08 September 2007
A lot of valuable data currently resides in relational databases. They power most Web sites and are therefore also a natural data source for the Semantic Web. Within enterprise settings, integrating various databases is often a motivation for adopting RDF. Thus, making relational databases accessible to RDF-based systems is an important and recurrent problem.
This document describes the D2RQ mapping platform, followed by some issues and requirements that have emerged from experience with D2RQ. Finally, we outline areas for future community work.
Our group has worked on database-to-RDF mapping since 2002. D2R Map was an early exploration of the problem space. It was succeeded by D2RQ [1], which has been used in various RDF-based data integration projects. Its companion, D2R Server [2], is used by a growing number of Web data sources to provide public SPARQL endpoints and Linked Data views on relational data. The project has accumulated about 4600 downloads, at a rate of currently 150 per month. Versions of D2RQ have been integrated with the TopBraid Composer ontology toolset and the Gnowsis Semantic Desktop. D2RQ is licensed under the terms of the GNU General Public License. Other licenses are granted upon request.
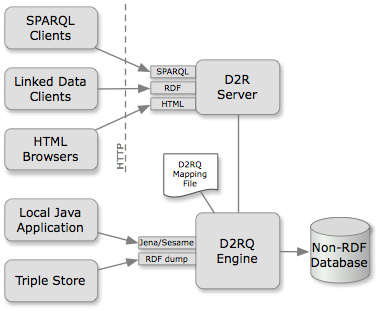
Access methods: A D2RQ-mapped database can be accessed in several ways:
Mapping language. Mappings between a database schema and an RDFS vocabulary or OWL ontology are expressed in a declarative mapping language. The language is designed to offer the expressivity needed to create RDF views for a given target vocabulary from the often messy databases that are found in the wild. The language itself is expressed in RDF, and typically written down as an N3 file.
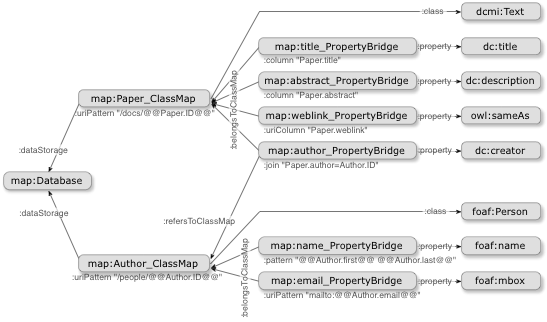
An example of a simple D2RQ mapping, rendered as an RDF graph, is shown below: ClassMaps define a set of resources, and how these resources are identified. PropertyBridges take values from the database and attach them as properties to these resources, or link to other resources.
Basic ClassMaps and PropertyBridges can be further refined. This allows us to express conditional mappings, N:M joins, value translation tables, and to include custom value transformation functions. A full description of the mapping language is found in the D2RQ manual.
Performance and compatibility. We have used D2RQ with acceptable performance on databases that range from hundred thousands to a few million records. Performance depends on the access method: Generation of RDF dumps, access through RDF APIs, and the Linked Data and HTML interfaces scale well with increasing database size. Performance of the SPARQL-to-SQL rewriting required for answering SPARQL queries depends on the query complexity. Queries that only include basic triple patterns show performance similar to an equivalent hand-written SQL query. Queries involving additional SPARQL features, in particular OPTIONAL, FILTER and LIMIT, sometimes display unacceptable performance. This is due to limitations in the implementation of D2RQ's SPARQL-to-SQL rewriting engine. We expect to address most of these issues in the next release of the engine.
D2RQ has been tested with Oracle, MySQL, and PostgreSQL, and works with any SQL-92 compatible database.
Limitations. Some things that D2RQ does not do:
Examples. Some example datasets that are published with D2R Server on the Web are the DBLP bibliography, the Project Gutenberg catalogue, the CIA World Factbook, and a dataset describing our workgroup.
Two major issues have emerged while we support our products and interact with users. Both might be useful input for future work in the area.
As relational databases evolve over time, many deployed databases are in a state where they do not conform to generally accepted database design principles. Our users often want to create “clean” RDF from rather messy databases. This requires an expressive mapping language with support for various value transformation functions, conditional mappings, fixups for various database design anti-patterns, possibly pluggable custom extensions, and the ability to handle highly normalized table structures as well as those below first normal form.
What most people actually expect from RDF-based applications are expressive and fast queries over an integrated view on several, or in the Web case even an unbounded number of data sources. RDF access to relational data, taken by itself, does not do much to fulfil this expectation. What is needed are answers to some well-known, but hard data integration questions:
Federation versus Replication. Expressive queries over multiple data sources can be answered by replicating all data locally, or by relying on query federation, where query fragments are sent to different data sources and the answers are integrated to obtain a result.
There is current work in both directions: DARQ allows federated SPARQL queries over multiple sources. Current versions of the ARQ SPARQL engine allow to explicitly route patterns to specific data sources. On the other hand, the replication approach seams to be quite successful within Web settings, as exemplified by Google. Semantic Web search engines following this approach are SWSE, Swoogle and Zitgist. There is foundational work on combining both approaches: Semantic Web Crawling: a Sitemap Extension enables data providers to publish descriptions about different access models to their data.
Data Source Discovery and Description. The classic approach to data source discovery are registries which collect data source descriptions. Descriptions must allow to find out what data is available at the source, and what would be good queries to ask. There has been some early work on SPARQL endpoint discovery and description. The Linked Data paradigm provides RDF links as an alternative discovery mechanism for the Semantic Web. Links have proven to be a pretty successful discovery mechanism on the classic HTML Web and it is still an open question how link-based discovery will play together with registry-based discovery on the Semantic Web.
Schema Mapping. A question that still lacks clear answers despite considerable efforts is schema mapping. To provide integrated views on various data sources, mechanisms to translate data between different schemata are needed. The mechanisms offered by RDF Schema and OWL are insufficient in practice. The upcoming Rules Interchange Format might provide for such mappings. Other open questions are discovery and retrieval of schema mappings from the Web.
A promising testbed for exploring these questions is emerging within the W3C Linking Open Data community project, where various data providers are publishing large quantities of RDF data on the Web, provide SPARQL endpoints and use RDF links to interlink data from different sources. As of September 2007, the network includes 25 independent data sources which publish altogether more than 2 billion RDF triples.
Within an RDF-based data integration scenario, mapping relational databases to RDF is a local problem and its technical realization matters little form the overall perspective of the integrated system.
With Virtuoso, DartGrid, SPASQL, SquirrelRDF, Relational.OWL and D2RQ, there are various suitable solutions for RDF access to relational data around. We expect that future work in this area will concentrate on performance tuning, comparison of the expressivity of different mapping languages, and gaining practical experience with choosing appropriate approaches for different technical environments.
As a next step towards practical RDF-based data integration, we expect that questions around federation, replication, data source discovery and schema mapping will become more and more important. This is also the area where community agreement and standardization efforts are needed.