all entities and attributes with URIs, a generalized form of URLs. In RDF, each tuple is expressed not as an n-ary proposition with named slots, but instead as a set of binary propositions with the relations being the names of the slots.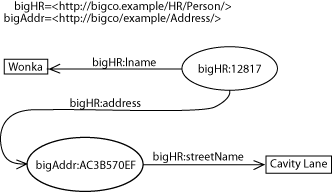
RDF's graph model lends itself well to expressing relational data. Foreign key relationships are simply expressed as arcs in the graph, rather than as coincident attributes, simplifying queries that express such joins. By using URIs in propositions, SPARQL addresses some key database federation challenges: unique attribute identification and unique tuple identification.
We wish to show the reader how RDF and SPARQL can be used to improve access to relational databases. We will frame most of our example data and queries on a simple data integration use case. We will discuss the semantics of that data in conventional databases; in particular, the semantics of link relationships and datatypes.
We will introduce RDF and SPARQL and discussion various techniques for improving mappings between RDF and relational data. An implementation survey will show what existing code is available, and where the development energy lies.
While use cases for datbase federation abound, we will use this collaboration use case to describe SPARQL queries over relational databases.
A common data integration challenge occurs when one company acquires another and needs to merge the databases. Consider that bigCo acquires littleCo and the bigCo human resources department is now responsible for all of littleCo's employee profiles. As the two database were independently developed, the data integrators face the challenge of supporting useful queries that execute over both databases.
A manager, "Sue", believes that bigCo should present at the upcoming Widget Workshop. She looks for employees who have published papers on widget construction, widget delployment, or widget result analysis. Her goal is to find employees with overlapping skillsets and work at the same site.
While there are many ways employee profiles may indicate skillsets, for simplicity of examples, we examine the keywords of published papers.
Conventional approaches would involve:
Each of these involves a significan cost; a cost that can be avoided by using a query tool with the appropriate expressivity. Development of such a tool also has a significant cost, but that cost is ameliorated through re-use with other databases.
Organizations of all sorts have information scattered around in a number of media, ranging from flat files and email archives to relational and object-oriented databases to spatial and text systems. As various industries go through periods of consolidation, the organizations in those industries find themselves purchased by, merged with, or purchasing other organizations, which only magnifies the problem of distributed data.
Users of SQL DBMSs have dealt with this problem for a couple of decades with varying solutions and varying success. In the last decade or so, SQL implementations have productized the solutions that give the greatest amount of success for the broadest set of requirements. Examples include <<cite IBM's distributed database consolidater>>, <<cite Oracle's distributed database consolidater>>, and <<cite Sybase's distributed database consolidater>>.
While those products give a lot of power to data integrators, they have serious weaknesses. First, they are primarily (sometimes exclusively) able to integrate only data from two or more SQL databases -- and they usually work better when all of the databases are from the same implementer as the <<consolidator>>. Second, they provide little or no ability to automate the creation of meaningful views that combine closely related data from those disparate sources. In addition, their work is complicated because of differing privilege and security models, as well as different authorization assignments amongst the various databases. Finally, they tend to be rather brittle and don't deal easily with changes within the databases whose data are being integrated.
Those weaknesses require system administrators, database administrators, and programmers to expend significant effort to overcome. As the amount and number of sources of data continues to grow, the administrative and programming burdens increase (and not always linearly at that!). Tools that ease those burdens would be very beneficial to medium and large enterprises (perhaps not as much to small enterprises).
One of the biggest problems in integrating data from disparate sources, even if they are all SQL databases managed by DBMSs from the same implementor, is finding ways to match data in one database to data having the same semantics in another database.
Within a single SQL database, data managers are able to provide a syntax-level, structural way of tying data in multiple tables together: foreign keys. One or more columns in one table are declared to be a foreign key whose (combined) values match values in the same number of columns in one or more rows of another table. For example, a PROJECTS table might have a column that identifies the department responsible for the project, so there would be a foreign key defined on the OWNING_DEPARTMENT column in the PROJECTS table that references the DEPT_ID column in the DEPARTMENTS table.
