BELOW IS THE INITIAL HTML DRAFT POSTED BY THE EDITING GROUP |
![]()

W3C Uncertainty Reasoning for the World Wide Web Incubator Group
W3C Incubator Group Report 05 March 2008
This version:
Latest version:
Editors:
- Kenneth Laskey, MITRE.
- Kathryn Laskey, George Mason University.
- Paulo Costa, George Mason University.
- Mitch Kokar, Northeastern University.
- Trevor Martin, University of Bristol.
- Thomas Lukasiewicz, Oxford University.
Contributors
See Acknowledgments.
Copyright© 2007 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply.
Abstract
This is the report of the W3C Uncertainty Reasoning for the World Wide Web Incubator Group (URW3) as specified in the Deliverables section of its charter.
In this report we present requirements for better defining the challenge of reasoning with and representing uncertain information available through the World Wide Web and related WWW technologies.
Specifically the report:
- identifies and describes situations on the scale of the World Wide Web for which uncertainty reasoning would significantly increase the potential for extracting useful information,
- identifies methodologies that can be applied to these situations and the fundamentals of a standardized representation that could serve as the basis for information exchange necessary for these methodologies to be effectively used,
- includes a set of use cases illustrating conditions under which uncertainty reasoning is important,
- provides an overview of and discuss the applicability to the World Wide Web of numerous uncertainty reasoning techniques and the information that needs to be represented for effective uncertainty reasoning to be possible,
- includes a bibliography of work relevant to the challenge of developing standardized representations for uncertainty and exploiting them in Web-based services and applications.
The report identifies various areas which require further investigation and debate. The intention is ....
Status of this document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of Final Incubator Group Reports is available. See also the W3C technical reports index at http://www.w3.org/TR/.
This document was developed by the W3C Uncertainty Reasoning for the World Wide Web Incubator Group. It represents the consensus view of the group, in particular those listed in the acknowledgements, on requirements for ...
Publication of this document by W3C as part of the W3C Incubator Activity indicates no endorsement of its content by W3C, nor that W3C has, is, or will be allocating any resources to the issues addressed by it. Participation in Incubator Groups and publication of Incubator Group Reports at the W3C site are benefits of W3C Membership.
Incubator Groups have as a goal to produce work that can be implemented on a Royalty Free basis, as defined in the W3C Patent Policy. Participants in this Incubator Group have made no statements about whether they will offer licenses according to the licensing requirements of the W3C Patent Policy for portions of this Incubator Group Report that are subsequently incorporated in a W3C Recommendation.
Table of Contents
1. Introduction
2.1. Scope of the URW3
2.2. Process
4. Most Commonly Used Approaches to Uncertainty for the WWW
4.1. Bayesian Models
4.2. Fuzzy Logic
5. Use Cases
5.1. Discovery
5.2. Wine Sweetness
5.3. Use Cases motivating refinement of Uncertainty Ontology
5.5. Ontology Based Reasoning and Retrieval from Large-Scale Databases
5.7. Recommendation
5.9. Soft Shopping Agent
5.11. Appointment Making
5.16. Buying Speakers
6. Benefits of Standardization
6.2. Aspects of Uncertainty Reasoning for Potential Standardization
6.3. Methodologies that would be Supported by Potential Standardization
1. Introduction
1.1 The Problem of Uncertainty Representation and Reasoning
The World Wide Web community envisions effortless interaction between humans and computers, seamless interoperability and information exchange among web applications, and rapid and accurate identification and invocation of appropriate Web services. As work with semantics and services grows more ambitious, there is increasing appreciation of the need for principled approaches to representing and reasoning under uncertainty. In this Report, the term "uncertainty" is intended to encompass a variety of forms of incomplete knowledge, including incompleteness, inconclusiveness, vagueness, ambiguity, and others. The term "uncertainty reasoning" is meant to denote the full range of methods designed for representing and reasoning with knowledge when Boolean truth values are unknown, unknowable, or inapplicable. Commonly applied approaches to uncertainty reasoning include probability theory, Dempster-Shafer theory, fuzzy logic, and numerous other methodologies.
To illustrate, consider a few web-relevant reasoning challenges that could be addressed by reasoning under uncertainty.
- Information extracted from large information networks such as the World Wide Web is typically incomplete. The ability to exploit partial information is very useful for identifying sources of service or information. For example, that an online service deals with greeting cards may be evidence that it also sells stationery. It is clear that search effectiveness could be improved by appropriate use of technologies for handling uncertainty.
- Much information on the World Wide Web is likely to be uncertain. Examples include weather forecasts or gambling odds. Canonical methods for representing and integrating such information are necessary for communicating it in a seamless fashion.
- Web information is also often incorrect or only partially correct, raising issues related to trust or credibility. Uncertainty representation and reasoning helps to resolve tension amongst information sources having different confidence and trust levels.
- The Semantic Web vision implies that numerous distinct but conceptually overlapping ontologies will co-exist and interoperate. It is likely that in such scenarios ontology mapping will benefit from the ability to represent degrees of membership and/or likelihoods of membership in categories of a target ontology, given information about class membership in the source ontology.
- Dynamic composability of Web Services will require runtime identification of processing and data resources and resolution of policy objectives. Uncertainty reasoning techniques may be necessary to resolve situations in which existing information is not definitive.
Uncertainty is an intrinsic feature of many of the required tasks, and a full realization of the World Wide Web as a source of processable data and services demands formalisms capable of representing and reasoning under uncertainty. Although it is possible to use semantic markup languages such as OWL to represent qualitative and quantitative information about uncertainty, there is no established foundation for doing so. Therefore, each developer must come up with his/her own set of constructs for representing uncertainty. This is a recipe for disaster in an environment so dependent on interoperability among systems and applications.
Apart from the interoperability nightmare caused by proprietary uncertainty representations, there are ancillary issues such as how to balance representational power vs. simplicity of uncertainty representations, which uncertainty representation technique(s) addresses uses such as the examples listed above, how to ensure the consistency of representational formalisms and ontologies, etc. None of these issues can be addressed in a principled way by current Web standards.
1.2 The Incubator Group Activity (XG)
Given the current state of the overall subject of uncertainty representation and reasoning for the WWW, it became clear that the best approach would be to create an Incubator group, which provides an opportunity to share perspectives on the topic with all the advantages already cited in the W3C's Incubator Activity W3C's Incubator Activity. Once the group was launched, both the group's Private Website and Charter were posted with all the details regarding the group's assignments, rules, and deliverables. Among the instructions, URW3 members were reminded that membership conditions include patent disclosure obligations as set out in Section 6 of the W3C Patent Policy and of their goal to produce work that can be implemented on a Royalty Free basis, as defined in the W3C Patent Policy.
2. Intent and Process
2.1 Scope of the URW3
As stated in the URW3's Charter, the objectives of the group were twofold:
- To identify and describe situations on the scale of the World Wide Web for which uncertainty reasoning would significantly increase the potential for extracting useful information; and,
- To identify methodologies that can be applied to these situations and the fundamentals of a standardized representation that could serve as the basis for information exchange necessary for these methodologies to be effectively used.
For the first objective, the URW3-XG has compiled a set of use case descriptions to expand on the examples noted above, and solicited and further developed other examples of the kinds of information management challenges that would benefit (and if available, have already benefited) most from mechanisms for reasoning under uncertainty.
For the second objective, the URW3-XG has investigated, proposed, and implemented methodologies that may be applied to address the use cases developed under the first objective and that show promise as candidate solutions for uncertainty reasoning on the scale of the World Wide Web. The combination of use cases and associated methodologies was examined to determine the most commonly required information and also that information that while not common may be especially important in select situations.
The results of this one-year work pursuing the above objectives were listed below, in a total of 16 use cases, some of them including comprehensive information and details on how uncertainty would
It is our expectation that the URW3-XG would recommend those aspects that are considered most important to be included in a standard representation of vagueness and uncertainty. The information below was written in a way of avoiding any connotation that this group advocates the choice of any one uncertainty methodology over others. Instead, we complied with our directives of seeking to identify the type of information that would need to be saved as part of a general resource description and transmitted to a reasoning engine for useful processing. The recommended set does not include all identified information or address every use case in the initial collection. Instead, the entire use case collection below provides a basis for discussing whether the recommended set is sufficient to advocate further actions along the W3C Recommendation Track, either as a separate Recommendation or as part of other related work.
Finally, our scope did not include recommending a single methodology but to investigate whether standard representations of uncertainty can be identified that will support requirements across a wide spectrum of reasoning approaches.
2.2 Process
To achieve the objectives above-cited the XG group was comprised by 25 participants from all continents but Africa, who were spread through a range of time zones spanning 18 hours. It performed a total of 20 telecons, with an average duration between 90 and 120 minutes, plus a face-to-face meeting held at the 5th ISWC (Busan - Korea). The telecons were supported by the W3C resources (e.g. telecon bridge, IRC, RSSAgent, etc) and its results and action items were all cataloged in online Minutes. Every telecon also had an agenda with items to be discussed, the first always being to approve the last telecon's minutes.
Most of the issues being discussed were posted in the groups website in the form of wiki pages, who were constantly updated as new data were available and conclusions were draw. three months before the group's assignment, a draft of this report was posted in wiki format so everyone was able to participate.
This Report is the major deliverable of the URW3-XG and describes the work done by the XG, identifies the elements of uncertainty that need to be represented to support reasoning under uncertainty for the World Wide Web, and includes a set of use cases illustrating conditions under which uncertainty reasoning is important. Along with the use cases (Section 5), this report also includes the Uncertainty Ontology (Section 3) that was developed during the discussions within our work, an overview of the applicability to the World Wide Web of numerous uncertainty reasoning techniques and the information that needs to be represented for effective uncertainty reasoning to be possible (Section 4), and a discussion on the benefits of standardization of uncertainty representation to the WWW and the SW (Section 6). Finally, it includes a Bibliography of work relevant to the challenge of developing standardized representations for uncertainty and exploiting them in Web-based services and applications.
3. Uncertainty Ontology
To demonstrate some basic functionality of exchanging uncertain information a simple ontology was developed. Another reason for this ontology was to classify the use cases developed by this group with the intent of obtaining a relatively complete coverage of the functionalities related to uncertainty reasoning about information available on the World Wide Web.
It should be clear that this ontology does not pretend to be complete.
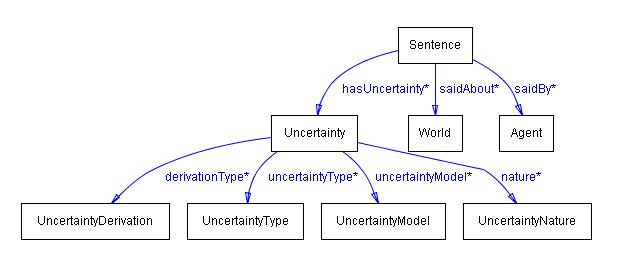
A short description of the ontology is presented below. First, the top level of the ontology is shown. Then the classes in the ontology are described. And finally the relations among the classes are discussed. The boxes in the figures represent classes. The arrows represent relationships (also known as properties). The star ('*') next to a property name indicates that the multiplicity constraints for this property have not been specified (i.e., the property can have zero or more values for any instance from the domain class). The "isa" annotation next to an arrow indicates that the arrow represents the "subClassOf" relationship.
The Uncertainty Ontology can be downloaded as an OWL file.
3.1 Classes of the Uncertainty Ontology
The top level of the Uncertainty is presented below.

3.1.1 Sentence
An expression in some logical language that evaluates to a truth-value (formula, axiom, assertion). It is then assumed that information will be presented in the form of sentences. So the uncertainty will be associated with sentences.
3.1.2 World
This represents the world about which the Sentence is said.
3.1.3 Agent
This is the class repreenting whoever makes the statement. It can be either a human or a computer agent (machine).
3.1.4 Uncertainty
A statement about the uncertainty associated with the sentence.
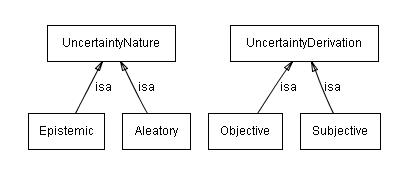
3.1.5 Uncertainty Nature
This captures the information about the nature of the uncertainty, i.e., whether the uncertainty is inherent in the phenomenon expressed by the sentence, or it is the result of lack of knowledge of the agent.
Aleatory - the uncertainty comes from the world; uncertainty is an inherent property of the world.
Epistemic - the uncertainty is due to the fact that the agent's knowledge is limited.

3.1.6 Uncertainty Derivation
It contains information about how the fact about uncertainty was derived.
Objective - derived in a formal way, repeatable derivation process.
Subjective - subjective judgement, possibly a guess.
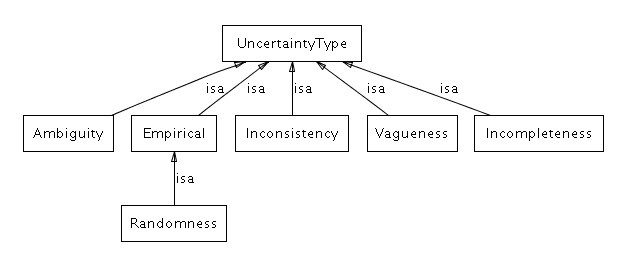
3.1.7 Uncertainty Type
This class represents the formal aspect of uncertainty, i.e., the type of semantic relation between the world that the sentence is about and the representation of the uncertainty.
