Submitted by: García Gómez, Sergio (1), de Castro García, Ricardo (1), Sánchez Sáez, Nuria (2)
(1) Telefónica I+D, Spain
(2) IT Deusto, Spain
The core business of Telco operators is managed with OSS (Operations Support Systems) and BSS (Business Support Systems). In an incumbent operator, lots of OSS's BSS's growing in a disparate way (in-house developments, commercial-off-the-self, etc.), using heterogeneous data models and technologies. These systems can be considered legacy systems.
Usually, these legacy systems need to communicate with each other to exchange information. This communication has the following characteristics:
Currently, in order to realize successful communications, there must be confronted several problems related to the quality of data:
There exist a common information model for OSS/BSS interoperability which is hardly used: SID (Shared Information and Data), defined by the Telemanagement Forum. It is an extensible, object oriented model, conceived to help in the definition of OSS interfaces and foster the interoperability among COTS. This model is not generally used by most of the legacy systems.
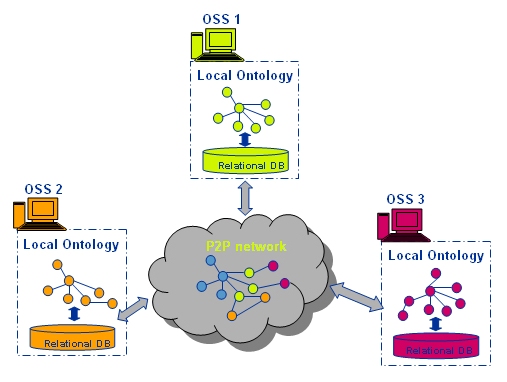
To mitigate all these problems, the Project SPIDERS (Semantic P2p data Interchange with Distributed agEnts among netwoRk management Systems) was envisaged, with the objective of creating an information federated semantic layer and the mechanisms to propagate, share and validate data among network management systems.
The specific objectives are:
This approach will enable autonomic communications solutions for network and services management, since it will allow to discovering information and relationships among the distributed pieces of data, compose new processes, or take decisions based on policies.
To fulfill these requirements, it has been conceived the SPIDERS agent, a piece of software attached to every OSS and its database(s) so that it can carry out the information and manipulation of data, accessing to the database, and offering an interface to the OSS. These agents make up, in fact, a P2P network in which every agent can query any other agent, that is, every OSS can send and receive information throughout the network management ecosystem.
In order to make queries based on the SID ontology, and to extract information from the relational database, the D2R Server software is used, embedded in the agent. D2R Server has demonstrated its suitability in complex scenarios with disparate ontologies and database models. By means of SPIDERS user interface, it is possible to design the SPARQL queries to send to a remote OSS and to map the result sequences to the local database schema.
From short term and long term objectives described, and the SPIDERS approach, there are several hot topics that must be addressed regarding the translation between relational and semantic information. But beyond formal requirements, it must be taken into account that real-life, legacy data models are only partially described by the schema, and an important part of the semantics lie in the mind of designers and developers.
This requires to know which system has data implementing each class in the ontology, and to apply rules and reasoning over the SPARQL queries, so that the data sources can be viewed as a whole.
This reasoning mechanism may help also to relate semantically distant data in the queries. SID ontology is very large, and pieces of data which are relationally close, may be semantically far.
This requirement arises many other itchy issues, as generation/work out of primary and foreign keys, data types compatibilities, fulfilment of constraints, data formats, etc.
This problem also arises either when structured data is stored in only one field (VARCHAR, for instance), and the ontology describes the individual data properties, or just the opposite, when one data property must come from the combination of different individual fields in the database.
Barrasa Rodríguez, J. (2007) Modelo para la Definición Automática de correspondencias Semánticas entre Ontologías y Modelos Relacionales. PhD Thesis. Polytechnic University of Madrid.
Bizer, C. et al. (2007) D2RQ V0.5 - Treating Non-RDF Relational Databases as Virtual RDF Graphs, http://www.wiwiss.fu-berlin.de/suhl/bizer/d2rq/spec/
Dobson S. and Denazis, S (2006). A Survey of Autonomic Communications, In ACM Transactions on Autonomous and Adaptive Systems, December 2006.
Prud'hommeaux, E. and Seaborne, A. (2007). A. SPARQL Query Language for RDF, 14 June 2007, http://www.w3.org/TR/rdf-sparql-query/
Telemanagement Forum (2007). NGOSS Release 7.0 SID Solution Suite (GB922 & GB926) http://www.tmforum.org/page32554.aspx