SQL applications typically combine such related information from, say, PROJECTS and DEPARTMENTS by performing a join based on the relationships between values in columns of the two tables. In this case, it would make sense to join rows in these two tables based on equality of values in the two columns -- that is, match each row in the PROJECTS table with one or more rows in the DEPARTMENTS table for which the value in that row of the OWNING_DEPARTMENT column is equal to the value in the DEPT_ID column.
Unfortunately, SQL doesn't have a join operator to express the request "join two tables based on a foreign key relationship", so each application programmer has to determine which such relationships exist and write explicit joins for each required situation. In toy databases, that's a trivial exercise. Real-world databases have hundreds of tables, many having thousands of columns and millions of rows, making it impossible for one programmer to remember all of the foreign key relationships that might exist. That requires still more work as the programmer has to pause his primary task to reference database documentation to find out what such relationships might exist. The solution is obvious -- make the relationships obvious so the programmer doesn't have to take that extra step!
But the tricky bit is this: How can an arbitrary entity "know" that OWNING_DEPARTMENT has anything at all to do with DEPT_ID? In the example we've just seen, the foreign key links values of one column of one table to values in a corresponding column of another table...but so what? SQL is oblivious to subtleties such as "do those columns have anything to do with one another"? SQL would be equally happy to match the NUM_OF_ENGINEERS column in the PROJECTS table with the DEPT_ID column of the DEPARTMENTS table (assuming, of course, that the columns had a comparable data type).
While the problem is serious enough when both tables are found in the same database, it gets much worse when the tables are spread around databases that were designed with greatly differing requirements in organizations with radically different cultural climates making significantly different assumptions.
Ideally, application developers should be able to use some tool -- perhaps a GUI-based modeling tool -- that would allow them to easily identify tables whose relationships might be relevant to the application(s) under development, as well as columns within those tables that have some relationship based on characteristics other than the column names and/or programmer knowledge.
And that is precisely where the Semantic Web comes in. If (and today that's a really big "if") some additional (non-structural) metadata has been created for each of those tables, the chances of performing joins based on explicit foreign key relationships (without unreasonable programmer effort) increases significantly. Better yet, there may be implicit relationships of the same sort -- relationships where there is no SQL schema definition of a foreign key relationship, but where there are columns in multiple tables that are tightly bound in meaning.
Unfortunately, creation of such metadata on a large scale (hundreds of databases, hundreds of tables in each, thousands of columns in many tables, etc.) is improbable. It's unlikely enough that new databases will have such metadata consistently provided, and the chances are nearly nil that existing databases will be retrofitted with it.
So what can be done to use the semantics that exist without sophisticated metadata describing all of those relationships? For good or ill, SQL's structural metadata is the only meaningful source of such information. That, of course, exists in single databases in the form of foreign keys. Foreign keys capture the idea that "I don't know what this stuff means, but I do know that it means the same thing as that stuff". In other words, there is a pretty good assumption that the values of the referencing column(s) mean the same thing to the database and the applications as the values of the referenced column(s).
Just possibly, database designers might capture a similar level of semantics in the use of SQL's distinct data types. In SQL, a distinct type is one based on another type, but with its own set of operations. For example, a database designer might create a distinct type named DEPT_ID based on INTEGER. By default, DEPT_ID would have no operations defined on it, and values of DEPT_ID could not be used simply as though they were values of INTEGER. The database designer would have to define operations on values of type DEPT_ID according to its semantics. However, it is easy to determine that every column in every table of a database whose data type is DEPT_ID mean the same thing.
When multiple databases are involved, things get more complicated. Most SQL engines don't support cross-database foreign keys and those that do usually limit them to databases residing on the same server. As a result, there is rarely the opportunity to use foreign keys to unify information from two or more databases.
However, there may well be distinct types defined in each of two or more databases for the same concept, such as "department codes". In one database, the distinct type might be named DEPT_ID and in another it might be named DCODE, which complicates things a bit. But a relatively small amount of additional semantic metadata goes a very long way towards unifying those concepts. And if that additional metadata is provided in the form of an RDF graph using both RDFS and OWL, the relationships between the distinct types, and the columns that are defined on them, begin to solidify. It becomes possible to apply automatic reasoning to collections of such metadata to determine more and more such relationships, whether they are explicitly provided or not.