Ambiguity - the referents of terms in a sentence to the world are not clearly specified and therefore it cannot be determined whether the sentence is satisfied, see also http://en.wikipedia.org/wiki/Ambiguity.
Empirical - a sentence about a world (an event) is either satisfied or not satisfied in each world, but it is not known in which worlds it is satisfied; this can be resolved by obtaining additional information (e.g., an experiment). A special case of this type is Randomness - sentence is an instance of a class for which there is a statistical law governing whether instances are satisfied.
Vagueness - there is not a precise correspondence between terms in the sentence and referents in the world, see also http://en.wikipedia.org/wiki/Vagueness.
Inconsistency - there is no world that would satisfy the statement.
Incompleteness - information about the world is incomplete, some information is missing.

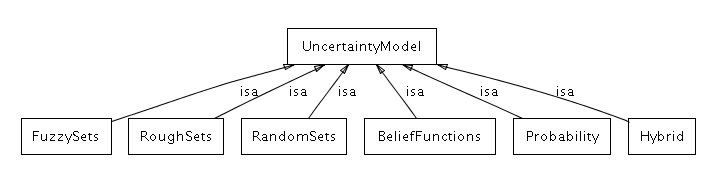
3.1.8 UncertaintyModel
This class contains information on the mathematical theories for the uncertainty types. The specific types of theories include, but are not limited to, the following:
Probability
Fuzzy Sets
Belief Functions
Random Sets
Rough Sets
Combination of Several Models (Hybrid), e.g., Fuzzy Sets and Probability

3.2 Properties of the Uncertainty ontology
hasUncertainty - sentence S has uncertainty U
saidAbout - sentence S is said about world W
saidBy - sentence S was said by agent A
nature - uncertainty U has nature S (either aleatory or epistemic (lack of knowledge))
uncertaintyType - uncertainty U is of type T
uncertaintyModel - uncertainty U is modeled using the mathematical theory M
derivationType - uncertainty U was obtained by derivation of type D
4. Most Commonly Used Approaches to Uncertainty for the WWW
This section should be ready by February 06, 2008. |
Coordinator: Thomas Lukasiewicz. |
Draft Text for Section 4 (copyright permission being sought for public release)
4.1 Bayesian Models
Brief explanation of Bayesian Models applied to WWW, its major applications, advantages, shortcomings, and current state.
4.2 Fuzzy Logic
Brief explanation of Bayesian Models applied to WWW, its major applications, advantages, shortcomings, and current state
5. Use Cases
This section should be ready by February 06, 2008. |
Coordinator: Editing Team |
Explanation of why we listed use cases. Our objectives, what we wanted to prove, etc. Then, for each use case we write a subsection with a brief explanation. Details will be in appendix 1.
Explanation of why we listed use cases. Our objectives, what we wanted to prove, etc. Then, for each use case we write a subsection with a brief explanation. Details will be in appendix 1.
Detailed descriptions of all use cases can be found in Appendix 1.
5.1 Discovery
Original author: Ken Laskey
Service oriented architecture (SOA) assumes a world of distributed resources which are accessible across a network. It is assumed that catalogues will exist for different classes of resources, such as SOA services, and the user will be able to search these catalogs for a desired item. Note, a class of items will be described using a list of relevant properties and items belonging to that class will be described by assigning values to these properties. For discovery to occur, there must be some alignment of or mediation between the list of properties used by those populating the catalogue and those searching it. There must also be some alignment of or mediation between the nonnumeric values assigned to the properties, both in describing items for the catalog and defining the search criteria.
Uncertainty occurring in this use case include the following:
Terminology mismatches may make it difficult for the system to find the class of items the user intends. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Vagueness)
Given the class of items, the user may not unambiguously understand the meaning of the properties by which the class is described. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Vagueness)
Given a set of properties of interest to the user, there is uncertainty in trading off the user’s target property values against those of items in the catalogue. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Empirical)
5.2 Wine Sweetness
Original author: From URSW 2006
Wine domain is a very attracting domain both for experts and non experts. The main reason of its attractiveness is given by:
- the high number of properties that qualify a wine or a set of wines
- the fuzziness of the properties values for characterizing a wine as belonging to a certain category.
The “Wine Sweetness” use case focus on a particular wine property that is the wine sweetness. The goal is to present a particular unknown wine’s sweetness to the user, according to his/her personal and possibly vague sweetness criteria. This is done by considering a knowledge base of reference that could have a finer/coarser classification, or it could use a terminology that is different from the one adopted by the user.
Furthermore, even when the same terminology is used, the interpretation of a vague classification label (like “dry”) may differ between the creator of the knowledge base and the user who queries the knowledge base.
Uncertainty occurring in this use case include the following:
Knowledge bases may have different classification granularity, or different terminologies. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Vagueness; UncertaintyDerivation: Subjective)
Even considering the same terminology, the interpretation of a vague classification label (like “dry”) may differ between the creator of the knowledge base and the user. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Vagueness; UncertaintyDerivation: Subjective)
The classification, in a knowledge base, may be based on perception rather than on actual measurement. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Vagueness; UncertaintyDerivation: Subjective)
The information in various knowledge bases may be conflicting. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Inconsistency; UncertaintyDerivation: Objective)
5.3 Use Cases motivating refinement of Uncertainty Ontology
Original author: Peter Vojtas
We follow Charter http://www.w3.org/2005/Incubator/urw3/charter. The objectives of the URW3-XG are twofold:
- To identify and describe situations on the scale of the World Wide Web for which uncertainty reasoning would significantly increase the potential for extracting useful information;
- To identify methodologies that can be applied to these situations and the fundamentals of a standardized representation that could serve as the basis for information exchange necessary for these methodologies to be effectively used.
To motivate this, the charter mentions several use cases. In this use case we briefly link these „charter use cases“ to several more detailed use cases
The main method to achieve goals is to enrich web documents with Uncertainty Annotations [UncAnn], hence increase the potential for extracting useful information.
In automated Web data processing we often face situations when Boolean truth values are unknown, unknowable, or inapplicable. The nightmare caused by proprietary uncertainty representations makes impossible to use these for further processing. We briefly mention several use cases originally mentioned in the URW3 charter. Moreover we include here a a finer grained version of Uncertainty Ontology to show a possible evolution of upper level UncertaintyOntology and emphasize uncertainty issues connected to machine processing (lot of situations is perfectly certain when considering human consumption of web resources). We focus especially on finer classification of Machine Agents (UncAnn Agent:MachineAgent) and uncertainty caused by lack of knowledge of a machine agent (UncAnn UncertaintyNature:Epistemic:MachineEpistemic).
5.4 Belief Fusion and Opinion Pooling
Original author: Matthias Nickles
A typical situation for web users is the need to aggregate information from multiple sources on the web. Issues related to uncertainty arise in such a situation in case the set of information acquired from multiple sources about the same fact is inconsistent (UncertaintyType: Inconsistency), or - more generally - in case that multiple information sources attribute different grades of belief (for example uncertain or mutually inconsistent beliefs) to the same statement (UncertaintyNature: Epistemic). If the user is not able to decide in favor of a single alternative (due to insufficient trust in the respective information sources, which can be seen as the default situation on the web), the aggregated statement resulting from the fusion of multiple statements is typically uncertain (UncertaintyNature: Epistemic. The types of uncertainty in this situation can vary. E.g., we could have UncertaintyType: Empirical).
A similar situation can be observed when a single information artifact on the web (e.g., a knowledge base, an ontology, a product rating, meta data, or even an ordinary web page) shall be created from multiple possibly contradictory information sources (e.g., expert opinions, existing ontologies, product recommendations, meta data, web pages...). The result needs to reflect and weight multiple input information appropriately, which typically yields uncertainty in case of heterogeneous input information.
There are several approaches to belief fusion. Examples for belief aggregation operators which can yield uncertain results are logarithmic and linear pools (LogOP, LinOP), and Bayesian Network Aggregation. One possible criterion for a successful fusion is the minimization of the divergence of the resulting probability distribution from the input probability distributions.
5.5 Ontology Based Reasoning and Retrieval from Large-Scale Databases
Original author: Giorgos Stoilos
In our use case scenario we will consider a production company, which has a knowledge base that consists of videos and images about persons (which usually are actors or models), TV spots, advertisements, etc. This company wants to publish its content on the Web so as advertisement or other production companies can use this knowledge base to look for either video footage like films, TV spots, etc or of persons to be employed for advertisements (casting). Each entry in the knowledge base contains a photo or a video, and some specific information like body and face characteristics, age or profession-like characteristic, in the case of persons, or video annotations in the case of spots or sceneries. The casting company has created a user interface for inserting the information of persons as instances of a predefined ontology or for performing semantic annotation of its multimedia content. It also provides a query engine to perform ontology-based search for its content through the web. A user can query the knowledge base providing information like the name, the height, the type of the hair (e.g. good quality, perfect, punk), the body (e.g. slim, athletic, plum), age range (e.g. 30s, 50s, MiddleAged), and more, in the case of persons, or information like the place the video spot is taking place (indoors vs. outdoors), the time of day (morning, afternoon, night), the landscape it depicts (mountain, sea), a sky being cloudy or not, a sea being wavy or not, and many more.
The knowledge engineer of the application has identified that applying a classical (Boolean) knowledge based system in the above scenario is very problematic due to the nature of the knowledge and information. For example, an attempt to assign a Boolean meaning to concepts like "30s", "MiddleAged", "Teen", "Kid", "Slim", "Tall", ... would lead to intuitive paradoxes. On the other hand, it is also merely impossible to define other more expressive concepts, like the concept "StudentLooks" in terms of the already problematic concepts "Teen" and "Kid". Similarly, a sky being cloudy or wavy or time being morning or afternoon is also a matter of degree.
His solution to the problem is to use fuzzy ontologies where the membership of an individual (person) or image object to a Concept is annotated with a degree of membership. So one is able to classify "model1" as Tall, Thin, MiddleAged, to degrees 0.6, 0.9, 0.7, respectively, depending on the model's actual height, weight and age. Then, one is able to infer that "model1" is StudentLooking or AccademicLooking to specific degrees according to the definition of the concepts in the ontology and the interpretation of them according to the theory of fuzzy ontologies. Interestingly, the developed system also provides a easy and natural way to provide end-users with rankings in the query results which is not easily supported by Booelan models, or even more to allow end-users specify preferences and weights over the atoms (ingredients) of their queries, thus allowing for far more expressivity.
5.6 SOA Execution Context
Original author: Ken Laskey
As defined in the OASIS Reference Model for Service Oriented Architecture (SOA-RM), the execution context of a service interaction is the set of infrastructure elements, process entities, policy assertions and agreements that are identified as part of an instantiated service interaction, and thus forms a path between those with needs and those with capabilities.
As discussed in SOA-RM, the service description (and a corresponding description associated with the service consumer and its needs) contains information that can include preferred protocols, semantics, policies and other conditions and assumptions that describe how a service can and may be used. The participants (providers, consumers, and any third parties) must agree and acknowledge a consistent set of agreements in order to have a successful service interaction, i.e. realizing the described real world effects. The execution context is the collection of this consistent set of agreements.
Uncertainty occurring in this use case include the following:
Service consumer may have insufficient information about provider's capabilities and associated requirements to ascertain whether service provider can meet needs at acceptable cost. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: could be Ambiguity or Vagueness)
Service provider may have insufficient information about consumer's need to know whether the functionality it provides can meet that need. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: could be Ambiguity or Vagueness)
5.7 Recommendation
Original author: From URSW 2006
Recommender systems form a rapidly growing category of web-based system. A recommender system takes input from a user in the form of a query or an exemplar of the kind of item the user seeks, and returns recommendations for information or products. For example, the user might input a list of keywords and the system would return a list of recommended books, articles and/or web sites. The user might input one or a few movies, and the system might return a list of suggested movies for the user to view. Many e-commerce sites employ recommending systems to suggest products that customers might want to purchase. Another well-known example for this use case is the search for web pages using a search engine.
This use case discusses uncertainties that typically occur in the context of recommender systems or recommendations generated using other technical means (e.g., agents). The main scenario is as follows: A single or multiple recommendation searcher(s) express(es) her/their preferences in a machine readable format. A recommender system then combines a set of recommendations (obtained by a number of agents or other recommender systems) into an aggregated recommendation and ranking. For example, a user might input a movie, and the system would form its recommendation by aggregating recommendations provided by consumers who have seen the movie.
In this scenario uncertainty can occur for several reasons:
- the set of recommendations obtained from multiple agents might be inconsistent.
- a recommendation possibly matches the preference(s) of the recommendation searcher only imperfectly.
- a recommender system might have obtained its recommendation using statistical means (e.g., using collaborative filtering).
- an agent or a recommender system might have a low confidence in its recommendation, i.e., it is uncertain whether its recommendation actually matches the preference.
- the preferences provided by a recommendation searcher can be uncertain or inconsistent, e.g., because a user might not be able to express his preferences in sufficient detailedness.
- sometimes a single recommendation shall reflect multiple preferences provided by multiple recommendation searchers (e.g., if a group of users seeks for a single recommendation which reflects the preferences of all group members as good as possible). Uncertainty arises e.g. in case these input preferences are inconsistent.
