Warning:
This wiki has been archived and is now read-only.
Social Web
Information pertaining to collaborating with the Social Web Incubator Group.
Social Web Provenance Related Use Cases
The following are use cases developed by the W3C Social Web Incubator Group that are relevant to provenance:
- Re-use your data
- Tracking sources
- Anonymity
- Shills (Veriying identity)
- Re-tracting mistweets
- Document takedown
- Which is a sub-case of the not fleshed out case, removing data or changing permission
Revised News Aggregator Scenario
Below is an edited version of the News Aggregator Scenario in the Provenance XG's User Requirements document. This version is tuned to address some of the novel concerns coming from the Social Web XG and the use cases above.
News Aggregator Scenario
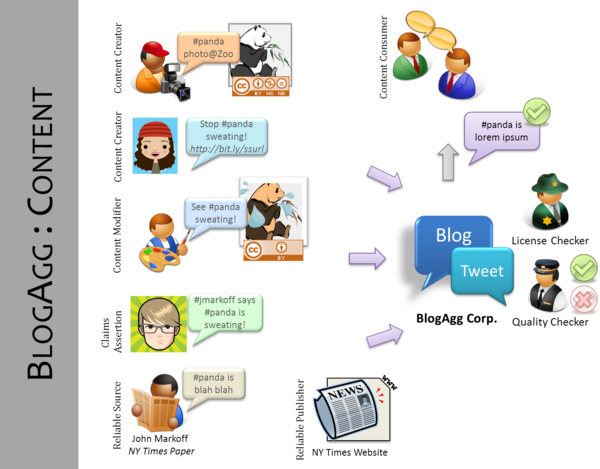
Many web users would like to have mechanisms to automatically determine whether a web document or resource can be used, based on the original source of the content, the licensing information associated with the resource, and any usage restrictions on that content. Furthermore, in cases of mashed-up content it would be useful to ascertain automatically whether or not to trust it by examining the processes that created, aggregated, and delivered it as well as who was responsible for these processes. To illustrate these issues, we present the following scenario of a fictitious website, BlogAgg, that aggregates news information and opinion from the Web.
BlogAgg aims to provide rich real time news to its readers automatically. It does this by aggregating information from a wider variety of sources including microblogging websites, news websites, publicly available blogs and other opinion. It is imperative for BlogAgg to present only credible and trusted content on its site to satisfy its customer, attract new business, and avoid legal issues. Importantly, it wants to ensure that the news that it aggregates are correctly attributed to the right person so that they may receive credit. Additionally, it wants to present the most attractive content it can find including images and video. However, unlike other aggregators it wants to track many different web sites to try and find the most up to the date news and information.
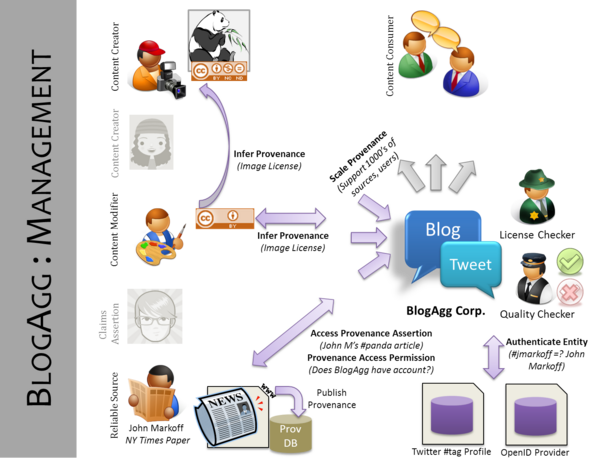
Unfortunately for BlogAgg, the source of the information is not often apparent from the data that it aggregates from the web. In particular, it must employ teams of people to check that selected content is both high-quality and can be used legally. The site would like this quality control process to be handled automatically.
For example, one day BlogAgg discovers that #panda is a trending topic on Twitter. It finds that a tweet "#panda being moved from Chicago Zoo to Florida! Stop it from sweating http://bit.ly/ssurl", is being retweeted across many different microblogging sites. BlogAgg wants to find the correct originator of the microblog who first got the word out. It would like to check if it is a trustworthy source (whether organization or person) and verify the news story. It would also like to credit the original source in its site, and in these credits it would like to include some identifying information about that person, for example, a link to a Facebook profile. In cases where the person wishes to remain anonymous, BlogAgg would like to provide some sort of information that shows the source is authoritative and/or trustworthy on the topic.
Following the tiny-url, BlogAgg discovers a site protesting the move of the panda. BlogAgg wants to determine what author (and their affiliation) is responsible for the site so that its name can run next to the snippet of text that BlogAgg runs. In determining the snippet of text to use, BlogAgg needs to determine whether or not the text originated at the panda protest site or was a quoted from another site. Additionally, the site contains an image of a panda that appears as if it is sweating. BlogAgg would like to automatically use a thumbnail version of this image in its site, therefore, it needs to determine if the image license allows this or if that license has expired and is no longer in force. Furthermore, BlogAgg would like to determine if the image was modified, by whom, and if the underlying image can be reused (i.e. whether the license of the image is actually correct). Additionally, it wants to find out whether any modifications were just touch-ups or were significant modifications. Using the various information about the content it has retrieved, BlogAgg creates an aggregated post. For the post, it provides a visual seal showing how much the site trusts the information. By clicking on the seal, the user can inspect how the post was constructed and from what sources and a description of how the trust rating was derived from those sources.
After publication of the panda piece by BlogAgg, the original author of the panda tweet discovers that the information that they had was incorrect and wants to retract the statement. She therefore removes (or clicks the retract button) on Twitter. BlogAgg periodically checks to see if any of the information it used to produce a piece has been retracted, if it has, it updates the post to reflect this retraction. During these checks, BlogAgg also checks whether their information is up-to-date for example if it's pointing a the correct identity of the author, whether that information has moved or been deleted.
Note, that BlogAgg would want to do this same sort of process for thousands to hundreds of thousands a sites a day. It would want to automate its aggregation and checking process as much as possible. It is important for BlogAgg to be able to detect when this aggregation process does not work in particular when it can not determine the origins of the content it uses. These need to be flagged and reported to BlogAgg's operators.