With all of this in mind, a small case study will help clarify both the nature of the problem and the approach to a solution.
This paper assumes a familiarity with relational databases and SQL. RDF concepts are summarized here.
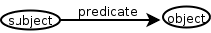 The RDF data model consists of triples consisting of two nodes, (
The RDF data model consists of triples consisting of two nodes, (subject and object) and a predicate identifying their relationship.
The RDF terms in this paper are either literals or URIs. Literals are nodes that represent their lexical value. Literals are indicated by boxes with the lexical value inside.
 They may have either an ISO language tag or an XML Schema datatype.
URIs represent resources in the world on the Web. They are represented as ellipses with their identifiers inside.
They may have either an ISO language tag or an XML Schema datatype.
URIs represent resources in the world on the Web. They are represented as ellipses with their identifiers inside.
 The other form of RDF node, blank node, is not used in this paper.
The other form of RDF node, blank node, is not used in this paper.
A taxonomy is a dictionary of terms representing a common understanding within some community. The difference between a schema a taxonomy and an ontology is just a matter of degree.
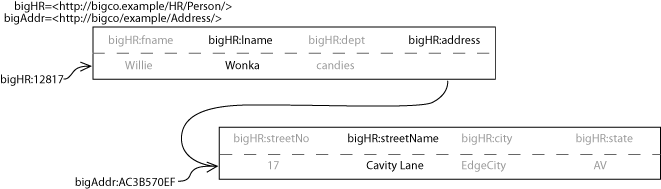
Examples of RDF in this document are either expressed as pictures of directed labeled graphs, or in a language called Turtle. Turtle represents RDF triples as subject predicate object, terminated by a ".". Turtle also allows URIs to be abbreviated via the use of namespace prefixes (similar to those in XML). The following example of Turtle contains two triples, representing the first name and address of an employee at the hypothetical company, bigCo:
@prefix hr: <http://bigco.example/HR/Person/> . @prefix ofcs: <http://bigco.example/HR/Office/> . hr:e12817 hr:fname "Willie" . hr:e12817 hr:primaryOffice ofcs:AC3B670EF . ofcs:AC3B670EF ofcs:site <http://bigco.example/site/binnyStreet> .
SPARQL is a query language for RDF. The subset of SPARQL used in this paper can be described as
[prefix declarations] SELECT <variable list> WHERE { <graph pattern> }
Prefix declarations in SPARQL are similar to those in Turtle. SPARQL graph patterns are built up from basic graph patterns. Basic graph patterns are simply Turtle triples that may contain variables in place of the subject, predicate, and/or object terms. Consider this example SPARQL query:
PREFIX hr: <http://bigco.example/HR/Person/>
PREFIX ofcs: <http://bigco.example/HR/Office/>
SELECT ?givenName
WHERE { ?who hr:fname ?givenName .
?who hr:primaryOffice ?office .
?office ofcs:site <http://bigco.example/site/binnyStreet> }
This query asks for the first name (fname) of all the employees in bigCo's database who work at the binnyStreet site.
SPARQL graph patterns can be combined into more complex graph patterns by including UNIONs (like SQL UNIONs) and OPTIONALs (very much like LEFT OUTER JOINs).
PREFIX hr: <http://bigco.example/HR/Person/>
PREFIX ofcs: <http://bigco.example/HR/Office/>
SELECT ?id ?primarySite ?secondarySite
WHERE { { ?who hr:employeeID ?id }
UNION { ?who hr:contractorID ?id }
?who hr:primaryOffice ?office .
?office ofcs:site ?site
OPTIONAL { ?who hr:secondaryOffice ?office2 .
?office2 ofcs:site ?site2 } }
This query gets the ids and sites of all the employees and contractors. It also gets their secondary site if there is one in the database.
Like many SQL dialects, SPARQL has LIMIT and OFFSET to control report slicing.