In order to enable formal inference to be carried out on the set of recommendations, the semantics of recommendation needs to be cleanly defined and an appropriate formal framework for the representation of recommendations is required. Also, an ability is needed to express preferences, scales and rankings in a formal way.
5.8 Extraction / Annotation
Original author: Peter Vojtas
The motivating situation is a user (or a web service) that wants a web scale overview of available informations – e.g. overview over all car selling shops or online shops selling notebooks. The advantage would be a possibility of comparison of different market offers. Another application is competitor tracking system.
Main problem is the size of data and the fact that these data are mainly designed for human consumption.
Solution are extraction and annotation tools. There are many annotation tools linked on http://annotation.semanticweb.org/annotationtool_view, mainly using a proprietary uncertainty representations (or built in uncertainty handling). Here uncertainty annotation of results would be especially helpful.
Assume that a user user is looking for notebooks and we would like to provide a machine support for his/her search. A typical statement which is a subject of uncertainty assignment in this use case is: (UncAnn Sentence) An html coded web page with URL contains informations, which according to an ontology o1 (UncAnn World:DomainOntology) about notebooks can be expressed by a RDF triple (ntb1, O1:has_priceProperty, 20000). The agent producing this statement is (UncAnn Agent:MachineAgent) especially an induction agent (UncAnn Agent:MachineAgent:InductiveAgent). For extensions of concepts see a finer grained version of Uncertainty Ontology.
Uncertainty nature of this statement is (UncAnn UncertaintyNature:Epistemic:MachineEpistemic), uncertainty type is usualy (UncAnn UncertaintyType:Empirical:Randomness). Instances used for training an extraction tool (UncAnn World:DomainOntology:Instances) are web pages, the uncertainty model is usually complicated (mixture of html structure, regular expressions, annotation ontology and similarity measures) and combination of several models, typically (UncAnn UncertaintyModel:CombinationOfSeveralModels:ProbabilityAndFuzzySetsCombinationModels) . Depending on this the evidence for this uncertainty statement (UncAnn World:DomainOntology:Instances:Evidence) are precision and recall on this training set.
5.9 Soft Shopping Agent
Original author: Umberto Straccia
Suppose we have a car selling web site offering cars and we would like to buy a car. Descriptions of the cars are stored in databases and we have some ontology encoding information about the domain. Now, suppose that preferably we would like to pay around 11000 euro and the car should have fewer than 15000 km on the odometer. Also, if there are leather seats then I would like to have air conditioning, the color is preferably blue, and the car is is not old.
Of course, most of our constraints, e.g. on price and kilometers, aren't crisp as we may still accept e.g.~a car's cost of 11200 euro and with an odometer reading of 16000km. Hence, these constraints are rather vague (fuzzy) (we may model this by means of so-called fuzzy memebr functions). We may also give some preference weight to my requirements.
On the other hand, the seller may offer a discount on the car's catalogue price, but the bigger the discout the less satisfied he is. For instance, related to the e.g a sold Mazda3, the seller may consider optimal to sell above 15000euro, but can go down to $13500euro to a lesser degree of satisfaction.
For each car, there will be an optimal price it can be sold, which maximises the product of the buyer's degree of satisfaction and the seller's degree of satisfaction. This is the so-called NASH equilibrium of the matching. Each car gets an optimal degree of buyer/seller degree of satisfaction.
From the buyer perspective, he asks for the TOP-k cars and their optimal price, ranked the optimal degree of sadisfaction.
From the seller perspective, he may ask for the TOP-k buyer's for a given car and their optimal price, ranked the optimal degree of sadisfaction.
5.10 A chain from the Web to the user
Original author: Peter Vojtas
To get information from the web to the user we have to use a chain of tools – typically web crawling, web data extraction, middleware transformation, user querying and delivering answer. There are several use cases dealing with particular problems of uncertainty along such a chain, e.g. Extraction-Annotation and User_prefference_modelling_for_top-k_answers. Usually there is a middleware connecting those.
The problem is, how does uncertainty evolve along such a chain.
Our understanding of this is to view the whole chain of models, methods and tools from web to the user and especially handling uncertainty combination along this (UncAnn UncertaintyModel:CombinationOfSeveralModels).
5.11 Appointment Making
Original author: Kathryn Laskey
This use case was inspired by the 2001 Scientific American article, The Semantic Web, by Berners-Lee, Hendler and Lassila. The article describes a scenario in which Lucy and her brother Pete must schedule their mother for a sequence of visits to a physical therapist. They agree to share the chauffeuring, and Lucy tasks her Semantic Web agent to set up the appointments:
Lucy instructed her Semantic Web agent through her handheld Web browser. The agent promptly retrieved information about Mom's prescribed treatment from the doctor's agent, looked up several lists of providers, and checked for the ones in-plan for Mom's insurance within a 20-mile radius of her home and with a rating of excellent or very good on trusted rating services. It then began trying to find a match between available appointment times (supplied by the agents of individual providers through their Web sites) and Pete's and Lucy's busy schedules.
It is clear that many uncertainties arise in handling this classic use case for the Semantic Web use case. For example, both the provider's and the consumer's schedules may be uncertain, and in traffic-clogged metropolitan areas, the amount of time it takes to get from the consumer's location to the place where the service is rendered may be highly uncertain.
5.12 Other Use Cases from URSW Workshop 2006 (should we keep this?)
One or two paragraphs explaining the Use Case.
Original author: From the URSW 2006
5.13 User Preference Modeling for top-k Answers
Original author: Peter Vojtas
This is in a sense a generalization of some aspects of Discovery use case. Given a populated catalogue by some extraction tool (see use case about extraction) of items and a user’s criteria and/or multicriterial utility function for item potentially listed in the catalogue retrieve best, top-k matches.
Usually, the main problem is to learn user preferences. This can be done either by implicit information collection (system tracks user behavior, click streams, …) or by explicit information collection (system poses questions, user answers). Sometimes a recommender system finds similar users (UncAnn UncertaintyModel:SimilarityModels). Another problem is effective retrieval of search results ordered by these preferences (usualy top-k answers suffice).
As result of any data mining procedure, results of such user preference mining will be uncertain.
Typical sentence which is a subject of uncertainty assignment is: (UncAnn Sentence) User1 prefers most item1 (list of of top-k most preferred items for User1 consists of item1, ..., itemk).
There are models using partially ordered sets to represent preferences. Different ad hoc ranking approaches are used. Possible model is UncAnn UncertaintyModel:FuzzySets or UncertaintyModel:PreferenceModels.
5.14 Ontology Mediated Multimedia Information Retrieval
Original author: Umberto Straccia
Suppose we want to device ontology mediated multimedia information retrieval system, which combines logic-based retrieval with multimedia feature-based similarity retrieval. An ontology layer may be used to define (in terms of semantic web like language) the relevant abstract concepts and relations of the application domain, while a content-based multimedia retrieval system is used for feature-based retrieval. We ask to make queries such as
- Find top-k ranked video passages made by Umberto whose title is about 'tour' - Find top-k ranked images similar to a given one, which is about an animal
5.15 Healthcare and Life Sciences
Original author: Vipul Kashyap.
The entire Healthcare and Life Sciences spectrum involves the creation and manipulation of uncertain information and knowledge. A collection of use cases are presented characterized by a simple taxonomy.
5.15.1 Hypothesis Uncertainty
Some examples of Uncertainty in the context of Hypothesis Generation and Validation are enumerated below:
Mutations in the alpha synuclein could cause Parkinsons Disease
- Hypotheses of relationships based on statistical analysis of microarray data associated with p-values, confidence intervals, etc.
- Gene Ontology Evidence codes in support of a particular GO annotation of a gene
- Evidence classes in the OBO Evidence Ontology
5.15.2 Interpretation/Classification Uncertainty
Some examples of Uncertainty in the context of interpreting and classifying different types of information are enumerated below:
- The patient has elevated cholesterol based on his reading of X mg/dl
- Given the same set of symptoms, Doctor X and Y come up with diagnosis of mild and severe disease respectively
- True/False Positive/Negative rates of patient classifications and diagnoses.
- Use of measures such as Precision, Recall, PPV, NPV, etc.
5.15.3 Prediction-oriented Uncertainty
Some examples of Uncertainty in the context of predicting some phenomena based on currently available information are enumerated below:
A person with the BRCA1 gene has a disposition towards Breast Cancer with 70% probability in the future
5.15.4 Belief oriented uncertainty
Some examples of Uncertainty in the context of believing (or not believing) certain hypotheses and theories are enumerated below.
- It is believed to the best of our knowledge that a particular gene is not implicated in a particular disease
- Associated non-monotonicity with the above, i.e., if more knowledge is available, the statement could be proven false.
5.15.5 Data Source based Uncertainty
Some examples of Uncertainty in the context of trusting various data sources are enumerated below.
- Samples from the same patient are analyzed by different labs. Lab 1 results show an 80% probability of Disease 1, whereas Lab2 shows a 90% probability for the same.
- If the Cleveland Clinic says that Avandia is bad for Diabetes, the statement has a higher value of certainty as opposed to an individual Dr. X
5.15.6 Data Uncertainty
Some examples that illustrate the inherent uncertainty of the data generated in the Healthcare and Life Sciences are enumerated below.
- Approximate location of a clinical feature, e.g, tumor in spatial location in the human body as captured in radiological image or any other digital artifact
- Data inconsistency and incompletenes encountered in Healthcare and Drug Databases
- Data uncertainty introduced due to sampling errors, sampling rates, etc.)
- Data uncertainty introduced due to the limitations (least count error?) of the device measuring patient characteristics (e.g., temperature)
- Data uncertainty introduced due to limitation of instruments used to collect experimental data, e.g., micro-arrays
5.16 Buying Speakers
Original authors: Mitch Kokar, Kathryn Laskey and Peter Vojtas
The main point of this use case is to show that in some cases one needs to combine different kinds of uncertainty. In this particular use case two types of uncertainty are considered: Randomness and Vagueness.
The scenario includes a customer who is interested in purchasing a set of speakers, but the question is (1) whether to go to a store today or wait until tomorrow to buy speakers, (2) which speakers to buy and (3) at which store. Customer is interested in two speaker features: wattage and price. Customer has a valuation formula that combines the likelihood of availability of speakers on a particular day in a particular store, as well as the two features. The features of wattage and price are fuzzy. Optionally, Customer gets the formulas from CustomerService, an ontology based Web service that collects information about products, stores, statistics, evaluations.
It is assumed that there is known probability distribution on the availability of particular speaker type in particular stores on a particular day in the future. Also it is assumed that both the customer's agent and the consumer service agent share the same Uncertainty Ontology. The customer's agent issues a query (a sentence) using terms from the Uncertainty Ontology: Sentence. It is a complex sentence consisting of three basic sentences. One related to the availability, one to the wattage and one to the price of speakers. Each of these sub-sentences will have uncertainty Uncertainty associated with it. The uncertainty type related to the availability of particular speaker type in the stores is of type UncertaintyType: Empirical. The uncertainty nature is UncertaintyNature: Aleatory. The uncertainty model is UncertaintyModel: Probability. The customer has (or obtains from CustomerService) definitions of features of wattage and price in terms of fuzzy membership functions. For wattage, Customer has three such functions: weak, medium and strong. These are of "trapezoid shaped" membership functions. Similarly, for price Customer has three such membership functions: cheap, reasonable and expensive.
In the end, the customer gets necessary information about the availability and types of speakers from stores. This information is sufficient for the customer to compute the required metric and to make the decision on which speakers to buy, where and when.
6. Benefits of Standardization
6.1 Where use cases imply standardization benefits
We can consider the use cases above as processes in which a consumer of information makes a request to a provider (or multiple providers) of web-accessible information or services, and receives a response (or multiple responses).
The use cases illustrate several examples where uncertainty arises during this interaction and there are a number of topics that are common across use cases. Specifically, we can sub-divide into three areas - the producer’s specification of what can be provided, the consumer’s request (description of what is wanted) and the result. Taking these in turn:
6.1.1 Uncertainty in provider’s specification
This relates primarily to the provider’s descriptors (i.e. properties used to describe the topic / item / service provided) and the values assigned to these descriptors. Such values may be based on perception rather than measurement (for example, a picture of someone with an ‘athletic physique”), or on overlapping categories where an item can belong to multiple categories at different membership levels (e.g. a film could belong strongly to the genre ‘comedy’ and weakly to the genre ‘adventure’).
Additional uncertainty may arise where the provider makes assertions related to the use of the information or service provided. Standardization could assist (for example) in determining intersection with similar assertions by the consumer, e.g. privacy policies.
6.1.2 Uncertainty in consumer’s request
The provider has to deal with cases of incomplete and/or inconsistent information in the request from a consumer. Further uncertainty may arise where a request is based partly on submitted data and partly on background information, such as known consumer preferences or history.
As above, further uncertainty may arise where the consumer makes assertions related to the use of the information provided in the request.
6.1.3 Result returned to consumer
The consumer may have to deal with uncertainty in the result from a single provider or in results from multiple providers. In the first case, the most obvious possibility is that the result is incomplete or inconsistent in some way. Inconsistency is not a binary state - in many cases, a small inconsistency in a result may not affect the usefulness of the answer. It is however an area in which standardization of uncertainty could aid uniform handling of results. Similarly, incompleteness in a result may not affect its usefulness.
Further uncertainty may arise from use of the provider’s use of consumer preferences, the process of finding responses to a partially matched request, etc. Inconsistency is possible from a single provider but is more likely where results are aggregated from multiple providers. In cases where a consumer is dealing with more than one provider, these problems are multiplied because different providers may have different interpretations of descriptors and values, or even different sets of descriptors, as well as different approaches to processing requests, variation in use of consumer preferences, different historical data on a particular consumer, etc). Clearly standardization would clarify the uncertainty in this process to the benefit of both producers and consumers.
Underlying these aspects are the fundamental questions that motivate standardization - how do the different parties assess uncertainty, and can these assessments be meaningfully combined, particularly when they are derived from different methodologies. The work of this XG is not to develop or even identify (begin Peter here we claim that we are not going to identify... end Peter) many of the mechanisms that these use cases imply are needed to process uncertainty. The current effort intends to identify (begin Peter here we claim that we are going to identify...this sounds to me a little bit strange end Peter) the types of information that are likely to be valuable for such processing to occur and to provide guidance to those who would develop the syntax to convey this information in a machine-processible way.
6.2 Goals of Standardization
The challenges related to uncertainty reasoning on the scale of the World Wide Web have been introduced in Section 1, and the goal of standardization would be to enable the understanding and processing needed for consistent use of available information when uncertainty is present. Many applications which generate data for the web already handle uncertainty in some form. For example, information retrieval systems may rank pages in terms of “relevance” on a scale of 0-100, weather forecasts are frequently qualified (e.g. 30% chance of showers), product finders return lists which are ordered according to the quality of match with a user’s requirements. These applications implicitly or explicitly define and handle uncertainty, and communicate it to the user. Standardization is not necessary for these individual applications which handle uncertainty internally in a (hopefully) consistent manner.
However, as soon as an application incorporates externally produced uncertain data, there is a need to standardize the representation of the characterization of the uncertainty. The notion of interoperability - being able to access and process data from any web source - is fundamental to a web of distributed information, and cannot be achieved unless all sources conform to common standards. As argued in the introduction, much of the available data on the web is subject to uncertainty - so that without standardization of uncertainty, applications using this information are either (i) inaccurate or (ii) have to make assumptions that enable them to ignore uncertainty. Neither of these options is likely to lead to practical, accurate reasoning about real-world data, except in a limited set of cases.
The aim of uncertainty standardization for the World Wide Web should be
- to enable mark-up of a web-based information source so that the nature of any associated uncertainty is clear - whether the uncertainty is a product of the inference process, is inherent in the stored facts or is due to limited knowledge of the information provider
- to permit the definition of extensions to the uncertainty framework
The availability of an uncertainty mark-up language for annotating web data makes it possible to (semi)automate and manage the trustworthiness of the information on the Web. Indeed, there are many cases in which the same data can have different reliability depending on: the source from which they are generated, the context in which they are produced, the time in which they are made available. Currently, such information generally cannot be managed simply because there are no way for knowing the associated uncertainty. With the availability of uncertainty murk-up annotation, such information can be properly treated for the first time.
Is there a reason to keep sections 6.3 and 6.4 separate or should these be combined in a single section? |
6.3 Aspects of Uncertainty Reasoning for Potential Standardization
Many approaches to uncertainty use a numerical scale (e.g. from 0 to 1 or 0 to 100) but interpret and process these values in different ways. It is not necessary for every implemented system to interpret and process every form of uncertainty. The aim should be for common understanding and interpretation of the core forms, and the ability to extend the framework as necessary. For example, if data is published with probabilities attached, any other application would be able to perform specified operations on those probabilities and know that the results were meaningful.
In summary, the following aspects must be considered
- semantics - any standarization proposal should leverage the semantics related to the model-theoretic semantics of OWL.
- extensibility - the standard must support uncertainty models listed above (section 3) but should not restrict the expression of uncertainty to these models.
- expressibility / ease of use
As such, we conclude the following as guidelines when considering possible standards development efforts related to uncertainty:
- We see no single approach to uncertainty reasoning that will solve all problems, so a standard must support current and, to the extent we currently understand, future uncertainty reasoning methodologies.
- A standard must provide a means to clearly identify the context under which provided uncertainty information was generated and, possibly, the intended use of the information.
- A standard must provide the means to convey uncertainty information needed to support any methodology.
7. Recommendations
See http://www.w3.org/2005/Incubator/urw3/wiki/Recommendations for wiki page where Recommendations are being developed.
7.1 Overall Conclusions of XG Work
Answer the main questions posed to the group.
7.2 Specific Recommendations for Standardization
What do we recommend as a follow up of our work.
8. Acknowledgements
The editors acknowledge significant contributions from the following persons (in alphabetical order):
- Fernando Bobillo, University of Granada.
- Anne Cregan,
- Claudia d'Amato, University of Bari.
- Nicola Fanizzi, University of Bari.
- Francis Fung, IET, Inc.
Vipul Kashyap, Partners HealthCare System, Inc.
- Sebastian Kruk, DERI Galway.
- Thomas Lukasiewicz, Oxford University.
Eric Monk, McDonald Bradley, Inc.
- Matthias Nickles, University of Bath.
- Jeff Pan, University of Aberdeen.
- Michael Pool, Convera, Inc.
- Pavel Smrz, Brno University of Technology.
- Giorgos Stamou, Image, Video and Multimedia Systems Lab (IVML-NTUA).
- Giorgos Stoilos, Image, Video and Multimedia Systems Lab (IVML-NTUA).
- Umberto Straccia, CNR - Consiglio Nazionale delle Ricerche.
- Edward Thomas, University of Aberdeen, Computing Science.
- Miroslav Vacura,
- Peter Vojtas, Charles University.
Bibliography
The following are some links to publications related to representing and reasoning under uncertainty in the World Wide Web. This list is illustrative of the techniques investigated by the XG, and is not intended to be an exhaustive list.
Costa, Paulo C.G. (2005) Bayesian Semantics for the Semantic Web. Doctoral Dissertation. Department of Systems Engineering and Operations Research, George Mason University: Fairfax, VA, USA. p. 312.
Damasio, Carlos; Pan, Jeff; Stoilos, Giorgos; Straccia, Umberto (2006) An Approach to Representing Uncertainty Rules in RuleML, Proceeedings of the 2nd International Conference on Rules and Rule Markup Languages for the Semantic Web (RuleML-06).
Ding, Zhongli; and Peng, Yun (2004) A Probabilistic Extension to Ontology Language OWL, in 37th Annual Hawaii International Conference on System Sciences (HICSS'04). 2004. Big Island, Hawaii.
Fukushige, Yoshio (2004) Representing Probabilistic Knowledge in the Semantic Web. Presented at the W3C workshop on Semantic Web for Life Sciences. Cambridge, MA, USA.
Gu, Tao; Pung, Hung K.; and Zhang, Da Q. (2004) A Bayesian Approach for Dealing with Uncertainty Contexts, in Second International Conference on Pervasive Computing. 2004. Vienna, Austria: Austrian Computer Society.
Lukasiewicz, Thomas (2006) Fuzzy Description Logic Programs under the Answer Set Semantics for the Semantic Web. Proceedings of the 2nd International Conference on Rules and Rule Markup Languages for the Semantic Web (RuleML-06). Extended version: Fundamenta Informaticae, 82, 1-22, 2008.
Lukasiewicz, Thomas (2007) Probabilistic Description Logic Programs. International Journal of Approximate Reasoning, 45(2), 288-307.
Mitra, Prasenjit; Noy, Natasha; and Jaiswal,Anuj R. (2005) Ontology Mapping Discovery with Uncertainty. Presented at the Fourth International Semantic Web Conference (ISWC 2004). November, 7th 2005, Galway, Ireland.
Pan, Jeff; Stoilos, Giorgos; Stamou, Giorgos; Tzouvaras, Vassilis; Horrocks, Ian (2006) f-SWRL: A Fuzzy Extension of SWRL Data Semantics, special issue on Emergent Semantics, Volume 4090/2006: 28-46.
Pool, Michael; and Aikin, Jeffrey (2004) KEEPER and Protege: An Elicitation Environment for Bayesian Inference Tools, in Workshop on Protege and Reasoning held at the Seventh International Protege Conference. 2004: Bethesda, MD, USA.
Sanchez, Ellie (2006) Fuzzy Logic and the Semantic Web. 1st Edition, April 3, 2006. Oxford, UK: Elsevier Science.
- Straccia, U. (2005) Towards a fuzzy description logic for the semantic web. In Proceedings of the Second European Semantic Web Conference, ESWC 2005.
- Stoilos, G., Stamou, G., Tzouvaras, V., Pan, J.Z., Horrocks, I. (2005) Fuzzy OWL: Uncertainty and the Semantic Web. In: Proceedings of the International Workshop on OWL: Experience and Directions (OWL-ED2005)
Appendix 1: Use Cases
A.1. Use case 1: Discovery
A.1.1. Purpose and Goals
Given a populated catalogue of items and a user’s criteria for a particular item potentially listed in the catalogue, identify the best match.
A.1.2 Assumptions and Preconditions
- The catalogue has been populated using a property set and property values that have a machine processable representation of the vocabulary used
- A similar machine processable representation exists for the vocabulary used to state the search criteria.
A.1.3 Required Resources
- Catalog populated by independent entities whose native descriptions may not directly align with the catalog property and value vocabularies. Catalog entries may be collected from other catalogs. Catalog may also contain entries for multiple items, each with its own property vocabulary.
- Description of catalog property and value vocabularies.
- Description of user property and value vocabularies.
A.1.4 Successful End
The user finds an item sufficiently close to their search criteria and is not hampered by vocabulary differences with those who populated the catalogue.
A.1.5 Failed End
The user does not find an item sufficiently close to their search criteria but has an explanation of how the criteria was not met, e.g. there were no screws of the length needed.
A.1.6 Main Scenario
- User specifies item of interest, e.g. looking for a MP3 player.
- System identifies item class and returns form with list of properties used to describe item.
(If system does not recognize exact class requested, uncertainty in whether system identifies most appropriate class. UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Vagueness)
- User provides target search values for properties of interest (e.g., hard drive size, impact resistance, price). System may also support indicating relative importance of search properties chosen.
(Uncertainty in whether user understands semantics of properties, whether catalog entry provider entered values consistent with property semantics intended by system, assumed by user. UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Vagueness)
- System returns ranked list of item instances, e.g. different models of MP3 players from different producers.
(Uncertainty in whether user understands semantics of target values, e.g. "high impact resistance" vs. "5g impact". UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Empricial)
A.1.7 Additional Background Information or References
Service oriented architecture (SOA) assumes a world of distributed resources which are accessible across a network. It is assumed that catalogues will exist for different classes of resources, such as SOA services, and the user will be able to search these catalogs for a desired item. Note, a class of items will be described using a list of relevant properties and items belonging to that class will be described by assigning values to these properties. For discovery to occur, there must be some alignment of or mediation between the list of properties used by those populating the catalogue and those searching it. There must also be some alignment of or mediation between the nonnumeric values assigned to the properties, both in describing items for the catalog and defining the search criteria.
A.1.8 General Issues and Relevance to Uncertainty
Terminology mismatches (UncertaintyNature: Epistemic; UncertaintyType: Vagueness): User wants a specific item, but his terminology may make it difficult for the system to find the class of items the user intends.
Example:
- Storage drawer on a cooking stove is missing a part that allows the drawer to easily roll in and out, but it is not clear what that part is called.
- Limitations of deterministic representation:
- No obvious, well-defined, commonly agreed upon name for part.
- Possible Approach(es):
- Fuzzy set
Given the class of items, the user may not unambiguously understand the meaning of the properties by which the class is described. Ambiguity on properties of items (UncertaintyNature: Epistemic; UncertaintyType: Vagueness)
Example:
- The missing drawer part appears to have a screw as part of it, but it is not clear whether the screw size is part of the part description. If size is one of the descriptive properties, it is unknown whether the screw size is in English or metric units.
- Limitations of deterministic representation:
- Description is usually related to context in identifying what is important as a descriptive property.
- Possible Approach(es):
- Probability to decide whether property is appropriate for context, what units manufacturer would use.
Given a set of properties of interest to the user, there is uncertainty in trading off the user’s target property values against those of items in the catalogue. Value Assessment (UncertaintyNature: Epistemic; UncertaintyType: Empirical)
Example:
User is a 42 years old male, graphical designer, who wants a notebook with properties hasDisplaySize="15", hasWeight="lessThan5Pounds", hasBluetooth="true", hasBatteryAutonogy="Between2and3Hours", and hasColor="Black". Catalog doesn't have an item that fulfills all five, but has one notebook that meets 4 and two that meet 3 of the user requirements. Instead of presenting a "no item found", the system needs to return a prioritized list. Not necessarily the item with 4 positive requirements will be the best option for the customer.
- Limitations of deterministic representation:
- A typical catalog system based on deterministic representation and reasoning might use rules to sort out items that did not completely meet a request. However, most real life catalog systems will have to deal with a high number of properties and customer profiles, making the use of rules a sub-optimal approach (i.e. cases not predicted by the rules will default to a configuration that might not be ideal).