The semantics of SPARQL are defined in terms of relational algebra (joins, left outer joins, unions). Once an RDF representaion of a tuple and a foreign key are chosen, each SPARQL query has a defined interpretation in relational algebra. Of course, only queries that correspond to the existing relational data will be useful.
The expressivity of SPARQL constraints is much less than that of SQL. The constraints are a subset of the XPath functions used in XQuery, and a few functions specific to the RDF data model.
As we've mentioned, the power of SPARQL to perform data-integration tasks by performing single queries that span multiple databases does not require that data be stored natively as RDF. Instead, there need only be some set of rules that describe how data residing according to a legacy relational schema can be modeled as an RDF graph. We refer to such a set of rules as a mapping. There are many facets to such a mapping, and existing tools take different approaches to these various facets. What follows is a look at the tasks that a mapping must accomplish, and the choices that implementations make when defining their mappings.
We've seen already that one benefit of the RDF data model is the use of URIs as a universal identifier syntax for referring unambiguously to entities and relationships. While the SPARQL queries (which operate against an RDF data model) will use these universal names, the mapping must provide information on translating these names back into the traditional, shorter names used for tables and columns within a database. Further, the primary keys that unambiguously identify rows within a relational model must also be incorporated into URIs to unambiguously identify nodes within an RDF graph.
The most straightforward way of moving between table and column names and URIs involves creating URIs that embed the names of databases, tables, and columns within them. For example, the RDF used in the Terminology section uses the following predicate for the first name relationship: <http://bigco.example/HR/Person/fname>. By syntactic convention, this predicate maps to the fname column of the Person table in the HR database. A system utilizing automated mappings based on relational schema would know to always construct and expect predicate URIs of the form http://bigco.example/<<database name>>/<<table name>>/<<column name>>. A similar approach can be used for generating the URI of resources which act as the subjects of relations. These resources correspond to rows in the database, and their URIs can be automatically generated from the values in the primary key column(s) in a table. Thus, the same example from the Terminology section contains the URI <http://bigco.example/HR/Person/e12817>.
Generating automated mappings from relational schemas is appealing because the URIs can be generated with no intervention from the user. On the other hand, automated mappings such as this do not take advantage of shared vocabulary terms and, as such, lose some of the intended benefits of using common universal names.
In systems that utilize automated mappings, the same mapping applies to all relations and all resources. An alternative approach allows configuration information to specify how to translate certain database columns into RDF predicates and certain tables' rows into RDF resources. These configurable mappings are usually based on URI templates, skeletons of URIs into which zero or more pieces of information from the relational schema (database name, table name, column name, primary key column value) can be inserted. The simplest version of a configurable mapping maps a collumn directly to a literal URI. For example, the column HR.Person.fname in the above example could be configured to map directly to <http://xmlns.com/foaf/0.1/givenname>. A parametrized template might be used to map a pharmaceutical company's in-house protein database to standard URIs corresponding with accession numbers published by the NCBI: <http://www.ncbi.nlm.nih.gov/proteins/<<primary key>>/>. (Note that the approach for configuring these mappings must be invertible in order that URIs specified in SPARQL queries can be translated back into the appropriate database columns and rows.)
In the relational model, attributes of one entity that refer to another entity are expressed via foreign key constraints. In addition to specifying how to name resource and relations within the RDF model, mappings must also specify how to expose foreign key relationships (joins) within the RDF model that is queried with SPARQL. There are several approaches to this:
The most straightforward way to represent foreign key relationships in the RDF model is by explicit exposure of the attribute values used to establish the relationship within the database. In this case, a SPARQL query must reflect this simultaneous atribute constraint:
...
WHERE { ?who person:primaryOffice ?officePk .
?office ofcs:primaryKey ?officePk .
?office ofcs:site <http://bigco.example/site/binnyStreet> }
Notice the inclusion of the artificial ?officePk variable, which is included in the SPARQL query only to link the office and site resources together. This interpretation of a SPARQL query is effectively a transliteration of the SQL-style of join constraint:
...
FROM person
INNER JOIN site ON person.primaryOffice=office.primaryKey
WHERE office.site="binnyStreet"
Conceptually, the object of a foreign key relationship is the resource itself, rather than a data value used to identify the resource. Because a node within an RDF graph can serve as both the object and subject of relationships, a SPARQL query carries with it enough information to express foreign key relationships implicitly. Consider this rewriting of the above example:
...