- Possible Approach(es):
- A probabilistic ontology can be used to estimate the preference of a given property given a user profile, based on statistical and anecdotal data. Multiattribute utility could be used to rank the items according to the user's preferences as estimated by the system. In this example, the result would be a prioritized list built upon the historical preferences of customers with that specific profile.
A.2. Use case 2: Wine Sweetness
A.2.1 Purpose and Goals
Given a set of knowledge bases containing information about wine, present a user with an approximate classification (according to his/her personal, and possibly vague criteria) of a particular unknown wine’s sweetness.
A.2.2 Assumptions and Preconditions
- To simplify matters, we might assume that a wine’s sweetness is only determined by its sugar content (and not, e.g., its acidity).
- The user is a wine expert that has defined unambiguous classification criteria for evaluating a wine’s sweetness. As a particular example, he may provide the system with mappings (fuzzy sets) dry, offdry, and sweet from the universe of sugar percentages [0,100] to the unit interval [0,1], where for example dry(p)=0.4 means that he would consider a wine with a sugar percentage of p, dry to degree 0.4.
- There are a number of wines (w1, w2, …, wm) that the system knows the classification of, and a particular target wine w that the user would like to classify.
- The system has no information about how the classifications of wines asserted by the various knowledge bases were obtained.
A.2.3 Required Resources
- Any number of knowledge bases (possibly) containing information about w1, …, wm and w.
- Definitions for every classification label the user maintains.
- Sugar content of w1, …, wm (but not of w).
A.2.4 Successful End
The user is given (an approximation of) the sweetness classification of wine w, e.g. (an interval containing) the degree to which w is dry, off-dry or sweet.
A.2.5 Failed End
The classification of w cannot be obtained (e.g., it can only be established that the degree to which w is dry is in [0,1]).
A.2.6 Main Scenario
* User specifies classification labels and their definitions, and provides target wine’s name w. * System queries the available knowledge bases for w, using the information about w1, …, wn ,and combines the results. * System returns approximation of wine’s classification according to user’s labels.
A.2.7 Additional Background Information or References
Text goes here
A.2.8 General Issues and Relevance to Uncertainty
Some relevant variations for this Use Case include:
- Wine advice for novices: the user knows nothing about wines. However, he has recently tasted the wines w1, w2, …, wm, and still recalls which of these he taught of as very dry, dry, rather dry, rather sweet, sweet, and very sweet. As he is eager to learn more about wines, he wants to buy a number of very dry white wines that satisfy some additional criteria (e.g. cheap German wines). The system should provide the user with (a ranking of) names of wines that satisfy these criteria. To obtain a set of wines that would be considered dry by the user, the system can make use of the user's perception of w1, w2, …, wm. Again, we assume that the system has no information about the criteria that were used to obtain the knowledge bases.
- In general, the use case can apply to any set of objects characterized by a vague property the definition of which can differ from user to user
In addition, it is interesting to note that knowledge bases may use a finer/coarser classification, or a different terminology, than the user. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Vagueness; UncertaintyDerivation: Subjective)
Even when using the same terminology, the interpretation of a vague classification label (like “dry”) may differ between the creator of the knowledge base and the user who queries the knowledge base. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Vagueness; UncertaintyDerivation: Subjective)
In some knowledge bases, the classification may be based on perception rather than on actual measurement (for instance, of the sugar content). (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Vagueness; UncertaintyDerivation: Subjective)
The information in various knowledge bases may be conflicting (for instance, because of differing, or erroneous, perceptions). (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: Inconsistency; UncertaintyDerivation: Objective)
Figures attached to this page:
- [get | view] (3.5 KB) attachment:Uncertainty.owl
- [get | view] (28.4 KB) attachment:UncertaintyModels.jpg
- [get | view] (10.3 KB) attachment:UncertaintyNature.jpg
- [get | view] (21.3 KB) attachment:UncertaintyTop.jpg
- [get | view] (28.4 KB) attachment:UncertaintyTypes.jpg
{kind=link}
{kind=link}
{kind=link}
{kind=link}
A.3 Use Case Title: ''Use Cases motivating refinement of Uncertainty Ontology''
A.3.1 - Purpose/Goals
We follow Charter http://www.w3.org/2005/Incubator/urw3/charter. The objectives of the URW3-XG are twofold:
- To identify and describe situations on the scale of the World Wide Web for which uncertainty reasoning would significantly increase the potential for extracting useful information;
- To identify methodologies that can be applied to these situations and the fundamentals of a standardized representation that could serve as the basis for information exchange necessary for these methodologies to be effectively used.
To motivate this, the charter mentions several use cases. In this use case we briefly link these „charter use cases“ to several more detailed use cases
The main method to achieve goals is to enrich web documents with Uncertainty Annotations [UncAnn], hence increase the potential for extracting useful information.
A.3.2 - Assumptions/Preconditions
- We need a unified model of uncertainty annotation of web resources
- Due to the size of the web this should be done automatically (maybe after some human training for particular domain)
A.3.3 - Required Resources
- Uncertainty Ontology, deductive engines using uncertainty information
- in case of third party uncertainty annotation we need a storage for these annotated resources
A.3.4 - Successful End
Automatic processing of web resources will be more accurate
A.3.5 - Failed End (Describe what happens if this use case fails)
- Nothing happens, the web will be as of today
A.3.6 - Main Scenario
- Development of more detailed uncertainty ontology
- get acquaintance within some specific domain
- experiments with processing of resources annotated with such ontology
- life cycle of development continues until models and methods bring improvement
A.3.7 - Additional background information or references
Some acquaintance with uncertainty processing is in the community of Information Retrieval, see e.g. Parsons, S., '' Current approaches to handling imperfect information in data and knowledge bases ''
A.3.8 - General Issues and Relevance to Uncertainty In automated Web data processing we often face situations when Boolean truth values are unknown, unknowable, or inapplicable. The nightmare caused by proprietary uncertainty representations makes impossible to use these for further processing. We briefly mention several use cases originally mentioned in the URW3 charter. Moreover we include here Fine grained version of Uncertainty Ontology a finer grained version of Uncertainty Ontology to show a possible evolution of upper level UncertaintyOntology and emphasize uncertainty issues connected to machine processing (lot of situations is perfectly certain when considering human consumption of web resources). We focus especially on finer classification of Machine Agents (UncAnn Agent:MachineAgent) and uncertainty caused by lack of knowledge of a machine agent (UncAnn UncertaintyNature:Epistemic:MachineEpistemic).
Information extracted from large information networks such as the World Wide Web is typically incomplete (UncAnn UncertaintyType:Incompleteness). The ability to exploit partial information is very useful for identifying sources of service or information. For example, that an online service deals with greeting cards may be evidence that it also sells stationery. It is clear that search effectiveness could be improved by appropriate use of technologies for handling uncertainty.
Much information on the World Wide Web is likely to be uncertain. In some cases this is an inherent property of the world (UncAnn UncertaintyNature:Aleatory). Nevertheless, it is a difference, whether this world is the physical world, or living, society or business. Examples include weather forecasts (UncAnn UncertaintyNature:Aleatory:PhysicalWorldAleatory), gambling odds or stock exchange (UncAnn UncertaintyNature:Aleatory:BusinessWorldAleatory). Canonical methods for representing and integrating such information are necessary for communicating it in a seamless fashion.
Web information is also often incorrect or only partially correct, raising issues related to trust or credibility (UncAnn UncertaintyNature: Trust, UncertaintyType:Lie). Uncertainty representation and reasoning helps to resolve tension amongst information sources having different confidence and trust levels (this is one of few cases where even a human agent has problems with processing information).
The Semantic Web vision implies that numerous distinct but conceptually overlapping ontologies will co-exist and interoperate (UncAnn UncertaintyNature:Epistemic:MachineEpistemic). It is likely that in such scenarios ontology mapping will benefit from the ability to represent degrees of membership and/or likelihoods of membership in categories of a target ontology, given information about class membership in the source ontology.
Dynamic composability of Web Services will require runtime identification of processing and data resources and resolution of policy objectives. Uncertainty reasoning techniques may be necessary to resolve situations in which existing information is not definitive (UncAnn UncertaintyNature:Epistemic:MachineEpistemic).
All models and respective methods for handling different types of uncertainty are relevant (UncAnn UncertaintyModel)
We recommend aspects that are considered most important to be included in a standard representation of uncertainty : Extensions of UncertaintyOntology which prove to be useful in annotation of web resources in order to improve their machine processing
A.4. Use case 4: Belief fusion / Opinion pooling
A.4.1 Purpose and Goals
If a single information artifact (e.g., a knowledge base, an ontology, or a product rating on the web) shall be created from multiple possibly contradictory information sources (e.g., expert opinions, existing ontologies, or product recommendations), the user (e.g., the knowledge engineer) applies a fusion operator in order to yield possibly uncertain fused beliefs from multiple input beliefs provided by the information sources.
A.4.2 Assumptions and Preconditions
For the most basic version of this use case, the only assumption is that the user is able to retrieve information from multiple sources on the Web. For more complex versions, a technical infrastructure for the aggregation of distributed information sources needs to exist (e.g., a distributed knowledge or data base, a news aggregator...).
A.4.3 Required Resources
1. An adequate collection of the relevant input information (opinions, ratings, source ontologies...)
2. Optionally: Information provenance identifiers in order to distinguish the information contributions. Resources could be meta-data (provenance annotations), URIs, social networks, or contexts.
A.4.4 Successful End
The user managed to create a single, coherent merger of the contributions such that the merger i) is in a format which supports the representation of uncertainty, ii) is consistent, and iii) reflects the support (belief grades) provided by each information source for each contained statement appropriately.
A.4.5 Failed End
\neg Successful End
A.4.6 Main Scenario
1. The user identifies information sources she considers to be relevant.
2. Inconsistencies and other disparities are identified, preferably automatically
3. The system applies a belief aggregation operator, calculating possibly uncertain fused beliefs from the input beliefs.
4. The result is represented in some appropriate formal web language (e.g., one of the existing probabilistic enhancements of OWL).
A.4.7 Additional Background Information or References
Uncertainty approaches to belief fusion and opinion pooling (sometimes also called probability aggregation) are researched in AI since quite a long time, although no consensus regarding the "best" approach exists.
Similar approaches, although partly on a different epistemic level, exist in research communities such as sensor fusion and database integration.
A related area is the theory of social choice, especially judgement aggregation, and that of computational trust for the assessment of those knowledge sources which shall be aggregated. The latter issue is dealt with in Richardson, M., Agrawal, R., and Domingos, P. (2003) Trust Management for the Semantic Web. Proceedings of the Second International Semantic Web Conference, 2003.
Instance-based learning and particularly similarity-based learning could also be used for coping with the presented knowledge fusion problem. An example is presented in C. d'Amato, N. Fanizzi, F. Esposito. Analogical Reasoning in Description Logics 2nd ISWC Workshop on Uncertainty Reasoning for the Semantic Web. Athens, Georgia (USA), November, 5-9, 2006.
An approach which relates the problem of belief fusion with Context Ontologies and provenance annotation on the Web can be found in Nickles, M. (2007) Social Acquisition of Ontologies from Communication Processes. Applied Ontology, 2007.
A.4.8 General Issues and Relevance to Uncertainty
This use case is especially relevant wrt. uncertainty in case the set of information acquired from multiple sources about the same fact is inconsistent (UncertaintyNature: Epistemic; UncertaintyType: Inconsistency) , or (more generally) if multiple information sources attribute multiple and mutually different grades of belief to the same statement. If the user does not want to decide in favor of a single alternative, and wants the merger to weight all input beliefs adequately (instead of discarding some of them), the single statement resulting from the fusion of multiple statements will be uncertain (UncertaintyNature: Epistemic; UncertaintyType: Empirical usually, but might also depend on the uncertainty type of the input statements.)
It might be reasonable to consider in addition factors such as the trustability of the information contributors at aggregation.
Examples for belief aggregation operators which can yield uncertain results are logarithmic and linear pools (LogOP, LinOP), and Bayesian Network Aggregation. One possible criterion for a successful fusion is the minimization of the divergence of the resulting probability distribution from the input probability distributions.
In order to yield an uncertain fusion result it is of course not necessary that any of the input statements which shall be fused is already uncertain itself. One important issue that it is open is how to adapt this essentially "probabilistic use case" for the use of fuzzy logic (if possible).
A.5. Use case 5: Ontology Based Reasoning and Retrieval from Large-Scale Databases
A.5.1. Purpose and Goals
Given a large company database which involved a high degree of vague and imprecise data, make the content available on the Semantic Web for ontology based querying.
A.5.2 Assumptions and Preconditions
A database containing a huge amount of vague data and a method to produce fuzzy assertions (knowledge) based on the original numerical database values.
A.5.3 Required Resources
A large-scale database containing videos of persons with information about their characteristics and videos with semantic annotations.
An ontology for performing knowledge-based semantic access to the database content.
A high-performance and scalable fuzzy reasoning system for performing reasoning over the large-scale database.
A.5.4 Successful End
The user can efficiently and effectively find a set of models, spot or other footage without having to browse through the entire collection and try to identify with his own criteria the best matching for him. The successful accomplishment can dramatically improve the productivity of production companies or other related companies having databases with data of such nature.
A.5.5 Failed End
The users have to browse through the entire collection of images or videos with merely no help by the system and try to match the viewed content with the search criteria they have in their mind.
A.5.6 Main Scenario
The data are fuzzified according to metrics defined by the knowledge engineer expert of the specific application. Then, an ontology is created to enable ontology-based content retrieval. Finally, users can use the system and issue queries to the system. The system performs fuzzy reasoning with the data and provides the user with a ranked set of recommendations.
A.5.7 Additional Background Information or References
The specific use case scenario comes from a real world industrial application, which already has such a footage database: Production company database: CINEGRAM S.A. http://www.cinegram.gr/ The use case can be coped and has been tested with several fast and scalable fuzzy reasoning systems:
ONTOSEARCH2 (http://www.image.ece.ntua.gr/php/pub_details.php?code=529 see also http://dipper.csd.abdn.ac.uk/OntoSearch/about.jsp.) which is a tractable DL reasoner based on the DL DL-Lite. Currently it also supports fuzzy DL-Lite. Since ONTOSEARCH2 is based on DL-Lite it is able to cope with millions and even billions of fuzzy data and perform expressive fuzzy querying over such data, and
Expressive Fuzzy DL reasoning engine: FiRE (http://www.image.ece.ntua.gr/php/savepaper.php?id=445 see also http://www.image.ece.ntua.gr/~nsimou/) is a very expressive fuzzy DL reasoner based on Fuzzy-SHIN. It also supports storing and querying fuzzy knowledge over the Sesame triple-store platform additionally supporting expressive fuzzy querying over hundreds of thousands of data. Sesame provides the ability to query over hundreds of thousands of fuzzy data.
A.5.8 General Issues and Relevance to Uncertainty
Vague Concepts and information (Uncertainty nature: Aleatory; UncertaintyType: Vagueness) User wants a recommendation of videos, images or models, but the current non semantic, low level information in the database.
Example: User wants all tall and thin models that have a Student looks. The database contains the height (in cms), weights (in kgs) and age of each models. There are two cases here. 1) In absence of an ontology that defined concepts Tall, Thin and Student the user has to define these concepts in terms of height, weight etc in his query. In other words he has to issue a query like the following:
“Get me all x, where Model(x) and (either (Female(x), Height(x)>175cm and Weight(x)<60kg) or Male(x), Height(x)>185cm and Weight(x)<87kg, and age(x) between 18 and 23.”
2) In the presence of an ontology the ontology engineer has defined concepts tall, thin and Student by using similar definitions as above, i.e. he has defined someone above 185km as Tall.
Obviously a model that satisfies all but the weight condition is missed; similarly if all but the age restrictions are satisfies. This is counterintuitive since still these persons might qualify according to the user needs
A.6. Use case 1: SOA Execution Context
A.6.1. Purpose and Goals
Establish the set of conditions that ensures a prospective consumer of a SOA service has identified the appropriate service to address its needs and to ensure for a possible provider of a SOA service that the consumer is authorized to use the service. In addition, the consumer and provider must agree on specifics of message exchange and the semantics of the exchanged messages, both message type and content..
A.6.2 Assumptions and Preconditions
- The service provider has made visible a description of the functionality that results from interacting with the service.
- Both consumer and provider have made visible descriptions of their assumptions, technical and business requirements, and policies under which an interaction can proceed.
A.6.3 Required Resources
- Service descriptions created and made visible to consumer.
- Provider and consumer reference functionality, technical conditions, policies, etc. that have descriptions which are visible to each other.
- Mechanisms exist to facilitate matching alternatives in functionality, technical conditions, policies, etc.
A.6.4 Successful End
The service consumer is satisfied that the service provides the required results (i.e. real world effects) and the consumer and provider have aligned their assumptions, technical and business requirements, and policies so that use of the service may proceed.
A.6.5 Failed End
The service interaction will not proceed but in the best case the consumer and provider have sufficient information to know what broke down in establishing the execution context.
A.6.6 Main Scenario
- Consumer compiles or otherwise accesses a list of services whose descriptions indicate certain business functionality.
(Uncertainty in whether list is complete, whether list is appropriate as match to desired need UncertaintyNature: Epistemic; UncertaintyType: could be Ambiguity or Vagueness)
- Consumer compares described functionality of each service against his/her needs.
(Uncertainty as to whether description is complete enough, i.e. has covered sufficient aspects of consumer needs; are semantics aligned so terms mean same thing or consumer knows correspondence when terms different. UncAnn - UncertaintyNature: Epistemic; UncertaintyType: could be Ambiguity or Vagueness)
- Consumer takes subset for which functionality match is most promising and compares other assumptions, technical and business requirements, and policies. For example, consumer may have policy that if s/he provides contact information, the service provider must not use the information for a purpose other than this interaction.
(Uncertainty same as for step 2. UncAnn - UncertaintyNature: Epistemic; UncertaintyType: could be Ambiguity or Vagueness)
- Consumer engages with provider to resolve any disconnects. Either consumer or provider may decide to proceed even if not satisfied that all disconnects are completely resolved.
(Uncertainty in that consumer and provider may not have complete understanding of resolutions, e.g. a number of circumstances are covered in resolutions and one party not sure how all the permutations work but does not feel further delay is justified in to work more details. UncAnn - UncertaintyNature: Epistemic; UncertaintyType: could be Ambiguity or Vagueness)
- Service used and interaction completed.
(Uncertainty as to whether consumer needs have been satisfied. UncAnn - UncertaintyNature: Epistemic; UncertaintyType: could be Ambiguity or Vagueness)
A.6.7 Additional Background Information or References
As defined in the OASIS Reference Model for Service Oriented Architecture (SOA-RM), the execution context of a service interaction is the set of infrastructure elements, process entities, policy assertions and agreements that are identified as part of an instantiated service interaction, and thus forms a path between those with needs and those with capabilities.
As discussed in SOA-RM, the service description (and a corresponding description associated with the service consumer and its needs) contains information that can include preferred protocols, semantics, policies and other conditions and assumptions that describe how a service can and may be used. The participants (providers, consumers, and any third parties) must agree and acknowledge a consistent set of agreements in order to have a successful service interaction, i.e. realizing the described real world effects. The execution context is the collection of this consistent set of agreements.
A.6.8 General Issues and Relevance to Uncertainty
Service consumer may have insufficient information about provider's capabilities and associated requirements to ascertain whether service provider can meet needs at acceptable cost. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: could be Ambiguity or Vagueness)
Example:
- The provider requires address and email information but does not specify privacy policy to let consumer know whether information will be used for other purposes, such as marketing lists. The consumer needs to decide whether to supply the information or terminate the interaction.
- Limitations of deterministic representation:
- No matter how much information is supplied by the provider, it is always possible there will be some additional information that the consumer would like (or needs) to have.
- Possible Approach(es):
- Bayesian decision theory for user assistant to create probabilistic expectation of provider intent and recommend to consumer whether to provide information based on previous provider information and consumer preferences.
Service provider may have insufficient information about consumer's need to know whether the functionality it provides can meet that need. (UncAnn - UncertaintyNature: Epistemic; UncertaintyType: could be Ambiguity or Vagueness)
Example:
- The consumer initiates a transaction but does not specify whether they are interested in a detailed log of the exchange or just a confirmation of the final results. The provider executes a different process to capture the detailed log and provides the detailed log for an extra fee. The provider could capture the detailed log and offer it at the end for a premium fee, but there is some cost to the provider in capturing the detailed log.
- Limitations of deterministic representation:
- A simple standard default does not allow the provider to generate additional income from consumers who decide on the detailed log at the end.
- Possible Approach(es):
- Bayesian decision theory to estimate likelihood based on knowledge of consumer, e.g. categorization based on collected information about consumer. Provider will choose course of action to maximize expected financial return.
A.7. Use case 7: Recommendation
A.7.1 Purpose and Goals
Develop an ability to express a set of recommendations by a number of agents and an ability to express an aggregated recommendation and ranking such that formal inference can be carried out on the set of recommendations. Also, an ability to express preferences and scales in a formal way.
A.7.2 Assumptions and Preconditions
- Searchers and recommenders have expressed their preferences and scales in machine readable form.
- The catalogue has been populated using a property set and property values that have a machine processable representation of the vocabulary used
- A similar machine processable representation exists for the vocabulary used to state the search criteria.
A.7.3 Required Resources
- Standardized ontologies for preferences, scales, voters
- Formal language for the representation of uncertain/fuzzy single and aggregated recommendations
A.7.4 Successful End
Having obtained an aggregated recommendation and ranking such that formal inference can be carried out on the set of recommendations
A.7.5 Failed End
\neg Successful End
A.7.6 Main Scenario
A single or multiple recommendation searcher(s) express(es) her/their preferences in a machine readable format. A recommender system then combines a set of recommendations (obtained by a number of agents or other recommender systems) into an aggregated recommendation and ranking. For example, a user might input a movie, and the system would form its recommendation by aggregating recommendations provided by consumers who have seen the movie.
A.7.7 Additional Background Information or References
This use case is closely related to the research on collaboration-based recommender systems. Information about this research area can be found for example at http://www.deitel.com/ResourceCenters/Web20/RecommenderSystems/RecommenderSystemsandCollaborativeFiltering/tabid/1318/Default.aspx
A.7.8 General Issues and Relevance to Uncertainty
Various agents may have different scales, and more important: different preferences and different confidence levels. A set of recommendations or a set of preferences may be inconsistent.
In detail, the following issues relate this use case to uncertainty:
- the set of recommendations obtained from multiple agents might be inconsistent.
- a recommendation possibly matches the preference(s) of the recommendation searcher only imperfectly.
- a recommender system might have obtained its recommendation using statistical means (e.g., using collaborative filtering).
- an agent or a recommender system might have a low confidence in its recommendation, i.e., it is uncertain whether its recommendation actually matches the preference.
- the preferences provided by a recommendation searcher can be uncertain or inconsistent, e.g., because a user might not be able to express his preferences in sufficient detailedness.
- sometimes a single recommendation shall reflect multiple preferences provided by multiple recommendation searchers (e.g., if a group of users seeks for a single recommendation which reflects the preferences of all group members as good as possible). Uncertainty arises e.g. in case these input preferences are inconsistent.
A.8 Use Case Title: ''Extraction-Annotation''
A.8.1 - Purpose/Goals
The motivating situation is a user (or a web service) that wants a web scale overview of available information – e.g. overview over all car selling shops. The advantage would be a possibility of comparison of different market offers. Another application is competitor tracking system.
Main problem is the size of data and the fact that these data are mainly designed for human consumption.
Many of our use cases assume that e.g. "web resources has been populated using a property set and property values that have a machine processable representation of the vocabulary used". On the other side, the W3C activity Gleaning Resource Descriptions from Dialects of Languages (GRDDL) see www.w3.org/TR/grddl/ in GRDDL specification introduces markup based on existing standards for declaring that an XML document includes data compatible with the Resource Description Framework (RDF) and for linking to algorithms (typically represented in XSLT), for extracting this data from the document (e.g. products in an e-shop).
Our approach tries to generalize this to arbitrary HTML, XHTML sources and extending "Dialects of languages" to semi-structured html pages and also to dominantly text pages (e.g. accident reports). Main goal is to do this "gleaning" (also web content mining, extraction) automatically for a large number of resources. Task is easy for humans, nevertheless humans can not process a large number of pages. Task is difficult for machines, nevertheless machines can process large number of resources. The main trick is to find a trade-off between amount of human assistance (especially in training and ontology creation) and automation. Second issue is domain dependence. One can easily write a script extracting RDF triples from a single page. The goal is to extract data from pages never visited. Third dimension of the problem is "machine difficulty" of the resource. Some pages (e.g. generated from a database) are easier for machine extraction than other dominantly textual.
Our task is: given such a resource and an ontology extract data contained in this resource (to obtain an instance of some ontology parts, typically instances of a class and some properties of that class) and annotate the original resource (wrt given ontology).
A.8.2 - Assumptions/Preconditions
arbitrary web shop page, e.g. http://notebook.cz/model/Acer
- data structure, ontology, containing attributes of notebooks
special part of extraction ontology supporting extraction - e.g. typical values, ranges of values, regular expressions, ... Here owl:oneOf could be extended to owlExtension:Usualy_One_Of and extension of possibilities defining data
types, e.g.
o1:ntb_memory owlExtension:usualy_has_range 128MB..8GB
o1:ntb_disk owlExtension:usualy_has_range 20GB..500GB.
A.8.3 - Required Resources
- as above
A.8.4 - Successful End
We will be able to extract RDF data from pages which are plain (both structured, textual) HTML files wrt a given ontology and annotate the original page with RDFa. Moreover the result should be machine understandable and an input for further processing - see Discovery use case.
A.8.5 - Failed End
lot of pages will be not machine processable, lot of information will be practically unachievable for a human.