WHERE { ?who person:primaryOffice ?office .
?office ofcs:site <http://bigco.example/site/binnyStreet> }
This query implicitly communicates the fact that person.primaryOffice is a foreign key to the primary key in the office table. Given the mappings between relational columns and RDF predicate names already discussed, existing mapping systems can use foreign-key relational schema information to correctly interpret queries like this one. In the absence of foreign-key constraint information, RDF schema information that defines the domain and range of a predicate can be used to determine which relational table holds the primary key of a foreign-key relationship.
By reading either the foreign-key constraint-data within the relational schema or the RDF schema domain and range information, a mapping system can automatically determine the information needed to process implicit joins within SPARQL queries. Some database configurations are more complex, however, and require a configurable mapping of relationships between tables. These mappings allow the configurations to specify additional join conditions and to specify explicitly the tables and columns involved on both sides of the join.
A variety of systems currently exist that use the above strategies to expose relational data to SPARQL queries. Most of these are linked from the ESW Wiki page RdfAndSql. A brief survey of them follows here:
SquirrelRDF is an open-source project from Damian Steer at HP Labs that seeks to expose LDAP and relational data sources as RDF. It automatically generates URIs from relational schema information and requires explicit joins within SPARQL to query relationships between entities.
D2RQ is a declarative mapping language (and an implementation of the mapping language within the Jena Semantic Web toolkit) produced by Chris Bizer, Richard Cyganiak, and Jorg Garbers of Freie Universität Berlin and by Oliver Maresch of Technische Universität Berlin. D2RQ uses highly configurable mappings to translate between relational entities and attributes and URIs and also to map foreign key relationships into joins implicit within SPARQL. D2RQ functions as a query rewriter: it takes as input a mapping and a SPARQL query and produces as output SQL to run against the target relational database.
Virtuoso is a commercial and open-source object-relational database system developed by OpenLink Software. Its query-rewriting approach is similar to D2RQ. However, whereas D2RQ specifies its mapping information via an RDF vocabulary, Virtuoso uses SQL-language extensions to declare and configure the mapping.
DartQuery is a component of the DartGrid application framework which rewrites SPARQL queries as SQL against legacy relational databases. It uses a Datalog-like language to define views such that each legacy relational table is seen as one particular view of one or more classes from an RDFS/OWL ontology. DartQuery does not concern itself with generating URIs, but instead focuses on using RDF Schema and OWL semantics to map SPARQL queries down to relational data.
Oracle's RDF Data Model is part of Oracle's Spatial 10g release. SPARQL queries, wrapped in SQL, query a triple-based data store. The same queries can also query conventional relations, though not yet from SPARQL.
SPASQL is an open-source module compiled into the MySQL server to give MySQL native support for RDF. Mapping will be added, using the D2RQ mapping language.
RDF graphs and relational databases have notions of schema, data structures that take a first cut at describing well-formed application data. In relational databases, this is frequently expressed as extensions to SQL (extensions??? i don't know SQL ∞) table construction directives and queried as a specially named SQL table. In RDF, these are expressed is specific graph constructions that advise of additional propositions that one can infer about the instance data.
The example data above can be expressed in common RDF terms:
@prefix hr: <http://bigco.example/HR/Person/> . @prefix ofcs: <http://bigco.example/HR/Office/> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . @prefix wail: <http://www.eyrie.org/~zednenem/2002/wail/> . hr:e12817 foaf:givenname "Willie" . hr:e12817 wail:workAddress ofcs:AC3B670EF . ofcs:AC3B670EF wail:locatedIn <http://bigco.example/site/binnyStreet> .
Two RDF taxonomies are used (together) to express specific data structures in an RDF graph. RDFS expresses subclass relationships, subproperty relationships and domain and range of RDF predicates. RDFS cannot directly be used for validation. OWL is a much more complex language. It allows one to make more complex inferences and express cardinality constraints and contradictory propositions. This is useful for sanity checking as poor modeling can lead to an inconsistent system. Below is a summary of some key constructions from both languages:
| example use | implication | ||
|---|---|---|---|
| rdfs:domain | P1 rdfs:domain C1 . a P1 b . |
a rdf:type C1 . | |
| rdfs:range | P1 rdfs:range C2 . a P1 b . |
b rdf:type C2 . | |
| rdfs:subClassOf | R1 rdfs:subClassOf R2 . R2 rdfs:subClassOf R3 . a rdf:type R1 . |
R1 rdfs:subClassOf R3 . a rdf:type R2 . a rdf:type R3 . | |
| rdfs:subProperyOf | P1 rdfs:subPropertyOf P2 . P2 rdfs:subPropertyOf P3 . a P1 b . |
P1 rdfs:subPropertyOf P3 . a P2 b . a P3 b . | |
| owl:onPropery | C1 rdfs:subClassOf C2 . C2 rdf:type owl:Restriction . C2 rdfs:onProperty P1 . C2 rdfs:allValuesFrom R1 . a rdfs:allValuesFrom t1 . t1 rdf:type R1 . |
a rdf:type C1 . | :Cat rdfs:subClassOf X . X rdf:type owl:Restriction . X rdfs:onProperty :child . X rdfs:allValuesFrom :kitten . mewler :child :kitten . |
Simple mappings can be tailored for any database to enable it to serve intuitive common queries. We may, for example, wish to express Person.fname as foaf:givenname. FOAF is a popular vocabulary for expressing social networks. The FOAF community has written a large amount of presentation and link analysis software for this taxonomy. If a custodian of the HR database configured the database to map foaf:givenname to the fname attribute, they would grant a large community a familar term for that attribute. Also, some software written for the FOAF taxonomy would work with the HR data.
One-to-many and many-to-many relations are frequently modeled as repeated properties in RDF. Consider relations {People, Groups, GroupToPerson}, where the latter expresses a many-to-many relation between people's membership in groups. The most convenient way to write that in RDF is as a repeatd property.
:groupX :hasMember :Alice . :groupX :hasMember :Bob . :groupY :hasMember :Alice .
In effect, this :hasMember predicate is expressing a pair of joins to associate a person with a group. Dart Grid and D2RQ have this expressivity.
@@Jim, Susie indicated that you might have lots to say about mappings. Is it about this kind of mapping?@@
This opperation can be assisted by a GUI tool, for example Dart Grid. Dart Grid takes an ontology expressed in RDF Schema and OWL and a connection to database. It allows the user to associate database relations (tables) with RDF classes, and database attributes (column headings) with RDF predicates. The schema advises the user of relationships between objects in the taxonomy. The user associates the attributes of a given relation with the properties of a given class. This information, combined with the object relationships in the RDF Schema, allows tools to infer the logical foreign key/primary key relationships in the relational data.
The semantics for RDF data include monotonicity; no data should be added that invalidates a previous conclusions. For instance, imagine a predicate http://bigco.example/salesTerms#city is localized (from when bigco was a small company) to cities in Oregon, and a script that queries the city and street address in order to sends advertisiments. As bigco expands its sales to neighboring Washington, it is insufficient to add a predicate for the state without reliably visiting all the consumers of the data. If it is impractical to discover each consumer, as it is for web data or relational data in a large institution, it is practical to migrate gracefully by publishing the data evolved data under a new identifier. The objects of the #city predicates can be re-expressed, paired with the appropriate state code, as objects of a new #a2state predicate.
In this way, RDF data is consistent with the deployment strategies for large SQL systems. There is some added burden on the smaller publishers if they make their data available on the web vs. keep it in-house with easily controlled availability.
Until recently, much of the relational data has been exported into RDF; RDF query interfaces to relational databases is a fairly recent development. RDF triple stores, consisting of a subject, predicate and object, were developed early and are currently widespread. Queries against these databases were expensive as each triple in the query implied a new self-join. Further, the data is not efficiently indexed because assumptions of a unique indexes on tuples break down when that tuple is split into several tuples, one per attribute.