A.8.6 - Main Scenario
First type of scenario, is describing the process of extraction and annotation (details above or in links), e.g
- classify different web resources - some are easy for extraction (simple tables), some more difficult (non correct html pages with non regularities in the tag tree) up to dominantly text content
- specify whether we are training a wrapper for a specific page which is often changed or for a wide spectrum of pages
- specif methods and uncertainty issues
- and so on
Or we can understand this scenario as sequences needed for inclusion to final report, then this scenario has following steps
- today form of the use case b. design formally a core of an extraction ontology
c. connect it to the Uncertainty ontology http://www.w3.org/2005/Incubator/urw3/wiki/UncertaintyOntology
and/or
pr-owl ontology http://pr-owl.org
and/or
Task_oriented_uncertainty_ontology http://www.w3.org/2005/Incubator/urw3/wiki/Discussion
A.8.7 - Additional background information or references
papers on data extraction see e.g. http://www.cs.uic.edu/~liub/Web-Content-Mining-2.pdf
A.8.8 - General Issues and Relevance to Uncertainty
Solution are extraction and annotation tools. There are many annotation tools linked on http://annotation.semanticweb.org/annotationtool_view, mainly using a proprietary uncertainty representations (or built in uncertainty handling). One of main tasks of this XG is to provide fundamentals of a standardized representation of uncertainty that could serve as the basis for information exchange. Here uncertainty annotation of results would be especially helpful.
In what follows we use acquaintance from uncertainty issues in experiments with web content mining as described in http://c4i.gmu.edu/ursw2007/files/papers/URSW2007_T9_VojtasEtAl.pdf, see also presentation http://c4i.gmu.edu/ursw2007/files/talks/URSW2007_T9_VojtasEtAl_Slides.pdf.
In what follows we present issues and relevance to uncertainty which are specific for this use case and we annotate them (UncAnn) with reference to Uncertainty Ontology (UncertaintyOntology) and extensions to classes and properties described in Fine grained version of Uncertainty Ontology.
Assume that a user is looking for notebooks and we would like to provide a machine support for his/her search. A typical statement which is a subject of uncertainty assignment in this use case is: (UncAnn Sentence)An html coded web page with URL contains informations, which according to an ontology o1 (UncAnn World: DomainOntology) about notebooks can be expressed by a RDF triple (ntb1, O1:has_priceProperty, 20000). The agent producing this statement is (UncAnn Agent:MachineAgent) especially an induction agent (UncAnn Agent:MachineAgent:InductiveAgent).
Uncertainty nature of this statement is (UncAnn UncertaintyNature:Epistemic:MachineEpistemic), uncertainty type is usualy (UncAnn UncertaintyType:Empirical:Randomness). Instances used for training an extraction tool (UncAnn World:DomainOntology:Instances) are web pages, the uncertainty model is usually complicated (mixture of html structure, regular expressions, annotation ontology and similarity measures) and combination of several models, typically (UncAnn UncertaintyModel:CombinationOfSeveralModels:ProbabilityAndFuzzySetsCombinationModels) . Depending on this the evidence for this uncertainty statement (UncAnn World:DomainOntology:Instances:Evidence) are precision and recall on this training set.
The goal of this use case is to find out which models of uncertainty and vagueness are appropriate. Especially it is clear that a more detailed ontology is needed (containing information supporting successful automatic extraction - it is not a human uncertainty, it is a machine uncertainty). One can expect that the system is learning/improving during usage and the extraction ontology is extended.
Extraction form textual pages need another type of knowledge, e.g. transforming a sentence to a (Subject Verb Object) tree (full, partial).
A.9. Use case 9: Soft Shopping Agent
A.9.1 Purpose and Goals
Suppose we have a car selling web site offering cars and we would like to buy a car. Descriptions of the cars are stored in databases and we have some ontology encoding information about the domain. Now, suppose that preferably we would like to pay around 11000 euro and the car should have fewer than 15000 km on the odometer. Also, if there are leather seats then I would like to have air conditioning, the color is preferably blue, and the car is is not old.
Of course, most of our constraints, e.g. on price and kilometers, aren't crisp as we may still accept e.g.~a car's cost of 11200 euro and with an odometer reading of 16000km. Hence, these constraints are rather vague (fuzzy) (we may model this by means of so-called fuzzy memebr functions). We may also give some preference weight to my requirements.
On the other hand, the seller may offer a discount on the car's catalogue price, but the bigger the discout the less satisfied he is. For instance, related to the e.g a sold Mazda3, the seller may consider optimal to sell above 15000euro, but can go down to $13500euro to a lesser degree of satisfaction.
For each car, there will be an optimal price it can be sold, which maximises the product of the buyer's degree of satisfaction and the seller's degree of satisfaction. This is the so-called NASH equilibrium of the matching. Each car gets an optimal degree of buyer/seller degree of satisfaction.
From the buyer perspective, he asks for the TOP-k cars and their optimal price, ranked the optimal degree of sadisfaction.
From the seller perspective, he may ask for the TOP-k buyer's for a given car and their optimal price, ranked the optimal degree of sadisfaction.
A.9.2 Assumptions and Preconditions
A data source containing requests and items to be sold.
A.9.3 Required Resources
A database, an ontology and a top-k reasoner.
A.9.4 Successful End
The players can efficiently and effectively find top-k results
A.9.5 Failed End
The players have to browse the data.
A.9.6 Main Scenario
Text goes here
A.9.7 Additional Background Information or References
- @inproceedings{Ragone07,
- Author = {Azzurra Ragone and Umberto Straccia and Tommaso Di Noia and Eugenio Di Sciascio and Francesco M. Donini}, Booktitle = {4th European Semantic Web Conference (ESWC-07)}, Number = {4519}, Pages = {414--428}, Publisher = {Springer Verlag}, Series = {Lecture Notes in Computer Science}, Title = {Vague Knowledge Bases for Matchmaking in P2P E-Marketplaces}, Year = {2007}}
- @inproceedings{Straccia07,
- Address = {Cancun, Mexico}, Author = {Straccia, Umberto}, Booktitle = {World Congress of the International Fuzzy Systems Association (IFSA-07)}, Title = {Towards Vague Query Answering in Logic Programming for Logic-based Information Retrieval}, Year = {2007}}
- @inproceedings{Straccia07a,
- Address = {Insbruck, Austria}, Author = {Straccia, Umberto and Visco, Giulio}, Booktitle = {Proceeedings of the International Workshop on Description Logics (DL-07)}, Date-Added = {2007-05-02 13:11:08 +0200}, Date-Modified = {2007-06-12 11:17:37 +0200}, Publisher = {CEUR}, Title = {{DLM}edia: an Ontology Mediated Multimedia Information Retrieval System},
Url = {http://ceur-ws.org}, Volume = {250}, Year = {2007}}
- Address = {Insbruck, Austria}, Author = {Straccia, Umberto and Visco, Giulio}, Booktitle = {Proceeedings of the International Workshop on Description Logics (DL-07)}, Date-Added = {2007-05-02 13:11:08 +0200}, Date-Modified = {2007-06-12 11:17:37 +0200}, Publisher = {CEUR}, Title = {{DLM}edia: an Ontology Mediated Multimedia Information Retrieval System},
- Basic System reference: there are two systems, which go towards iplementing the use case.
* fuzzyDL, a fuzzy OWL-Lite reasoner with a full fledged mixed integer programming environment (http://gaia.isti.cnr.it/~straccia/software/fuzzyDL/fuzzyDL.html)
* DLMedia, a fuzzy DLR-Lite reasoner with a built-in top-k database retrieval engine (http://gaia.isti.cnr.it/~straccia/software/DLMedia/DLMedia.html)
A.9.8 General Issues and Relevance to Uncertainty
Matchmaking in eCommerce with soft constraints is about vague reasoning. The uncertainty type is vagueness(UncertaintyType:Vagueness), as matchings are found only to some degree. The possible model is based on mathematical fuzzy logic(UncertaintyModel:Fuzzy Sets). An optimization and reasoning procedure is involved (Agent:Machine:Machine Deduction - optimizing finding top-k answers on the web). One important issue that remains open is Large scale Top-k retrieval algorithms for Semantic Web languages
A.10 Use Case Title: ''A chain from the Web to the user''
A.10.1 - Purpose/Goals
To get information from the web to the user we have to use a chain of tools – typically web crawling, web data extraction, middleware transformation, user querying and delivering answer. There are several use cases dealing with particular problems of uncertainty along such a chain, e.g. Extraction-Annotation and User_prefference_modelling_for_top-k_answers. Usually there is a middleware connecting those.
The problem is, how does uncertainty evolve along such a chain.
A.10.2 - Assumptions/Preconditions
- the above problem has many variants, depending on the type of web resource, type of user
- The problem depends also on size of data needed to process
A.10.3 - Required Resources
- Some already running examples where proprietary uncertainty representations can be helpful for understanding the whole problem
- Human annotated examples, to verify training and experimenting new models
A.10.4 - Successful End
Extend web standards in such a way that the whole chain from the Web to the user is covered by uncertainty application in a unified way and reusable
A.10.5 - Failed End
There will be only proprietary orchestrations of web services
A.10.6 - Main Scenario
- Solve problems of particular part of the chain
- Try to integrate models, methods and tools
A.10.7 - Additional background information or references
in the following paper an experimental chain of tools is described (more focused on user side of chain)
P. Gurský, T. Horváth, J. Jirásek , S. Krajči, R. Novotný, V. Vaneková, P. Vojtáš, Knowledge Processing for Web Search – An Integrated Model, In: C. Badica and M. Paprzycki (eds.) Proceedings of the 1st International Symposium on Intelligent and Distributed Computing (IDC 2007), STUDIES IN COMPUTATIONAL INTELLIGENCE (vol. 78), Springer, 2007, pp: 95-104, see http://www.springer.com/engineering/book/978-3-540-74929-5
see also http://nazou.fiit.stuba.sk for more experiments on a chain of tools
A.10.8 - General Issues and Relevance to Uncertainty
In what follows we present issues and relevance to uncertainty which are specific for this use case and we annotate them (UncAnn) with reference to Uncertainty Ontology (UncertaintyOntology) and extensions to classes and properties described in Fine grained version of Uncertainty Ontology.
In what follows we use acquaintance from uncertainty issues in experiments with a chain connecting web and user as described in http://c4i.gmu.edu/ursw2007/files/papers/URSW2007_T9_VojtasEtAl.pdf, see also presentation http://c4i.gmu.edu/ursw2007/files/talks/URSW2007_T9_VojtasEtAl_Slides.pdf.
Our understanding of this is to view the whole chain of models, methods and tools from web to the user and especially handling uncertainty combination along this (UncAnn UncertaintyModel: CombinationOfSeveralModels). First experiments with such a chain are described in ''Web Search with variable user model''
First there is the Web. Only a few resources are annotated (tagged or made understandable to a computer). Some of them are structured in html tables (meaning less or difficult to understand). Many pages contain information in natural language and are designed for human consumption. This is typically difficult to understand for machines (UncAnn UncertaintyNature:Epistemic:MachineEpistemic).
When (at least a candidate) set of resources was allocated, we face a decision, download and what ?(a snippet or whole source code). Are there uncertainty problems in Wrappers, Crawlers, Search engines (see e.g. L. Galambos ''Egothor - Java search engine'')?
Some middleware between user and indexed resources has to care for matching and uncertainty too (see,e.g. ''Semantic Web Infrastructure using Data Pile'' and Data Integration Using Data Pile Structure'').
How to model users is another problem with many uncertainty problems, especially from the point of combination of different models, e.g. UncertaintyModel: Probability and UncertaintyModel: PreferenceModels. Considering the whole chain maybe can help us to understand different sorts of uncertainty in a context of an integrated Web application
A.11 Use Case Title: ''Making an Appointment''
A.11.1 - Purpose/Goals
Schedule an interaction with a provider of a business service (e.g., doctor, lawyer, etc.), taking into account geographic proximity, schedule constraints of consumer(s), schedule constraints of provider, and possibly other constraints.
A.11.2 - Assumptions/Preconditions
- Consumer(s) need capability provided by provider(s)
- Provider(s) can provide service requested by consumer(s).
- A means exists to represent constraints and preferences
- Times available
- Travel distance
- Information about whether provider is an acceptable match with consumer
- Example in the medical domain is consumer’s insurance carrier and list of carriers accepted from provider;
- In general, there may be an approved and/or recommended list of providers from which consumer wishes to choose.
A.11.3 - Required Resources
- List of providers of service consumer wishes to access
- Includes characteristics such as whether provider is on one or more lists of preferred provider
- Includes geographic information
- Includes office hours
- Includes other constraints on accessibility
- Calendar of consumer
- Schedule of provider and openings
- Uncertainty Ontology
A.11.4 - Successful End
Consumer is given one or more recommended times when provider is available for scheduling. Consumer selects among these. Agreed-upon time is entered into consumer’s calendar and scheduled with provider.
A.11.5 - Failed End
No provider is found who meets consumer’s constraints and is available at times consumer can make.
A.11.6 - Main Scenario
- Consumer enters system and requests to make an appointment
- System asks which type of appointment is desired (if multiple types are supported) and requests specifics on request:
- Consumer’s geographic location (home and work)
- Preferred list of providers (if any – this can be a reference such as “providers accepted by xxx insurance company” or “providers recommended by publication yyy”
- Consumer enters requested information.
- System requests information on consumer’s goals and preferences (preferred times; preferred travel time)
- Consumer enters requested information
Example - consumer requests less than 10% chance that drive from work location to provider location will take more than 30 minutes. (UncAnn - UncertaintyNature: Aleatory; UncertaintyType: Empirical]; UncertaintyModel: Probability)
- System matches consumer’s information against provider’s list
Example - For each provider under consideration, system calls a service that estimates probability distribution on travel times from consumer's workplace to provider's location at time of appointment. System rejects all provider/appointment time combinations for which there is greater than 10% probability that driving time is greater than 30 minutes. (UncAnn - UncertaintyNature: Aleatory; UncertaintyType: Empirical]; UncertaintyModel: Probability)
- System presents consumer with a list of providers and appointment times
- Example - Result includes graphic of a timeline, with a bar indicating 10th, 50th and 90th percentiles on driving time from consumer's workplace to provider's location at time of appointment.
- Consumer selects one of the options
A.11.7 - Additional background information or references
This use case was inspired by the article Berners-Lee, T., Hendler, J., & Lassila, O. (2001). The Semantic Web, Scientific American (pp. 29-37).
A.11.8 - General Issues and Relevance to Uncertainty
Uncertainty about availability of consumer(s) – their schedules may not be fully firmed up. (UncAnn - UncertaintyNature: Aleatory; UncertaintyType: Empirical)
Example:
- Consumer must attend a meeting which will be held either Wednesday or Thursday morning, but the time has not yet been finalized. Consumer would prefer not to schedule the appointment at these times, but wants an appointment within a week.
- Limitations of deterministic representation:
- No way to indicate tentative or uncertain availability.
- Possible approaches
- Qualitative probability - time slots are tagged as definitely available, probably available, possibly available, and unavailable. Multiattribute utility - likelihood of having to reschedule is traded off against desirability of time slot.
Uncertainty about availability of provider(s) – slots may open up at times consumer prefers over currently available times. (UncAnn - UncertaintyNature: Aleatory; UncertaintyType: Empirical)
Uncertainty about whether provider can meet consumer’s constraints (e.g., physician specialty, does provider accept patient’s insurance). (UncAnn - UncertaintyNature: Epistemic and/or Aleatory (depends on type of constraint); UncertaintyType: Empirical)
Uncertainty about time it will take consumer to get to provider’s location (or vice versa if service is provided at consumer’s locale). (UncAnn - UncertaintyNature: Aleatory; UncertaintyType: Empirical)
Example
- Consumer must drive from work to the appointment, and must make sure she allows sufficient time for the trip.
- Limitations of deterministic representation:
- The driving time varies considerably with traffic and weather, and a deterministic representation does not take this into account.
- Possible approaches:
Probability theory and statistics on traffic in the region can be used to estimate typical driving time at the time of day of the appointment. On day of appointment, the probability distribution can be updated to take account current weather and traffic conditions. The appointment making system could use a probabilistic ontology to interchange information with a traffic forecasting service.
A.13 Use Case Title: ''User preference modeling for top-k answers''
A.13.1 - Purpose/Goals
This is in a sense a generalization of some aspects of Discovery use case. Given a populated catalogue by some extraction tool (see use case about extraction) of items and a user’s criteria and/or multicriterial utility function for item potentially listed in the catalogue retrieve best, top-k matches.
A.13.2 - Assumptions/Preconditions
- similarly as in Discovery - The catalogue has been populated using a property set and property values that have a machine processable representation of the vocabulary used
- We have data extracted and annotated
A.13.3 - Required Resources
- Populated catalog
- user preference model and instances for single user
A.13.4 - Successful End
User gets answer fitting to his/her preferences He/she gets answers fast, because retrieving top-k is understood without computing all answers
A.13.5 - Failed End
There is a danger in uncertainty methods - namely combinatorial explosion - namely, replacing two valued Boolean model can lead to the point that everything is relevant in some nonzero degree
A.13.6 - Main Scenario
- Buyer queries the web for a product
- He / she realizes that to search all web resources is very time consuming
- Consulting a web services providing overview information is a good choice
- He has to follow instructions which web service uses to learn his / her preferences or the system uses implicit learning (learning from click stream)
A.13.7 - Additional background information or references
Efficient algorithms for top-k answering where studied in Fagin et al., ''Making Optimal aggregation algorithms for middleware '', learning user preferences from explicit information is described in ''Ordinal Classification with Monotonicity Constraints''. In ''EL description logic with aggregation of user preference concepts'' it is shown that these models can be described in description logic and hence compatible with web modeling standards.
A.13.8 - General Issues and Relevance to Uncertainty
In what follows we present issues and relevance to uncertainty which are specific for this use case and we annotate them (UncAnn) with reference to Uncertainty Ontology (UncertaintyOntology) and extensions to classes and properties described in Fine grained version of Uncertainty Ontology.
As result of any data mining procedure, results of such user preference mining will be uncertain.
Typical sentence which is a subject of uncertainty assignment is: (UncAnn Sentence) User1 prefers most item1 (list of of top-k most preferred items for User1 consists of item1, ..., itemk).
This statement can be made by the user himself or by another human (UncAnn Agent:HumanAgent). For the semantic web, more interesting case is the statement made by (UncAnn Agent:MachineAgent). The statement can be produced by a combination of an inductive procedure (UncAnn Agent:MachineAgent:InductiveAgent - mining user preferences) and a deductive procedure (UncAnn Agent:MachineAgent:DeductiveAgent - optimizing finding top-k answers on the web).
Uncertainty assigned to the above statement has typically (UncAnn UncertaintyNature:Epistemic:MachineEpistemic)
User's preference is in no case Boolean (yes-no), typical (UncAnn UncertaintyType:Vagueness) is about vagueness, which arises when the boundaries of meaning of user objective are indistinct.
There are models using partially ordered sets to represent preferences. Different ad hoc ranking approaches are used. Possible model is UncAnn UncertaintyModel:FuzzySets or UncertaintyModel: PreferenceModels. To make these uncertainty annotations usable for other machine agents a fine grained specification of UncAnn World:DomainOntology:Instances and or World:DomainOntology:Evidence has to be made to support agents decision how to proceed with this information.
Efficient algorithms for top-k answering where studied in Fagin et al., ''Making Optimal aggregation algorithms for middleware '', learning user preferences from explicit information is described in ''Ordinal Classification with Monotonicity Constraints''. In ''EL description logic with aggregation of user preference concepts'' it is shown that these models can be described in description logic and hence compatible with web modeling standards.
We have developed and inductive method learning user preference from given evaluation of a sample of objects (see reference list)
We recommend aspects that are considered most important to be included in a standard representation of vagueness and uncertainty: a concept of truth value as a comparative notion of relevance / preference
A.14. Use case 14: Ontology Mediated Information Retrieval
A.14.1 Purpose and Goals
Suppose we want to device ontology mediated multimedia information retrieval system, which combines logic-based retrieval with multimedia feature-based similarity retrieval. An ontology layer may be used to define (in terms of semantic web like language) the relevant abstract concepts and relations of the application domain, while a content-based multimedia retrieval system is used for feature-based retrieval. We ask to make queries such as
- Find top-k ranked video passages made by Umberto whose title is about 'tour' - Find top-k ranked images similar to a given one, which is about an animal
A.14.2 Assumptions and Preconditions
A data source containing the multimedia data and an ontology
A.14.3 Required Resources
A data source containing the multimedia data and an ontology, a top-k reasoner logical reasoner and a multimedia information retrieval system
A.14.4 Successful End
The players can efficiently and effectively find top-k results
A.14.5 Failed End
The players have to browse the data.
A.14.6 Main Scenario
Text goes here
A.14.7 Additional Background Information or References
* @inproceedings{Straccia07,
- Address = {Cancun, Mexico}, Author = {Straccia, Umberto}, Booktitle = {World Congress of the International Fuzzy Systems Association (IFSA-07)}, Title = {Towards Vague Query Answering in Logic Programming for Logic-based Information Retrieval}, Year = {2007}}
* @inproceedings{Straccia07a,
- Address = {Insbruck, Austria}, Author = {Straccia, Umberto and Visco, Giulio}, Booktitle = {Proceeedings of the International Workshop on Description Logics (DL-07)}, Date-Added = {2007-05-02 13:11:08 +0200}, Date-Modified = {2007-06-12 11:17:37 +0200}, Publisher = {CEUR}, Title = {{DLM}edia: an Ontology Mediated Multimedia Information Retrieval System},
Url = {http://ceur-ws.org}, Volume = {250}, Year = {2007}}
- Basic System reference:
* DLMedia, a fuzzy DLR-Lite top-k reasoner with a built-in top-k multimedia retrieval engine (http://gaia.isti.cnr.it/~straccia/software/DLMedia/DLMedia.html)
A.14.8 General Issues and Relevance to Uncertainty
The notion of "Relevance" in Multimedia Information Retrieval can be formalized as a vague relation among information need and multimedia object. The uncertainty type is vagueness(UncertaintyType:Vagueness), as matchings are found only to some degree. The possible model is based on mathematical fuzzy logic(UncertaintyModel:Fuzzy Sets). A reasoning procedure is also involved (Agent:Machine:Machine Deduction - optimizing finding top-k answers on the web).
A.16 Use Case: ''Got Speakers?''
A.16.1 - Purpose/Goals
Customer needs to make a decision on (1) whether to go to a store today or wait until tomorrow to buy speakers, (2) which speakers to buy and (3) at which store. Customer is interested in two speaker features: wattage and price. Customer has a valuation formula that combines the likelihood of availability of speakers on a particular day in a particular store, as well as the two features. The features of wattage and price are fuzzy. Optionally, Customer gets the formulas from CustomerService, a Web based service that collects information about products, stores, statistics, evaluations.
A.16.2 - Assumptions/Preconditions
Customer either relies on the definitions provided by CustomerService or is knowledgeable in both probability and fuzzy sets
Stores provide information to CustomerService. CustomerService keeps information on both probabilistic models and fuzzy models
- Customer has the capability of either obtaining or defining a combination function for combining probabilistic information with fuzzy
A.16.3 - Required Resources
Data collected by CustomerService on the availability of items, which in turn depends on restocking and rate of selling
- Ontology of uncertainty that covers both probability and fuzziness
A.16.4 - Successful End
Customer gets necessary information about the availability and types of speakers from stores. This information is sufficient for customer to compute the required metric.
A.16.5 - Failed End
- Customer does not get necessary information and thus needs to go to multiple stores, wasting in this way a lot of time.
A.16.6 - Main Scenario
- Customer formulates query about availability of speakers in the stores within some radius.
Customer sends the query to the CustomerService.
CustomerService replies with information about the availability of speakers. CustomerService cannot say for sure whether a given type of speaker will be available in a store tomorrow or not. It all depends on delivery and rate of sell. Thus CustomerService provides the customer only with probabilistic information.
Since part of the query involves requests that cannot be answered in crisp terms (vagueness), CustomerService annotates its replies with fuzzy numbers.
CustomerService uses the uncertainty annotated information to compute a metric.
- Customer uses the resulting values of the metric for particular stores and for particular types of speaker to decide whether to buy speakers, what type and which store.
A.16.7 - Additional background information or references
This use case was inspired by the following paper: "sMart - A Semantic Matchmaking Portal for Electronic Markets", by Sudir Agarwal and Steffen Lamparter. In: Proceedings of the 7th International IEEE Conference on E-Commerce Technology 2005, Munich, Germany, IEEE Computer Society (2005).
A.16.8 - General Issues and Relevance to Uncertainty
1. There is known probability distribution on the availability of particular speaker type in particular stores on a particular day in the future. Say there are two stores (not too close to each other) and the probability that speakers of type X will be available in stores A and B tomorrow are Pr(X, A)=0.4 and Pr(X, B)=0.6. The probabilities for all types of speakers are represented in the same way.
The uncertainty annotation process (UncAnn) was used.
The agent issues a query (a sentence): Sentence. It is a complex sentence consisting of three basic sentences. One related to the availability, one to the wattage and one to the price of speakers.
Each of these sub-sentences will have uncertainty Uncertainty associated with it.
The uncertainty type related to the availability of particular speaker type in the stores is of type UncertaintyType: Empirical.
The uncertainty nature is UncertaintyNature: Aleatory.
The uncertainty model is UncertaintyModel: Probability.
2. The customer has (or obtains from CustomerService) definitions of features of wattage and price in terms of fuzzy membership functions. For wattage, Customer has three such functions: weak, medium and strong. These are of "trapezoid shaped" membership functions. Similarly, for price Customer has three such membership functions: cheap, reasonable and expensive.
The uncertainty type related to the features of wattage and price is of type UncertaintyType: Vagueness.
The uncertainty nature is UncertaintyNature: Epistemic.
The uncertainty model is UncertaintyModel: FuzzySets.
3. The valuation has three possible outcomes, all are expressed as fuzzy membership functions: bad, fair, good and super.
4. Customer knows the probabilistic information, since the probabilities are provided by CustomerService. CustomerService uses the Uncertainty Ontology for this purpose.
5. Customer has (or selects) fuzzy definitions of the features of wattage and price. Again, the six membership functions that define these features are annotated with the Uncertainty Ontology.
6. Customer has (or uses one suggested by CustomerService) a combination function that computes the decision, d, based upon those types of input. This function can be modified by each customer, however the stores need to give input to CustomerService - the probabilities and the (crisp) values of wattage and price for their products. The features are fuzzified by the customer's client software. Customer uses the Uncertainty Ontology to annotate the fuzziness of particular preferences.