Triple stores have the advantage of being very flexible and are an excellent way to store fringe data. Projects like FeDeRate allow the normalizable data to be stored in conventional relations, and the fringe data, where the schema is evolving quickly, to be stored in triple stores. Queries can join access to the two types of database, sacrificing neither the efficiency of normalized queries nor the flexibility of triple stores.
Expressing relational data in RDF gives us insights as to how to evolve this data into a world wide web of data. This data needs identifiers that are globally unique to avoid ambiguity when merging independently developed databases. Much as views free users from the details of the tuple arrangement, expressing data in an abstract form, like triples, allows greater flexibility and re-use of queries across different databases.
Of course, the data need never be expressed in RDF. Several query engines map SPARQL queries to relational queries, either by re-writing into an SQL query, or by compiling directly into evaluation structures native to the database. The latter gives a performance almost exaclty equivilent to that of SQL. Given the efficiency, the globally-grounded terms, and the terse, portable queries, SPARQL is an excellent language to unify the databases of the world.
The development of self-adjusting heterogeneous databases will free both users and administrators of many of the details of the storage model. With SPARQL, the same query can work as the data evolves from a flat file, to an XML file, to various topologies of relational database; the query is finally independent of the storage.
Eric would like to especially thank Lee Feigenbaum for suppling the initial Survey section.
$Log: Overview.html,v $ Revision 1.33 2007/04/20 20:45:25 eric + sotd + virtuoso can do heterogeneous joins (can it? is it really in one join?) Revision 1.32 2007/03/21 19:50:02 eric reworked example Revision 1.31 2007/03/21 19:36:31 eric ... Revision 1.30 2007/03/21 18:54:26 eric + Oracle RDF and SPASQL Revision 1.29 2007/03/21 18:15:19 eric + uc:di Revision 1.28 2007/03/21 18:13:35 eric ~ changed pics ~ some edits + todo += automatable Revision 1.27 2007/03/21 17:47:23 eric + -new PNGs for comparison Revision 1.26 2007/03/21 16:57:05 eric ~ s/terminology/intro to RDF/ Revision 1.25 2007/03/21 16:55:28 eric ~ moved terminology Revision 1.24 2007/03/21 16:55:04 eric + outline Revision 1.23 2007/03/21 14:26:55 eric typos Revision 1.22 2007/03/21 01:30:38 eric dartquery Revision 1.21 2007/03/21 00:39:26 eric cleaning up survey Revision 1.20 2007/03/21 00:25:31 eric approaches to mappings Revision 1.19 2007/03/21 00:01:56 eric + JimM's text ~ brought UNION / OPTIONAL into line with use case data Revision 1.18 2007/03/20 23:06:19 eric ... Revision 1.17 2007/03/20 21:58:02 eric ~ working with LeeF Revision 1.16 2007/03/20 21:56:52 eric mapping and direct mapping section (leef) Revision 1.15 2007/03/20 21:20:07 eric + data for UC Revision 1.14 2007/03/20 20:25:00 eric + Use Case Revision 1.13 2007/03/20 18:06:57 eric edits Revision 1.12 2007/03/18 21:55:25 eric + Oracle 10.2g SPASQL Revision 1.11 2007/03/18 21:43:05 eric + surveyed features + Semantics of Schema Evolution Revision 1.10 2007/03/18 05:56:15 eric + Link Topology Revision 1.9 2007/03/18 05:04:44 eric ~ unify Direct Tuple Mapping and Mapless System Revision 1.8 2007/03/17 22:54:04 eric + bit about SPARQL algebra and expressivity Revision 1.7 2007/03/17 19:35:52 eric ~ fix broken links Revision 1.6 2007/03/17 19:35:04 eric ~ rearranged tail sections ~ Acknowledgements Revision 1.5 2007/03/17 19:26:15 eric + ids ~ Abstract down to two paragraphs. moved rest around. Revision 1.4 2007/03/17 19:08:45 eric + LeeF's Survey + References Revision 1.3 2007/03/15 15:34:25 eric + more mapping + conclusion Revision 1.2 2007/03/15 06:17:07 eric + ... Revision 1.1 2007/03/15 02:01:30 eric started